机器学习深度学习——文本预处理
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——序列模型(NLP启动!)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
里面的算法写起来也不难,但是对于算法小白来说还是要点时间,不过花点时间也能搞明白。
文本预处理
- 步骤
- 读取数据集
- 词元化
- 词表
- 整合所有功能
- 小结
步骤
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列,我们将进行解析文本的预处理操作,步骤包括:
1、将文本作为字符串加载到内存中。
2、将字符串拆分为词元(如单词和字符)。
3、建立一个词表,将拆分的词元映射到数字索引。
4、将文本转换为数字索引序列,方便模型操作。
import collections
import re
from d2l import torch as d2l
读取数据集
我们从《时光机器》这篇外国书中加载文本,只有几万多的单词。
下面的函数将数据集读取到由多条文本行组成的列表中,其中每条文本行都是一个字符串。(这边省略了标点符号和字母大写)
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')
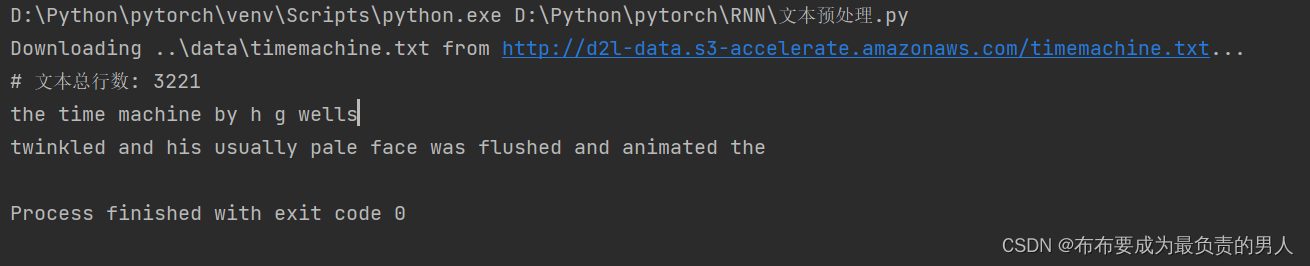
def read_time_machine(): #@save"""将时间机器的数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])运行结果:
词元化
下面的tokenize函数将文本行列表(lines)作为输入。每个文本序列又被拆分成一个词元列表,词元(token)是文本的基本单位(可以分解为单词或字符)。
最后返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
def tokenize(lines, token='word'): #@save"""将文本拆分为单词词元或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)tokens = tokenize(lines)
for i in range(11):print(tokens[i])
运行结果:
[‘the’, ‘time’, ‘machine’, ‘by’, ‘h’, ‘g’, ‘wells’]
[]
[]
[]
[]
[‘i’]
[]
[]
[‘the’, ‘time’, ‘traveller’, ‘for’, ‘so’, ‘it’, ‘will’, ‘be’, ‘convenient’, ‘to’, ‘speak’, ‘of’, ‘him’]
[‘was’, ‘expounding’, ‘a’, ‘recondite’, ‘matter’, ‘to’, ‘us’, ‘his’, ‘grey’, ‘eyes’, ‘shone’, ‘and’]
[‘twinkled’, ‘and’, ‘his’, ‘usually’, ‘pale’, ‘face’, ‘was’, ‘flushed’, ‘and’, ‘animated’, ‘the’]
词表
模型更喜欢使用的输入不是字符串而是数字,因此我们构造一个字典就好了,这个字典就叫词表。
步骤如下:
1、将训练集中的文档合并在一起,对它们的唯一词元进行统计,得到的统计结果称为语料(corpus)
2、根据每个唯一词元的出现频率,为其分配数字索引(很少出现的词元可以被移除来降低复杂度)
3、不存在或者已删除的词元将映射到特定的位置词元
< u n k > <unk> <unk>
4、我们就可以增加一个列表来保存那些被保留的词元,如:
< p a d > :填充词元 < b o s > :序列开始词元 < e o s > :序列结束词元 <pad>:填充词元\\ <bos>:序列开始词元\\ <eos>:序列结束词元 <pad>:填充词元<bos>:序列开始词元<eos>:序列结束词元
具体代码如下:
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# 按出现频率排序counter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # 未知词元的索引为0return 0@propertydef token_freqs(self):return self._token_freqsdef count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line] # 提取每一行的每个词元,其实也就是一个双层循环# 返回一个可以用来计数的APIreturn collections.Counter(tokens)
我们首先使用数据集作为语料库来构建词表,然后打印一下前几个高频词元以及他们的索引:
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])
输出结果:

