大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——InputFormat数据输入
3.1.1切片与MapTask并行度决定机制
1、问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2、MapTask并行度决定机制
**数据块:**Block是HDFS物理上把数据分成一块一块。
**数据切片:**数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。

3.1.2Job提交流程源码和切片源码详解
1、Job提交流程源码详解
waitForCompletion()submit();// 1建立连接connect(); // 1)创建提交Job的代理new Cluster(getConfiguration());// (1)判断是本地yarn还是远程initialize(jobTrackAddr, conf); // 2 提交job
submitter.submitJobInternal(Job.this, cluster)// 1)创建给集群提交数据的Stag路径Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);// 2)获取jobid ,并创建Job路径JobID jobId = submitClient.getNewJobID();// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir);// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);maps = writeNewSplits(job, jobSubmitDir);input.getSplits(job);// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);conf.writeXml(out);// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
2、Job提交流程源码解析
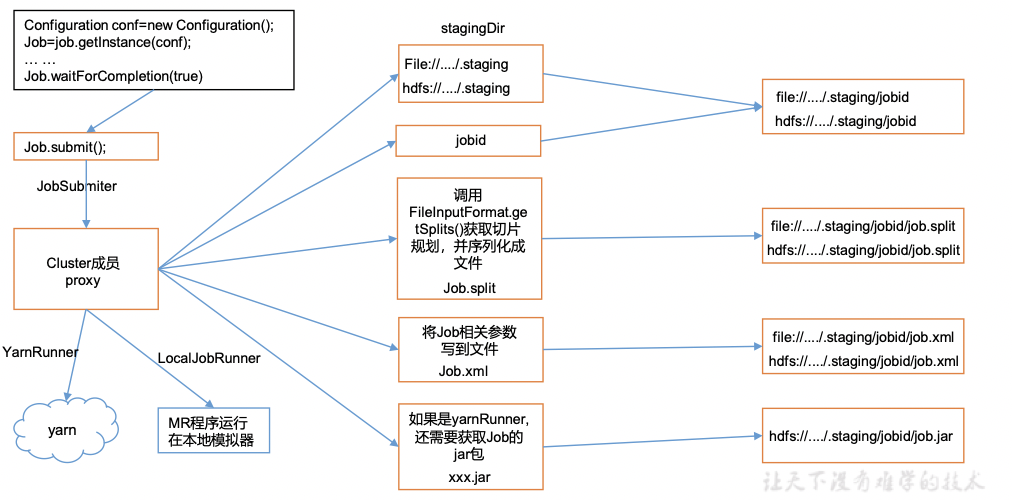
wordcount:断点打在Driver集群提交的代码
boolean result = job.waitForCompletion(true);
DEBUG:step into
3.1.3FileInputFormat切片机制
1、切片机制
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
2、案例分析
(1)输入数据有两个文件:
file1.txt 320M
file2.txt 10M
(2)经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10
FileInputFormat切片大小的参数配置
(1)源码中计算切片大小的公式
Math.max(minSize, Math.min(maxSize, blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
(2)切片大小设置
maxsize(切片最大值):参数如果调的比blockSize小,则会让切片变小,而且就等于配置的这个参数值。
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize还大。
(3)获取切片信息API
// 获取切片的文件名称
String name = inputSplit.getPath().getName();
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
3.1.4CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1、应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2、虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3、切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
3.1.5CombineTextInputFormat案例实操
1、需求
将输入的大量小文件合并成一个切片统一处理。
(1)输入数据
准备4个小文件
(2)期望
期望一个切片处理4个文件
2、实现过程
(1)不做任何处理,运行1.6节的WordCount案例程序,观察切片个数为4。
(2)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为3。
(a)驱动类中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
(b)运行如果为3个切片。

(3)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为1。
(a)驱动中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
(b)运行如果为1个切片。

