pytorch零基础实现语义分割项目(二)——标签转换与数据加载
数据转换与加载
- 项目列表
- 前言
- 标签转换
- RGB标签到类别标签映射
- RGB标签转换成类别标签数据
- 数据加载
- 随机裁剪
- 数据加载
项目列表
语义分割项目(一)——数据概况及预处理
语义分割项目(二)——标签转换与数据加载
语义分割项目(三)——语义分割模型(U-net和deeplavb3+)
前言
在前面的文章中我们介绍了数据集的概况以及预处理,在训练之前除了数据预处理之外我们还需要对于标签进行处理,因为标签是以RGB格式存放的,我们需要把他们变换成常见的类别标签,并且因为语义分割问题是针对像素的分类,在数据量较大的情况下容易内存溢出(OOM),所以我们往往需要重写数据加载类针对大量数据进行加载。
标签转换
RGB标签到类别标签映射
我们知道RGB图像的数据点有三个通道,每个通道取值范围为0−2550-2550−255
即(0−255,0−255,0−255)(0-255, 0-255, 0-255)(0−255,0−255,0−255),那么我们可以考虑这样一个思路,我们设置一个长度为2553255^32553的向量,这样就可以容纳所有像素的取值范围。在之前的文章中我们定义了VOC_COLORMAP和VOC_CLASSES,对应着像素形式的类别和文字形式的类别
VOC_COLORMAP = [[226, 169, 41], [132, 41, 246], [110, 193, 228], [60, 16, 152], [254, 221, 58], [155, 155, 155]]
VOC_CLASSES = ['Water', 'Land (unpaved area)', 'Road', 'Building', 'Vegetation', 'Unlabeled']
那么我们构造一个voc_colormap2label函数,通过enumerate遍历VOC_COLORMAP获取索引与像素类别,并赋值colormap2label
def voc_colormap2label():colormap2label = torch.zeros(256 ** 3, dtype=torch.long)for i, colormap in enumerate(VOC_COLORMAP):colormap2label[(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = ireturn colormap2label
RGB标签转换成类别标签数据
通过上面的函数我们可以获得RGB标签到类别标签的映射关系,那么我们在构造一个函数,传入RGB标签数据colormap和RGB标签向类别标签的映射colormap2label,返回值是类别标签。
def voc_label_indices(colormap, colormap2label):colormap = colormap.permute(1, 2, 0).numpy().astype('int32')idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256 + colormap[:, :, 2])return colormap2label[idx]
数据加载
随机裁剪
由于输入图像的形状不能确定,并且有时图像太大会影响训练速度或者影响内存,所以我们需要对于图像和标签进行裁剪,我们调用torchvision.transforms.RandomCrop.get_params可以获取随机裁剪的区域(这一步的操作是为了使得数据和标签的区域匹配),然后我们使用torchvision.transforms.functional.crop可以进行数据和标签同步裁剪。
def voc_rand_crop(feature, label, height, width):rect = torchvision.transforms.RandomCrop.get_params(feature, (height, width))feature = torchvision.transforms.functional.crop(feature, *rect)label = torchvision.transforms.functional.crop(label, *rect)return feature, label
数据加载
我们简单介绍一下数据加载类SemanticDataset
| 函数名 | 用途 |
|---|---|
__init__ | 用于初始参数设置 |
normalize_image | 将图像设置成0-1范围内并进行normalize |
pad_params | 获取图像padding参数 |
pad_image | 根据pad参数padding图像 |
__getitem__ | 通过索引获取数据 |
__len__ | 获取数据长度 |
数据加载类的主要的思路是加载图像和标签,对于图像进行规范化(除以255以及normalize),如果图像过大进行裁剪,如果图像过小进行padding,对于标签我们调用之前的函数从RGB标签转换成类别标签
