06 - Stream如何提高遍历集合效率?
前面我们讲过 List 集合类,那我想你一定也知道集合的顶端接口 Collection。
在 Java8 中,Collection 新增了两个流方法,分别是 Stream() 和 parallelStream()。
1、什么是 Stream?
现在很多大数据量系统中都存在分表分库的情况。
例如,电商系统中的订单表,常常使用用户 ID 的 Hash 值来实现分表分库,这样是为了减少单个表的数据量,优化用户查询订单的速度。
但在后台管理员审核订单时,他们需要将各个数据源的数据查询到应用层之后进行合并操作。
例如,当我们需要查询出过滤条件下的所有订单,并按照订单的某个条件进行排序,单个数据源查询出来的数据是可以按照某个条件进行排序的,但多个数据源查询出来已经排序好的数据,并不代表合并后是正确的排序,所以我们需要在应用层对合并数据集合重新进行排序。
在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
Java8 中添加了一个新的接口类 Stream,他和我们之前接触的字节流概念不太一样,Java8 集合中的 Stream 相当于高级版的 Iterator,他可以通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream 的聚合操作与数据库 SQL 的聚合操作 sorted、filter、map 等类似。我们在应用层就可以高效地实现类似数据库 SQL 的聚合操作了,而在数据操作方面,Stream 不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
接下来我们就用一个简单的例子来体验下 Stream 的简洁与强大。
这个 Demo 的需求是过滤分组一所中学里身高在 160cm 以上的男女同学,我们先用传统的迭代方式来实现,代码如下:
Map<String, List<Student>> stuMap = new HashMap<String, List<Student>>();for (Student stu: studentsList) {if (stu.getHeight() > 160) { // 如果身高大于 160if (stuMap.get(stu.getSex()) == null) { // 该性别还没分类List<Student> list = new ArrayList<Student>(); // 新建该性别学生的列表list.add(stu);// 将学生放进去列表stuMap.put(stu.getSex(), list);// 将列表放到 map 中} else { // 该性别分类已存在stuMap.get(stu.getSex()).add(stu);// 该性别分类已存在,则直接放进去即可}}}我们再使用 Java8 中的 Stream API 进行实现:
- 串行实现
Map<String, List<Student>> stuMap = stuList.stream().filter((Student s) -> s.getHeight() > 160).collect(Collectors.groupingBy(Student::getSex));- 并行实现
Map<String, List<Student>> stuMap = stuList.parallelStream().filter((Student s) -> s.getHeight() > 160).collect(Collectors.groupingBy(Student ::getSex));通过上面两个简单的例子,我们可以发现,Stream 结合 Lambda 表达式实现遍历筛选功能非常得简洁和便捷。
2、Stream 如何优化遍历?
上面我们初步了解了 Java8 中的 Stream API,那 Stream 是如何做到优化迭代的呢?并行又是如何实现的?下面我们就透过 Stream 源码剖析 Stream 的实现原理。
2.1、Stream 操作分类
在了解 Stream 的实现原理之前,我们先来了解下 Stream 的操作分类,因为他的操作分类其实是实现高效迭代大数据集合的重要原因之一。为什么这样说,分析完你就清楚了。
官方将 Stream 中的操作分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)。中间操作只对操作进行了记录,即只会返回一个流,不会进行计算操作,而终结操作是实现了计算操作。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。操作分类详情如下图所示:
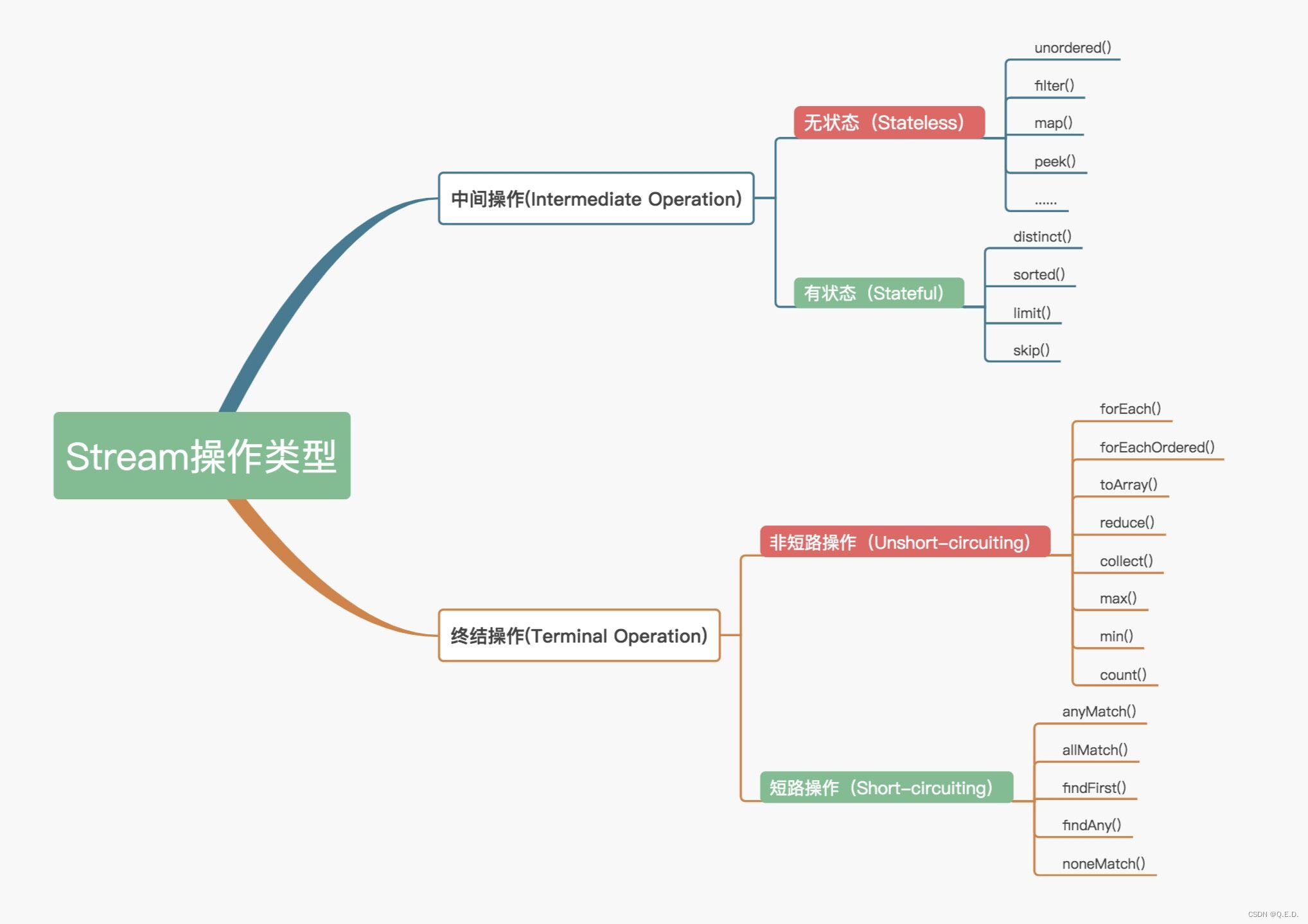
我们通常还会将中间操作称为懒操作,也正是由这种懒操作结合终结操作、数据源构成的处理管道(Pipeline),实现了 Stream 的高效。
2.2、Stream 源码实现
在了解 Stream 如何工作之前,我们先来了解下 Stream 包是由哪些主要结构类组合而成的,各个类的职责是什么。参照下图:
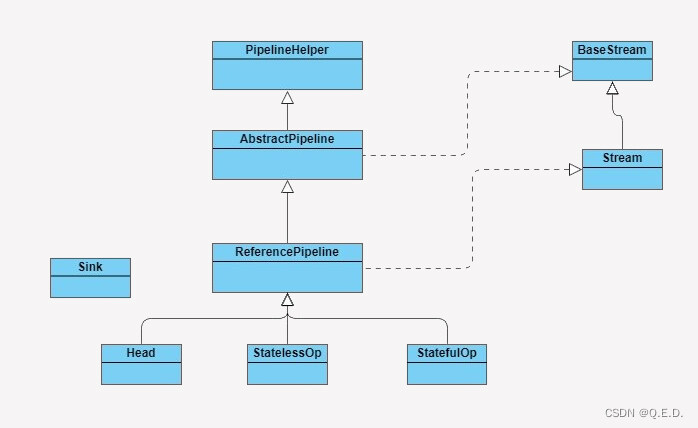
BaseStream 和 Stream 为最顶端的接口类。BaseStream 主要定义了流的基本接口方法,例如,spliterator、isParallel 等;Stream 则定义了一些流的常用操作方法,例如,map、filter 等。
ReferencePipeline 是一个结构类,他通过定义内部类组装了各种操作流。他定义了 Head、StatelessOp、StatefulOp 三个内部类,实现了 BaseStream 与 Stream 的接口方法。
