NOSQL——redis的安装,配置与简单操作
目录
一、缓存的相关知识
1)缓存的概念
2)系统缓存
buffer与cache:
3)缓存保存位置及分层结构
DNS缓存
应用层缓存
数据层缓存
分布式缓存服务:
数据库:
硬件缓存
二、关系型数据与非关系型数据库
1)关系型数据库
2)非关系型数据库
3)关系型数据库和非关系型数据库区别:
(1)数据存储方式不同
(2)扩展方式不同
(3)对事务性的支持不同
4)非关系型数据库产生背景
5)NOSQL 与 SQL的数据记录对比
三、redis的相关知识
1)redis的简介
2)redis的五大数据类型
3)redis的优缺点
Redis缺点
4)Redis的适用场景
5)Redis采用单线程的原因
6)redis运行速度快的原因
7)Redis与memcached比较
四、redis的安装配置
1)redis的源码编译安装
2)redis的服务管理
五、redis的命令工具
1)redis-cli:Redis 命令行工具
2)redis-benchmark 测试工具
(1)并发连接与100000 个请求处理性能测试
(2)数据包的存取的性能测试
(3) 键值对的创建速度测试
编辑
六、redis的简单操作
1)redis键值对的存取
2)redis键值列表的获取
(1)获取全部列表
(2)获取以某字符为开头任意长度的键
(3)获取以某字符为开头,后面为指定长度的键
添加测试数据:
3)判断键是否存在
4)删除键
5)查看键存储的数据类型
6)rename 重命名
7)renamenx 重命名
8)dbsize查看键数目
9)设置和清空密码
设置和查看密码
清空密码
七、Redis多数据库操作
1)多数据库间切换select
2)多数据库间移动数据
3)清除数据库内数据
八、redis的常见错误与解决方案
1)Redis常见运维故障
2)Redis故障排查
一、缓存的相关知识
1)缓存的概念
缓存是为了调节速度不一致的两个或多个不同的物质的速度,在中间对速度较慢的一方起到加速作用,比如CPU的一级、二级缓存是保存了CPU最近经常访问的数据,内存是保存CPU经常访问硬盘的数据,而且硬盘也有大小不一的缓存,甚至是物理服务器的raid 卡有也缓存,都是为了起到加速CPU 访问硬盘数据的目的,因为CPU的速度太快了,CPU需要的数据由于硬盘往往不能在短时间内满足CPU的需求,因此CPU缓存、内存、Raid 卡缓存以及硬盘缓存就在一定程度上满足了CPU的数据需求,即CPU 从缓存读取数据可以大幅提高CPU的工作效率
2)系统缓存
buffer与cache:
- buffer: 缓冲也叫写缓冲,一般用于写操作,可以将数据先写入内存再写入磁盘,buffer 一般用于写缓冲,用于解决不同介质的速度不一致的缓冲,先将数据临时写入到里自己最近的地方,以提高写入速度,CPU会把数据先写到内存的磁盘缓冲区,然后就认为数据已经写入完成看,然后由内核在后续的时间在写入磁盘,所以服务器突然断电会丢失内存中的部分数据
- cache: 缓存也叫读缓存,一般用于读操作,CPU读文件从内存读,如果内存没有就先从硬盘读到内存再读到CPU,将需要频繁读取的数据放在里自己最近的缓存区域,下次读取的时候即可快速读取
3)缓存保存位置及分层结构
互联网应用领域,缓存是服务响应速度提升的关键
- 用户层:浏览器DNS缓存,应用程序DNS缓存,操作系统DNS缓存客户端
- 代理层:CDN,反向代理缓存
- Web层:Web服务器缓存
- 应用层:页面静态化
- 数据层:分布式缓存,数据库
- 系统层:操作系统cache
- 物理层:磁盘cache, Raid Cache
DNS缓存
浏览器的DNS缓存默认为60秒,即60秒之内在访问同一个域名就不在进行DNS解析。
应用层缓存
Nginx、PHP等web服务可以设置应用缓存以加速响应用户请求,另外有些解释性语言,比如:PHP/Python/Java不能直接运行,需要先编译成字节码,但字节码需要解释器解释为机器码之后才能执行,因此字节码也是一种缓存,有时候还会出现程序代码上线后字节码没有更新的现象。所以一般上线新版前,需要先将应用缓存清理,再上线新版。
另外可以利用动态页面静态化技术,加速访问,比如:将访问数据库的数据的动态页面,提前用程序生成静态页面文件html 电商网站的商品介绍,评论信息非实时数据等皆可利用此技术实现
数据层缓存
分布式缓存服务:
- Redis
- Memcached
数据库:
- MySQL 查询缓存
- innodb缓存、MYISAM缓存
硬件缓存
- CPU缓存(L1的数据缓存和L1的指令缓存)、二级缓存、三级缓存
- 磁盘缓存:Disk Cache
- 磁盘阵列缓存:Raid Cache,可使用电池防止断电丢失数据
二、关系型数据与非关系型数据库
1)关系型数据库
- 关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录
