Hadoop知识点总结
1. MapReduce中Shuffle的执行流程是什么样的?
- 阶段:Map端Shuffle、Reduce端Shuffle
- 功能:分区、排序、分组
Map端Shuffle
- 分区(Partition):在这个阶段,Map任务会调用分区器,根据Key的Hash值取模,以确定数据将进入哪个Reduce分区。
- 溢写(Spill):分区后的数据会被放入一个内存缓冲区。当缓冲区达到80%的阈值时,数据会被锁定并进行以下操作:
- 排序:使用内存中的快速排序算法,将相同分区的数据放在一起,并在每个分区内按照Key进行排序。
- 溢写:将排序好的数据写入磁盘,形成多个有序的小文件。
- 合并(Merge):每个Map任务会将自己生成的所有小文件合并成一个整体有序的大文件。在此过程中,会在磁盘中进行归并排序,将相同分区的数据放在一起,并在每个分区内按照Key进行排序。
Reduce端Shuffle
- 拉取(Pull):每个Reduce任务都会从每个Map任务生成的文件中读取属于自己的那部分数据。
- 合并(Merge):将拉取到的多份数据合并为整体有序的一份数据。在此过程中,会在磁盘中进行归并排序,按照Key进行排序。
- 分组(Group):按照Key进行分组,将相同Key的所有Value放入一个列表中。
2. YARN中MR程序运行的流程?
-
任务提交:客户端开始向ResourceManager提交MapReduce程序。
-
验证及启动:ResourceManager对提交的程序进行验证。如果验证通过,ResourceManager会随机选择一台NodeManager,并在其上启动Application Master。
-
资源申请:Application Master根据任务的需要,向ResourceManager申请运行任务所需的Container资源。
-
资源分配:ResourceManager根据当前资源状况,分配对应的Container,并将分配信息返回给Application Master。
-
资源分发:Application Master根据从ResourceManager接收到的Container信息,将这些信息分发给对应的NodeManager。
-
任务启动:NodeManager收到Container信息后,启动MapTask和ReduceTask。
-
任务监控:每个Task将其运行状态报告给Application Master。Application Master监控着每个Task的状态,直到任务结束。
-
任务结束:当所有Task都完成后,Application Master将运行结果返回。
3. YARN中的调度策略?
-
FIFO (First In, First Out):这是最简单的调度策略,也是Hadoop 1.x系列的默认调度策略。在这种策略下,任务会按照提交到系统的顺序进行处理,即先提交的任务先运行。这种策略简单易实现,但是在处理大型、长时间运行的任务时可能导致资源利用率低和等待时间长。
-
Capacity Scheduler:这是Apache Hadoop的默认调度器,它采用了多队列的设计,并在每个队列内部使用FIFO策略。每个队列都有固定的资源容量,当队列的资源没有被完全使用时,空余的资源可以被其他队列动态抢占。这种策略保证了资源的公平性和效率,但是需要进行适当的队列管理和配置。
-
Fair Scheduler:这是Cloudera Hadoop(CDH)的默认调度器,它也采用了多队列的设计。但与Capacity Scheduler不同的是,Fair Scheduler 会在队列内部公平地分配资源,而不是先进先出。此外,它还支持动态资源抢占和权重分配,使得某些队列可以获得更多的资源。这种策略在处理多种不同类型和大小的任务时非常有效。
4. Hive的元数据有几种存储管理方式?
-
内嵌 (Embedded):这种方式使用Hive内置的Apache Derby数据库来存储和管理元数据。这种方式的好处是配置简单,不需要额外的数据库服务。但是,因为Derby数据库不支持多个访问实例,所以这种方式只适合于单用户的测试环境。
-
本地 (Local):这种方式使用一个外部的关系型数据库(如MySQL,PostgreSQL,Oracle等)来存储和管理元数据。外部数据库可以支持多用户并发访问,因此这种方式适合于生产环境。需要注意的是,选择这种方式需要自行维护数据库服务,包括安全,备份和性能优化等。
-
远程 (Remote):这种方式使用一个独立的Metastore服务来存储和管理元数据。Metastore服务可以运行在一个或者多个服务器上,并使用一个外部的关系型数据库来存储元数据。这种方式的好处是可以分离Hive和元数据的存储,提高系统的可扩展性和稳定性。同时,也可以支持更高级的功能,如权限管理,审计和元数据版本控制等。
5. Hive的计算引擎支持哪几种?
-
MapReduce:这是Hive最初的计算引擎,也是许多早期Hadoop应用的基础。MapReduce模型简单易懂,非常适合处理大规模数据。然而,由于它的计算模型相对固定,且每个任务都需要读写磁盘,因此在处理复杂查询和交互式查询时,性能可能不尽如人意。
-
Tez:Tez是为了解决MapReduce在复杂数据处理上的性能问题而设计的计算框架。Tez引擎可以将一个查询的多个阶段合并为一个Tez任务,从而避免了不必要的磁盘I/O,大大提高了查询效率。此外,Tez还支持动态的计算图,可以更好地适应各种查询模式。
-
Spark:Spark是一种通用的大数据处理框架,它提供了比MapReduce更高级的计算模型,如RDD和DataFrame,以及丰富的计算库,如MLlib和GraphX。使用Spark作为Hive的计算引擎可以实现内存级的计算,大大提高了查询速度,特别是对于迭代式的数据处理任务。
6. Hive中常用的字符串函数有哪些?
-
split(str, regex): 将字符串
str按照正则表达式regex分割,返回一个数组。 -
substr(str, pos, len): 从字符串
str中提取出从位置pos开始,长度为len的子串。 -
regexp_replace(str, regex, replacement): 将字符串
str中符合正则表达式regex的部分替换为replacement。 -
concat(str1, str2, ...): 将两个或多个字符串连接在一起。
-
