机器学习复习题
1 单选题
- ID3算法、C4.5算法、CART算法都是( )研究方向的算法。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:A
- ( )作为机器学习重要算法之一,是一种利用多个树分类器进行分类和预测的方法。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:B
- ()是一种具有非线性适应性信息处理能力的算法,可克服传统人工智能方法对模式识别、语音识别、非结构化信息处理方面的缺陷。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:C
- ()是机器学习较早的研究方向,其源于英国数学家托马斯.贝叶斯在1763年发表的一篇论文中提到的贝叶斯定理。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:D
- 基于学习策略进行分类,机器学习可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:A
- 机器学习按学习方法大致可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:B
- 机器学习按学习方式大致可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:C
- 机器学习按数据形式大致可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:D
- 机器学习的实质是( )。
A. 根据现有数据,寻找输入数据和输出数据的映射关系/函数
B. 建立数据模型
C. 衡量输入数据和输出数据的映射关系/函数的好坏
D. 挑出输入数据和输出数据的最佳映射关系/函数
参考答案: A
- 越复杂的模型,在training data set表现出越好的误差性能,但在testing data set中并不总是表现出好的误差性能,这种现象被称为( )?
A. 过拟合
B. 泛化性能
C. 欠拟合
D. 泛化能力
参考答案: A
- K近邻算法是( )。
A.有监督学习
B.无监督学习
C.半监督学习
D.自主学习
参考答案: A
- 在数据预处理阶段,我们常常对数值特征进行归一化或标准化(standardization, normalization)处理。这种处理方式理论上不会对下列哪个模型产生很大影响?()
A. k k k-Means
B. k k k-NN
C. 决策树
参考答案:C
分析: k k k-Means和 k k k-NN都需要使用距离。而决策树对于数值特征,只在乎其大小排序,而非绝对大小。不管是标准化或者归一化,都不会影响数值之间的相对大小。关于决策树如何对数值特征进行划分。
- 下面哪个情形不适合作为 k k k-Means迭代终止的条件?
A. 前后两次迭代中,每个聚类中的成员不变
B. 前后两次迭代中,每个聚类中样本的个数不变
C. 前后两次迭代中,每个聚类的中心点不变
参考答案:B
分析:A和C是等价的,因为中心点是聚类中成员各坐标的均值
- 关于欠拟合(under-fitting),下面哪个说法是正确的?
A. 训练误差较大,测试误差较小
B. 训练误差较小,测试误差较大
C. 训练误差较大,测试误差较大
参考答案:C
当欠拟合发生时,模型还没有充分学习训练集中基本有效信息,导致训练误差太大。测试误差也会较大,因为测试集中的基本信息(分布)是与训练集相一致的。
