ORB特征笔记
简介
ORB = Oriented FAST + Rotated BRIEF
前面的Oriented FAST说明的是它的关键点的选取是一种改良过的FAST,在FAST的基础上加了方向信息;后面的Rotated BRIEF是指特征描述符使用BRIEF描述子(Binary Robust Independent Elementary Feature),是一种速度极快的二进制描述子。
改良的FAST角点检测
在前面笔记中已经记录了FAST角点检测的基本原理。oFAST主要改良的点是增加了关键点的方向描述,还有就是增加了图像金字塔。
1. 构造高斯金字塔
ORB中的图像金字塔和SIFT中的多尺度高斯金字塔不同,每层只有一副图。金字塔共有n层,第s层的尺度为:。
是初始尺度,默认值1.2。原图在第0层。第s层的图片尺寸为:
。

2. 特征点检测
在不同尺度的图像上使用FAST算法检测特征点 。FAST在边缘上有较大的响应,ORB中利用了Harris角点响应度量来排序FAST的关键点。对于目标为N个关键点的情况,首先将阈值设置得足够低以获取比N多的关键点,然后根据Harris角点响应值排序,选取前N个关键点。
3. 计算特征点主方向
使用灰度质心法计算出以特征点中心O为圆心,半径为r的圆形区域内的质心点C。 特征点的主方向是从O到C的向量的方向。
灰度质心的位置点C为:
其中,的计算方法为:
因此:
特征点的主方向角度为:
构建rBRIEF描述符
经过oFAST得到了关键点和其主方向后,接下来就要构建出关键点的特征描述符了。ORB有旋转不变性,在构建BRIEF描述符之前,会将特征点的邻域旋转到特征点的主方向上。
BRIEF特征描述符
BRIEF的核心思想是在关键点P的周围选取N个点对,然后把这N个点对的边角结果组合起来作为该关键点的描述子。Brief算法生成的是一种二值化的描述子,匹配的时候只需要使用简单的汉明距离比对即可,使用bits之间的异或操作就能完成。因此它的时间空间代价都比较低,效果也还不错。
1. 滤波:对原图滤波,去除部分噪声。
2. 选取点对:以关键点为中心,选取一定大小的图像窗口p,在窗口内选择一对点,比较两者像素值的大小,进行赋值,二值测试函数定义如下:
其中,表示像素x在窗口p内的像素值。
3. 在窗口p中随机选取N(128,256,512,默认为256) 对随机点对,重复第2步进行二进制赋值,最后得到一个N维的二进制描述子,这个结果向量被定义为:
这个式子其实直白理解就是,每一个bit表示了一个点对的对比结果。
Brief算法中点对的选取方法
对于SxS的区域内选取点对,原始Brief论文中做了5种方法:
1.(X,Y) ~ i.i.d(独立同分布)。服从均匀分布:
位置均匀分布在块内。
2. (X,Y) ~ i.i.d(独立同分布)。服从高斯分布:采样带内服从各向同性的高斯分布。
3. X ~ i.i.d(独立同分布),服从高斯分布;Y~ i.i.d(独立同分布),服从高斯分布
。 采样分两步,第一步以原点为中心的高斯分布中采样出
,然后再以
为中心,采样得到第二个位置。超出块的范围的位置会被钳在块的边缘处。
4. 在空间量化极坐标下的离散位置随机采样;
5. 。
固定为原点,
采样自粗粒度的极坐标网格的离散位置上。
上述5种采样方式的示意图如下:

在旋转不是非常厉害的图像里,用BRIEF生成的描述子的匹配质量非常高。
Steered BRIEF
原始的BRIEF算法,不具有旋转不变性,当平面发生非常小角度的旋转后,其匹配质量会大幅下降。下图是各种描述子在平面旋转角度和算法对应的正常有效点(inliers)的百分比示意图:

Steered BRIEF会根据关键点的方向进行旋转,然后再计算Biref描述符。对于特征点邻域内的n个点对的集合:
通过一个旋转角度为对应的旋转矩阵
做变换,定义出旋转后的点对集合
:
因此steered BRIEF算子变成了:
这个函数定义实际就是对旋转后的点对儿进行对比生成Biref描述符的计算过程。
rBRIEF
steered BRIEF解决了BRIEF不具有旋转不变性的问题,但它在描述符的可区分性上。描述符本身是关键点的特征信息,在匹配的时候可以用来区分不同的关键点。如果描述符的可区分性变差,则不同的关键点相似度会变高,不容易找到对应的关键点,误匹配率会变大。论文中对100K个采样的关键点用不同的方法生成的特征描述符的均值分布:

