【0基础学爬虫】爬虫基础之爬虫的基本介绍

大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为爬虫的基本介绍。
一、爬虫概述
爬虫又称网络蜘蛛、网络机器人,网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:
- 通用网络爬虫(Scalable Web Crawler):抓取互联网上所有数据,爬取对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据,是捜索引擎抓取系统(Baidu、Google、Yahoo 等)的重要组成部分。
- 聚焦网络爬虫(Focused Crawler):抓取互联网上特定数据,按照预先定义好的主题有选择地进行网页爬取的一种爬虫,将爬取的目标网页定位在与主题相关的页面中,选择性地爬取特定领域信息。
- 增量式网络爬虫(Incremental Web Crawler):抓取互联网上刚更新的数据,采取增量式更新和只爬取新产生的或者已经发生变化网页,它能够在一定程度上保证所爬取的页面是尽可能新的页面,减少时间和空间上的耗费。
- 深层网络爬虫(Deep Web Crawler):表层网页(Surface Web)是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面;深层网页(Deep Web)是指不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。在互联网中,深层页面的数量往往比表层页面的数量要多很多。
爬虫程序能模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频、音频) 等爬取到本地,进而提取自己需要的数据,并存放起来使用,每一个程序都有自己的规则,网络爬虫也不例外,它会根据人们施加的规则去采集信息,这些规则为网络爬虫算法,根据使用者的目的,爬虫可以实现不同的功能,但所有爬虫的本质,都是方便人们在海量的互联网信息中找到并下载到自己要的那一类,提升信息获取效率。
爬虫采集的都是正常用户能浏览到的内容,而非所谓的 ”入侵服务器“,常说高水准者可 ”所见即所得“,意为只要是能看的内容就能爬取到,希望各位都能达到这个程度~
二、爬虫的用途
现如今大数据时代已经到来,网络爬虫技术成为这个时代不可或缺的一部分,企业需要数据来分析用户行为、自己产品的不足之处以及竞争对手的信息等,而这一切的首要条件就是数据的采集。网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数据,谁就拥有了决策的主动权。
网络爬虫目前主要的应用领域如:搜索引擎、数据采集、数据分析、信息聚合、竞品监控、认知智能、舆情分析等等,爬虫业务相关的公司数不胜数,如百度、谷歌、天眼查、企查查、新榜、飞瓜等等,在大数据时代,爬虫的应用范围广、需求大,简单举几个贴近生活的例子:
求职需求:获取各个城市的招聘信息及薪资标准,方便筛选出适合自己的;
租房需求:获取各个城市的租房信息,以便挑选出心仪的房源;
美食需求:获取各个地方的好评美食,让吃货不迷路;
购物需求:获取各个商家同一个商品的价格及折扣信息,让购物更实惠;
购车需求:获取心仪车辆近年的价格波动,以及不同渠道各车型的价格,助力挑选爱车。
三、URI 及 URL 的含义
URI(Uniform Resource Identifier),即统一资源标志符,URI(Uniform Resource Location),即统一资源定位符,例如 https://www.kuaidaili.com/ ,既是一个 URI,也是一个 URL,URL 是 URI 的子集,对于一般的网页链接,习惯称为 URL,一个 URL 的基本组成格式如下:
scheme://[username:password@]host[:port][/path][;parameters][?query][#fragment]各部分含义如下:
scheme:获取资源使用的协议,例如 http、https、ftp 等,没有默认值,scheme 也被称为 protocol;
