RaabitMQ(三) - RabbitMQ队列类型、死信消息与死信队列、懒队列、集群模式、MQ常见消息问题
RabbitMQ队列类型
Classic经典队列
-
这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。
-
经典队列可以选择是否持久化(Durability)以及是否自动删除(Auto delete)两个属性。
-
Durability有两个选项,Durable和Transient。 Durable表示队列会将消息保存到硬盘,这样消息的安全性更高。但是同时,由于需要有更多的IO操作,所以生产和消费消息的性能,相比Transient会比较低。
-
Auto delete属性如果选择为是,那队列将在至少一个消费者已经连接,然后所有的消费者都断开连接后删除自己。
-
经典队列不适合积累太多的消息。如果队列中积累的消息太多了,会严重影响客户端生产消息以及消费消息的性能。因此,经典队列主要用在数据量比较小,并且生产消息和消费消息的速度比较稳定的业务场景。比如内部系统之间的服务调用。
Quorum仲裁队列
-
仲裁队列,是3.8引入的一个新队列类型;仲裁队列相比Classic经典队列,在分布式环境下对消息的可靠性保障更高。
-
Quorum是基于Raft一致性协议实现的一种新型的分布式消息队列,他实现了持久化,多备份的FIFO队列,主要就是针对RabbitMQ的镜像模式设计的。简单理解就是quorum队列中的消息需要有集群中多半节点同意确认后,才会写入到队列中。
-
Classic与Quorum对比、少了一些高级特性:
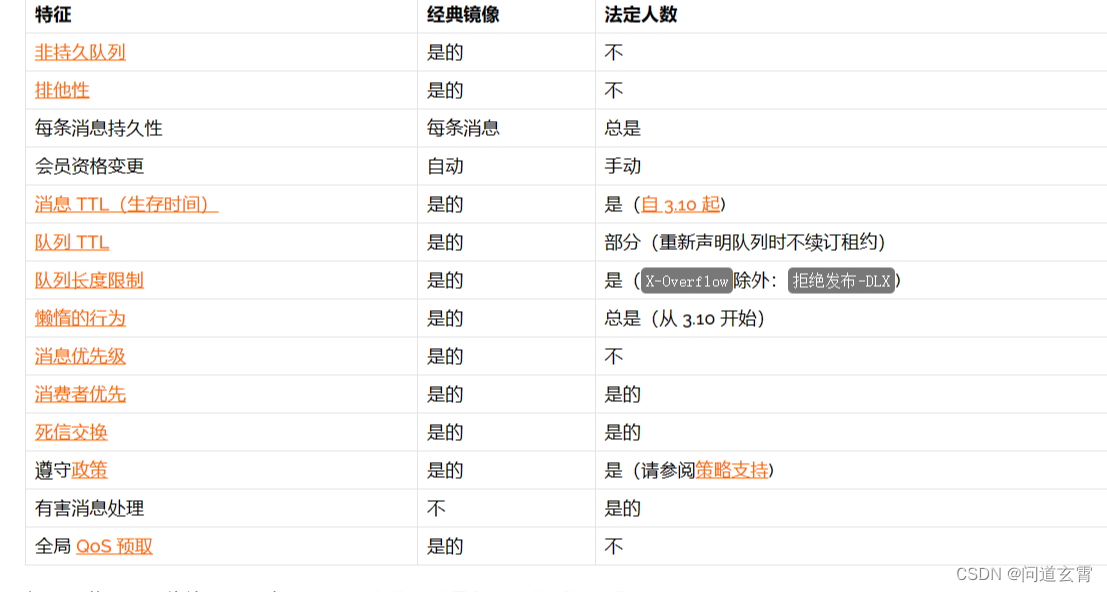
-
Quorum队列更适合于 队列长期存在,并且对容错、数据安全方面的要求比低延迟、不持久等高级队列更能要求更严格的场景。例如 电商系统的订单,引入MQ后,处理速度可以慢一点,但是订单不能丢失。
-
Quorum不适合的场景如下:
- 队列的临时性:暂时性或独占队列、高队列变动率(声明和删除率)
- 尽可能低的延迟:由于其数据安全功能,底层共识算法固有的延迟更高
- 当数据安全不是优先事项时(例如,应用程序不使用手动确认,不使用发布者确认)
- 很长的队列积压(流可能更适合)
创建Quorum队列
Spring创建仲裁队列需要设置参数“-x-queue-type”为“quorum”
@Configuration
public class QuorumConfig {public final static String QUEUE_TYPE = "x-queue-type";public final static String QUEUE_TYPE_VAL = "quorum";public final static String QUEUE_NAME = "quorumQueue";@Beanpublic Queue quorumQueue() {HashMap<String, Object> params = new HashMap<>();params.put(QUEUE_TYPE,QUEUE_TYPE_VAL);Queue queue = new Queue(QUEUE_NAME, true, false, false, params);return queue;}
}
Rabbit Client创建Quorum队列:
Map<String,Object> params = new HashMap<>();
params.put("x-queue-type","quorum");
//声明Quorum队列的方式就是添加一个x-queue-type参数,指定为quorum。默认是classic
channel.queueDeclare(QUEUE_NAME, true, false, false, params);
Quorum队列的消息是必须持久化的,所以durable参数必须设定为true,如果声明为false,就会报错。同样,exclusive参数必须设置为false。这些声明,在Producer和Consumer中是要保持一致的。
Stream队列
- Stream队列是3.9.0版本引入新队列类型。
- 持久化到磁盘并且具备分布式备份的,更适合于消费者多,读消息非常频繁的场景。
- Stream队列的核心是以append-only只添加的日志来记录消息,整体来说,就是消息将以append-only的方式持久化到日志文件中,然后通过调整每个消费者的消费进度offset,来实现消息的多次分发。类似kafka;
创建Stream队列
Spring AMQP目前还不支持创建Stream队列;只能使用原生API创建