class SemanticDataset(torch.utils.data.Dataset):def __init__(self, is_train, crop_size, data_dir):self.transform = torchvision.transforms.Normalize(mean=[0.4813, 0.4844, 0.4919], std=[0.2467, 0.2478, 0.2542])self.crop_size = crop_sizeself.data_dir = data_dirself.is_train = is_trainself.colormap2label = voc_colormap2label()txt_fname = os.path.join(data_dir, 'train.txt' if self.is_train else 'test.txt')with open(txt_fname, 'r') as f:self.images = f.read().split()def normalize_image(self, img):return self.transform(img.float() / 255)def pad_params(self, crop_h, crop_w, img_h, img_w):hight = max(crop_h, img_h)width = max(crop_w, img_w)y_s = (hight - img_h) // 2x_s = (width - img_w) // 2return hight, width, y_s, x_sdef pad_image(self, hight, width, y_s, x_s, feature):zeros = torch.zeros((feature.shape[0], hight, width))zeros[:, y_s:y_s + feature.shape[1], x_s:x_s + feature.shape[2]] = featurereturn zerosdef __getitem__(self, idx):mode = torchvision.io.image.ImageReadMode.RGBfeature = torchvision.io.read_image(os.path.join(self.data_dir, 'images', '{:03d}.jpg'.format(int(self.images[idx]))))label = torchvision.io.read_image(os.path.join(self.data_dir, 'labels', '{:03d}.png'.format(int(self.images[idx]))), mode)c_h, c_w, f_h, f_w = self.crop_size[0], self.crop_size[1], feature.shape[1], feature.shape[2]if f_h < c_h or f_w < c_w:higth, width, y_s, x_s = self.pad_params(c_h, c_w, f_h, f_w)feature = self.pad_image(higth, width, y_s, x_s, feature)label = self.pad_image(higth, width, y_s, x_s, label)feature = self.normalize_image(feature) feature, label = voc_rand_crop(feature, label,*self.crop_size)label = voc_label_indices(label, self.colormap2label)return (feature, label)def __len__(self):return len(self.images)
使用torch.utils.data.DataLoader批量加载数据
def load_data_voc(batch_size, crop_size, data_dir = './dataset'):train_iter = torch.utils.data.DataLoader(SemanticDataset(True, crop_size, data_dir), batch_size, shuffle=True, drop_last=True)test_iter = torch.utils.data.DataLoader(SemanticDataset(False, crop_size, data_dir), batch_size, shuffle=False, drop_last=True)return train_iter, test_iter
相关文章:
——标签转换与数据加载)
pytorch零基础实现语义分割项目(二)——标签转换与数据加载
数据转换与加载项目列表前言标签转换RGB标签到类别标签映射RGB标签转换成类别标签数据数据加载随机裁剪数据加载项目列表 语义分割项目(一)——数据概况及预处理 语义分割项目(二)——标签转换与数据加载 语义分割项目&#x…...

python(8.5)--列表习题
目录 一、求输出结果题 二、计算列表元素个数 三、查找是否存在某元素 四、删除某元素 五、如何在列表中插入元素 六、如何从列表中删除重复的元素 七、 如何将列表中的元素按照从小到大的顺序排序 八、从列表中删除重复的元素 九、大到小的顺序排序 一、求输出结…...