concat_ws(separator, str1, str2, ...): 使用特定的分隔符
separator将多个字符串连接在一起。 -
length(str): 返回字符串
str的长度。 -
instr(str, substr): 返回子串
substr在字符串str中第一次出现的位置。如果没有找到,返回0。 -
reverse(str): 返回一个与输入字符串
str相反的字符串。 -
trim(str): 返回去掉输入字符串
str两端的空格后的字符串。
7. Hive中常用的判断函数有哪些?
-
CASE WHEN:这是一种条件判断语句,它允许你在查询中添加逻辑判断。结构是这样的:
CASE WHEN condition THEN result [WHEN other_condition THEN other_result ...] [ELSE else_result] END。如果condition为真,则返回result;否则,如果other_condition为真,则返回other_result;如果所有条件都不为真,则返回else_result。 -
IF(testCondition, passValue, failValue):这是一个简单的条件判断函数,如果
testCondition为真,就返回passValue,否则返回failValue。 -
NVL(testValue, replaceValue):这个函数会检查
testValue是否为NULL。如果testValue为NULL,它会返回replaceValue;否则,它会返回testValue。 -
COALESCE(value1, value2, ...):这个函数从列表中返回第一个非NULL的值。如果所有值都是NULL,它将返回NULL。
8. Hive中常用的日期函数有哪些?
-
datediff(enddate, startdate): 返回两个日期之间的天数差。
enddate和startdate都应该是日期型的字符串。 -
date_add(date, num): 在日期
date上加上num天。 -
date_sub(date, num): 在日期
date上减去num天。 -
from_unixtime(unixtime, format): 将UNIX时间戳
unixtime转换为格式化的日期字符串。format参数是可选的,如果不提供,将使用默认的格式yyyy-MM-dd HH:mm:ss。 -
unix_timestamp(date, format): 将格式化的日期字符串
date转换为UNIX时间戳。format参数是可选的,如果不提供,将假设date是默认的格式yyyy-MM-dd HH:mm:ss。 -
date_format(date, format): 将日期
date转换为指定格式format的字符串。 -
current_date(): 返回当前的日期,格式为
yyyy-MM-dd。
9. Hive中如何处理JSON数据?
-
通过函数处理:
-
get_json_object(json_string, json_path):此函数可以从JSON字符串中获取数据。json_string是包含JSON数据的列,json_path是你想要获取的数据的JSON路径。
-
例如,假设你有一个名为my_table的表,其中有一列名为my_json,包含以下JSON数据:{"name":"John", "age":30, "city":"New York"}。那么,你可以使用以下查询来提取name字段:
SELECT get_json_object(my_json, '$.name') FROM my_table; 2. json_tuple(json_string, path1, path2, ...):此函数用于从JSON字符串中提取多个值。json_string是包含JSON数据的列,path1, path2, ... 是你想要获取的数据的JSON路径。
使用上面的例子,如果你想同时提取name和age字段,你可以使用以下查询:
SELECT name, age FROM my_table LATERAL VIEW json_tuple(my_json, 'name', 'age') jt AS name, age;2. JSON SerDe:SerDe是Serializer/Deserializer的简写,是Hive用来读写数据的接口。使用JSON SerDe,你可以直接创建一个JSON格式的表,然后加载JSON文件到这个表中。具体的创建表语句如下:
CREATE TABLE json_table (column1 type1, column2 type2, ...)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
然后,你可以使用LOAD DATA语句将JSON文件加载到这个表中:
LOAD DATA LOCAL INPATH 'path_to_json_file' INTO TABLE json_table;10. Hive中窗口函数有哪些,row_number(),rank()和dense_rank()的区别?
-
窗口聚合:这些函数可以在窗口内进行聚合操作。
sum、max、min、avg和count都可以在OVER子句中使用,以计算窗口内的总和、最大值、最小值、平均值和计数。 -
分析函数:
row_number():在窗口内为每行分配一个唯一的整数,从1开始。即使有两行具有完全相同的排序值,这两行也会得到不同的行号。rank():在窗口内为每行分配一个排名。如果两行具有完全相同的排序值,它们将得到相同的排名,下一个排名值将会跳过。dense_rank():在窗口内为每行分配一个排名。如果两行具有完全相同的排序值,它们将得到相同的排名,下一个排名值将不会跳过。ntile(n):在窗口内将行分成n个等大的组,每个组具有相同数量的行(如果可能)。percent_rank():计算每行的百分比排名。
-
位置偏移:
first_value:返回窗口内的第一个值。last_value:返回窗口内的最后一个值。lead:返回指定偏移量后的值。lag:返回指定偏移量前的值。
11. 分区和分桶的区别是什么?
-
设计目的:
- 分区:主要用于提高查询效率。通过创建分区,你可以避免全表扫描,只检索特定分区的数据。
- 分桶:主要用于解决随机数据采样、行级事务操作以及Reduce Join问题。