Map<String,Object> params = new HashMap<>();params.put("x-queue-type","stream");params.put("x-max-length-bytes", 20_000_000_000L); // maximum stream size: 20 GBparams.put("x-stream-max-segment-size-bytes", 100_000_000); // size of segment files: 100 MBchannel.queueDeclare(QUEUE_NAME, true, false, false, params);
Stream队列的durable参数必须声明为true,exclusive参数必须声明为false。
x-max-length-bytes 表示日志文件的最大字节数, x-stream-max-segment-size-bytes 每一个日志文件的最大大小。这两个是可选参数,通常为了防止stream日志无限制累计,都会配合stream队列一起声明。
消费者:
Map<String,Object> consumeParam = new HashMap<>();consumeParam.put("x-stream-offset","last");channel.basicConsume(QUEUE_NAME, false,consumeParam, myconsumer);
x-stream-offset的类型:
- first: 从日志队列中第一个可消费的消息开始消费
- last: 消费消息日志中最后一个消息
- next: 相当于不指定offset,消费不到消息。
- Offset: 一个数字型的偏移量
- Timestamp:一个代表时间的Data类型变量,表示从这个时间点开始消费。例如 一个小时前Date timestamp = new Date(System.currentTimeMillis() - 60 * 60 * 1_000)
Stream队列产品目前不够成熟,目前用的最多的还是Classic经典队列。RabbitMQ目前主推的是Quorum队列;
死信消息
有以下三种情况,RabbitMQ会将一个正常消息转成死信
-
消息被消费者确认拒绝。消费者把requeue参数设置为true(false),并且在消费后,向 RabbitMQ返回拒绝。channel.basicReject或者channel.basicNack。
-
消息达到预设的TTL时限还一直没有被消费。
-
消息由于队列已经达到最长长度限制而被丢掉
-
TTL即最长存活时间 Time-To-Live 。消息在队列中保存时间超过这个TTL,即会被认为死亡。死亡的消息会被丢入死信队列,如果没有配置死信队列的话,RabbitMQ会保证死了的消息不会再次被投递,并且在未来版本中,会主动删除掉这些死掉的消息。
-
声明队列时、设置"x-message-ttl"值;
-
Map<String, Object> args = new HashMap<String, Object>();args.put("x-message-ttl", 60000);channel.queueDeclare("myqueue", false, false, false, args);
如何判断消息是否为死信
消息被作为死信转移到死信队列后,header中还会加上第一次成为死信的三个属性,并且这三个属性在以后的传递过程中都不会更改。具体可以调试去看看;
- x-first-death-reason :原因
- x-first-death-queue : 队列
- x-first-death-exchange : 交换机
死信队列
- 存在死信消息的队列;
- RabbitMQ中有两种方式可以声明死信队列,一种是针对某个单独队列指定对应的死信队列。另一种就是以策略的方式进行批量死信队列的配置。
流程图如下:
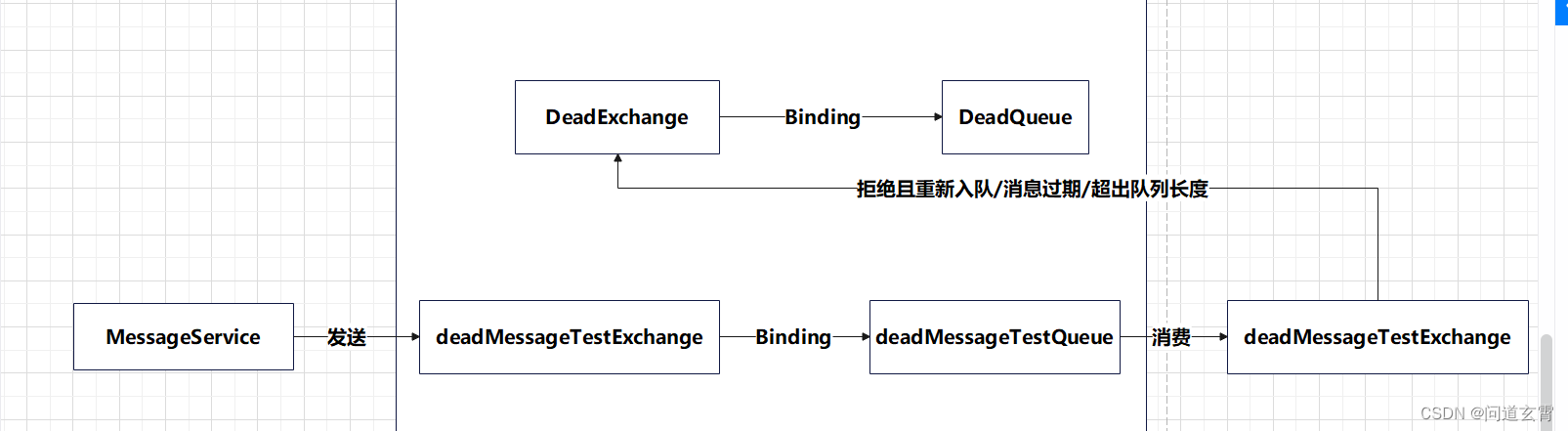
代码:
死信交换机、队列:
@Configuration
public class DeadConfig {public final static String DEAD_EXCHANGE = "deadExchange";public final static String DEAD_QUEUE_NAME = "deadQueue";@Beanpublic FanoutExchange deadExchange() {FanoutExchange directExchange = new FanoutExchange(DEAD_EXCHANGE);return directExchange;}@Beanpublic Queue deadQueue() {Queue queue = new Queue(DEAD_QUEUE_NAME);return queue;}@Beanpublic Binding deadBinding(FanoutExchange deadExchange, Queue deadQueue) {return BindingBuilder.bind(deadQueue).to(deadExchange);}}