图中X轴表示到均值0.5的距离。y轴则是对应BRIEF描述符中的特征bits数量。
注:网上参考的所有文章几乎都是说y轴是特征点数量,这点我持保留意见,虽然最终要表达的意思是差不多的。论文中描述这个图表的原话是:
“the spread of means for a typical Gaussian BRIEF pattern of 256 bits over 100k sample keypoints”。
个人感觉应该是根据100K个采样点统计后按照概率所计算的描述符中某个bit feature列计算均值,然后按照这个均值到0.5的距离进行分段统计。假设距离为0的有140个,表示的是这256个列中,有140 bit feature列的均值就是0.5。如下图所示:

以上仅为个人理解,大家可以去看看原始论文,或者去参看一下“参考资料”中最后一个链接。
为什么X轴要用到均值0.5的距离?因为我们得到的描述符都是二值的(0,1),对于多个0和1组成的串。如果计算出的均值是0.5,则表示这个串中0和1的数量是相等的。如果0更多,则均值偏向0;如果1更多,则均值偏向1。后面两种情况计算距离都会偏离0.5,表示这一组数据中的0或1更多,因此对应的特征值就越相似,越难以区分。
为了解决steered BRIEF的这个问题,ORB中引入了rBRIEF。它不使用BRIEF原始论文中选取点对儿的5种方式的任何一种,而是通过统计学习得到一种比较好的选取点集的方法。
首先创建一个300K个关键点的训练集。然后在一个31x31大小的块中做二值测试。每个点对儿是块内部两个5x5的子窗口,一个子窗口相当于一个像素,其灰度值是这个子窗口内所有像素灰度值的均值,可以通过积分图像快速求得。我们记块的宽度,子窗口的宽度
。

因此,子窗口总数量为,计算得到不同的选取点对儿的方式为:
。
注:原始论文中,
。原始论文中N的值并没有覆盖全子窗口,M的值,论文中是有去除一些重叠的区域,但没有找到重叠区域是如何定义的。如果哪位大神清楚请帮忙说明一下。本文中的N和M来自网上的参考资料,更容易理解一点,N取的是全部子窗口(会加1),M按照组合方式计算(不考虑去掉重叠区域)。
rBRIEF算法的最终目的是从这M种选取点对儿方式中找出最优的256中选择方法。算法的流程如下:
1. 在每个样本点的31x31的邻域内,用不同的点对儿选取方式做二值测试,每个样本点对应M个结果。结果是一个300K * M的矩阵,对矩阵每一列计算均值:

2. 根据每一列的均值到0.5的距离对列进行重新排序,得到T(下图为一种可能出现的示意图):