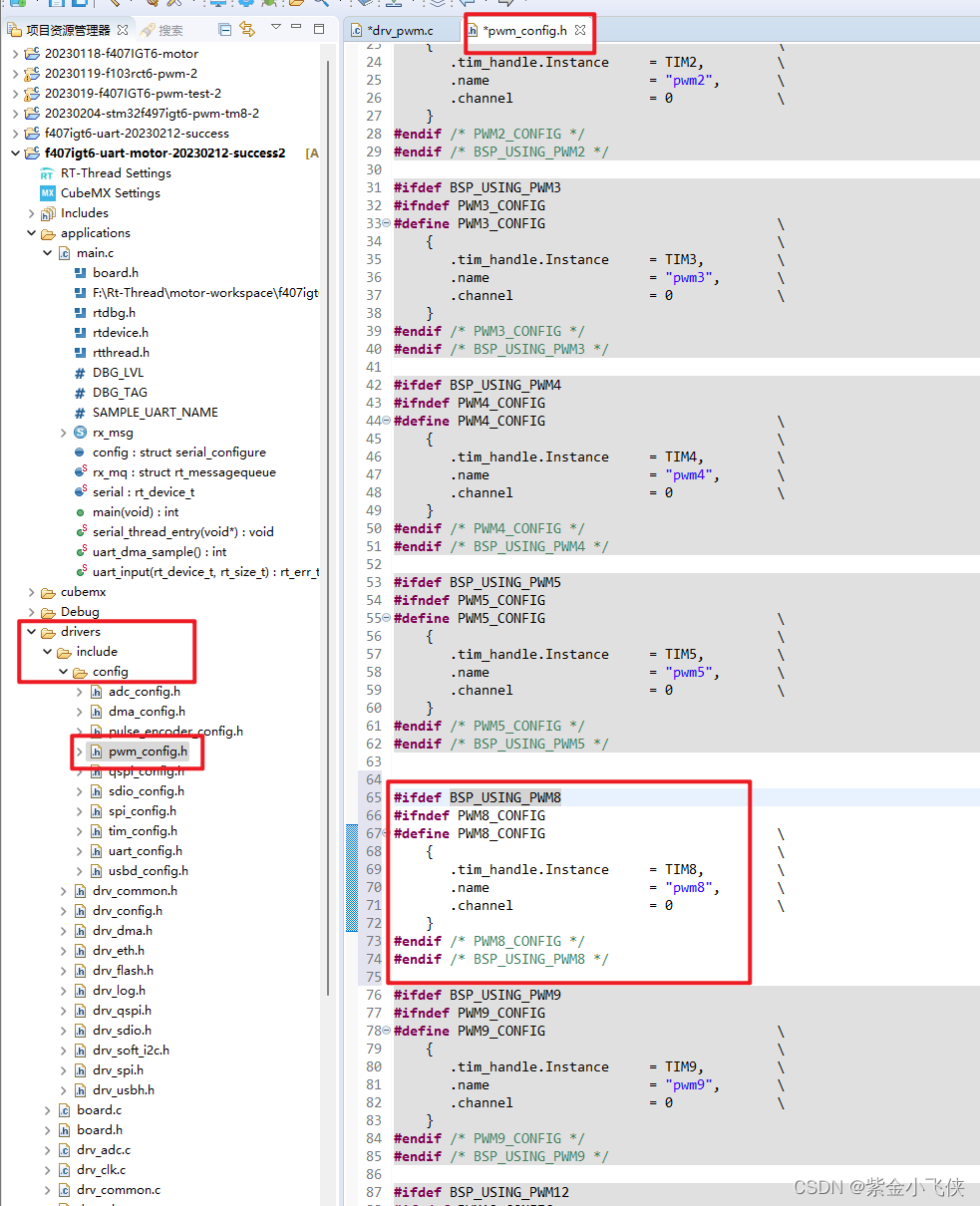
rt-thread pwm 多通道
一通道pwm参考 https://blog.csdn.net/yangshengwei230612/article/details/128738351?spm1001.2014.3001.5501 以下主要是多通道与一通道的区别 芯片 stm32f407rgt6 1、配置PWM设备驱动相关宏定义 添加PWM宏定义 #define BSP_USING_PWM8 #define BSP_USING_PWM8_CH1 #d…...

