解析从Linux零拷贝深入了解Linux-I/O(上)
本文将从文件传输场景以及零拷贝技术深究 Linux I/O 的发展过程、优化手段以及实际应用。
前言
存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性:
- 速度足够快:存储器的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储器;
- 容量足够大:容量能够存储计算机所需的全部数据;
- 价格足够便宜:价格低廉,所有类型的计算机都能配备。
但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件,于是现代计算机的存储器设计采用了一种分层次的结构:

从顶至底,现代计算机里的存储器类型分别有:寄存器、高速缓存、主存和磁盘 ,这些存储器的速度逐级递减而容量逐级递增。
存取速度最快的是寄存器 ,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理。
第二层是高速缓存 ,也即我们平时了解的 CPU 高速缓存 L1、L2、L3 ,一般 L1 是每个 CPU 独享,L3 是全部 CPU 共享,而 L2 则根据不同的架构设计会被设计成独享或者共享两种模式之一,比如 Intel 的多核芯片采用的是共享 L2 模式而 AMD 的多核芯片则采用的是独享 L2 模式。
第三层则是主存 ,也即主内存,通常称作随机访问存储器(Random Access Memory, RAM)。是与 CPU 直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质。
至于磁盘 则是图中离用户最远的一层了,读写速度相差内存上百倍;另一方面自然针对磁盘操作的优化也非常多,如零拷贝**、** direct I/O**、** 异步 I/O 等等,这些优化的目的都是为了提高系统的吞吐量;另外操作系统内核中也有磁盘高速缓存区、PageCache、TLB等,可以有效的减少磁盘的访问次数。
现实情况中,大部分系统在由小变大的过程中,最先出现瓶颈的就是I/O,尤其是在现代网络应用从 CPU 密集型转向了 I/O 密集型的大背景下,I/O越发成为大多数应用的性能瓶颈。
传统的 Linux 操作系统的标准 I/O 接口是基于数据拷贝操作的,即 I/O 操作会导致数据在操作系统内核地址空间的缓冲区和用户进程地址空间定义的缓冲区之间进行传输。设置缓冲区最大的好处是可以减少磁盘 I/O 的操作 ,如果所请求的数据已经存放在操作系统的高速缓冲存储器中,那么就不需要再进行实际的物理磁盘 I/O 操作;然而传统的 Linux I/O 在数据传输过程中的数据拷贝操作深度依赖 CPU ,也就是说 I/O 过程需要 CPU 去执行数据拷贝的操作,因此导致了极大的系统开销,限制了操作系统有效进行数据传输操作的能力。
这篇文章就从文件传输场景以及零拷贝 技术深究 Linux I/O的发展过程、优化手段以及实际应用。
需要了解的词
- DMA DMA,全称 Direct Memory Access,即直接存储器访问,是为了避免 CPU 在磁盘操作时承担过多的中断负载而设计的;在磁盘操作中,CPU 可将总线控制权交给 DMA 控制器,由 DMA 输出读写命令,直接控制 RAM 与 I/O 接口进行 DMA 传输,无需 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,使得 CPU 的效率大大提高。
- MMU Memory Management Unit—内存管理单元,主要实现:
- 竞争访问保护管理需求 :需要严格的访问保护,动态管理哪些内存页/段或区,为哪些应用程序所用。这属于资源的竞争访问管理需求;
- 高效的翻译转换管理需求 :需要实现快速高效的映射翻译转换,否则系统的运行效率将会低下;
- 高效的虚实内存交换需求 :需要在实际的虚拟内存与物理内存进行内存页/段交换过程中快速高效。
- Page Cache 为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核使用 页缓存(Page Cache) 机制来对文件中的数据进行缓存。