发送者:
@Controller
public class MessageTx {@Autowiredprivate MessageService messageService;@GetMapping("/sendDeadMsg")@ResponseBodypublic String sendMoreMsgTx(){//发送10条消息for (int i = 0; i < 10; i++) {String msg = "msg"+i;System.out.println("发送消息 msg:"+msg);// xiangjiao.exchange 交换机// xiangjiao.routingKey 队列messageService.sendMessage(MessageConfig.EXCHANGE_NAME, "", msg);//每两秒发送一次try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}}return "send ok";}
}@Slf4j
@Component
public class MessageService {@Autowiredprivate RabbitTemplate rabbitTemplate;public void sendMessage(String exchange,String routingKey,Object msg) {// 暂时关闭 return 配置//rabbitTemplate.setReturnCallback(this);//发送消息rabbitTemplate.convertAndSend(exchange,routingKey,msg);}}
消费者:
public class MessageConsumer {// @RabbitHandler : 标记的方法只能有一个参数,类型为String ,若是传Map参数、则需要传入map参数// @RabbitListener:标记的方法可以传入Channel, Message参数@RabbitListener(queues = MessageConfig.MESSAGE_QUEUE_NAME)public void listenObjectQueue(Channel channel, Message message, String msg) throws IOException {System.out.println("接收到object.queue的消息" + msg);System.out.println("消息ID : " + message.getMessageProperties().getDeliveryTag());try {channel.basicReject(message.getMessageProperties().getDeliveryTag(), false);System.out.println("拒绝消息 , tag = " + message.getMessageProperties().getDeliveryTag());
// channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);}catch (IOException exception) {//拒绝确认消息channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, true);//拒绝消息
// channel.basicReject(message.getMessageProperties().getDeliveryTag(), true);}}}注入容器:
@Configuration