- 关于集成学习(ensemble learning),下面说法正确的是:
A. 单个模型都是使用同一算法
B. 在集成学习中,使用“平均权重”会好于使用“投票”
C. 单个模型之间有低相关性
参考答案:C
- 以下说法哪些是正确的?
A. 在使用 k k k-NN算法时,k通常取奇数
B. k k k-NN是有监督学习算法
C.在使用 k k k-NN算法时, k k k取值越大,模型越容易过拟合
D. k k k-NN和 k k k-Means都是无监督学习算法
参考答案:B
- (单选题)不属于神经网络常用学习算法的是( )。
A. 监督学习
B. 增强学习
C. 观察与发现学习
D. 无监督学习
参考答案: C
- (单选题)
( ) 是一门用计算机模拟或实现人类视觉功能的新兴学科,其主要研究目标是使计算机具有通过二维图像认知三维环境信息的能力。
A. 机器视觉
B. 语音识别
C. 机器翻译
D. 机器学习
参考答案: A
- (单选题)在图灵测试中,如果有超过( )的测试者不能分清屏幕后的对话者是人还是机器,就可以说这台计算机通过了测试并具备人工智能。
A. 30%
B. 40%
C. 50%
D. 60%
参考答案: A
- (单选题)知识图谱可视为包含多种关系的图。在图中,每个节点是一个实体(如人名、地名、事件和活动等),任意两个节点之间的边表示这两个节点之间存在的关系。下面对知识图谱的描述,哪一句话的描述不正确( )
A. 知识图谱中一条边可以用一个三元组来表示
B. 知识图谱中一条边连接了两个节点,可以用来表示这两个节点存在某一关系
C. 知识图谱中两个节点之间仅能存在一条边
D. 知识图谱中的节点可以是实体或概念
参考答案:C
- 以下哪个步骤不是机器学习所需的预处理工作( )
A. 数值属性的标准化
B. 变量相关性分析
C. 异常值分析
D. 与用户讨论分析需求
参考答案: D
- 数据预处理对机器学习是很重要的,下面说法正确的是( )
A. 数据预处理的效果直接决定了机器学习的结果质量
B. 数据噪声对神经网络的训练没什么影响
C. 对于有问题的数据都直接删除即可
D. 预处理不需要花费大量的时间
参考答案: A
- 谷歌新闻每天收集非常多的新闻,并运用( )方法再将这些新闻分组,组成若干类有关联的新闻。于是,搜索时同一组新闻事件往往隶属同一主题的,所以显示到一起。
A. 回归
B. 分类
C. 聚类
D. 关联规则
参考答案: C
- 回归问题和分类问题的区别是什么?
A. 回归问题与分类问题在输入属性值上要求不同
B. 回归问题有标签,分类问题没有
C. 回归问题输出值是连续的,分类问题输出值是离散的
D. 回归问题输出值是离散的,分类问题输出值是连续的
参考答案: C
- 有关数据质量不正确的说法是( )
A. 错误的数据将可能产生有害于决策的结果
B. 因为数据量很大,所以数据质量差一些也对机器学习没多大影响
C. 数据预处理的重要目的是提高机器学习结果的质量
D. 从业务系统提取的脏数据需要预处理才能进行建模工作
参考答案: B
- 假设你正在做天气预报,并使用算法预测明天气温(摄氏度/华氏度),你会把这当作一个分类问题还是一个回归问题?
A. 分类
B. 回归
参考答案: B
- 假设你在做股市预测。你想预测某家公司是否会在未来7天内宣布破产(通过对之前面临破产风险的类似公司的数据进行训练)。你会把这当作一个分类问题还是一个回归问题?
A. 分类
B. 回归
参考答案: A
-
下列哪一个图片的假设与训练集过拟合?