此外,由于读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」 。比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32 ~ 64 KB 也读取到 PageCache,这样后面读取 32 ~ 64 KB 的成本就很低,如果在 32 ~ 64 KB 淘汰出 PageCache 前,有进程读取到它了,收益就非常大。
虚拟内存 在计算机领域有一句如同摩西十诫般神圣的哲言:"计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决 ",从内存管理、网络模型、并发调度甚至是硬件架构,都能看到这句哲言在闪烁着光芒,而虚拟内存则是这一哲言的完美实践之一。虚拟内存为每个进程提供了一个一致的、私有且连续完整的内存空间 ;所有现代操作系统都使用虚拟内存,使用虚拟地址取代物理地址,主要有以下几点好处:利用上述的第一条特性可以优化,可以把内核空间和用户空间的虚拟地址映射到同一个物理地址 ,这样在 I/O 操作时就不需要来回复制了。

- 多个虚拟内存可以指向同一个物理地址;
- 虚拟内存空间可以远远大于物理内存空间;
- 应用层面可管理连续的内存空间,减少出错。
- NFS 文件系统 网络文件系统是 FreeBSD 支持的文件系统中的一种,也被称为 NFS;NFS 允许一个系统在网络上与它人共享目录和文件,通过使用 NFS,用户和程序可以象访问本地文件 一样访问远端系统上的文件。
- Copy-on-write 写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建 ,因此多个调用者只是读取操作时可以共享同一份资源。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
为什么要有 DMA
在没有 DMA 技术前,I/O 的过程是这样的:
- CPU 发出对应的指令给磁盘控制器,然后返回;
- 磁盘控制器收到指令后,于是就开始准备数据,会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个中断 ;
- CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据一次一个字节地读进自己的寄存器,然后再把寄存器里的数据写入到内存,而在数据传输的期间 CPU 是被阻塞的状态,无法执行其他任务。

整个数据的传输过程,都要需要 CPU 亲自参与拷贝数据,而且这时 CPU 是被阻塞的;简单的搬运几个字符数据那没问题,但是如果我们用千兆网卡或者硬盘传输大量数据的时候,都用 CPU 来搬运的话,肯定忙不过来。
计算机科学家们发现了事情的严重性后,于是就发明了 DMA 技术,也就是直接内存访问(Direct Memory Access) 技术。
简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务 。
具体流程如下图:

- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,释放 CPU;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 依然可以执行其它事务 ;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 中断信号,将数据从内核拷贝到用户空间,系统调用返回。
在有了 DMA 后,整个数据传输的过程,CPU 不再参与与磁盘交互的数据搬运工作,而是全程由 DMA 完成,但是 CPU 在这个过程中也是必不可少的,因为传输什么数据,从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
早期 DMA 只存在在主板上,如今由于 I/O 设备越来越多,数据传输的需求也不尽相同,所以每个 I/O 设备里面都有自己的 DMA 控制器。
传统文件传输的缺陷
有了 DMA 后,我们的磁盘 I/O 就一劳永逸了吗?并不是的;拿我们比较熟悉的下载文件举例,服务端要提供此功能,比较直观的方式就是:将磁盘中的文件读出到内存,再通过网络协议发送给客户端。
具体的 I/O 工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len)
write(socket, tmp_buf, len)代码很简单,虽然就两行代码,但是这里面发生了不少的事情:

这其中有:
- 4 次用户态与内核态的上下文切换 两次系统调用 read() 和 write()中,每次系统调用都得先从用户态切换到内核态 ,等内核完成任务后,再从内核态切换回用户态;上下文切换 的成本并不小,一次切换需要耗时几十纳秒到几微秒,在高并发场景下很容易成为性能瓶颈(参考线程切换和协程切换的成本差别 )。
- 4 次数据拷贝 两次由 DMA 完成拷贝,另外两次则是由 CPU 完成拷贝;我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 额外的资源,大大降低了系统性能。
所以,要想提高文件传输的性能,就需要减少用户态与内核态的上下文切换 和内存拷贝 的次数。
如何优化传统文件传输
减少「用户态与内核态的上下文切换」
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
减少「数据拷贝」次数
前面提到,传统的文件传输方式会历经 4 次数据拷贝;但很明显的可以看到:从内核的读缓冲区拷贝到用户的缓冲区 和从用户的缓冲区里拷贝到 socket 的缓冲区 」这两步是没有必要的。
因为在下载文件,或者说广义的文件传输场景中,我们并不需要在用户空间对数据进行再加工 ,所以数据并不需要回到用户空间中。
零拷贝
那么零拷贝 技术就应运而生了,它就是为了解决我们在上面提到的场景——跨过与用户态交互的过程,直接将数据从文件系统移动到网络接口而产生的技术。
零拷贝实现原理
零拷贝技术实现的方式通常有 3 种:
- mmap + write
- sendfile
- splice
mmap + write
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了省去这一步,我们可以用 mmap() 替换 read() 系统调用函数,伪代码如下:
buf = mmap(file, len)
write(sockfd, buf, len)mmap的函数原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);mmap() 系统调用函数会在调用进程的虚拟地址空间中创建一个新映射,直接把内核缓冲区里的数据「映射 」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。