public class MessageConfig {public final static String EXCHANGE_NAME = "deadMessageTestExchange";public final static String MESSAGE_QUEUE_NAME = "deadMessageTestQueue";public final static String MESSAGE_ROUTE_KEY = "deadMessageTestRoutingKey";public final static String DEAD_EXCHANGE_KEY = "x-dead-letter-exchange";@Beanpublic FanoutExchange deadMessageTestExchange() {return new FanoutExchange(EXCHANGE_NAME);}@Beanpublic Queue deadMessageTestQueue() {HashMap<String, Object> params = new HashMap<>();params.put(DEAD_EXCHANGE_KEY, DeadConfig.DEAD_EXCHANGE);return new Queue(MESSAGE_QUEUE_NAME, true, false, false, params);}@Beanpublic MessageConsumer deadMessageTestConsumer() {return new MessageConsumer();}@Beanpublic Binding messageBinding(Queue deadMessageTestQueue, FanoutExchange deadMessageTestExchange) {return BindingBuilder.bind(deadMessageTestQueue).to(deadMessageTestExchange);}
}
延迟队列
RabbitMQ有提供插件使用延迟队列, 另外可借助 死信队列 实现延迟队列;
实现思路:
- 给普通队列设置消息过期时间(延迟时间), 不设置消费者;
- 当消息过期后,将消息放入死信队列, 给死信队列设置消费者;
懒队列
懒队列会尽可能早的将消息内容保存到硬盘当中,并且只有在用户请求到时,才临时从硬盘加载到RAM内存当中。 可解决部分消息积压问题、(海量消息积压,RabbitMQ存不下就得使用分布式存储消息)
适用的一些场景:
- 消费者服务宕机了
- 有一个突然的消息高峰,生产者生产消息超过消费者
- 消费者消费太慢了
默认情况下,RabbitMQ接收到消息时,会保存到内存以便使用,同时把消息写到硬盘。但是,
消息写入硬盘的过程是会阻塞队列的。RabbitMQ虽然做了优化,但是在长队列中表现不是很理想,所以有了懒队列、 以磁盘IO为代价解决消息积压问题;
SpringBoot懒队列声明方式:
@Configuration
public class LazyQueueConfig {@Beanpublic Queue lazyQueue() {HashMap<String, Object> params = new HashMap<>();params.put("x-queue-mode", "lazy");return new Queue("lazyQueue", true, false, false, params);}
}
原生API方式:
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-queue-mode", "lazy");
channel.queueDeclare("myqueue", false, false, false, args);
懒队列适合消息量大且长期有堆积的队列,可以减少内存使用,加快消费速度。但是这是以大量消耗集群的网络及磁盘IO为代价的。
集群模式
分布式环境下,是不允许单点故障存在,需要保证高可用, 因此需要集群环境保证高可用,另外若存在海量消息,还需要保证存放得下、即分布式存储;
普通集群模式
- 集群的各个节点之间只会有相同的元数据,即队列结构,而消息不会进行冗余,只存在一个节点中。
- 消费时,如果消费的不是存有数据的节点, RabbitMQ会临时在节点之间进行数据传输,将消息从存有数据的节点传输到消费的节点。
- 此模式解决分布式存储问题、但可靠性不高,相当于多个单机服务,每个都是独立的,一个都不可以宕机。某台机器宕机、则存储的消息无法消费、若未开启持久化、则丢失消息, 若消费者正在处理消息,则机器无法收到确认信息,该消息重新入队,则重复消费;
- 普通集群模式不支持高可用,即当某一个节点服务挂了后,需要手动重启服务,才能保证这一部分消息能正常消费。
镜像集群模式
- 在普通集群的基础上,每次保存消息后,机器主动同步到多台机器上, 而不是消费者获取消息时,再去其他节点上获取;
- 集群会选举主节点master, 当主节点挂了,则会重新选举;