3. 贪心搜索:
a. 将T的第一列取出放到R中;
b. 从T中取下一列,将它和R中的所有的列进行比较。如果相关性大于某个阈值则丢弃,否则将这一列放入R中。
c. 重复b步骤,直到R中选出了256个列。如果最终结果少于256个,则修改阈值再试一次。
经过这几步,最终就能得到256个点对儿的选取方法,结果就是rBREIF。
参考资料
https://www.researchgate.net/publication/221111151_ORB_an_efficient_alternative_to_SIFT_or_SURF![]() https://www.researchgate.net/publication/221111151_ORB_an_efficient_alternative_to_SIFT_or_SURFhttps://web.stanford.edu/class/cs231m/references/harris-stephens.pdf
https://www.researchgate.net/publication/221111151_ORB_an_efficient_alternative_to_SIFT_or_SURFhttps://web.stanford.edu/class/cs231m/references/harris-stephens.pdf![]() https://web.stanford.edu/class/cs231m/references/harris-stephens.pdfhttps://www.researchgate.net/publication/222485725_Measuring_Corner_Properties
https://web.stanford.edu/class/cs231m/references/harris-stephens.pdfhttps://www.researchgate.net/publication/222485725_Measuring_Corner_Properties![]() https://www.researchgate.net/publication/222485725_Measuring_Corner_Propertieshttps://www.researchgate.net/publication/221304115_BRIEF_Binary_Robust_Independent_Elementary_Features
https://www.researchgate.net/publication/222485725_Measuring_Corner_Propertieshttps://www.researchgate.net/publication/221304115_BRIEF_Binary_Robust_Independent_Elementary_Features![]() https://www.researchgate.net/publication/221304115_BRIEF_Binary_Robust_Independent_Elementary_Features02-p2-rbrief_哔哩哔哩_bilibili02-p2-rbrief是02-ORB特征提取的第2集视频,该合集共计2集,视频收藏或关注UP主,及时了解更多相关视频内容。
https://www.researchgate.net/publication/221304115_BRIEF_Binary_Robust_Independent_Elementary_Features02-p2-rbrief_哔哩哔哩_bilibili02-p2-rbrief是02-ORB特征提取的第2集视频,该合集共计2集,视频收藏或关注UP主,及时了解更多相关视频内容。 https://www.bilibili.com/video/BV1PW411M73t?p=2&vd_source=474bff49614e62744eb84e9f8340d91ahttp://media.ee.ntu.edu.tw/courses/cv/21S/slides/cv2021_lec03.pdf
https://www.bilibili.com/video/BV1PW411M73t?p=2&vd_source=474bff49614e62744eb84e9f8340d91ahttp://media.ee.ntu.edu.tw/courses/cv/21S/slides/cv2021_lec03.pdf![]() http://media.ee.ntu.edu.tw/courses/cv/21S/slides/cv2021_lec03.pdf
http://media.ee.ntu.edu.tw/courses/cv/21S/slides/cv2021_lec03.pdf
特征点匹配——ORB算法介绍_orb匹配算法_lhanchao的博客-CSDN博客《ORB: an efficient alternative to SIFT or SURF》是Rublee等人在2011年的ICCV上发表的一篇有关于特征点提取和匹配的论文,这篇论文介绍的方法跳出了SIFT和SURF算法的专利框架,同时以极快的运行速度赢得了众多青睐。下面我简单介绍一下ORB算法的流程。ORB算法的主要贡献如下: (1)为FAST算法提取的特征点加上了一个特征点方向; (2)使_orb匹配算法https://blog.csdn.net/lhanchao/article/details/52612954
相关文章:
ORB特征笔记
简介 ORB Oriented FAST Rotated BRIEF 前面的Oriented FAST说明的是它的关键点的选取是一种改良过的FAST,在FAST的基础上加了方向信息;后面的Rotated BRIEF是指特征描述符使用BRIEF描述子(Binary Robust Independent Elementary Featur…...
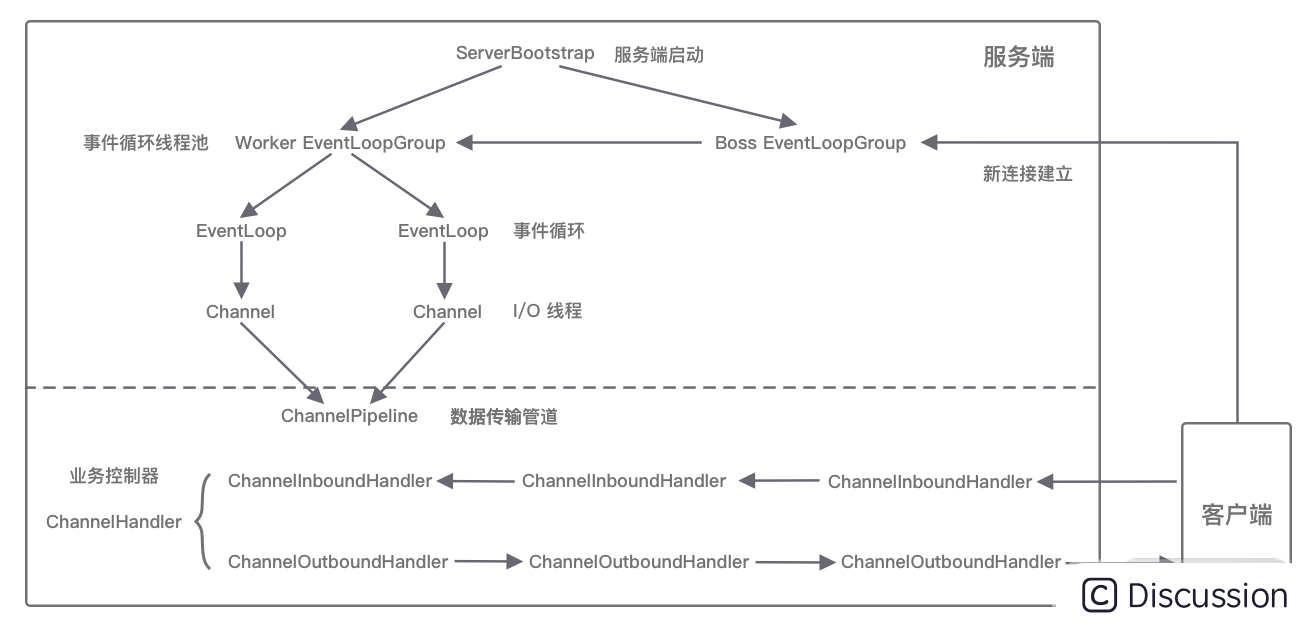
12.Netty源码之整体架构脉络
Netty 整体架构脉络 Netty 的逻辑处理架构为典型网络分层架构设计,共分为网络通信层、事件调度层、服务编排层,每一层各司其职。 网络通信层 网络通信层的职责是执行网络 I/O 的操作。它支持多种网络协议和 I/O 模型的连接操作。当网络数据读取到内核缓冲…...
【ArcGIS Pro二次开发】(54):三调名称转用地用海名称
三调地类和用地用海地类之间有点相似但并不一致。 在做规划时,拿到的三调,都需要将三调地类转换为用地用海地类,然后才能做后续的工作。 一般情况下,三调转用地用海存在【一对一,多对一和一对多】3种情况。 前2种情况…...