Sink 接口是定义每个 Stream 操作之间关系的协议,他包含 begin()、end()、cancellationRequested()、accpt() 四个方法。ReferencePipeline 最终会将整个 Stream 流操作组装成一个调用链,而这条调用链上的各个 Stream 操作的上下关系就是通过 Sink 接口协议来定义实现的。
2.3、Stream 操作叠加
我们知道,一个 Stream 的各个操作是由处理管道组装,并统一完成数据处理的。在 JDK 中每次的中断操作会以使用阶段(Stage)命名。
管道结构通常是由 ReferencePipeline 类实现的,前面讲解 Stream 包结构时,我提到过 ReferencePipeline 包含了 Head、StatelessOp、StatefulOp 三种内部类。
Head 类主要用来定义数据源操作,在我们初次调用 names.stream() 方法时,会初次加载 Head 对象,此时为加载数据源操作;接着加载的是中间操作,分别为无状态中间操作 StatelessOp 对象和有状态操作 StatefulOp 对象,此时的 Stage 并没有执行,而是通过 AbstractPipeline 生成了一个中间操作 Stage 链表;当我们调用终结操作时,会生成一个最终的 Stage,通过这个 Stage 触发之前的中间操作,从最后一个 Stage 开始,递归产生一个 Sink 链。如下图所示:

下面我们再通过一个例子来感受下 Stream 的操作分类是如何实现高效迭代大数据集合的。
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");String maxLenStartWithZ = names.stream().filter(name -> name.startsWith(" 张 ")).mapToInt(String::length).max().toString();这个例子的需求是查找出一个长度最长,并且以张为姓氏的名字。从代码角度来看,你可能会认为是这样的操作流程:首先遍历一次集合,得到以“张”开头的所有名字;然后遍历一次 filter 得到的集合,将名字转换成数字长度;最后再从长度集合中找到最长的那个名字并且返回。
这里我要很明确地告诉你,实际情况并非如此。我们来逐步分析下这个方法里所有的操作是如何执行的。
首先 ,因为 names 是 ArrayList 集合,所以 names.stream() 方法将会调用集合类基础接口 Collection 的 Stream 方法:
default Stream<E> stream() {return StreamSupport.stream(spliterator(), false);}然后,Stream 方法就会调用 StreamSupport 类的 Stream 方法,方法中初始化了一个 ReferencePipeline 的 Head 内部类对象:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {Objects.requireNonNull(spliterator);return new ReferencePipeline.Head<>(spliterator,StreamOpFlag.fromCharacteristics(spliterator),parallel);}再调用 filter 和 map 方法,这两个方法都是无状态的中间操作,所以执行 filter 和 map 操作时,并没有进行任何的操作,而是分别创建了一个 Stage 来标识用户的每一次操作。
而通常情况下 Stream 的操作又需要一个回调函数,所以一个完整的 Stage 是由数据来源、操作、回调函数组成的三元组来表示。如下图所示,分别是 ReferencePipeline 的 filter 方法和 map 方法:
@Overridepublic final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {Objects.requireNonNull(predicate);return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {@Overridepublic void begin(long size) {downstream.begin(-1);}@Overridepublic void accept(P_OUT u) {if (predicate.test(u))downstream.accept(u);}};}};}@Override@SuppressWarnings("unchecked")public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {Objects.requireNonNull(mapper);return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<R> sink) {return new Sink.ChainedReference<P_OUT, R>(sink) {@Overridepublic void accept(P_OUT u) {downstream.accept(mapper.apply(u));}};}};}new StatelessOp 将会调用父类 AbstractPipeline 的构造函数,这个构造函数将前后的 Stage 联系起来,生成一个 Stage 链表:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {if (previousStage.linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);previousStage.linkedOrConsumed = true;previousStage.nextStage = this;// 将当前的 stage 的 next 指针指向之前的 stagethis.previousStage = previousStage;// 赋值当前 stage 当全局变量 previousStage this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);this.sourceStage = previousStage.sourceStage;if (opIsStateful())sourceStage.sourceAnyStateful = true;this.depth = previousStage.depth + 1;}因为在创建每一个 Stage 时,都会包含一个 opWrapSink() 方法,该方法会把一个操作的具体实现封装在 Sink 类中,Sink 采用(处理 -> 转发)的模式来叠加操作。