username:password:用户名与密码,某些情况下 URL 需要提供用户名和密码才能访问,这是个特殊的存在,一般访问 ftp 时会用到,显式的表明了访问资源的用户名与密码,但是可以不写,不写的话可能会让输入用户名密码;
host:主机地址,可以是域名或 IP 地址,例如 www.kuaidaili.com、112.66.251.209;
port:端口,服务器设定的服务端口,http 协议的默认端口为 80,https 协议的默认端口为 443,例如 https://www.kuaidaili.com/ 相当于 https://www.kuaidaili.com:443;
path:路径,指的是网络资源在服务器中的指定地址,通过 host:port 我们能找到主机,但是主机上文件很多,通过 path 则可以定位具体文件。例如 https://www.baidu.com/file/index.html,path 为 /file/index.html,表示我们访问 /file/index.html 这个文件;
parameters:参数,用来指定访问某个资源时的附加信息,主要作用就是像服务器提供额外的参数,用来表示本次请求的一些特性,例如 https://www.kuaidaili.com/dps;kspider,kspider 即参数,现在用的很少,大多数将 query 部分作为参数;
query:查询,由于查询某类资源,若多个查询,则用 & 隔开,通过 GET 方式请求的参数,例如:https://www.kuaidaili.com/dps/?username=kspider&type=spider,query 部分为 username=kspider&type=spider,指定了 username 为 kspider,type 为 spider;
fragment:片段,对资源描述的部分补充,用来标识次级资源,例如 https://www.kuaidaili.com/dps#kspider,kspider 即为 fragment 的值:
应用:单页面路由、HTML 锚点;
#有别于?,?后面的查询字符串会被网络请求带上服务器,而 fragment 不会被发送的服务器;fragment 的改变不会触发浏览器刷新页面,但是会生成浏览历史;
fragment 会被浏览器根据文件媒体类型(MIME type)进行对应的处理;
默认情况下 Google 的搜索引擎会忽略
#及其后面的字符串,如果想被浏览引擎读取,需要在#后紧跟一个!,Google 会自动将其后面的内容转成查询字符串_escaped_fragment_的值,如 https://www.kuaidaili.com/dps#!kspider,转换后为 https://www.kuaidaili.com/dps?_escaped_fragment_=kspider。
由于爬虫的目标是获取资源,而资源都存储在某个主机上,所以爬虫爬取数据时必须要有一个目标的 URL 才可以获取数据,因此,URL 是爬虫获取数据的基本依据,准确理解 URL 的含义对爬虫学习有很大帮助。
四、爬虫的基本流程
- 发起请求:通过 URL 向服务器发起 Request 请求(同打开浏览器,输入网址浏览网页),请求可以包含额外的 headers、cookies、proxies、data 等信息,Python 提供了许多库,帮助我们实现这个流程,完成 HTTP 请求操作,如 urllib、requests 等;
- 获取响应内容:如果服务器正常响应,会接收到 Response,Response 即为我们所请求的网页内容,包含 HTML(网页源代码),JSON 数据或者二进制的数据(视频、音频、图片)等;
- 解析内容:接收到响应内容后,需要对其进行解析,提取数据内容,如果是 HTML(网页源代码),则可以使用网页解析器进行解析,如正则表达式(re)、Beautiful Soup、pyquery、lxml 等;如果是 JSON 数据,则可以转换成 JSON 对象进行解析;如果是二进制的数据,则可以保存到文件进行进一步处理;
- 保存数据:可以保存到本地文件(txt、json、csv 等),或者保存到数据库(MySQL,Redis,MongoDB 等),也可以保存至远程服务器,如借助 SFTP 进行操作等。
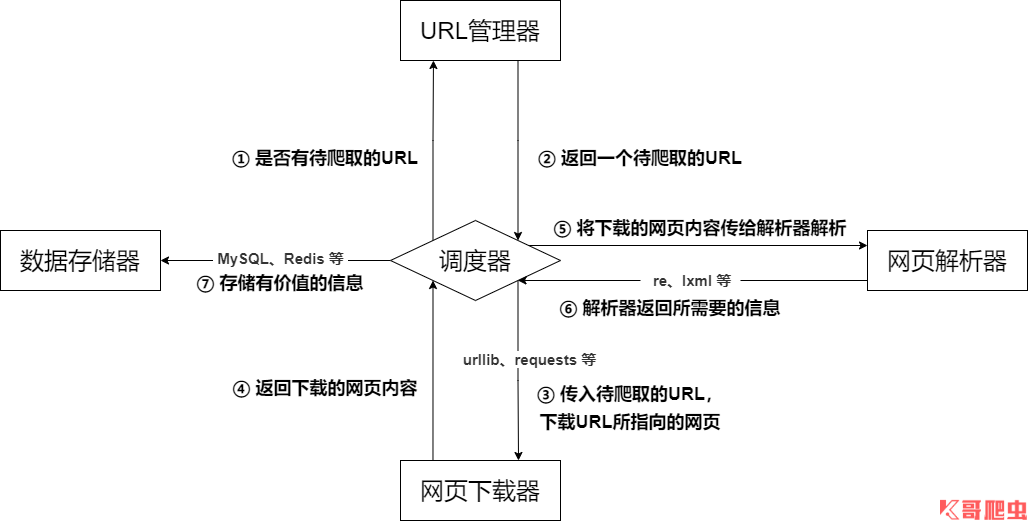
五、爬虫的基本架构
