Redis底层原理(持久化+分布式锁)
Redis底层原理
持久化
Redis虽然是个内存数据库,但是Redis支持RDB和AOF (Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中 ;Append Only File(追加文件))两种持久化机制,将数据写往磁盘,可以有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程。所谓内存快照,就是指内存中的数据在某一个时刻的状态记录。这就类似于照片,当你给朋友拍照时,一张照片就能把朋友一瞬间的形象完全记下来。RDB 就是Redis DataBase 的缩写。
给哪些内存数据做快照?
Redis 的数据都在内存中,为了提供所有数据的可靠性保证,它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中。但是,RDB 文件就越大,往磁盘上写数据的时间开销就越大。
RDB文件的生成是否会阻塞主线程
Redis 提供了两个手动命令来生成 RDB 文件,分别是 save 和 bgsave。
save:在主线程中执行,会导致阻塞;对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。 bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是Redis RDB 文件生成的默认配置。
命令实战演示


除了执行命令手动触发之外,Redis内部还存在自动触发RDB 的持久化机制,例如以下场景:
1)使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。

2)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
3)执行debug reload命令重新加载Redis 时,也会自动触发save操作。

4)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。
关闭RDB持久化,在课程讲述的Redis版本(6.2.4)上,是将配置文件中的save配置改为 save “”

bgsave执的行流程
为了快照而暂停写操作,肯定是不能接受的。所以这个时候,Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。
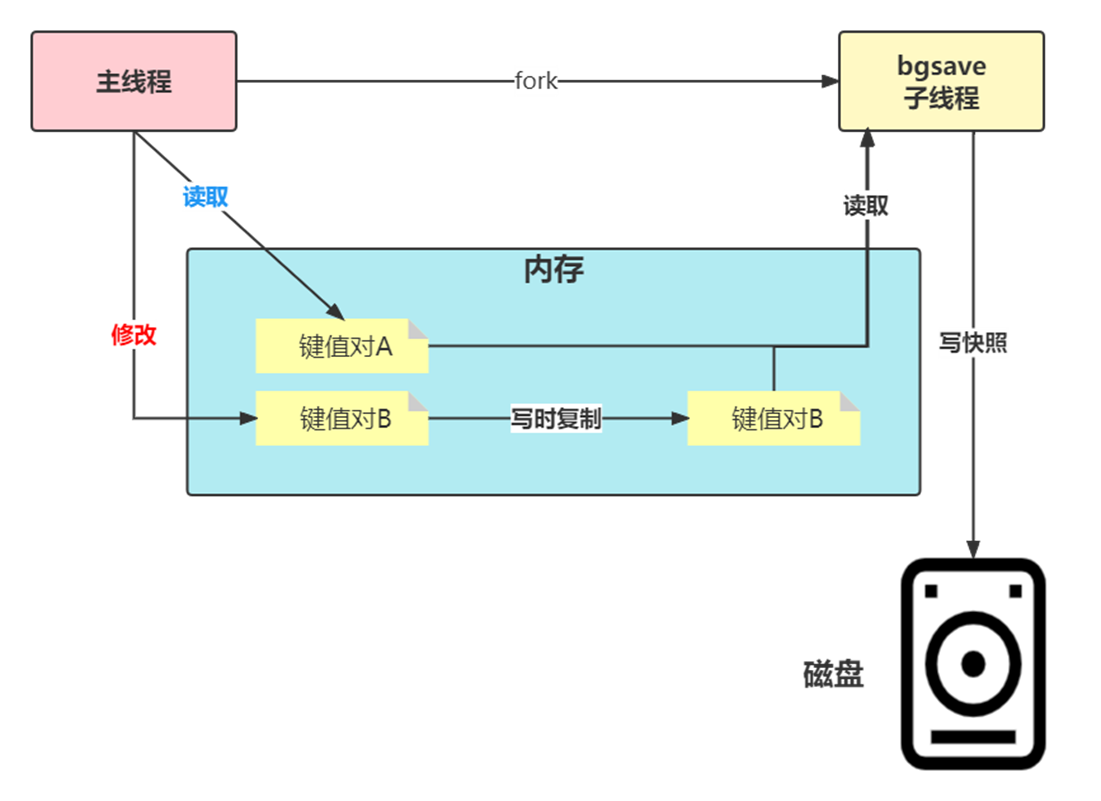
bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。
如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 B),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
这既保证了快照的完整性,也允许主线程同时对数据进行修改,避免了对正常业务的影响。
RDB文件
RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配置指定。

可以通过执行config set dir {newDir}和config set dbfilename (newFileName}运行期动态执行,当下次运行时RDB文件会保存到新目录。

Redis默认采用LZF算法对生成的RDB文件做压缩处理,压缩后的文件远远小于内存大小,默认开启,可以通过参数config set rdbcompression { yes |no}动态修改。 虽然压缩RDB会消耗CPU,但可大幅降低文件的体积,方便保存到硬盘或通过网维示络发送给从节点,因此线上建议开启。 如果 Redis加载损坏的RDB文件时拒绝启动,并打印如下日志:
Short read or OOM loading DB. Unrecoverable error,aborting now.
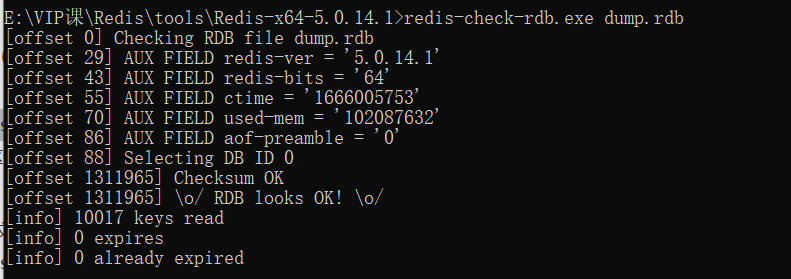
这时可以使用Redis提供的redis-check-rdb工具(老版本是redis-check-dump)检测RDB文件并获取对应的错误报告。
RDB的优缺点
RDB的优点
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景。
比如每隔几小时执行bgsave备份,并把 RDB文件拷贝到远程机器或者文件系统中(如hdfs),,用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
Redis中RDB导致的数据丢失问题
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
如下图所示,我们先在 T0 时刻做了一次快照(下一次快照是T4时刻),然后在T1时刻,数据块 5 和 8 被修改了。如果在T2时刻,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 8 的修改值因为没有快照记录,就无法恢复了。
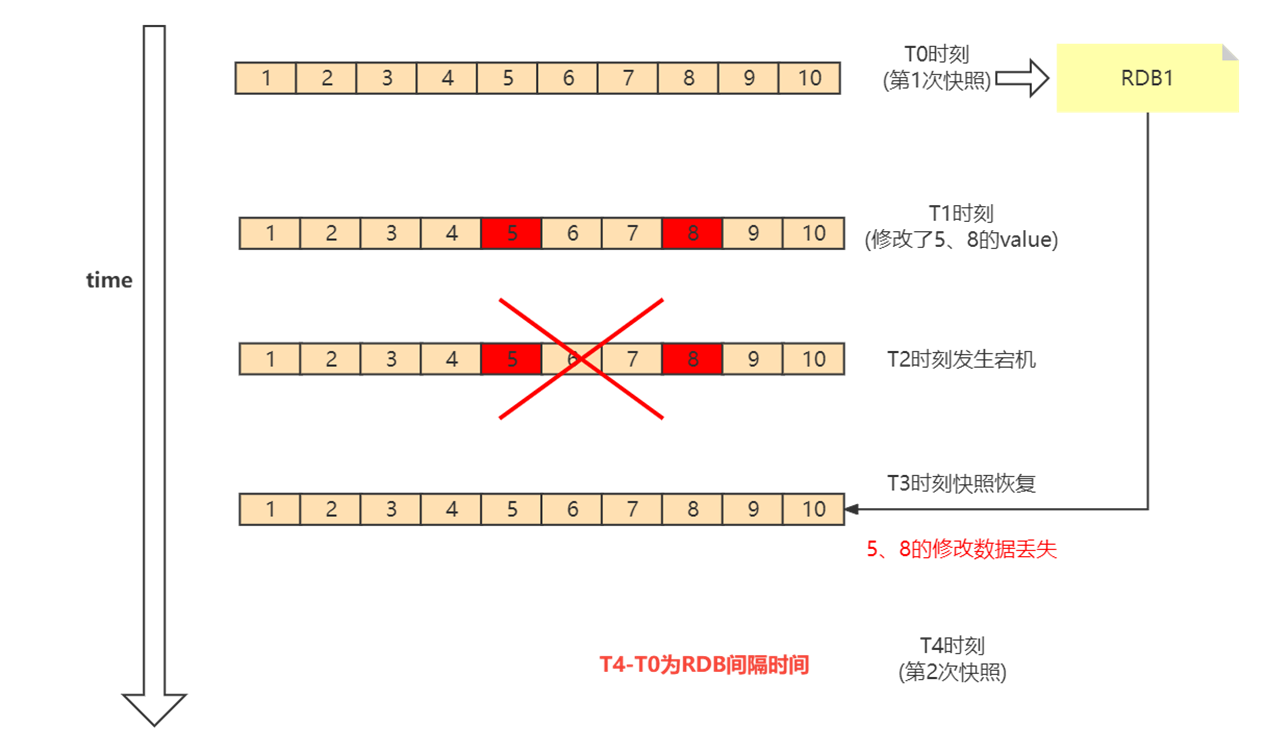
所以这里可以看出,如果想丢失较少的数据,那么T4-T0就要尽可能的小,但是如果频繁地执行全量 快照,也会带来两方面的开销:
1、频繁将全量数据写入磁盘,会给磁盘带来很大压力,多个快照竞争有限的磁盘带宽,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环。
2、另一方面,bgsave 子进程需要通过 fork 操作从主线程创建出来。虽然子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间越长。如果频繁fork出bgsave 子进程,这就会频繁阻塞主线程了。
所以基于这种情况,我们就需要AOF的持久化机制。
AOF
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。理解掌握好AOF持久化机制对我们兼顾数据安全性和性能非常有帮助。
使用AOF
开启AOF功能需要设置配置:appendonly yes,默认不开启。

