面试知识点准备与总结——(并发篇)
目录
- 线程有哪些状态
- 线程池的核心参数
- sleep和wait的区别
- lock 与 synchronized 的异同
- volatile能否保证线程安全
- 悲观锁和乐观锁的区别
- Hashtable 与 ConcurrentHashMap 的区别
- ConcurrentHashMap1.7和1.8的区别
- ThreadLocal的理解
- ThreadLocalMap中的key为何要设置为弱引用
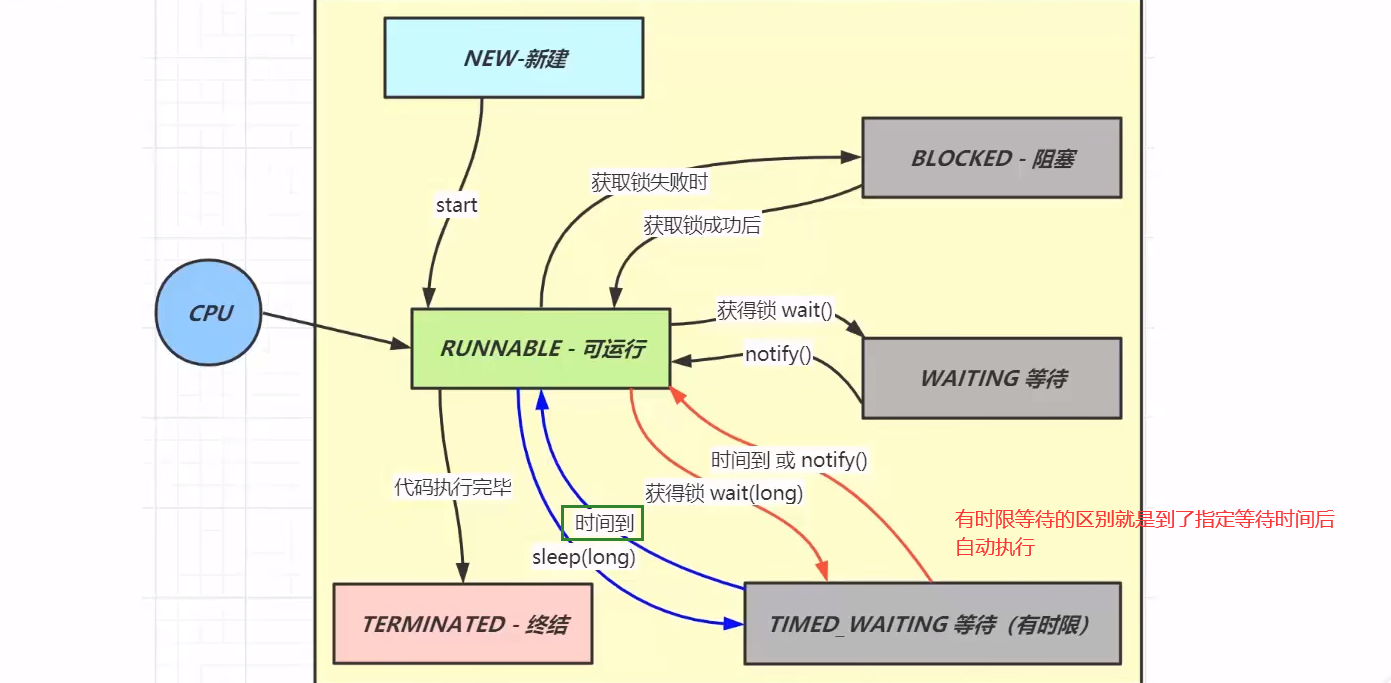
线程有哪些状态
Java线程分为六种状态,分别是新建,可运行,终结,阻塞,等待,有时限等待
前面三个新建,运行,终结都是单向不可逆的,而后面的阻塞,等待,有时限等待是可以与运行状态来回变换的
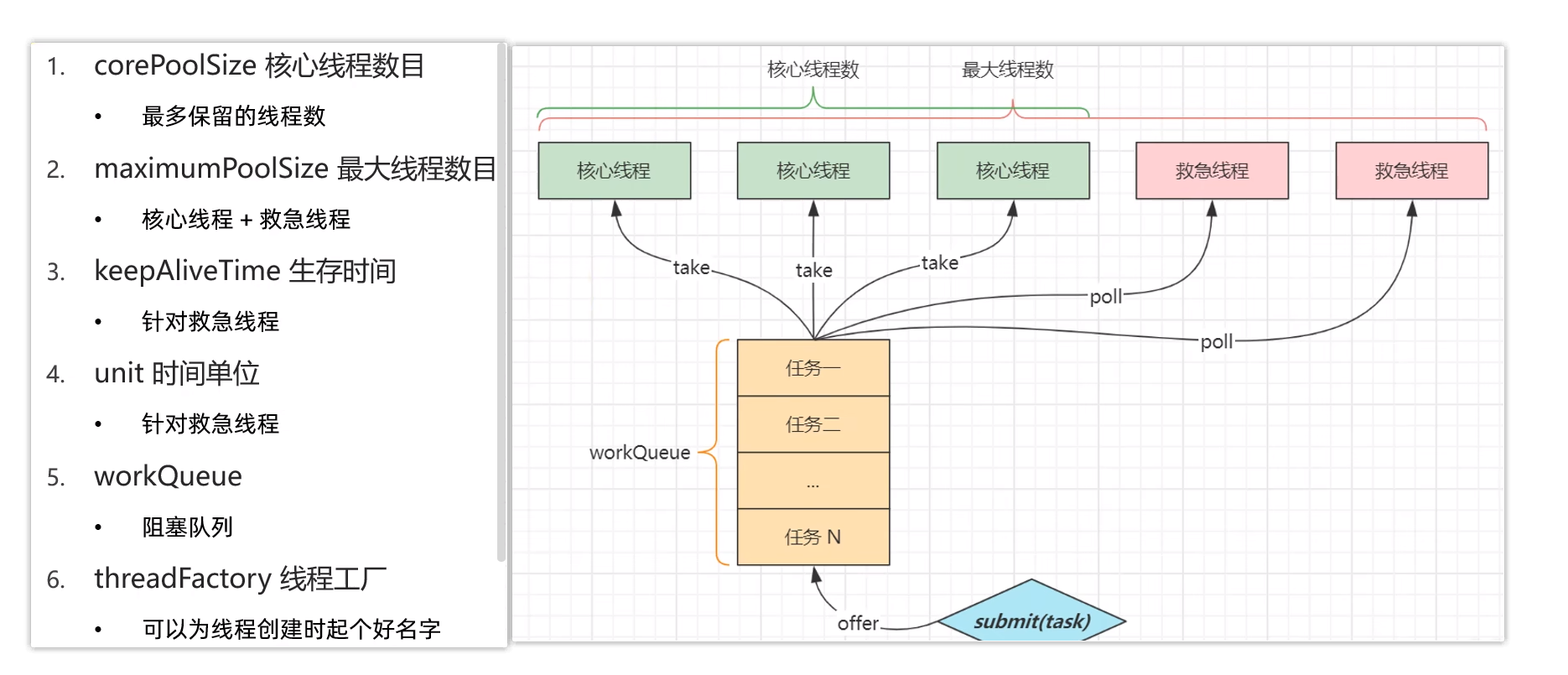
线程池的核心参数
线程池的核心参数一共有7个
核心线程数,是指一直保留在线程池里的线程数目最大线程数,是指核心线程数和救急线程数的总和生存时间,是指救急线程的存活时间,当救急线程空闲时间达到这个生存时间后,就会终结时间单位,是指存活时间的单位,是秒还是分钟或者小时阻塞队列,当核心线程用完后,剩下任务就在阻塞队列中排队,这里是指阻塞队列的长度线程工厂,给线程池创建新线程
最后一个是拒绝策略,拒绝策略有四种,如下
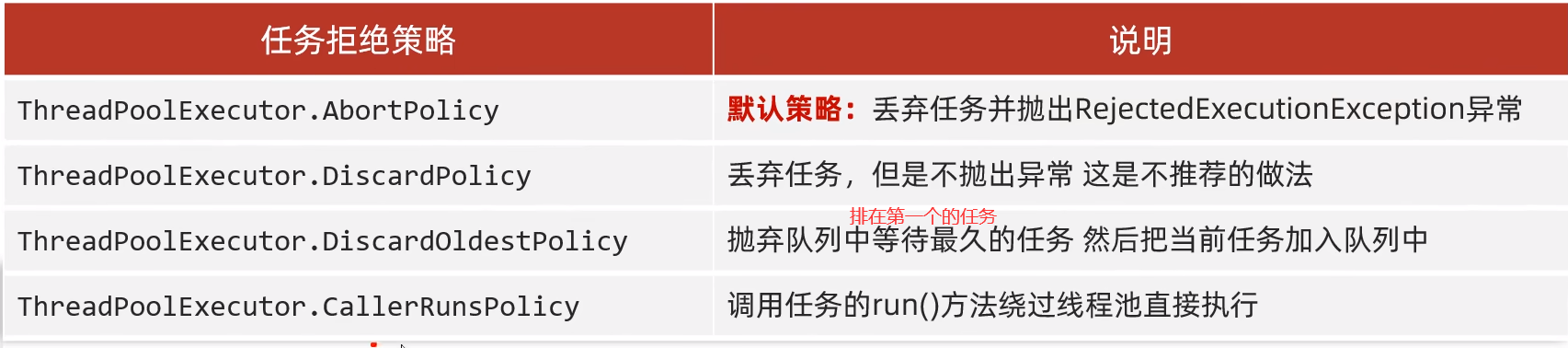
当任务数量超过核心线程数量,最大排队数量以及临时线程数量的总和,全负载时,多余任务会根据线程池的拒绝策略来丢弃或处理
sleep和wait的区别
一个共同点,三个不同点
共同点
wait() ,wait(long) 和 sleep(long) 的效果都是让当前线程暂时放弃 CPU 的使用权,进入阻塞状态
不同点
-
方法归属不同
- sleep(long) 是 Thread 的静态方法
- 而 wait(),wait(long) 都是 Object 的成员方法,每个对象都有
-
醒来时机不同
- 执行 sleep(long) 和 wait(long) 的线程都会在等待相应毫秒后醒来
- wait(long) 和 wait() 还可以被 notify 唤醒,wait() 如果不唤醒就一直等下去
- 它们都可以被打断唤醒
-
锁特性不同(重点)
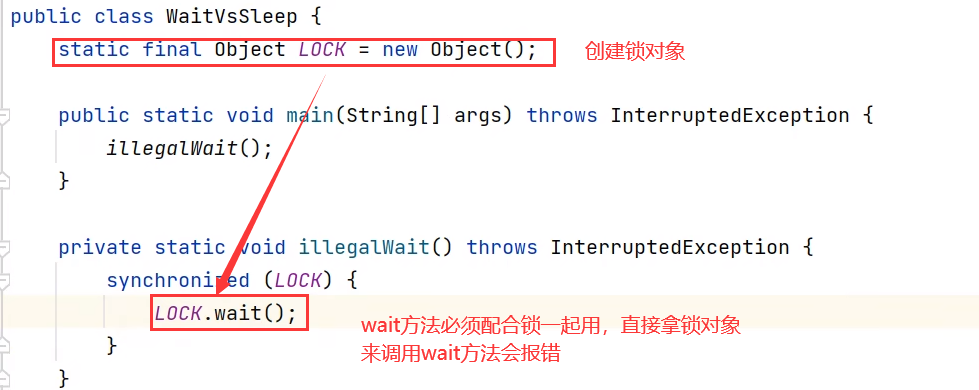
- wait 方法的调用必须先获取 wait 对象的锁,而 sleep 则无此限制
- wait 方法执行后会释放对象锁,允许其它线程获得该对象锁(我放弃 cpu,但你们还可以用)
- 而 sleep 如果在 synchronized 代码块中执行,并不会释放对象锁(我放弃 cpu,你们也用不了)
(这里简单可以理解,wait释放锁睡觉,sleep抱着锁睡觉)
lock 与 synchronized 的异同