- 此方式实现了集群高可用,但是集群之间同步消息频繁,海量数据时、同步频率更大,导致占满带宽;
消息常见问题
RabbitMQ如何保证消息不丢失
先看看哪些情况下,会存在丢失消息?
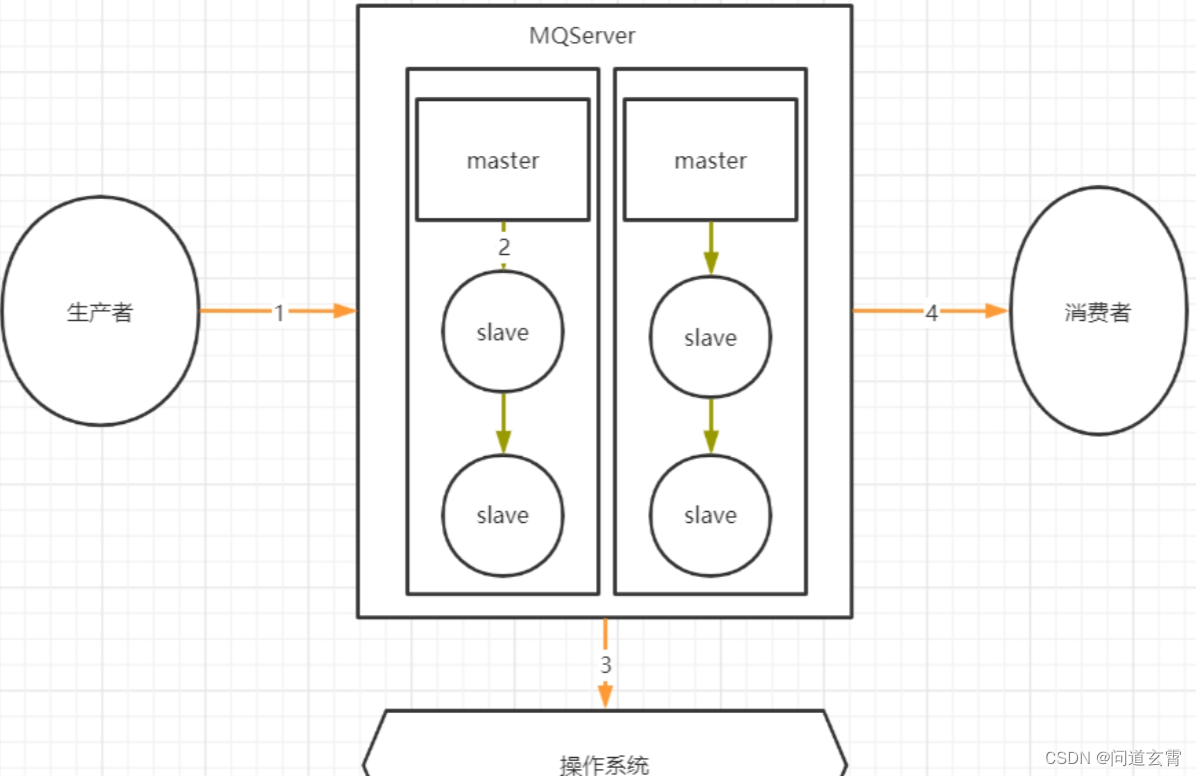
1,2,4步骤是可能丢消息的,因为三个步骤都是跨网络的;
生产者保证消息正确发送到RibbitMQ
- 对于单个数据,可以使用生产者确认机制。通过多次确认的方式,保证生产者的消息能够正确的发送到RabbitMQ中。
- RabbitMQ的生产者确认机制分为同步确认和异步确认。同步确认主要是通过在生产者端使用Channel.waitForConfirmsOrDie()指定一个等待确认的完成时间。异步确认机制则是通过channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2)在生产者端注入两个回调确认函数。第一个函数是在生产者消息发送成功时调用,第二个函数则是生产者消息发送失败时调用。两个函数需要通过sequenceNumber自行完成消息的前后对应。sequenceNumber的生成方式需要通过channel的序列获取。int sequenceNumber = channel.getNextPublishSeqNo();
- 如果发送批量消息,在RabbitMQ中,另外还有一种手动事务的方式,可以保证消息正确发送
- 手动事务机制主要有几个关键的方法: channel.txSelect() 开启事务; channel.txCommit() 提交事务; channel.txRollback() 回滚事务; 用这几个方法来进行事务管理。但是这种方式需要手动控制事务逻辑,并且手动事务会对channel产生阻塞,造成吞吐量下降
RabbitMQ消息存盘不丢消息
消息若是只存内存中,则宕机会丢失消息, 因此队列需要开启持久化,durable参数、默认创建队列,durable都会为true; 而Quorum和Stream队列默认都是开启持久化;
RabbitMQ 主从消息同步时不丢消息
普通集群模式,消息是分散存储的,不会主动进行消息同步了,是有可能丢失消息的。而镜像模式集群,数据会主动在集群各个节点当中同步,这时丢失消息的概率不会太高。
RabbitMQ消费者不丢失消息
消费者确认,分为自动确认,手动确认;若是自动确认,则消息处理完,会返回确认ack;若是处理出现异常, 则会重新入队,再次处理, 因此存在重复消费问题;
若是手动确认,消息处理过程中使用channel#basicAck, basicNack, basicReject返回确认或拒绝;SpringBoot配置文件中通过属性spring.rabbitmq.listener.simple.acknowledge-mode需要设置mutual手动确认;
SpringBoot配置文件中通过属性spring.rabbitmq.listener.simple.acknowledge-mode 进行指定。可以设定为 AUTO 自动应答; MANUAL 手动应答;NONE 不应答;
如何保证消息幂等?
当消费者消费消息处理业务逻辑时,如果抛出异常,或者不向RabbitMQ返回响应,默认情况下,RabbitMQ会无限次数的重复进行消息消费。
处理幂等问题,要设定RabbitMQ的重试次数。在SpringBoot集成RabbitMQ时,可以在配置文件
中指定spring.rabbitmq.listener.simple.retry开头的一系列属性,来制定重试策略。
需要在业务上处理幂等问题, 处理幂等问题的关键是要给每个消息一个唯一的标识;虽然RabbitMQ会给每条消息带上MessageId (处理幂等问题的关键是要给每个消息一个唯一的标识);
SpringBoot框架集成RabbitMQ后,可以给每个消息指定一个全局唯一的MessageID,在消费者端针对MessageID做幂等性判断。
//发送者
Message message2 = MessageBuilder.withBody(message.getBytes()).setMessageId(UUID.randomUUID().toString()).build();
rabbitTemplate.send(message2);//消费者获取MessageID,自己做幂等性判断
@RabbitListener(queues = "fanout_email_queue")
public void process(Message message) throws Exception {// 获取消息IdString messageId = message.getMessageProperties().getMessageId();...
