Pytorch量化之Post Train Static Quantization(训练后静态量化)
使用Pytorch训练出的模型权重为fp32,部署时,为了加快速度,一般会将模型量化至int8。与fp32相比,int8模型的大小为原来的1/4, 速度为2~4倍。
Pytorch支持三种量化方式:
- 动态量化(Dynamic Quantization): 只量化权重,激活在推理过程中进行量化
- 静态量化(Static Quantization): 量化权重和激活
- 量化感知训练(Quantization Aware Training,QAT): 插入量化算子后进行训练,主要在静态量化精度不满足需求时进行。
大多数情况下,我们只需要进行静态量化,少数情况下在量化感知训练不满足时使用QAT进行微调。所以本篇只重点讲静态量化,并且理论部分先略过(后面再专门总结),只关注实操。
注:下面的代码是在pytorch1.10下,后面Pytorch对量化的接口有调整
官方文档:Quantization — PyTorch 1.10 documentation
动态模式(Eager Mode)与静态模式(fx graph)
Pytorch支持用2种方式量化,一种是动态图模式,也是我们日常使用Pytorch训练所使用的方式,使用这种方式量化需要自己手动修改网络结构,在支持量化的算子前、后插入量化节点,优点是方便调试。静态模式则是由pytorch自动在计算图中插入量化节点,不需要手动修改网络。
网络上大部分的教程都是基于静态模式,这种方式比较大的问题就是需要手动修改网络结构,官方教程里的网络是属于demo型, 其中的QuantStub和DeQuantStub就分别是量化和反量化的节点:
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):def __init__(self):super(M, self).__init__()# QuantStub converts tensors from floating point to quantizedself.quant = torch.quantization.QuantStub()self.conv = torch.nn.Conv2d(1, 1, 1)self.relu = torch.nn.ReLU()# DeQuantStub converts tensors from quantized to floating pointself.dequant = torch.quantization.DeQuantStub()def forward(self, x):# manually specify where tensors will be converted from floating# point to quantized in the quantized modelx = self.quant(x)x = self.conv(x)x = self.relu(x)# manually specify where tensors will be converted from quantized# to floating point in the quantized modelx = self.dequant(x)return x
Pytorch对于很多网络层是不支持量化的(比如很常用的Prelu),如果我们用这种方式,我们就必须在这些不支持的层前面插入DeQuantStub,然后在支持的层前面插入QuantStub。笔者体验下来,体验很差,个人觉得不太实用,会破坏原来的网络结构。
而静态图模式,我们只需要调用Pytorch提供的接口将原模型转换一下即可,不需要修改原来的网络结构文件,个人认为实用性更强。

静态模式量化
1. 载入fp32模型,并转成fx graph
其中量化参数有‘fbgemm’和‘qnnpack’两种,前者在x86运行,后者在arm运行。
model_fp32 = torch.load(xxx)
model_fp32_quantize = copy.deepcopy(model_fp32)
qconfig_dict = {"": torch.quantization.get_default_qconfig('fbgemm')}
model_fp32_quantize.eval()
# preparemodel_prepared = quantize_fx.prepare_fx(model_fp32_quantize, qconfig_dict)
model_prepared.eval()
2.读取量化数据,标定(Calibration)量化参数
标定的过程就是使用模型推理量化图片,然后统计权重和激活分布,从而得到量化参数。量化图片一般来源于训练集(几百张左右,根据测试情况调整)。量化图片可以通过Pytorch的Dataloader读取,也可以直接自行实现读图片然后送入网络。
### 使用dataloader读取
for i, (data, label) in enumerate(train_loader):data = data.to(torch.device("cpu:0"))outputs = model_prepared(data)print("calibrating {}".format(i))if i > 1000:break
3. 转换为量化模型并保存
quantized_model = quantize_fx.convert_fx(model_prepared)
torch.jit.save(torch.jit.script(quantized_model), "quantized_model.pt")
速度测试
量化后的模型使用方法与fp32模型一样:
import torch
import cv2
import numpy as np
torch.set_num_threads(1)fused_model = torch.jit.load("jit_model.pt")
fused_model.eval()
fused_model.to(torch.device("cpu:0"))img = cv2.imread("./1.png")
img_fp32 = img.astype(np.float32)
img_fp32 = (img_fp32-127.5) / 127.5
input = torch.from_numpy(img).permute(2, 0, 1).unsqueeze(0).float()def speed_test(model, input):# warm upfor i in range(10):model(input)import timestart = time.time()for i in range(100):model(input)end = time.time()print("model time: ", (end-start)/100)time.sleep(10)# quantized model
quantized_model= torch.jit.load("quantized_model.pt")
quantized_model.eval()
quantized_model.to(torch.device("cpu:0"))speed_test(fused_model, input)
speed_test(quantized_model, input)
实测fp32模型单核运行120ms, 量化后47ms
结语
本文介绍了fx graph模式下的Pytorch的PTSQ方法,并实测了一个模型,效果还比较不错。