C语言练习 | 初学者经典练习汇总
目录 1、下面代码输出多少,为什么? 2、你要好好学习么? 3、一直写代码, 4、两个数求最大值 5、输入1-5输出工作日,输入6-7输出休息日,其他输入错误 6、写一个输入密码的代码 7、怎么样当输入数字时候…...
 | 机试题算法思路 【2023】)
华为OD机试 - 自动曝光(Python) | 机试题算法思路 【2023】
最近更新的博客 华为OD机试 - 卡片组成的最大数字(Python) | 机试题算法思路 华为OD机试 - 网上商城优惠活动(一)(Python) | 机试题算法思路 华为OD机试 - 统计匹配的二元组个数(Python) | 机试题算法思路 华为OD机试 - 找到它(Python) | 机试题算法思路 华为OD机试…...

「6」线性代数(期末复习)
🚀🚀🚀大家觉不错的话,就恳求大家点点关注,点点小爱心,指点指点🚀🚀🚀 目录 第五章 相似矩阵及二次型 &2)方阵的特征值与特征向量 &3ÿ…...
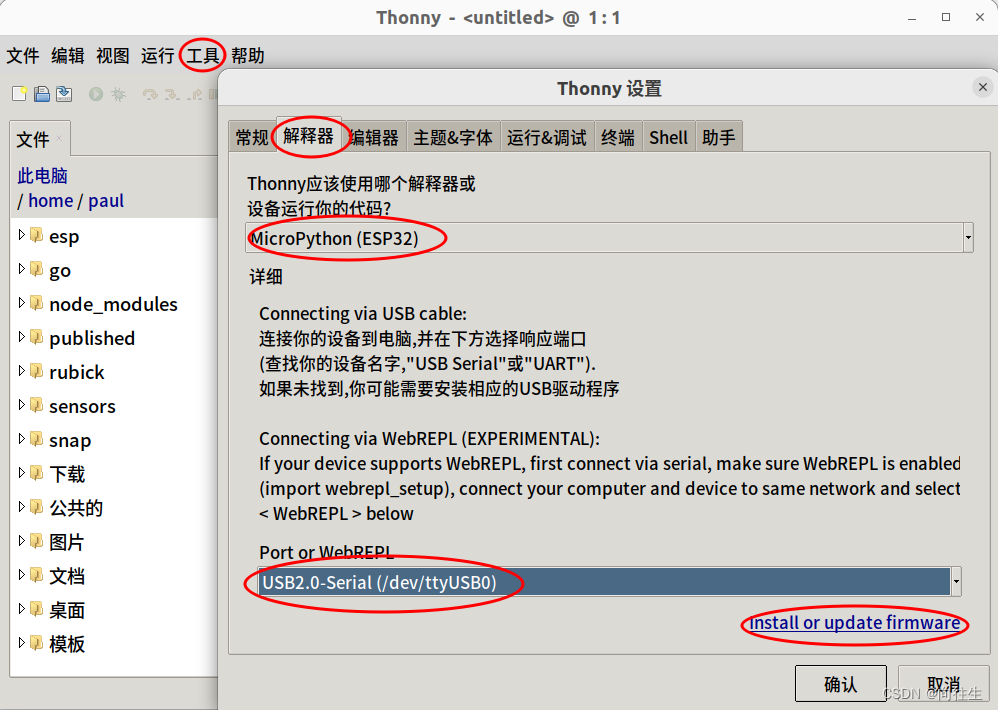
1.1 硬件与micropython固件烧录及自编译固件
1.ESP32硬件和固件 淘宝搜ESP32模块,20-50元都有,自带usb口,即插即用. 固件下载地址:MicroPython - Python for microcontrollers 2.烧录方法 为简化入门难度,建议此处先使用带GUI的开发工具THonny,记得不是给你理发的tony老师. 烧录的入口是: 后期通过脚本一次型生成和烧…...

【MySQL进阶】视图 存储过程 触发器
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...

[Linux篇] Linux常见命令和权限
文章目录使用XShell登录Linux1.Linux常用基本命令:1.1 ls(列出当前的目录下都有哪些文件和目录)1.2 cd (change directory 切换目录)1.3 pwd(查看当前目录的绝对路径)1.4 touch(创建文件)1.5 ca…...