-
语法:
- 分区:使用
PARTITIONED BY语句创建分区。 - 分桶:使用
CLUSTERED BY语句创建分桶。
- 分区:使用
-
实现方式:
- 分区:在目录级别进行数据划分。分区字段是逻辑字段,不会真正存储在数据文件中。
- 分桶:在文件级别进行数据划分。分桶字段是物理字段,会真正存储在数据文件中。
-
使用场景:
- 分区:常规的数据查询和处理,特别是当你需要根据某些字段(如日期)频繁地过滤数据时。
- 分桶:随机数据采样、行级事务操作以及Reduce Join操作。
12. Hive中的sort by、order by、distribute by和cluster by有什么区别?
-
ORDER BY:这是最常见的排序操作,它会对输入进行全局排序。但是,因为只有一个reducer,所以当处理大量数据时,
ORDER BY可能会导致性能瓶颈。 -
SORT BY:
SORT BY也会对数据进行排序,但不保证全局排序。每个reducer会对其接收到的数据进行排序,但不同reducer间的数据可能不是有序的。因此,SORT BY通常比ORDER BY更快,但可能不会返回完全排序的结果。 -
DISTRIBUTE BY:
DISTRIBUTE BY会根据指定的列对数据进行分区。每个分区将被发送到一个特定的reducer。DISTRIBUTE BY不会对数据进行排序,所以同一个分区内的数据可能是无序的。 -
CLUSTER BY:
CLUSTER BY是DISTRIBUTE BY和SORT BY的结合。它首先根据指定的列对数据进行分区,然后在每个分区内进行排序。这样,同一个分区内的数据将是有序的。
13. 如何在Linux命令行执行Hive的SQL语句?
-
hive -e:使用
-e选项,你可以直接在命令行中执行Hive SQL语句。例如:hive -e 'SELECT * FROM my_table;'这个命令将执行
SELECT * FROM my_table;这个Hive SQL语句,并将结果输出到命令行。 -
hive -f:使用
-f选项,你可以执行存储在文件中的Hive SQL语句。例如:hive -f /path/to/my_script.sql这个命令将执行
/path/to/my_script.sql文件中的Hive SQL语句。
14. Hive中的优化有哪些?
-
参数优化:
-
本地模式(Local Mode):当处理小数据量时,可以尝试使用本地模式来避免Hadoop MapReduce的开销。在本地模式中,Hive会在单个JVM中直接运行查询。
-
矢量化查询(Vectorized Query Execution):这种优化方式可以显著提高内存中数据的处理速度。它通过处理数据块(而非单个行)来达到这个效果。
-
并行执行(Parallel Execution):Hive可以并行执行多个任务,例如MapReduce作业或子查询。这可以显著提高大规模查询的执行速度。
-
推测执行(Speculative Execution):Hadoop可以在多个节点上复制同一个任务,当其中一个节点执行缓慢时,其他节点的结果可以被提前使用。这可以避免慢节点影响整个查询的执行时间。
-
关联优化器(Join Optimizer):Hive可以根据表的大小和连接类型来重新排序连接操作,以提高查询性能。
-
代价基础优化(Cost-Based Optimization,CBO):Hive可以使用CBO来生成更有效的查询计划。CBO会考虑各种因素,如数据大小、过滤器选择性等。
-
零拷贝读取(Zero-Copy Read):这是一种优化读取性能的技术,它可以避免在读取数据时进行不必要的数据拷贝。
-
-
设计优化:
-
分区表(Partitioning):通过在表中创建分区,你可以将数据分成更小的部分,这样在查询时就只需要查找相关的分区,而不是整个表。
-
分桶表(Bucketing):通过对表进行分桶,你可以根据哈希函数将数据分布到多个桶中。这可以提高某些类型查询的性能,例如采样查询和JOIN查询。
-
文件格式(File Format):选择合适的文件格式可以提高查询性能。例如,Parquet和ORC是两种列式存储格式,它们可以提高列存储的查询性能。
-
压缩格式(Compression Format):选择合适的压缩格式也可以提高查询性能,因为它可以减少存储和IO成本。不过,压缩数据可能会增加CPU使用率。
-
ORC索引优化:如果你使用ORC文件格式,你可以利用其内置的索引来提高查询性能。
-
-
开发优化:
- 基于谓词下推(Predicate Pushdown):这是一种优化查询的方法,它通过在数据源尽可能早的阶段应用过滤器来减少需要处理的数据量。
15. Hive中的数据倾斜怎么发现的?什么原因导致的?怎么解决?
-
根本原因:分区的规则
-
默认分区:根据Key的Hash值取余reduce的个数
-
优点:相同的Key会由同一个reduce处理
-
缺点:可能导致数据倾斜
-
-
数据倾斜的场景:经过Shuffle过程中,数据重新分区
-
group by / count(distinct):分组
-
join:【Reduce Join】
-
-
解决方案
-
通用方案:调整Reduce个数:增大:适合于多个Key的数据全部集中在某个Reduce导致的数据倾斜
-
group by / count(distinct)
-
开启Combiner,减少进入Reduce数据量,来避免数据倾斜
hive.map.aggr=true
-
随机分区
-
方式一:开启参数
hive.groupby.skewindata=true
-
开启这个参数以后,底层会自动走两个MapReduce
-
第一个MapReduce自动实现随机分区
-
第二个MapReduce做最终的聚合
-
-
方式二:手动指定,适合于这一步的结果并不是最终结果,一定后续还有程序会对当前数据的进行处理
distribute by rand():将数据写入随机的分区中,避免数据倾斜
-
-
-
-
Join:避免走Reduce Join
-
方案一:尽量避免走Reduce Join
-
Map Join:尽量将不需要参加Join的数据过滤,将大表转换为小表
-
构建分桶Bucket Map Join
-
-
方案二:skewjoin:避免数据倾斜的Reduce Join过程【==限制:外连接不生效==】
-
相关文章:

Hadoop知识点总结
1. MapReduce中Shuffle的执行流程是什么样的? - 阶段:Map端Shuffle、Reduce端Shuffle - 功能:分区、排序、分组 Map端Shuffle 分区(Partition):在这个阶段,Map任务会调用分区器,根据Key的Hash值取模&a…...

相关搜索量激增10000%!“芭比周边”产品火爆亚马逊!
据外媒报道,芭比娃娃是今年夏天最热的话题。今年7月份,“芭比娃娃”是亚马逊上搜索最多的词。第二季度,Shopify上的芭比娃娃销量激增了56%。知名玩具制造商美泰(Mattel)预计,受电影的推动,在未来…...

C高级第四讲
1、思维导图 2、写一个shell函数,获取用户的uid和gid并使用变量接收 #!/bin/bash function get_id() {uidid -u ubuntugidid -g ubuntu } get_id echo "uid:$uid" echo "gid:$gid"运行结果 3、排序 冒泡排序 /* ------------------------…...
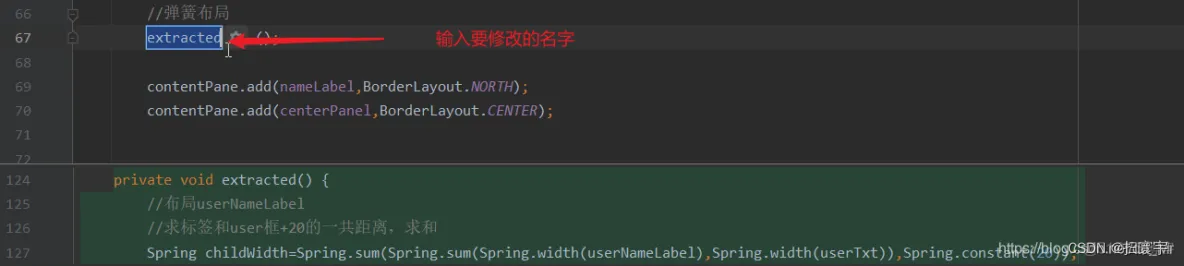
Idea小操作
Idea操作 idea提取内容构成一个方法 idea提取内容构成一个方法...