当执行 max 方法时,会调用 ReferencePipeline 的 max 方法,此时由于 max 方法是终结操作,所以会创建一个 TerminalOp 操作,同时创建一个 ReducingSink,并且将操作封装在 Sink 类中。
@Overridepublic final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) {return reduce(BinaryOperator.maxBy(comparator));}最后,调用 AbstractPipeline 的 wrapSink 方法,该方法会调用 opWrapSink 生成一个 Sink 链表,Sink 链表中的每一个 Sink 都封装了一个操作的具体实现。
@Override@SuppressWarnings("unchecked")final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {Objects.requireNonNull(sink);for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {sink = p.opWrapSink(p.previousStage.combinedFlags, sink);}return (Sink<P_IN>) sink;}当 Sink 链表生成完成后,Stream 开始执行,通过 spliterator 迭代集合,执行 Sink 链表中的具体操作。
@Overridefinal <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {Objects.requireNonNull(wrappedSink);if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {wrappedSink.begin(spliterator.getExactSizeIfKnown());spliterator.forEachRemaining(wrappedSink);wrappedSink.end();}else {copyIntoWithCancel(wrappedSink, spliterator);}}Java8 中的 Spliterator 的 forEachRemaining 会迭代集合,每迭代一次,都会执行一次 filter 操作,如果 filter 操作通过,就会触发 map 操作,然后将结果放入到临时数组 object 中,再进行下一次的迭代。完成中间操作后,就会触发终结操作 max。
这就是串行处理方式了,那么 Stream 的另一种处理数据的方式又是怎么操作的呢?
2.4、Stream 并行处理
Stream 处理数据的方式有两种,串行处理和并行处理。要实现并行处理,我们只需要在例子的代码中新增一个 Parallel() 方法,代码如下所示:
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");String maxLenStartWithZ = names.stream().parallel().filter(name -> name.startsWith(" 张 ")).mapToInt(String::length).max().toString();Stream 的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用 TerminalOp 的 evaluateParallel 方法进行并行处理。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {assert getOutputShape() == terminalOp.inputShape();if (linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);linkedOrConsumed = true;return isParallel()? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())): terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));}这里的并行处理指的是,Stream 结合了 ForkJoin 框架,对 Stream 处理进行了分片,Splititerator 中的 estimateSize 方法会估算出分片的数据量。
ForkJoin 框架和估算算法,在这里我就不具体讲解了,如果感兴趣,你可以深入源码分析下该算法的实现。
通过预估的数据量获取最小处理单元的阀值,如果当前分片大小大于最小处理单元的阀值,就继续切分集合。每个分片将会生成一个 Sink 链表,当所有的分片操作完成后,ForkJoin 框架将会合并分片任何结果集。
3、合理使用 Stream
看到这里,你应该对 Stream API 是如何优化集合遍历有个清晰的认知了。Stream API 用起来简洁,还能并行处理,那是不是使用 Stream API,系统性能就更好呢?通过一组测试,我们一探究竟。