29岁从事功能测试被辞,面试2个月都找不到工作吗?
最近一个28岁老同学联系我,因为被公司辞退,找我倾诉,于是写下此文。 他是14年二本毕业,在我的印象里人特别懒,不爱学习,专业不好,毕业前因为都没找到合适工作,直接去创业了…...

【C#个人错题笔记1】
观前提醒 记录一些我不会或者少见的内容,不一定适合所有人 字符串拼接 int a3,b8; Console.WriteLine(ab);//11 Console.WriteLine("ab");//ab Console.WriteLine(a""b);//38 Console.WriteLine("ab"ab);//ab38 Console.WriteLine…...

基于lambda的mongodb查询插件
需求背景需要一个像mybatis plus 一样的基于lambda, 且面向对象的查询mongo数据的插件。在网上找了很久,没有发现有类似功能的插件。于是自己手写了一个,借助mongoTemplate屏蔽了底层查询语句的实现细节。在此基础上,实现了查询的统一封装。技…...
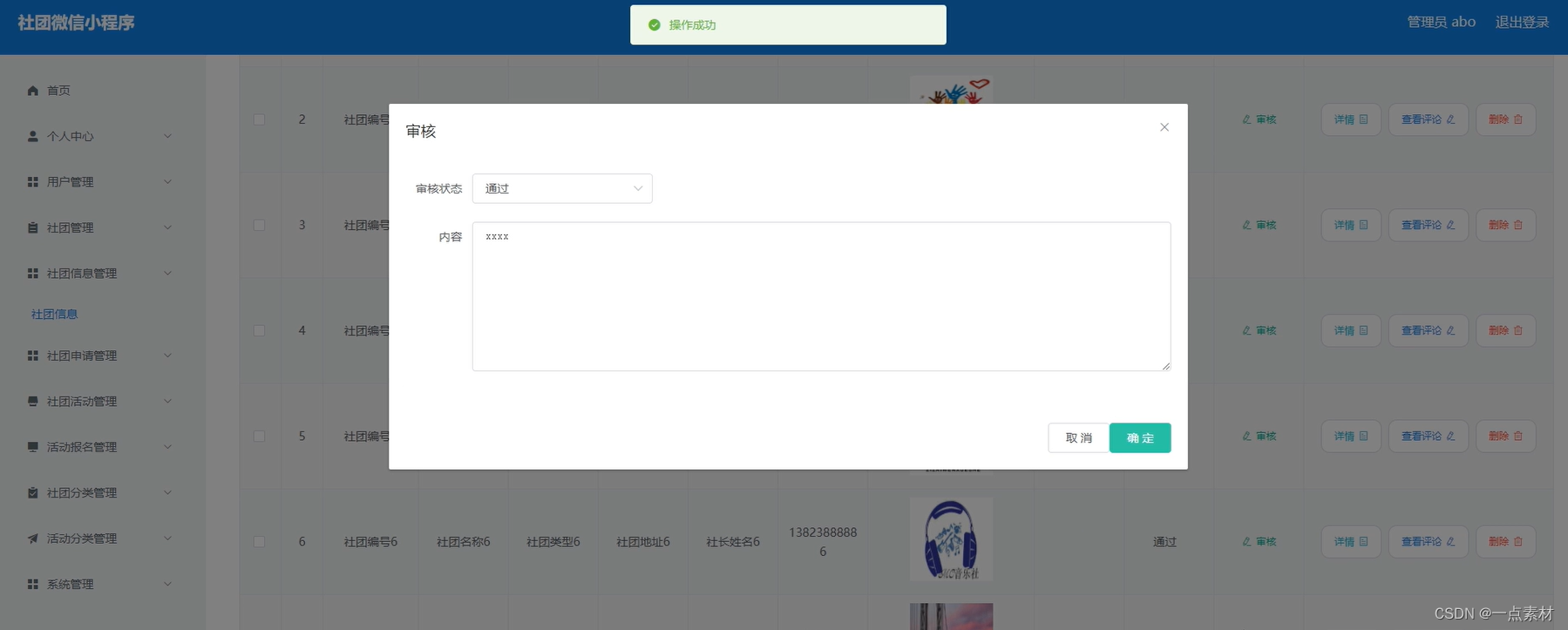
基于微信小程序的微信社团小程序
文末联系获取源码 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏览器…...