爬虫的基本架构主要由五个部分组成,分别是爬虫调度器、URL 管理器、网页下载器、网页解析器、信息采集器:
- 爬虫调度器:相当于一台电脑的 CPU,主要负责调度 URL 管理器、下载器、解析器之间的协调工作,用于各个模块之间的通信,可以理解为爬虫的入口与核心,爬虫的执行策略在此模块进行定义;
- URL 管理器:包括待爬取的 URL 地址和已爬取的 URL 地址,防止重复抓取 URL 和循环抓取 URL,实现 URL 管理器主要用三种方式,通过内存、数据库、缓存数据库来实现;
- 网页下载器:负责通过 URL 将网页进行下载,主要是进行相应的伪装处理模拟浏览器访问、下载网页,常用库为 urllib、requests 等;
- 网页解析器:负责对网页信息进行解析,可以按照要求提取出有用的信息,也可以根据 DOM 树的解析方式来解析。如正则表达式(re)、Beautiful Soup、pyquery、lxml 等,根据实际情况灵活使用;
- 数据存储器:负责将解析后的信息进行存储、显示等数据处理。
六、robots 协议
robots 协议也称爬虫协议、爬虫规则等,是指网站可建立一个 robots.txt 文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取 robots.txt 文件来识别这个页面是否允许被抓取。但是,这个robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视 robots.txt 文件去抓取网页的快照。 如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的 robots.txt,或者使用 robots 元数据(Metadata,又称元数据)。
robots 协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私,俗称 “君子协议”。
robots.txt 文件内容含义:
- User-agent:, 这里的 * 代表的所有的搜索引擎种类, 是一个通配符
- Disallow: /admin/, 这里定义是禁止爬取 admin 目录下面的目录
- Disallow: /require/, 这里定义是禁止爬取 require 目录下面的目录
- Disallow:/ABC/, 这里定义是禁止爬取 ABC 目录下面的目录
- Disallow:
/cgi-bin/*.htm, 禁止访问 /cgi-bin/ 目录下的所有以 ".htm" 为后缀的 URL(包含子目录) - Disallow:
/*?*, 禁止访问网站中所有包含问号 (?) 的网址 - Disallow:/.jpg$, 禁止抓取网页所有的 .jpg 格式的图片
- Disallow:/ab/adc.html, 禁止爬取 ab 文件夹下面的 adc.html 文件
- Allow:/cgi-bin/, 这里定义是允许爬取 cgi-bin 目录下面的目录
- Allow:/tmp, 这里定义是允许爬取 tmp 的整个目录
- Allow: .htm$, 仅允许访问以 ".htm" 为后缀的 URL
- Allow: .gif$, 允许抓取网页和 gif 格式图片
- Sitemap:网站地图, 告诉爬虫这个页面是网站地图
查看网站 robots 协议,网站 url 加上后缀 robotst.txt 即可,以快代理为例:
https://www.kuaidaili.com/
- 禁止所有搜索引擎访问网站的任何部分
- 禁止爬取 /doc/using/ 目录下面的目录
- 禁止爬取 /doc/dev 目录下面所有以 sdk 开头的目录及文件
七、爬虫与法律
近年来,与网络爬虫相关的法律案件和新闻报道层出不穷,推荐观看:K哥爬虫普法专栏,不论是不是爬虫行业的可能都听说过一句 “爬虫学的好,牢饭吃到饱”,甚至不少人觉得爬虫本身就是有问题的,处于灰色地带,抗拒以致不敢学爬虫,但实际并不是这样,爬虫作为一种计算机技术,其技术本身是具有中立性的,法律也并没禁止爬虫技术,当今互联网很多技术是依赖于爬虫技术而发展的,公开数据、不做商业目的、不涉及个人隐私、不要把对方服务器爬崩、不碰黑产及黄赌毒就不会违法,技术无罪,有罪的是人,切记不要触碰法律的红线!