我们将对常规的迭代、Stream 串行迭代以及 Stream 并行迭代进行性能测试对比,迭代循环中,我们将对数据进行过滤、分组等操作。分别进行以下几组测试:
- 多核 CPU 服务器配置环境下,对比长度 100 的 int 数组的性能;
- 多核 CPU 服务器配置环境下,对比长度 1.00E+8 的 int 数组的性能;
- 多核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能;
- 单核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能。
由于篇幅有限,我这里直接给出统计结果,你也可以自己去验证一下,具体的测试代码可以在Github上查看。通过以上测试,我统计出的测试结果如下(迭代使用时间):
- 常规的迭代
- Stream 并行迭代 < 常规的迭代
- Stream 并行迭代 < 常规的迭代
- 常规的迭代
通过以上测试结果,我们可以看到:在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。所以我们在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。
用事实说话,我们看到其实使用 Stream 未必可以使系统性能更佳,还是要结合应用场景进行选择,也就是合理地使用 Stream。
4、总结
纵观 Stream 的设计实现,非常值得我们学习。从大的设计方向上来说,Stream 将整个操作分解为了链式结构,不仅简化了遍历操作,还为实现了并行计算打下了基础。
从小的分类方向上来说,Stream 将遍历元素的操作和对元素的计算分为中间操作和终结操作,而中间操作又根据元素之间状态有无干扰分为有状态和无状态操作,实现了链结构中的不同阶段。
在串行处理操作中,Stream 在执行每一步中间操作时,并不会做实际的数据操作处理,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过 Java8 中的 Spliterator 迭代器进行数据处理;此时,每执行一次迭代,就对所有的无状态的中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
在并行处理操作中,Stream 对中间操作基本跟串行处理方式是一样的,但在终结操作中,Stream 将结合 ForkJoin 框架对集合进行切片处理,ForkJoin 框架将每个切片的处理结果 Join 合并起来。最后就是要注意 Stream 的使用场景。
5、思考题
这里有一个简单的并行处理案例,请你找出其中存在的问题。
// 使用一个容器装载 100 个数字,通过 Stream 并行处理的方式将容器中为单数的数字转移到容器 parallelListList<Integer> integerList = new ArrayList<Integer>();for (int i = 0; i < 100; i++) {integerList.add(i);}List<Integer> parallelList = new ArrayList<Integer>();integerList.stream().parallel().filter(i -> i % 2 == 1).forEach(i -> parallelList.add(i));相关文章:
06 - Stream如何提高遍历集合效率?
前面我们讲过 List 集合类,那我想你一定也知道集合的顶端接口 Collection。 在 Java8 中,Collection 新增了两个流方法,分别是 Stream() 和 parallelStream()。 1、什么是 Stream? 现在很多大数据量系统中都存在分表分库的情况…...
【Spring】使用注解的方式获取Bean对象(对象装配)
目录 一、了解对象装配 1、属性注入 1.1、属性注入的优缺点分析 2、setter注入 2.1、setter注入的优缺点分析 3、构造方法注入 3.1、构造方法注入的优缺点 二、Resource注解 三、综合练习 上一个博客中,我们了解了使用注解快速的将对象存储到Spring中&#x…...
[webpack] 基本配置 (一)
文章目录 1.基本介绍2.功能介绍3.简单使用3.1 文件目录和内容3.2 下载依赖3.3 启动webpack 4.基本配置4.1 五大核心概念4.2 基本使用 1.基本介绍 Webpack 是一个静态资源打包工具。它会以一个或多个文件作为打包的入口, 将我们整个项目所有文件编译组合成一个或多个文件输出出去…...

模板学堂|SQL数据集动态参数使用场景及功能详解
DataEase开源数据可视化分析平台于2022年6月正式发布模板市场(https://dataease.io/templates/)。模板市场旨在为DataEase用户提供专业、美观、拿来即用的仪表板模板,方便用户根据自身的业务需求和使用场景选择对应的仪表板模板&a…...

Wlan——射频和天线基础知识
目录 射频的介绍 射频和Wifi 射频的相关基础概念 射频的传输 信号功率的单位 射频信号传输行为 天线的介绍 天线的分类 天线的基本原理 天线的参数 射频的介绍 射频和Wifi 什么是射频 从射频发射器产生一个变化的电流(交流电),通过…...

前端实习周记第三周周记
第二周总结 第二周主要是做了一些PC端细节内容。大的地方改的不多,但是小的细节蛮多。 值得一提的是,第二周做的微信小程序,改了很多逻辑。改逻辑需要与后端进行联调,收获很大,思路也愈发清楚。 记录做了什么是好习…...

Android 13 Launcher界面——移除Launcher的删除和卸载功能
目录 一.背景 二.将卸载功能进行屏蔽 三.将移除功能屏蔽 四.将Remove按钮与Uninstall按钮屏蔽...