- SQL语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作
- 主流的关系型数据库包括Oracle、 MySQL、SQL Server、Microsoft Access、 DB2、PostgreSQL 等
以上数据库在使用的时候必须先建库建表设计表结构,然后存储数据的时候按表结构去存,如果数据与表结构不匹配就会存储失败
2)非关系型数据库
- NoSQL(NoSQL=NotonlysQL),意思是“不仅仅是SQL",是非关系型数据库的总称。
- 除了主流的关系型数据库外的数据库,都认为是非关系型。
- 不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数(比如微信群聊里的文字、图片、视频、音乐等)。
- 主流的NOSQL 数据库有Redis、MongBD、 Hbase(分布式非关系型数据库,大数据使用)、Memcached、ElasticSearch(简称ES,索引型数据库)、TSDB(时续型数据库) 等
3)关系型数据库和非关系型数据库区别:
(1)数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式
- 关系型数据天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据
- 与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存储和提取方式的首要影响因素。(很容易切换数据类型,一个数据集当中有多种数据类型)
(2)扩展方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展。
- 要支持更多并发量,SQL数据库是纵向扩展,也就是说提高处理能力,使用速度更快速的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来克服。虽然SQI数据库有很大打展空间,但最终肯定会达到纵向扩展的上限。(数据一般存储在本地的文件系统中。读可以通过读写分离、负载均衡来分摊性能,但读写仍然很消耗IO性能)
- 而NoSQL数据库是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。(数据分布存储在不同服务器上,可以并发地读写,加快效率)
- 横向扩展:加服务器。(比较便宜)
- 纵向扩展:提高硬件配置,比如换更高性能的CPU、加CPU核数、硬盘、磁盘IO、内存条。(除硬盘外,其他需要停机才能加)
(3)对事务性的支持不同
- 如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事务原子性细粒度控制,并且易于回滚事务
- 虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面
- 非关系型数据库在事务的处理和稳定性方面,不如关系型数据库。但读写性能好、易于扩展,处理大数据方面占优势
关系型数据库:特别适合高事务性要求和需要控制执行计划的任务,事务细粒度控制更好
非关系型数据库:事务控制会稍显弱势,其价值点在于高扩展性和大数据量处理方面
4)非关系型数据库产生背景
可用于应对Web2.0纯动态网站类型的三高问题。
- High performance —— 对数据库高并发读写需求
- Hugestorage——对海量数据高效存储与访问需求
- HighScalability&&HighAvailability——对数据库高可扩展性与高可用性需求
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给web2.0的数据库发展带来新的思路。让关系型数据库关注在关系上和对数据的一致性保障,非关系型数据库关注在存储和高效率上。例如,在读写分离的MySQI数据库环境中,可以把经常访问的数据(即高热数据)存储在非关系型数据库中,提升访问速度。
5)NOSQL 与 SQL的数据记录对比
关系型数据库:
- 实例-->数据库-->表(table)-->记录行(row)、数据字段(column)
非关系型数据库:
- 实例-->数据库-->集合(collection) -->键值对(key-value)
- 非关系型数据库不需要手动建数据库和集合(表)。
三、redis的相关知识
1)redis的简介
Redis是一个开源、基于内存、使用C语言编写的key-value数据库,并提供了多种语言的API。它的数据结构十分丰富,主要可以用于数据库、缓存、分布式锁、消息队列等...
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率
- 若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;
- 若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力