3.1.6FileInputFormat实现类
思考:**在运行MapReduce程序时,输入文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。**那么,针对不同的数据类型, MapReduce是如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等
1、TextInputFormat
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。值是这行的内容,不包括任何终止符(换行符和回车符),Text类型。
以下是一个示例。比如,一个分片包含了如下4条文本记录。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
每条记录表示以下键/值对:
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
2、KeyValueTextInputFormat
每一行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置**conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, “\t”);**来设定分隔符。默认分隔符是tab(\t)。
以下是一个示例,输入时一个包含4条记录的分片。其中—>表示一个(水平方向的)制表符。
line1—>Rich learning form
line2—>Intelligent learning engine
line3—>Learning more convenient
line4—>From the real demand for more close to the enterprise
每条记录表示为以下键/值对:
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line3,Learning more convenient)
(line4,From the real demand for more close to the enterprise)
此时的键是每行排在制表符之前的Text序列。
3、NLineInputFormat
如果使用NLineInputFormat,代表每个map进程处理的**InputSplit不再按Block块去划分,而是按NLineInputFormat指定的行数N来划分。**即输入文件的总行数/N=切片书,如果不整除,切片数=商+1。
以下是一个示例,仍然以上面的4行输入为例。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
例如,如果N是2,则每个输入分片包含两行。开启2个MapTask。
(0,Rich learning form)
(19,Intelligent learning engine)
另一个mapper则受到后两行:
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
这里的键和值和TextInputFormat生成的一样。
3.1.7KeyValueTextInputFormat使用案例
1、需求
统计输入文件中每一行的第一个单词相同的行数。
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
(2)期望结果数据
banzhang 2
xihuan 2
2、需求分析

3、代码实现
(1)编写Mapper类
package com.cuiyf41.kvtext;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class KVTextMapper extends Mapper<Text, Text, Text, LongWritable> {// 1 设置valueLongWritable v = new LongWritable(1);@Overrideprotected void map(Text key, Text value, Mapper<Text, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {// 2 写出context.write(key, v);}
}
(2)编写Reducer类
package com.cuiyf41.kvtext;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class KVTextReducer extends Reducer<Text, LongWritable, Text, LongWritable> {LongWritable v = new LongWritable();@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {long sum = 0;// 1 汇总统计for(LongWritable value:values){sum += value.get();}v.set(sum);// 2 输出context.write(key, v);}
}
(3)编写Driver类
package com.cuiyf41.kvtext;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class KVTextDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 输入输出路径需要根据自己电脑上实际的输入输出路径设置args = new String[] { "e:/input/kvtext.txt", "e:/output1" };Configuration conf = new Configuration();// 设置切割符conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");// 1 获取job对象Job job = Job.getInstance(conf);// 2 设置jar包位置,关联mapper和reducerjob.setJarByClass(KVTextDriver.class);job.setMapperClass(KVTextMapper.class);job.setReducerClass(KVTextReducer.class);// 3 设置map输出kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 4 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 5 设置输入输出数据路径FileInputFormat.setInputPaths(job, new Path(args[0]));// 设置输入格式job.setInputFormatClass(KeyValueTextInputFormat.class);// 6 设置输出数据路径FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobjob.waitForCompletion(true);}
}
3.1.8NLineInputFormat使用案例
1、需求
对每个单词进行个数统计,要求根据每个输入文件的行数来规定输出多少个切片。此案例要求每三行放入一个切片中。
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2)期望输出数据
Number of splits:4
2、需求分析

3、代码实现
(1)编写Mapper类
package com.cuiyf41.nline;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable> {private Text k= new Text();private LongWritable v = new LongWritable(1);@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {// 1 获取一行String line = value.toString();// 2 切割String[] splited = line.split(" ");// 3 循环写出for(int i = 0; i < splited.length; i++){k.set(splited[i]);context.write(k, v);}}
}
(2)编写Reducer类
package com.cuiyf41.nline;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class NLineReducer extends Reducer<Text, LongWritable,Text, LongWritable> {LongWritable v = new LongWritable();@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {long sum = 0;// 1 汇总for(LongWritable value:values){sum += value.get();}v.set(sum);// 2 输出context.write(key, v);}
}
(3)编写Driver类
package com.cuiyf41.nline;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class NLineDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// 输入输出路径需要根据自己电脑上实际的输入输出路径设置args = new String[] { "e:/input/nline.txt", "e:/output1" };// 1 获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 7设置每个切片InputSplit中划分三条记录NLineInputFormat.setNumLinesPerSplit(job, 3);// 8使用NLineInputFormat处理记录数job.setInputFormatClass(NLineInputFormat.class);// 2设置jar包位置,关联mapper和reducerjob.setJarByClass(NLineDriver.class);job.setMapperClass(NLineMapper.class);job.setReducerClass(NLineReducer.class);// 3设置map输出kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 4设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 5设置输入输出数据路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 6提交jobjob.waitForCompletion(true);}
}
4、测试
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2)输出结果的切片数,如图4-10所示:

3.1.9自定义InputFormat
在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题。
自定义InputFormat步骤如下:
(1)自定义一个类继承FileInputFormat。
(2)改写RecordReader,实现一次读取一个完整文件封装为KV。
(3)在输出时使用SequenceFileOutPutFormat输出合并文件。
3.1.10自定义InputFormat案例实操
无论HDFS还是MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
1、需求
将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
(1)输入数据
one.txt
yongpeng weidong weinan
sanfeng luozong xiaoming
two.txt
longlong fanfan
mazong kailun yuhang yixin
longlong fanfan
mazong kailun yuhang yixin
three.txt
shuaige changmo zhenqiang
dongli lingu xuanxuan
(2)期望输出文件格式
2、需求分析
1)自定义一个类继承FileInputFormat
- 重写isSplitable()方法,返回false不可分割
- 重写createRecordReader(),创建自定义的RecordReader对象,并初始化
2)改写Recor,实现一次读取一个完整文件封装为KV
- 采用IO流一次读取一个文件输出到value中,因为设置了不可切片,最终把所有文件都封装到了value中
- 获取文件路径信息+名称,并设置key
3)设置Driver
// 设置输入的inputFormat
job.setInputFormatClass(WholeFileInputformat.class);// 设置输出的outputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
3、程序实现
(1)自定义InputFromat
package com.cuiyf41.inputfile;import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;// 定义类继承FileInputFormat
public class WholeFileInputformat extends FileInputFormat<Text, BytesWritable>{@Overrideprotected boolean isSplitable(JobContext context, Path filename) {return false;}@Overridepublic RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {WholeRecordReader recordReader = new WholeRecordReader();recordReader.initialize(split, context);return recordReader;}
}
(2)自定义RecordReader类
package com.cuiyf41.inputfile;import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;public class WholeRecordReader extends RecordReader<Text, BytesWritable>{private Configuration configuration;private FileSplit split;private boolean isProgress= true;private BytesWritable value = new BytesWritable();private Text k = new Text();@Overridepublic void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {this.split = (FileSplit)split;configuration = context.getConfiguration();}@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {if (isProgress) {// 1 定义缓存区byte[] contents = new byte[(int)split.getLength()];FileSystem fs = null;FSDataInputStream fis = null;try {// 2 获取文件系统Path path = split.getPath();fs = path.getFileSystem(configuration);// 3 读取数据fis = fs.open(path);// 4 读取文件内容IOUtils.readFully(fis, contents, 0, contents.length);// 5 输出文件内容value.set(contents, 0, contents.length);// 6 获取文件路径及名称String name = split.getPath().toString();// 7 设置输出的key值k.set(name);} catch (Exception e) {}finally {IOUtils.closeStream(fis);}isProgress = false;return true;}return false;}@Overridepublic Text getCurrentKey() throws IOException, InterruptedException {return k;}@Overridepublic BytesWritable getCurrentValue() throws IOException, InterruptedException {return value;}@Overridepublic float getProgress() throws IOException, InterruptedException {return 0;}@Overridepublic void close() throws IOException {}
}
(3)编写SequenceFileMapper类处理流程
package com.cuiyf41.inputfile;import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class SequenceFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable>{@Overrideprotected void map(Text key, BytesWritable value, Mapper<Text, BytesWritable, Text, BytesWritable>.Context context) throws IOException, InterruptedException {context.write(key, value);}
}
(4)编写SequenceFileReducer类处理流程
package com.cuiyf41.inputfile;import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> {@Overrideprotected void reduce(Text key, Iterable<BytesWritable> values, Reducer<Text, BytesWritable, Text, BytesWritable>.Context context) throws IOException, InterruptedException {context.write(key, values.iterator().next());}
}
(5)编写SequenceFileDriver类处理流程
package com.cuiyf41.inputfile;import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;public class SequenceFileDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 输入输出路径需要根据自己电脑上实际的输入输出路径设置args = new String[] { "e:/input/format", "e:/output" };// 1 获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置jar包存储位置、关联自定义的mapper和reducerjob.setJarByClass(SequenceFileDriver.class);job.setMapperClass(SequenceFileMapper.class);job.setReducerClass(SequenceFileReducer.class);// 7设置输入的inputFormatjob.setInputFormatClass(WholeFileInputformat.class);// 8设置输出的outputFormatjob.setOutputFormatClass(SequenceFileOutputFormat.class);// 3 设置map输出端的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(BytesWritable.class);// 4 设置最终输出端的kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(BytesWritable.class);// 5 设置输入输出路径Path input = new Path(args[0]);Path output = new Path(args[1]);// 如果输出路径存在,则进行删除FileSystem fs = FileSystem.get(conf);if (fs.exists(output)) {fs.delete(output,true);}FileInputFormat.setInputPaths(job, input);FileOutputFormat.setOutputPath(job, output);// 6 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
相关文章:
大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——InputFormat数据输入
3.1.1切片与MapTask并行度决定机制 1、问题引出 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。 思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个M…...
【Opencv 系列】 第4章 直方图
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言1、直方图的定义、意义、特征2、直方图:2.1 灰度直方图2.2 彩色直方图前言 提示:以下是本篇文章正文内容,下面案例可供参考 …...
C#反射原理
一、前言反射(Reflection)的内容在博客中已经写了一篇,什么是反射,反射的使用,反射优缺点总结;在面试中突然被问道反射的原理,按照理解反射就是在Reflection命名空间和对象的Type对象获取类的方…...
python+vue微信小程序的线上服装店系统
服装行业是一个传统的行业。根据当前发展现状,网络信息时代的全面普及,服装行业也在发生着变化,单就服饰这一方面,利用手机购物正在逐步进入人们的生活。传统的购物方式,不仅会耗费大量的人力、时间,有时候还会出错。小程序系统伴随智能手机为我们提供了新的方向。手机线上服装…...
众德全自动批量剪辑工具,批量去重伪原创视频,全自动合成探店带货等视频
众德全自动批量剪辑工具已连续更新两年,服务了大大小小的自媒体公司工作室共200多个,成就了几百个草根创业者,实现月入10万,自从创办众德传媒之前,我一直坚信自媒体才是年轻草根创业者的出路,不需要技术门槛…...