相关文章:
【0基础学爬虫】爬虫基础之爬虫的基本介绍
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学…...
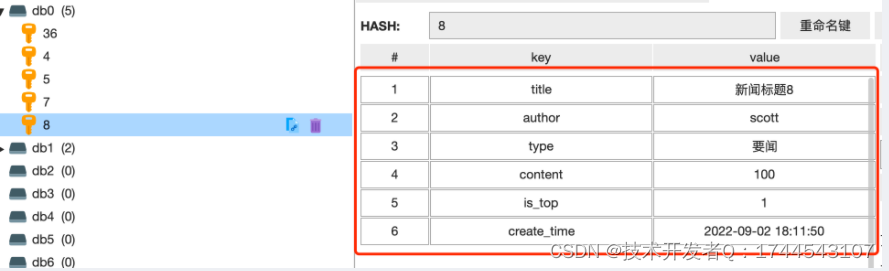
Python 数据库开发实战 - Python与Redis交互篇- 综合案例 - 新闻管理系统 - 缓存新闻数据至redis
接下来这个章节将继续来完成 《新闻管理系统》 这个项目,上一章节我们完成了 “发表新闻” 这个功能,在发表新闻后,什么时候才会缓存该条新闻记录呢?并不是说在发表新闻成功之后就立刻被缓存,而是该新闻被管理员审批通…...
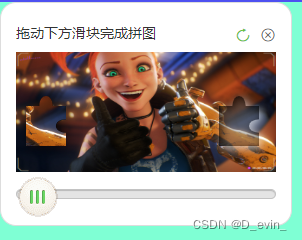
Vue拼图验证
vue-puzzle-verification 封装的一个用于登录验证的拼图的vue组件,使用了canvas画图和拖拽的一些技巧。支持大小、形状、图片、偏差、范围的自定义。 一、安装使用 npm install vue-puzzle-verification 二、main.js里引入 import PuzzleVerification from vue…...
这个神器,让 Python 爬虫如此简单
相信大家应该都写过爬虫,简单的爬虫只需要使用 requests 即可。遇到复杂的爬虫,就需要在程序里面加上请求头和参数信息。类似这种: 我们一般的步骤是,先到浏览器的网络请求中找到我们需要的请求,然后将请求头和参数信…...

网络舆情公关必须把握的四项基本原则
在这个网络媒体占主导的时代,舆情公关进入了网络自媒体时代,有时候可能企业认为是小事儿,也可能在网上掀起轩然大波,所以网络舆情优化成为营销推广工作中重要一环。网络舆情优化的目标是让网络舆论对企业经营发展有利的方向发展&a…...
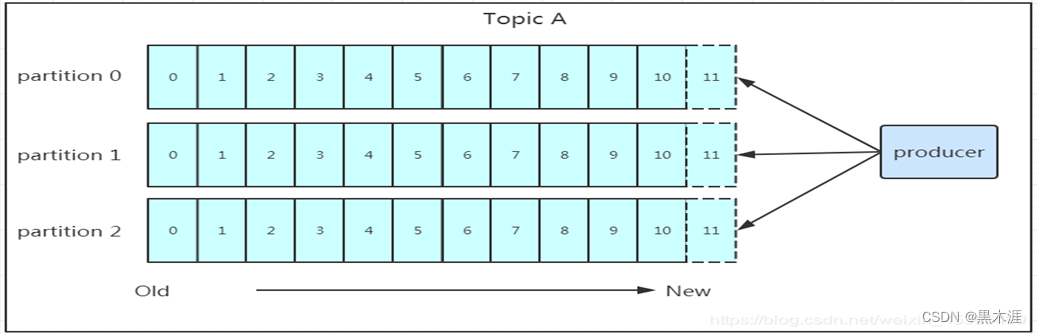
Kafka技术认知
文章目录概念理解名词解释基本架构工作流程Kafka的特性概念理解 Kafka是分布式的基于发布-订阅消息队列。是一个分布式、支持分区的、多副本的,基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景…...
