高可用的“异地多活”架构设计
前言
后台服务可以划分为两类,有状态和无状态。高可用对于无状态的应用来说是比较简单的,无状态的应用,只需要通过 F5 或者任何代理的方式就可以很好的解决。后文描述的主要是针对有状态的服务进行分析。
服务端进行状态维护主要是通过磁盘或内存进行保存,比如 MySQL 数据库,redis 等内存数据库。除了这两种类型的维护方式,还有 jvm 的内存的状态维持,但jvm的状态生命周期通常很短。
高可用
1、高可用的一些解决方案
高可用,从发展来看,大致经过了这几个过程:
-
冷备
-
双机热备
-
同城双活
-
异地双活
-
异地多活
在聊异地多活的时候,还是先看一些其他的方案,这有利于我们理解很多设计的缘由。
冷备
冷备,通过停止数据库对外服务的能力,通过文件拷贝的方式将数据快速进行备份归档的操作方式。简而言之,冷备,就是复制粘贴,在 linux 上通过 cp 命令就可以很快完成。可以通过人为操作,或者定时脚本进行。有如下好处:
-
简单
-
快速备份(相对于其他备份方式)
-
快速恢复。只需要将备份文件拷贝回工作目录即完成恢复过程(亦或者修改数据库的配置,直接将备份的目录修改为数据库工作目录)。更甚,通过两次mv命令就可瞬间完成恢复。
-
可以按照时间点恢复。比如,几天前发生的拼多多优惠券漏洞被人刷掉很多钱,可以根据前一个时间点进行还原,“挽回损失”。
以上的好处,对于以前的软件来说,是很好的方式。但是对于现如今的很多场景,已经不好用了,因为:
-
服务需要停机。n个9肯定无法做到了。然后,以前我们的停机冷备是在凌晨没有人使用的时候进行,但是现在很多的互联网应用已经是面向全球了,所以,任何时候都是有人在使用的。
-
数据丢失。如果不采取措施,那么在完成了数据恢复后,备份时间点到还原时间内的数据会丢失。传统的做法,是冷备还原以后,通过数据库日志手动恢复数据。比如通过 redo日志,更甚者,我还曾经通过业务日志去手动回放请求恢复数据。恢复是极大的体力活,错误率高,恢复时间长。
-
冷备是全量备份。全量备份会造成磁盘空间浪费,以及容量不足的问题,只能通过将备份拷贝到其他移动设备上解决。所以,整个备份过程的时间其实更长了。
-
想象一下每天拷贝几个T的数据到移动硬盘上,需要多少移动硬盘和时间。并且,全量备份是无法定制化的,比如只备份某一些表,是无法做到的。
如何权衡冷备的利弊,是每个业务需要考虑的。
双机热备
热备,和冷备比起来,主要的差别是不用停机,一边备份一边提供服务。但还原的时候还是需要停机的。由于我们讨论的是和存储相关的,所以不将共享磁盘的方式看作双机热备。
- Active/Standby模式
相当于1主1从,主节点对外提供服务,从节点作为backup。通过一些手段将数据从主节点同步到从节点,当故障发生时,将从节点设置为工作节点。数据同步的方式可以是偏软件层面,也可以是偏硬件层面的。偏软件层面的,比如mysql的master/slave方式,通过同步binlog的方式;sqlserver的订阅复制方式。偏硬件层面,通过扇区和磁盘的拦截等镜像技术,将数据拷贝到另外的磁盘。偏硬件的方式,也被叫做数据级灾备;偏软件的,被叫做应用级灾备。后文谈得更多的是应用级灾备。
- 双机互备
本质上还是Active/Standby,只是互为主从而已。双机互备并不能工作于同一个业务,只是在服务器角度来看,更好的压榨了可用的资源。比如,两个业务分别有库A和B,通过两个机器P和Q进行部署。那么对于A业务,P主Q从,对于B业务,Q主P从。整体上看起来是两个机器互为主备。这种架构下,读写分离是很好的,单写多读,减少冲突又提高了效率。
其他的高可用方案还可以参考各类数据库的多种部署模式,比如mysql的主从、双主多从、MHA;redis 的主从,哨兵,cluster 等等。
2、同城双活
前面讲到的几种方案,基本都是在一个局域网内进行的。业务发展到后面,有了同城多活的方案。和前面比起来,不信任的粒度从机器转为了机房。这种方案可以解决某个IDC机房整体挂掉的情况(停电,断网等)。
同城双活其实和前文提到的双机热备没有本质的区别,只是“距离”更远了,基本上还是一样(同城专线网速还是很快的)。双机热备提供了灾备能力,双机互备避免了过多的资源浪费。
在程序代码的辅助下,有的业务还可以做到真正的双活,即同一个业务,双主,同时提供读写,只要处理好冲突的问题即可。需要注意的是,并不是所有的业务都能做到。
业界更多采用的是两地三中心的做法。远端的备份机房能更大的提供灾备能力,能更好的抵抗地震,恐袭等情况。双活的机器必须部署到同城,距离更远的城市作为灾备机房。灾备机房是不对外提供服务的,只作为备份使用,发生故障了才切流量到灾备机房;或者是只作为数据备份。原因主要在于:距离太远,网络延迟太大。