【计算机网络】socket编程
文章目录 1. 网络通信的理解2.进程PID可以取代端口号吗?3. 认识TCP协议4. 认识 UDP协议5. socket编程接口udp_server.hpp的代码解析socket——创建 socket 文件描述符Initserver——初始化1.创建套接字接口,打开网络文件bind——绑定的使用 2.给服务器指…...

2023华为OD机试真题 Python 实现【寻找最大价值的矿堆/深度优先搜索】
前言 本题使用Python解答,如果需要Java代码,请点击以下链接:点我 题目 我们规定,0表示空地,1表示银矿、2表示金矿,矿堆表示由相邻的金矿或银矿连接形成的地图。 银矿价值是1 ,金矿价值是2 ,你的目标是找出地图中最大价值的矿堆,并且输出该矿堆的价值 示例1 输入:…...

【Java面试】Nacos自动注册原理实现以及服务注册更新并如何保存到注册表
文章目录 Nacos自动注册原理实现服务注册更新并如何保存到注册表 Nacos自动注册原理实现 完整流程 我们知道SpringBoot提供了挂载点的方式来帮助我们的类完成自动注入。 Nacos再META-INF的spring.factories这个文件中添加了自己需要自动注入的Bean对象。 叫做NacosServiceRegi…...

linux 手动编译安装 pkg-config 步骤
1. 下载源码 Index of /releases (pkg-config.freedesktop.org) 2. 解压 并 进入解压后的文件夹 3. 运行配置文件 ./configure 错误解决办法:在linux中使用 ./configure 时报错 4. 编译、 自检、 安装 make make check make install 5. 安装完成后查看版本号…...