2022年新一代kaldi团队技术输出盘点
目录 1. 技术创新 1.1 Pruned RNN-T loss 1.2 RNN-T 的快速 GPU 解码 1.3 多码本量化索引的知识蒸馏 1.4 RNN-T 和 CTC 的低延时训练 1.5 Zipformer 1.6 Small tricks 2. 模型部署 2.1 Sherpa 2.1 Sherpa-ncnn 3. 更多的 recipe 和模型 参考资料 1. 技术创新 1.1 …...

数据结构复习(三)顺序表oj
目录 27. 移除元素 26. 删除有序数组中的重复项 88. 合并两个有序数组 27. 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外…...

2023.2.10每日一题
每日一题题目描述解题核心解法一:模拟题目描述 题目链接:2553. 分割数组中数字的数位 给你一个正整数数组nums,请你返回一个数组answer,你需要将nums中每个整数进行数位分割后,按照nums中出现的相同顺序放入答案数组…...

Homekit智能家居DIY一智能吸顶灯
买灯要看什么因素 好灯具的灯光可以说是家居的“魔术师”,除了实用的照明功能外,对细节的把控也非常到位。那么该如何选到一款各方面合适的灯呢? 照度 可以简单理解为清晰度,复杂点套公式来说照度光通量(亮度&#x…...
关于 OAuth 你又了解哪些?
作者罗锦华,API7.ai 技术专家/技术工程师,开源项目 pgcat,lua-resty-ffi,lua-resty-inspect 的作者。 OAuth 的背景 OAuth,O 是 Open,Auth 是授权,也就是开放授权的意思。OAuth 始于 2006 年&a…...

18. 构造函数和析构函数,构造函数的分类和调用
构造函数和析构函数 构造函数 //没有返回值 不用写void//函数名 与 类名相同//可以有参数 ,可以发生重载//构造函数 由编译器自动调用一次 无须手动调用析构函数 //没有返回值 不用写void函数名 与类名相同 函数名前 加 ~不可以有参数 ,不可以发生重载析构函数 也是由编译器自…...
)
JavaScript设计模式es6(23种)
设计模式简介设计模式代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。设计模式是一套被反复使用的…...

设计「业务」与「技术」方案
三天研发,两天设计; 01【优先做设计方案】 职场中的那些魔幻操作,研发最烦的是哪个? 作为一个数年且资深的互联网普通开发,可以来说明一下为什么是:缺乏设计; 面对业务需求的时候,…...

C/C++:预处理(下)
目录 一.回顾程序的编译链接过程 二. 预处理之预定义#define 1.#define定义的标识符 2.#define定义的宏 3.带副作用的表达式作为宏实参 4.两个经典的宏 5.#define使用的一些注意事项小结 6.宏与函数的比较 7.#undef 附:关于#define的三个冷知识 三. 条件…...