3D Tiles官方示例资源下载链接
本文列出Cesium官方提供的 3D Tiles 1.0和1.1规范的9个示例切块集(tileset)。 有关如何使用本地服务器托管这些示例的详细信息,请参阅 INSTRUCTIONS.md。 推荐:用 NSDT设计器 快速搭建可编程3D场景。 1、Metadata Granularities …...

【Java】分支结构习题
【Java】分支结构 文章目录 【Java】分支结构题1 :数字9 出现的次数题2 :计算1/1-1/21/3-1/41/5 …… 1/99 - 1/100 的值。题3 :猜数字题4 :牛客BC110 X图案题5 :输出一个整数的每一位题6 : 模拟三次密码输…...
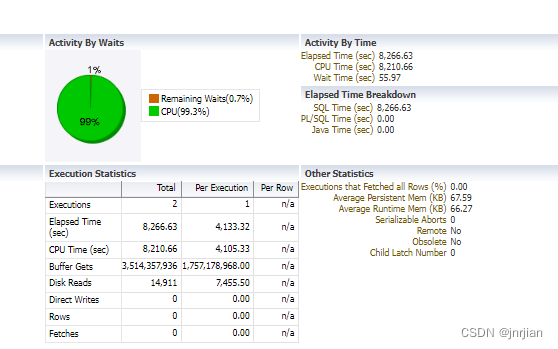
删除主表 子表外键没有索引的性能优化
整个表147M,执行时一个CPU耗尽, buffer gets 超过1个G, 启用并行也没有用 今天开发的同事问有个表上的数据为什么删不掉?我看了一下,也就不到100000条数据,表上有外键,等了5分钟hang在那里&…...

面向切面编程AOP
面向切面编程简介 IoC使软件组件松耦合。AOP让你能够捕捉系统中经常使用的功能,把它转化成组件。 AOP(Aspect Oriented Programming):面向切面编程,面向方面编程。(AOP是一种编程技术) AOP是对…...

大学生活题解
样例输入: 3 .xA ... Bx.样例输出: 6思路分析: 这道题只需要在正常的广搜模板上多维护一个— —方向,如果当前改变方向,就坐标不变,方向变,步数加一;否则坐标变,方向不…...

flask的配置项
flask的配置项 为了使 Flask 应用程序正常运行,有多种配置选项需要考虑。下面是一些基本的 Flask 配置选项: DEBUG: 这个配置项决定 Flask 是否应该在调试模式下运行。如果这个值被设为 True,Flask 将会提供更详细的错误信息,并…...

暑假刷题第16天--7/28
143. 最大异或对 - AcWing题库(字典树) #include<iostream> using namespace std; const int N100005; int a[N]; int nex[10000007][2],cnt; void insert(int x){int p0;for(int i30;i>0;i--){int ux>>i&1;if(!nex[p][u])nex[p][u]…...

vue vite ts electron ipc arm64
初始化 npm init vue # 全选 yes npm i # 进入项目目录后使用 npm install electron electron-builder -D npm install commander -D # 额外组件增加文件 新建 plugins 文件夹 src/background.ts 属于主进程 ipcMain.on、ipcMain.handle 都用于主进程监听 ipc,…...

数据分析-关于指标和指标体系
一、电商指标体系 二、指标体系的作用 三、统计学中基本的分析手段...