相关文章:
Pytorch量化之Post Train Static Quantization(训练后静态量化)
使用Pytorch训练出的模型权重为fp32,部署时,为了加快速度,一般会将模型量化至int8。与fp32相比,int8模型的大小为原来的1/4, 速度为2~4倍。 Pytorch支持三种量化方式: 动态量化(Dynamic Quantization&…...

Sql奇技淫巧之EXIST实现分层过滤
在这样一个场景,我 left join 了很多张表,用这些表的不同列来过滤,看起来非常合理 但是出现的问题是 left join 其中一张或多张表出现了笛卡尔积,且无法消除 FUNCTION fun_get_xxx_helper(v_param_1 VARCHAR2,v_param_2 VARCHAR2…...

Linux下升级jdk1.8小版本
先输入java -version 查看是否安装了jdk java -version (1)如果没有返回值,直接安装新的jdk即可。 (2)如果有返回值,例如: java version "1.8.0_251" Java(TM) SE Runtime Enviro…...

【Mysql】数据库基础与基本操作
🌇个人主页:平凡的小苏 📚学习格言:命运给你一个低的起点,是想看你精彩的翻盘,而不是让你自甘堕落,脚下的路虽然难走,但我还能走,比起向阳而生,我更想尝试逆风…...

87 | Python人工智能篇 —— 机器学习算法 决策树
本教程将深入探讨决策树的基本原理,包括特征选择方法、树的构建过程以及剪枝技术,旨在帮助读者全面理解决策树算法的工作机制。同时,我们将使用 Python 和 scikit-learn 库演示如何轻松地实现和应用决策树,以及如何对结果进行可视化。无论您是初学者还是有一定机器学习经验…...
【计算机视觉】干货分享:Segmentation model PyTorch(快速搭建图像分割网络)
一、前言 如何快速搭建图像分割网络? 要手写把backbone ,手写decoder 吗? 介绍一个分割神器,分分钟搭建一个分割网络。 仓库的地址: https://github.com/qubvel/segmentation_models.pytorch该库的主要特点是&#…...
解析湖仓一体的支撑技术及实践路径
自2021年“湖仓一体”首次写入Gartner数据管理领域成熟度模型报告以来,随着企业数字化转型的不断深入,“湖仓一体”作为新型的技术受到了前所未有的关注,越来越多的企业视“湖仓一体” 为数字化转型的重要基础设施。 01 数据平台的发展历程…...
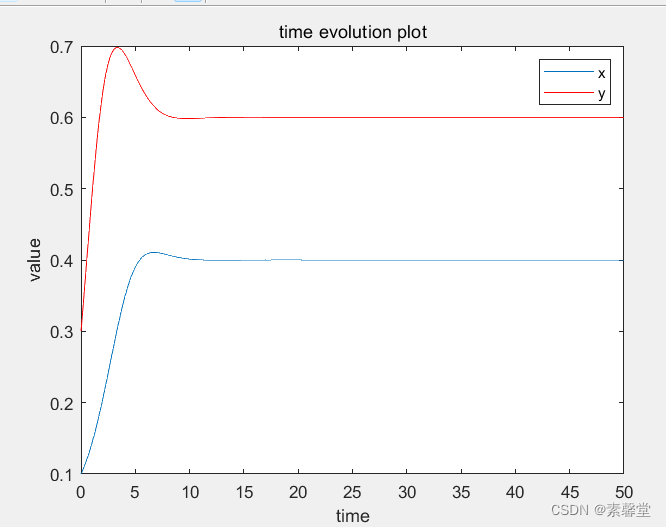
40.利用欧拉法求解微分方程组(matlab程序)
1.简述 求解微分方程的时候,如果不能将求出结果的表达式,则可以对利用数值积分对微分方程求解,获取数值解。欧拉方法是最简单的一种数值解法。前面介绍过MATLAB实例讲解欧拉法求解微分方程,今天实例讲解欧拉法求解一阶微分方程组。…...