2)redis的五大数据类型
基础数据类型包括:string(字符串)、list(列表,双向链表)、hash(散列,键值对集合)、set(集合,不重复)和sorted set也可以称为Zset(有序集合)
| 结构类型 | 结构存储的值 | 结构的读写能力 |
| String | 可以是字符串、整数、浮点数 | 对整个字符串或者字符串的其中一部分进行操作,对整数和浮点数执行自增或者自减操作 |
| list | 一个链表,链表上每个节点都包含了一个字符串 | 从链表的两端推入或者弹出元素:根据偏移量对链表进行修剪:读取单个或多个元素,根据值查找或者移除元素 |
| set | 包含字符串的无序收集器,并且被包含的每个字符串都是独一无二各不相同的 | 添加、获取、移除单个元素,检查一个元素是否存在与集合中,计算交集、并集、差集,从集合里面随机获取元素 |
| hash | 包含键值对的无序散列表 | 添加、获取、移除单个键值对,获取所有键值对 |
| zset | 字符串成员与浮点数分值之间的有序映射,元素的排列顺序由分值的大小决定 | 添加、获取、删除单个元素,根据分值范围或者成员来获取元素 |
3)redis的优缺点
(1)具有极高的数据读写速度: 数据读取的速度最高可达到110000 次/s,数据写入速度最高可达到81000次/s。
(2)支持的数据结构: key-value,支持丰富的数据类型:Strings、 Lists、Hashes、 Sets 及Sorted Sets 等数据类型操作。
- Strings 字符串型
- Lists 列表型
- Hashes 哈希(散列)
- Sets 无序集合
- Sorted Sets 有序集合(或称zsets)
(redis也可以做消息队列,可以通过Sorted Sets实现)
(3)支持数据的持久化: 可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性: Redis所有操作都是原子性的。(支持事务,所有操作都作为事务)
(5)支持数据备份: 即 master-salve 模式的数据备份。(支持主从复制)
Redis缺点
- 缓存和数据库双写一致性问题
- 缓存雪崩问题
- 缓存击穿问题
- 缓存的并发竞争问题
4)Redis的适用场景
- Redis作为基于内存运行的数据库,是一个高性能的缓存,一般应用在session缓存、 队列、排行榜、计数器、最近最热文章、最近最热评论、发布订阅等
- Redis适用于数据实时性要求高、数据存储有过期和淘汰特征的、不需要持久化或者只需要保证弱一致性、逻辑简单的场景
5)Redis采用单线程的原因
首先要明确的是Redis单线程指的是网络IO和键值对读写是由一个线程来完成的,但Redis持久化、集群数据等是由额外的线程执行的。了解Redis使用单线程之前可以先了解一下多线程的开销。
通常情况下,使用多线程可以增加系统吞吐率或者可以增加系统扩展性,但多线程通常会存在同时访问某些共享资源,为了保证访问共享资源的正确性,就需要有额外的机制进行保证,这个机制首先会带来一定的开销。其实对于多线程并发访问的控制一直是一个难点问题,如果没有精细的设计,比如说,只是简单地采用一个粗粒度互斥锁,就会出现不理想的结果。即使增加了线程,大部分线程也在等待获取访问共享资源的互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加
此外:
值得注意的是在Redis6.0中引入了多线程。在Redis6.0之前,从网络IO处理到实际的读写命令处理都是由单个线程完成的,但随着网络硬件的性能提升,Redis的性能瓶颈有可能会出现在网络IO的处理上,也就是说单个主线程处理网络请求的速度跟不上底层网络硬件的速度。针对此问题,Redis采用多个IO线程来处理网络请求,提高网络请求处理的并行度,但多IO线程只用于处理网络请求,对于读写命令,Redis仍然使用单线程处理!
6)redis运行速度快的原因
- Redis是基于内存的,绝大部分请求都是内存操作,十分的迅速
- Redis具有高效的底层数据结构,为优化内存,对每种类型基本都有两种底层实现方式
主要执行过程是单线程,避免了不必要的上下文切换和资源竞争,不存在多线程导致的CPU切换和锁的问题。
- IO多路复用机制:使其在网络IO操作中能并发处理大量的客户端请求从而实现高吞吐率。
IO多路复用机制是指一个线程处理多个IO流,也就是常说的select/epoll机制。在Redis运行单线程的情况下,该机制允许内核中同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给Redis线程处理,这就实现了一个Redis线程处理多个IO流的效果,进而提升并发性。
7)Redis与memcached比较
| 比较的种类 | Memcached | Redis |
|---|---|---|
| 类型 | Key-value数据库 | Key-value数据库 |
| 过期策略 | 支持 | 支持 |
| 数据类型 | 单一数据类型 | 五大数据类型 |
| 持久化 | 不支持 | 支持 |
| 主从复制 | 不支持 | 支持 |
| 虚拟内存 | 不支持 | 支持 |
四、redis的安装配置
1)redis的源码编译安装
---------------------- Redis 安装部署 ----------------------------------------
//环境准备
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config#修改内核参数
vim /etc/sysctl.conf
vm.overcommit_memory = 1
net.core.somaxconn = 2048sysctl -p//安装redis
yum install -y gcc gcc-c++ maketar zxvf /opt/redis-7.0.9.tar.gz -C /opt/
cd /opt/redis-7.0.9
make
make PREFIX=/usr/local/redis install
#由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。#创建redis工作目录
mkdir /usr/local/redis/{conf,log,data}cp /opt/redis-7.0.9/redis.conf /usr/local/redis/conf/useradd -M -s /sbin/nologin redis
chown -R redis.redis /usr/local/redis/#环境变量
vim /etc/profile
PATH=$PATH:/usr/local/redis/bin #增加一行source /etc/profile//修改配置文件
vim /usr/local/redis/conf/redis.conf
bind 127.0.0.1 192.168.73.105 #87行,添加 监听的主机地址
protected-mode no #111行,将本机访问保护模式设置no。如果开启了,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应
port 6379 #138行,Redis默认的监听6379端口
daemonize yes #309行,设置为守护进程,后台启动
pidfile /usr/local/redis/log/redis_6379.pid #341行,指定 PID 文件
logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
dir /usr/local/redis/data #504行,指定持久化文件所在目录
requirepass abc123 #1037行,增加一行,设置redis密码