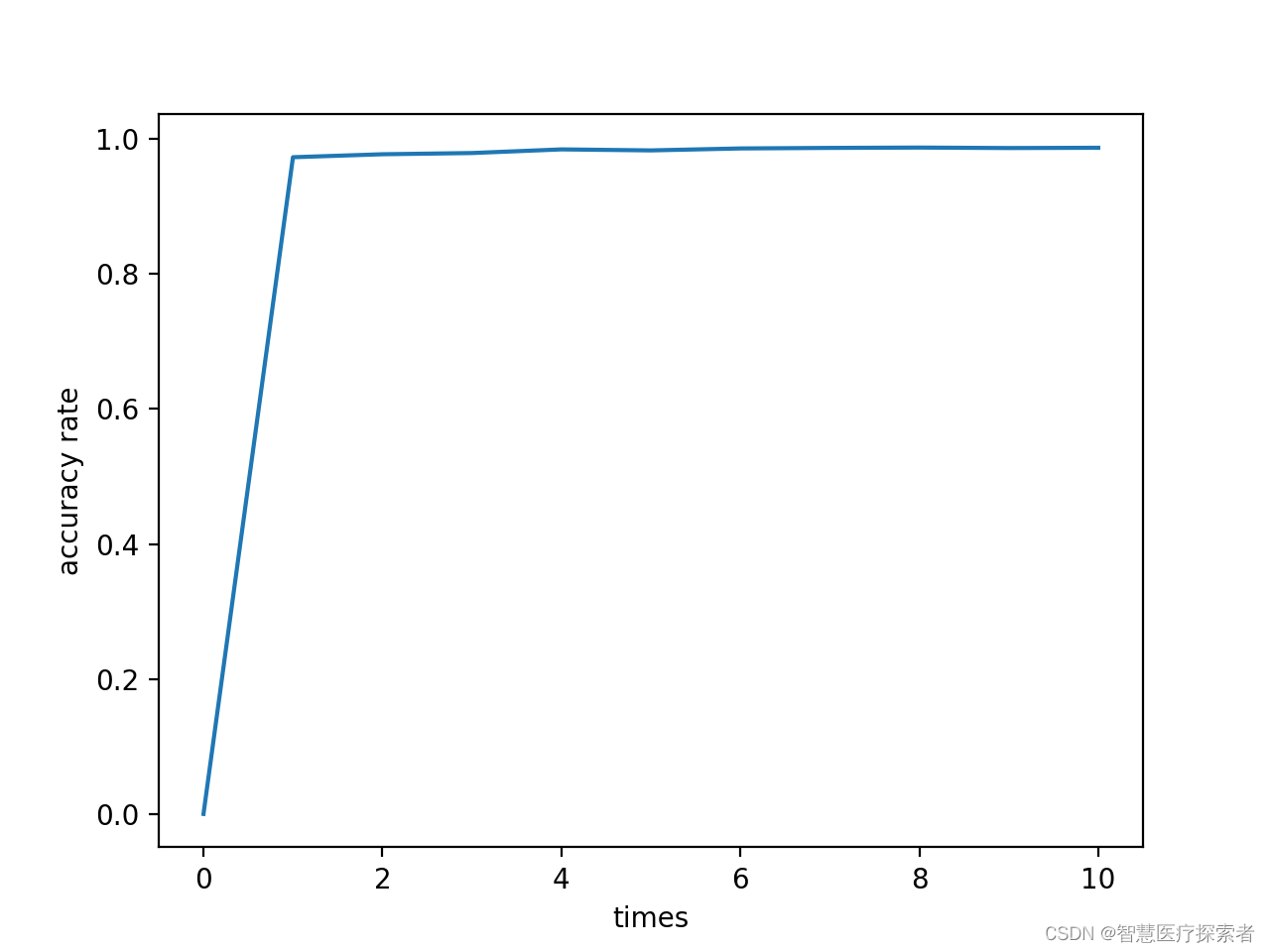
深度学习:使用卷积神经网络CNN实现MNIST手写数字识别
引言 本项目基于pytorch构建了一个深度学习神经网络,网络包含卷积层、池化层、全连接层,通过此网络实现对MINST数据集手写数字的识别,通过本项目代码,从原理上理解手写数字识别的全过程,包括反向传播,梯度…...
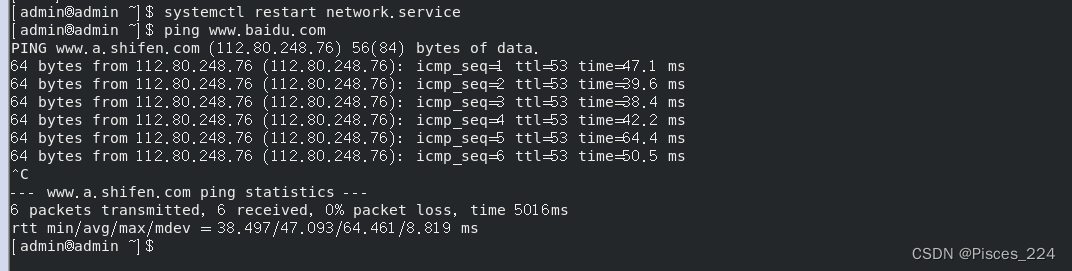
docker search 镜像报错: connect: no route to host (桥接模式配置静态IP)
如下 原因 可能有多种: ① 没有开放防火墙端口 ② ip地址配置有误 解决 我是因为虚拟机采用了桥接模式,配置静态ip地址有问题。 先确认虚拟机采用的是 桥接模式,然后启动虚拟机。 1、打开命令行,输入下面指令,打开…...

【VUE】[Violation] Added non-passive event listener to a scroll-blocking...
环境 chrome: 115.0.5790.170vue: ^3.3.4element-plus: ^2.3.4vite: ^4.4.7 问题 [Violation] Added non-passive event listener to a scroll-blocking <某些> 事件. Consider marking event handler as passive to make the page more responsive. See <URL> …...

runit-docker中管理多个服务
runit-docker中管理多个服务 介绍Runit, systemctl和supervisor是三种不同的服务管理工具区别runit优点程序构成快速开始runit实现服务退出执行指定操作runit监管服务打印日志到syslogrunit监管服务后台运行runit监管服务一些错误总结 介绍 runit 是一个轻量级的、稳定的、跨平…...

Intune 应用程序管理
由于云服务提供了增强的安全性、稳定性和灵活性,越来越多的组织正在采用基于云的解决方案来满足他们的需求。这正是提出Microsoft Endpoint Manager等解决方案的原因,它结合了SCCM和Microsoft Intune,以满足本地和基于云的端点管理。 与 Int…...
