数据挖掘的基本概念和大数据的特点
数据挖掘是指从大量数据中提取有价值的信息或模式的过程。它通常使用计算机技术来分析数据,并利用统计学、机器学习、人工智能等方法来发现数据中的隐藏规律、趋势和关联性。
数据挖掘的基本概念包括以下几个方面:
-
数据预处理:对原始数据进行清洗、去噪、过滤和变换等处理,以便于后续的分析和挖掘。
-
数据表示和转换:将数据转化为适合分析的形式,如将文本转化为向量,将时间序列数据进行平滑处理等。
-
数据挖掘算法:根据问题的特点和数据的特征选择合适的算法进行数据挖掘,如聚类、分类、关联规则挖掘、异常检测等。
-
模式评估和解释:对挖掘出来的模式进行评估和解释,判断其是否有意义,并提取其中的有用信息。
大数据的特点主要包括以下几个方面:
-
数据量大:大数据通常包括海量的数据,数据量超出了传统数据处理工具的处理能力。
-
多样性:大数据来自各种不同的数据源和类型,包括结构化、半结构化和非结构化的数据。
-
时效性:大数据通常需要实时或近实时处理,因为数据的产生和变化速度非常快。
-
高维度:大数据往往具有很高的维度,包括多个属性和特征,需要采用高效的算法进行处理和分析。
-
不确定性:大数据中包含了很多不确定性和噪声,需要采用特殊的技术来处理和过滤。
综上所述,数据挖掘是从大量数据中提取有价值的信息或模式的过程,而大数据则具有数据量大、多样性、时效性、高维度和不确定性等特点。
相关文章:

数据挖掘的基本概念和大数据的特点
数据挖掘是指从大量数据中提取有价值的信息或模式的过程。它通常使用计算机技术来分析数据,并利用统计学、机器学习、人工智能等方法来发现数据中的隐藏规律、趋势和关联性。 数据挖掘的基本概念包括以下几个方面: 数据预处理:对原始数据进行…...
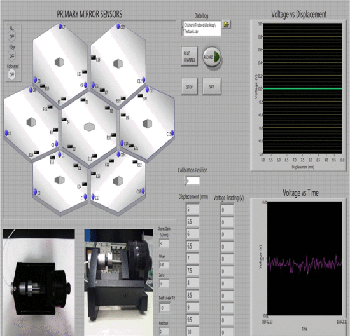
LabVIEW开发分段反射器测试台
LabVIEW开发分段反射器测试台 随着对太空的观察需求越来越远,而不是当前技术(如哈勃望远镜)所能达到的,有必要增加太空望远镜主镜的尺寸。但是,增加主镜像的大小时存在几个问题。随着反射镜尺寸的增加,制造…...

二级python和二级c哪个简单,二级c语言和二级python
大家好,小编为大家解答二级c语言和二级office一起报可以吗的问题。很多人还不知道计算机二级c语言和python哪个好考,现在让我们一起来看看吧! 介绍Python有很多库和使用Qt编写的接口,这自然创建c调用Python的需求。一路摸索,充满艰辛的添加头…...

E: Package ‘curl‘ has no installation candidate/ E:软件包没有可用的安装源
解决方案: 访问etc/apt/source.list 修改或者添加安装源 不用版本的Linux 有不同的配置比如我的是Debian 12 其他版本的去搜索引擎搜索即可 vim /etc/apt/source.list 改成修改或添加 // 以下是官方示例 deb http://deb.debian.org/debian bookworm main non-…...

代理模式及常见的3种代理类型对比
代理模式及常见的3种代理类型对比 代理模式代理模式分类静态代理JDK动态代理CGLIB动态代理Fastclass机制 三种代理方式之间对比常见问题 代理模式 代理模式是一种设计模式,提供了对目标对象额外的访问方式,即通过代理对象访问目标对象,这样可…...

8.6 校招 内推 面经
绿泡泡: neituijunsir 交流裙,内推/实习/校招汇总表格 1、面经 | 车载测试-23 面经 | 车载测试-23 2、校招 | 荣耀2024届全球校园招聘启动(内推) 校招 | 荣耀2024届全球校园招聘启动(内推) 3、校招 |…...

【大数据之Flume】七、Flume进阶之自定义Sink
(1)概述: Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。 Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Chan…...

vue对于时间的处理
2023-08-05 11:25:45 假如这个就是我们要传的时间字符串 比如今天是2023-08-05(同一天):现在把这个时间字符串传入到 formatDate()这个方法,就会给你返回 11:25 比如今天是2023-08-06(前一天&a…...

Apache DolphinScheduler 3.1.8 版本发布,修复 SeaTunnel 相关 Bug
近日,Apache DolphinScheduler 发布了 3.1.8 版本。此版本主要基于 3.1.7 版本进行了 bug 修复,共计修复 16 个 bug, 1 个 doc, 2 个 chore。 其中修复了以下几个较为重要的问题: 修复在构建 SeaTunnel 任务节点的参数时错误的判断条件修复 …...