编译安装解压过程省略

2)redis的服务管理
//定义systemd服务管理脚本
vim /usr/lib/systemd/system/redis-server.service
[Unit]
Description=Redis Server
After=network.target[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true[Install]
WantedBy=multi-user.target#启动服务
systemctl start redis-server
systemctl enable redis-servernetstat -lntp | grep 6379
五、redis的命令工具
| 工具 | 作用 |
|---|---|
| redis-server | 用于启动redis的工具 |
| redis-benchmark | 用于检测redis在本机的运行效率 |
| redis-check-aof | 修复AOF持久化文件 |
| redis-check-rdb | 修复RDB持久化文件 |
| redis-cli | redis命令行工具 |
1)redis-cli:Redis 命令行工具
redis-cli -h host -p port [-a password]-h:指定远程主机机-p:指定Redis服务的端口号-a:指定密码,未设置数据库密码可以省略-a选项#-a选项若不添加任何选项表示使用127.0.0.1:6379连接本机上的Redis数据库#登录本机redis-cli#远程登录redis-cli -h 192.168.73.50 -p 6379 [-a 密码]
2)redis-benchmark 测试工具
redis-benchmark是官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能
基本的测试语法:redis-benchmark [选项] [选项值]-h:指定服务器主机名。-p:指定服务器端口。-s:指定服务器 socket-c:指定并发连接数。-n:指定请求数。-d:以字节的形式指定SET/GET值的数据大小。-k:l=keep alive 0=reconnect -r:SET/GET/INCR 使用随机key,SADD使用随机值-P:通过管道传输<numreg>请求-q:强制退出redis,仅显示query/sec值--csv:以CSV格式输出-l:生成循环,永久执行测试-t:仅运行以逗号分隔的测试命令列表-I:Idle模式,仅打开N个idle连接并等待(1)并发连接与100000 个请求处理性能测试
redis-benchmark -h 192.168.73.50 -p 6379 -a 'abc123' -c 100 -n 100000
(2)数据包的存取的性能测试
redis-benchmark -h 192.168.73.50 -p 6379 -a 'abc123' -q -d 100
(3) 键值对的创建速度测试
redis-benchmark -t set,lpush -n 100000 -q
六、redis的简单操作
| 命令 | 作用 |
|---|---|
| set | 存放数据 |
| get | 获取数据 |
| keys * | 查看所有的key |
| keys k? | 查看k开头后面任意一位的数据 |
| exists | 判断键是否存在(存在1,不存在0) |
| del | 删除键 |
| type | 查看键对应的value值类型 |
| rename key1 key2 | 改名,不管key2是否存在都会改名成功。如果存在,key1的值会覆盖key2得值 |
| renamenx key1 key2 | 改名,若key2不存在,可以改名成功。若key2存在则不进行改名 |
| dbsize | 查看当前数据库中key的数目 |
1)redis键值对的存取
set:存放数据,命令格式为 set key valueget:获取数据,命令格式为 get key
2)redis键值列表的获取
键值的设置:
192.168.73.105:6379> set v1 1
OK
192.168.73.105:6379> set v2 2
OK
192.168.73.105:6379> set v3 3
OK
192.168.73.105:6379> set k1 4
OK
192.168.73.105:6379> set k2 5
OK
192.168.73.105:6379> set k3 6
OK
(1)获取全部列表

