Apache Doris 入门教程33:统计信息
统计信息
统计信息简介
Doris 查询优化器使用统计信息来确定查询最有效的执行计划。Doris 维护的统计信息包括表级别的统计信息和列级别的统计信息。
表统计信息:
| 信息 | 描述 |
|---|---|
row_count | 表的行数 |
data_size | 表的⼤⼩(单位 byte) |
update_rows | 收集统计信息后所更新的行数 |
healthy | 表的健康度 |
update_time | 最近更新的时间 |
last_analyze_time | 上次收集统计信息的时间 |
表的健康度:表示表统计信息的健康程度。当
update_rows大于等于row_count时,健康度为 0;当update_rows小于row_count时,健康度为100 * (1 - update_rows / row_count)。
列统计信息:
| 信息 | 描述 |
|---|---|
row_count | 列的总行数 |
data_size | 列的总⻓度(单位 byte) |
avg_size_byte | 列的平均⻓度(单位 bytes) |
ndv | 列 num distinct value |
min | 列最小值 |
max | 列最⼤值 |
null_count | 列 null 个数 |
收集统计信息
手动收集
⽤户通过 ANALYZE 语句触发手动收集任务,根据提供的参数,收集指定的表或列的统计信息。
列统计信息收集语法:
ANALYZE < TABLE | DATABASE table_name | db_name > [ PARTITIONS (partition_name [, ...]) ][ (column_name [, ...]) ][ [ WITH SYNC ] [WITH INCREMENTAL] [ WITH SAMPLE PERCENT | ROWS ] [ WITH PERIOD ] ][ PROPERTIES ("key" = "value", ...) ];
其中:
- table_name: 指定的的目标表。可以是
db_name.table_name形式。 - partition_name: 指定的目标分区(目前只针对Hive外表)。必须是
table_name中存在的分区,多个列名称用逗号分隔。分区名样例:event_date=20230706, nation=CN/city=Beijing - column_name: 指定的目标列。必须是
table_name中存在的列,多个列名称用逗号分隔。 - sync:同步收集统计信息。收集完后返回。若不指定则异步执行并返回任务 ID。
- period:周期性收集统计信息。单位为秒,指定后会定期收集相应的统计信息。
- sample percent | rows:抽样收集统计信息。可以指定抽样比例或者抽样行数。
全量收集
收集列统计信息
列统计信息主要包括列的行数、最大值、最小值、NULL 值个数等,通过 ANALYZE TABLE 语句进行收集。
示例:
- 收集
example_tbl表所有列的统计信息,使用以下语法:
mysql> ANALYZE TABLE stats_test.example_tbl;
+--------+
| job_id |
+--------+
| 51730 |
+--------+
- 收集
example_tbl表city,age,sex列的统计信息,使用以下语法:
mysql> ANALYZE TABLE stats_test.example_tbl(city, age, sex);
+--------+
| job_id |
+--------+
| 51808 |
+--------+
增量收集
对于分区表,在进行全量收集后,如果新增分区或者删除分区,可以使用增量收集来提高统计信息收集的速度。
使用增量收集时系统会自动检查新增的分区或者已删除的分区。有以下三种情形:
- 对于新增分区,收集新分区的统计信息后和历史统计信息合并/汇总。
- 对于已删除的分区,重新刷新历史统计信息。
- 无新增/删除的分区,不做任何操作。
增量收集适合类似时间列这样的单调不减列作为分区的表,或者历史分区数据不会更新的表。
注意:
- 直方图统计信息不支持增量收集。
- 使用增量收集时,必须保证表存量的统计信息可用(即其他历史分区数据不发生变化),否则会导致统计信息有误差。
示例:
- 增量收集
example_tbl表的统计信息,使用以下语法:
-- 使用with incremental
mysql> ANALYZE TABLE stats_test.example_tbl WITH INCREMENTAL;
+--------+
| job_id |
+--------+
| 51910 |
+--------+-- 配置incremental
mysql> ANALYZE TABLE stats_test.example_tbl PROPERTIES("incremental" = "true");
+--------+
| job_id |
+--------+
| 51910 |
+--------+
抽样收集
在表数据量较大时,系统收集统计信息可能会比较耗时,可以使用抽样收集来提高统计信息收集的速度。根据实际情况指定抽样的比例或者抽样的行数。
示例:
- 抽样收集
example_tbl表的统计信息,使用以下语法:
-- 使用with sample rows抽样行数
mysql> ANALYZE TABLE stats_test.example_tbl WITH SAMPLE ROWS 5;
+--------+
| job_id |
+--------+
| 52120 |
+--------+-- 使用with sample percent抽样比例
mysql> ANALYZE TABLE stats_test.example_tbl WITH SAMPLE PERCENT 50;
+--------+
| job_id |
+--------+
| 52201 |
+--------+-- 配置sample.row抽样行数
mysql> ANALYZE TABLE stats_test.example_tbl PROPERTIES("sample.rows" = "5");
+--------+
| job_id |
+--------+
| 52279 |
+--------+-- 配置sample.percent抽样比例
mysql> ANALYZE TABLE stats_test.example_tbl PROPERTIES("sample.percent" = "50");
+--------+
| job_id |
+--------+
| 52282 |
+--------+
同步收集
一般执行 ANALYZE 语句后系统会启动异步任务去收集统计信息并立刻返回统计任务 ID。如果想要等待统计信息收集结束后返会,可以使用同步收集方式。
示例:
- 抽样收集
example_tbl表的统计信息,使用以下语法:
-- 使用with sync
mysql> ANALYZE TABLE stats_test.example_tbl WITH SYNC;-- 配置sync