A.
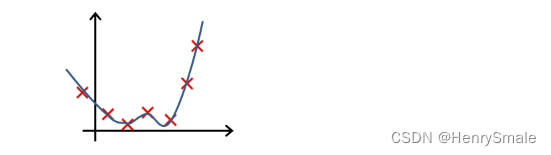
B.
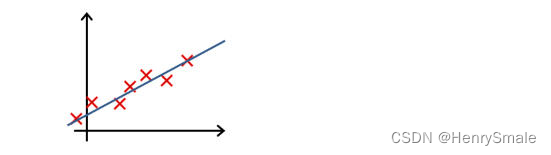
C.
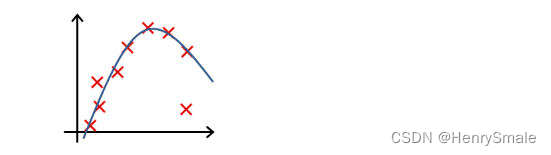
D.
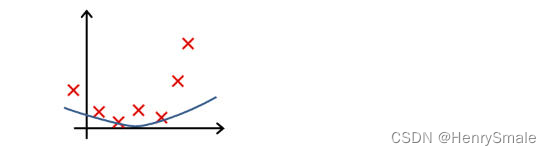
参考答案: A -
下列哪一个图片的假设与训练集欠拟合?
A.
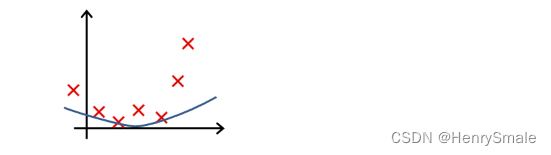
B.
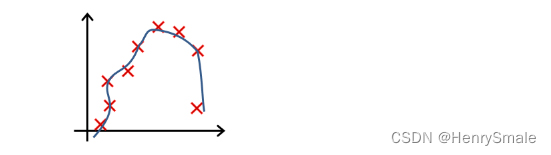
C.
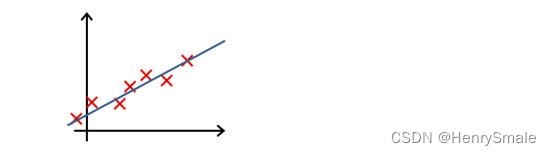
D.
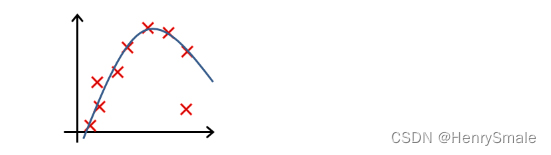
参考答案: A -
给定一定数量的红细胞、白细胞图像以及它们对应的标签,设计出一个红、白细胞分类器,这属于什么问题?
A. 有监督学习
B. 半监督学习
C. 无监督学习
D. 其他答案都正确
参考答案: A
- 已知变量x与y正相关,且由观测数据算得x的样本平均值为3,y的样本平均值为3.5,则由该观测数据算得的线性回归方程可能是( )。
A. y=0.4x+2.3
B. y=2x-2.4
C. y=-2x+9.5
D. y=-0.3x+4.4
参考答案: A
- ( )属于机器学习中的回归问题。
A. 根据房屋特性预测房价
B. 预测短信是否为垃圾短信
C. 识别车牌
D. 机场安检人脸识别
参考答案: A
- 以下哪个选项是尚未实现的人工智能技术?( )
A. 无人驾驶
B. 人工智能下围棋
C. 智能导航
D. 人脑芯片
参考答案: D
- 以下哪个选项是已经实现的人工智能技术?( )
A. 有情感的机器人
B. 通过图灵测试的语音应答机器人
C. 自我进化的机器人
D. 智能导航
参考答案: D
- 当前的人工智能处于( )阶段。
A. 弱人工智能
B. 强人工智能
C. 超人工智能
D. 非人工智能
参考答案: A
- 若得到如下一颗决策树,则属性值为(色泽 = 乌黑,根蒂 = 稍蜷,敲声 = 浊响,纹理 = 清晰,脐部 = 稍凹,触感 = 硬滑)的西瓜应判别为()
A. 好瓜
B. 坏瓜
C. 好瓜坏瓜都行
D. 无法判断
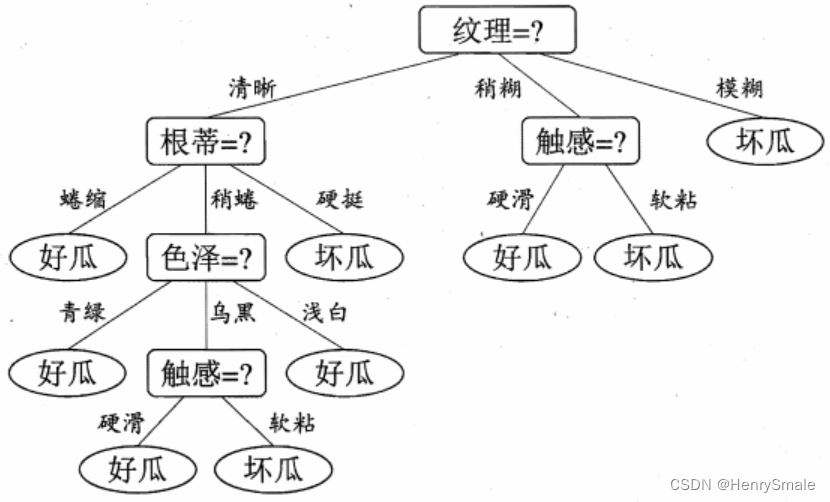
参考答案: A
- 若神经网络结构中输入层有a个神经元,紧跟其后的隐藏层有b个神经元,则从输入层到该隐藏层的权重个数是( )
A. a + b
B. a - b
C. a * b
D. a/b
参考答案: C
- 在聚类中,样本数据()
A. 有标签信息
B. 没有标签信息
C. 标签信息可有可无
D. 不同的聚类情况不一样
参考答案: B
- 聚类试图将样本划分为若干个不相交的子集,每个子集称为( )
A. 类
B. 树
C. 簇
D. 点
参考答案: C
- 根据下图,查准率的定义是( )
A. P = T P T P + F N P = \frac{TP}{TP + FN} P=TP+FNTP
B. P = T P T N + F N P = \frac{TP}{TN + FN} P=TN+FNTP
C. P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP
D. P = T P T P + T N P = \frac{TP}{TP + TN} P=TP+TNTP