(2)获取以某字符为开头任意长度的键
keys v*
keys k*
(3)获取以某字符为开头,后面为指定长度的键
添加测试数据:
192.168.73.105:6379> set v123 123
OK
192.168.73.105:6379> set v11 11
OK
192.168.73.105:6379> set v1124 1124keys v?
keys v??
keys v???
keys v????
3)判断键是否存在
exists 键 #返回结果 为0 则为不存在,返回为1即为存在
4)删除键
del 键
5)查看键存储的数据类型
type 键
6)rename 重命名
- 使用rename命令进行重命名时,无论目标key是否存在都会进行重命名,且源key的值会覆盖目标key的值
- 在实际使用过程中,建议先用exists命令查看目标key 是否存在,然后再决定是否执行rename 命令,以避免覆盖重要数据
命令格式: rename 源key 目标key
7)renamenx 重命名
——会检查目标键名是否已存在
renamenx 命令的作用是对已有key进行重命名,并检测新名是否存在,如果目标key存在则不进行重命名。(不覆盖)
renamenx 源key 目标key
8)dbsize查看键数目
dbsize
9)设置和清空密码
设置和查看密码
#设置redis的登录密码
config set requirepass password
#查看redis的密码
config get requirepass 
清空密码
#清空密码config set requirepass '' 
七、Redis多数据库操作
Redis 支持多数据库,Redis默认情况下包含16个数据库,数据库名称是用数字0-15来依次命名的。
使用redis-cli连接Redis数据库后,默认使用的是序号为0的数据库。
多数据库相互独立,互不干扰
1)多数据库间切换select
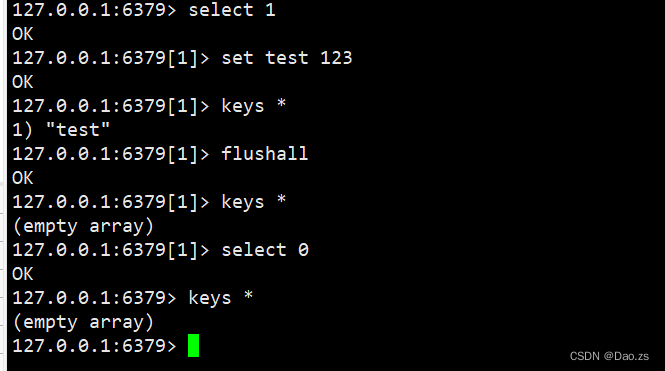
命令格式:select 序号#使用redis-cli连接Redis数据库后,默认使用的是序号为0的数据库。127.0.0.1:6379>select 10 #切换至序号为10的数据库127.0.0.1:6379[10]>select 15 #切换至序号为15的数据库127.0.0.1:6379[15]>select 0 #切换至序号为0的数据库127.0.0.1:6379[0]>
