机器学习基础07-模型选择01-利用scikit-learn 基于Pima 数据集对LogisticRegression算法进行评估
选择合适的模型是机器学习和深度学习中非常重要的一步,它直接影响到模型的性能和泛化能力。
“所有模型都是坏的,但有些模型是有用的”。建立模型之后就要去评 估模型,确定模型是否有用。模型评估是模型开发过程中不可或缺的一部
分,有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。
在选择模型时,需要综合考虑以下几个因素:
-
问题类型:首先需要明确问题的类型,是分类问题、回归问题、聚类问题还是其他类型的问题。不同类型的问题可能需要使用不同类型的模型。
-
数据量:数据量的大小对模型选择有影响。如果数据量较小,可以考虑使用较简单的模型,以防止过拟合。而如果数据量较大,可以考虑使用较复杂的模型,以更好地捕捉数据中的模式和规律。
-
特征数量和质量:特征是训练模型的关键。特征数量过多可能导致维度灾难,特征质量不好可能影响模型的性能。在特征数量较多的情况下,可以考虑使用特征选择技术来减少特征数量。
-
算法复杂度:模型的算法复杂度对于训练和推断的效率有影响。对于大规模数据或实时应用,需要选择计算复杂度较低的模型。
-
预测性能:需要对不同模型的预测性能进行评估,例如使用交叉验证等方法来评估模型的泛化能力。
-
领域知识:对于特定领域的问题,可能有一些经验性的模型或方法更加适用。
模型评估
要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证。此外,还可以采用重新采样评估的方法,使用新的数据来评估算法模型。
下面就将介绍如何使用 scikit-learn 中的采样评估办法来评价算法模型的准确度。
在评估机器学习算法的时候,为什么不将训练数据集直接作为评估数据集,最直接的原因是过度拟合,不能有效地发现算法模型的不足。所谓拟合是指已知某函数的若干离散函数值{f1,f2,…,fn},通过调整该函数中若干待定系数f (λ1,λ2,…,λn),使该函数与已知点集的差别(最小二乘意义)最小。
过度拟合是指为了得到一致假设变得过度严格。避免过度拟合是分类器设计中的一个核心任务,通常采用增大数据量和评估数据集的方法对分类器进行评估。
评估就是估计算法在预测新数据的时候能达到什么程度,但这不是对算法准确度的保证。当评估完算法模型之后,可以用整个数据集(训练数据集和评估数据集的合集)重新训练算法,生成最终的算法模型。接下来将学习四种不同的分离数据集的方法,用来分离训练数据集和评估数据集,并用其评估算法模型:
· 分离训练数据集和评估数据集。
· K折交叉验证分离。
· 弃一交叉验证分离。
· 重复随机评估、训练数据集分离。
分离训练数据集和评估数据集
最简单的方法就是将评估数据集和训练数据集完全分开,采用评估数据集来评估算法模型。可以简单地将原始数据集分为两部分,第一部分用来训练算法生成模型,第二部分通过模型来预测结果,并与已知的结果进行比较,来评估算法模型的准确度。如何分割数据集取决于数据集的规模,通常会将67%的数据作为训练集,将33%的数据作为评估数据集。
这是一种非常简洁,快速的数据分离技术,通常在具有大量数据、数 据分布比较平衡,或者对问题的展示比较平均的情况下非常有效。这个方
法非常快速,对某些执行比较慢的算法非常有效。
下面给出一个简单的按照67%:33%的比例分离数据,来评估逻辑回归模型的例子。
import pandas as pd
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_split#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]
# 分割数据集
test_size = 0.33
# 随机数种子
seed = 4
# 分割数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)# 逻辑回归
model = LogisticRegression(solver='lbfgs', max_iter=1000)
# 训练模型
model.fit(X_train, Y_train)
# 评估模型
result = model.score(X_test, Y_test)print("算法评估结果:%.3f%%" % (result * 100))运行结果:
算法评估结果:80.315%
执行后得到的结果大约是 80%。需要注意的是,为了让算法模型具有良好的可复用性,在指定了分离数据的大小的同时,还指定了数据随机的粒度(seed=4),将数据随机进行分离。通过指定随机的粒度,可以确保每次执行程序得到相同的结果,这有助于比较两个不同的算法生成的模型的结果。为了保证算法比较是在相同的条件下执行的,必须保证训练数据集和评估数据集是相同的
问题:分割数据集比例的调整对模型评估的影响有多大?
数据随机的粒度调整对模型评估的影响有多大?
数据随机的粒度指的是在数据集划分和处理过程中的随机性程度。这包括随机种子的设置、样本洗牌的方式等
K折交叉验证分离
交叉验证是用来验证分类器的性能的一种统计分析方法,有时也称作循环估计,在统计学上是将数据样本切割成小子集的实用方法。基本思想是按照某种规则将原始数据进行分组,一部分作为训练数据集,另一部分作为评估数据集。首先用训练数据集对分类器进行训练,再利用评估数据集来测试训练得到的模型,以此作为评价分类器的性能指标。
K折交叉验证是将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,再用这K个模型最终的验证集的分类准确率的平均数,作为此K折交叉验证下分类器的性能指标。K一般大于等于 2,实际操作时一般从 3 开始取值,只有在原始数据集和数据量小的时候才会尝试取 2。K 折交叉验证可以有效地避免过学习及欠学习状态的发生,最后得到的结果也比较具有说服力。
通常情况下,K的取值为3、5、10。代码如下:
import pandas as pd
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]# 分割数据集
