2023年的深度学习入门指南(19) - LLaMA 2源码解析
2023年的深度学习入门指南(19) - LLaMA 2源码解析
上一节我们学习了LLaMA 2的补全和聊天两种API的使用方法。本节我们来看看LLaMA 2的源码。
补全函数text_completion源码解析
上一节我们讲了LLaMA 2的编程方法。我们来复习一下:
generator = Llama.build(ckpt_dir=ckpt_dir,tokenizer_path=tokenizer_path,max_seq_len=max_seq_len,max_batch_size=max_batch_size,)prompts = ["上下五千年,英雄万万千。黄沙百战穿金甲,不破楼兰终不还",]results = generator.text_completion(prompts,max_gen_len=max_gen_len,temperature=temperature,top_p=top_p,)
我们先来看看text_completion函数的参数是什么意思,该函数的原型为:
def text_completion(
self,
prompts: List[str],
temperature: float = 0.6,
top_p: float = 0.9,
max_gen_len: Optional[int] = None,
logprobs: bool = False,
echo: bool = False,
) -> List[CompletionPrediction]:
我们来看下这些参数的含义:
- prompts:这是一个字符串列表,每个字符串都是一个用于生成文本的提示。
- temperature(默认值为0.6):这是一个控制生成文本随机性的参数。温度值越高,生成的文本就越随机;温度值越低,生成的文本就越倾向于最可能的输出。
- top_p(默认值为0.9):这是一个控制生成文本多样性的参数,它设定了从最高概率的词开始,累计到总概率超过top_p的词为止,然后从这些词中随机选择一个词作为生成的词。这种方法也被称为nucleus sampling或top-p sampling。
- max_gen_len:可选参数,表示生成的文本的最大长度。如果未指定,那么将使用模型参数中的最大序列长度减1。
- logprobs(默认值为False):如果为True,那么在返回的结果中会包含生成的每个词的对数概率。
- echo(默认值为False):这是一个控制是否在生成的文本中包含输入提示的参数。
参数明白了之后我们看text_completion完整实现:
def text_completion(self,prompts: List[str],temperature: float = 0.6,top_p: float = 0.9,max_gen_len: Optional[int] = None,logprobs: bool = False,echo: bool = False,) -> List[CompletionPrediction]:if max_gen_len is None:max_gen_len = self.model.params.max_seq_len - 1prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]generation_tokens, generation_logprobs = self.generate(prompt_tokens=prompt_tokens,max_gen_len=max_gen_len,temperature=temperature,top_p=top_p,logprobs=logprobs,echo=echo,)if logprobs:return [{"generation": self.tokenizer.decode(t),"tokens": [self.tokenizer.decode(x) for x in t],"logprobs": logprobs_i,}for t, logprobs_i in zip(generation_tokens, generation_logprobs)]return [{"generation": self.tokenizer.decode(t)} for t in generation_tokens]
总结起来就三步,这个text_completion其实就是generate的包装函数:
- 编码:调用tokenizer.encode
- 生成:调用generate
- 解码:调用tokenizer.decode
分词

import os
from logging import getLogger
from typing import Listfrom sentencepiece import SentencePieceProcessorlogger = getLogger()class Tokenizer:def __init__(self, model_path: str):# reload tokenizerassert os.path.isfile(model_path), model_pathself.sp_model = SentencePieceProcessor(model_file=model_path)logger.info(f"Reloaded SentencePiece model from {model_path}")# BOS / EOS token IDsself.n_words: int = self.sp_model.vocab_size()self.bos_id: int = self.sp_model.bos_id()self.eos_id: int = self.sp_model.eos_id()self.pad_id: int = self.sp_model.pad_id()logger.info(f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}")assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()def encode(self, s: str, bos: bool, eos: bool) -> List[int]:assert type(s) is strt = self.sp_model.encode(s)if bos:t = [self.bos_id] + tif eos:t = t + [self.eos_id]return tdef decode(self, t: List[int]) -> str:return self.sp_model.decode(t)