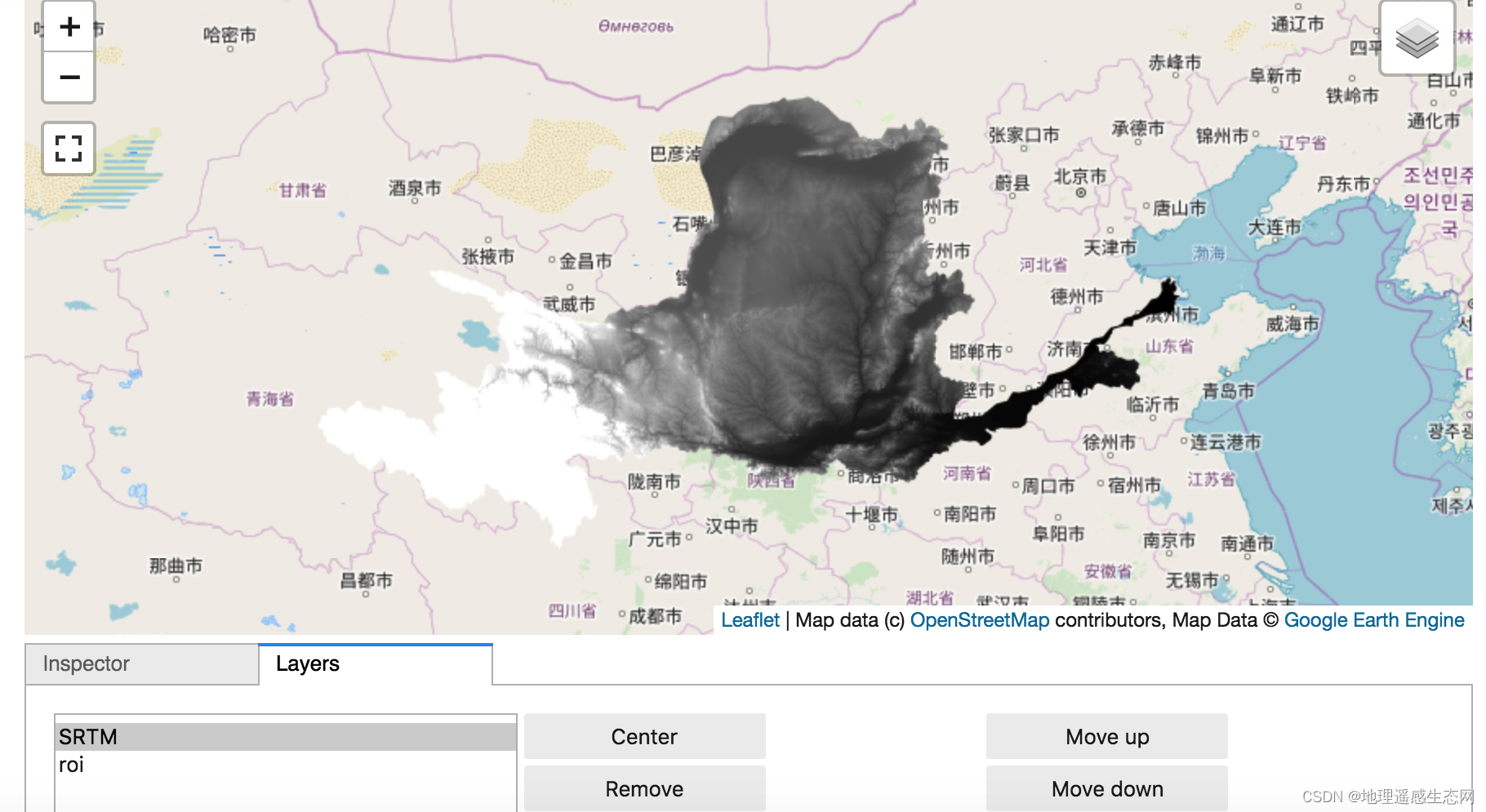
GEE学习笔记 七十三:【GEE之Python版教程七】静态展示影像和动态展示影像
我们使用GEE在线编辑可以直接通过在线的网页可以加载展示我们计算的结果,而python版的GEE要展示我们的计算结果可能就比较麻烦。如果有同学看过GEE的python版API中可以找到一个类ee.mapclient,这个类的介绍是它是GEE官方通过Tk写的一个加载展示地图的类。…...