AOF文件名通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同RDB持久化方式一致,通过dir配置指定。
AOF的工作流程
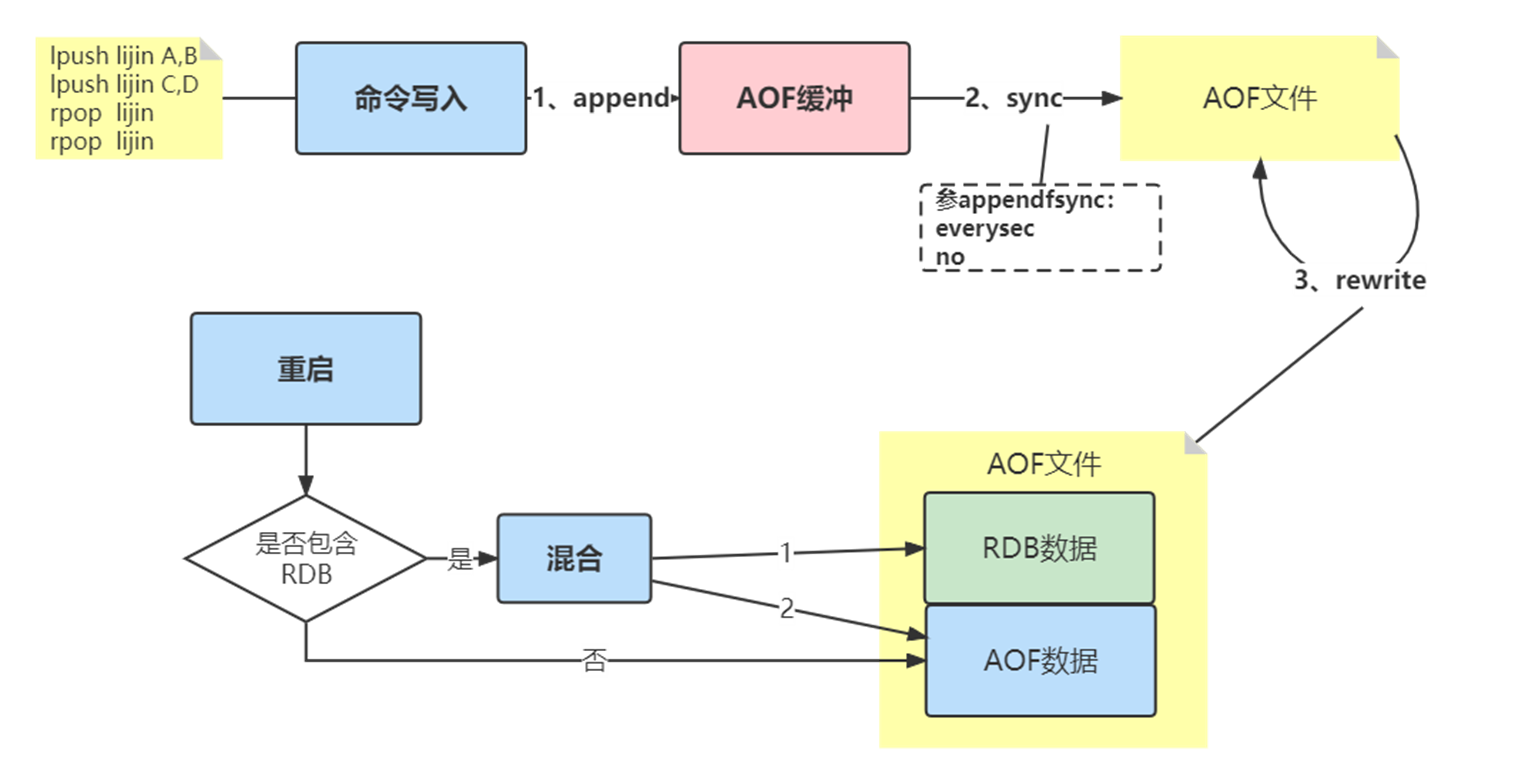
AOF的工作流程主要是4个部分:命令写入( append)、文件同步( sync)、文件重写(rewrite)、重启加载( load)。
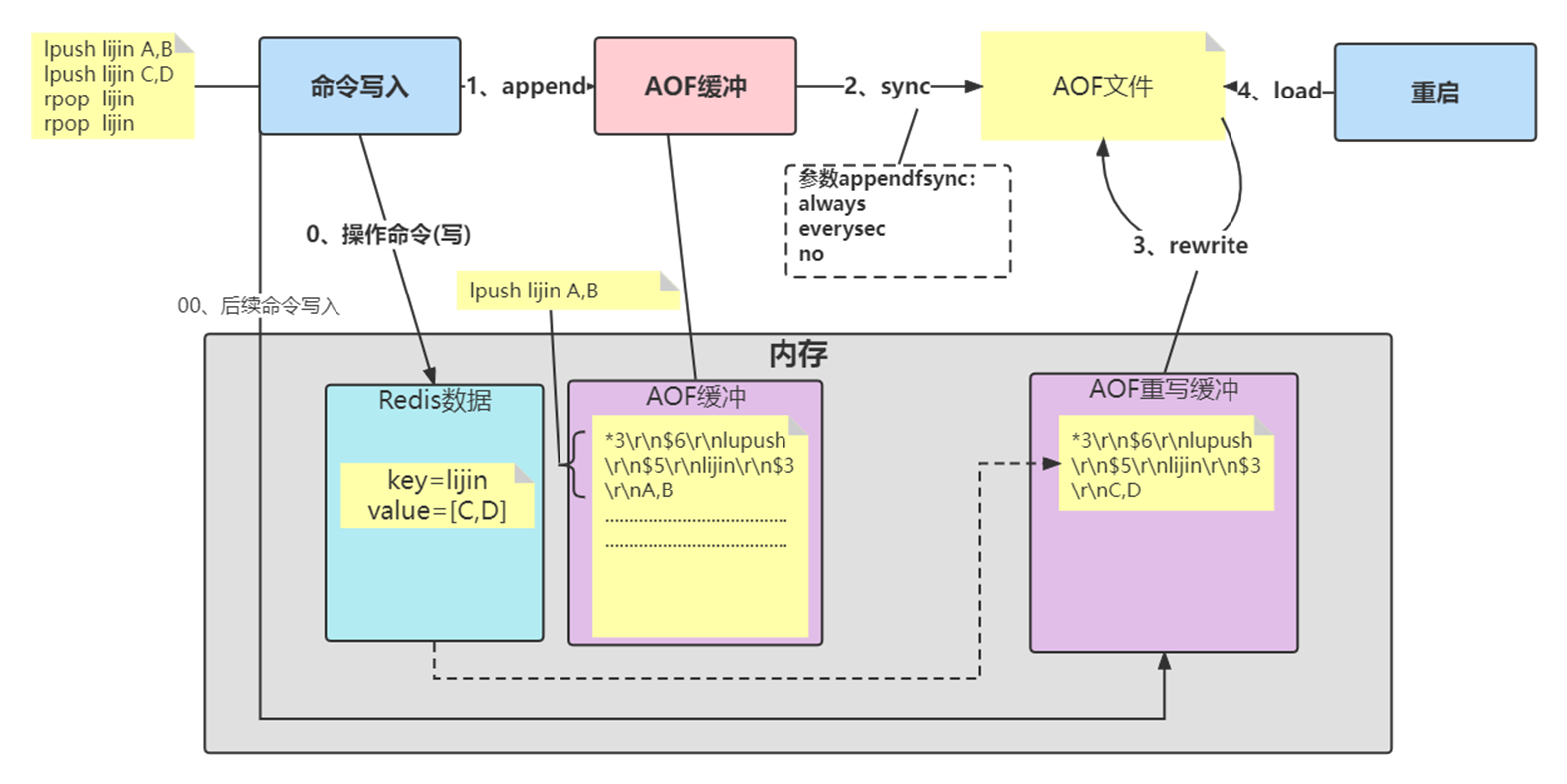
命令写入
AOF命令写入的内容直接是RESP文本协议格式。例如lpush lijin A B这条命令,在AOF缓冲区会追加如下文本:
*3\r\n$6\r\nlupush\r\n$5\r\nlijin\r\n$3\r\nA B
看看 AOF 日志的内容。其中,“*3”表示当前命令有三个部分,每部分都是由“$+数字”开头,后面紧跟着 具体的命令、键或值。这里,“数字”表示这部分中的命令、键或值一共有多少字节。例如,“$3 set”表示这部分有 3 个字节,也就是“set”命令。
1 )AOF为什么直接采用文本协议格式?
文本协议具有很好的兼容性。开启AOF后,所有写入命令都包含追加操作,直接采用协议格式,避免了二次处理开销。文本协议具有可读性,方便直接修改和处理。
2)AOF为什么把命令追加到aof_buf中?
Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡。
Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制。