OpenAI-Translator 实战总结
最近在极客时间学习《AI 大模型应用开发实战营》,自己一边跟着学一边开发了一个进阶版本的 OpenAI-Translator,在这里简单记录下开发过程和心得体会,供有兴趣的同学参考 功能概览 通过openai的chat API,实现一个pdf翻译器实现一个…...
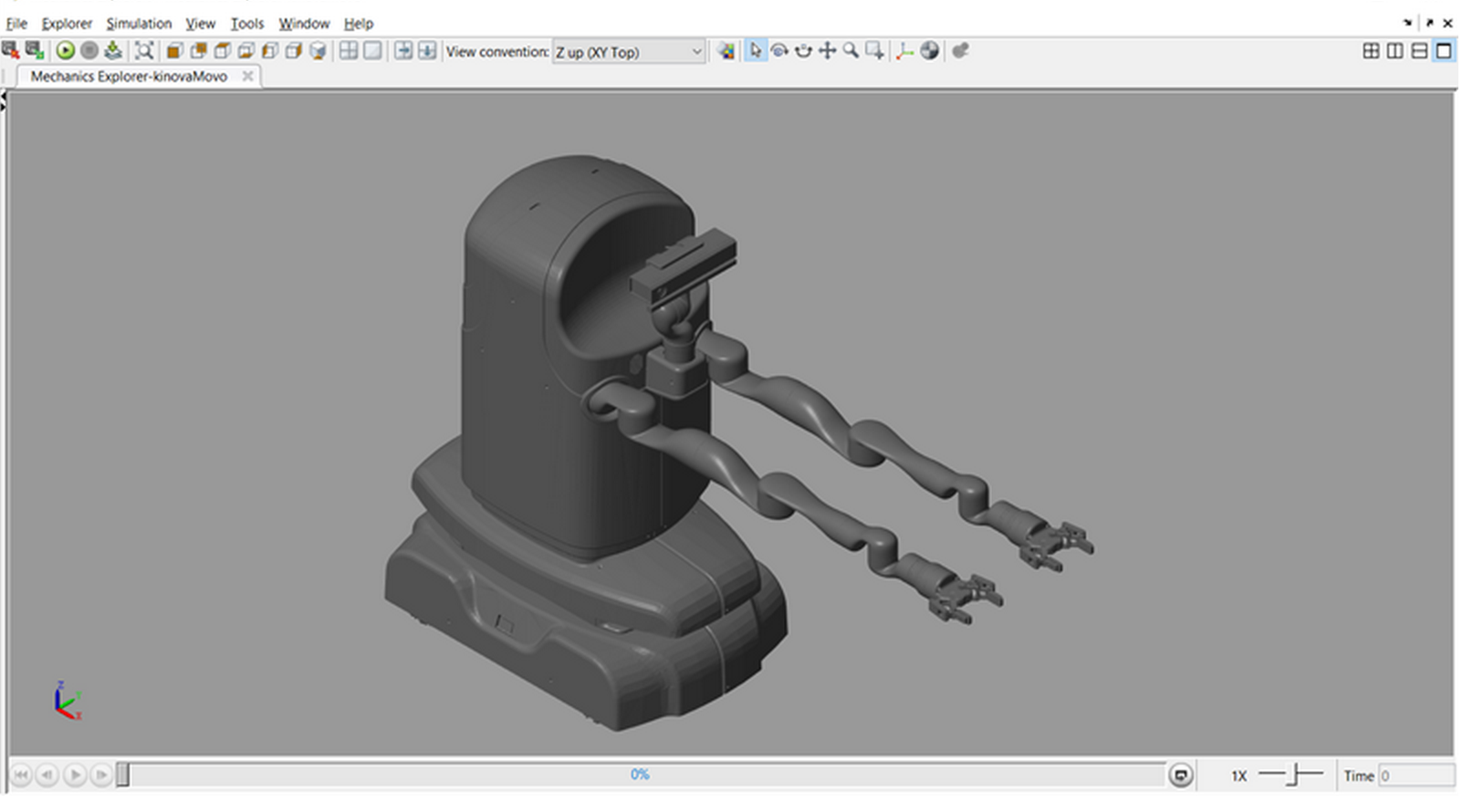
【工业机器人】用于轨迹规划和执行器分析的机械手和移动机器人模型(MatlabSimulink)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