【项目精选】基于网络爬虫技术的网络新闻分析(论文+源码+视频)
基于网络爬虫技术的网络新闻分析主要用于网络数据爬取。本系统结构如下: (1)网络爬虫模块。 (2)中文分词模块。 (3)中3文相似度判定模块。 (4)数据结构化存储模块。 &…...
)
华为OD机试 - 任务混部(JS)
任务混部 题目 公司创新实验室正在研究如何最小化资源成本,最大化资源利用率,请你设计算法帮他们解决一个任务混部问题:有taskNum项任务,每个任务有开始时间(startTime),结束时间(endTime),并行度(parallelism)三个属性,并行度是指这个任务运行时将会占用的服务…...
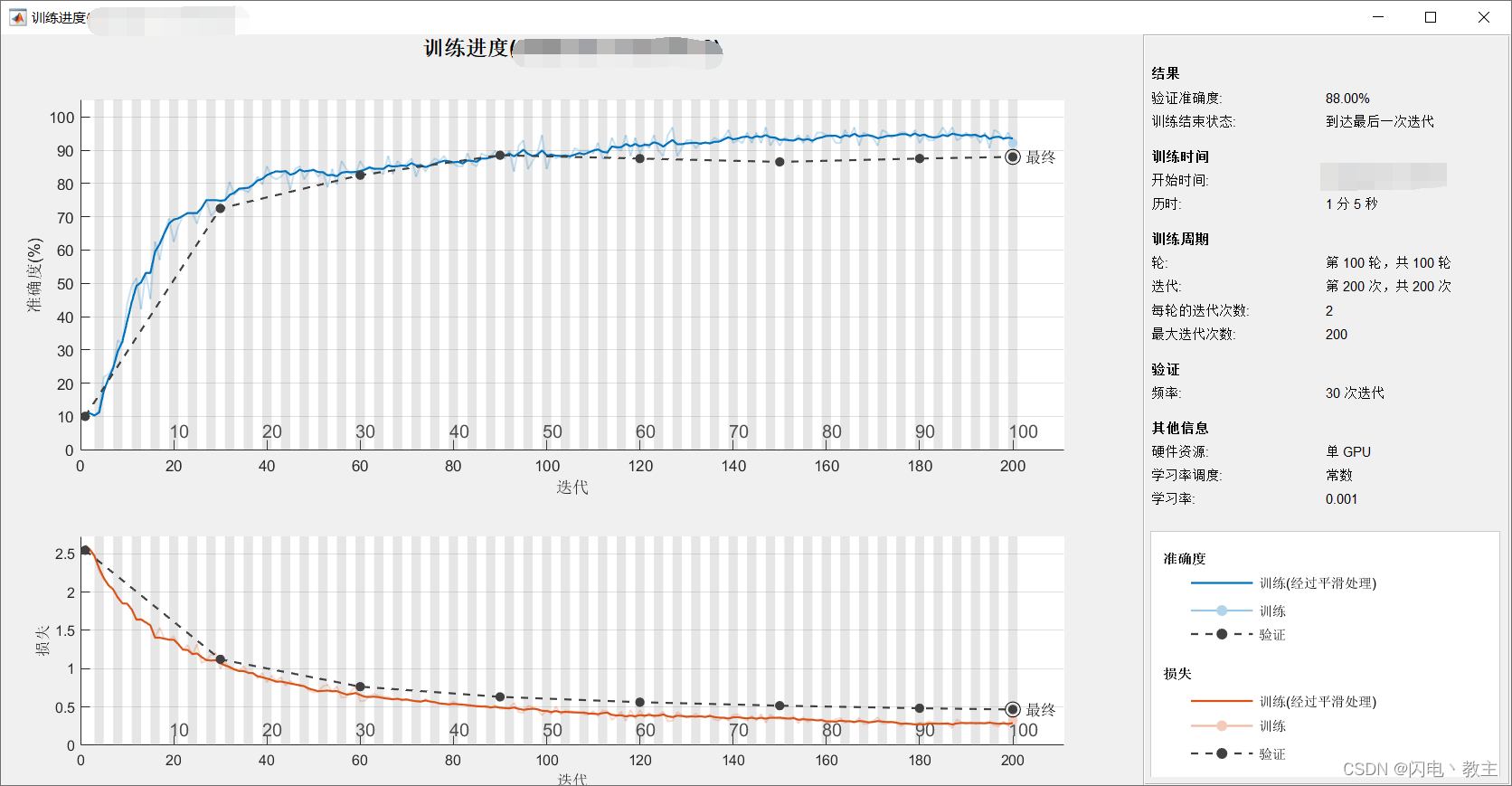
Matlab搭建AlexNet实现手写数字识别