mysql> ANALYZE TABLE stats_test.example_tbl PROPERTIES("sync" = "true");
自动收集
自动收集是指用户在执行 ANALYZE 语句时,指定 PERIOD 或者 AUTO 关键字或者进行相关配置时,系统后续将自动生成任务,进行统计信息的收集。
周期性收集
周期性收集是指在一定时间间隔内,重新收集表相应的统计信息。
示例:
- 周期性(每隔一天)收集
example_tbl表的统计信息,使用以下语法:
-- 使用with period
mysql> ANALYZE TABLE stats_test.example_tbl WITH PERIOD 86400;
+--------+
| job_id |
+--------+
| 52409 |
+--------+-- 配置period.seconds
mysql> ANALYZE TABLE stats_test.example_tbl PROPERTIES("period.seconds" = "86400");
+--------+
| job_id |
+--------+
| 52535 |
+--------+
管理任务
查看统计任务
通过 SHOW ANALYZE 来查看统计信息收集任务的信息。
语法如下:
SHOW ANALYZE < table_name | job_id >[ WHERE [ STATE = [ "PENDING" | "RUNNING" | "FINISHED" | "FAILED" ] ] ];
其中:
- table_name:表名,指定后可查看该表对应的统计任务信息。可以是
db_name.table_name形式。不指定时返回所有统计任务信息。 - job_id:统计信息任务 ID,执行
ANALYZE非同步收集统计信息时所返回的值。不指定时返回所有统计任务信息。
目前 SHOW ANALYZE 会输出 11 列,具体如下:
| 列名 | 说明 |
|---|---|
job_id | 统计任务 ID |
catalog_name | catalog 名称 |
db_name | 数据库名称 |
tbl_name | 表名称 |
col_name | 列名称 |
job_type | 任务类型 |
analysis_type | 统计类型 |
message | 任务信息 |
last_exec_time_in_ms | 上次执行时间 |
state | 任务状态 |
schedule_type | 调度方式 |
在系统中,统计信息任务包含多个子任务,每个子任务单独收集一列的统计信息。
示例:
- 查看 ID 为
20038的统计任务信息,使用以下语法:
mysql> SHOW ANALYZE 20038
+--------+--------------+----------------------+----------+-----------------------+----------+---------------+---------+----------------------+----------+---------------+
| job_id | catalog_name | db_name | tbl_name | col_name | job_type | analysis_type | message | last_exec_time_in_ms | state | schedule_type |
+--------+--------------+----------------------+----------+-----------------------+----------+---------------+---------+----------------------+----------+---------------+
| 20038 | internal | default_cluster:test | t3 | [col4,col2,col3,col1] | MANUAL | FUNDAMENTALS | | 2023-06-01 17:22:15 | FINISHED | ONCE |
+--------+--------------+----------------------+----------+-----------------------+----------+---------------+---------+----------------------+----------+---------------+可通过SHOW ANALYZE TASK STATUS [job_id],查看具体每个列统计信息的收集完成情况。
mysql> show analyze task status 20038 ;
+---------+----------+---------+----------------------+----------+
| task_id | col_name | message | last_exec_time_in_ms | state |
+---------+----------+---------+----------------------+----------+
| 20039 | col4 | | 2023-06-01 17:22:15 | FINISHED |
| 20040 | col2 | | 2023-06-01 17:22:15 | FINISHED |
| 20041 | col3 | | 2023-06-01 17:22:15 | FINISHED |
| 20042 | col1 | | 2023-06-01 17:22:15 | FINISHED |
+---------+----------+---------+----------------------+----------+- 查看
example_tbl表的的统计任务信息,使用以下语法:
mysql> SHOW ANALYZE stats_test.example_tbl;
+--------+--------------+----------------------------+-------------+-----------------+----------+---------------+---------+----------------------+----------+---------------+
| job_id | catalog_name | db_name | tbl_name | col_name | job_type | analysis_type | message | last_exec_time_in_ms | state | schedule_type |
+--------+--------------+----------------------------+-------------+-----------------+----------+---------------+---------+----------------------+----------+---------------+