具体过程如下:
- 应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里,应用进程跟操作系统内核「共享」这个缓冲区;
- 应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
- 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以看到,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile()如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:

带有 scatter/gather 的 sendfile 方式
Linux 2.4 内核进行了优化,提供了带有 scatter/gather 的 sendfile 操作,这个操作可以把最后一次 CPU COPY 去除。其原理就是在内核空间 Read BUffer 和 Socket Buffer 不做数据复制,而是将 Read Buffer 的内存地址、偏移量记录到相应的 Socket Buffer 中,这样就不需要复制。其本质和虚拟内存的解决方法思路一致,就是内存地址的记录。
你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:

splice 方式
splice 调用和sendfile 非常相似,用户应用程序必须拥有两个已经打开的文件描述符,一个表示输入设备,一个表示输出设备。与sendfile不同的是,splice允许任意两个文件互相连接,而并不只是文件与socket进行数据传输。对于从一个文件描述符发送数据到socket这种特例来说,一直都是使用sendfile系统调用,而splice一直以来就只是一种机制,它并不仅限于sendfile的功能。也就是说 sendfile 是 splice 的一个子集。
splice() 是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以splice()的两个入参文件描述符要求必须有一个是管道设备。
使用 splice() 完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用 pipe(),从用户态陷入内核态;创建匿名单向管道,pipe() 返回,上下文从内核态切换回用户态;
- 用户进程调用 splice(),从用户态陷入内核态;
- DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端"拷贝"进管道,splice()返回,上下文从内核态回到用户态;
- 用户进程再次调用 splice(),从用户态陷入内核态;
- 内核把数据从管道的读取端拷贝到socket缓冲区,DMA 控制器将数据从socket缓冲区拷贝到网卡;
- splice() 返回,上下文从内核态切换回用户态。

在 Linux 2.6.17 版本引入了 splice,而在 Linux 2.6.23 版本中, sendfile 机制的实现已经没有了,但是其 API 及相应的功能还在,只不过 API 及相应的功能是利用了 splice 机制来实现的。
和 sendfile 不同的是,splice 不需要硬件支持。
零拷贝的实际应用
Kafka
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {return fileChannel.transferTo(position, count, socketChannel);
}如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
Nginx
Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
http {
...sendfile on
...
}由于文章篇幅过长,下文继续讲解!

相关文章:
解析从Linux零拷贝深入了解Linux-I/O(上)
本文将从文件传输场景以及零拷贝技术深究 Linux I/O 的发展过程、优化手段以及实际应用。前言 存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性: 速度足够快:存储器的存取速度应当快于 CPU …...

JavaScript系列之公有、私有和静态属性和方法
文章の目录一、公有属性、公有方法1、定义2、理解3、ES54、ES6二、私有属性、私有方法1、定义2、理解3、ES54、ES6三、静态属性、静态方法1、定义2、理解3、ES54、ES6写在最后一、公有属性、公有方法 1、定义 指的是所属这个类的所有对象都可以访问的属性,叫做公有…...