科技云报道:一波未平一波又起?AI大模型再出邪恶攻击工具
AI大模型的快速向前奔跑,让我们见识到了AI的无限可能,但也展示了AI在虚假信息、深度伪造和网络攻击方面的潜在威胁。 据安全分析平台Netenrich报道,近日,一款名为FraudGPT的AI工具近期在暗网上流通,并被犯罪分子用于编…...

深度对话|如何设计合适的网络经济激励措施
近日,我们与Mysten Labs的首席经济学家Alonso de Gortari进行了对话,讨论了如何在网络运营商和参与者之间找到激励措施的平衡,以及Sui的经济如何不断发展。 是什么让您选择将自己的经济学背景应用于区块链和Web3领域? 起初&…...

opencv带GStreamer之Windows编译
目录 1、下载GStreamer和安装2. GSTReamer CMake配置3. 验证是否配置成功 1、下载GStreamer和安装 下载地址如下: gstreamer-1.0-msvc-x86_64-1.18.2.msi gstreamer-1.0-devel-msvc-x86_64-1.18.2.msi 安装目录无要求,主要是安装完设置环境变量 xxx\1…...
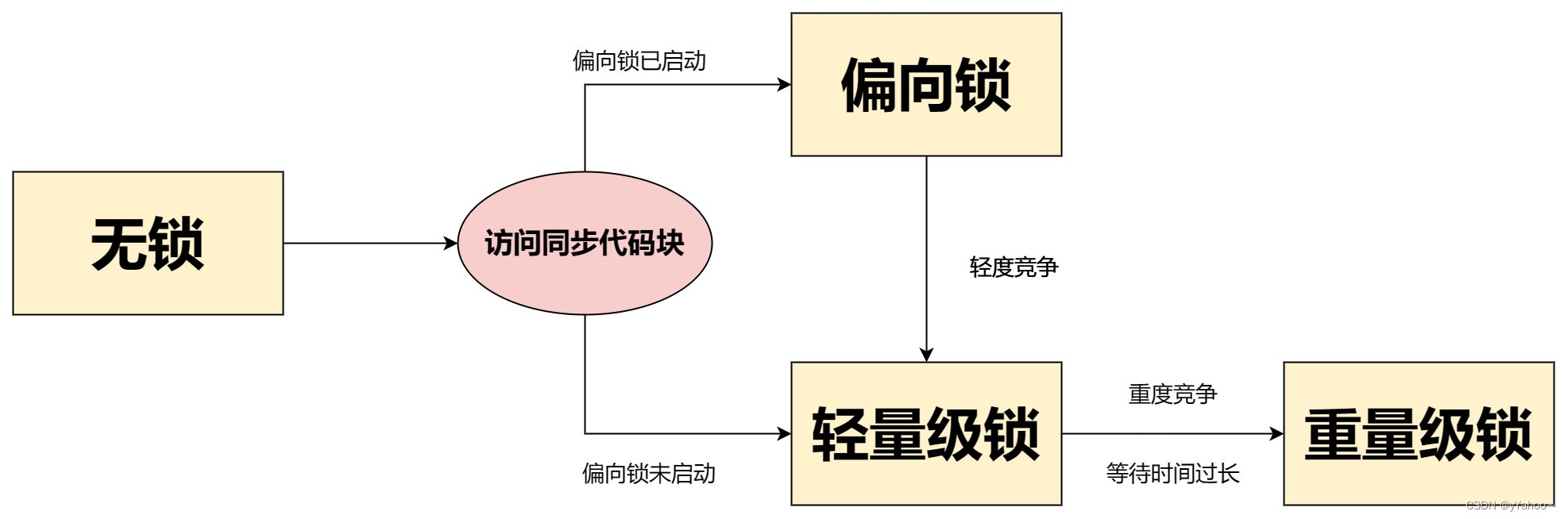
Java并发编程之锁的升级
Java 中的锁机制是多线程编程中的一部分。锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。 锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能…...
多核异构处理器A核与M核通信过程
多核异构处理器是指集成了不同类型或架构的CPU的系统级芯片(SoC)。 例如,有些处理器同时包含了高性能的A核(如Cortex-A)和低功耗的M核(如Cortex-M)。 这样的设计可以让不同的CPU负责不同的任务…...
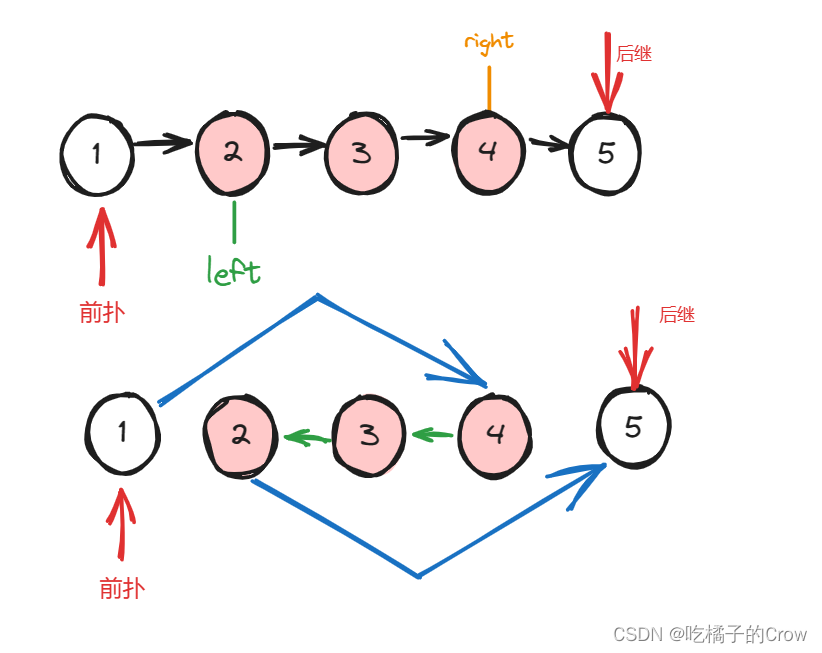
面试热题(反转链表)
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 链表的题,大部分都可以用指针或者递归可以做,指针如果做不出来的话,…...
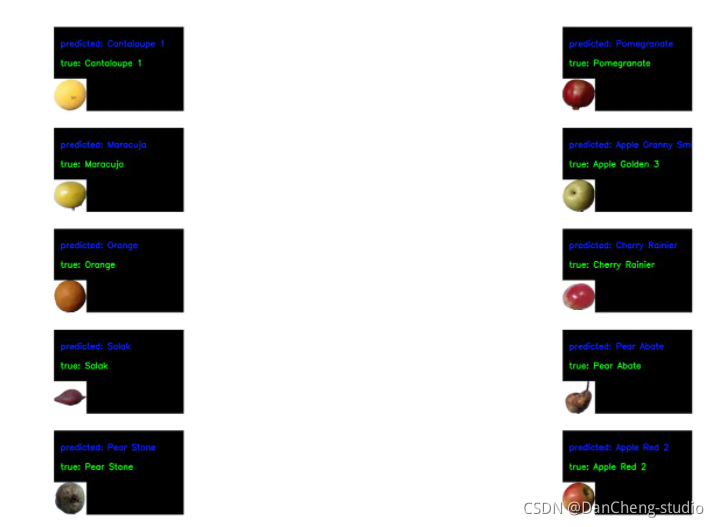
竞赛项目 深度学习的水果识别 opencv python
文章目录 0 前言2 开发简介3 识别原理3.1 传统图像识别原理3.2 深度学习水果识别 4 数据集5 部分关键代码5.1 处理训练集的数据结构5.2 模型网络结构5.3 训练模型 6 识别效果7 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习…...