首先是用到了分词组件SentencePieceProcessor。SentencePieceProcessor是SentencePiece库中的一个组件,它实现了子词(subword)tokenize和detokenize的功能。
其主要作用包括:
- 将文本tokenize成子词(subword)。SentencePiece 使用的数据驱动方法,可以学习文本的词汇表并将文本tokenize成子词单元。
- 将子词detokenize合并成原始文本。可以将tokenize后的子词序列重新合并为原始文本。
- 提供vocab管理。可以获得tokenize的子词词汇表等信息。
- 支持多种语言文本的tokenize和detokenize。
- 提供高效的实现。底层使用C++实现,可以快速处理大规模文本。
- 提供多种模型选择,如BPE、unigram等。
- 支持自定义训练子词化模型。
好,下面我们回到这段代码本身。这段代码实现了一个基于SentencePiece的Tokenizer类,可以进行文本的tokenize和detokenize。
主要逻辑:
- 在初始化时加载SentencePiece模型文件model_path。
- 获取模型的词汇表大小n_words,以及特殊token的id(bos_id,eos_id,pad_id)。
- encode方法可以将字符串文本s tokenize成id列表。可以选择在开始加入bos_id,结尾加入eos_id。
- decode方法可以将id列表解码还原为字符串文本。
这样就构建了一个封装SentencePiece tokenize/detokenize的Tokenizer类。可以加载自定义的SentencePiece模型,然后就可以方便地对文本进行子词化处理。
这种方式可以重复使用已训练好的SentencePiece模型,为下游NLP任务提供可靠的tokenize和detokenize功能。
最后我们再讲一讲几个特殊的符号bos_id、eos_id和pad_id:
- bos_id: 开始符(Beginning of Sentence)的id。用于表示一个序列的开始。
- eos_id: 结束符(End of Sentence)的id。用于表示一个序列的结束。
- pad_id: 填充符(Padding)的id。当需要将多个序列长度对齐时,可以使用pad_id在较短序列后面填充。
聊天函数chat_completion
在进入generate函数之前,我们再看看chat_completion是如何实现的。
def chat_completion(self,dialogs: List[Dialog],temperature: float = 0.6,top_p: float = 0.9,max_gen_len: Optional[int] = None,logprobs: bool = False,) -> List[ChatPrediction]:if max_gen_len is None:max_gen_len = self.model.params.max_seq_len - 1prompt_tokens = []for dialog in dialogs:if dialog[0]["role"] != "system":dialog = [{"role": "system","content": DEFAULT_SYSTEM_PROMPT,}] + dialogdialog = [{"role": dialog[1]["role"],"content": B_SYS+ dialog[0]["content"]+ E_SYS+ dialog[1]["content"],}] + dialog[2:]assert all([msg["role"] == "user" for msg in dialog[::2]]) and all([msg["role"] == "assistant" for msg in dialog[1::2]]), ("model only supports 'system', 'user' and 'assistant' roles, ""starting with 'system', then 'user' and alternating (u/a/u/a/u...)")dialog_tokens: List[int] = sum([self.tokenizer.encode(f"{B_INST} {(prompt['content']).strip()} {E_INST} {(answer['content']).strip()} ",bos=True,eos=True,)for prompt, answer in zip(dialog[::2],dialog[1::2],)],[],)assert (dialog[-1]["role"] == "user"), f"Last message must be from user, got {dialog[-1]['role']}"dialog_tokens += self.tokenizer.encode(f"{B_INST} {(dialog[-1]['content']).strip()} {E_INST}",bos=True,eos=False,)prompt_tokens.append(dialog_tokens)generation_tokens, generation_logprobs = self.generate(prompt_tokens=prompt_tokens,max_gen_len=max_gen_len,temperature=temperature,top_p=top_p,logprobs=logprobs,)if logprobs:return [{"generation": {"role": "assistant","content": self.tokenizer.decode(t),},"tokens": [self.tokenizer.decode(x) for x in t],"logprobs": logprobs_i,}for t, logprobs_i in zip(generation_tokens, generation_logprobs)]return [{"generation": {"role": "assistant", "content": self.tokenizer.decode(t)}}for t in generation_tokens]