过滤器与拦截器
文章目录一、前言1、概述2、过滤器与拦截器异同2.1 简介2.2 异同2.3 总结3、Filters vs HandlerInterceptors二、过滤器1、概述2、生命周期2.1 生命周期概述2.2 基于函数回调实现原理3、自定义过滤器两种实现方式3.1 WebFilter注解注册3.2 过滤器(配置类注册过滤器&…...

spring boot 和cloud 版本升级
spring boot 和cloud 版本对应 背景:原来一直用的版本是Hoxton.SR12 2.3.10.RELEASE(SR12一路升,几乎没有影响,不需要测试,但是换大版本就有点担心) 去年2022年底黑鸭子报漏洞把springboot,clou…...
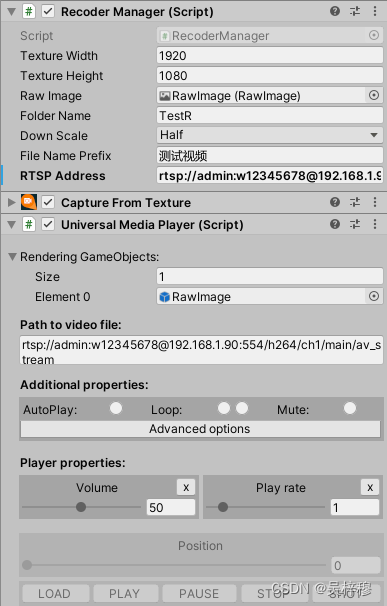
untiy 录制网络摄像头视频并保存到本地文件
网络摄像头使用的是海康威视的,关于如何使用Ump插件播放海康威视rtsp视频流,请参考我的这篇文章 内部有ump插件的下载链接 untiy接入 海康威视网络摄像头 录屏使用的插件是 AVPro movieCapture 4.6.3版, 插件和完整工程的下载链接放在本文的…...
部署)
微服务架构设计模式-(15)部署
关联概念 流程 将软件投入到生产环境 架构 软件运行的环境结构 生产环境四个关键功能 服务管理接口 使开发人员能够创建、更新和配置服务 运行时服务管理 确保始终运行一定数量的服务实例非中断更新 监控 让开发人员了解服务情况,包括日志文件和各种应用指标可观…...
Redis:数据结构
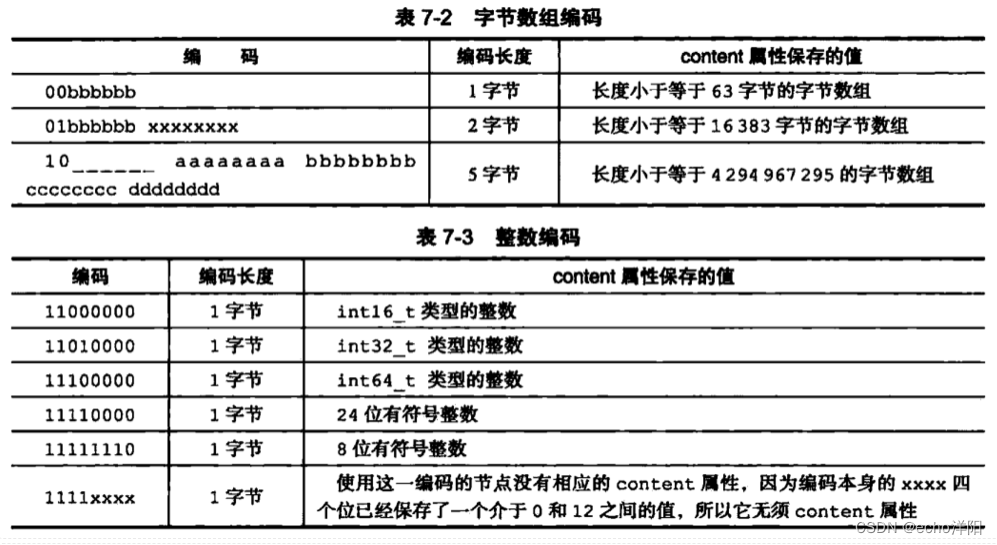