num_folds = 9
# 随机数种子
seed = 4
# K折交叉验证,将数据分成10份,9份训练,1份测试,重复10次,取平均值,得到最终模型,评估模型
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
# 逻辑回归,使用lbfgs求解器,最大迭代次数1000,默认是100,如果模型没有收敛,可以适当增大
model = LogisticRegression(solver='lbfgs', max_iter=1000)
# 训练模型
result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f%% (%.3f%%)" % (result.mean() * 100, result.std() * 100))
运行结果:
执行结果中给出了评估的得分及标准方差
算法评估结果:77.068% (4.536%)
弃一交叉验证分离
如果原始数据有N个样本,那么弃一交叉验证就是N-1个交叉验证,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以弃一交叉验证会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此次弃一交叉验证分类器的性能指标。
相较于K折交叉验证,弃一交叉验
证有两个显著的优点:
- 每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
- 实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但弃一交叉验证的缺点是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,弃一交叉验证在实际运行上便有困难,需要花费大量的时间来完成算法的运算与评估,除非每次训练分类器得到模型的速度很快,或者可以用并行化计算减少计算所需的时间。
代码如下:
import timeimport pandas as pd
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import cross_val_score, LeaveOneOut#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]# 记录方法开始时间
start_time = time.time()
# 分割数据集
loocv = LeaveOneOut()model = LogisticRegression(solver='lbfgs', max_iter=1000)result = cross_val_score(model, X, Y, cv=loocv)
# 记录方法结束时间
end_time = time.time()print("算法评估结果:%.3f%% (%.3f%%)" % (result.mean() * 100, result.std() * 100))# 计算方法运行时间
execution_time = end_time - start_timeprint("方法运行时间:", execution_time, "秒")
运行结果:
算法评估结果:77.604% (41.689%)
方法运行时间: 8.518770933151245 秒利用此方法计算出的标准方差和K折交叉验证的结果有较大的差距。而且方法的运行时间也是很明显的变长了许多
重复随机分离 评估数据集与训练数据集
另外一种K折交叉验证的用途是随机分离数据为训练数据集和评估数据集,但是重复这个过程多次,就如同交叉验证分离。下面的例子就是将数据按照67%:33%的比例分离,然后重复这个过程10次。
代码如下:
import pandas as pd
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import cross_val_score, ShuffleSplit#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]
# 分割数据集
n_splits = 10
# 测试数据集占比
test_size = 0.33
# 随机数种子
seed = 7
# K折交叉验证,将数据分成10份,9份训练,1份测试,重复10次,取平均值,得到最终模型,评估模型
kfold = ShuffleSplit(n_splits=n_splits, test_size=test_size, random_state=seed)
# 逻辑回归,使用lbfgs求解器,最大迭代次数1000,默认是100,如果模型没有收敛,可以适当增大
model = LogisticRegression(solver='lbfgs', max_iter=500)
# 训练模型
result = cross_val_score(model, X, Y, cv=kfold)
# 记录方法结束时间
print("算法评估结果:%.3f%% (%.3f%%)" % (result.mean() * 100, result.std() * 100))运行结果:
算法评估结果:76.535% (2.235%)
介绍了上面四种用来分离数据集的方法,并通过分离后的评估数据集来评估算法模型。
通常会按照下面的原则来选择数据分离的方法:
- K折交叉验证是用来评估机器学习算法的黄金准则。通常会取K为3、5、10来分离数据。
- 分离训练数据集和评估数据集。因为执行效率比较高,通常会用于算法的执行效率比较低,或者具有大量数据的时候。
- 弃一交叉验证和重复随机分离评估数据集与训练数据集这两种方法,通常会用于平衡评估算法、模型训练的速度及数据集的大小。还有一条黄金准则就是,当不知道如何选择分离数据集的方法时,请选择K折交叉验证来分离数据集;当不知道如何设定K值时,请将K值设为
10。
下一节将学习如何评估分类和回归算法的方法,并创建算法的评估报告,以便选择最终的算法和生成算法模型。
相关文章:

机器学习基础07-模型选择01-利用scikit-learn 基于Pima 数据集对LogisticRegression算法进行评估
选择合适的模型是机器学习和深度学习中非常重要的一步,它直接影响到模型的性能和泛化能力。 “所有模型都是坏的,但有些模型是有用的”。建立模型之后就要去评 估模型,确定模型是否有用。模型评估是模型开发过程中不可或缺的一部 分ÿ…...

单片机实现动态内存管理
1.简介 多数传统的单片机并没有动态内存管理功能。单片机通常具有有限的存储资源,包括固定大小的静态RAM(SRAM)用于数据存储和寄存器用于特定功能。这些资源在编译时被分配并且在程序的整个生命周期中保持不变。 2.动态内存管理好处 灵活性和…...

(JS逆向专栏十一)某融平台网站登入RSA
声明: 本文章中所有内容仅供学习交流,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 名称:点融 目标:登入参数 加密类型:RSA 目标网址:https://www.dianrong.com/accoun…...
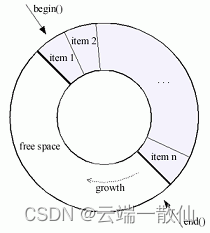
c++ boost circular_buffer
boost库中的 circular_buffer顾名思义是一个循环缓冲器,其 capcity是固定的当容量满了以后,插入一个元素时,会在容器的开头或结尾处删除一个元素。 circular_buffer为了效率考虑,使用了连续内存块保存元素 使用固定内存&#x…...

网络编程——端口
端口 一、端口概述 TCP/IP 协议采用端口标识通信的进程 用于区分一个系统里的多个进程 二、端口特点 1、对于同一个端口,在本同系统中对应着不同的进程 2、对于同一个系统,一个端口只能被一个进程拥有 3、一个进程拥有一个端口后,传输层送…...
【网络】自定义协议 | 序列化和反序列化 | Jsoncpp
本文首发于 慕雪的寒舍 以tcpServer的计算器服务为例,实现用jsoncpp来进行序列化和反序列化 阅读本文之前,请先阅读 自定义协议 | 序列化和反序列化 | 以tcpServer为例 1.安装jsoncpp 我所用的系统是centos7.6,先用下面的命令查找相关的包 …...