}
可为了业务上的方便,再封装一层, 专门用来放入消息ID, 否则设置ID的代码随处可见;
如何保证消息的顺序?
RabbitMQ中保证顺序的方法是 单队列+单消息推送; 若是多队列的情况下,RabbitMQ没有很好的解决方案;
个人思考:如果RabbitMQ架构上很难处理,可以通过业务设置保证顺序, 即给每条消息设置序号, 消费时、查询数据库之前的消息是否处理完,若没有查到,则等待一会, 若查得到,则处理消息,处理完后,把消息id + 序号 放入数据库代表已经处理完;
RabbitMQ的数据堆积问题
bbitMQ一直以来都有一个缺点,就是对于消息堆积问题的处理不好。当RabbitMQ中有大量消息堆积时,整体性能会严重下降。而目前新推出的Quorum队列以及Stream队列,目的就在于解决这个核心问题。目前大部分企业还是围绕Classic经典队列构建应用。因此,在使用RabbitMQ时,还是要非常注意消息堆积的问题。尽量让消息的消费速度和生产速度保持一致。
- 对于生产者:
最明显的方式自然是降低消息生产的速度。但是,生产者端产生消息的速度通常是跟业务息息相关的,一般情况下不太好直接优化。但是可以选择尽量多采用批量消息的方式,降低IO频率。 - 对于服务器端
- 可使用懒队列方式存储 部分消息积压(单机的磁盘容量还是有限)
- 可使用Sharding分片队列(分布式存储)
- 对于消费者
- 检查业务代码是不是太挫了, 优化代码
- 代码性能没问题、则要增加消费者数量,提升消费速度;
- 若是经常存在海量消息,则可以放入数据库、慢慢消费;
相关文章:
RaabitMQ(三) - RabbitMQ队列类型、死信消息与死信队列、懒队列、集群模式、MQ常见消息问题
RabbitMQ队列类型 Classic经典队列 这是RabbitMQ最为经典的队列类型。在单机环境中,拥有比较高的消息可靠性。 经典队列可以选择是否持久化(Durability)以及是否自动删除(Auto delete)两个属性。 Durability有两个选项,Durable和Transient。 Durable表…...

Unity3D GPU Selector/Picker
Unity3D GPU Selector/Picker 一、概述 1.动机 Unity3D中通常情况下使用物理系统进行物体点击选择的基础,对于含大量对象的场景,添加Collider组件会增加内容占用,因此使用基于GPU的点击选择方案 2.实现思路 对于场景的每个物体,…...
灰度非线性变换之c++实现(qt + 不调包)
本章介绍灰度非线性变换,具体内容包括:对数变换、幂次变换、指数变换。他们的共同特点是使用非线性变换关系式进行图像变换。 1.灰度对数变换 变换公式:y a log(1x) / b,其中,a控制曲线的垂直移量;b为正…...

轻量级Web框架Flask
Flask-SQLAlchemy MySQL是免费开源软件,大家可以自行搜索其官网(https://www.MySQL.com/downloads/) 测试MySQL是否安装成功 在所有程序中,找到MySQL→MySQL Server 5.6下面的命令行工具,然后单击输入密码后回车&am…...

【gridsample】地平线如何支持gridsample算子
文章目录 1. grid_sample算子功能解析1.1 理论介绍1.2 代码分析1.2.1 x,y取值范围[-1,1]1.2.2 x,y取值范围超出[-1,1] 2. 使用grid_sample算子构建一个网络3. 走PTQ进行模型转换与编译 实操以J5 OE1.1.60对应的docker为例 1. grid_sample算子功能解析 该段主要参考:…...
JPA实现存储实体类型信息
本文已收录于专栏 《Java》 目录 背景介绍概念说明DiscriminatorValue 注解:DiscriminatorColumn 注解:Inheritance(strategy InheritanceType.SINGLE_TABLE) 注解: 实现方式父类子类执行效果 总结提升 背景介绍 在我们项目开发的过程中经常…...

阿里云快速部署开发环境 (Apache + Mysql8.0+Redis7.0.x)
本文章的内容截取于云服务器管理控制台提供的安装步骤,再整合前人思路而成,文章末端会提供原文连接 ApacheMysql 8.0部署MySQL数据库(Linux)步骤一:安装MySQL步骤二:配置MySQL步骤三:远程访问My…...
语音秘书:让录音转文字识别软件成为你的智能工作助手
每当在需要写文章的深夜,我的思绪经常跟不上我的笔,即便是说出来用录音机录下,再书写出来,也需要耗费大量时间。这个困扰了我很久的问题终于有了解决的办法,那就是录音转文字软件。它像个语言魔术师,将我所…...