图1 两地三中心
如上图,用户流量通过负载均衡,将服务A的流量发送到IDC1,服务器集A;将服务B的流量发送到IDC2,服务器B;同时,服务器集a和b分别从A和B进行同城专线的数据同步,并且通过长距离的异地专线往IDC3进行同步。当任何一个IDC当机时,将所有流量切到同城的另一个IDC机房,完成了failover。
当城市1发生大面积故障时,比如发生地震导致IDC1和2同时停止工作,则数据在IDC3得以保全。同时,如果负载均衡仍然有效,也可以将流量全部转发到IDC3中。不过,此时IDC3机房的距离非常远,网络延迟变得很严重,通常用户的体验的会受到严重影响的。

图2 两地三中心主从模式
上图是一种基于Master-Slave模式的两地三中心示意图。城市1中的两个机房作为1主1从,异地机房作为从。也可以采用同城双主+keepalived+vip的方式,或者MHA的方式进行failover。但城市2不能(最好不要)被选择为Master。
3、异地双活
同城双活可以应对大部分的灾备情况,但是碰到大面积停电,或者自然灾害的时候,服务依然会中断。对上面的两地三中心进行改造,在异地也部署前端入口节点和应用,在城市1停止服务后将流量切到城市2,可以在降低用户体验的情况下,进行降级。但用户的体验下降程度非常大。
所以大多数的互联网公司采用了异地双活的方案。

图3 简单的异地双活示意图
上图是一个简单的异地双活的示意图。流量经过LB后分发到两个城市的服务器集群中,服务器集群只连接本地的数据库集群,只有当本地的所有数据库集群均不能访问,才failover到异地的数据库集群中。
在这种方式下,由于异地网络问题,双向同步需要花费更多的时间。更长的同步时间将会导致更加严重的吞吐量下降,或者出现数据冲突的情况。吞吐量和冲突是两个对立的问题,你需要在其中进行权衡。例如,为了解决冲突,引入分布式锁/分布式事务;为了解决达到更高的吞吐量,利用中间状态、错误重试等手段,达到最终一致性;降低冲突,将数据进行恰当的sharding,尽可能在一个节点中完成整个事务。
对于一些无法接受最终一致性的业务,饿了么采用的是下图的方式:

对于个别一致性要求很高的应用,我们提供了一种强一致的方案(Global Zone),Globa Zone是一种跨机房的读写分离机制,所有的写操作被定向到一个 Master 机房进行,以保证一致性,读操作可以在每个机房的 Slave库执行,也可以 bind 到 Master 机房进行,这一切都基于我们的数据库访问层(DAL)完成,业务基本无感知。
——《饿了么异地多活技术实现(一)总体介绍》
也就是说,在这个区域是不能进行双活的。采用主从而不是双写,自然解决了冲突的问题。
实际上,异地双活和异地多活已经很像了,双活的结构更为简单,所以在程序架构上不用做过多的考虑,只需要做传统的限流,failover等操作即可。但其实双活只是一个临时的步骤,最终的目的是切换到多活。因为双活除了有数据冲突上的问题意外,还无法进行横向扩展。
异地多活