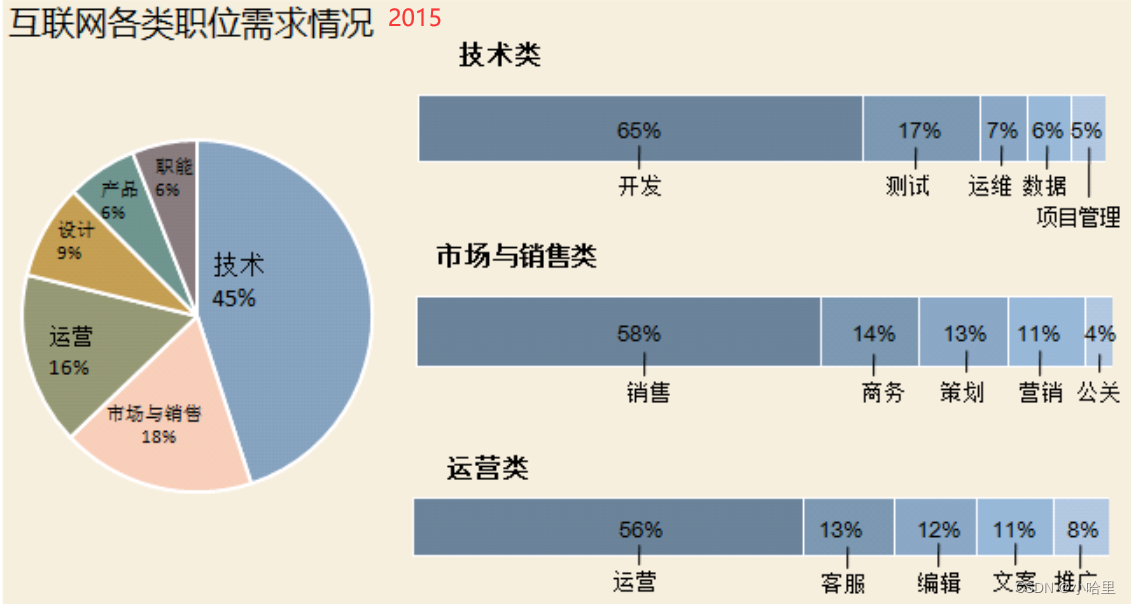
2023互联网相关岗位转行与就业选择的简单分析
文章目录1、城市2、岗位1、城市 能找得到工作的城市,可能主要也就这些base了 2、岗位 主要技术岗位 Python 侧重人工智能,人工智能门槛高大家心知肚明。如果学python 不走人工智能,只走单纯的后端开发,不管从薪资还是岗位数量…...
LeetCode·每日一题·1223.掷骰子模拟·记忆化搜索
作者:小迅链接:https://leetcode.cn/problems/dice-roll-simulation/solutions/2103471/ji-yi-hua-sou-suo-zhu-shi-chao-ji-xiang-xlfcs/来源:力扣(LeetCode)著作权归作者所有。商业转载请联系作者获得授权࿰…...

【GPLT 二阶题目集】L2-043 龙龙送外卖
参考地址:AcWing 4474. 龙龙送外卖(杂题选讲) 作者:yxc 感谢y总! 龙龙是“饱了呀”外卖软件的注册骑手,负责送帕特小区的外卖。帕特小区的构造非常特别,都是双向道路且没有构成环 —— 你可以…...
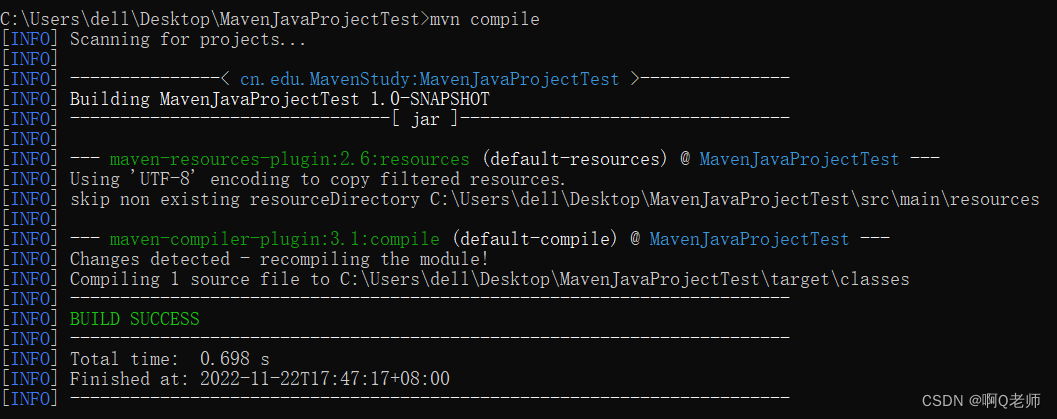
Maven:基础知识
Maven概念图生命周期目录工程创建测试常用命令COMPILATION ERROR : 不再支持目标选项 5。请使用 7 或更高版本。问题解决pom.xml文件properties配置示例scope配置详解概念图 依赖管理构建项目Maven 的底层核心实现项目的构建和管理必须通过插件完成,但插件本身并不包…...