我们先看一下参数:
- dialogs:一个对话列表,其中每个对话都是一个字典列表,表示一段对话。
- temperature:一个浮点数,表示生成文本时使用的温度。默认值为 0.6。
- top_p:一个浮点数,表示生成文本时使用的 top-p 采样。默认值为 0.9。
- max_gen_len:一个可选的整数,表示生成文本的最大长度。如果未指定,则使用模型参数中的最大序列长度减一。
- logprobs:一个布尔值,表示是否返回生成文本的对数概率。默认值为 False。
函数返回一个 ChatPrediction 列表,其中每个元素都是一个字典,包含生成的回复和相关信息。
函数首先检查 max_gen_len 是否为 None,如果是,则将其设置为模型参数中的最大序列长度减一。然后,对于每个对话,函数执行以下操作:
- 如果第一条消息的角色不是 “system”,则在对话的开头添加一条默认的系统提示。
- 将第一条和第二条消息合并为一条消息,并更新对话。
- 检查对话中消息的角色是否符合要求(即以 “system” 开始,然后交替出现 “user” 和 “assistant”)。
- 对于每一组相邻的提示和回答(即每两条消息),使用 tokenizer 对其进行编码,并将编码后的 token 连接起来。
- 检查最后一条消息是否来自用户。
- 对最后一条消息进行编码,并将编码后的 token 添加到 token 列表中。
接下来,函数调用 generate 方法生成回复,并根据 logprobs 参数的值返回相应的结果。如果 logprobs 为 True,则返回包含生成回复、token 和对数概率的字典列表;否则,返回仅包含生成回复的字典列表。这些生成回复都具有 “assistant” 角色,并使用 tokenizer 进行解码。
总体来说,只是增加了对于对话角色的业务逻辑处理,核心还是调用generate函数。
温度与top p采样
在进入讲解generate函数之前,我们先讲一个小知识点,就是温度temperature的作用。我们看下面的代码:
if temperature > 0:probs = torch.softmax(logits[:, -1] / temperature, dim=-1)next_token = sample_top_p(probs, top_p)else:next_token = torch.argmax(logits[:, -1], dim=-1)
temperature 是一个超参数,用于控制生成文本的多样性。当 temperature 较高时,概率分布更加平坦,因此采样出的标记更具多样性。当 temperature 较低时,概率分布更加尖锐,因此采样出的标记更倾向于概率最大的那个。当 temperature 等于 0 时,直接选择概率最大的标记。

那么,sample_top_p是如何实现的呢?我把解说写在代码注释里面了:
def sample_top_p(probs, p):# 这行代码将输入的概率 probs 按照降序排序。probs_sort 是排序后的概率,probs_idx 是对应的索引。probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)# 这行代码计算 probs_sort 的累积和。累积和是从第一个元素开始,依次将序列中的每个元素与前面所有元素的和相加得到的。probs_sum = torch.cumsum(probs_sort, dim=-1)# 这行代码生成一个布尔掩码,用于指示哪些累积和减去当前概率的值大于 p。这用于确定哪些概率应该被设为0,以保证被抽样的概率和不超过 p。mask = probs_sum - probs_sort > p# 这行代码使用上述生成的掩码,将那些使累积和减去当前概率的值大于 p 的 probs_sort 中的元素设为0。probs_sort[mask] = 0.0# 这行代码将 probs_sort 中的每个元素除以它们的和,以便重新归一化概率分布。probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))# 这行代码从归一化的 probs_sort 中抽取一个样本。torch.multinomial 是PyTorch中的多项式分布抽样函数,它根据每个元素的权重抽取样本。next_token = torch.multinomial(probs_sort, num_samples=1)# 这行代码使用 torch.gather 函数从 probs_idx 中收集对应 next_token 的索引,这样就能得到原始概率 probs 中对应的索引。next_token = torch.gather(probs_idx, -1, next_token)return next_token
总的来说,sample_top_p保留了按概率高低排序的大致分布,但过滤了长尾部分的低概率噪声。然后从重归一化的分布中采样,既保证了质量,又增加了适当的随机性。
generate函数
好,我们终于开始探索最核心的生成函数上了:
@torch.inference_mode()def generate(self,prompt_tokens: List[List[int]],max_gen_len: int,temperature: float = 0.6,top_p: float = 0.9,logprobs: bool = False,echo: bool = False,) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
首先是这个函数的参数,其实我们已经比较熟悉了。包括输入的提示 tokens(prompt_tokens),最大生成长度(max_gen_len),温度参数(temperature,影响生成文本的随机性), top_p(用于决定采样过程中保留的 token 集合的概率阈值,也被称为 “nucleus sampling”),是否返回每个 token 的对数概率(logprobs),以及是否将输入的提示返回(echo)。