图4 异地多活的示意图
根据异地双活的思路,我们可以画出异地多活的一种示意图。每个节点的出度和入度都是4,在这种情况下,任何节点下线都不会对业务有影响。但是,考虑到距离的问题,一次写操作将带来更大的时间开销。时间开销除了影响用户体验以外,还带来了更多的数据冲突。在严重的数据冲突下,使用分布式锁的代价也更大。这将导致系统的复杂度上升,吞吐量下降。所以上图的方案是无法使用的。
回忆一下我们在解决网状网络拓扑的时候是怎么优化的?引入中间节点,将网状改为星状:

图5 星状的异地多活
改造为上图后,每个城市下线都不会对数据造成影响。对于原有请求城市的流量,会被重新 LoadBalance 到新的节点(最好是LB到最近的城市)。为了解决数据安全的问题,我们只需要针对中心节点进行处理即可。但是这样,对于中心城市的要求,比其他城市会更高。比如恢复速度,备份完整性等,这里暂时不展开。我们先假定中心是完全安全的。
如果我们已经将异地多活的业务部署为上图的结构,很大程度解决了数据到处同步的问题,不过依然会存在大量的冲突,冲突的情况可以简单认为和双活差不多。那么还有没有更好的方式呢?
这里可以关联一下饿了么的 GlobalZone 方案,总体思路就是“去分布式”,也就是说将写的业务放到一个节点的(同城)机器上。阿里是这么思考的:

阿里理想中的异地多活架构
实际上我猜测很多业务也是按照上图去实现的,比如滴滴打车业务这种,所有的业务都是按城市划分开的。用户、车主、目的地,他们的经纬度通常都是在同一个城市的。单个数据中心并不需要和其他数据中心进行数据交互,只有在统计出报表的时候才需要,但报表是不太注重实时性的。那么,在这种情况下,全国的业务其实可以被很好的sharding的。
但是对于电商这种复杂的场景和业务,按照前文说的方式进行sharding已经无法满足需求了。因为业务线非常复杂,数据依赖也非常复杂,每个数据中心相互进行数据同步的情况无可避免。淘宝的解决方式和我们切分微服务的方式有点类似:
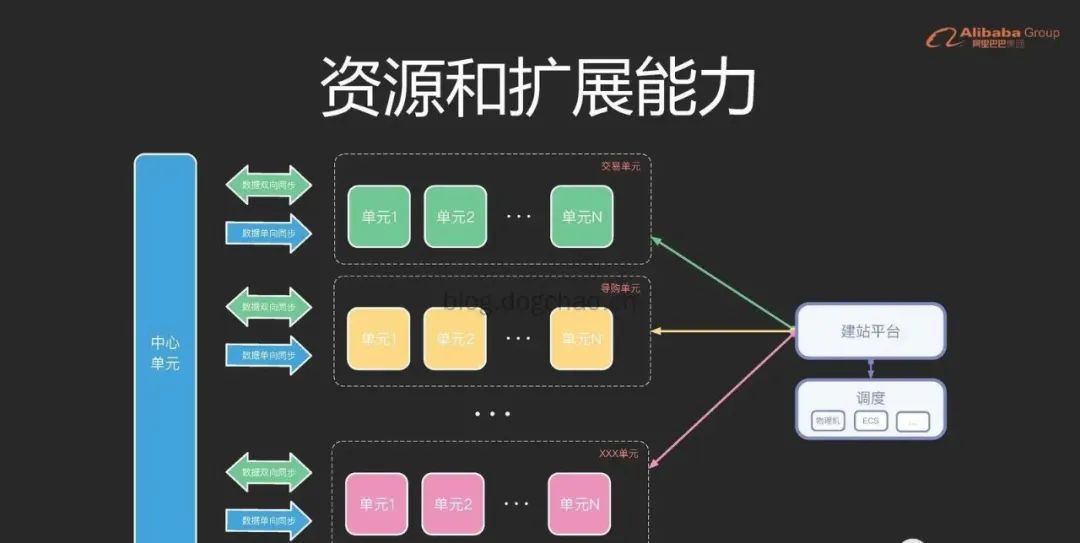
淘宝按照单元切分的异地多活架构
注意看图中的数据同步箭头。以交易单元为例,属于交易单元的业务数据,将与中心单元进行双向同步;不属于交易单元的业务数据,单向从中心单元同步。中心单元承担了最复杂的业务场景,业务单元承担了相对单一的场景。对于业务单元,可以进行弹性伸缩和容灾;对于中心单元,扩展能力较差,稳定性要求更高。可以遇见,大部分的故障都会出现在中心单元。
按照业务进行单元切分,已经需要对代码和架构进行彻底的改造了(可能这也是为什么阿里要先从双活再切到多活,历时3年)。比如,业务拆分,依赖拆分,网状改星状,分布式事务,缓存失效等。除了对于编码的要求很高以外,对测试和运维也有非常大的挑战。
如此复杂的情况,如何进行自动化覆盖,如何进行演练,如何改造流水线。这种级别的灾备,不是一般公司敢做的,投入产出也不成正比。不过还是可以把这种场景当作我们的“假想敌”,去思考我们自己的业务,未来会怎么发展,需要做到什么级别的灾备。相对而言,饿了么的多活方案可能更适合大多数的企业。
本文只是通过画图的方式进行了简单的描述,其实异地多活是需要很多很强大的基础能力的。比如,数据传输,数据校验,数据操作层(简化客户端控制写和同步的过程)等。
相关文章:
高可用的“异地多活”架构设计
前言 后台服务可以划分为两类,有状态和无状态。高可用对于无状态的应用来说是比较简单的,无状态的应用,只需要通过 F5 或者任何代理的方式就可以很好的解决。后文描述的主要是针对有状态的服务进行分析。 服务端进行状态维护主要是通过磁盘…...
【面试题】Map和Set
1. Map和Object的区别 形式不同 // Object var obj {key1: hello,key2: 100,key3: {x: 100} } // Map var m new Map([[key1, hello],[key2, 100],[key3, {x: 100}] ])API不同 // Map的API m.set(name, 小明) // 新增 m.delete(key2) // 删除 m.has(key3) // …...