可以从三个层面分解
不同点
①语法层面
- synchronized 是关键字,源码在 jvm 中,用 c++ 语言实现
- Lock 是接口,源码由 jdk 提供,用 java 语言实现
- 使用 synchronized 时,退出同步代码块锁会自动释放,而使用 Lock 时,需要手动调用 unlock 方法释放锁
②功能层面
- 二者均属于悲观锁、都具备基本的互斥、同步、锁重入(可以加多道锁)功能
- Lock 提供了许多 synchronized 不具备的功能,例如获取等待状态(哪些线程被阻塞了)、公平锁、可打断、可超时(可设置最大超时时间,超过指定时间放弃获取锁)、多条件变量
- Lock 有适合不同场景的实现,如 ReentrantLock(可重入锁), ReentrantReadWriteLock(读多写少场景)
③性能层面
- 在没有竞争时(或竞争很少时),synchronized 做了很多优化,如偏向锁、轻量级锁,性能不赖
- 在竞争激烈时,Lock 的实现通常会提供更好的性能
Lock锁,是用创建的锁对象调用lock(),unlock()方法,上锁和释放锁
synchronized ,是同步代码块或同步方方法的方式
公平锁
- 公平锁的公平体现
- 已经处在阻塞队列中的线程(不考虑超时)始终都是公平的,先进先出
- 公平锁是指未处于阻塞队列中的线程来争抢锁,如果队列不为空,则老实到队尾等待
- 非公平锁是指未处于阻塞队列中的线程来争抢锁,与队列头唤醒的线程去竞争,谁抢到算谁的
- 公平锁会降低吞吐量,一般不用
条件变量
- ReentrantLock 中的条件变量功能类似于普通 synchronized 的 wait,notify,用在当线程获得锁后,发现条件不满足时,临时等待的链表结构
- 与 synchronized 的等待集合不同之处在于,ReentrantLock 中的条件变量可以有多个,可以实现更精细的等待、唤醒控制
volatile能否保证线程安全
线程安全要考虑三个方面:可见性、有序性、原子性
①可见性指,一个线程对共享变量修改,另一个线程能看到最新的结果
②有序性指,一个线程内代码按编写顺序执行
③原子性指,一个线程内多行代码以一个整体运行,期间不能有其它线程的代码插队
原子性
- 起因:多线程下,不同线程的指令发生了交错导致的共享变量的读写混乱
- 解决:用悲观锁或乐观锁解决,volatile 并不能解决原子性
可见性
- 起因:由于编译器优化、或缓存优化、或 CPU 指令重排序优化导致的对共享变量所做的修改另外的线程看不到
- 解决:用 volatile 修饰共享变量,能够防止编译器等优化发生,让一个线程对共享变量的修改对另一个线程可见
下面就是一个典型的永远循环-可见性案例
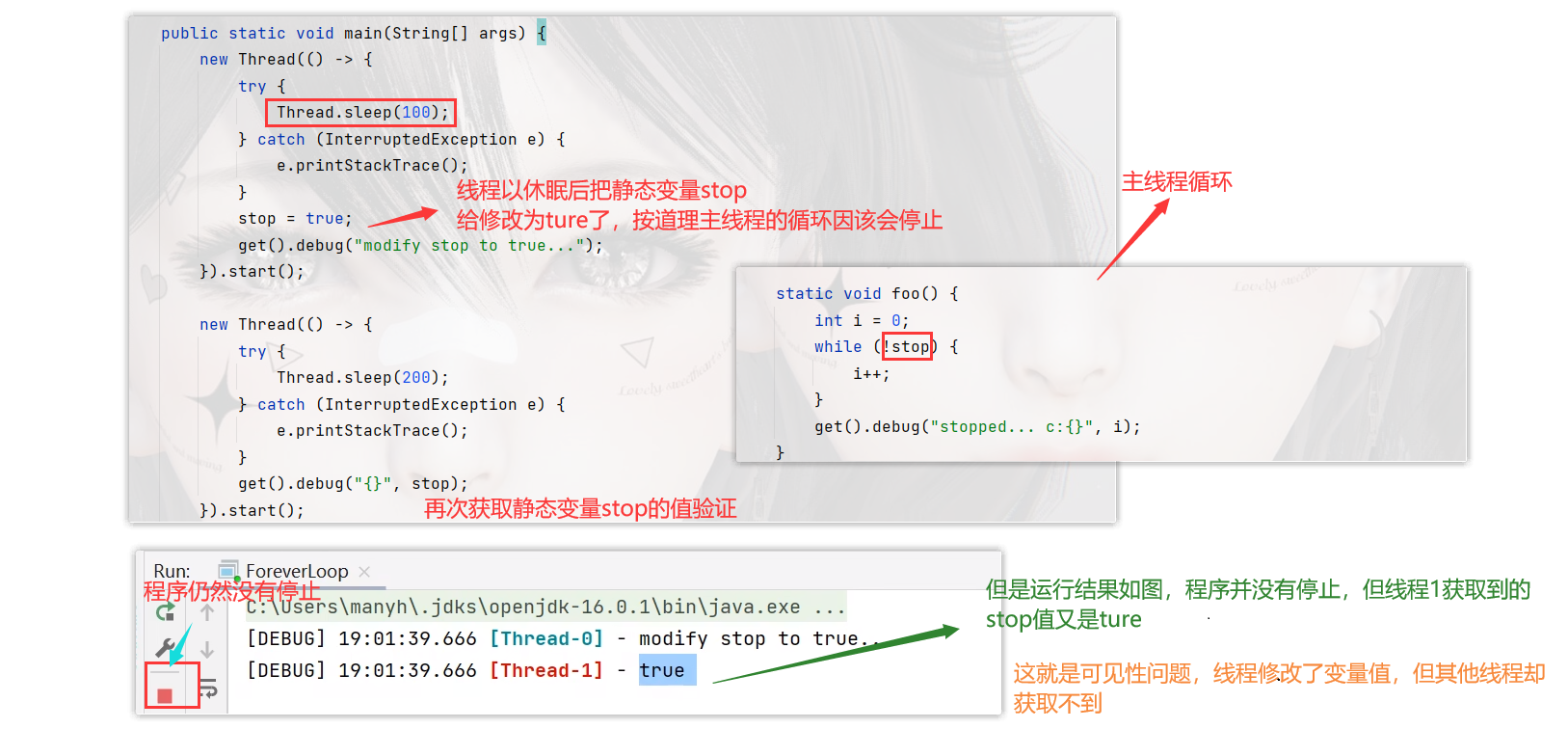
那到底是什么原因导致了线程0修改stop值后,主线程仍然继续循环,而线程1获取的stop又显示为true呢?