PGLBox全面解决图训练速度、成本、稳定性、复杂算法四大问题!
图神经网络(Graph Neural Network,GNN)是近年来出现的一种利用深度学习直接对图结构数据进行学习的方法,通过在图中的节点和边上制定聚合的策略,GNN能够学习到图结构数据中节点以及边内在规律和更加深层次的语义特征。…...
使用入门篇)
超详细的 pytest 教程(一)使用入门篇
前言 pytest到目前为止还没有翻译的比较好全面的使用文档,很多英文不太好的小伙伴,在学习时看英文文档还是很吃力。本来去年就计划写pytest详细的使用文档的,由于时间关系一直搁置,直到今天才开始写。本文是第一篇,主…...
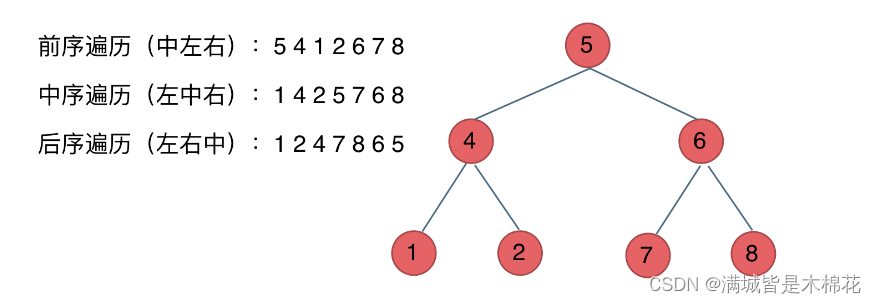
二叉树理论基础知识点
二叉树的种类 在我们解题过程中二叉树有两种主要的形式:满二叉树和完全二叉树 满二叉树 满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 如图所示: 这…...
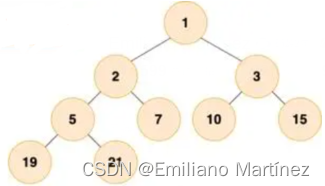
【算法基础】堆⭐⭐⭐
一、堆 1. 堆的概念 堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质: (1)堆中某个结点的值总是不大于或不小于其父结点的值; (2)堆总是一棵完全二叉树。 将根结点最大的堆叫做最大堆或大根堆,根结点…...

时序预测 | MATLAB实现CNN-SVM卷积支持向量机时间序列预测
时序预测 | MATLAB实现CNN-SVM卷积支持向量机时间序列预测 目录时序预测 | MATLAB实现CNN-SVM卷积支持向量机时间序列预测预测效果基本介绍研究回顾程序设计参考资料预测效果 基本介绍 CNN-SVM预测模型将深度学习模型作为特征学习器,将SVM 支持向量机 作为训练器进行…...