简单动态字符串SDS Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串),而是自己构 建了一种名为简单动态字符串(simple dynamic string, SDS)的抽象类型,并将SDS用作Redis的默认字符 串表示。 SDS 的实现…...
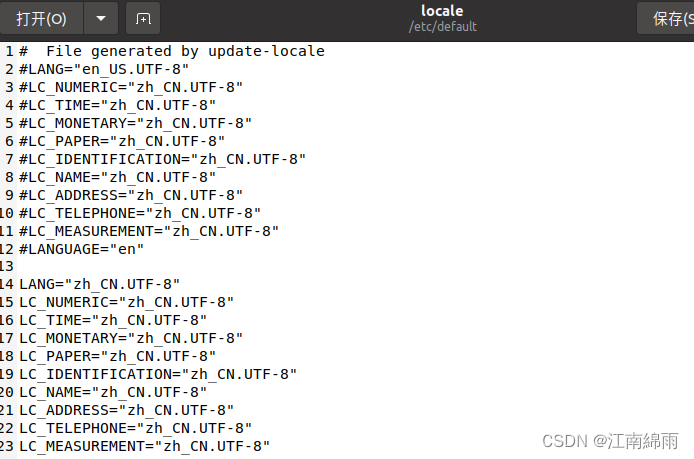
2.18 设置language和中文输入法
文章目录一:设置language二:设置中文输入法一:设置language nvidia的开发板上默认只有English,需要点击如下管理: 接着进入如下界面: 此时图中的“汉语(中国)”应该是没有的&…...
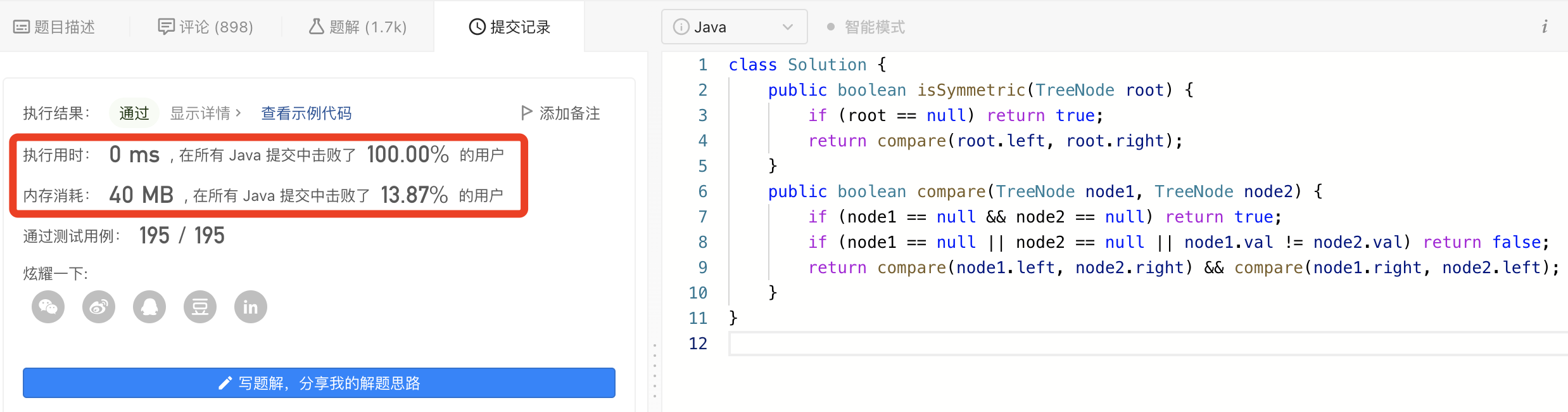
图解LeetCode——剑指 Offer 28. 对称的二叉树
一、题目 请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。 二、示例 2.1> 示例 1: 【输入】root [1,2,2,3,4,4,3] 【输出】true 2.2> 示例 2: 【输入】root [1,2,2,nul…...
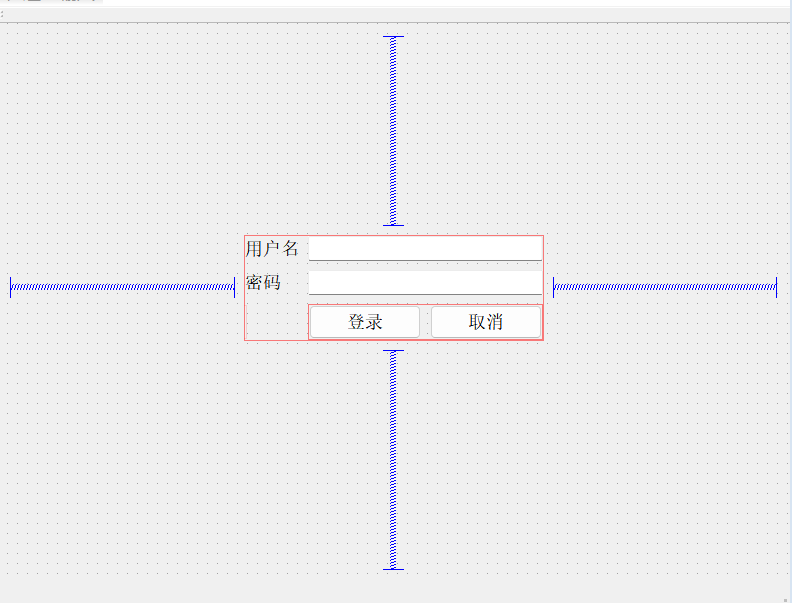
Qt Desginer布局方法
首先将我们需要的控件拖拽到一个合适的位置,该例子中用到了两个label,两个lineEdit和两个pushButton。 然后我们需要利用弹簧来控制控件到控件之间的距离以及控件到窗体边界的距离,因为这里只有一组控件(两个label,两个…...
)
C/C++、Java、Python的比较及学习(3)
函数间的值传递与地址传递 值传递方式:指主调函数把实参的值赋给形参。 在这种传递方式下,主调函数中的实参地址与被调函数中的形参地址是相互独立的。 函数被调用时,系统为形参变量分配内存单元,并将实参的值存入到对应形参的内存…...