Vue+ElementUI操作确认框及提示框的使用
在进行数据增删改查操作中为保证用户的使用体验,通常需要显示相关操作的确认信息以及操作结果的通知信息。文章以数据的下载和删除提示为例进行了简要实现,点击下载以及删除按钮,会出现对相关信息的提示,操作结果如下所示。 点击…...

宋浩线性代数笔记(二)矩阵及其性质
更新线性代数第二章——矩阵,本章为线代学科最核心的一章,知识点多而杂碎,务必仔细学习。 重难点在于: 1.矩阵的乘法运算 2.逆矩阵、伴随矩阵的求解 3.矩阵的初等变换 4.矩阵的秩 (去年写的字,属实有点ugl…...

Linux之Shell 编程详解(二)
第 9 章 正则表达式入门 正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文 本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在 Linux 中,grep, sed,awk 等文本处理工具都支持…...
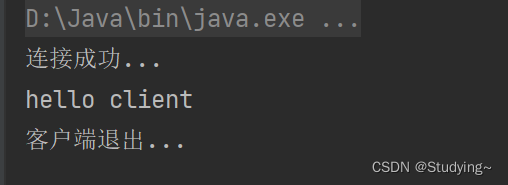
TCP网络通信编程之字节流
目录 【TCP字节流编程】 // 网络编程中,一定是server端先运行 【案例1】 【思路分析】 【客户端代码】 【服务端代码】 【结果展示】 【案例2】 【题目描述】 【注意事项】 【服务端代码】 【客户端代码】 【代码结果】 【TCP字节流编程】 // 网络编程中&a…...

【暑期每日一练】 day8
目录 选择题 (1) 解析: (2) 解析: (3) 解析: (4) 解析: (5) 解析: 编程题 题一 描述…...

maven的基本学习
maven https://www.bilibili.com/video/BV14j411S76G?p1&vd_source5c648979fd92a0f7ba8de0cde4f02a6e 1.简介 1.1介绍 Maven翻译为"专家"、“内行”,是Apache下的一个纯Java开发的开源项目。基于项目对象模型(缩写:POM)概念,Maven利用一…...

疲劳驾驶检测和识别2:Pytorch实现疲劳驾驶检测和识别(含疲劳驾驶数据集和训练代码)
疲劳驾驶检测和识别2:Pytorch实现疲劳驾驶检测和识别(含疲劳驾驶数据集和训练代码) 目录 疲劳驾驶检测和识别2:Pytorch实现疲劳驾驶检测和识别(含疲劳驾驶数据集和训练代码) 1.疲劳驾驶检测和识别方法 2.疲劳驾驶数据集 (1)疲…...

安防监控视频汇聚EasyCVR修改录像计划等待时间较长,是什么原因?
安防监控视频EasyCVR视频融合汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发等。音视频流媒体视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、云存储、回放与检…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...
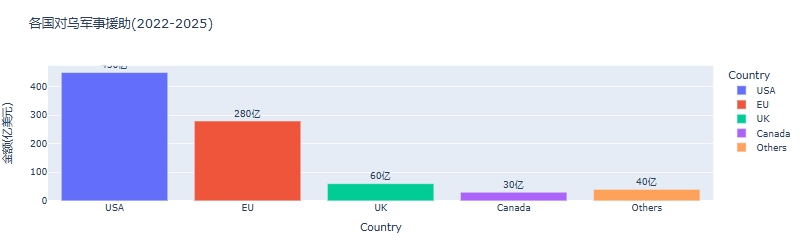
python可视化:俄乌战争时间线关键节点与深层原因
俄乌战争时间线可视化分析:关键节点与深层原因 俄乌战争是21世纪欧洲最具影响力的地缘政治冲突之一,自2022年2月爆发以来已持续超过3年。 本文将通过Python可视化工具,系统分析这场战争的时间线、关键节点及其背后的深层原因,全面…...

Qt/C++学习系列之列表使用记录
Qt/C学习系列之列表使用记录 前言列表的初始化界面初始化设置名称获取简单设置 单元格存储总结 前言 列表的使用主要基于QTableWidget控件,同步使用QTableWidgetItem进行单元格的设置,最后可以使用QAxObject进行单元格的数据读出将数据进行存储。接下来…...
: 发布订阅模式)
JS设计模式(5): 发布订阅模式
解锁JavaScript发布订阅模式:让代码沟通更优雅 在JavaScript的世界里,我们常常会遇到这样的场景:多个模块之间需要相互通信,但是又不想让它们产生过于紧密的耦合。这时候,发布订阅模式就像一位优雅的信使,…...