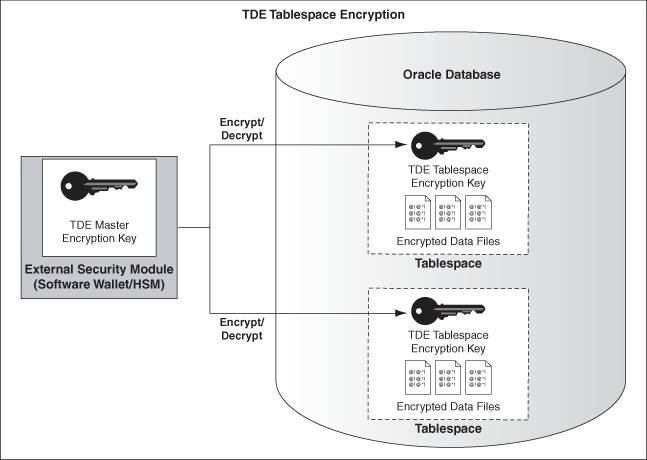
Oracle DB 安全性 : TDE HSM TCPS Wallet Imperva
• 配置口令文件以使用区分大小写的口令 • 对表空间进行加密 • 配置对网络服务的细粒度访问 TCPS 安全口令支持 Oracle Database 11g中的口令: • 区分大小写 • 包含更多的字符 • 使用更安全的散列算法 • 在散列算法中使用salt 用户名仍是Oracle 标识…...
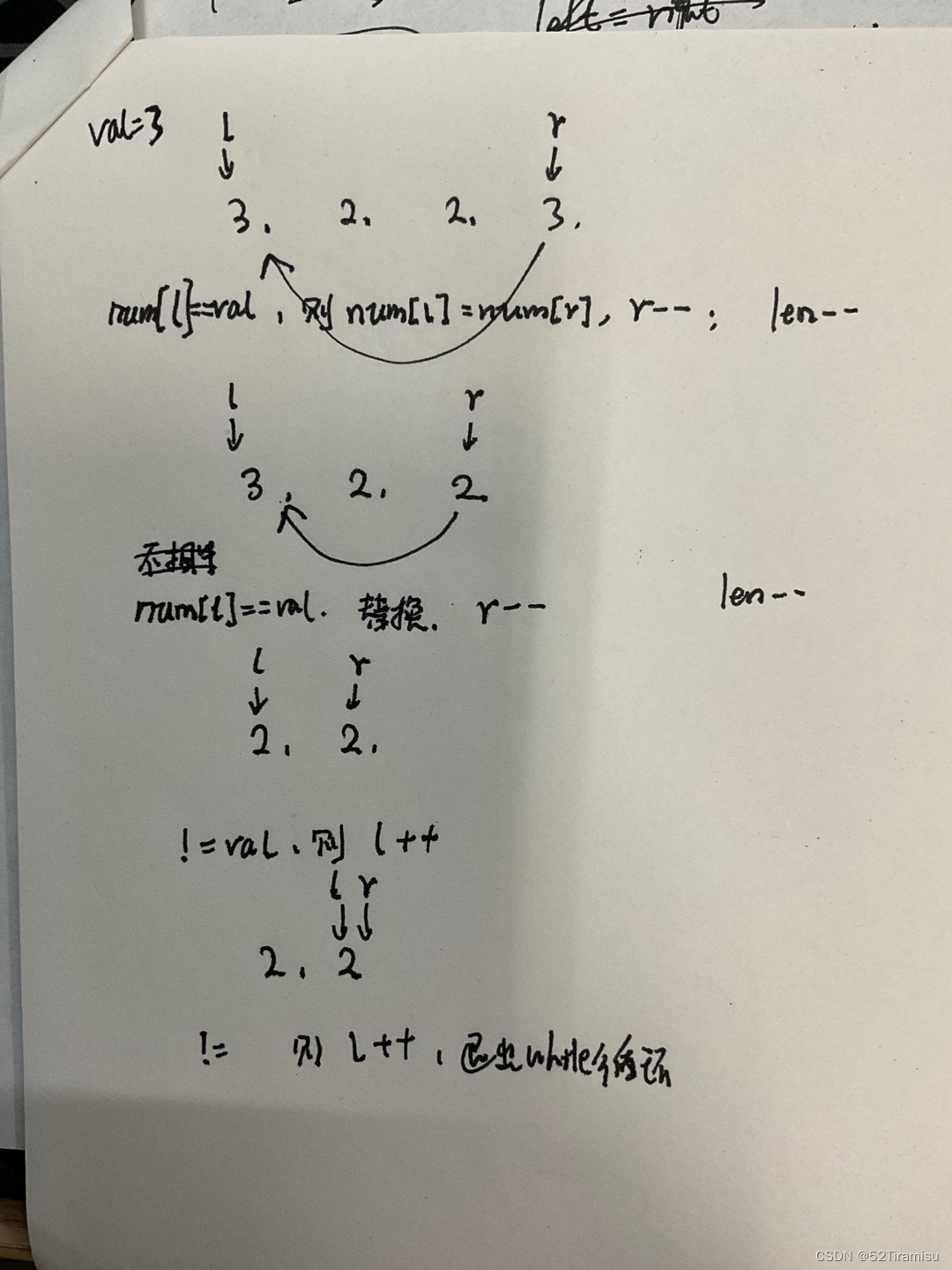
leetcode27—移除元素
思路: 参考26题目双指针的思想,只不过这道题不是快慢指针。 看到示例里面数组是无序的,也就是说后面的元素也是可能跟给定 val值相等的,那么怎么处理呢。就想到了从前往后遍历,如果left对应的元素 val时,…...