其中就是JIT的起的作用,JIT是优化器,对热点的字节码文件进行优化,例如频繁调用的方法,反复执行的循环;
在线程0还没有改变stop的值时,主线程在线程0睡眠的100毫秒内,已经执行了几百万次了,这时优化器JIT坐不住了,就对这个反复读取的stop且每次读取值都相同的字节码做优化,避免它频繁从内存中读取,把stop认为是false,把它的字节码编译成机器码缓存起来,再次循环时,就直接拿这个机器码,节省中间解释过程。如下图
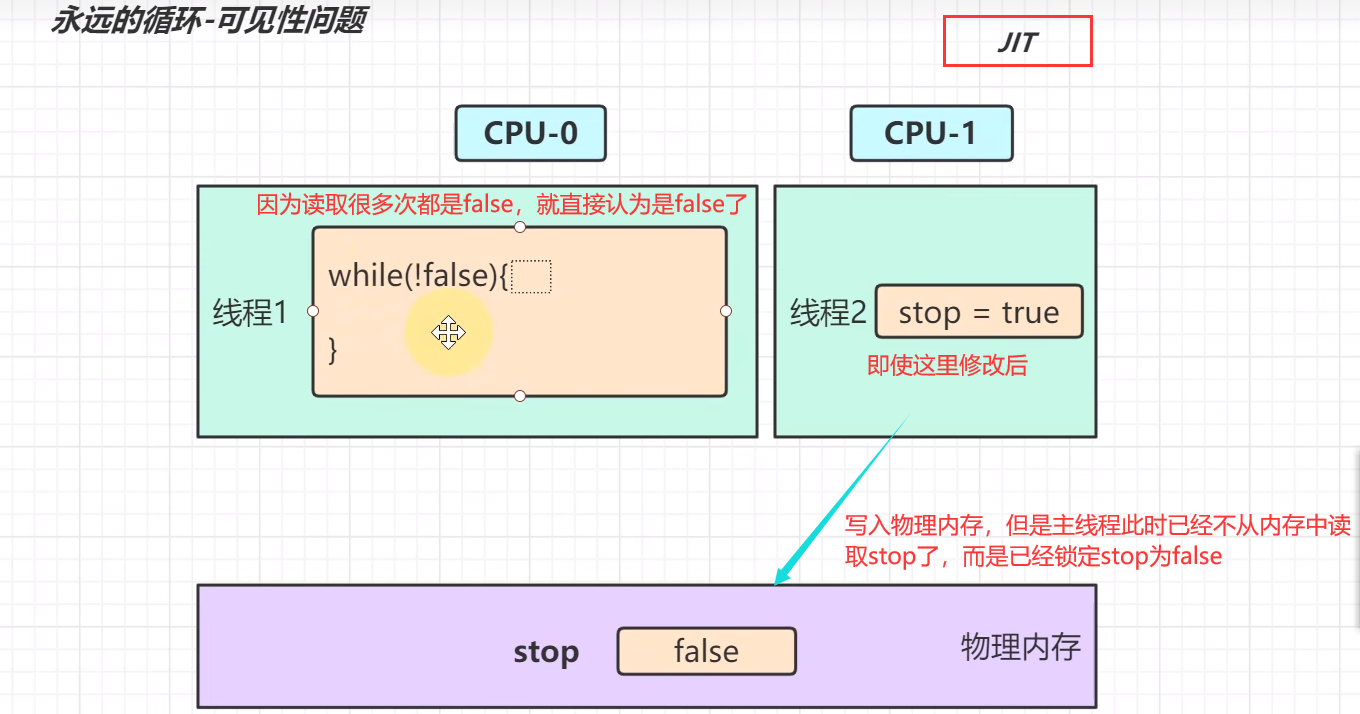
若上面那个stop变量用了volatile修饰,JIT就不会对其优化,放过它
有序性
- 起因:由于编译器优化、或缓存优化、或 CPU 指令重排序优化导致指令的实际执行顺序与编写顺序不一致
- 解决:用 volatile 修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果
- 注意:
- volatile 变量写加的屏障是阻止上方其它写操作越过屏障排到 volatile 变量写之下
- volatile 变量读加的屏障是阻止下方其它读操作越过屏障排到 volatile 变量读之上
- volatile 读写加入的屏障只能防止同一线程内的指令重排
写是上面操作不能越过下面(避免被程序之前的数据覆盖),读是下面操作不能越过上面(避免读取的是程序后面的数据)
是不能逆着箭头排的

悲观锁和乐观锁的区别
对比悲观锁与乐观锁
-
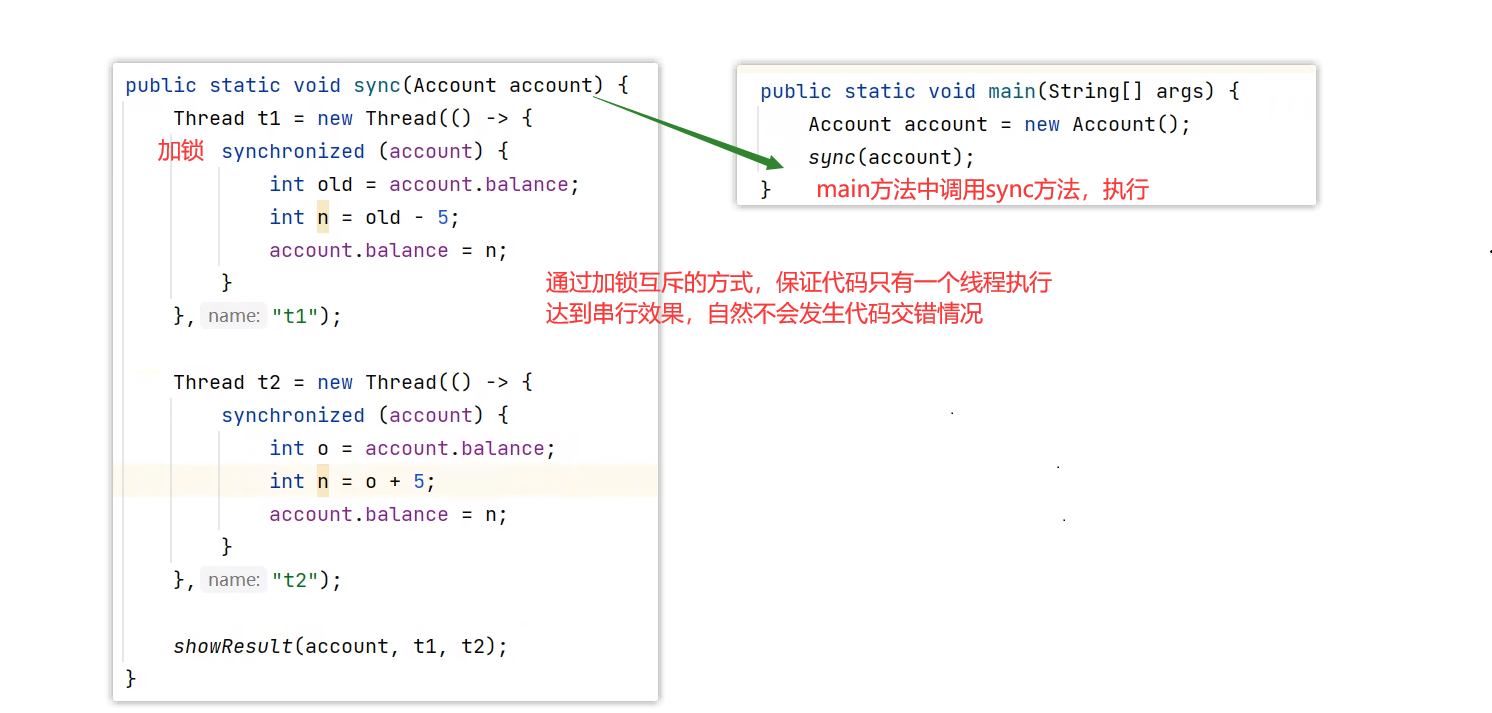
悲观锁的代表是 synchronized 和 Lock 锁
- 其核心思想是【线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程,都得停下来等待】
- 线程从运行到阻塞、再从阻塞到唤醒,涉及线程上下文切换,如果频繁发生,影响性能
- 实际上,线程在获取 synchronized 和 Lock 锁时,如果锁已被占用,都会做几次重试操作,减少阻塞的机会
-
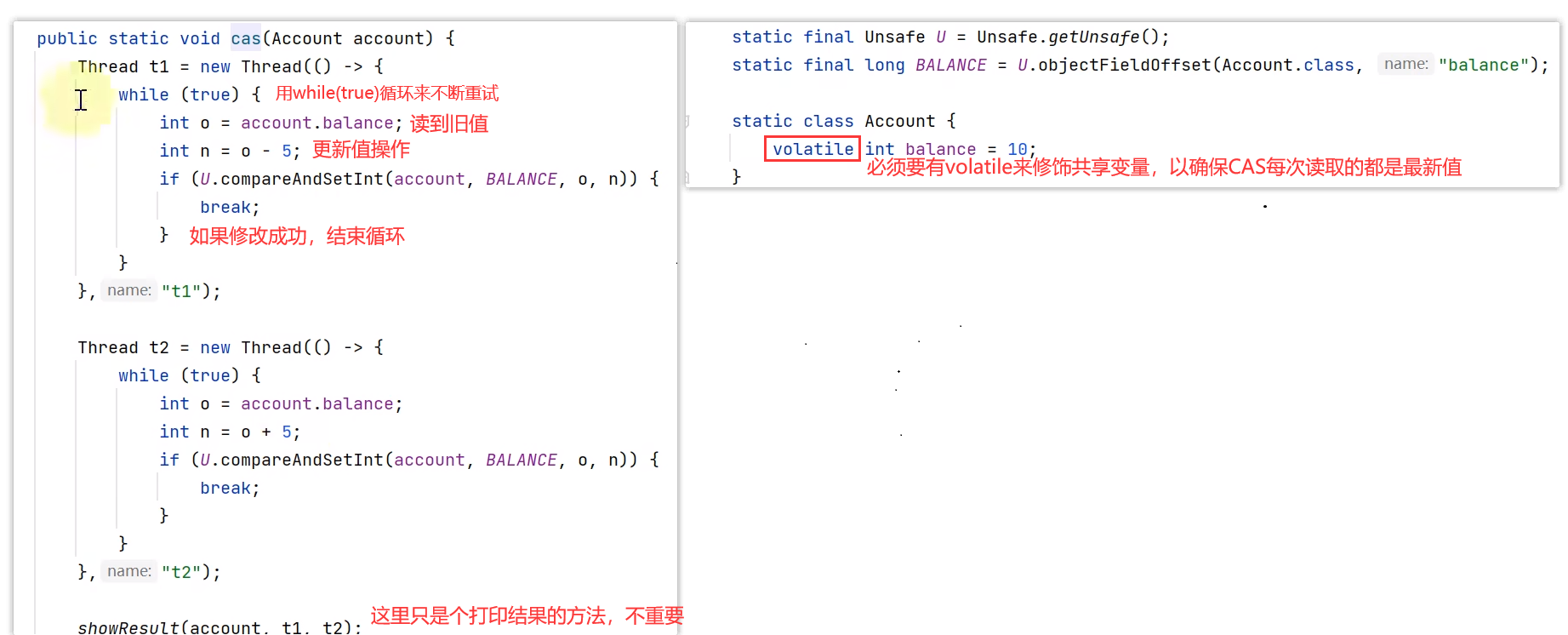
乐观锁的代表是 AtomicInteger,使用 cas (compareAndSetInt方法,比较并交换的缩写)来保证原子性
- 其核心思想是【无需加锁,每次只有一个线程能成功修改共享变量,其它失败的线程不需要停止,不断重试直至成功】
- 由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换
- 它需要多核 cpu 支持,且线程数不应超过 cpu 核数
cas方法是从乐观的角度出发,假设每次获取数据别人都不会修改,所以不会上锁。只不过在修改共享数据的时候,会检查一下,把传入的旧值和当前共享变量的最新值作比较,来判断别人有没有修改过这个数据。
如果别人修改过,那么我再次获取现在最新的值。