params = self.model.paramsbsz = len(prompt_tokens)assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)min_prompt_len = min(len(t) for t in prompt_tokens)max_prompt_len = max(len(t) for t in prompt_tokens)assert max_prompt_len <= params.max_seq_lentotal_len = min(params.max_seq_len, max_gen_len + max_prompt_len)pad_id = self.tokenizer.pad_idtokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")for k, t in enumerate(prompt_tokens):tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")if logprobs:token_logprobs = torch.zeros_like(tokens, dtype=torch.float)prev_pos = 0eos_reached = torch.tensor([False] * bsz, device="cuda")input_text_mask = tokens != pad_id
接着,根据提供的 prompt_tokens 初始化一个 tokens 张量,长度为 total_len,并填充模型的 pad_id。然后,将 prompt_tokens 的内容复制到 tokens 张量的对应位置。
for cur_pos in range(min_prompt_len, total_len):logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)if logprobs:token_logprobs[:, prev_pos + 1 : cur_pos + 1] = -F.cross_entropy(input=logits.transpose(1, 2),target=tokens[:, prev_pos + 1 : cur_pos + 1],reduction="none",ignore_index=pad_id,)if temperature > 0:probs = torch.softmax(logits[:, -1] / temperature, dim=-1)next_token = sample_top_p(probs, top_p)else:next_token = torch.argmax(logits[:, -1], dim=-1)next_token = next_token.reshape(-1)# only replace token if prompt has already been generatednext_token = torch.where(input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token)tokens[:, cur_pos] = next_tokeneos_reached |= (~input_text_mask[:, cur_pos]) & (next_token == self.tokenizer.eos_id)prev_pos = cur_posif all(eos_reached):break
然后,对于 tokens 张量中的每一个位置,计算下一个 token 的 logits,并基于这些 logits 生成下一个 token。如果 logprobs 参数为真,则计算每个 token 的对数概率。如果温度大于 0,则使用 softmax 函数和温度参数对 logits 进行缩放,然后使用 top-p 采样生成下一个 token。否则,直接选择 logits 最大的 token。新生成的 token 会替换 tokens 张量中的对应位置。
如果生成的 token 是结束标记(eos_id),则更新 eos_reached 标记。如果所有的序列都已经生成了结束标记,则停止生成。
if logprobs:token_logprobs = token_logprobs.tolist()out_tokens, out_logprobs = [], []for i, toks in enumerate(tokens.tolist()):# cut to max gen lenstart = 0 if echo else len(prompt_tokens[i])toks = toks[start : len(prompt_tokens[i]) + max_gen_len]probs = Noneif logprobs:probs = token_logprobs[i][start : len(prompt_tokens[i]) + max_gen_len]# cut to eos tok if anyif self.tokenizer.eos_id in toks:eos_idx = toks.index(self.tokenizer.eos_id)toks = toks[:eos_idx]probs = probs[:eos_idx] if logprobs else Noneout_tokens.append(toks)out_logprobs.append(probs)return (out_tokens, out_logprobs if logprobs else None)
最后,如果 logprobs 参数为真,则将 token_logprobs 转换为列表。然后,对于 tokens 张量中的每一行(即每一个生成的序列),如果 echo 参数为假,则去掉提示部分。然后,如果存在结束标记,则去掉结束标记之后的部分。最后,返回生成的 tokens 和对数概率(如果 logprobs 参数为真)。
这个函数返回的是一个元组,第一个元素是一个列表,包含每一个生成的 token 序列。第二个元素是一个列表,包含每一个生成的对数概率序列(如果 logprobs 参数为真)。
build构造函数
最后我们再说下构造Llama的部分:
@staticmethoddef build(ckpt_dir: str,tokenizer_path: str,max_seq_len: int,max_batch_size: int,model_parallel_size: Optional[int] = None,) -> "Llama":if not torch.distributed.is_initialized():torch.distributed.init_process_group("nccl")if not model_parallel_is_initialized():if model_parallel_size is None:model_parallel_size = int(os.environ.get("WORLD_SIZE", 1))initialize_model_parallel(model_parallel_size)local_rank = int(os.environ.get("LOCAL_RANK", 0))torch.cuda.set_device(local_rank)# seed must be the same in all processestorch.manual_seed(1)if local_rank > 0:sys.stdout = open(os.devnull, "w")start_time = time.time()checkpoints = sorted(Path(ckpt_dir).glob("*.pth"))assert len(checkpoints) > 0, f"no checkpoint files found in {ckpt_dir}"assert model_parallel_size == len(checkpoints), f"Loading a checkpoint for MP={len(checkpoints)} but world size is {model_parallel_size}"ckpt_path = checkpoints[get_model_parallel_rank()]checkpoint = torch.load(ckpt_path, map_location="cpu")with open(Path(ckpt_dir) / "params.json", "r") as f:params = json.loads(f.read())model_args: ModelArgs = ModelArgs(max_seq_len=max_seq_len,max_batch_size=max_batch_size,**params,)tokenizer = Tokenizer(model_path=tokenizer_path)model_args.vocab_size = tokenizer.n_wordstorch.set_default_tensor_type(torch.cuda.HalfTensor)model = Transformer(model_args)model.load_state_dict(checkpoint, strict=False)print(f"Loaded in {time.time() - start_time:.2f} seconds")return Llama(model, tokenizer)
虽然这么一大段,但其实都是一些初始化的工作。
-
分布式设置:首先,这段代码检查是否已经初始化了 PyTorch 的分布式环境,如果没有则进行初始化。然后,检查是否已经初始化了模型并行环境,如果没有,则获取环境变量 WORLD_SIZE 的值作为模型并行的大小,并进行初始化。
-
设备设置:获取环境变量 LOCAL_RANK 的值作为本地排名,并设置当前设备为该排名对应的 GPU。
-
随机种子设置:为了确保所有进程生成的随机数相同,设置随机种子为 1。
-
标准输出设置:如果本地排名大于 0,则将标准输出重定向到空设备,即不显示任何输出。
-
加载模型检查点:找到检查点目录中的所有检查点文件,并按照文件名排序。然后,根据模型并行的排名选择一个检查点文件,并加载该检查点。然后,加载模型参数。
-
构建模型和分词器:使用加载的模型参数和提供的 max_seq_len 和 max_batch_size 构建模型参数对象。然后,加载分词器,并设置模型参数的词汇表大小为分词器的词汇表大小。然后,设置默认的张量类型为半精度浮点型(以节省内存和计算资源)。然后,构建 Transformer 模型,并加载模型检查点。
-
最后,构建一个 Llama 对象,包含加载的模型和分词器,并返回该对象。
小结
本节我们学习了LLaMA 2的源码,包括补全函数text_completion和聊天函数chat_completion的实现,以及它们的真正实现generate函数的原理。我们还学习了温度temperature和top p采样的原理。
对于没有搞到深度学习生成的同学,可能有一点难度。
LLaMA的代码还差一部分就是模型的部分,我们放到下一节来讲。要不然知识点太多大家容易大脑缺氧:)
相关文章:
2023年的深度学习入门指南(19) - LLaMA 2源码解析
2023年的深度学习入门指南(19) - LLaMA 2源码解析 上一节我们学习了LLaMA 2的补全和聊天两种API的使用方法。本节我们来看看LLaMA 2的源码。 补全函数text_completion源码解析 上一节我们讲了LLaMA 2的编程方法。我们来复习一下: generator Llama.build(ckpt_di…...

慕课网Go-2.数组、slice、map、list
数组 package mainimport "fmt"func main() {var course1 [3]stringcourse1[0] "go"course1[1] "grpc"course1[2] "gin"for _, value : range course1 {fmt.Println(value)}course2 : [3]string{2: "grpc"}fmt.Println(…...

Django的Rest framework搭建自定义授权登录
系列文章目录 提示:阅读本章之前,请先阅读目录 文章目录 系列文章目录一、前言User模型User的viewsUser的serializersutils的md5加密自定义认证方法配置路由总路由分路由rest的配置 一、前言 之前的文章有写过通过jwt认证的文章,今天这一篇是…...

01 矩阵(力扣)多源广度优先搜索 JAVA
给定一个由 0 和 1 组成的矩阵 mat ,请输出一个大小相同的矩阵,其中每一个格子是 mat 中对应位置元素到最近的 0 的距离。 两个相邻元素间的距离为 1 。 输入:mat [[0,0,0],[0,1,0],[0,0,0]] 输出:[[0,0,0],[0,1,0],[0,0,0]] 输入…...
怎么绘制简爱思维导图?用这个工具绘制很简单
怎么绘制简爱思维导图?绘制思维导图是一项非常有用的技能,有助于梳理思路、整理知识、更好地理解和记忆信息。因此,无论你是学生、教师、工程师、项目经理或者只是想要更好地组织自己的想法,学会绘制思维导图都是非常有益的。下面…...