2)多数据库间移动数据
move 键值 序号(库的序号)
3)清除数据库内数据
FLUSHDB:清空当前数据库数据FLUSHALL:清空所有数据库的数据,
八、redis的常见错误与解决方案
1)Redis常见运维故障
- 使用 keys* 把库堵死。——建议使用别名把这个命令改名
- 超过内存使用后,部分数据被删除。——这个有删除策略的,选择适合自己的即可
- 没开持久化,却重启了实例,数据全掉。——记得非缓存的信息需要打开持久化
- RDB的持久化需要 Vm.overcommit_memory=1 ,否则会持久化失败
- 没有持久化情况下,主从,主重启太快,从还没认为主挂的情况下,从会清空自己的数据,人为重启主节点前,先关闭从节点的同步
2)Redis故障排查
- 结合Redis 监控查看QPS、缓存命中率、内存使用率等信息
- 确认机器层面的资源是否有异常
- 故障时及时上机,使用 redis-cli monitor 打印出操作日志,然后分析(事后分析此条失效)
- 和研发沟通,确认是否有大Key在堵塞(大Key也可以在日常的巡检中获得) 和组内同事沟通,确实是否有误操作
- 和运维同事、研发一起排查流量是否正常,是否存在被刷的情况
相关文章:
NOSQL——redis的安装,配置与简单操作
目录 一、缓存的相关知识 1)缓存的概念 2)系统缓存 buffer与cache: 3)缓存保存位置及分层结构 DNS缓存 应用层缓存 数据层缓存 分布式缓存服务: 数据库: 硬件缓存 二、关系型数据与非关系型数据…...
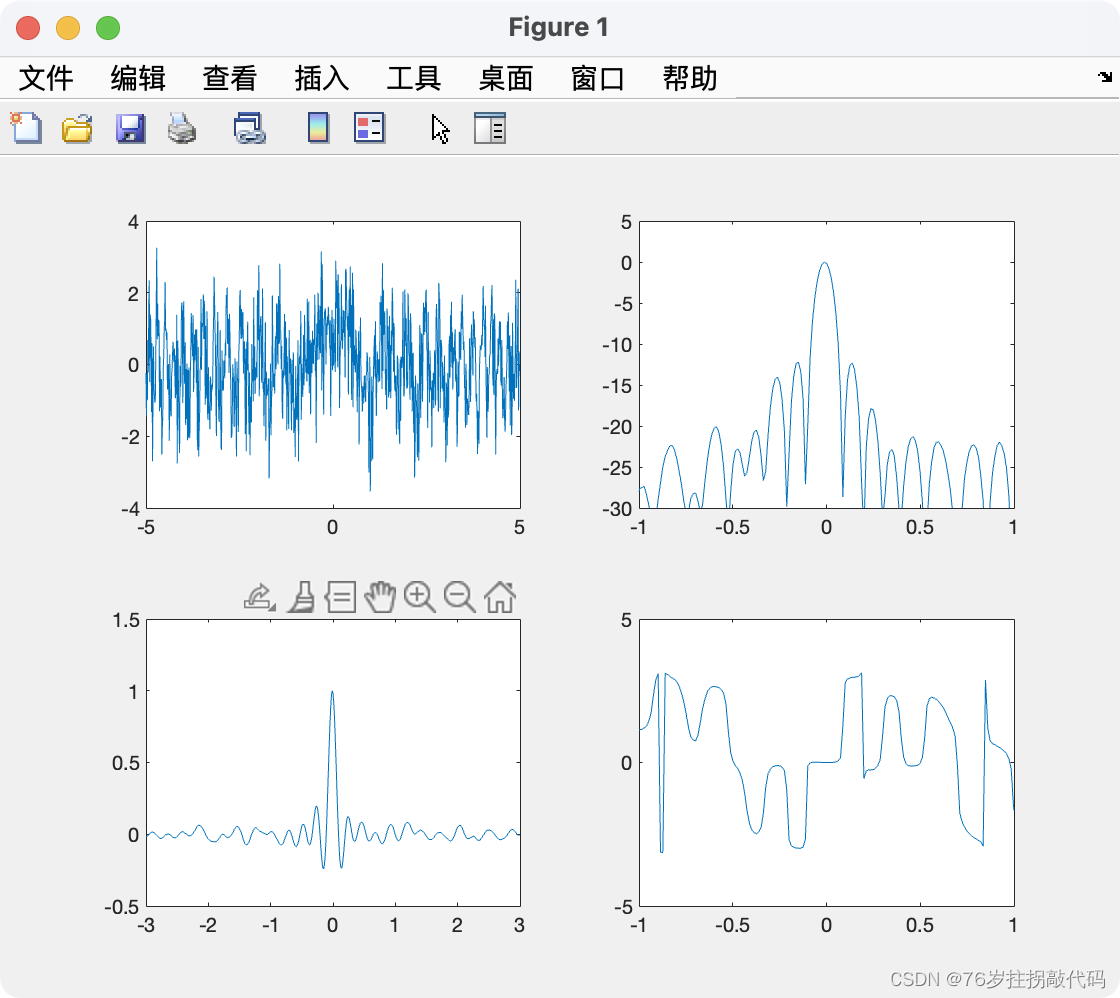
《合成孔径雷达成像算法与实现》Figure3.7
代码复现如下: clc clear all close all%参数设置 TBP 100; %时间带宽积 T 10e-6; %脉冲持续时间%参数计算 B TBP/T; …...
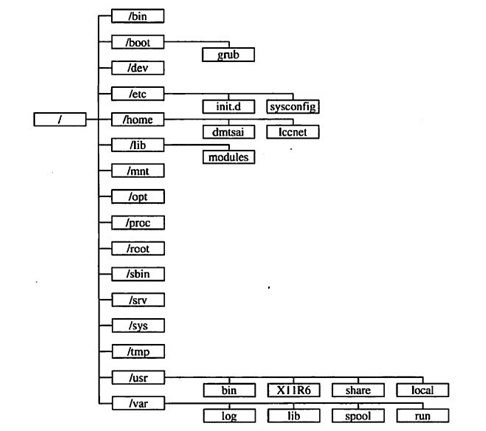
Linux 目录结构
初学Linux,首先需要弄清Linux 标准目录结构 / root --- 启动Linux时使用的一些核心文件。如操作系统内核、引导程序Grub等。home --- 存储普通用户的个人文件 ftp --- 用户所有服务httpdsambauser1user2bin --- 系统启动时需要的执行文件(二进制&#x…...