智慧校园建设方案
第一章、 智慧教学 6.1. 校本资源库 提供校本资源管理功能,实现学校内的教学资源的共建共享,促进教师之间的交流学习,提升学校的整体教学水平。在本系统中学校可以统一采购资源接入到校本资源库中供教师下载使用,教师也可以将…...
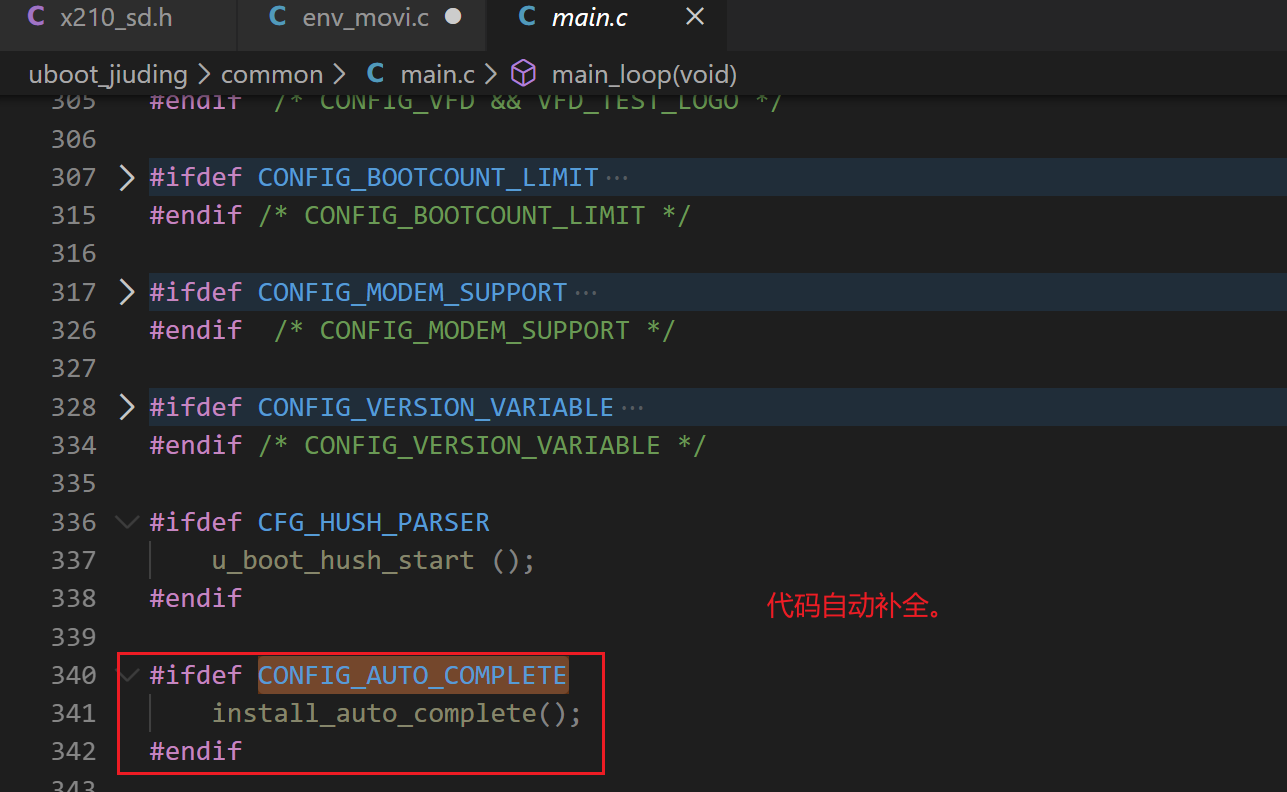
ARM uboot 源码分析5 -启动第二阶段
一、start_armboot 解析6 1、console_init_f (1) console_init_f 是 console(控制台)的第一阶段初始化。_f 表示是第一阶段初始化,_r 表示第二阶段初始化。有时候初始化函数不能一次一起完成,中间必须要夹杂一些代码,…...