| 68603 | internal | default_cluster:stats_test | example_tbl | | MANUAL | INDEX | | 2023-05-05 17:53:27 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | last_visit_date | MANUAL | COLUMN | | 2023-05-05 17:53:26 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | age | MANUAL | COLUMN | | 2023-05-05 17:53:27 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | city | MANUAL | COLUMN | | 2023-05-05 17:53:25 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | cost | MANUAL | COLUMN | | 2023-05-05 17:53:27 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | min_dwell_time | MANUAL | COLUMN | | 2023-05-05 17:53:24 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | date | MANUAL | COLUMN | | 2023-05-05 17:53:27 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | user_id | MANUAL | COLUMN | | 2023-05-05 17:53:25 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | max_dwell_time | MANUAL | COLUMN | | 2023-05-05 17:53:26 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | sex | MANUAL | COLUMN | | 2023-05-05 17:53:26 | FINISHED | ONCE |
- 查看所有的统计任务信息,并按照上次完成时间降序,返回前 3 条信息,使用以下语法:
mysql> SHOW ANALYZE WHERE state = "FINISHED" ORDER BY last_exec_time_in_ms DESC LIMIT 3;
+--------+--------------+----------------------------+-------------+-----------------+----------+---------------+---------+----------------------+----------+---------------+
| job_id | catalog_name | db_name | tbl_name | col_name | job_type | analysis_type | message | last_exec_time_in_ms | state | schedule_type |
+--------+--------------+----------------------------+-------------+-----------------+----------+---------------+---------+----------------------+----------+---------------+
| 68603 | internal | default_cluster:stats_test | example_tbl | age | MANUAL | COLUMN | | 2023-05-05 17:53:27 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | sex | MANUAL | COLUMN | | 2023-05-05 17:53:26 | FINISHED | ONCE |
| 68603 | internal | default_cluster:stats_test | example_tbl | last_visit_date | MANUAL | COLUMN | | 2023-05-05 17:53:26 | FINISHED | ONCE |
+--------+--------------+----------------------------+-------------+-----------------+----------+---------------+---------+----------------------+----------+---------------+
终止统计任务
通过 KILL ANALYZE 来终止正在运行的统计任务。
语法如下:
KILL ANALYZE job_id;
其中:
- job_id:统计信息任务 ID。执行
ANALYZE非同步收集统计信息时所返回的值,也可以通过SHOW ANALYZE语句获取。
示例:
- 终止 ID 为 52357 的统计任务。
mysql> KILL ANALYZE 52357;
查看统计信息
表统计信息
暂不可用。
通过 SHOW TABLE STATS 来查看表的总行数以及统计信息健康度等信息。
语法如下:
SHOW TABLE STATS table_name [ PARTITION (partition_name) ];
其中:
- table_name: 导入数据的目标表。可以是
db_name.table_name形式。 - partition_name: 指定的目标分区。必须是
table_name中存在的分区,只能指定一个分区。
目前 SHOW TABLE STATS 会输出 6 列,具体如下:
| 列名 | 说明 |
|---|---|
row_count | 行数 |
update_rows | 更新的行数 |
data_size | 数据大小。单位 byte |
healthy | 健康度 |
update_time | 更新时间 |
last_analyze_time | 上次收集统计信息的时间 |
示例:
- 查看
example_tbl表的统计信息,使用以下语法:
mysql> SHOW TABLE STATS stats_test.example_tbl;
+-----------+-------------+---------+-----------+---------------------+---------------------+