always
同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
everysec
每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
no
操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘,通常同步周期最长30秒。
很明显,配置为always时,每次写入都要同步AOF文件,在一般的SATA 硬盘上,Redis只能支持大约几百TPS写入,显然跟Redis高性能特性背道而驰,不建议配置。
配置为no,由于操作系统每次同步AOF文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
配置为everysec,是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性。理论上只有在系统突然宕机的情况下丢失1秒的数据。(严格来说最多丢失1秒数据是不准确的)
想要获得高性能,就选择 no 策略;如果想要得到高可靠性保证,就选择always 策略;如果允许数据有一点丢失,又希望性能别受太大影响的话,那么就选择everysec 策略。
重写机制
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制压缩文件体积。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
重写后的AOF 文件为什么可以变小?有如下原因:
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件含有无效命令,如set a 111、set a 222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
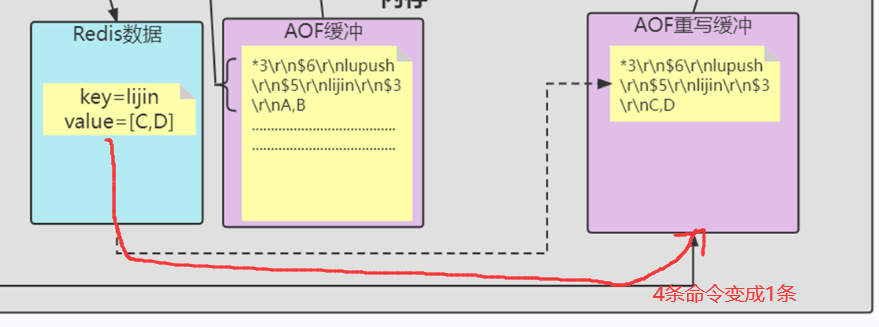
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为: lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。
AOF重写降低了文件占用空间,除此之外,另一个目的是:更小的AOF文件可以更快地被Redis加载。
AOF重写过程可以手动触发和自动触发:
手动触发:直接调用bgrewriteaof命令。

自动触发:根据auto-aof-rewrite-min-size和 auto-aof-rewrite-percentage参数确定自动触发时机。

auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认为64MB。
auto-aof-rewrite-percentage :代表当前AOF 文件空间(aof_currentsize)和上一次重写后AOF 文件空间(aof_base_size)的比值。
另外,如果在Redis在进行AOF重写时,有写入操作,这个操作也会被写到重写日志的缓冲区。这样,重写日志也不会丢失最新的操作。
重启加载
AOF和 RDB 文件都可以用于服务器重启时的数据恢复。redis重启时加载AOF与RDB的顺序是怎么样的呢?
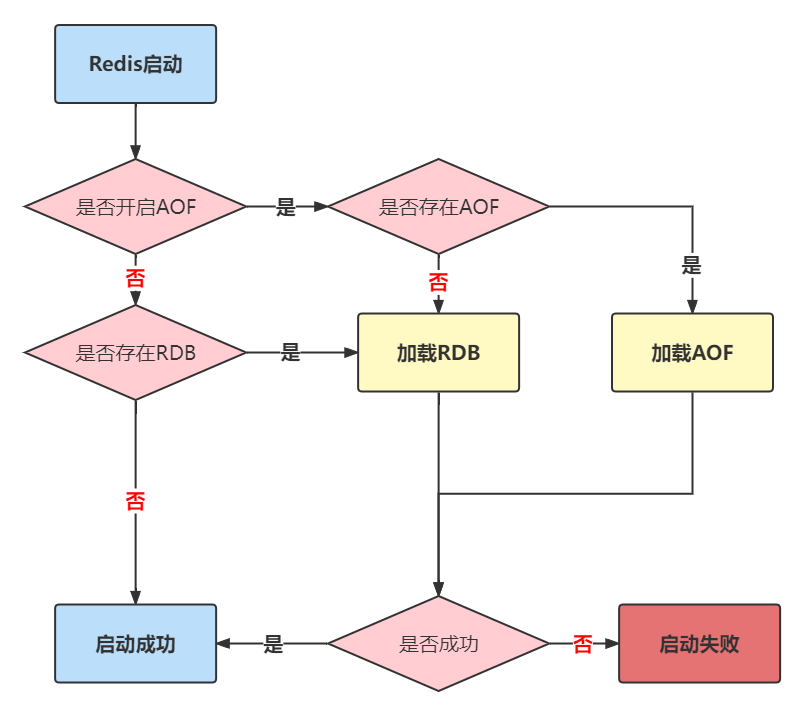
1,当AOF和RDB文件同时存在时,优先加载AOF
2,若关闭了AOF,加载RDB文件
3,加载AOF/RDB成功,redis重启成功
4,AOF/RDB存在错误,启动失败打印错误信息
文件校验
加载损坏的AOF 文件时会拒绝启动,对于错误格式的AOF文件,先进行备份,然后采用redis-check-aof --fix命令进行修复,对比数据的差异,找出丢失的数据,有些可以人工修改补全。
AOF文件可能存在结尾不完整的情况,比如机器突然掉电导致AOF尾部文件命令写入不全。Redis为我们提供了aof-load-truncated 配置来兼容这种情况,默认开启。加载AOF时当遇到此问题时会忽略并继续启动,同时如下警告日志。

优缺点(持久化策略的选择的参考)
-
### RDB(数据量小,并发量小的情况下,可以选择) - 优点: - RDB 是一个非常紧凑(compact)的文件,体积小,因此在传输速度上比较快,因此适合灾难恢复。- RDB 可以最大化Redis 的性能:父进程在保存RDB 文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘I/O 操作。- RDB 在恢复大数据集时的速度比AOF 的恢复速度要快。 - 缺点: RDB是一个快照过程,无法完整的保存所有数据,尤其在数据量比较大时候,一旦出现故障丢失的数据将更多。 当redis中数据集比较大时候,RDB由于RDB方式需要对数据进行完成拷贝并生成快照文件,fork的子进程会耗CPU,并且数据越大,RDB快照生成会越耗时。 RDB文件是特定的格式,阅读性差,由于格式固定,可能存在不兼容情况。 ### AOF(并发量大的情况下,可以选择) - 优点:- 数据更完整,秒级数据丢失(取决于设置fsync策略)。- 兼容性较高,由于是基于redis通讯协议而形成的命令追加方式,无论何种版本的redis都兼容,再者aof文件是明文的,可阅读性较好。 - 缺点:- 数据文件体积较大,即使有重写机制,但是在相同的数据集情况下,AOF文件通常比RDB文件大。- 相对RDB方式,AOF速度慢于RDB,并且在数据量大时候,恢复速度AOF速度也是慢于RDB。- 由于频繁地将命令同步到文件中,AOF持久化对性能的影响相对RDB较大。 ### 混合持久化(4.0版本以后的默认选择方式) - 优点: 混合持久化结合了RDB持久化 和 AOF 持久化的优点, 由于绝大部分都是RDB格式,加载速度快,同时结合AOF,增量的数据以AOF方式保存了,减少数据丢失。 - 缺点: 兼容性差,一旦开启了混合持久化,在4.0之前版本都不识别该aof文件,同时由于前部分是RDB格式,阅读性较差。
redis淘汰策略(持久化后,完整流程下应该关注怎么淘汰)
参考文章
redis六种淘汰策略,redis默认的淘汰策略,如何设置redis淘汰策略和最大内存
(noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外)
redis六种淘汰策略,redis默认的淘汰策略,如何设置redis淘汰策略和最大内存_嗑嗑嗑瓜子的猫的博客-CSDN博客_redis默认淘汰策略
redis淘汰策略
redis淘汰策略_我们一直在路上的博客-CSDN博客_redis淘汰策略
RDB-AOF混合持久化
通过 aof-use-rdb-preamble 配置项可以打开混合开关,yes则表示开启,no表示禁用,默认是禁用的,可通过config set修改