【ip neigh】管理IP邻居( 添加ARP\NDP静态记录、删除记录、查看记录)
一、邻居管理存在状态 1、NUD_NONE: 初始状态。当一个新的路由缓存条目被创建时,arp_bind_neighbour()函数被调用.如果找不到相匹配的ARP缓存条目, neigh_alloc()将创建一个新的ARP缓存条目并设置状态为NUD_NONE. 2、NUD_INCOMPLETE:未完成状…...
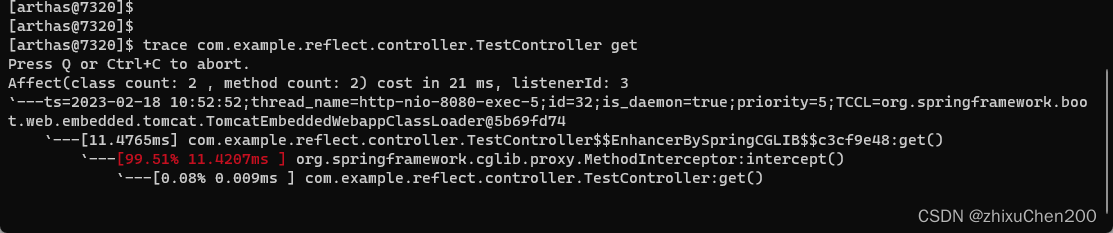
Java程序员线上排查问题神器-Arthas
文章目录前言一、Arthas是什么?二、快速入门1.下载2.如何运行三、常用命令1.dashboard2.trace总结前言 最近公司项目版本迭代升级,在开发新需求导致没什么时间写博客。 在开发需求的过程中,我写了一个接口,去批量调内部已经写好…...
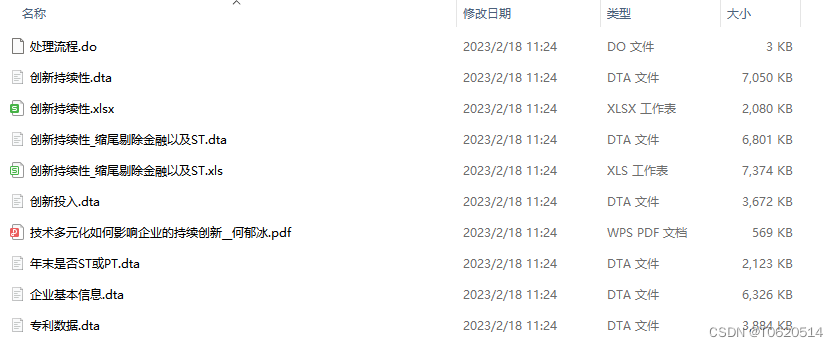
上市公司企业持续创新能力、创新可持续性(原始数据+计算代码+计算结果)(2008-2021年)
数据来源:自主计算 时间跨度:2008-2021年 区域范围:沪深A股上市公司 指标说明: 参考何郁冰(2017)[1]的做法,将持续创新作为独立研究变量,同时采用创新投入指标(研发经费) 和创新…...
)
华为OD机试 - 考古学家(JS)
考古学家 题目 有一个考古学家发现一个石碑 但是很可惜 发现时其已经断成多段 原地发现N个断口整齐的石碑碎片 为了破解石碑内容 考古学家希望有程序能帮忙计算复原后的石碑文字组合数 你能帮忙吗 备注: 如果存在石碑碎片内容完全相同,则由于碎片间的顺序不影响复原后的碑…...