/flask-sqlalchemy)
flask---》更多查询方式/连表查询/原生sql(django-orm如何执行原生sql)/flask-sqlalchemy
更多查询方式 #1 查询: filer:写条件 filter_by:等于的值 # 查询所有 是list对象 res session.query(User).all() # 是个普通列表 print(type(res)) print(len(res))# 2 只查询某几个字段 # select name as xx,email from user; res session.…...
116版本内核UI定制)
Chromium内核浏览器编译记(三)116版本内核UI定制
转载请注明出处:https://blog.csdn.net/kong_gu_you_lan/article/details/132180843?spm1001.2014.3001.5501 本文出自 容华谢后的博客 往期回顾: Chromium内核浏览器编译记(一)踩坑实录 Chromium内核浏览器编译记(…...
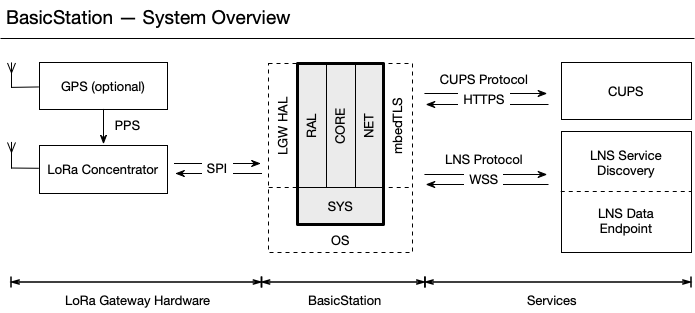
LoRaWan网关设计架构介绍
LoRa 数据包转发器是在基于 LoRa 的网关(带或不带 GPS)主机上运行的程序。它将集中器(上行链路)接收到的 RF 数据包通过安全的 IP 链路转发到LoRaWAN 网络服务器( LNS )。它还通过相同的安全 IP 将 LNS(下行链路)发送的 RF 数据包传输到一台或多台设备。此外,它还可以传…...
)
vue 全局状态管理(简单的store模式、使用Pinia)
目录 为什么使用状态管理简单的store模式服务器渲染(SSR) pinia简介示例1. 定义一个index.ts文件2. 在main.ts中引入3. 定义4. 使用 为什么使用状态管理 多个组件可能会依赖同一个状态时,我们有必要抽取出组件内的共同状态集中统一管理&…...

ORACLE和MYSQL区别
1,Oracle没有offet,limit,在mysql中我们用它们来控制显示的行数,最多的是分页了。oracle要分页的话,要换成rownum。 2,oracle建表时,没有auto_increment,所有要想让表的一个字段自增,…...
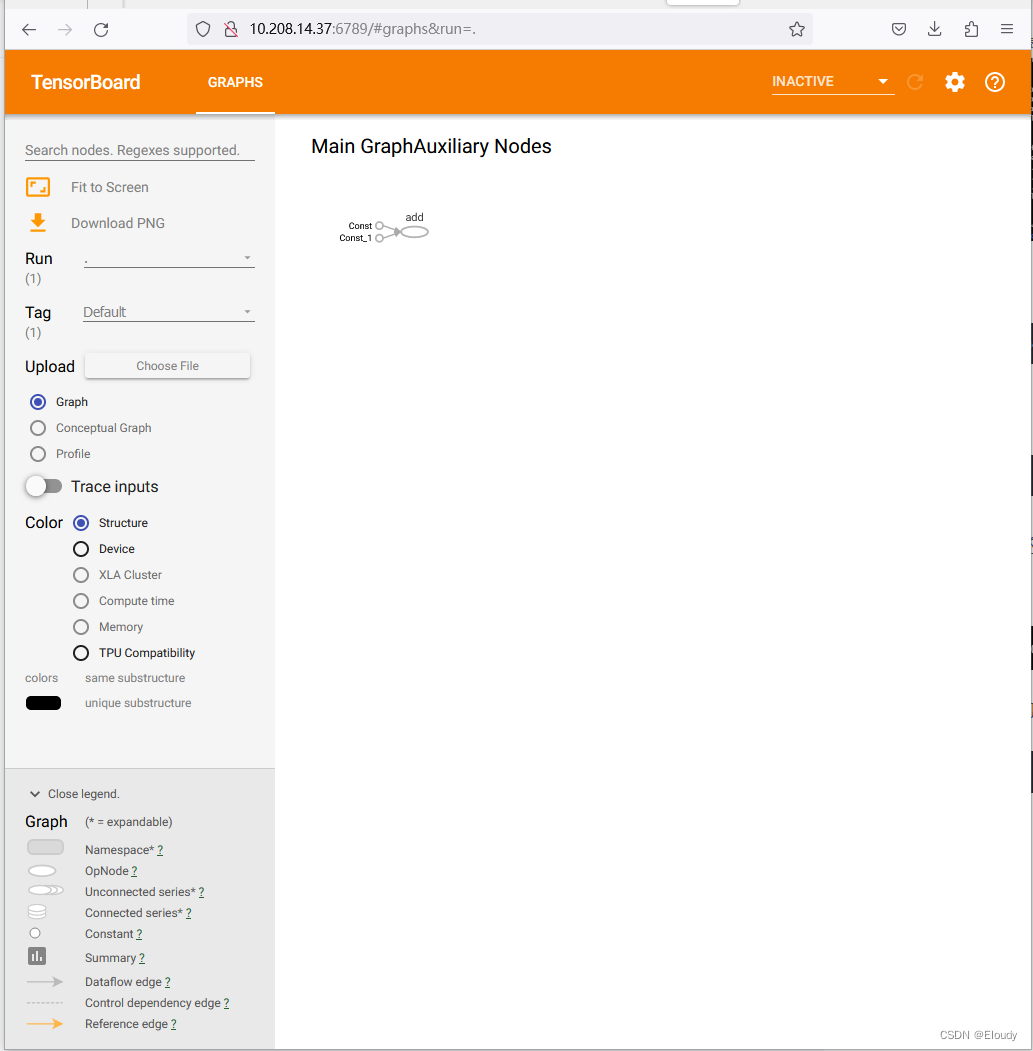
tensorflow 1.14 的 demo 02 —— tensorboard 远程访问
tensorflow 1.14.0, 提供远程访问 tensorboard 服务的方法 第一步生成 events 文件: 在上一篇demo的基础上加了一句,如下, tf.summary.FileWriter("./tmp/summary", graphsess1.graph) hello_tensorboard_remote.py …...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...