如果别人没有修改过,那么我现在直接修改共享数据的值.(乐观锁)
CAS是要和volatile一起使用,这样才能保证每次看到的共享变量是最新值
synchronized 加锁是使用的互斥方式,将多行代码作为一个整体执行,保证并发下的原子性
而CAS没有互斥,是并发执行,只是在修改操作时,用比较并交换的原则,来判断传入的旧值和当前获取的最新值是否一致(看看你要更新的值有没有被人修改过),一致才修改成功,不一致则修改失败,修改失败也无所谓,因为乐观锁是不断重试直至成功,在while(true)循环中,再拿到新值,在最新值得基础上做更新操作
下面是代码演示
synchronized 悲观锁
CAS 乐观锁
Hashtable 与 ConcurrentHashMap 的区别
Hashtable 对比 ConcurrentHashMap
- Hashtable 与 ConcurrentHashMap 都是线程安全的 Map 集合
- Hashtable 并发度低,整个 Hashtable 对应一把锁,同一时刻,只能有一个线程操作它
- ConcurrentHashMap 并发度高,整个 ConcurrentHashMap 对应多把锁,只要线程访问的是不同锁,那么不会冲突
(Hashtable的底层实现是数组+链表结构实现的;hashtable的容量是质数,有较好的分布性,不需要进行二次哈希)
ConcurrentHashMap1.7和1.8的区别
ConcurrentHashMap 1.7
- 数据结构:
Segment(大数组) + HashEntry(小数组) + 链表,每个 Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突 - 并发度:Segment 数组大小即并发度,决定了同一时刻最多能有多少个线程并发访问。Segment 数组不能扩容,意味着并发度在 ConcurrentHashMap 创建时就固定了
- 索引计算
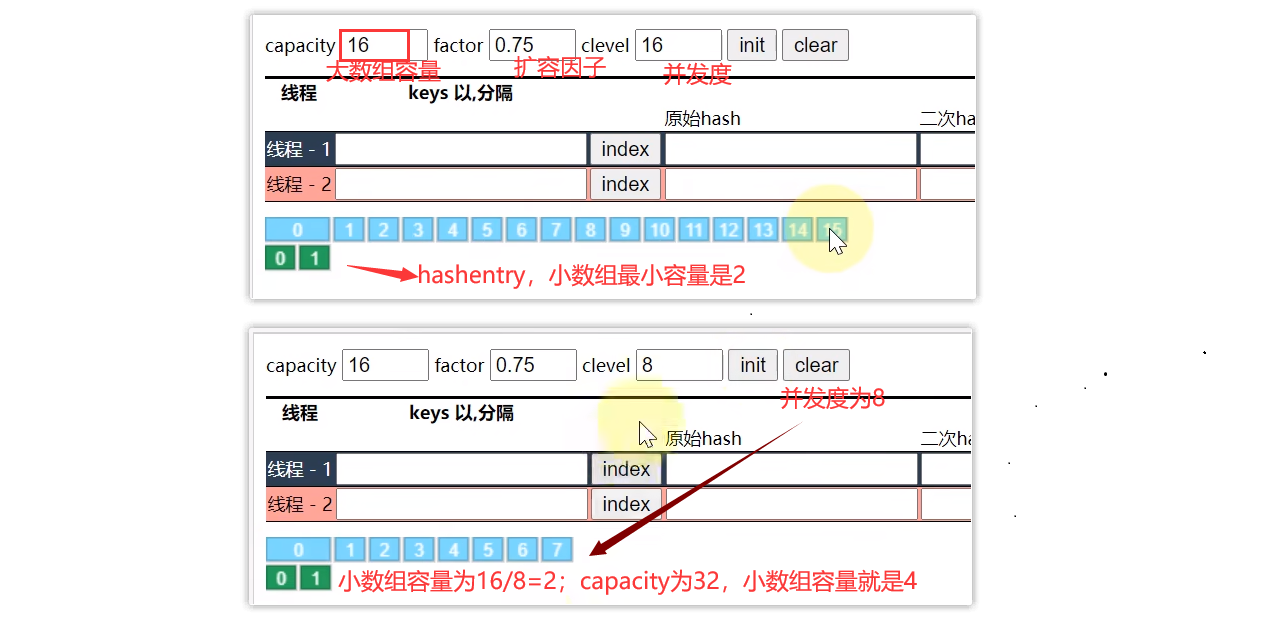
- 假设大数组长度是 2m2^m2m,key 在大数组内的索引是 key 的二次 hash 值的高 m 位(例如:capacity为32,32是2的5次方,取二次hash值高5位,就是前5位,转十进制就得到存储位置索引值)
- 假设小数组长度是 2n2^n2n,key 在小数组内的索引是 key 的二次 hash 值的低 n 位
- 扩容:每个小数组的扩容相对独立,小数组在超过扩容因子时会触发扩容,每次扩容翻倍;由于hashtable是加锁了的,即使链表使用头插法,也不会像ConcurrentHashMap那样导致死链
- Segment[0] 原型:首次创建其它小数组时,会以此原型为依据,数组长度,扩容因子都会以原型为准,下图作为演示
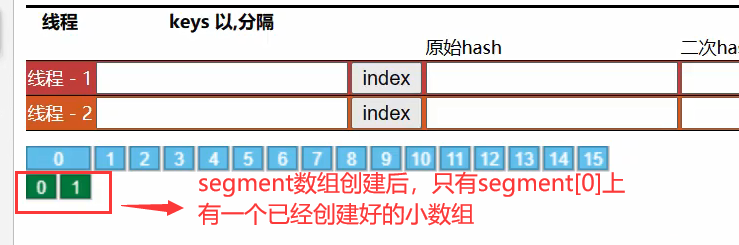
新的小数组会根据当前segment[0]做为原型来创建 - 小数组容量最小是2;小数组容量 = 大数组容量 / 可并发数