参考答案: C
分析: T P TP TP指 “预测为正(Positive), 预测正确(True)” (可以这样记忆:第一位表示该预测是否正确,第二位表示该预测结果为正还是负) , 于是,我们可以这样理解查准率 P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP : 所有预测为正例的样本中,预测准确的比例;召回率 R = T P T P + T N R = \frac{TP}{TP + TN} R=TP+TNTP:所有预测准确的样本中,正例所占的比例。
2 多选题
- 下面属于训练集(Training data set)和测试集(Testing data set)区别表述的是
A. Testing data set用于测试寻找到的函数的效果
B. Training data set用于寻找函数
C. Training data set用于挑选模型
D. Training data set用于构建模型
参考答案: ABCD
- 机器学习的方法由( )等几个要素构成。
A. 损失函数
B. 优化算法
C. 模型
D. 模型评估指标
参考答案: ABCD
- 下列哪些学习问题不属于监督学习?( )
A. 聚类
B. 回归
C. 分类
D. 降维
参考答案: AD
- 下面的一些问题最好使用有监督的学习算法来解决,而其他问题则应该使用无监督的学习算法来解决。以下哪一项你会使用监督学习?(选择所有适用的选项)在每种情况下,假设有适当的数据集可供算法学习。
A. 根据一个人的基因(DNA)数据,预测他/她的未来10年患糖尿病的几率
B. 根据心脏病患者的大量医疗记录数据集,尝试了解是否有多种类型的心脏病患者群,我们可以为其量身定制不同的治疗方案
C. 让计算机检查一段音频,并对该音频中是否有人声(即人声歌唱)或是否只有乐器(而没有人声)进行分类
D. 给出1000名医疗患者对实验药物的反应(如治疗效果、副作用等)的数据,发现患者对药物的反应属于哪种类别或“类型”
参考答案: AD
- 当数据集中样本类别不均衡时,常采用哪些方法来解决?()
A. 降采样
B. 升采样
C. 人造数据
D. 更换分类算法
E. 以上都不是。
参考答案: ACD
相关文章:
机器学习复习题
1 单选题 ID3算法、C4.5算法、CART算法都是( )研究方向的算法。 A . 决策树 B. 随机森林 C. 人工神经网络 D. 贝叶斯学习 参考答案:A ( )作为机器学习重要算法之一,是一种利用多个树分类器进行分类和预测…...