开源在线文档服务OnlyOffice
开源在线文档服务OnlyOffice应用启动与示例运行 - 掘金 ONLYOFFICE API 文档 - Example - IDEA运行Java示例 | ONLYOFFICE中文网 NEXTCLOUDonlyoffice的搭建和使用_nextcloud onlyoffice_莫冲的博客-CSDN博客 OnlyOffice java 部署使用,文件流方式 预览文件 | 言曌博…...

汽车基本常识
目录 电源KL30KL15 零部件简称 电源 KL30 KL15 零部件简称 VCU:整车控制器 直接网络管理节点 CDU:充电系统控制器 MCU:电机控制器 TCU:变速箱控制器 ABS:防抱死系统 EPS:助力转向 T-Box:远程…...

百度资深PMO阚洁受邀为第十二届中国PMO大会演讲嘉宾
百度在线网络技术(北京)有限公司资深PMO阚洁女士受邀为由PMO评论主办的2023第十二届中国PMO大会演讲嘉宾,演讲议题:运筹于股掌之间,决胜于千里之外 —— 360斡旋项目干系人。大会将于8月12-13日在北京举办,…...

为什么C++有多种整型?
C中有多种整型是为了满足不同的需求,提供更灵活和高效的整数表示方式。不同的整型具有不同的字节大小、范围和精度,可以根据应用的需求选择合适的整型类型。以下是一些原因解释为什么C有多种整型: 内存和性能优化:不同的整型在内存…...