该状态开启后,如果执行bgrewriteaof命令,则会把当前内存中已有的数据弄成二进程存放在aof文件中,这个过程模拟了rdb生成的过程,然后Redis后面有其他命令,在触发下次重写之前,依然采用AOF追加的方式
Redis持久化相关的问题
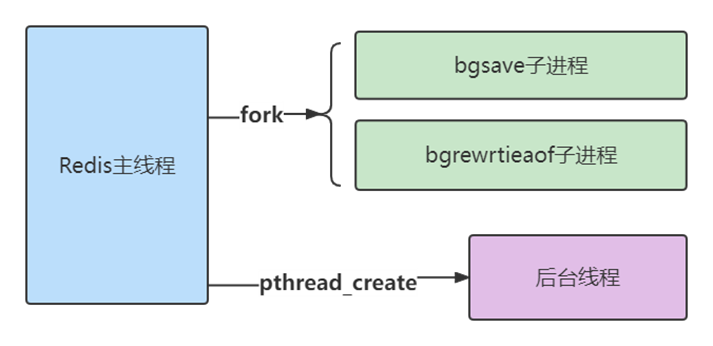
主线程、子进程和后台线程的联系与区别?
进程和线程的区别
从操作系统的角度来看,进程一般是指资源分配单元,例如一个进程拥有自己的堆、栈、虚存空间(页表)、文件描述符等;
而线程一般是指 CPU 进行调度和执行的实体。
一个进程启动后,没有再创建额外的线程,那么,这样的进程一般称为主进程或主线程。
Redis 启动以后,本身就是一个进程,它会接收客户端发送的请求,并处理读写操作请求。而且,接收请求和处理请求操作是 Redis 的主要工作,Redis 没有再依赖于其他线程,所以,我一般把完成这个主要工作的 Redis 进程,称为主进程或主线程。
主线程与子进程
通过fork创建的子进程,一般和主线程会共用同一片内存区域,所以上面就需要使用到写时复制技术确保安全。
后台线程
从 4.0 版本开始,Redis 也开始使用pthread_create 创建线程,这些线程在创建后,一般会自行执行一些任务,例如执行异步删除任务
Redis持久化过程中有没有其他潜在的阻塞风险?
当Redis做RDB或AOF重写时,一个必不可少的操作就是执行fork操作创建子进程,对于大多数操作系统来说fork是个重量级错误。虽然fork创建的子进程不需要拷贝父进程的物理内存空间,但是会复制父进程的空间内存页表。例如对于10GB的Redis进程,需要复制大约20MB的内存页表,因此fork操作耗时跟进程总内存量息息相关,如果使用虚拟化技术,特别是Xen虚拟机,fork操作会更耗时。
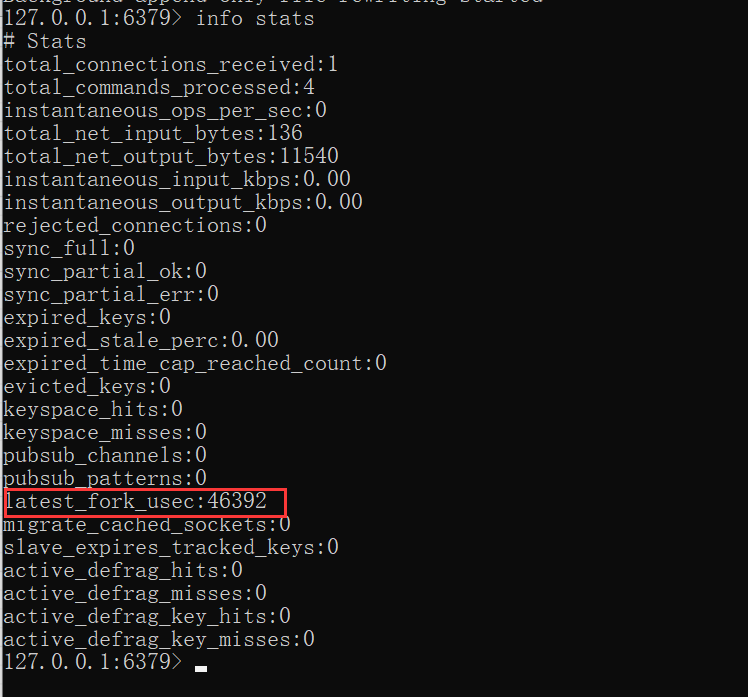
fork耗时问题定位:
对于高流量的Redis实例OPS可达5万以上,如果fork操作耗时在秒级别将拖慢Redis几万条命令执行,对线上应用延迟影响非常明显。正常情况下fork耗时应该是每GB消耗20毫秒左右。可以在info stats统计中查latest_fork_usec指标获取最近一次fork操作耗时,单位微秒。
如何改善fork操作的耗时:
1)优先使用物理机或者高效支持fork操作的虚拟化技术
2)控制Redis实例最大可用内存,fork耗时跟内存量成正比,线上建议每个Redis实例内存控制在10GB 以内。
3)降低fork操作的频率,如适度放宽AOF自动触发时机,避免不必要的全量复制等。
持久化机制问题:参考文档
redis持久化机制_redis默认的持久化方式_CaptainCats的博客-CSDN博客
为什么主从库间的复制不使用 AOF?
1、RDB 文件是二进制文件,无论是要把 RDB 写入磁盘,还是要通过网络传输 RDB,IO效率都比记录和传输 AOF 的高。
2、在从库端进行恢复时,用 RDB 的恢复效率要高于用 AOF。
分布式锁
Redis分布式锁最简单的实现
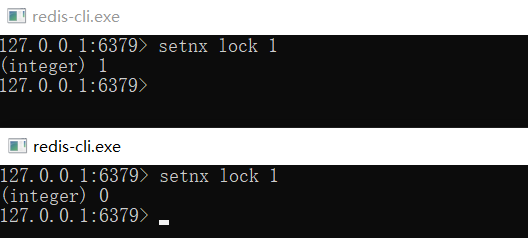
想要实现分布式锁,必须要求 Redis 有「互斥」的能力,我们可以使用 SETNX 命令,这个命令表示SET if Not Exists,即如果 key 不存在,才会设置它的值,否则什么也不做。
两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
客户端 1 申请加锁,加锁成功:
客户端 2 申请加锁,因为它后到达,加锁失败:
此时,加锁成功的客户端,就可以去操作「共享资源」,例如,修改 MySQL 的某一行数据,或者调用一个 API 请求。
操作完成后,还要及时释放锁,给后来者让出操作共享资源的机会。如何释放锁呢?
也很简单,直接使用 DEL 命令删除这个 key 即可,这个逻辑非常简单。
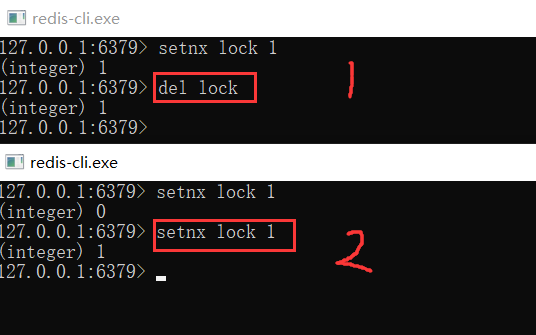
但是,它存在一个很大的问题,当客户端 1 拿到锁后,如果发生下面的场景,就会造成「死锁」:
1、程序处理业务逻辑异常,没及时释放锁
2、进程挂了,没机会释放锁
这时,这个客户端就会一直占用这个锁,而其它客户端就「永远」拿不到这把锁了。怎么解决这个问题呢?
如何避免死锁?
我们很容易想到的方案是,在申请锁时,给这把锁设置一个「租期」。
在 Redis 中实现时,就是给这个 key 设置一个「过期时间」。这里我们假设,操作共享资源的时间不会超过 10s,那么在加锁时,给这个 key 设置 10s 过期即可:
SETNX lock 1 // 加锁 EXPIRE lock 10 // 10s后自动过期