无线液位传感器—简介
近年来,随着无线传感网络技术的愈发成熟和稳定,无线传感器因其安装、维护方便,不用布线、节约成本,监测方便,使用灵活,可适用于多种工业领域等优点,正在逐步替代部分传统有线传感器,…...
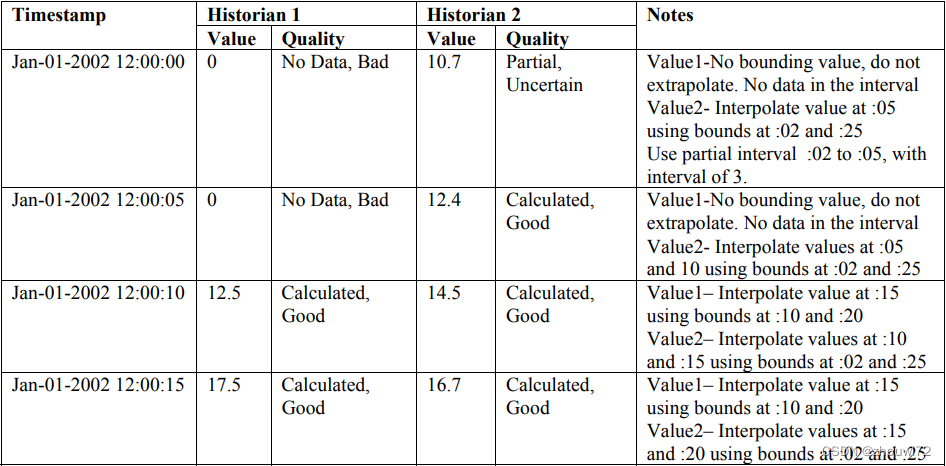
通讯协议034——全网独有的OPC HDA知识一之聚合(三)时间加权平均
本文简单介绍OPC HDA规范的基本概念,更多通信资源请登录网信智汇(wangxinzhihui.com)。 本节旨在详细说明HDA聚合的要求和性能。其目的是使HDA聚合标准化,以便HDA客户端能够可靠地预测聚合计算的结果并理解其含义。如果用户需要聚合中的自定义功能&…...