| row_count | update_rows | healthy | data_size | update_time | last_analyze_time |
+-----------+-------------+---------+-----------+---------------------+---------------------+
| 8 | 0 | 100 | 6999 | 2023-04-08 15:40:47 | 2023-04-08 17:43:28 |
+-----------+-------------+---------+-----------+---------------------+---------------------+
- 查看
example_tbl表p_201701分区的统计信息,使用以下语法:
mysql> SHOW TABLE STATS stats_test.example_tbl PARTITION (p_201701);
+-----------+-------------+---------+-----------+---------------------+---------------------+
| row_count | update_rows | healthy | data_size | update_time | last_analyze_time |
+-----------+-------------+---------+-----------+---------------------+---------------------+
| 4 | 0 | 100 | 2805 | 2023-04-08 11:48:02 | 2023-04-08 17:43:27 |
+-----------+-------------+---------+-----------+---------------------+---------------------+
查看列统计信息
通过 SHOW COLUMN STATS 来查看列的不同值数以及 NULL 数量等信息。
语法如下:
SHOW COLUMN [cached] STATS table_name [ (column_name [, ...]) ] [ PARTITION (partition_name) ];
其中:
- cached: 展示当前FE内存缓存中的统计信息。
- table_name: 收集统计信息的目标表。可以是
db_name.table_name形式。 - column_name: 指定的目标列,必须是
table_name中存在的列,多个列名称用逗号分隔。 - partition_name: 指定的目标分区,必须是
table_name中存在的分区,只能指定一个分区。
目前 SHOW COLUMN STATS 会输出 10 列,具体如下:
| 列名 | 说明 |
|---|---|
column_name | 列名称 |
count | 列的总行数 |
ndv | 不同值的个数 |
num_null | 空值的个数 |
data_size | 列的总⻓度(单位 bytes) |
avg_size_byte | 列的平均⻓度(单位 bytes) |
min | 列最小值 |
max | 列最⼤值 |
示例:
- 查看
example_tbl表所有列的统计信息,使用以下语法:
mysql> SHOW COLUMN STATS stats_test.example_tbl;
+-----------------+-------+------+----------+-------------------+-------------------+-----------------------+-----------------------+
| column_name | count | ndv | num_null | data_size | avg_size_byte | min | max |
+-----------------+-------+------+----------+-------------------+-------------------+-----------------------+-----------------------+
| date | 6.0 | 3.0 | 0.0 | 28.0 | 4.0 | '2017-10-01' | '2017-10-03' |
| cost | 6.0 | 6.0 | 0.0 | 56.0 | 8.0 | 2 | 200 |
| min_dwell_time | 6.0 | 6.0 | 0.0 | 28.0 | 4.0 | 2 | 22 |
| city | 6.0 | 4.0 | 0.0 | 54.0 | 7.0 | 'Beijing' | 'Shenzhen' |
| user_id | 6.0 | 5.0 | 0.0 | 112.0 | 16.0 | 10000 | 10004 |
| sex | 6.0 | 2.0 | 0.0 | 7.0 | 1.0 | 0 | 1 |
| max_dwell_time | 6.0 | 6.0 | 0.0 | 28.0 | 4.0 | 3 | 22 |
| last_visit_date | 6.0 | 6.0 | 0.0 | 112.0 | 16.0 | '2017-10-01 06:00:00' | '2017-10-03 10:20:22' |
| age | 6.0 | 4.0 | 0.0 | 14.0 | 2.0 | 20 | 35 |
+-----------------+-------+------+----------+-------------------+-------------------+-----------------------+-----------------------+
- 查看
example_tbl表p_201701分区的统计信息,使用以下语法:
mysql> SHOW COLUMN STATS stats_test.example_tbl PARTITION (p_201701);
+-----------------+-------+------+----------+--------------------+-------------------+-----------------------+-----------------------+
| column_name | count | ndv | num_null | data_size | avg_size_byte | min | max |
+-----------------+-------+------+----------+--------------------+-------------------+-----------------------+-----------------------+
| date | 3.0 | 1.0 | 0.0 | 16.0 | 4.0 | '2017-10-01' | '2017-10-01' |
| cost | 3.0 | 3.0 | 0.0 | 32.0 | 8.0 | 2 | 100 |