【TypeScrip】TypeScrip的任意类型(Any 类型 和 unknown 顶级类型):
文章目录一、安转依赖:【1】nodejs 环境执行ts【2】使用ts-node二、Any 类型 和 unknown 顶级类型【1】没有强制限定哪种类型,随时切换类型都可以 我们可以对 any 进行任何操作,不需要检查类型【2】声明变量的时候没有指定任意类型默认为any【…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

微服务通信安全:深入解析mTLS的原理与实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、引言:微服务时代的通信安全挑战 随着云原生和微服务架构的普及,服务间的通信安全成为系统设计的核心议题。传统的单体架构中&…...
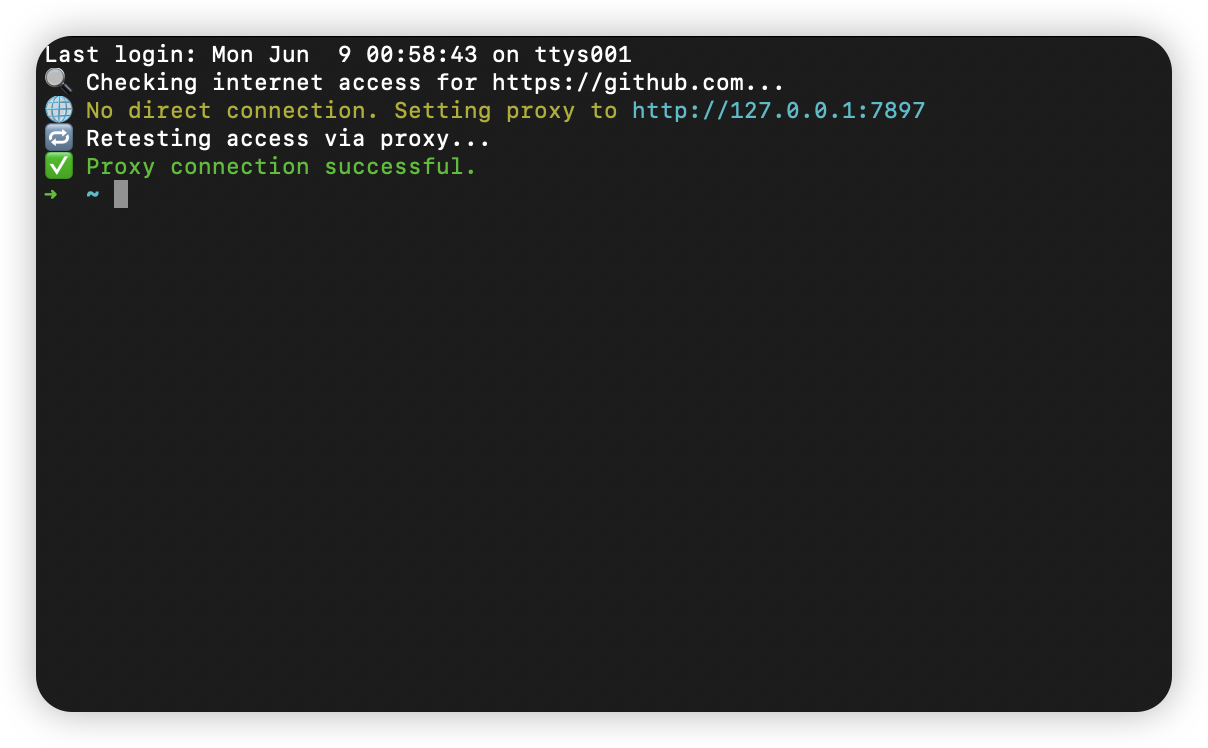
macOS 终端智能代理检测
🧠 终端智能代理检测:自动判断是否需要设置代理访问 GitHub 在开发中,使用 GitHub 是非常常见的需求。但有时候我们会发现某些命令失败、插件无法更新,例如: fatal: unable to access https://github.com/ohmyzsh/oh…...