Spring之事务底层源码解析
Spring之事务底层源码解析 1、EnableTransactionManagement工作原理 开启 Spring 事务本质上就是增加了一个 Advisor,当我们使用 EnableTransactionManagement 注解来开启 Spring 事务时,该注解代理的功能就是向 Spring 容器中添加了两个 Bean…...

【华为OD机试真题 Python】创建二叉树
前言:本专栏将持续更新华为OD机试题目,并进行详细的分析与解答,包含完整的代码实现,希望可以帮助到正在努力的你。关于OD机试流程、面经、面试指导等,如有任何疑问,欢迎联系我,wechat:steven_moda;email:nansun0903@163.com;备注:CSDN。 题目描述 请按下列描达构建…...
RuoYi-Vue-Plus搭建(若依)
项目简介 1.RuoYi-Vue-Plus 是重写 RuoYi-Vue 针对 分布式集群 场景全方位升级(不兼容原框架)2.环境安装参考:https://blog.csdn.net/tongxin_tongmeng/article/details/128167926 JDK 11、MySQL 8、Redis 6.X、Maven 3.8.X、Nodejs > 12、Npm 8.X3.IDEA环境配置…...

uboot和linux内核移植流程简述
一、移植uboot流程 1、从半导体芯片厂下载对应的demo,然后编译测试demo版的uboot 开发板基本都是参考半导体厂商的 dmeo 板,而半导体厂商会在他们自己的开发板上移植好 uboot、linux kernel 和 rootfs 等,最终制作好 BSP包提供给用户。我们可…...

【CS224W】(task2)传统图机器学习和特征工程
note 和CS224W课程对应,将图的基本表示写在task1笔记中了;传统图特征工程:将节点、边、图转为d维emb,将emb送入ML模型训练Traditional ML Pipeline Hand-crafted feature ML model Hand-crafted features for graph data Node-l…...
【算法基础】并查集⭐⭐⭐⭐⭐【思路巧,代码短,面试常考】
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题近几年来反复出现在信息学的国际国内赛题中。其特点是看似并不复杂,但数据量…...