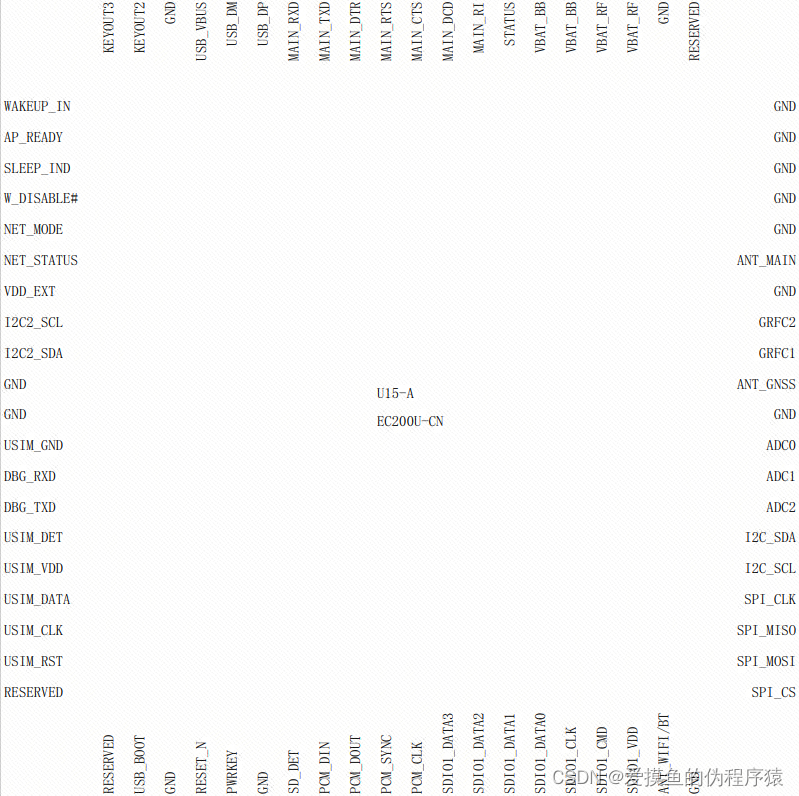
EC200U-CN学习(三)
EC200U系列内置丰富的网络协议,集成多个工业标准接口,并支持多种驱动和软件功能(适用于Windows 7/8/8.1/10、Linux和Android等操作系统下的USB驱动),极大地拓展了其在M2M领域的应用范围,如POS、POC、ETC、共…...
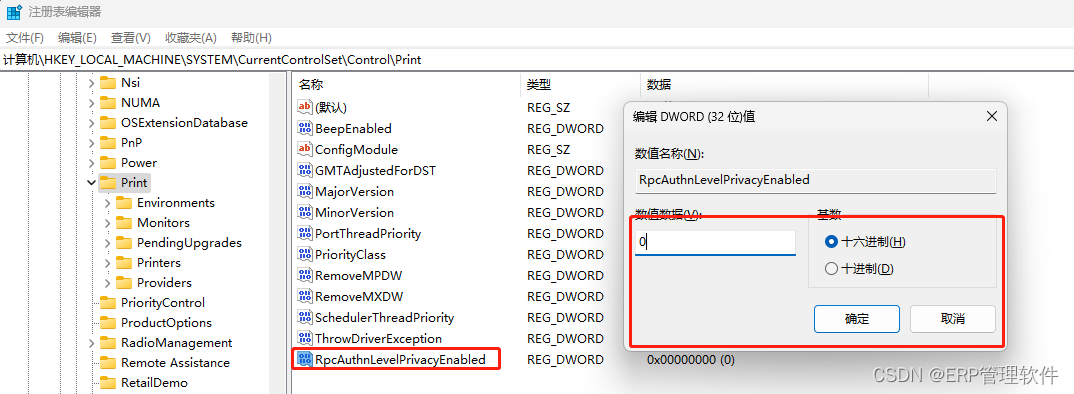
【windows】连接共享打印机提示:0x0000011B
【问题现象】 添加共享打印机的时候, 提示错误:0x0000011B。 【解决方法】 按winr键,在运行输入regedit 然后在注册表中找到路径: 计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Print 打开后,在右侧…...
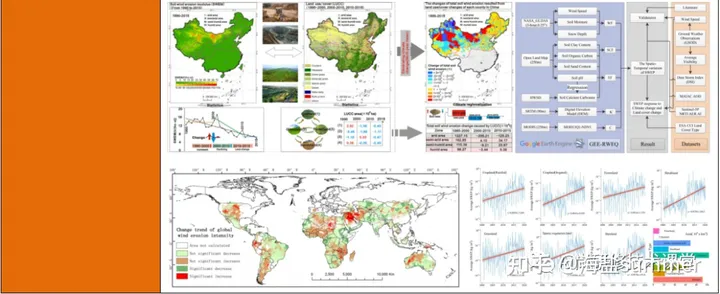
基于“RWEQ+”集成技术在土壤风蚀模拟与风蚀模数估算、变化归因分析中的实践应用及SCI论文撰写
【查看原文】基于“RWEQ”集成技术在土壤风蚀模拟与风蚀模数估算、变化归因分析中的实践应用及SCI论文撰写 土壤风蚀是一个全球性的环境问题。中国是世界上受土壤风蚀危害最严重的国家之一,土壤风蚀是中国干旱、半干旱及部分湿润地区土地荒漠化的首要过程。中国风…...