【MongoDB】数据库、集合、文档常用CRUD命令
目录 一、数据库操作 1、创建数据库操作 2、查看当前有哪些数据库 3、查看当前在使用哪个数据库 4、删除数据库 二、集合操作 1、查看有哪些集合 2、删除集合 3、创建集合 三、文档基本操作 1、插入数据 2、查询数据 3、删除数据 4、修改数据 四、文档分页查询 …...

【JVM】是如何管理内存的
文章目录 JVM 内存管理 模型JVM内存管理示例解析jvm 常见优化手段 JVM 内存管理 模型 以下是JVM内存管理的详细图示: ------------------------------------------------------ | Java 运行时数据区 | ------…...
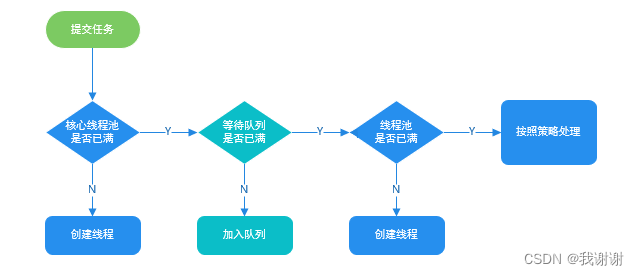
进程与线程、线程创建、线程周期、多线程安全和线程池(ThreadPoolExecutor)
目录 进程与线程线程和进程的区别是什么?线程分两种:用户线程和守护线程线程创建四种方式run()和start()方法区别:为什么调用 start() 方法时会执行 run() 方法,为什么不能直接调用 run() 方法?Runnable接口和Callable…...

《论文阅读13》Efficient Urban-scale Point Clouds Segmentationwith BEV Projection
一、论文 研究领域: 城市级3D语义分割论文:Efficient Urban-scale Point Clouds Segmentationwith BEV Projection论文链接 注: BEV: Birds Eye View BEV投影是指鸟瞰视角(Birds Eye View,简称BEV)的一种从上方观看对象或场景的…...