【腾讯云 Cloud Studio 实战训练营】用于编写、运行和调试代码的云 IDE泰裤辣
文章目录 一、引言✉️二、什么是腾讯云 Cloud Studio🔍三、Cloud Studio优点和功能🌈四、Cloud Studio初体验(注册篇)🎆五、Cloud Studio实战演练(实战篇)🔬1. 初始化工作空间2. 安…...

[C#] 简单的俄罗斯方块实现
一个控制台俄罗斯方块游戏的简单实现. 已在 github.com/SlimeNull/Tetris 开源. 思路 很简单, 一个二维数组存储当前游戏的方块地图, 用 bool 即可, true 表示当前块被填充, false 表示没有. 然后, 抽一个 “形状” 类, 形状表示当前玩家正在操作的一个形状, 例如方块, 直线…...
postman官网下载安装登录详细教程
目录 一、介绍 二、官网下载 三、安装 四、注册登录postman账号(不注册也可以) postman注册登录和不注册登录的使用区别 五、关于汉化的说明 一、介绍 简单来说:是一款前后端都用来测试接口的工具。 展开来说:Postman 是一个…...

(贪心) 剑指 Offer 14- I. 剪绳子 ——【Leetcode每日一题】
❓剑指 Offer 14- I. 剪绳子 难度:中等 给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n > 1 并且 m > 1),每段绳子的长度记为 k[0],k[1]...k[m-1] 。请问 k[0]*k[1]*...*k[m…...
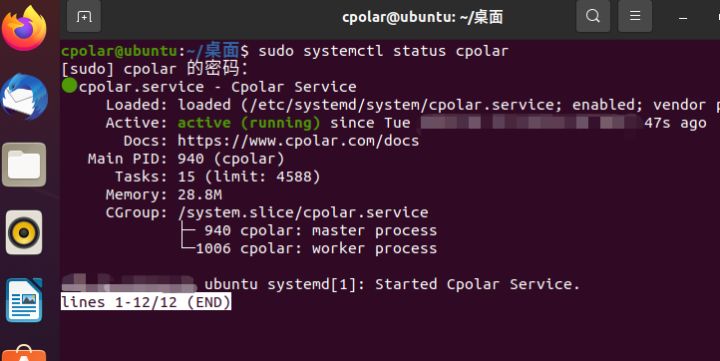
如何将Linux上的cpolar内网穿透设置成 - > 开机自启动
如何将Linux上的cpolar内网穿透设置成 - > 开机自启动 文章目录 如何将Linux上的cpolar内网穿透设置成 - > 开机自启动前言一、进入命令行模式二、输入token码三、输入内网穿透命令 前言 我们将cpolar安装到了Ubuntu系统上,并通过web-UI界面对cpolar的功能有…...
)
50.两数之和(力扣)
目录 问题描述 核心代码解决 代码思想 时间复杂度和空间复杂度 问题描述 给定一个整数数组 和一个整数目标值 ,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。numstarget 你可以假设每种输入只会对应一个答案。但是&am…...
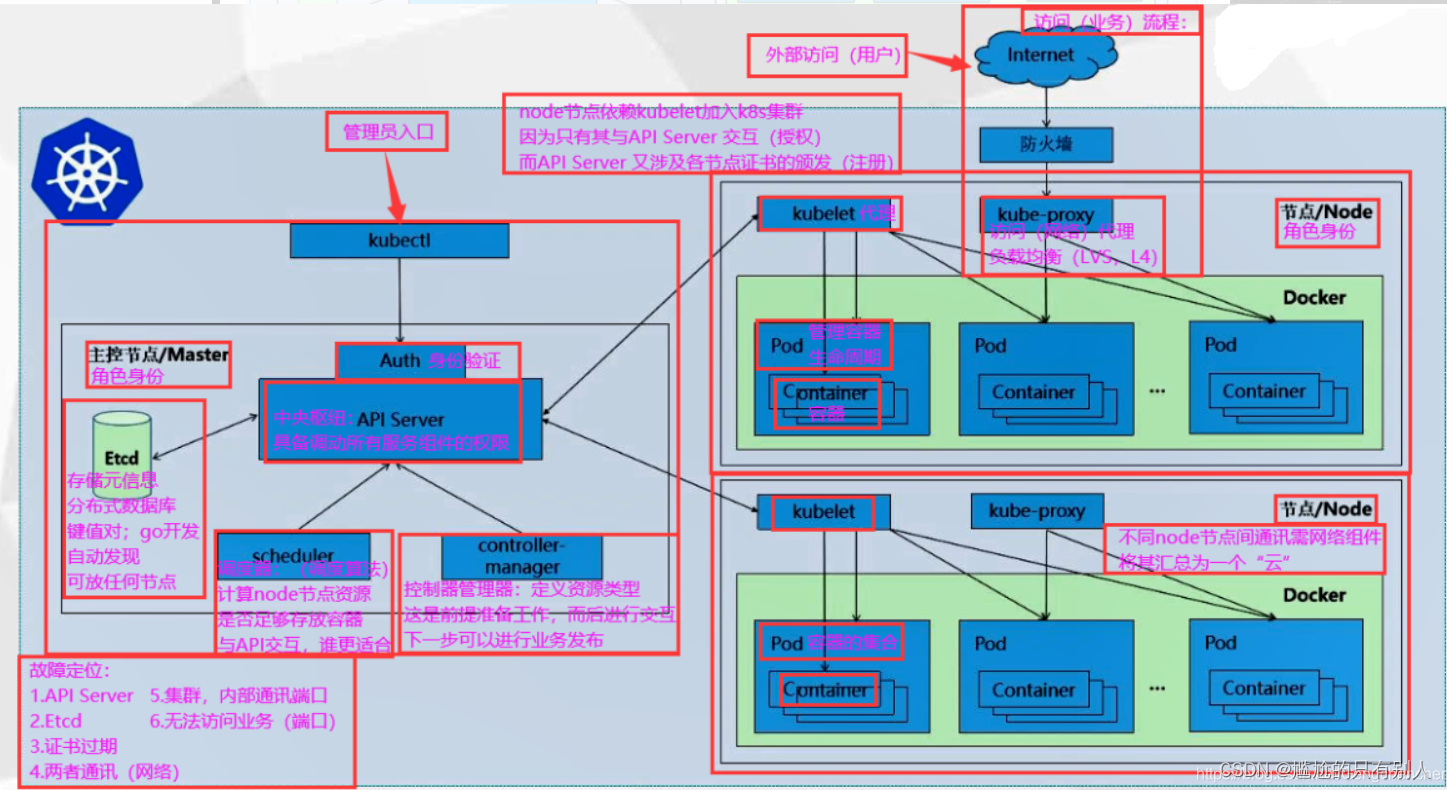
k8s基础