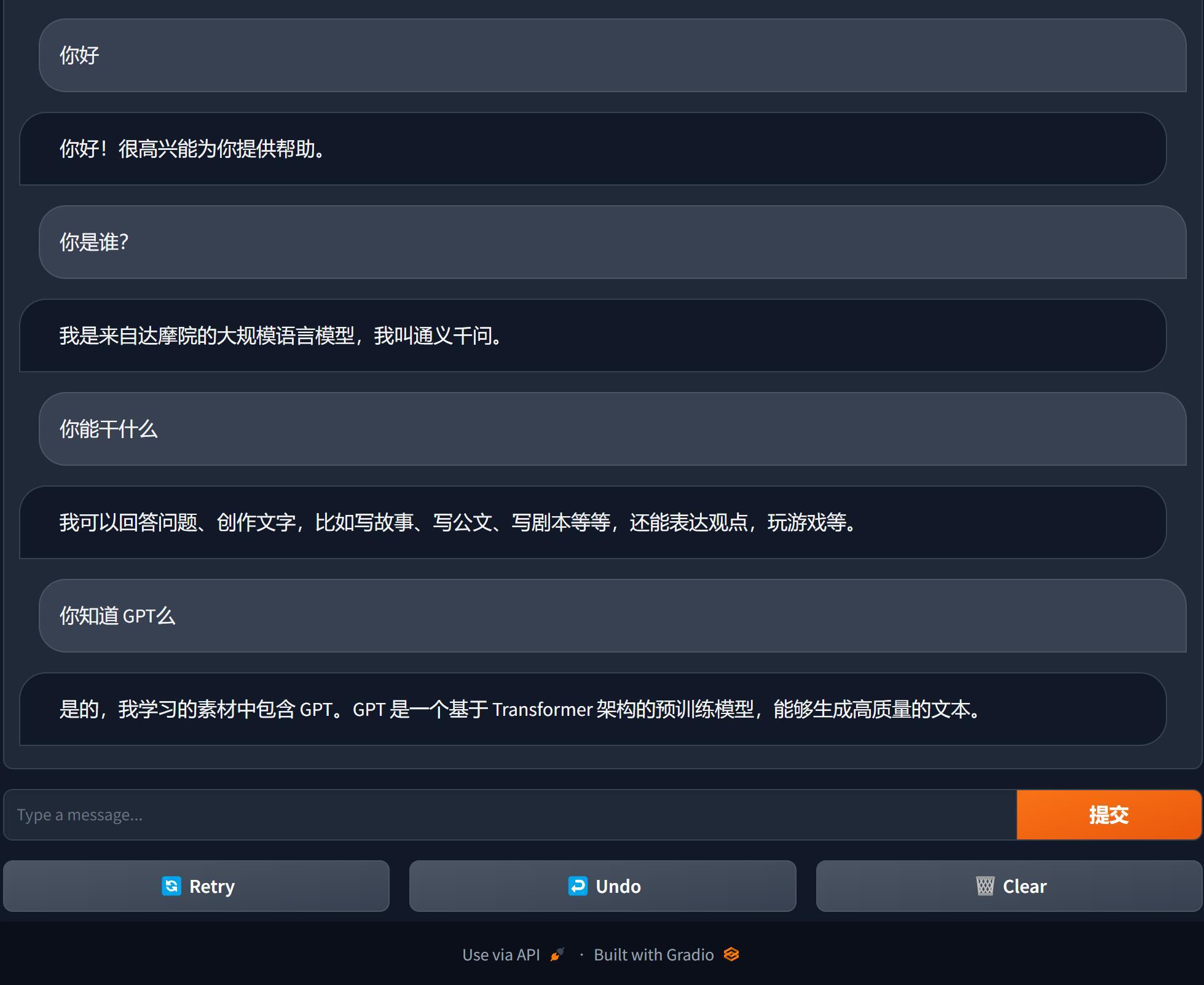
玩一玩通义千问Qwen开源版,Win11 RTX3060本地安装记录!
大概在两天前,阿里做了一件大事儿。 就是开源了一个低配版的通义千问模型--通义千问-7B-Chat。 这应该是国内第一个大厂开源的大语言模型吧。 虽然是低配版,但是在各类测试里面都非常能打。 官方介绍: Qwen-7B是基于Transformer的大语言模…...

oracle积累增量和差异增量
积累增量和差异增量: 对于 RMAN 来说,积累增量备份和差异增量备份都是增量备份的一种形式,它们之间的区别在于备份的范围和备份集的方式。 积累增量备份:在进行积累增量备份时,RMAN 会备份自最后一次完全备份或增量备…...
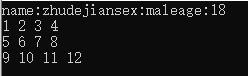
利用C++nlohmann库解析json文件
json文件示例: 代码运行环境VS2019 一、git下载nlohmann库文件源代码 源代码文件目录 二、利用VS2019新建工程,并配置项目属性 配置VC目录---包含目录 三、项目源代码 #include <iostream> #include <fstream> #include <nlohmann/jso…...