Django实现音乐网站 ⑻
使用Python Django框架制作一个音乐网站, 本篇主要是后台对单曲原有功能的基础上进行部分功能实现和显示优化。 目录 新增编辑 歌手下拉显示修改 设置歌曲时长 安装eyed3库 获取mp3时长 歌曲时长字段修改 重写save方法 增加歌手单曲数量 查询歌手单曲数量 …...
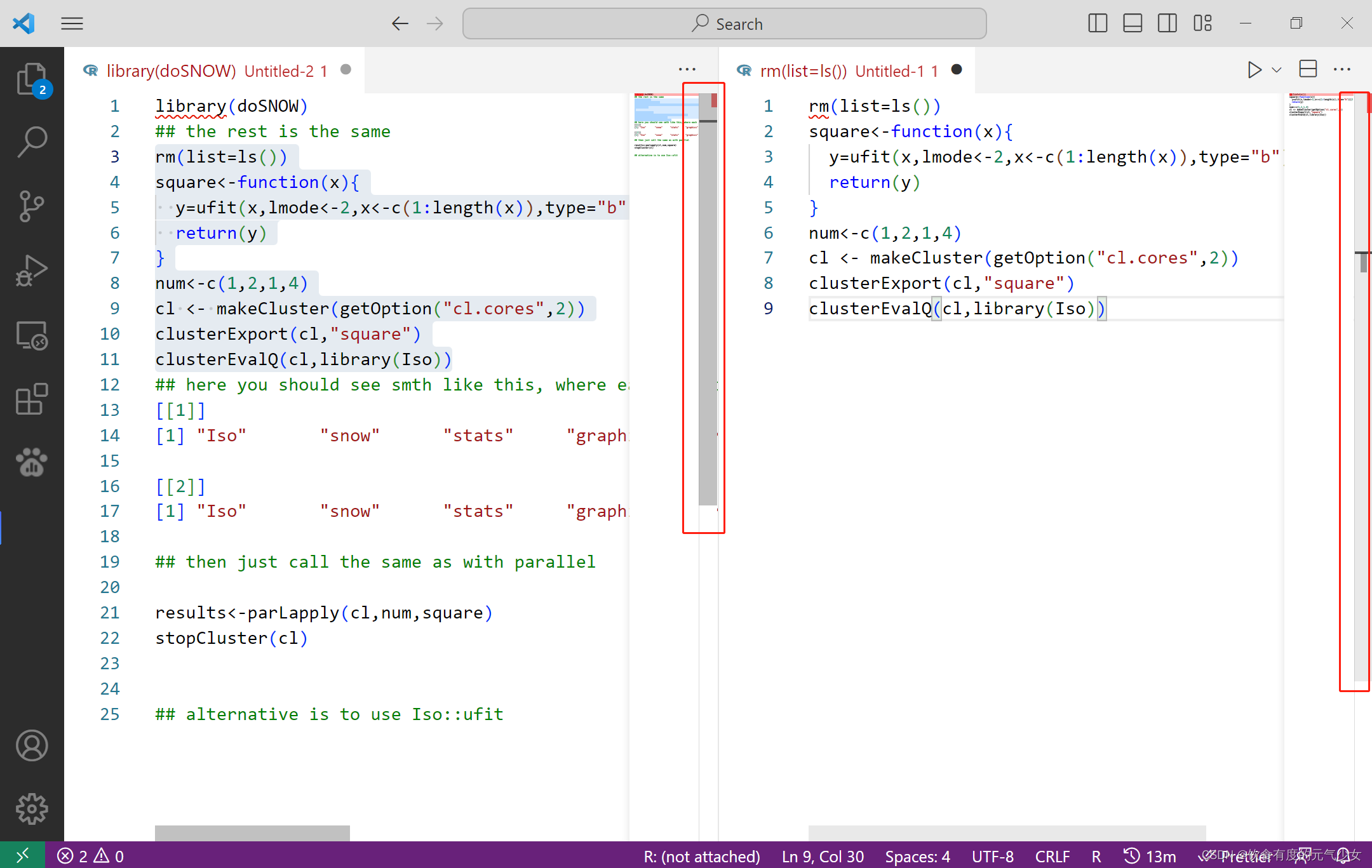
VScode中同时打开两个脚本
使用快捷键: CtrlAltRightArrow 效果: 可以看到,上述两个脚本使用独立的窗口进行编辑和查看。...

能源电力工程师专属Python学习资料
随着我国新型电力系统的建设,一方面电源侧各类新能源装机快速增长,对于新能源出力的功率预测需求日益增长;另一方面,我国电力市场经过 8 年建设,关于电力商品价格影响因素的研究亟待深入。超过 90% 的业务小伙伴都具备…...

推荐5款实用软件,提高工作效率,丰富生活乐趣
分享软件会让我感到开心和满足,因为我知道这些软件可以提高工作效率,丰富生活乐趣。今天再次将几款非常实用的软件推荐给大家。 截图翻译工具——CopyTranslator CopyTranslator是一款非常实用的截图翻译软件,它支持对截图、选定区域进行OCR文字识别,自动翻…...