这样一来,无论客户端是否异常,这个锁都可以在 10s 后被「自动释放」,其它客户端依旧可以拿到锁。
但现在还是有问题:
现在的操作,加锁、设置过期是 2 条命令,有没有可能只执行了第一条,第二条却「来不及」执行的情况发生呢?例如:
-
SETNX 执行成功,执行EXPIRE 时由于网络问题,执行失败
-
SETNX 执行成功,Redis 异常宕机,EXPIRE 没有机会执行
-
SETNX 执行成功,客户端异常崩溃,EXPIRE也没有机会执行
总之,这两条命令不能保证是原子操作(一起成功),就有潜在的风险导致过期时间设置失败,依旧发生「死锁」问题。
在 Redis 2.6.12 之后,Redis 扩展了 SET 命令的参数,用这一条命令就可以了:
SET lock 1 EX 10 NX

锁被别人释放怎么办?
上面的命令执行时,每个客户端在释放锁时,都是「无脑」操作,并没有检查这把锁是否还「归自己持有」,所以就会发生释放别人锁的风险,这样的解锁流程,很不「严谨」!如何解决这个问题呢?
解决办法是:客户端在加锁时,设置一个只有自己知道的「唯一标识」进去。
例如,可以是自己的线程 ID,也可以是一个 UUID(随机且唯一),这里我们以UUID 举例:
SET lock $uuid EX 20 NX
之后,在释放锁时,要先判断这把锁是否还归自己持有,伪代码可以这么写:
if redis.get("lock") == $uuid:redis.del("lock")
这里释放锁使用的是 GET + DEL 两条命令,这时,又会遇到我们前面讲的原子性问题了。这里可以使用lua脚本来解决。
安全释放锁的 Lua 脚本如下:
if redis.call("GET",KEYS[1]) == ARGV[1]
thenreturn redis.call("DEL",KEYS[1])
elsereturn 0
end
好了,这样一路优化,整个的加锁、解锁的流程就更「严谨」了。
这里我们先小结一下,基于 Redis 实现的分布式锁,一个严谨的的流程如下:
1、加锁
SET lock_key $unique_id EX $expire_time NX
2、操作共享资源
3、释放锁:Lua 脚本,先 GET 判断锁是否归属自己,再DEL 释放锁
Java代码实现分布式锁
package com.msb.redis.lock;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.params.SetParams;import java.util.Arrays;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;/*** 分布式锁的实现*/
@Component
public class RedisDistLock implements Lock {private final static int LOCK_TIME = 5*1000;private final static String RS_DISTLOCK_NS = "tdln:";/*if redis.call('get',KEYS[1])==ARGV[1] thenreturn redis.call('del', KEYS[1])else return 0 end*/private final static String RELEASE_LOCK_LUA ="if redis.call('get',KEYS[1])==ARGV[1] then\n" +" return redis.call('del', KEYS[1])\n" +" else return 0 end";/*保存每个线程的独有的ID值*/private ThreadLocal<String> lockerId = new ThreadLocal<>();/*解决锁的重入*/private Thread ownerThread;private String lockName = "lock";@Autowiredprivate JedisPool jedisPool;public String getLockName() {return lockName;}public void setLockName(String lockName) {this.lockName = lockName;}public Thread getOwnerThread() {return ownerThread;}public void setOwnerThread(Thread ownerThread) {this.ownerThread = ownerThread;}@Overridepublic void lock() {while(!tryLock()){try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}@Overridepublic void lockInterruptibly() throws InterruptedException {throw new UnsupportedOperationException("不支持可中断获取锁!");}@Overridepublic boolean tryLock() {Thread t = Thread.currentThread();if(ownerThread==t){/*说明本线程持有锁*/return true;}else if(ownerThread!=null){/*本进程里有其他线程持有分布式锁*/return false;}Jedis jedis = null;try {String id = UUID.randomUUID().toString();SetParams params = new SetParams();params.px(LOCK_TIME);params.nx();synchronized (this){/*线程们,本地抢锁*/if((ownerThread==null)&&"OK".equals(jedis.set(RS_DISTLOCK_NS+lockName,id,params))){lockerId.set(id);setOwnerThread(t);return true;}else{return false;}}} catch (Exception e) {throw new RuntimeException("分布式锁尝试加锁失败!");} finally {jedis.close();}}@Overridepublic boolean tryLock(long time, TimeUnit unit) throws InterruptedException {throw new UnsupportedOperationException("不支持等待尝试获取锁!");}@Overridepublic void unlock() {if(ownerThread!=Thread.currentThread()) {throw new RuntimeException("试图释放无所有权的锁!");}Jedis jedis = null;try {jedis = jedisPool.getResource();Long result = (Long)jedis.eval(RELEASE_LOCK_LUA,Arrays.asList(RS_DISTLOCK_NS+lockName),Arrays.asList(lockerId.get()));if(result.longValue()!=0L){System.out.println("Redis上的锁已释放!");}else{System.out.println("Redis上的锁释放失败!");}} catch (Exception e) {throw new RuntimeException("释放锁失败!",e);} finally {if(jedis!=null) jedis.close();lockerId.remove();setOwnerThread(null);System.out.println("本地锁所有权已释放!");}}@Overridepublic Condition newCondition() {throw new UnsupportedOperationException("不支持等待通知操作!");}}
锁过期时间不好评估怎么办?
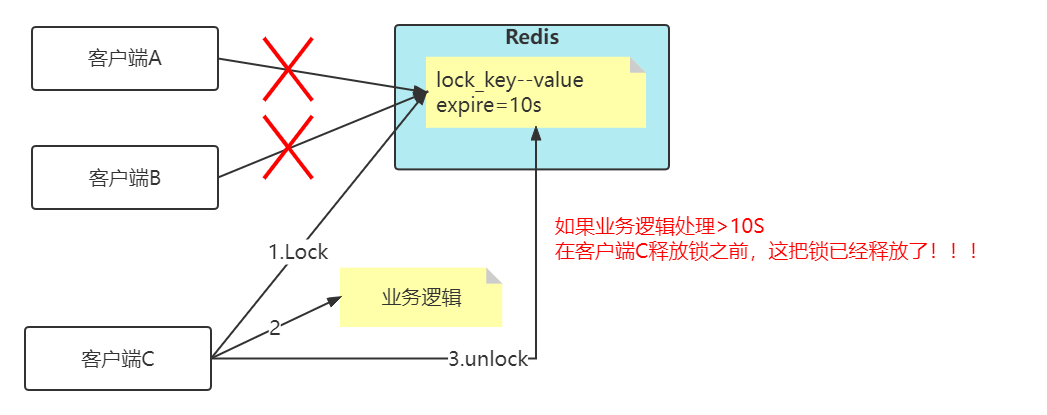
看上面这张图,加入key的失效时间是10s,但是客户端C在拿到分布式锁之后,然后业务逻辑执行超过10s,那么问题来了,在客户端C释放锁之前,其实这把锁已经失效了,那么客户端A和客户端B都可以去拿锁,这样就已经失去了分布式锁的功能了!!!
比较简单的妥协方案是,尽量「冗余」过期时间,降低锁提前过期的概率,但是这个并不能完美解决问题,那怎么办呢?
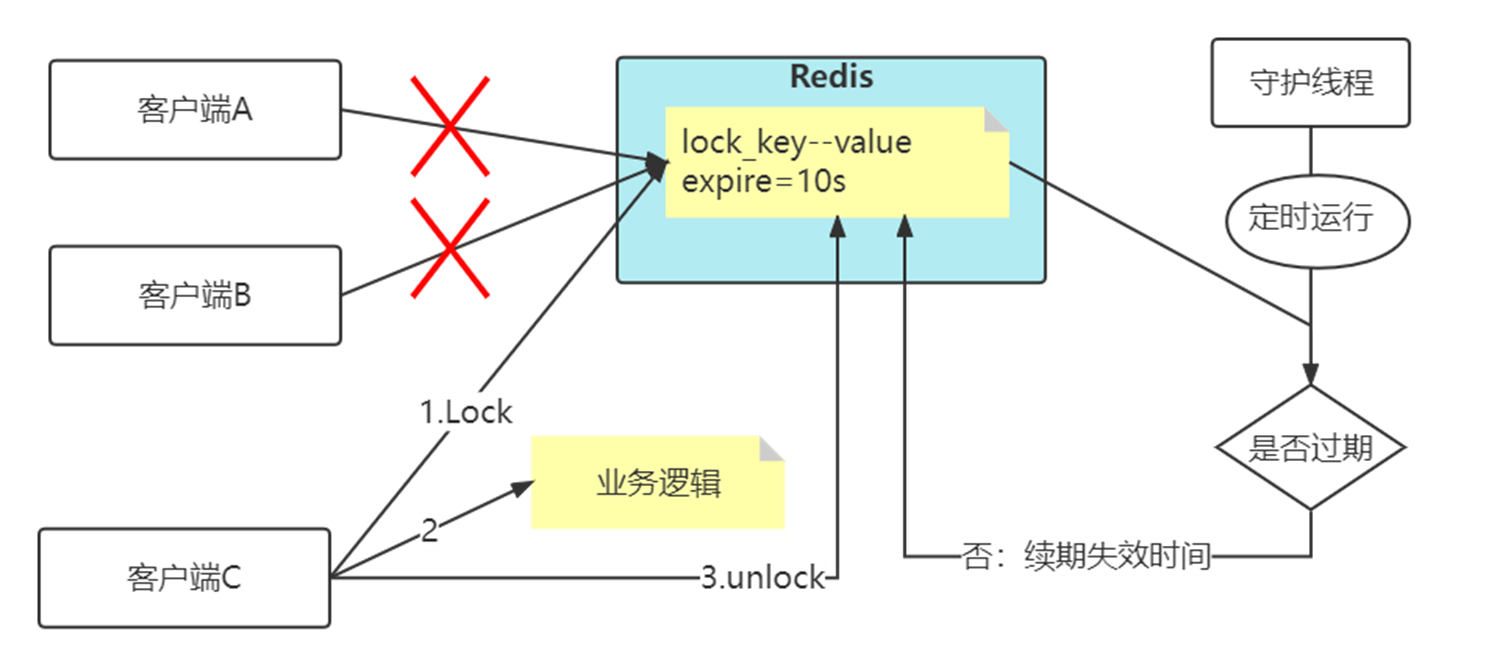
分布式锁加入看门狗
加锁时,先设置一个过期时间,然后我们开启一个「守护线程」,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行「续期」,重新设置过期时间。
这个守护线程我们一般也把它叫做「看门狗」线程。
为什么要使用守护线程:
分布式锁加入看门狗代码实现