下面来个图,有图有真相
并发度决定蓝色数组的大小,容量决定小数组entry的大小
ConcurrentHashMap 1.8
-
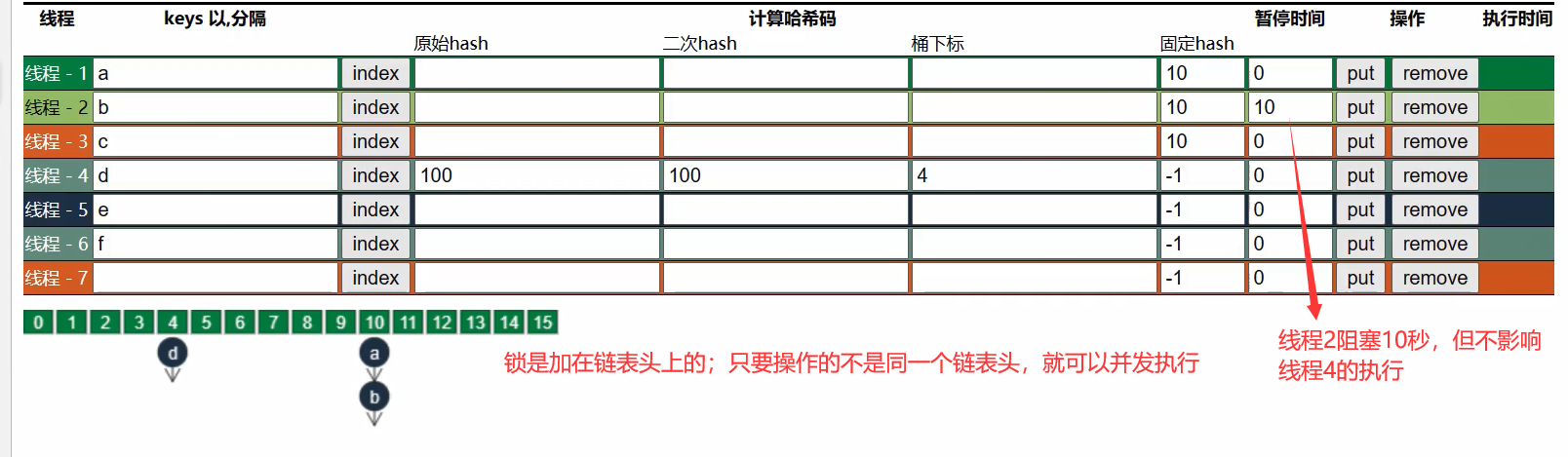
数据结构:
Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能
-
并发度:Node 数组有多大,并发度就有多大,与 1.7 不同,Node 数组可以扩容
-
扩容条件:Node 数组满 3/4 时就会扩容,1.7是超出才扩容
-
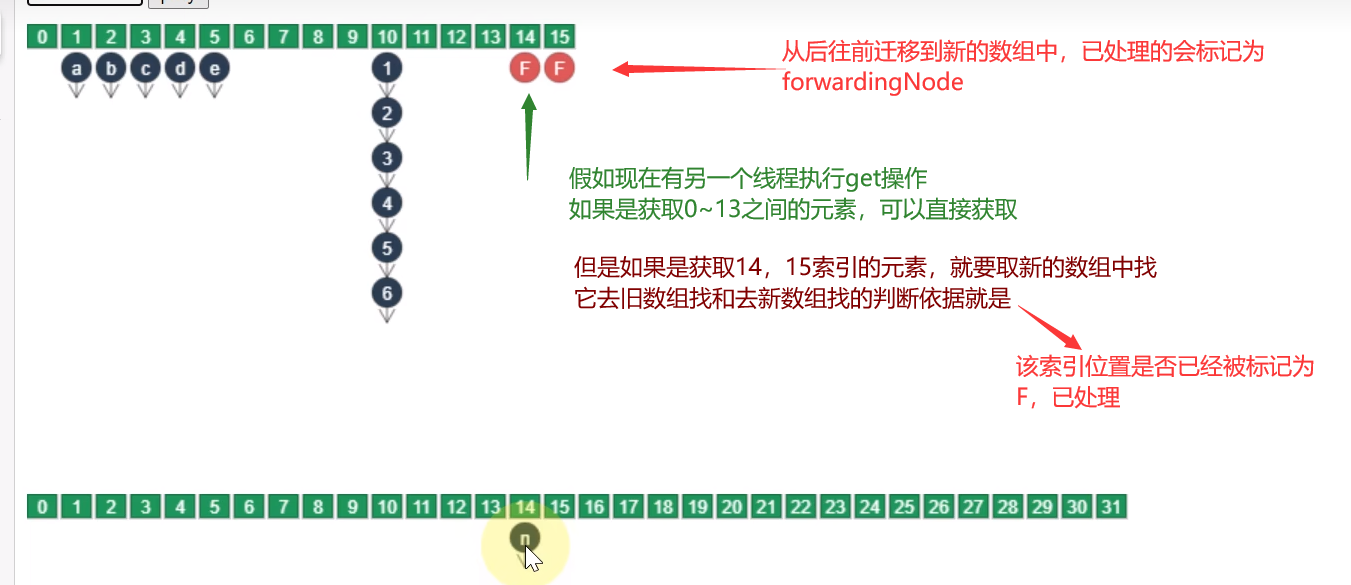
扩容单位:以链表为单位从后向前迁移链表,迁移完成的将旧数组头节点替换为 ForwardingNode
-
扩容时并发 get
-
根据是否为 ForwardingNode 来决定是在新数组查找还是在旧数组查找,不会阻塞
-
如果链表长度超过 1,则需要对节点进行复制(创建新节点),怕的是节点迁移后 next 指针改变
-
如果链表最后几个元素扩容后索引不变,则节点无需复制
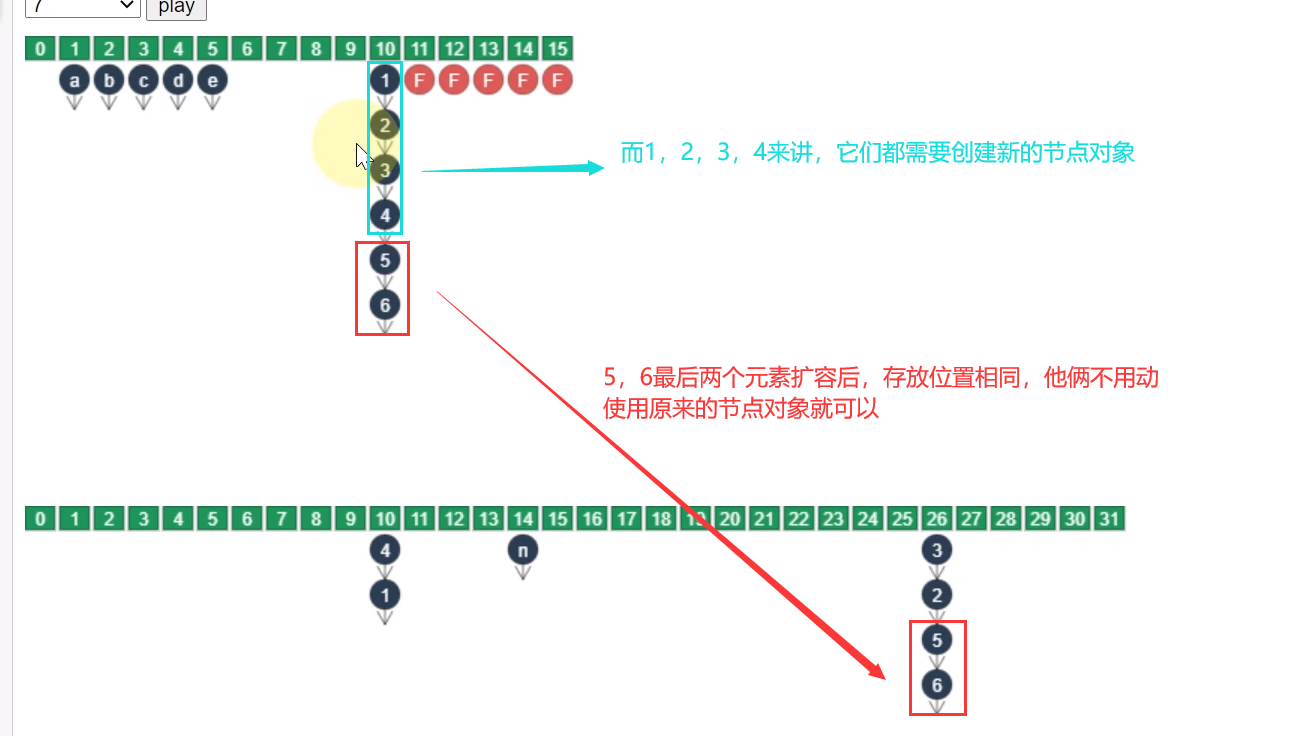
-
-
扩容时并发 put
- 如果 put 的线程与扩容线程操作的链表是同一个,put 线程会阻塞
- 如果 put 的线程操作的链表还未迁移完成,即头节点不是 ForwardingNode,则可以并发执行
- 如果 put 的线程操作的链表已经迁移完成,即头结点是 ForwardingNode,则可以协助扩容
-
capacity 代表预估的元素个数,capacity / factory 来计算出初始数组大小,需要贴近 2n2^n2n
例如,要放16个元素(capacity为16),但是数组满扩容因子就会扩容,如果数组长度为16是不够的,所以数组容量 = capacity / factory;简单说就是capacity是数组容量的3/4.
- loadFactor 只在计算初始数组大小时被使用,之后扩容固定为 3/4
- 超过树化阈值时的扩容问题,如果容量已经是 64,直接树化,否则在原来容量基础上做 3 轮扩容
区别
①从底层结构上
1.7ConcurrentHashMap 底层数据结构是Segment(大数组) + HashEntry(小数组) + 链表
而1.8 ConcurrentHashMap 底层数据结构是 数组 + 链表或红黑树,而且链表添加元素上不同于1.7的头插法,而是尾插法
②从初始化的时机上
与 1.7 相比是懒惰初始化,1.7是饿汉式初始化,初始化以后,数组及数组零号元素已经创建出来了,1.8是在第一次put元素时,才会创建底层数组结构,是懒汉式初始化
③从扩容时机上
1.7是容量超出扩容因子才扩容
而1.8是数组满 3/4(或扩容因子*数组容量) 时就会扩容
ThreadLocal的理解