现在,我们可以将每一条文本行转换成一个数字索引列表:
for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab.__getitem__(tokens[i]))
结果如下:
文本: [‘the’, ‘time’, ‘machine’, ‘by’, ‘h’, ‘g’, ‘wells’]
索引: [1, 19, 50, 40, 2183, 2184, 400]
文本: [‘twinkled’, ‘and’, ‘his’, ‘usually’, ‘pale’, ‘face’, ‘was’, ‘flushed’, ‘and’, ‘animated’, ‘the’]
索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
整合所有功能
在使用上述函数时,我们将所有功能打包到load_corpus_time_machine函数中,该函数返回corpus词元索引列表和vocab词表,我们在这边做出改变:
1、为了简化以后的村联,这里使用字符来实现词元化
2、数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
from d2l import torch as d2ldef load_corpus_time_machine(max_tokens=-1): #@save"""返回《时光机器》数据集的词元索引列表和词表"""lines = d2l.read_time_machine()tokens = d2l.tokenize(lines, 'char')vocab = d2l.Vocab(tokens)# 数据集中的每个文本行不一定是一个句子或一个段落# 所以将所有文本行展平到一个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocabcorpus, vocab = load_corpus_time_machine()
print(len(corpus), len(vocab))运行结果:
170580 28
小结
1、文本是序列数据的一种最常见形式之一。
2、为了对文本进行预处理,我们通常将文本拆分为词元,构建词表将词元字符串映射为数字索引,并将文本数据转换为词元索引以供模型操作。
相关文章:
机器学习深度学习——文本预处理
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——序列模型(NLP启动!) 📚订阅专栏:机器学习&am…...

Qt实现可伸缩的侧边工具栏(鼠标悬浮控制伸缩栏)
Qt实现可伸缩的侧边工具栏 一直在网上找,发现大多的实现方案都是用一个按钮,按下控制侧边栏的伸缩,但是我想要实现鼠标悬浮在侧边栏的时候就伸出,移开就收缩的功能,也没找到好的参考,所以决定自己实现一个…...

【Spring Boot】拦截器与统一功能处理
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: JavaEE进阶 上一篇文章我们讲解了Spring AOP是一个基于面向切面编程的框架,用于将某方面具体问题集中处理,通过代理对象来进行传递,但使用原生Spring AOP实现统一的…...

RabbitMQ的6种工作模式
RabbitMQ的6种工作模式 官方文档: http://www.rabbitmq.com/ https://www.rabbitmq.com/getstarted.html RabbitMQ 常见的 6 种工作模式: 1、simple简单模式 1)、消息产生后将消息放入队列。 2)、消息的消费者监听消息队列,如果队列中…...

MFC第二十六天 CRgn类简介与开发、封装CMemoryDC类并应用开发
文章目录 CRgn类简介与开发CRgn类简介CRgn类区域管理开发CRgn类区域管理与不规则形状的选取 封装CMemoryDC类并应用开发CMemoryDC.h封装CMemoryDC开发游戏透明动画CFlashDlg.hCFlashDlg.cpp 封装CMemoryDC开发游戏动画 附录四大窗口CDC派生类 CRgn类简介与开发 CRgn类简介 CR…...
解决VScode远程服务器时opencv和matplotlib无法直接显示图像的问题
解决VScode远程服务器时opencv和matplotlib无法直接显示图像的问题 1、本方案默认本地已经安装了VScode与MobaXterm2、在服务器端3、在本地端安装MobaXterm4、测试5、opencv显示测试(测试过程中需保持MobaXterm开启的状态)6、 matplotlib显示测试&#x…...