7天获英国名校邀请函|CSC青骨获批成功案例补记
Q老师要求2周内拿到邀请函且必须是世界排名前200名的高校。我们在第7天就获得了世界百强名校-英国兰卡斯特大学的邀请函,导师的研究方向完全契合,提前实现了Q老师的委托目标,使其顺利获批CSC青骨项目。特别提示:青骨项目国内派出院…...

ffmpeg ts列表合并为mp4
操作系统:ubuntu 注意事项: 1.ts文件顺序必须正确,也就是下一帧的dst和pst要比上一帧的大,否则会报错 2.codecpar->codec_tag要设置为0,否则报错Tag [27][0][0][0] incompatible with output codec id ‘27’ (avc1…...

MATLAB程序初始化OpenFOAM颗粒位置
问题引入 在OpenFOAM的颗粒两相流求解器中,我们可以采用manualInjection的方式进行自定义颗粒的初始位置,这个命令十分方便,在CFDEM中也有类似的命令,不过CFDEM中的命令更加强大,我们不仅可以定义颗粒的初始位置&…...

软件第三方CMA、CNAS测试的目的和意义,信息化建设验收测试依据是什么?
在当今互联网时代,软件的第三方CMA、CNAS测试成为了软件行业的重要环节。那么,这个测试的目的和意义是什么呢?另外,信息化建设验收测试依据又是什么呢? 一、软件测试第三方CMA、CNAS测试的目的和意义 1、研究进展 随着软件行业的迅…...
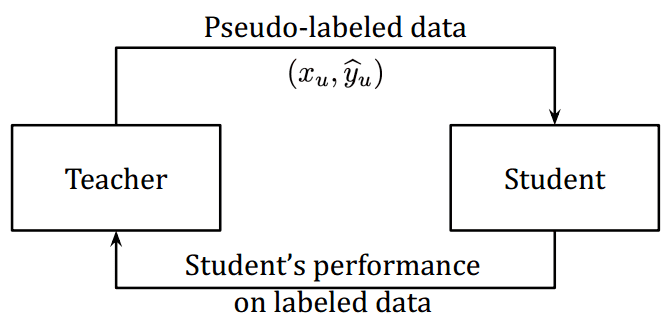
CNN成长路:从AlexNet到EfficientNet(02)
一、说明 在~10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。 二、第一阶段 …...

【Kubernetes】yaml文件格式
目录 YAML 语法格式: 查看 api 资源版本标签 写一个yaml文件demo 创建资源对象 查看创建的pod资源 创建service服务对外提供访问并测试 创建资源对象 查看创建的service 在浏览器输入 nodeIP:nodePort 即可访问 kubectl run --dry-runclient 打印相应的 A…...

Python web实战之Django的文件上传和处理详解
概要 关键词:Python Web开发、Django、文件上传、文件处理 今天分享一下Django的文件上传和处理。 1. 上传文件的基本原理 在开始深入讲解Django的文件上传和处理之前,先了解一下文件上传的基本原理。当用户选择要上传的文件后,该文件会被发…...

android res中values-swxxdp计算
一. res中values-swxxdp计算 以四寸中控面板为例 通过adb shell wm size获取屏幕大小为1264x1680 通过adb shell wm density获取屏幕显示密度dpi为300 最小宽度计算方法:s w 160 ∗ 手机宽度像素 / d p i sw160*手机宽度像素/dpisw160∗手机宽度像素/dpi 过公式…...

c动态内存申请
动态分配内存概述 先说数组的长度是预定义好的,固定不变的。但是呢,实际上所需的内存空间取决于实际输入的数据,而无法预先确定。所以根据实际情况,推出了内存管理函数。这些内存管理函数可以按需要动态分配内存空间,…...

C#8.0本质论第一章--C#概述
C#8.0本质论第一章–C#概述 朋友推荐的一本讲C#的书–C#本质论,英文叫Essential C#,官网可以免费看英文版的https://essentialcsharp.com/home。 C#可以为各种不同的系统平台开发应用软件和程序组件,支持移动设备,游戏主机&…...
geoserver编辑样式 【开发工具QGis的初次使用】
geoserver编辑样式 开发工具配置中文语言 geoserver样式的更改 开发工具 链接: geoserver样式style的更改 链接: QGis开发工具的安装及使用 配置中文语言 setting > options > general > 中文 geoserver样式的更改 链接: geoserver样式style的更改 利用QGIs Q…...
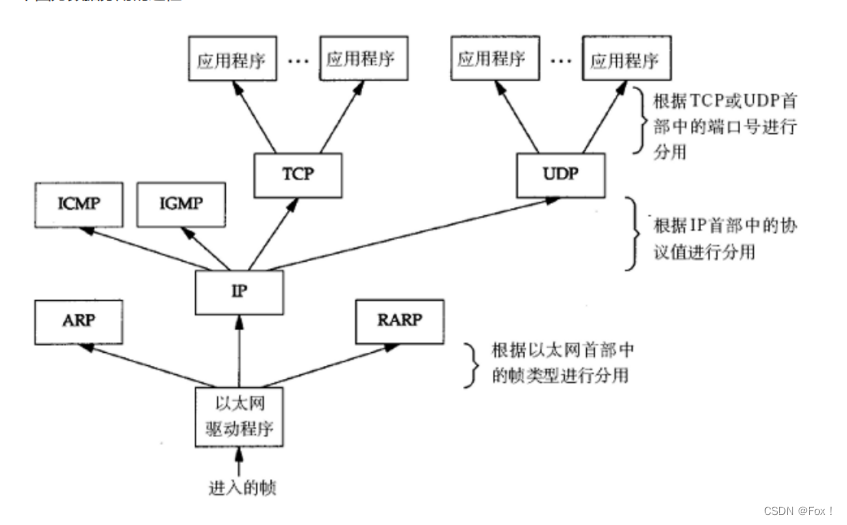
【网络基础知识铺垫】
文章目录 1 :peach:计算机网络背景:peach:1.1 :apple:网络发展:apple: 2 :peach:协议:peach:2.1 :apple:协议分层:apple:2.2 :apple:OSI七层模型:apple:2.3 :apple:TCP/IP模型:apple:2.4 :apple:TCP/IP模型与操作系统的关系:apple: 3 :peach:网络传输基本流程:peach:4 :peach:网…...