Python爬虫在电商数据挖掘中的应用
作为一名长期扎根在爬虫行业的专业的技术员,我今天要和大家分享一些有关Python爬虫在电商数据挖掘中的应用与案例分析。在如今数字化的时代,电商数据蕴含着丰富的信息,通过使用爬虫技术,我们可以轻松获取电商网站上的产品信息、用…...
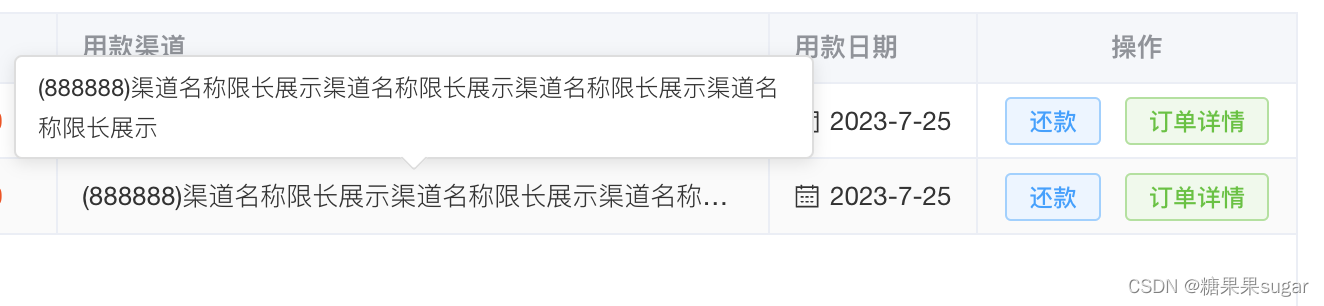
element-ui 表格el-table的列内容溢出省略显示,鼠标移上显示全部和定制样式
1、在对应列加上省略显示show-overflow-tooltip属性,如果加上这属性,鼠标移上还是没效果,要考滤是不是层级的原因,被其他挡住了。 :deep(.el-tooltip){position: relative;z-index:9; } <el-table-column label"用款渠…...

研究人员发现特斯拉汽车能被越狱,可免费解锁付费功能
Bleeping Computer 网站披露,柏林工业大学(Technical University of Berlin)的研究人员开发出一种新技术,可以破解特斯拉近期推出所有车型上使用的基于 AMD 的信息娱乐系统,并使其运行包括付费项目在内的任何软件。 实…...

【设计模式】责任链的基本概念及使用Predicate灵活构造校验链
文章目录 1. 概述1.1.背景1.2.责任链模式的概念 2.责任链的基本写法2.1.链表实现2.2.数组实现 3.Predicate校验链2.1.使用Predicate改写代码2.1.更丰富的条件拓展 4.总结 1. 概述 1.1.背景 在最近的开发中遇到了这么一个需求,需要对业务流程中的各个参数做前置校验…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...
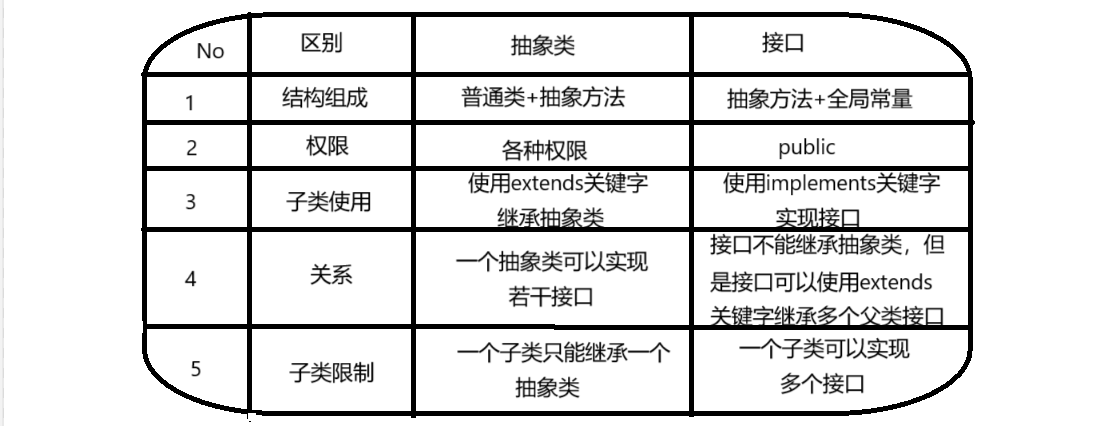
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...

AT模式下的全局锁冲突如何解决?
一、全局锁冲突解决方案 1. 业务层重试机制(推荐方案) Service public class OrderService {GlobalTransactionalRetryable(maxAttempts 3, backoff Backoff(delay 100))public void createOrder(OrderDTO order) {// 库存扣减(自动加全…...