Matlab搭建AlexNet实现手写数字识别 个人博客地址 文章目录Matlab搭建AlexNet实现手写数字识别环境内容步骤准备MNIST数据集数据预处理定义网络模型定义训练超参数网络训练和预测代码下载环境 Matlab 2020aWindows10 内容 使用Matlab对MNIST数据集进行预处理,搭建…...
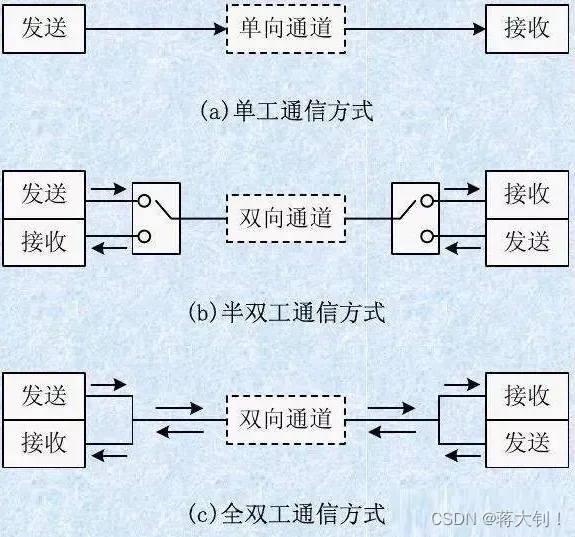
比较全面的HTTP和TCP网络传输的单工、全双工和半双工
文章目录单工、全双工、半双工1. 单工2. 半双工3. 全双工HTTP协议的工作模式TCP协议的工作模式本文参考: 图解网络传输单工、半双工、全双工 - 知乎 (zhihu.com) 问:HTTP是单工的还是双工的还是半双工的 - 简书 (jianshu.com) 关于TCP全双工模式的解释_忙…...