- ThreadLocal 可以实现【资源对象】的线程隔离,让每个线程各用各的【资源对象】,避免争用引发的线程安全问题
- ThreadLocal 同时实现了线程间的线程隔离和线程内(只要是同一个线程,可以在多个方法中获取同一变量的)资源共享
原理
每个线程内有一个 ThreadLocalMap 类型的集合,用来存储资源对象
- 调用 set 方法,就是以 ThreadLocal 自己作为 key,资源对象作为 value,放入当前线程的 ThreadLocalMap 集合中
- 调用 get 方法,就是以 ThreadLocal 自己作为 key,到当前线程中查找关联的资源值
- 调用 remove 方法,就是以 ThreadLocal 自己作为 key,移除当前线程关联的资源值
线程间的资源是隔离的,key(ThreadLocal)可以相同,但关联的资源池可能不同
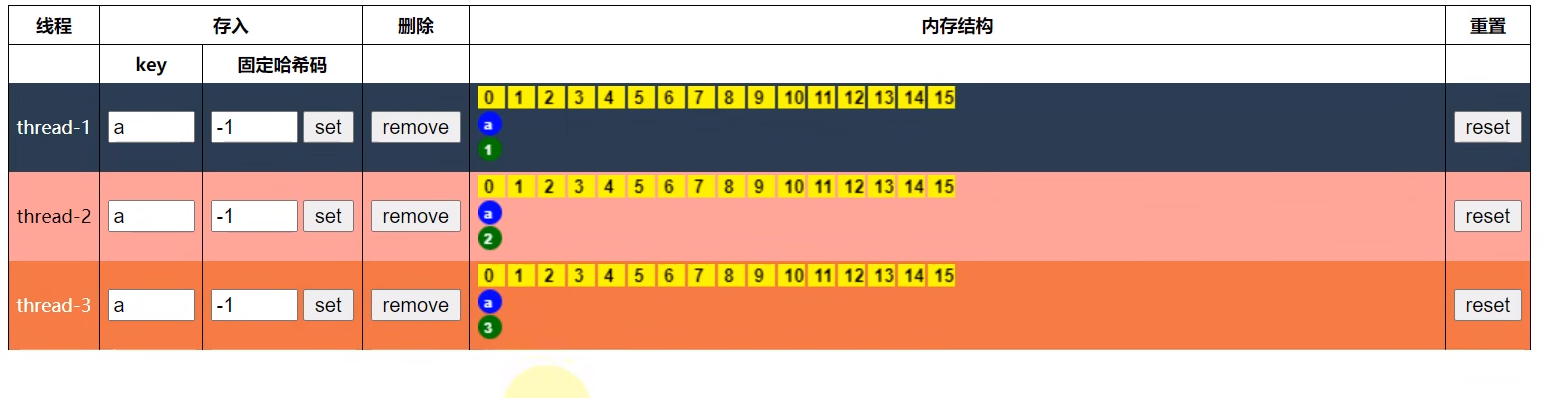
ThreadLocalMap
key 的 hash 值统一分配;初始容量为16;元素个数满2/3(扩容因子),数组扩容原来两倍,索引值相同时,不再使用链表那种拉链法,而是使用开放寻址法(从这索引开始,找下一个空闲位置作为索引位置)。
ThreadLocalMap中的key为何要设置为弱引用
弱引用 key
ThreadLocalMap 中的 key 被设计为弱引用,原因如下
- Thread 可能需要长时间运行(如线程池中的线程),如果 key 不再使用,需要在内存不足(GC)时释放其占用的内存
内存释放时机
①被动 GC 释放 key
- 仅是让 key 的内存释放,关联 value 的内存并不会释放
② 懒惰被动释放 value
- get key 时,发现是 null key,则释放其 value 内存;(当ThreadLocalMap根据key去get值时,发现key不存在,会放入一个为null的key;这是和其他map的不同之处)
- set key 时,会使用启发式扫描,清除临近的 null key 的 value 内存,启发次数与元素个数,是否发现 null key 有关
③主动 remove 释放 key,value
- 会同时释放 key,value 的内存,也会清除临近的 null key 的 value 内存
- 推荐使用它,因为一般使用 ThreadLocal 时都把它作为静态变量(即强引用),因此无法被动依靠 GC 回收

所以①和②两种方法都不可用,最好还是主动回收掉
相关文章:
面试知识点准备与总结——(并发篇)
目录线程有哪些状态线程池的核心参数sleep和wait的区别lock 与 synchronized 的异同volatile能否保证线程安全悲观锁和乐观锁的区别Hashtable 与 ConcurrentHashMap 的区别ConcurrentHashMap1.7和1.8的区别ThreadLocal的理解ThreadLocalMap中的key为何要设置为弱引用线程有哪些…...