Leetcode.2100 适合打劫银行的日子
题目链接 Leetcode.2100 适合打劫银行的日子 Rating : 1702 题目描述 你和一群强盗准备打劫银行。给你一个下标从 0开始的整数数组 security,其中 security[i]是第 i天执勤警卫的数量。日子从 0开始编号。同时给你一个整数 time。 如果第 i天满足以下所…...

linux ubuntu查日志信息以及错误排查
目录 一、linux的日志文件 1、常用日志文件 2、其他日志文件 二、历史日志的查看 1、查看Logrotate的配置信息 2、查看日志配置 一、linux的日志文件 Linux系统中最有趣的(可能也是最重要的)目录之一是/var/log。根据文件系统层次结构标准,在系统中运行的大多数…...

DOS经典软件,落下帷幕,新型国产平台,蓬勃发展
提起DOS时代,总让人难以忘怀,陷入深深回忆中,风靡一时的许多软件,如今早已不在,这几款被称为DOS必装的软件,更是让人惋惜。 你还记得这图吗?堪称DOS系统最经典的软盘复制与映像生成软件…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...
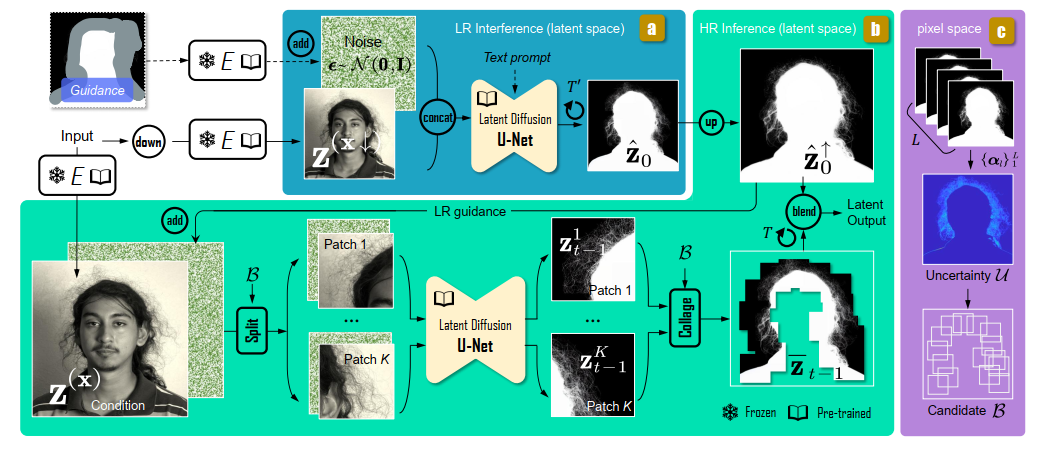
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...