CSS Houdini
前言 最近看了几篇文章,是关于 CSS Houdini 的。作为一个前端搬砖的还真不知道这玩意,虽然不知道的东西挺多的,但是这玩意有点高大上啊。 Houdini 是一组底层 API,它们公开了 CSS 引擎的各个部分,从而使开发人员能够通…...

C++引用
这里写目录标题引用引用的基本使用引用做函数参数引用作为函数返回值引用的本质常量引用引用与指针的区别&的三种作用引用 引用的基本使用 作用: 给变量起别名 语法: 数据类型 &别名 原名 引用的本质是给变量起别名,因此࿰…...
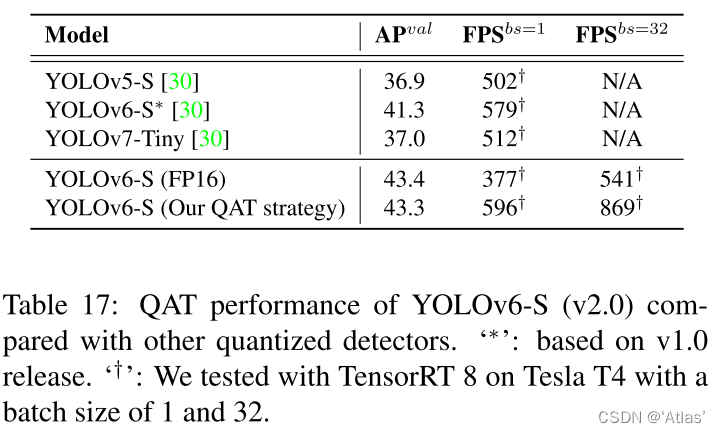
YOLOv6-目标检测论文解读
文章目录摘要问题算法网络设计BackboneNeckHead标签分配SimOTA(YOLOX提出):TAL(Task alignment learning,TOOD提出)损失函数分类损失框回归损失目标损失行业有用改进自蒸馏图像灰度边界填充量化及部署实验消…...

【factoryio】使用SCL编写 <机械手控制> 程序
使用虚拟工厂软件和博图联合仿真来编写【scl】机械手控制程序 文章目录 目录 文章目录 前言 二、程序编写 1.机械手运行部分 2.启动停止部分 3.急停复位部分 三、完整代码 总结 前言 在前面我们一起写过了许多案例控制的编写,在这一章我们一起来编写一下一个…...