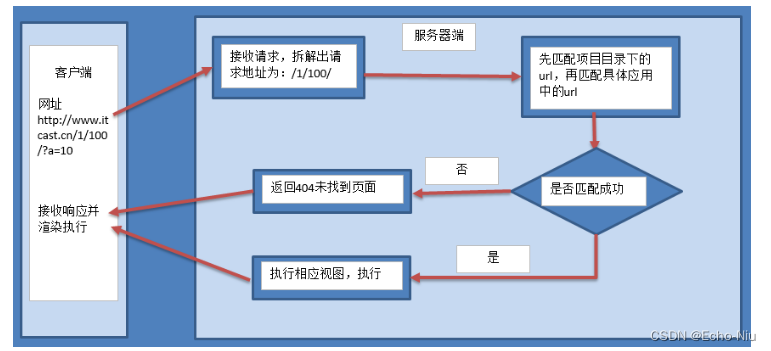
Django框架之模型视图-URLconf
URLconf 浏览者通过在浏览器的地址栏中输入网址请求网站对于Django开发的网站,由哪一个视图进行处理请求,是由url匹配找到的 配置URLconf 1.settings.py中 指定url配置 ROOT_URLCONF 项目.urls2.项目中urls.py 匹配成功后,包含到应用的urls…...
操作系统闲谈06——进程管理
操作系统闲谈06——进程管理 一、进程调度 01 时间片轮转 给每一个进程分配一个时间片,然后时间片用完了,把cpu分配给另一个进程 时间片通常设置为 20ms ~ 50ms 02 先来先服务 就是维护了一个就绪队列,每次选择最先进入队列的进程&#…...

DaVinci 偏好设置:用户 - UI 设置
偏好设置 - 用户/ UI 设置Preferences - User/ UI Settings工作区选项Workspace Options语言Language指定 DaVinci Resolve 软件界面所使用的语言。目前支持英语、简体中文、日语、西班牙语、葡萄牙语、法语、俄语、泰语和越南语等等。启动时重新加载上一个工作项目Reload last…...
Nacos超简单-管理配置文件
优点理论什么的就不说了,按照流程开始配配置吧。登录Centos,启动Naocs,使用sh /data/soft/restart.sh将自动启动Nacos。访问:http://192.168.101.65:8848/nacos/账号密码:nacos/nacos分为两部分,第一部分准…...
基于微信小程序的中国各地美食推荐平台小程序
文末联系获取源码 开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.…...

如何优雅的导出函数
在开发过程中,经常会引用外部函数。方法主要有两种: 方法一:包含头文件并制定lib位置 优点:使用简单缺点:lib和vs版本有关,不同的版本和编译模式可能导致编译失败 方法二:GetProcAddress 优…...

c++多重继承
1.概论多重继承是否有必要吗?这个问题显然是一个哲学问题,正确的解答方式是根据情况来看,有时候需要,有时候不需要,这显然是一句废话,有点像上马克思主义哲学或者中庸思。但是这个问题和那些思想一样&#…...
15_FreeRtos计数信号量优先级翻转互斥信号量
目录 计数型信号量 计数型信号量相关API函数 计数型信号量实验源码 优先级翻转简介 优先级翻转实验源码 互斥信号量 互斥信号量相关API函数 互斥信号量实验源码 计数型信号量 计数型信号量相当于队列长度大于1的队列,因此计数型信号量能够容纳多个资源,这在…...
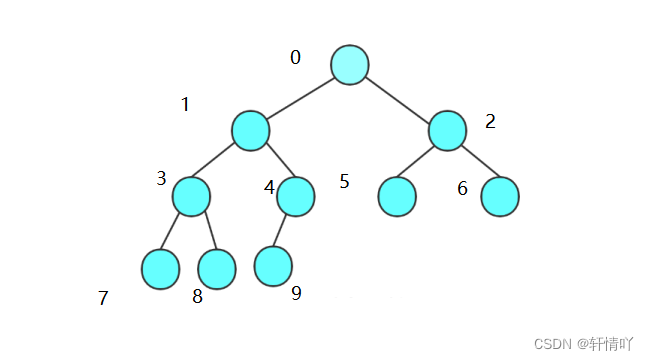
二叉树(一)
二叉树(一)1.树的概念2.树的相关概念3.树的表示4.树在实际中的运用5.二叉树概念及结构6.特殊的二叉树7.二叉树的性质🌟🌟hello,各位读者大大们你们好呀🌟🌟 🚀🚀系列专栏…...
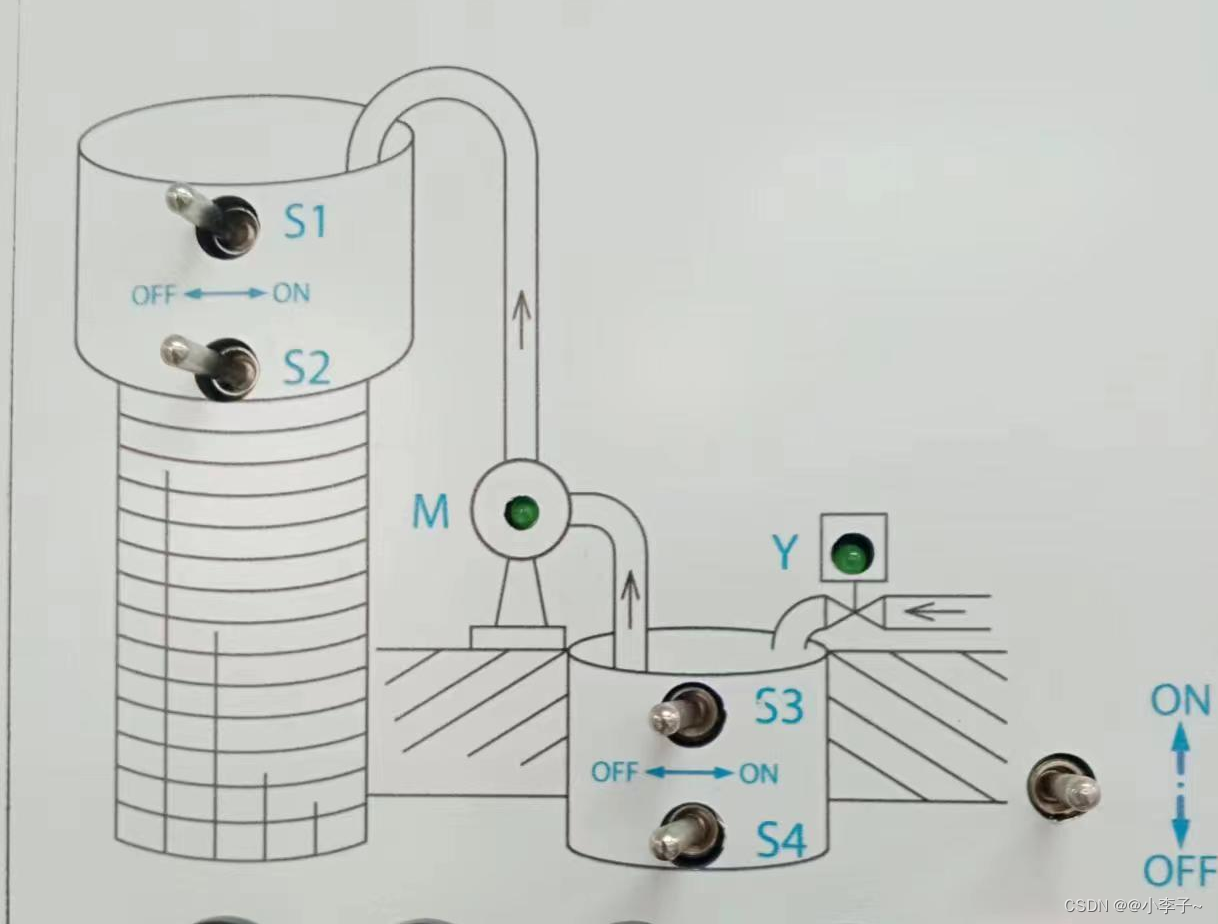
【SCL】1200案例:天塔之光数码管显示液体混合水塔水位
使用scl编写天塔之光&数码管显示&液体混合&水塔水位 文章目录 目录 文章目录 前言 一、案例1:天塔之光 1.控制要求 2.编写程序 3.效果 二、案例2:液体混合 1.控制要求 2.编写程序 三、案例3:数码管显示 1.控制要求 2.编写程序 3…...