| min_dwell_time | 3.0 | 3.0 | 0.0 | 16.0 | 4.0 | 2 | 22 |
| city | 3.0 | 2.0 | 0.0 | 29.0 | 7.0 | 'Beijing' | 'Shenzhen' |
| user_id | 3.0 | 3.0 | 0.0 | 64.0 | 16.0 | 10000 | 10004 |
| sex | 3.0 | 2.0 | 0.0 | 4.0 | 1.0 | 0 | 1 |
| max_dwell_time | 3.0 | 3.0 | 0.0 | 16.0 | 4.0 | 3 | 22 |
| last_visit_date | 3.0 | 3.0 | 0.0 | 64.0 | 16.0 | '2017-10-01 06:00:00' | '2017-10-01 17:05:45' |
| age | 3.0 | 3.0 | 0.0 | 8.0 | 2.0 | 20 | 35 |
+-----------------+-------+------+----------+--------------------+-------------------+-----------------------+-----------------------+
- 查看
example_tbl表city,age,sex列的统计信息,使用以下语法:
mysql> SHOW COLUMN STATS stats_test.example_tbl(city, age, sex);
+-------------+-------+------+----------+-------------------+-------------------+-----------+------------+
| column_name | count | ndv | num_null | data_size | avg_size_byte | min | max |
+-------------+-------+------+----------+-------------------+-------------------+-----------+------------+
| city | 6.0 | 4.0 | 0.0 | 54.0 | 7.0 | 'Beijing' | 'Shenzhen' |
| sex | 6.0 | 2.0 | 0.0 | 7.0 | 1.0 | 0 | 1 |
| age | 6.0 | 4.0 | 0.0 | 14.0 | 2.0 | 20 | 35 |
+-------------+-------+------+----------+-------------------+-------------------+-----------+------------+
- 查看
example_tbl表p_201701分区city,age,sex列的统计信息,使用以下语法:
mysql> SHOW COLUMN STATS stats_test.example_tbl(city, age, sex) PARTITION (p_201701);
+-------------+-------+------+----------+--------------------+-------------------+-----------+------------+
| column_name | count | ndv | num_null | data_size | avg_size_byte | min | max |
+-------------+-------+------+----------+--------------------+-------------------+-----------+------------+
| city | 3.0 | 2.0 | 0.0 | 29.0 | 7.0 | 'Beijing' | 'Shenzhen' |
| sex | 3.0 | 2.0 | 0.0 | 4.0 | 1.0 | 0 | 1 |
| age | 3.0 | 3.0 | 0.0 | 8.0 | 2.0 | 20 | 35 |
+-------------+-------+------+----------+--------------------+-------------------+-----------+------------+
修改统计信息
⽤户可以通过 ALTER 语句调整统计信息。
ALTER TABLE table_name MODIFY COLUMN column_name SET STATS ('stat_name' = 'stat_value', ...) [ PARTITION (partition_name) ];
其中:
- table_name: 删除统计信息的目标表。可以是
db_name.table_name形式。 - column_name: 指定的目标列,必须是
table_name中存在的列,每次只能修改一列的统计信息。 - stat_name 和 stat_value: 相应的统计信息名称和统计信息信息的值,多个统计信息逗号分隔。可以修改的统计信息包括
row_count,ndv,num_nulls,min_value,max_value,data_size。 - partition_name: 指定的目标分区。必须是
table_name中存在的分区,多个分区使用逗号分割。
示例:
- 修改
example_tbl表age列row_count统计信息,使用以下语法:
mysql> ALTER TABLE stats_test.example_tbl MODIFY COLUMN age SET STATS ('row_count'='6001215');
mysql> SHOW COLUMN STATS stats_test.example_tbl(age);
+-------------+-----------+------+----------+-----------+---------------+------+------+
| column_name | count | ndv | num_null | data_size | avg_size_byte | min | max |
+-------------+-----------+------+----------+-----------+---------------+------+------+
| age | 6001215.0 | 0.0 | 0.0 | 0.0 | 0.0 | N/A | N/A |
+-------------+-----------+------+----------+-----------+---------------+------+------+
- 修改
example_tbl表age列row_count,num_nulls,data_size统计信息,使用以下语法:
mysql> ALTER TABLE stats_test.example_tbl MODIFY COLUMN age SET STATS ('row_count'='6001215', 'num_nulls'='2023', 'data_size'='600121522');
mysql> SHOW COLUMN STATS stats_test.example_tbl(age);
+-------------+-----------+------+----------+-----------+---------------+------+------+
| column_name | count | ndv | num_null | data_size | avg_size_byte | min | max |
+-------------+-----------+------+----------+-----------+---------------+------+------+
| age | 6001215.0 | 0.0 | 2023.0 | 600121522 | 0.0 | N/A | N/A |
+-------------+-----------+------+----------+-----------+---------------+------+------+
删除统计信息
⽤户通过 DROP 语句删除统计信息,根据提供的参数,删除指定的表、分区或列的统计信息。删除时会同时删除列统计信息和列直方图信息。
语法:
DROP [ EXPIRED ] STATS [ table_name [ (column_name [, ...]) ] ];
其中:
- table_name: 要删除统计信息的目标表。可以是
db_name.table_name形式。 - column_name: 指定的目标列。必须是
table_name中存在的列,多个列名称用逗号分隔。 - expired:统计信息清理。不能指定表,会删除系统中无效的统计信息以及过期的统计任务信息。
示例:
- 清理统计信息,使用以下语法:
mysql> DROP EXPIRED STATS;
- 删除
example_tbl表的统计信息,使用以下语法:
mysql> DROP STATS stats_test.example_tbl;
- 删除
example_tbl表city,age,sex列的统计信息,使用以下语法:
mysql> DROP STATS stats_test.example_tbl(city, age, sex);
删除Analyze Job
用于根据job id删除自动/周期Analyze作业
DROP ANALYZE JOB [JOB_ID]
配置项
| conf | comment | default value |
|---|---|---|
| statistics_sql_parallel_exec_instance_num | 控制每个统计信息收集SQL在BE侧的并发实例数/pipeline task num | 1 |
| statistics_sql_mem_limit_in_bytes | 控制每个统计信息SQL可占用的BE内存 | 2L 1024 1024 * 1024 (2GiB) |
| statistics_simultaneously_running_task_num | 通过ANALYZE TABLE[DATABASE]提交异步作业后,可同时analyze的列的数量,所有异步任务共同受到该参数约束 | 5 |
| analyze_task_timeout_in_minutes | AnalyzeTask执行超时时间 | 12 hours |
| stats_cache_size | 统计信息缓存的实际内存占用大小高度依赖于数据的特性,因为在不同的数据集和场景中,最大/最小值的平均大小和直方图的桶数量会有很大的差异。此外,JVM版本等因素也会对其产生影响。下面给出统计信息缓存在包含100000个项目时所占用的内存大小。每个项目的最大/最小值的平均长度为32,列名的平均长度为16,统计信息缓存总共占用了61.2777404785MiB的内存。强烈不建议分析具有非常大字符串值的列,因为这可能导致FE内存溢出。 | 100000 |
常见问题
ANALYZE WITH SYNC 执行失败:Failed to analyze following columns...
SQL执行时间受query_timeout会话变量控制,该变量默认值为300秒,ANALYZE DATABASE/TABLE等语句通常耗时较大,很容易超过该时间限制而被cancel,建议根据ANALYZE对象的数据量适当增大query_timeout的值。
ANALYZE提交报错:Stats table not available...
执行ANALYZE时统计数据会被写入到内部表__internal_schema.column_statistics中,FE会在执行ANALYZE前检查该表tablet状态,如果存在不可用的tablet则拒绝执行任务。出现该报错请检查BE集群状态。
大表ANALYZE失败
由于ANALYZE能够使用的资源受到比较严格的限制,对一些大表的ANALYZE操作有可能超时或者超出BE内存限制。这些情况下,建议使用 ANALYZE ... WITH SAMPLE...。此外对于动态分区表的场景,强烈建议使用ANALYZE ... WITH INCREMENTAL...,该语句仅增量的处理数据更新的分区,能够避免大量的重复计算从而提高效率。
相关文章:

Apache Doris 入门教程33:统计信息
统计信息 统计信息简介 Doris 查询优化器使用统计信息来确定查询最有效的执行计划。Doris 维护的统计信息包括表级别的统计信息和列级别的统计信息。 表统计信息: 信息描述row_count表的行数data_size表的⼤⼩(单位 byte)update_rows收…...

有效需求的特征
如何区分优秀的软件需求和软件需求规格说明书(SRS)与可能导致问题的需求和规格说明书?在这篇文章中,我们将首先讨论单个需求应该具有的几种不同特性。然后,我们将讨论成功的SRS整体应具有的理想特征。 1.有效需求的特…...

基于51单片机无线温度报警控制器 NRF24L01 多路温度报警系统设计
一、系统方案 1、本设计默认采用STC89C52单片机,如需更换单片机请联系客服。 2、接收板LCD1602液晶实时显示当前检测的2点温度值以及对应的上下限报警值。发射板由DS18B20采集温度值,通过无线模块NRF24L01传给接收板。 3、按键可以设置温度上下限值&…...

Spring Data JPA的@Entity注解
一、示例说明 rules\CouponTypeConverter.java Converter public class CouponTypeConverterimplements AttributeConverter<CouponType, String> {Overridepublic String convertToDatabaseColumn(CouponType couponCategory) {return couponCategory.getCode();}Overr…...