OpenCV 中的光流 (C++/Python)
什么是光流? 光流是一项视频中两个连续帧之间每像素运动估计的任务。基本上,光流任务意味着计算像素的位移矢量作为两个相邻图像之间的对象位移差。光流的主要思想是估计物体由其运动或相机运动引起的位移矢量。 理论基础 假设我们有一个灰度图像——具有像素强度的矩阵。我…...
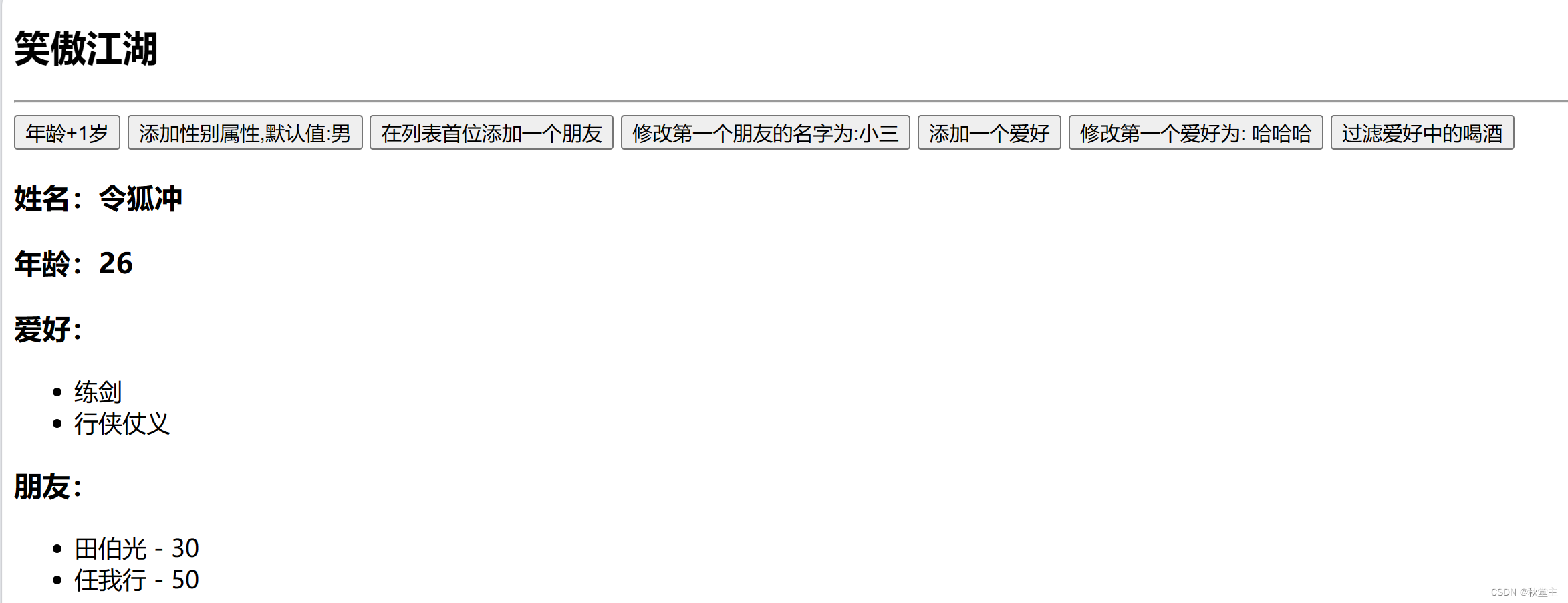
第9集丨Vue 江湖 —— 监测数据原理
目录 一、修改数据时的一个问题1.1 现象一1.2 现象二 二、Vue监测数据原理2.1 模拟一个数据监测2.2 数据劫持2.3 Vue.set()/vm.$set()2.4 基本原理2.4.1 如何监测对象中的数据?2.4.2 如何监测数组中的数据?2.4.3 修改数组中的某个元素 2.5 案例2.5.1 需求功能2.5.2 实现 一、…...

【YOLO】替换骨干网络为轻量级网络MobileNet3
替换骨干网络为轻量级网络MobileNet_v3 上一章 模型网络结构解析&增加小目标检测 文章目录 替换骨干网络为轻量级网络MobileNet_v3前言一、MobileNetV3介绍二、MobileNetV2&MobileNetV3三、MobileNetV3网络结构1. 结构查看2. 查看每层featuremap大小三、YOLOV5替换骨干…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...