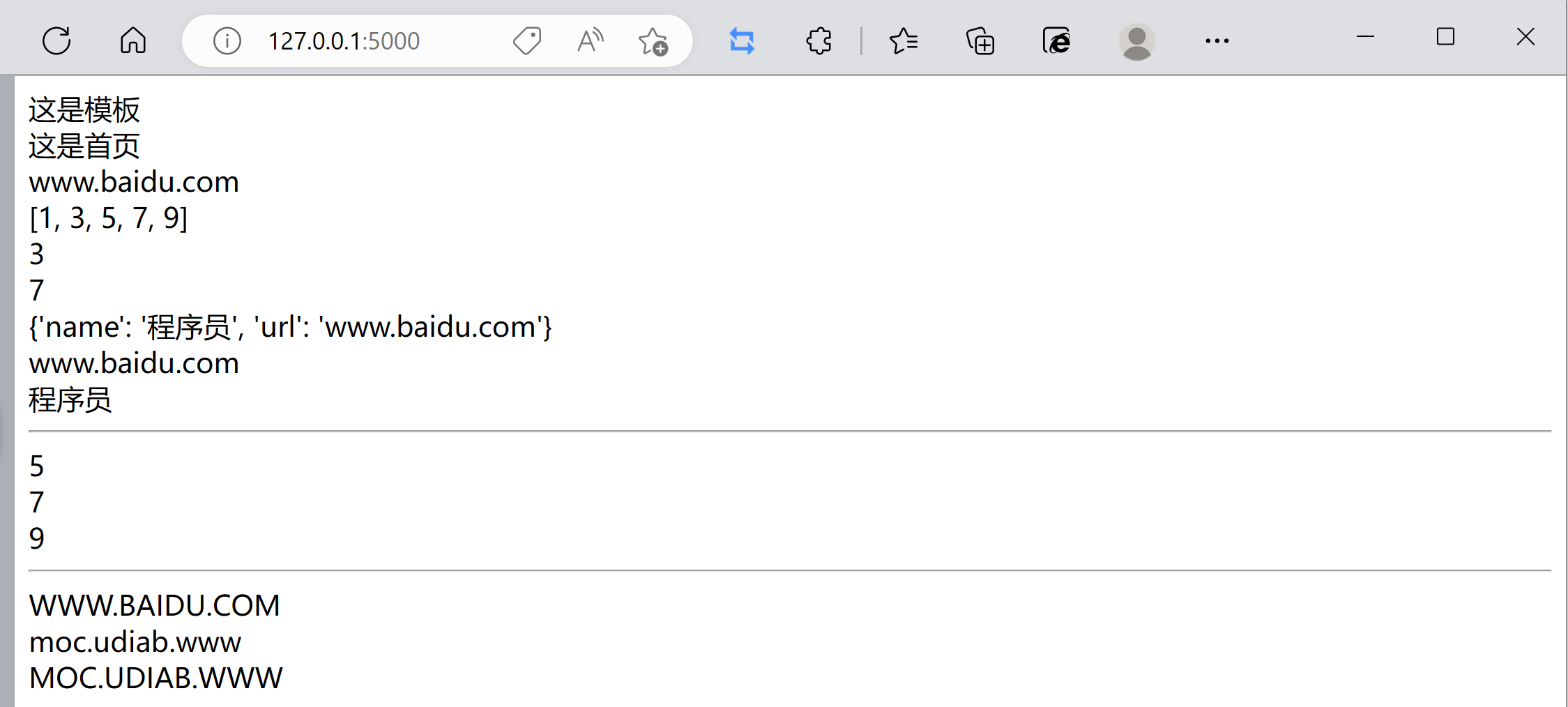
Web 框架 Flask 快速入门(一)flask基础与模板
前言 课程地址:Python Web 框架 Flask 快速入门 文章目录前言🌴 Flask基础和模板🌷 一个简单的flask程序🌼 模板的使用🌴 Flask基础和模板 1、web框架的作用 避免重复造轮子,app程序不必关心于服务器的沟…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...