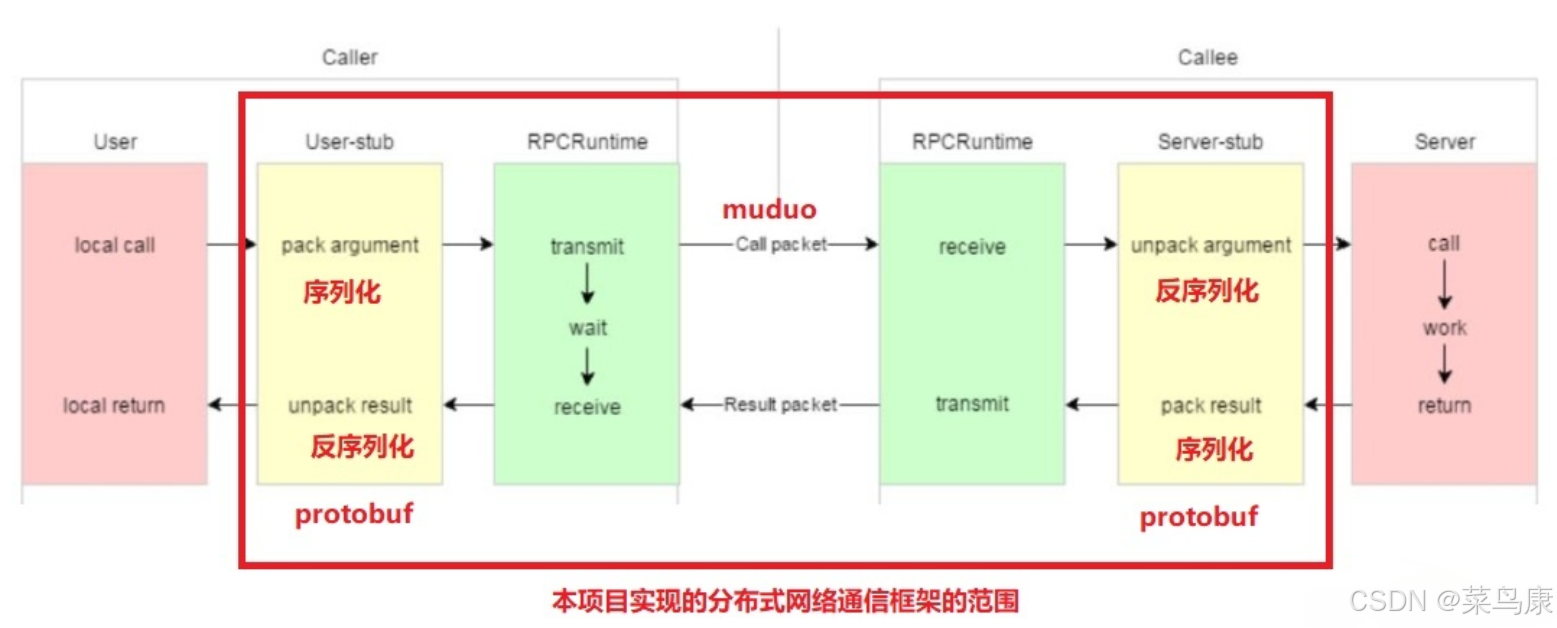
C++实现分布式网络通信框架RPC(2)——rpc发布端
有了上篇文章的项目的基本知识的了解,现在我们就开始构建项目。 目录 一、构建工程目录 二、本地服务发布成RPC服务 2.1理解RPC发布 2.2实现 三、Mprpc框架的基础类设计 3.1框架的初始化类 MprpcApplication 代码实现 3.2读取配置文件类 MprpcConfig 代码实现…...
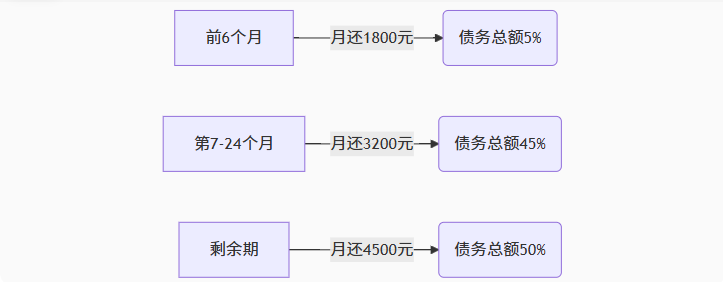
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...