QT学习记录散件
fromLocal8Bit() qt中fromLocal8Bit()函数可以设置编码。 因为QT默认的编码是unicode,不能显示中文的 而windows默认使用(GBK/GB2312/GB18030) 所以使用fromLocal8Bit()函数,可以实现从本地字符集GB到Unicode的转换,从…...
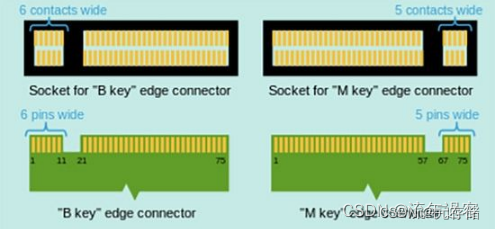
[SSD科普之1] PCIE接口详解及应用模式
PCI-Express(peripheral component interconnect express)是一种高速串行计算机扩展总线标准,它原来的名称为“3GIO”,是由英特尔在2001年提出的,旨在替代旧的PCI,PCI-X和AGP总线标准。一、PCI-E x1/x4/x8/x16插槽模式PCI-E有 x1/…...
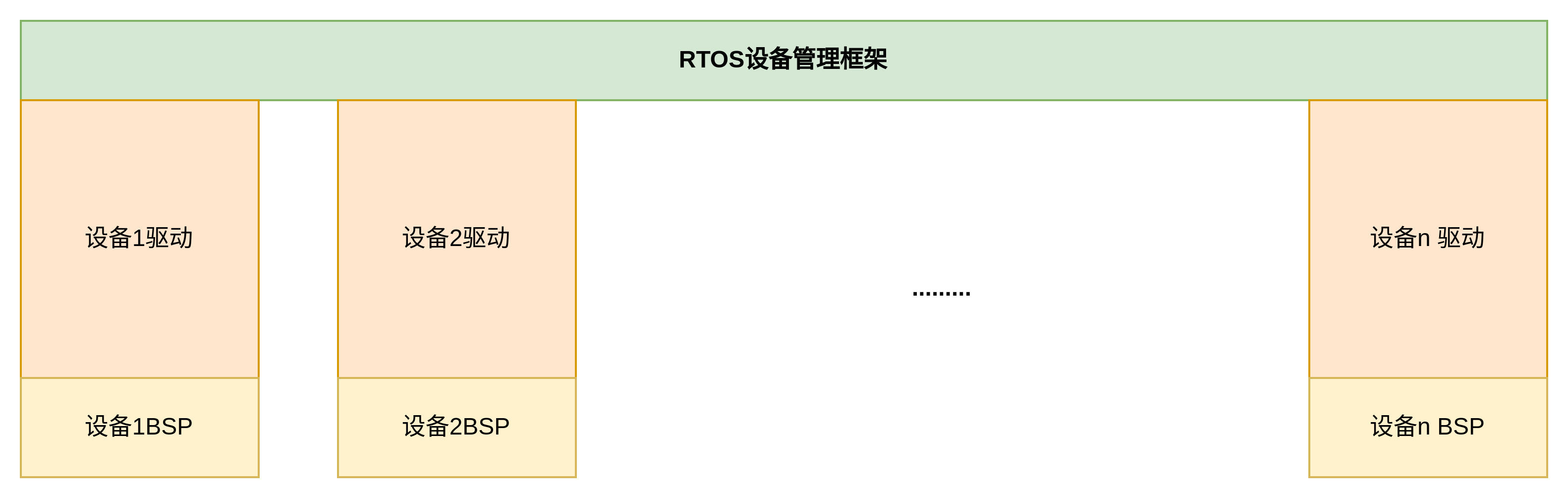
Linux设备驱动模型与 sysfs实现分析
RTOS和Linux系统上开发驱动的方式非常的不同,在RTOS系统下,驱动和驱动之间并没有实质性的联系,不同的驱动和BSP之间仅仅通过一层很薄很薄的设备管理框架聚合在一起构成RTOS的设备管理子系统。图形化表示如下: 设备驱动&BSP之间互相独立,互不影响,互不依赖,独立实现,…...

软考高级之制定备考计划
制定备考计划 高项准备时间最好是三个月以上,分为三个阶段来复习。 第一个阶段——熟悉知识点 第二个阶段——刷题 第三个阶段——冲刺复习 具体操作 第一个阶段 这个阶段的复习以教材和视频为主,掌握重要知识点。基础知识要打牢。例如࿱…...

[Pytorch] Linear层输出nan
参考链接: https://discuss.pytorch.org/t/well-formed-input-into-a-simple-linear-layer-output-nan/74720/11 总结原因: numpy需要更新 PS. 查看numpy版本号 打开Anaconda Prompt 进入环境 输入命令conda activate envname 然后输入pip show numpy…...

2023-2-19-What is ‘ template<typename E, E V> ‘?
目录C里面template怎么用inline函数模板类模板函数模板特化C里面template怎么用 template是什么? template其实是C的一种语法糖,本意是去简化程序员的工作. void swap(int *a,int *b){int temp *a;*a *b;*b temp; }比如在写一个交换函数的的时候,参数为两个in…...
)
华为OD机试题 - 字符串加密(JavaScript)
最近更新的博客 华为OD机试题 - 任务总执行时长(JavaScript) 华为OD机试题 - 开放日活动(JavaScript) 华为OD机试 - 最近的点 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试题 - 最小步骤数(JavaScript) 华为OD机试题 - 任务混部(JavaScript) 华为OD机试题 - N 进…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...