k8s基础 文章目录 k8s基础一、k8s组件二、k8s组件作用1.master节点2.worker node节点 三、K8S创建Pod的工作流程?四、K8S资源对象1.Pod2.Pod控制器3.service && ingress 五、K8S资源配置信息六、K8s部署1.K8S二进制部署2.K8S kubeadm搭建 七、K8s网络八、K8…...

【自然语言处理】大模型高效微调:PEFT 使用案例
文章目录 一、PEFT介绍二、PEFT 使用2.1 PeftConfig2.2 PeftModel2.3 保存和加载模型 三、PEFT支持任务3.1 Models support matrix3.1.1 Causal Language Modeling3.1.2 Conditional Generation3.1.3 Sequence Classification3.1.4 Token Classification3.1.5 Text-to-Image Ge…...
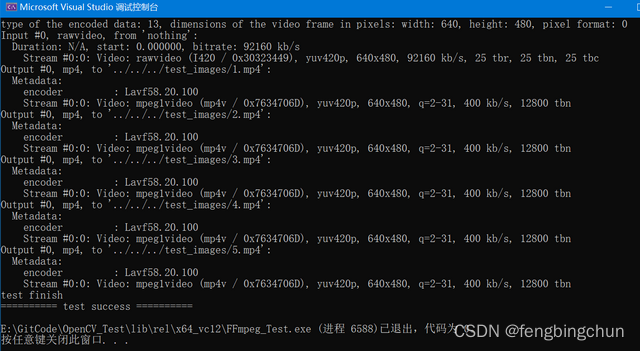
FFmpeg将编码后数据保存成mp4
以下测试代码实现的功能是:持续从内存块中获取原始数据,然后依次进行解码、编码、最后保存成mp4视频文件。 可保存成单个视频文件,也可指定每个视频文件的总帧数,保存多个视频文件。 为了便于查看和修改,这里将可独立的…...

设置VsCode 将打开的多个文件分行(栏)排列,实现全部显示
目录 1. 前言 2. 设置VsCode 多文件分行(栏)排列显示 1. 前言 主流编程IDE几乎都有排列切换选择所要查看的文件功能,如下为Visual Studio 2022的该功能界面: 图 1 图 2 当在Visual Studio 2022打开很多文件时,可以按照图1、图2所示找到自…...

Vue.js2+Cesium1.103.0 六、标绘与测量
Vue.js2Cesium1.103.0 六、标绘与测量 点,线,面的绘制,可实时编辑图形,点击折线或多边形边的中心点,可进行添加线段移动顶点位置等操作,并同时计算出点的经纬度,折线的距离和多边形的面积。 De…...

【redis 延时队列】使用go-redis的list做异步,生产消费者模式
分享一个用到的,使用go-redis的list做异步,生产消费者模式,接着再用 go 协程去检测队列里是否有东西去消费 如果队列为空,就会一直pop,空轮询导致 cpu 资源浪费和redis qps无效升高,所以可以通过 time.Sec…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...