Flutter-基础Widget
Flutter页面-基础Widget 文章目录 Flutter页面-基础WidgetWidgetStateless WidgetStateful WidgetState生命周期 基础widget文本显示TextRichTextDefaultTextStyle 图片显示FlutterLogoIconImageIamge.assetImage.fileImage.networkImage.memory CircleAvatarFadeInImage 按钮R…...
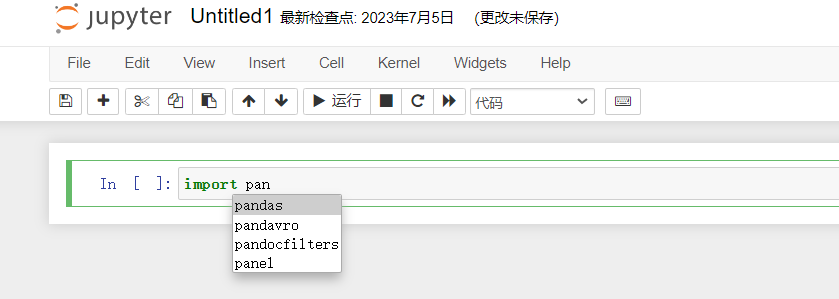
【数据分析专栏之Python篇】二、Jupyer Notebook安装配置及基本使用
文章目录 前言一、Jupter Notebook是什么1.1 简介1.2 组成部分1.3 Jupyter Notebook的主要特点 二、为什么使用Jupyter Notebook?三、安装四、Jupyter Notebok配置4.1 基本配置4.2 配置开机自启与后台运行4.3 开启代码自动补全 五、两种键盘输入模式5.1 编辑模式5.2 命令模式5…...

ubuntu22.04 DNSSEC(加密DNS服务) configuration
/etx/systemd/resolved.conf是ubuntu下DNS解析服务配置文件,systemd为ubuntu下system and service配置目录 step 1——修改resolved.conf参数 管理员权限打开 /systemd/resolved.conf sudo nano /etc/systemd/resolved.conf修改如下: # This file i…...
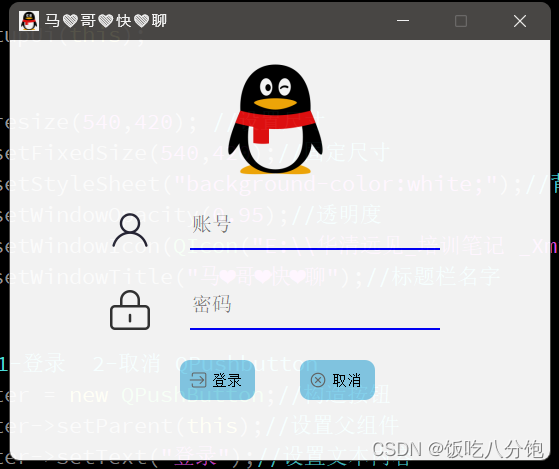
Qt 第一讲
登录框设置 #include "zuoye.h" #include "ui_zuoye.h"Zuoye::Zuoye(QWidget *parent): QWidget(parent), ui(new Ui::Zuoye) {ui->setupUi(this);//界面this->resize(540,420); //设置尺寸this->setFixedSize(540,420);//固定尺寸this->setS…...
IDEA 使用 maven 搭建 spring mvc
1. 创建项目 1.1 创建成功之后配置 Spring MVC 1.2 勾选 Spring MVC 2.更改配置文件 2.1 更改web.xml配置 更改为 <servlet-mapping><servlet-name>dispatcher</servlet-name><url-pattern>/</url-pattern></servlet-mapping>2.2 dispat…...
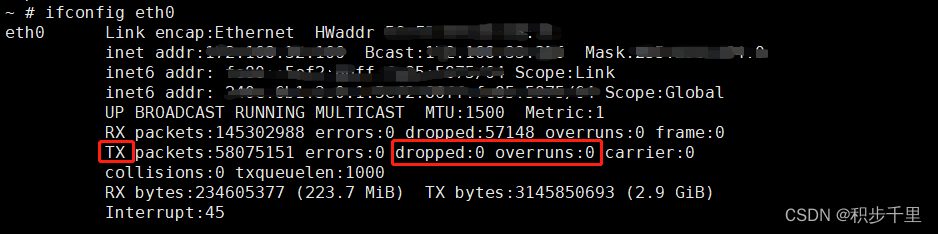
Hi3536网络应用调优
目录 1. 为什么UDP接收或发送会丢包? 2. 使用 socket 接口时,如何正确工作在非阻塞模式下? 3. TOE 使能及使用注意事项 4. TOE 模式下使用 socket 接口时的注意事项 1. 为什么UDP接收或发送会丢包? 用户态应用程序在接收 UDP 数据时࿰…...