人工智能轨道交通行业周刊-第34期(2023.2.13-2.19)
本期关键词:智慧地铁、枕簧检测选配机器人、智慧工地、接触网检修、工业缺陷检测 1 整理涉及公众号名单 1.1 行业类 RT轨道交通人民铁道世界轨道交通资讯网铁路信号技术交流北京铁路轨道交通网上榜铁路视点ITS World轨道交通联盟VSTR铁路与城市轨道交通RailMetro…...
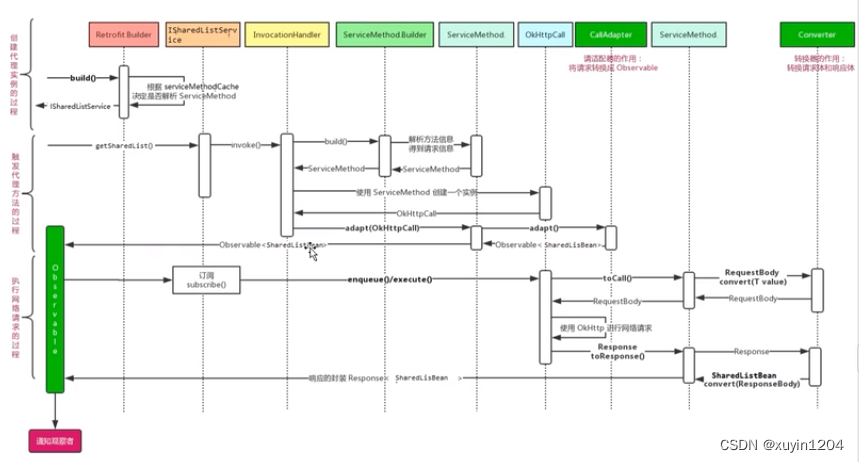
Retrofit 网络框架源码解析(二)
目录一、Okhttp请求二、Retrofit 请求retrofit是如何封装请求的三、Retrofit的构建过程四、Retrofit构建IxxxService对象的过程(Retrofit.create())4.1 动态代理4.2 ServiceMethod4.3 okHttpCall4.4 callAdapter五、Retrofit网络请求操作一、Okhttp请求 …...
SQL Server 2008新特性——更改跟踪
在大型的数据库应用中,经常会遇到部分数据的脱机和多个数据库的合并问题。比如现在有一个全省范围使用的应用程序,每个市都部署了单独的相同的应用程序服务器和数据库服务器,每个月需要将全省所有市的数据全部汇总起来用于出全省的报表&#…...

四六级真题长难句分析与应用
一、基本结构的长难句 基本结构的长难句主要考点:断开和简化 什么是长难句? 其实就是多件事连在了一块,这时候句子就变长、变难了 分析步骤: 第一件事就是要把长难句给断开,把多件事断开成一件一件的事情࿰…...
 | 机试题算法+思路 【2023】)
华为OD机试 - 玩牌高手(Python) | 机试题算法+思路 【2023】
最近更新的博客 华为OD机试 - 寻找路径 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 五键键盘 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - IPv4 地址转换成整数 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试 - 对称美学 | 备考思路,刷题要点,答疑 …...
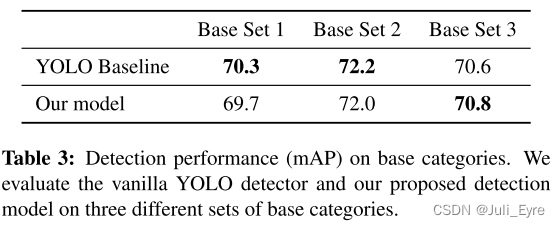
【论文阅读】 Few-shot object detection via Feature Reweighting
Few-shot object detection的开山之作之一 ~~ 特征学习器使用来自具有足够样本的基本类的训练数据来 提取 可推广以检测新对象类的meta features。The reweighting module将新类别中的一些support examples转换为全局向量,该全局向量indicates meta features对于检…...

现代卷积神经网络经典架构图
卷积神经网络(LeNet) LeNet 的简化版深层卷积神经网络(AlexNet) 从LeNet(左)到AlexNet(右)改进: dropOut层 - 不改变期望但是改变方差ReLU层 - 减缓梯度消失MaxPooling数…...
有关eclipse的使用tips
一、alt/键 会产生单词提示,可以提高编程速度。例如不需要辛辛苦苦的打出:System.out.println();整句,只需要在eclipse中输入syso,然后按住ALT/就会出来System.out.println();在alt键/不管用的情况下,可使用以下方法来…...
之CRUD)
Mybatis(4)之CRUD
首先是 增 ,我们要在数据库中增加一个数据 先来看看我们之前的插入语句 <insert id"insertRole">insert into try(id,name,age) values(3,nuonuo,20)</insert> 请注意,我们这里的 insert 是固定的,但在实际的业务场…...