一个利用oracle异常处理的函数
函数主体如下: CREATE OR REPLACE FUNCTION fn_get_agmt_bal(p_agmt_no varchar2) RETURN NUMBER ISv_bal NUMBER : 0;--在SQL/PLUS中执行时,若合dbms_output生效,需先执行【SET SERVEROUTPUT ON】; BEGINselect agmt_balinto v_balfrom edw…...
langchain-ChatGLM源码阅读:参数设置
文章目录 上下文关联对话轮数向量匹配 top k控制生成质量的参数参数设置心得 上下文关联 上下文关联相关参数: 知识相关度阈值score_threshold内容条数k是否启用上下文关联chunk_conent上下文最大长度chunk_size 其主要作用是在所在文档中扩展与当前query相似度较高…...

什么是Java中的工厂模式?
工厂模式(Factory Pattern)是一种常见的设计模式,它可以帮助我们简化对象创建的过程,将对象的创建与使用分离,提高代码的可维护性和可扩展性。在Java中,工厂模式通常分为简单工厂模式(Simple Fa…...
数据库--MySQL
一、什么是范式? 范式是数据库设计时遵循的一种规范,不同的规范要求遵循不同的范式。 最常用的三大范式 第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列) 第二范式(2NF):满足…...
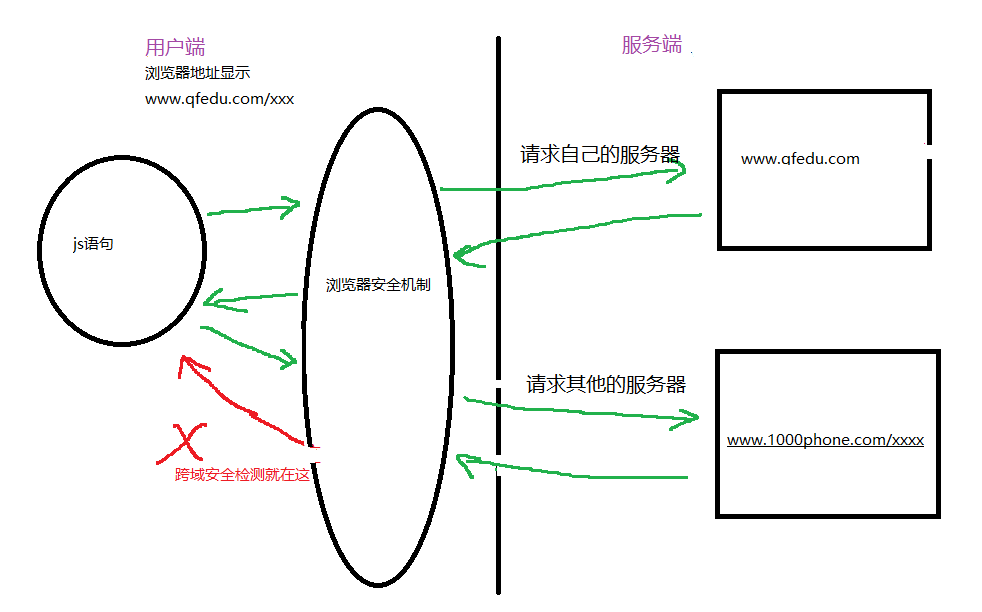
浏览器多管闲事之跨域
年少时的梦想就是买一台小霸王游戏机 当时的宣传语就是小霸王其乐无穷~。 大些了,攒够了零花钱,在家长的带领下终于买到了 那一刻我感觉就是最幸福的人 风都是甜的! 哪成想... 刚到家就被家长扣下了 “”禁止未成年人玩游戏机 (问过卖家了&a…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...