支付模块功能实现(小兔鲜儿)【Vue3】
支付 渲染基础数据 支付页有俩个关键数据,一个是要支付的钱数,一个是倒计时数据(超时不支付商品释放) 准备接口 import request from /utils/httpexport const getOrderAPI (id) > {return request({url: /member/order/$…...

php meilisearch demo
# 创建一个meilisearch 使用完自动销毁 docker run -itd --rm -p 7700:7700 getmeili/meilisearch:v1.3docker-compose 参数 version: "3" networks:flyserver:driver: bridge services:search:image: getmeili/meilisearch:v1.3restart: alwaysenvironment:- MEILI…...

芒格之道——查理·芒格股东会讲话1987-2022
你越是认真生活,你的生活就会越美好! 这里将读书过程划线的内容摘抄在这里,方便自己回顾。 书分为两部分,我先读了后半部分,而且是从后往前读,到了前半部分,我是从前往后读。书还挺贵ÿ…...

如何运营手游联运平台游戏?
运营手游联运平台游戏需要综合考虑多个方面,包括游戏选择、合作伙伴、市场推广、用户运营等。以下是运营手游联运平台游戏的一些建议: 游戏选择:选择优质的手游,确保游戏的品质和内容能够吸引玩家,满足市场需求。 合…...

vscode连接远程Linux服务器
文章目录 一、环境安装1.1 下载vscode1.2 下载vscode-sever 二、ssh链接2.1 安装Remote-SSH2.2 设置vscode ssh2.3 设置免密登录2.3.1 本地生成公私钥2.3.2 服务器端添加公钥 三、安装插件3.1 vscode安装插件3.1.1 在线安装插件3.1.2.1 下载插件3.1.2.2 安装插件 3.2 vscode-se…...

numpy 转换成 cupy 利用GPU执行 错误
ModuleNotFoundError: No module named cupy._core. routines_sorting 提示缺少包 使用 pyinstaller -D views.py --nocons 可以正常打包出来 但是运行出现报错 说明这个打包工具 忽略了很多 隐式导入的包 解决方法很简单 hiddenimports [fastrlock, fastrlock.rlock, cu…...
)
力扣:55. 跳跃游戏(Python3)
题目: 给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标。 来源:力扣(LeetCode) 链接:力扣 示例…...
Unity 编辑器资源导入处理函数 OnPreprocessAudio :深入解析与实用案例
Unity 编辑器资源导入处理函数 OnPreprocessAudio 用法 点击封面跳转下载页面 简介 在 Unity 中,资源导入是一个非常重要的环节,它决定了资源在项目中的使用方式和效果。Unity 提供了一系列的资源导入处理函数,其中之一就是 OnPreprocessAud…...
mongodb-win32-x86_64-2008plus-3.4.24-signed.msi
Microsoft Windows [版本 6.1.7601] 版权所有 (c) 2009 Microsoft Corporation。保留所有权利。C:\Users\Administrator>cd C:\MongoDB\Server\3.4\binC:\MongoDB\Server\3.4\bin>C:\MongoDB\Server\3.4\bin>mongod --help Options:General options:-h [ --help ] …...

java的反射
在java语言中,反射机制是指对于处在运行状态的类,都能够获取到这个类的所有属性和方法。对于任意一个对象,都能够调用它的任意一个方法以及访问它的属性;这种通过动态获取类或对象的属性以及方法从而完成调用功能被称为java语言的…...

MySQL — InnoDB 锁
文章目录 锁共享锁和排他锁意向锁记录锁间隙锁临键锁插入意向锁自增锁 锁 加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务…...
首批获得金融级行业云平台认证,天翼云深耕行业云
云计算下半场看什么? 无疑是金融、政务、制造等传统政企用户的上云与用云。随着数字经济发展和产业数字化的提速,上云已是政企用户推动其数字化转型不断深入的重要抓手,成为不可阻挡的趋势。 与互联网用户相比,政企用户上云极为…...

浅谈Python解释器的组成
Python解释器是一个复杂的软件,它可以解释和执行Python代码。以下是Python解释器的主要组成部分: 源代码词法分析器(Lexical Analyzer): 这部分的任务是将输入的Python源代码分解成称为"tokens"的基础元素。例如&#x…...
服务限流治理
一、基础概念 1.什么是服务限流? 限流在日常生活中也很常见,比如节假日你去一个旅游景点,为了不把景点撑爆,管理部门通常会在外面设置拦截,限制景点的进入人数(等有人出来之后,再放新的人进去…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...