OSG三维渲染引擎编程学习之五十七:“第五章:OSG场景渲染” 之 “5.15 光照”
目录 第五章 OSG场景渲染 5.15 光照 5.15.1 osg::Light光 5.15.2 osg::LightSource光源 第五章 OSG场景渲染 OSG存在场景树和渲染树,“场景数”的构建在第三章“OSG场景组织”已详细阐明,本章开始深入探讨“渲染树”。 渲染树一棵以状态集(StateSet)和渲染叶(RenderLe…...
[教你传话,表白,写信]
第一步 关注飞鸽传话助手 第二部 点击链接进入 第三步 点击发送,输入内容 第四步 就可以收到了...

物联网在智慧农业中的应用
随看现代科技的不断发展,近年来我国农业的进步是显而易见的。从八九十年代农业生产以人力为主,到之后的机械渐渐代替人力,再到如今物联网技术在农业领域的应用,多种前沿技术应用于农业物联网,对智慧农业生产的各个环节…...

AI科技日报-2026年5月22日
AI科技日报 日期:2026年5月22日人工智能正在从“会生成”向“会规划、会行动”进化,2026年成为全球AI发展的关键之年。以下为今日重要资讯。 一、大模型竞赛持续升级 OpenAI、谷歌、深度求索等顶尖AI企业正在发布规模更大或效率更高的最新版本大模型。斯…...

三星固件下载神器Bifrost:跨平台一站式解决方案深度解析
三星固件下载神器Bifrost:跨平台一站式解决方案深度解析 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost Bifrost是一款基于Kotlin Multiplatform构建…...

FTP明文传输风险与Wireshark抓包实证分析
1. 这不是危言耸听:FTP 的“裸奔”现状每天都在发生你有没有在公司内网用过 FTP 上传一份财务报表?有没有在校园网里用 FileZilla 向老师提交课程设计源码?有没有在运维后台用 ftp 命令同步过网站静态资源?如果答案是肯定的&#…...
)
AI Agent在体脂管理中的临床级精度突破:基于3276名受试者的双盲对照试验(FDA Class II类器械预审中)
更多请点击: https://kaifayun.com 第一章:AI Agent在体脂管理中的临床级精度突破:基于3276名受试者的双盲对照试验(FDA Class II类器械预审中) 临床验证设计与核心指标达成 本研究采用多中心、随机、双盲、平行对照…...

【紧急预警】2025年起Steam/Epic将强制要求AI生成内容标注——游戏公司AI Agent内容溯源方案已迫在眉睫
更多请点击: https://intelliparadigm.com 第一章:AI Agent游戏行业应用的监管变局与战略意义 近年来,AI Agent在游戏开发、智能NPC行为建模、动态剧情生成及玩家个性化体验优化等领域加速落地,引发全球监管机构高度关注。欧盟《…...

10分钟完成AI智能图像分层:layerdivider完整使用指南
10分钟完成AI智能图像分层:layerdivider完整使用指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经花费数小时手动分离插图中的不…...

为什么头部科技公司集体弃用Workday转向Lindy?——基于14家客户迁移数据的自动化人效拐点分析
更多请点击: https://intelliparadigm.com 第一章:Lindy人力资源自动化方案的演进逻辑与战略定位 Lindy人力资源自动化方案并非孤立的技术堆叠,而是根植于企业数字化成熟度跃迁与HR职能价值重构双重驱动下的系统性进化。其演进逻辑呈现清晰的…...

神经网络幻觉的本质与四层防御实战指南
1. 这不是“胡说八道”,是模型在用概率拼图——神经网络幻觉的本质与真实战场 “神经网络会幻觉”这个说法,这几年在技术社区、媒体标题甚至投资人会议里出现的频率,已经快赶上“算力瓶颈”和“数据飞轮”了。但绝大多数人听到这个词的第一反…...

DownKyi完整指南:三步掌握B站8K超高清视频下载
DownKyi完整指南:三步掌握B站8K超高清视频下载 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)。…...

Triton模型服务化:构建高可用AI推理生产系统
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句暗号,专为那些在Jupyter里调通了模型、画出了漂亮ROC曲线、却在部署时被生产环境…...