Android 13 Hotseat定制化修改——003 hotseat图标大小修改
目录 一.背景 二.未修改前效果 三.修改后效果 一.背景 由于需求是需要自定义修改Hotseat,所以此篇文章是记录如何自定义修改hotseat的,应该可以覆盖大部分场景,修改点有修改hotseat布局方向,hotseat图标数量,hotseat图标大小,hotseat布局位置,hotseat图标禁止形成文件…...
21、springboot的宽松绑定及属性处理类的构造注入
springboot的宽松绑定及属性处理类的构造注入 ★ 如何使用属性处理类所读取的属性 属性处理类最终变成了Spring容器中的一个Bean组件,因此接下来Spring即可将该Bean组件注入任意其他组件。 这种做法的好处是:可以将大量的配置信息封装一个对象——所以…...

nginx负载均衡(反向代理)
nginx负载均衡 负载均衡:由反向代理来实现。 nginx的七层代理和四层代理: 七层是最常用的反向代理方式,只能配置在nginx配置文件的http模块当中,而且配置方法名称:upstream模块,不能写在server模块中&#…...

AWS上传私有windows server2019镜像64位
一.制作自己的镜像 我使用的是esxi,建立一个windows虚拟机,开启。 根据aws官方文档,虚拟机里的系统重要需要注意以下几点: 1.只有一张网卡,ip获取配置成dhcp。 2.关闭系统防火墙。 3.开启windows rdp 远程功能。 …...

查看当前仓库对应的远程仓库地址
查看当前仓库对应的远程仓库地址 git remote -v这条命令能显示你当前仓库中已经添加了的仓库名和对应的仓库地址,通常来讲,会有两条一模一样的记录,分别是fetch和push,其中fetch是用来从远程同步 push是用来推送到远程 修改仓库…...

flask-script
# django中,有命令 python manage.py runserver python manage.py makemigrations ...自定制命令(django如何自定制命令)... -python manage.py init_db excel文件路径 指定表名 # flask启动项目,像djag…...

标准的OSI七层模型(其实了解tcp足矣)
七层模型,亦称OSI(Open System Interconnection)。参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。 它是一个七层的、抽象的模型体&#x…...

【C++】初识模板
C模板入门 一、泛型编程 二、函数模板1. 函数模板的概念2. 函数模板格式3. 函数模板的原理4. 函数模板的实例化5. 模板参数的匹配原则 三、类模板 一、泛型编程 假设我们想实现一个交换函数,并且支持不同类型的参数实现,我们可以用 typedef 将类型进行重…...

学习Pull request
我从我的导师Xing Fan指导和帮助,利用我的导师chunlong Li提供ChatGPT,在百度搜索,学习一些资料。以下很多内容都是我的导师Xing Fan做的。谢谢Xing Fan。考虑到隐私,不适合截图公开。 第一步: 打开Git Bash Here 如…...

python爬虫实战(1)--爬取新闻数据
想要每天看到新闻数据又不想占用太多时间去整理,萌生自己抓取新闻网站的想法。 1. 准备工作 使用python语言可以快速实现,调用BeautifulSoup包里面的方法 安装BeautifulSoup pip install BeautifulSoup完成以后引入项目 2. 开发 定义请求头…...