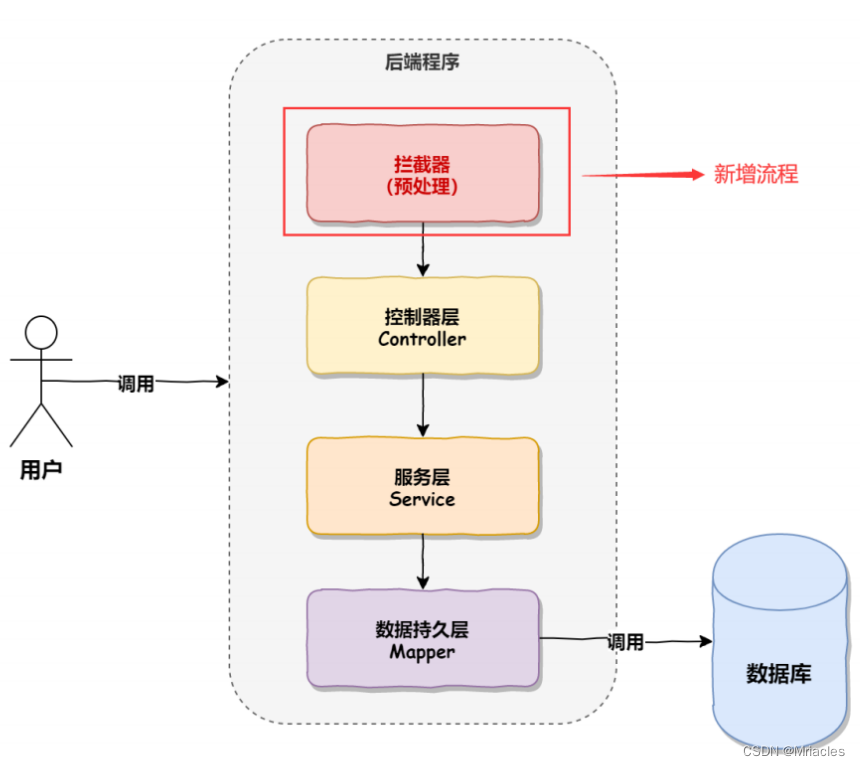
spring拦截器 与统一格式
目录 前言模拟拦截器拦截器的实现原理什么是动态代理? 什么是静态代理静态代理与动态代理的区别两种常用的动态代理方式基于接口的动态代理基于类的动态代理 JDK Proxy 与 CGlib的区别 其他 统⼀访问前缀添加统⼀异常处理统⼀数据返回格式 前言 之前博客讲述了 , 关于SpringA…...
leetcode 122. 买卖股票的最佳时机 II
2023.7.29 把整体利润拆分成每天的利润,将股票值想象成一个折线图,将所有上升的值相加即可。 代码: class Solution { public:int maxProfit(vector<int>& prices) {int ans 0;for(int i1; i<prices.size(); i){if(prices[i]-…...

代理模式:控制访问的设计模式
代理模式:控制访问的设计模式 什么是代理模式? 代理模式是一种常见的设计模式,它允许通过代理对象来控制对真实对象的访问。代理模式的主要目的是在不改变原始对象的情况下,提供额外的功能或控制访问。 为什么要使用代理模式&a…...

2020/7/30
Educational Codeforces Round 143 (Rated for Div. 2)\C_Tea_Tasting.cpp //题意:有n种茶,n个人,第i种茶有 a[i]的量,第i个人一次能喝 b[i], 第i个人从第i种茶开始往前喝,求每个人最多能喝多少茶。 //思路ÿ…...
图形编辑器开发:是否要像 Figma 一样上 wasm
大家好,我是前端西瓜哥。 wasm 拿来做 Web 端的图形编辑器貌似是不错的选择。 因为图形处理会有相当多无法利用到 WebGL GPU 加速的 CPU 密集的计算。比如对一条复杂贝塞尔曲线进行三角化,对多个图形进行复杂图形的布尔运算。 图形编辑器性能天花板 F…...

Linux学成之路(基础篇0(二十三)MySQL服务(主从MySQL服务和读写分离——补充)
目录 一、MySQL Replication概述 优点 异步复制(Asynchronous repication) 全同步复制(Fully synchronous replication) 半同步复制(Semisynchronous replication) 三、MySQL支持的复制 四、部署主从…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...