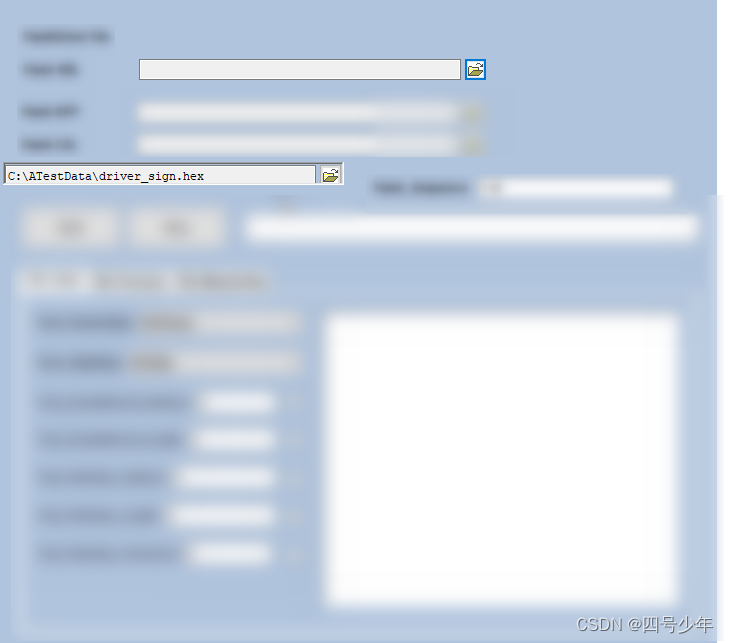
CANoe panel中,Path Dialog如何保存选择的文件路径
这里写目录标题 Path Dialog控件的设置系统变量和环境变量 Path Dialog控件的设置 过滤加载的文件类型 填写格式为:Hex file |.hex 其中Hex file为自定义name,.hex为你想识别的文件类型 系统变量和环境变量 系统变量:在canoe的Environmen…...

关于es中索引,倒排索引的理解
下面是我查询进行理解的东西 也就是说我们ES中的索引就相当于我们mysql中的数据库表,索引库就相当于我们的数据库,我们按照mapping规则会根据相应的字段(index为true默认)来创建倒排索引,这个倒排索引就相当于我们索引…...
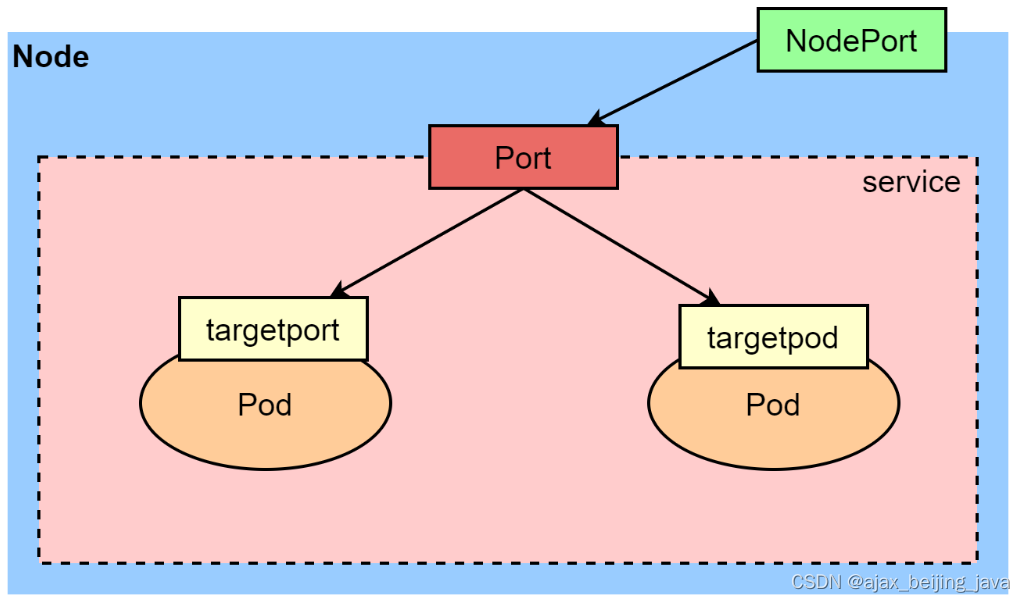
k8s service (二)
K8s service (二) Endpoint Endpoint是kubernetes中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod访问地址,它是根据service匹配文件中selector描述产生的。 一个Service由一组Pod组成,这些Pod通过Endpoints…...
桌面软件开发框架 Electron、Qt、WPF 和 WinForms 怎么选?
一、Electron Electron 是一个基于 Web 技术的跨平台桌面应用程序开发框架。它使用 HTML、CSS 和 JavaScript 来构建应用程序界面,并借助 Chromium 渲染引擎提供强大的页面渲染能力。Electron 的主要特点包括: 跨平台:Electron 可以在 Windows、macOS 和 Linux 等多个主流操…...

SSM框架的学习与应用(Spring + Spring MVC + MyBatis)-Java EE企业级应用开发学习记录(第二天)Mybatis的深入学习
SSM框架的学习与应用(Spring Spring MVC MyBatis)-Java EE企业级应用开发学习记录(第二天)Mybatis的深入学习(增删改查的操作) 上一篇我们的项目搭建好了,也写了简答的Junit测试类进行测试,可以正确映射…...