React Hooks 详细使用介绍
useState 状态管理 useState 是 React 中的一个基础 Hook,允许你在不使用 class 组件的情况下管理组件状态。 参数 初始值 你可以直接传递状态的初始值给 useState: const [name, setName] useState("John");使用函数设置初始值 当初始…...

python版《羊了个羊》游戏开发第一天
Python小型项目实战教学课《羊了个羊》 一、项目开发大纲(初级) 版本1.0:基本开发 课次 内容 技术 第一天 基本游戏地图数据 面向过程 第二天 鼠标点击和移动 面向对象 第三天 消除 设计模式:单例模式 第四天 完整…...

【uniapp】原生子窗体subNvue的使用与踩坑
需求 最近接到个需求, 需要在video组件上弹出弹窗, 也就是覆盖video这个原生组件 未播放时, 弹窗可以覆盖, 但是当video播放时, 写的弹窗就覆盖不了了 因为video是原生组件, 层级非常高, 普通标签是覆盖不了的, map标签同理 覆盖原生组件, 官方给出解决办法一. 使用cover-view…...
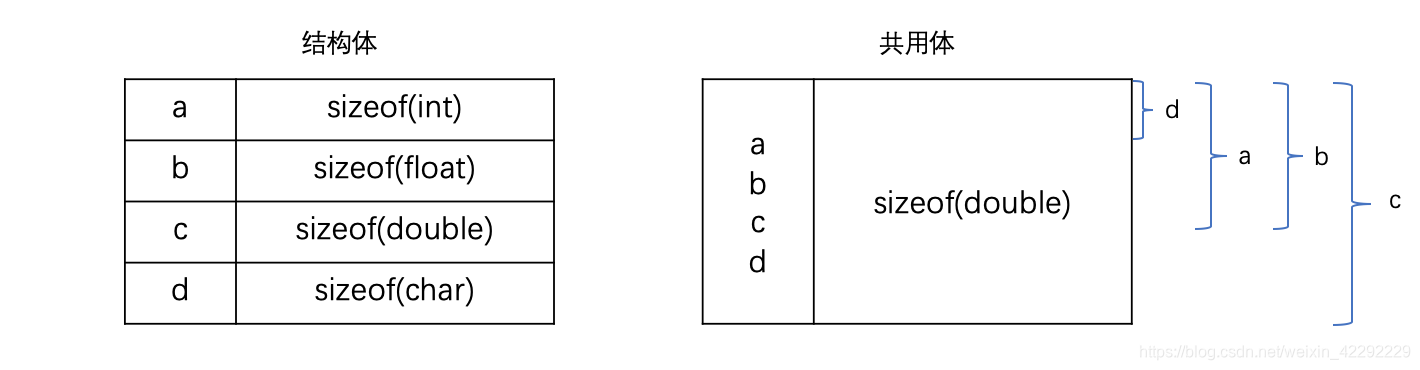
浅析 C 语言的共用体、枚举和位域
前言 最近在尝试阅读一些系统库的源码,但是其中存在很多让我感到既熟悉又陌生的语法。经过资料查阅,发现是 C 语言中的共用体和位域。于是,趁着课本还没有扔掉,将一些相关的知识点记录在本文。 文章目录 前言共用体 (union)枚举…...
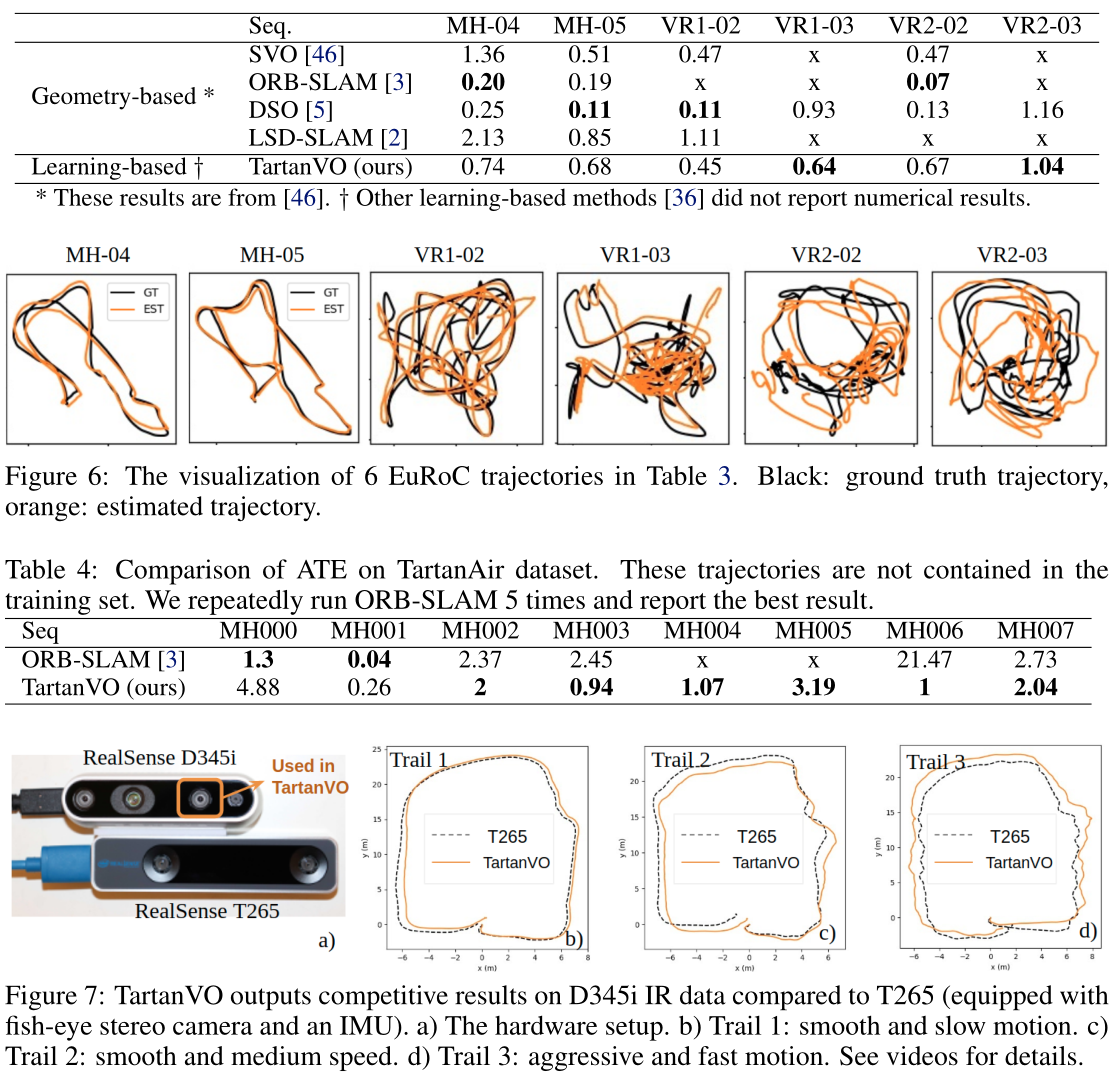
TartanVO: A Generalizable Learning-based VO 论文阅读
论文信息 题目:TartanVO: A Generalizable Learning-based VO 作者:Wenshan Wang, Yaoyu Hu 来源:ICRL 时间:2021 代码地址:https://github.com/castacks/tartanvo Abstract 我们提出了第一个基于学习的视觉里程计&…...
单例模式-java实现
介绍 单例模式的意图:保证某个类在系统中有且仅有一个实例。 我们可以看到下面的类图:一般的单例的实现,是属性中保持着一个自己的私有静态实例引用,还有一个私有的构造方法,然后再开放一个静态的获取实例的方法给外界…...

篇八:装饰器模式:动态增加功能
篇八:“装饰器模式:动态增加功能” 开始本篇文章之前先推荐一个好用的学习工具,AIRIght,借助于AI助手工具,学习事半功倍。欢迎访问:http://airight.fun/。 另外有2本不错的关于设计模式的资料,…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...