Java项目部署云windows细节
springboot项目 pom文件中必须要有这个插件(正常其实都有就是我手贱以前不小心删除了) 他的作用是查找主类 <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-…...

软件功能测试有什么注意事项?功能测试报告起到什么作用?
软件功能测试是软件开发过程中至关重要的一环,它用于评估软件功能的质量和稳定性,并确保软件能够按照预期进行工作。然而,在进行功能测试时,有一些注意事项需要特别关注,以确保测试的准确性和有效性。 一、软件功能测…...

Kubernetes 调度 约束
调度约束 Kubernetes 是通过 List-Watch 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。 APIServer…...
Grafana技术文档-概念-《十分钟扫盲》
Grafana官网链接 Grafana: The open observability platform | Grafana Labs 基本概念 Grafana是一个开源的度量分析和可视化套件,常用于对大量数据进行实时分析和可视化。以下是Grafana的基本概念: 数据源(Data Source)&#…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

ubuntu22.04 安装docker 和docker-compose
首先你要确保没有docker环境或者使用命令删掉docker sudo apt-get remove docker docker-engine docker.io containerd runc安装docker 更新软件环境 sudo apt update sudo apt upgrade下载docker依赖和GPG 密钥 # 依赖 apt-get install ca-certificates curl gnupg lsb-rel…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...
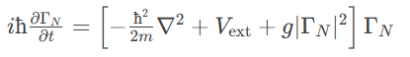
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...

门静脉高压——表现
一、门静脉高压表现 00:01 1. 门静脉构成 00:13 组成结构:由肠系膜上静脉和脾静脉汇合构成,是肝脏血液供应的主要来源。淤血后果:门静脉淤血会同时导致脾静脉和肠系膜上静脉淤血,引发后续系列症状。 2. 脾大和脾功能亢进 00:46 …...

StarRocks 全面向量化执行引擎深度解析
StarRocks 全面向量化执行引擎深度解析 StarRocks 的向量化执行引擎是其高性能的核心设计,相比传统行式处理引擎(如MySQL),性能可提升 5-10倍。以下是分层拆解: 1. 向量化 vs 传统行式处理 维度行式处理向量化处理数…...