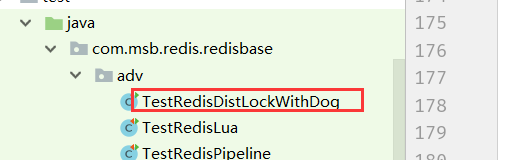
运行效果:

Redisson中的分布式锁
Redisson把这些工作都封装好了
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.12.3</version></dependency>
package com.msb.redis.config;import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MyRedissonConfig {/*** 所有对Redisson的使用都是通过RedissonClient*/@Bean(destroyMethod="shutdown")public RedissonClient redisson(){//1、创建配置Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");//2、根据Config创建出RedissonClient实例RedissonClient redisson = Redisson.create(config);return redisson;}
}
package com.msb.redis.redisbase.adv;import com.msb.redis.lock.rdl.RedisDistLockWithDog;
import org.junit.jupiter.api.Test;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;@SpringBootTest
public class TestRedissionLock {private int count = 0;@Autowiredprivate RedissonClient redisson;@Testpublic void testLockWithDog() throws InterruptedException {int clientCount =3;RLock lock = redisson.getLock("RD-lock");CountDownLatch countDownLatch = new CountDownLatch(clientCount);ExecutorService executorService = Executors.newFixedThreadPool(clientCount);for (int i = 0;i<clientCount;i++){executorService.execute(() -> {try {lock.lock(10, TimeUnit.SECONDS);System.out.println(Thread.currentThread().getName()+"准备进行累加。");Thread.sleep(2000);count++;} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}countDownLatch.countDown();});}countDownLatch.await();System.out.println(count);}
}
GitHub - redisson/redisson: Redisson - Redis Java client with features of In-Memory Data Grid. Over 50 Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Publish / Subscribe, Bloom filter, Spring Cache, Tomcat, Scheduler, JCache API, Hibernate, MyBatis, RPC, local cache ...
Redisson: Redis Java client with features of In-Memory Data Grid
锁过期时间不好评估怎么办?
集群下的锁还安全么?
基于 Redis 的实现分布式锁,前面遇到的问题,以及对应的解决方案:
1、死锁:设置过期时间
2、过期时间评估不好,锁提前过期:守护线程,自动续期
3、锁被别人释放:锁写入唯一标识,释放锁先检查标识,再释放
之前分析的场景都是,锁在「单个」Redis实例中可能产生的问题,并没有涉及到 Redis 的部署架构细节。
而我们在使用 Redis 时,一般会采用主从集群 +哨兵的模式部署,这样做的好处在于,当主库异常宕机时,哨兵可以实现「故障自动切换」,把从库提升为主库,继续提供服务,以此保证可用性。
但是因为主从复制是异步的,那么就不可避免会发生的锁数据丢失问题(加了锁却没来得及同步过来)。从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!
Redlock真的安全吗?
Redis 作者提出的 Redlock方案,是如何解决主从切换后,锁失效问题的。
Redlock 的方案基于一个前提:
不再需要部署从库和哨兵实例,只部署主库;但主库要部署多个,官方推荐至少 5 个实例。
注意:不是部署 Redis Cluster,就是部署 5 个简单的 Redis 实例。它们之间没有任何关系,都是一个个孤立的实例。
做完之后,我们看官网代码怎么去用的:
8. 分布式锁和同步器 · redisson/redisson Wiki · GitHub
8.4. 红锁(RedLock)
基于Redis的Redisson红锁 RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个 RLock对象关联为一个红锁,每个 RLock对象实例可以来自于不同的Redisson实例。
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功。
lock.lock();
...
lock.unlock();
大家都知道,如果负责储存某些分布式锁的某些Redis节点宕机以后,而且这些锁正好处于锁住的状态时,这些锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了 leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3); // 给lock1,lock2,lock3加锁,如果没有手动解开的话,10秒钟后将会自动解开 lock.lock(10, TimeUnit.SECONDS); // 为加锁等待100秒时间,并在加锁成功10秒钟后自动解开 boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS); ... lock.unlock();
Redlock实现整体流程
1、客户端先获取「当前时间戳T1」
2、客户端依次向这 5 个 Redis 实例发起加锁请求
3、如果客户端从 >=3 个(大多数)以上Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败。
4、加锁成功,去操作共享资源
5、加锁失败/释放锁,向「全部节点」发起释放锁请求。
所以总的来说:客户端在多个 Redis 实例上申请加锁;必须保证大多数节点加锁成功;大多数节点加锁的总耗时,要小于锁设置的过期时间;释放锁,要向全部节点发起释放锁请求。
我们来看 Redlock 为什么要这么做?
-
为什么要在多个实例上加锁?
本质上是为了「容错」,部分实例异常宕机,剩余的实例加锁成功,整个锁服务依旧可用。
-
为什么大多数加锁成功,才算成功?
多个 Redis 实例一起来用,其实就组成了一个「分布式系统」。在分布式系统中,总会出现「异常节点」,所以,在谈论分布式系统问题时,需要考虑异常节点达到多少个,也依旧不会影响整个系统的「正确性」。
这是一个分布式系统「容错」问题,这个问题的结论是:如果只存在「故障」节点,只要大多数节点正常,那么整个系统依旧是可以提供正确服务的。
-
为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久,而且,因为是网络请求,网络情况是复杂的,有可能存在延迟、丢包、超时等情况发生,网络请求越多,异常发生的概率就越大。
所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经「超过」了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
-
为什么释放锁,要操作所有节点?
在某一个 Redis 节点加锁时,可能因为「网络原因」导致加锁失败。
例如,客户端在一个 Redis 实例上加锁成功,但在读取响应结果时,网络问题导致读取失败,那这把锁其实已经在 Redis 上加锁成功了。
所以,释放锁时,不管之前有没有加锁成功,需要释放「所有节点」的锁,以保证清理节点上「残留」的锁。
好了,明白了 Redlock 的流程和相关问题,看似Redlock 确实解决了 Redis 节点异常宕机锁失效的问题,保证了锁的「安全性」。
但事实真的如此吗?
RedLock的是是非非
一个分布式系统,更像一个复杂的「野兽」,存在着你想不到的各种异常情况。
这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
N:Network Delay,网络延迟
P:Process Pause,进程暂停(GC)
C:Clock Drift,时钟漂移
比如一个进程暂停(GC)的例子
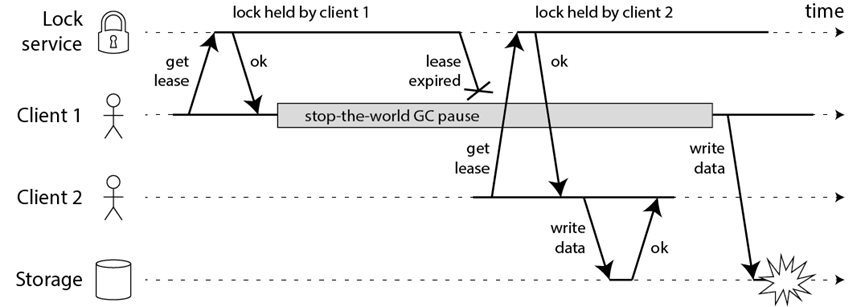
1)客户端 1 请求锁定节点 A、B、C、D、E
2)客户端 1 的拿到锁后,进入 GC(时间比较久)
3)所有 Redis 节点上的锁都过期了
4)客户端 2 获取到了 A、B、C、D、E 上的锁
5)客户端 1 GC 结束,认为成功获取锁
6)客户端 2 也认为获取到了锁,发生「冲突」
GC 和网络延迟问题:这两点可以在红锁实现流程的第3步来解决这个问题。
但是最核心的还是时钟漂移,因为时钟漂移,就有可能导致第3步的判断本身就是一个BUG,所以当多个 Redis 节点「时钟」发生问题时,也会导致 Redlock 锁失效。
RedLock总结
Redlock 只有建立在「时钟正确」的前提下,才能正常工作,如果你可以保证这个前提,那么可以拿来使用。
但是时钟偏移在现实中是存在的:
第一,从硬件角度来说,时钟发生偏移是时有发生,无法避免。例如,CPU 温度、机器负载、芯片材料都是有可能导致时钟发生偏移的。
第二,人为错误也是很难完全避免的。
所以,Redlock尽量不用它,而且它的性能不如单机版 Redis,部署成本也高,优先考虑使用主从+ 哨兵的模式 实现分布式锁(只会有很小的记录发生主从切换时的锁丢失问题)。
相关文章:
Redis底层原理(持久化+分布式锁)
Redis底层原理 持久化 Redis虽然是个内存数据库,但是Redis支持RDB和AOF (Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中 ;Appen…...
Spring Cloud Nacos实战(八) - Nacos集群配置
Nacos集群配置 更改Nacos启动命令配置原理 我们现在知道,想要启动Naocs只需要启动startup.sh命令即可,但是如果启动3个Nacos那?所以如果我们需要启动多个Nacos,其实Nacos本身默认启动就是集群模式。 注意点:如果是l…...