PHP实践:用openssl打造安全可靠的API签名验证系统
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。 🏆本文已…...
每天一道leetcode:剑指 Offer 50. 第一个只出现一次的字符(适合初学者)
今日份题目: 在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。 示例1 输入:s "abaccdeff" 输出:b 示例2 输入:s "" 输出: 提示 0 …...

【第五章 flutter学习之flutter进阶组件-下篇】
文章目录 一、Scaffold属性二、TabBar三、路由四、AlertDialog、SimpleDialog、showM...五、PageView六、Key七、AnimatedList八、动画 一、Scaffold属性 Flutter Scaffold 是一个用于构建基本用户界面的布局组件。它提供了许多属性,使得开发者能够轻松地创建一个完…...

单元测试和集成测试有什么区别
单元测试和集成测试有什么区别 单元测试和集成测试是软件开发中的两个重要测试阶段,它们的主要区别如下: 目的: 单元测试:主要针对代码的最小可测试单元,通常是一个函数或方法,确保它按照预期工作。集成…...

如何实现基于场景的接口自动化测试用例?
自动化本身是为了提高工作效率,不论选择何种框架,何种开发语言,我们最终想实现的效果,就是让大家用最少的代码,最小的投入,完成自动化测试的工作。 基于这个想法,我们的接口自动化测试思路如下…...
SAP 开发编辑界面-关闭助手
打开关闭助手时的开发界面如下: 关闭关闭助手后的界面如下: 菜单栏: 编辑--》修改操作--》关闭助手...
【el-image图片查看时 样式穿透表格问题】
element-ui el-image图片查看 样式混乱 解决方式 ::v-deep(.el-table__cell) {position: static !important; // 解决el-image 和 el-table冲突层级冲突问题 }加个样式即可...

GPT带我学-设计模式-模板模式
1 请你给我介绍一下设计模式中的模板模式 模板模式是一种行为设计模式,它定义了一个算法的骨架,将一些步骤的具体实现延迟到子类中。模板模式允许子类重新定义算法的某些特定步骤,而不需要改变算法的结构。 模板模式由以下几个角色组成&…...
Windows下调试UEFI程序:Visual Studio调试
以edk2\MdeModulePkg\Application\HelloWorld这个项目作为调试目标。 1. 使用VS2017建立Makefile工程 VS2017, 新建 project,取名X64dbg_vs。 Visual C > Other > Makefile Project, 注意项目路径为HelloWord程序路径。 随便填写config中的字符串ÿ…...

Vue中监听路由参数变化的几种方式
目录 一. 路由监听方式: 通过 watch 进行监听 1. 监听路由从哪儿来到哪儿去 2. 监听路由变化获取新老路由信息 3. 监听路由变化触发方法 4. 监听路由的 path 变化 5. 监听路由的 path 变化, 使用handler函数 6. 监听路由的 path 变化,触发method…...

angular——子组件如何接收父组件的动态传值
开发过程中,父组件给子组件传值的情况很常见,今天我们就来聊聊父组件给子组件传值可能会发生哪些意外,什么情况下子组件无法接收到父组件最新的传值; 传值情况: 基本数据类型:父组件给子组件传递 基本数据…...

php 桥接模式
一,桥接模式,是结构设计模式的一种,其将抽象部分和实现部分分离开来,使两部分可以独立的进行修改,提高系统的灵活性。在桥接模式中,需要定义一个抽象类和一个实现类,通过将实现类注入到抽象类中…...

Android 13 Hotseat定制化修改——004 hotseat布局位置
目录 一.背景 二.原生hotseat布局位置 三.修改Hotseat布局位置 一.背景 由于需求是需要自定义修改Hotseat,所以此篇文章是记录如何自定义修改hotseat的,应该可以覆盖大部分场景,修改点有修改hotseat布局方向,hotseat图标数量,hotseat图标大小,hotseat布局位置,hotseat…...
海外版金融理财系统源码 国际投资理财系统源码 项目投资理财源码
海外版金融理财系统源码 国际投资理财系统源码 项目投资理财源码...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...