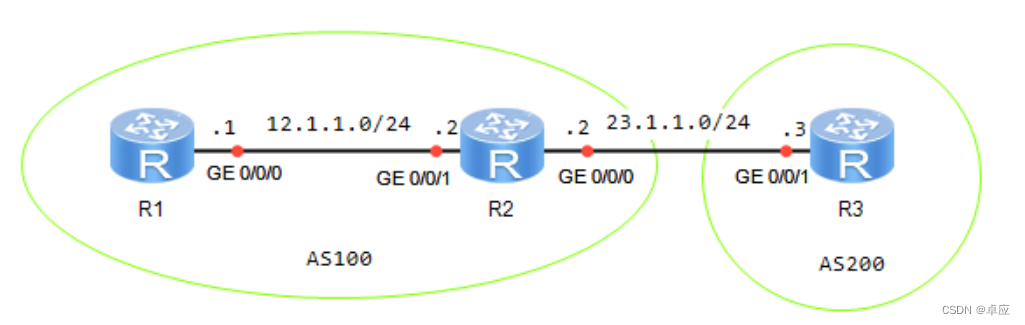
5.1配置IBGP和EBGP
5.2.1实验1:配置IBGP和EBGP 实验目的 熟悉IBGP和EBGP的应用场景掌握IBGP和EBGP的配置方法 实验拓扑 实验拓扑如图5-1所示: 图5-1:配置IBGP和EBGP 实验步骤 IP地址的配置 R1的配置 <Huawei>system-view Enter system view, return …...
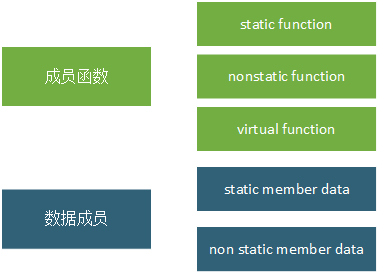
c++中超级详细的一些知识,新手快来
目录 2.文章内容简介 3.理解虚函数表 3.1.多态与虚表 3.2.使用指针访问虚表 4.对象模型概述 4.1.简单对象模型 4.2.表格驱动模型 4.3.非继承下的C对象模型 5.继承下的C对象模型 5.1.单继承 5.2.多继承 5.2.1一般的多重继承(非菱形继承) 5.2…...

[答疑]经营困难时期谈建模和伪创新-长点心和长点良心
leonll 2022-11-26 9:53 我们今年真是太难了……(此处删除若干字)……去年底就想着邀请您来给我们讲课,现在也没有实行。我想再和我们老大提,您觉得怎么说个关键理由,这样的形势合适引进UML开发流程? UML…...

计算机基础知识
计算机网络的拓扑结构 一、OSI 7层网络模型是指什么? 7层分别是什么?每层的作用是什么? OSI7层模型是 国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系。 每层功能:(自底向上) 物理层:建立、…...
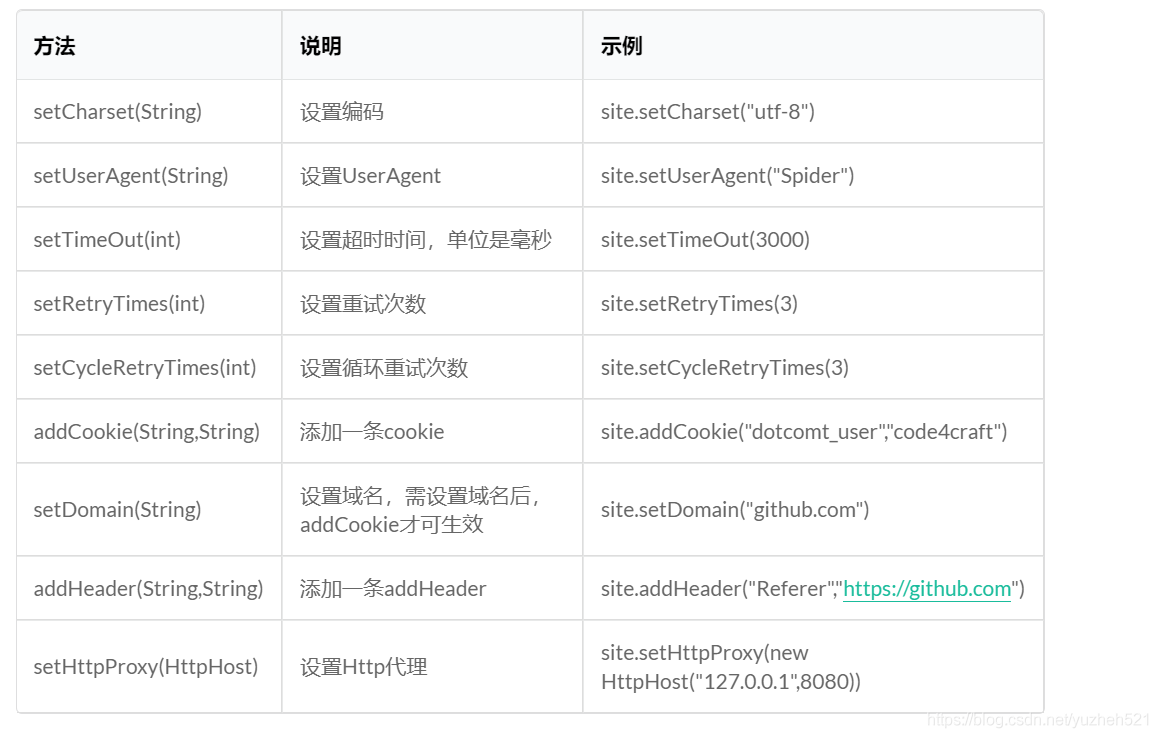
Java爬虫—WebMagic
一,WebMagic介绍WebMagic企业开发,比HttpClient和JSoup更方便一),WebMagic架构介绍WebMagic有DownLoad,PageProcessor,Schedule,Pipeline四大组件,并有Spider将他们组织起来…...

[软件工程导论(第六版)]第2章 可行性研究(复习笔记)
文章目录2.1 可行性研究的任务2.2 可行性研究过程2.3 系统流程图2.4 数据流图概念2.5 数据字典2.6 成本/效益分析2.1 可行性研究的任务 可行性研究的目的 用最小的代价在尽可能短的时间内确定问题是否能够解决。 可行性研究的3个方面 (1)技术可行性&…...
Mac下安装Tomcat以及IDEA中的配置
安装brew 打开终端输入以下命令: /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" 搜索tomcat版本,输入以下命令: brew search tomcat 安装自己想要的版本,例…...
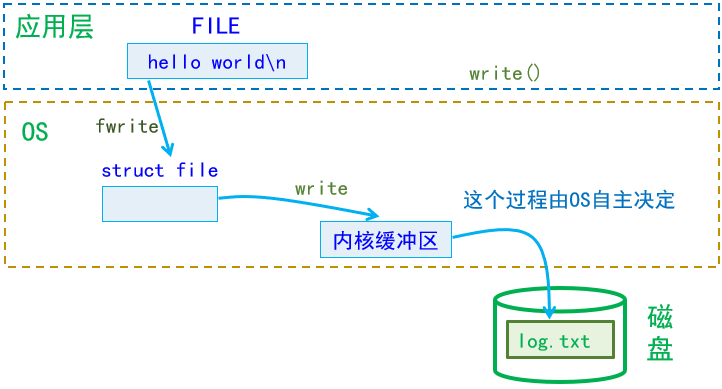
【Linux详解】——文件基础(I/O、文件描述符、重定向、缓冲区)
📖 前言:本期介绍文件基础I/O。 目录🕒 1. 文件回顾🕘 1.1 基本概念🕘 1.2 C语言文件操作🕤 1.2.1 概述🕤 1.2.2 实操🕤 1.2.3 OS接口open的使用(比特位标记)…...

HomMat2d
1.affine_trans_region(区域的任意变换) 2.hom_mat2d_identity(创建二位变换矩阵) 3.hom_mat2d_translate(平移) 4.hom_mat2d_scale(缩放) 5.hom_mat2d_rotate(旋转 &…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...

起重机起升机构的安全装置有哪些?
起重机起升机构的安全装置是保障吊装作业安全的关键部件,主要用于防止超载、失控、断绳等危险情况。以下是常见的安全装置及其功能和原理: 一、超载保护装置(核心安全装置) 1. 起重量限制器 功能:实时监测起升载荷&a…...