什么是低代码-甲骨文对低代码的定义
什么是低代码平台?低代码阶段使用简化的界面,允许开发人员构建应用程序和软件 既用户友好又响应迅速。而不是编写几行复杂的代码和语言结构, 您可以快速轻松地利用低代码来构建具有用户界面的整体应用程序, 组合和信息。低代码可以…...

shell编程之循环语句
typora-copy-images-to: pictures typora-root-url: …\pictures 文章目录typora-copy-images-to: pictures typora-root-url: ..\..\pictures一、for循环语句1. for循环语法结构㈠ 列表循环㈡ 不带列表循环㈢ 类C风格的for循环2. 应用案例㈠ 脚本计算1-100奇数和① 思路② 落地…...

神经动力学-第一章-神经动力学基础-神经系统的元素
神经元和数学 本章的主要目的是介绍神经科学的几个基本概念,尤其是动作电位、突触后电位、触发阈值、不应期和适应性。基于这些概念,建立了神经元动力学的初步模型,这个简单的模型(漏积分-火模型)将作为本书主题——广义积分-火模型的起点和参考,在第二部分和第三部分进…...
【力扣-LeetCode】64. 最小路径和 C++题解
64. 最小路径和难度中等1430收藏分享切换为英文接收动态反馈给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。说明:每次只能向下或者向右移动一步。示例 1:输入ÿ…...

Mysql数据库事务
数据库事务 数据库事务由一组sql语句组成。 所有sql语句执行成功则事务整体成功;任一条sql语句失败则事务整体失败,数据恢复到事务之前的状态。 Mysql 事务操作 开始事务 start transaction;- 或 begin;事务开始后,对数据的增删改操作不…...

【opencv源码解析0.3】调试opencv源码的两种方式
调试opencv源码的两种方式 上两篇我们分别讲了如何配置opencv环境,以及如何编译opencv源码方便我们阅读。但我们还是无法调试我们的代码,无法以我们的程序作为入口来一步一步单点调试看opencv是如何执行的。 【opencv源码解析0.1】VS如何优雅的配置ope…...
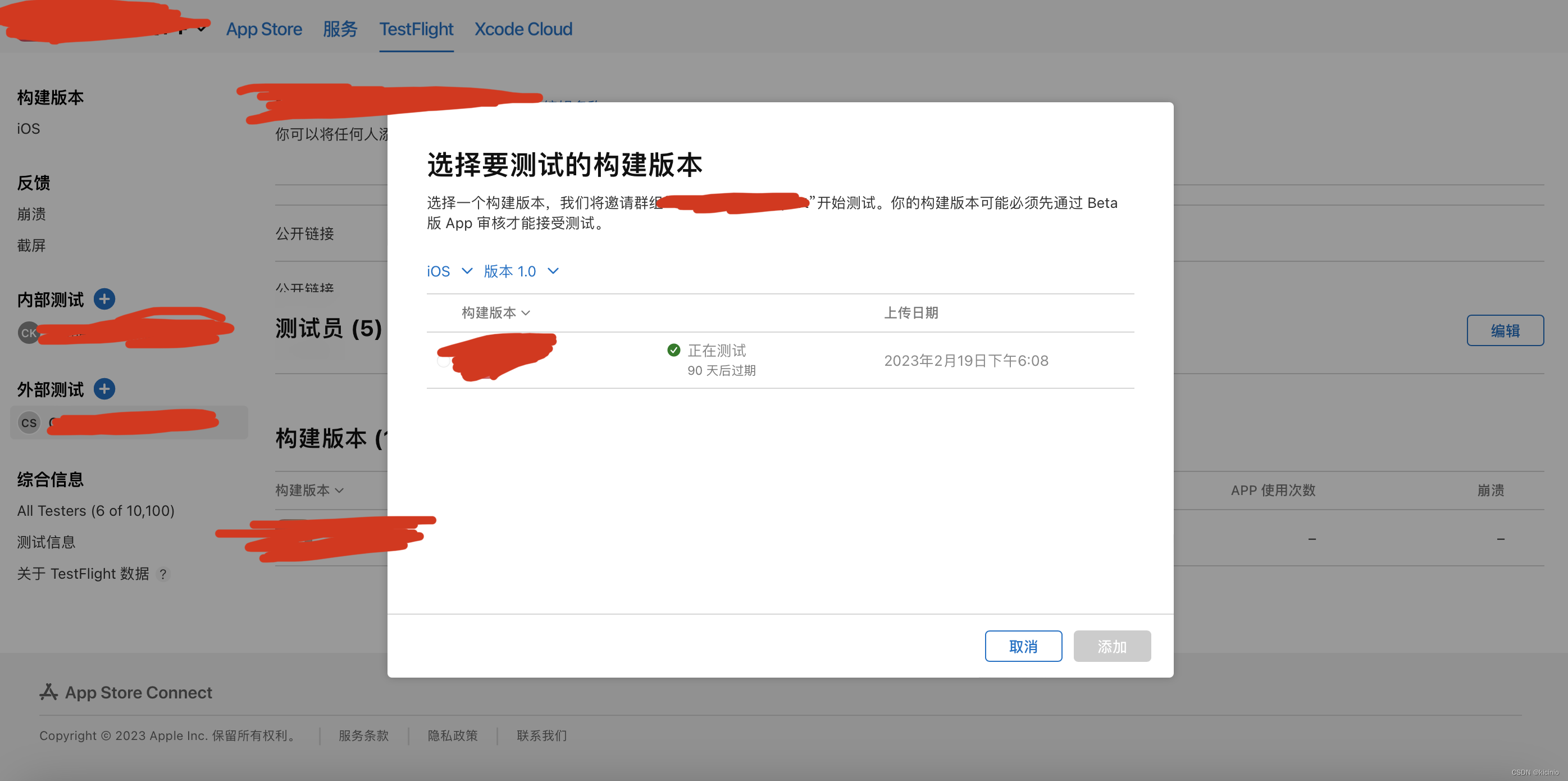
Xcode Archives打包上传 / 导出ipa 发布至TestFlight
Xcode自带的Archives工具可以傻瓜式上传到App Store Connect分发这里以分发到TestFlight为例进行操作。 环境:Xcode 14 一:Archives打包 选择Xcode菜单栏的Product,Archives选项,需要等待编译完成,进入如下界面&…...
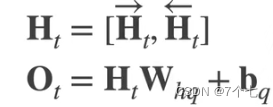
RNN GRU模型 LSTM模型图解笔记
RNN模型图解引用RNN模型GRULSTM深度RNN双向循环神经网络引用 动手学深度学习v2–李沐 LSTM长短期记忆网络3D模型–B站up梗直哥丶 RNN模型 加入了一个隐变量(状态),隐变量由上个隐变量和上一个输入而更新,这样模型就可以达到具有短期记忆的效…...
西电_数字信号处理二_学习笔记
文章目录【 第1章 离散随机信号 】【 第2章 维纳滤波 】【 第3章 卡尔曼滤波 】【 第4章 自适应滤波 】【 第5章 功率谱估计 】这是博主2022秋季所学数字信号处理二的思维导图(软件是幕布),供大家参考,如内容上有不妥之处…...
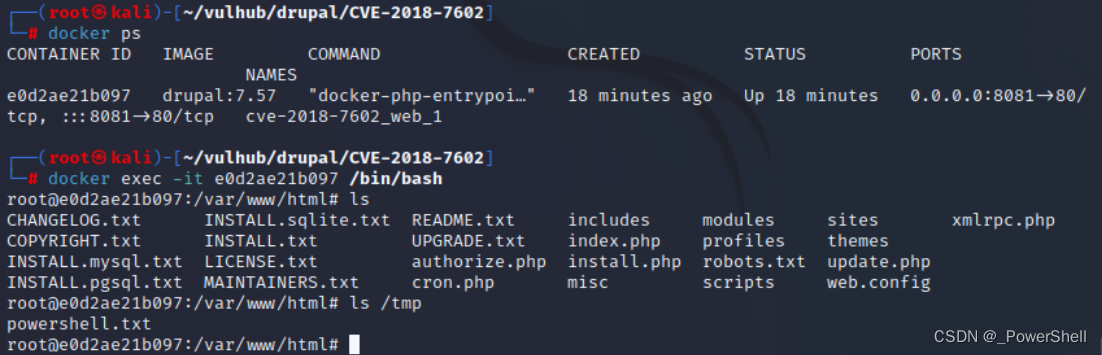
[ vulhub漏洞复现篇 ] Drupal 远程代码执行漏洞(CVE-2018-7602)
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
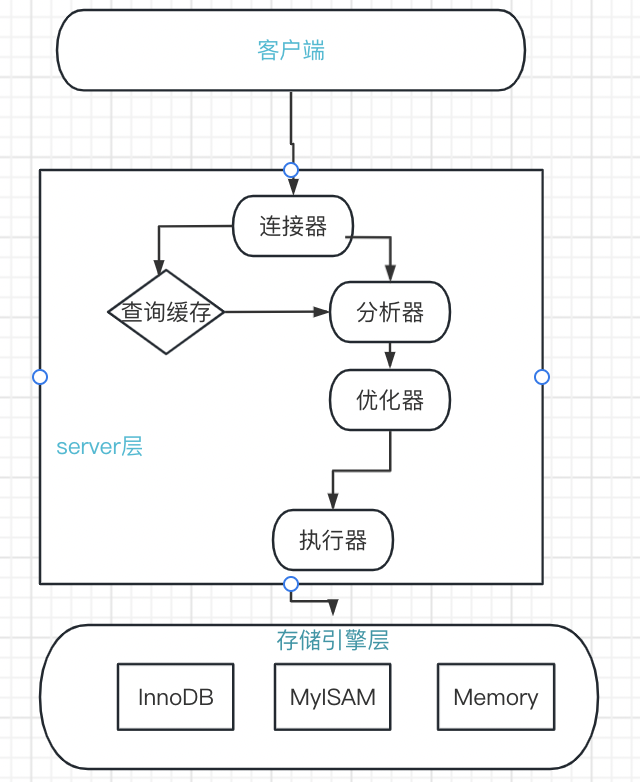
MySQL最佳实践
一、MySQL查询执行过程 1.MySQL分层结构 MySQL8.0没有查询缓存的功能了,如果频繁修改缓存,将会损耗性能查询流程就按照分层结构就可以清楚,只要了解各个组件的各自功能就行分析器主要分析语法和词法是否正确优化器主要优化SQL语句 二、MySQL更新执行过程 更新主要涉及两个重…...

Python 之 Matplotlib 散点图、箱线图和词云图
文章目录一、散点图1. scatter() 函数2. 设置图标大小3. 自定义点的颜色和透明度4. 可以选择不同的颜色条,配合 cmap 参数5. cmap 的分类5.1 Sequential colormaps:连续化色图5.2 Diverging colormaps:两端发散的色图 .5.3 Qualitative color…...
SpringCloud(三)Hystrix断路器服务降级、服务熔断、服务监控案例详解
七、Hystrix断路器 7.1 简介 分布式系统面临的问题 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。 多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微…...
【超好用】自定义的mybatis-plus代码生成器
BACKGROUND你是否也有这样的烦恼:每次写代码都需要创建很多包很多层很多类很多接口?耗时且费力姑且不谈,有时可能还大意了没有闪,搞出一堆bug这谁顶得住啊都3202年了,让程序自力更生吧!!教程 le…...
监控pod的资源使用量20230219)
Kubernetes学习笔记-计算资源管理(4)监控pod的资源使用量20230219
前面学了设置资源的requests和limits,这节课学习如何监控资源,根据监控资源使用情况,对requests和limits进行合理配置。收集、获取实际资源使用情况kubelet包含一个agent,名为cAdvisor,它会收集整个节点上运行的所有单…...
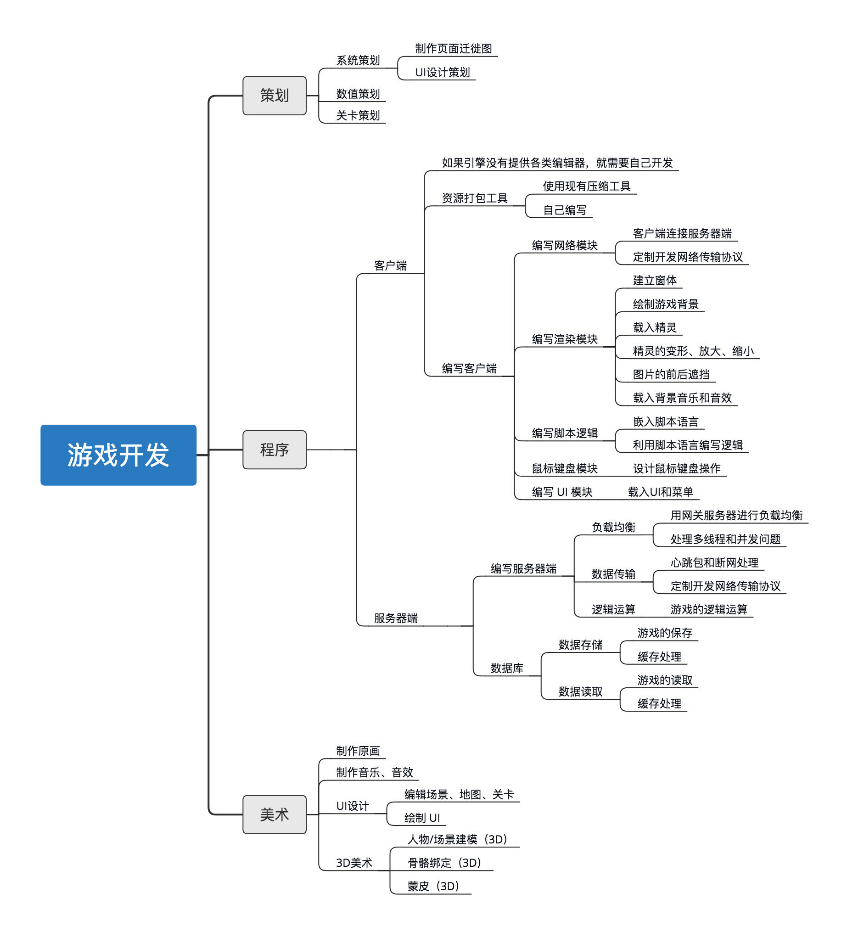
游戏开发 - 开发流程 - 收集
1.应用场景 主要用于了解,掌握游戏开发的整个流程。 2.学习/操作 1.文档阅读 复习课 | 带你梳理客户端开发的三个重点-极客时间 2.整理输出 2.1 游戏开发流程 -- 参考 按照游戏开发中的三大模块策划、程序、美术,画了一个图。 开发游戏的时候ÿ…...

LA@向量空间@坐标变换
文章目录向量空间向量空间的属性坐标例基变换坐标变换n维向量空间RnR^nRn子空间例线性组合与线性方程组生成子空间深度学习向量空间 设VVV是n维向量的非空集合,如果VVV对向量的加法和数乘运算封闭,即 ∀α,β∈V,∀k∈Rαβ,kα∈V\forall \alpha,\beta\in{V},\forall k\in{\ma…...
JSP脚本指令及标记学习笔记
好久没更新文章了,上次更新的文章还是一个学习笔记。本篇博文介绍的是JSP基本概念 1.JSP开发方法 一个jsp网页只需要加上<%%>就行了。 2.JSP运行机制 3.JSP脚本元素 3.1 JSP脚本代码 <% 脚本代码 %>实例 <% SimpleDateFormat df new SimpleDa…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...