学习笔记:Opencv实现限制对比度得自适应直方图均衡CLAHE
2023.8.19 为了完成深度学习的进阶,得学习学习传统算法拓展知识面,记录自己的学习心得 CLAHE百科: 一种限制对比度自适应直方图均衡化方法,采用了限制直方图分布的方法和加速的插值方法 clahe(限制对比度自适应直方图…...
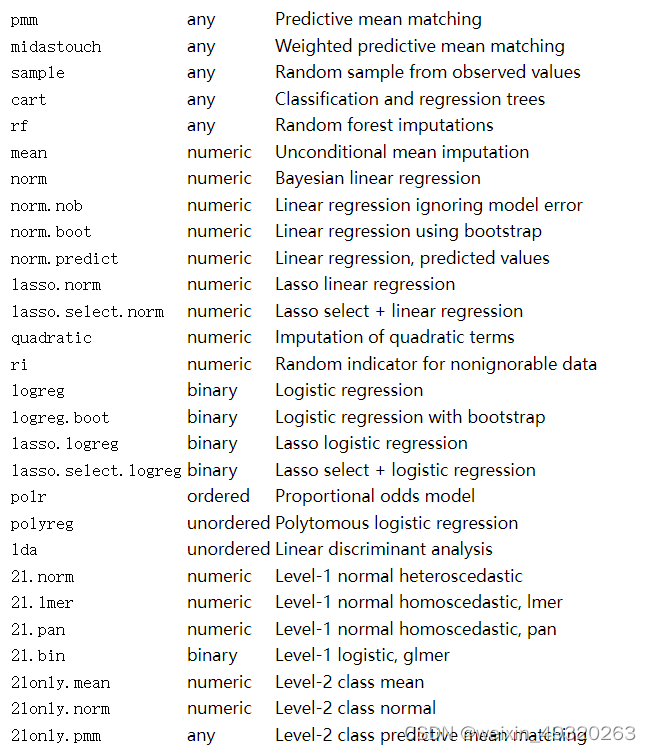
R语言处理缺失数据(1)-mice
#清空 rm(listls()) gc()###生成模拟数据### #生成100个随机数 library(magrittr) set.seed(1) asd<-rnorm(100, mean 60, sd 10) %>% round #平均60,标准差10 #将10个数随机替换为NA NA_positions <- sample(1:100, 10) asd[NA_positions] <- NA #转…...

SpringBoot自动配置原理
Spring Boot 的自动配置可以根据添加的jar依赖,自动配置 Spring Boot 应用程序。例如,我们想要使用Redis,直接在POM文件中增加spring-boot-starter-data-redis依赖,然后我们配置下连接信息就可以使用了。 那么Spring Boot 是如何…...
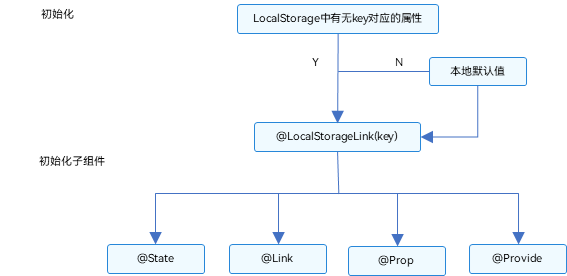
HarmonyOS学习路之方舟开发框架—学习ArkTS语言(状态管理 五)
管理应用拥有的状态概述 LocalStorage:页面级UI状态存储 LocalStorage是页面级的UI状态存储,通过Entry装饰器接收的参数可以在页面内共享同一个LocalStorage实例。LocalStorage也可以在UIAbility内,页面间共享状态。 本文仅介绍LocalStora…...

Java基础篇——反射枚举
反射&枚举 课程目标 1. 【理解】类加载器 2. 【理解】什么是反射 3. 【掌握】获取Class对象的三种方式 4. 【掌握】反射获取构造方法并创建对象 5. 【掌握】反射获取成员变量并使用 6. 【掌握】反射获取成员方法并使用 7. 【掌握】反射综合案例 8. 【理解】枚举B友:http…...

每日一学——案例难点Windows配置
在Windows上配置DNS服务器有几个步骤: 步骤1:打开网络连接设置 在任务栏上右键单击网络图标,并选择“打开网络和Internet设置”。 在新窗口中,选择“更改适配器选项”。 在打开的窗口中,找到正在使用的网络适配器&a…...

2023.8 - java - 运算符
Java 运算符 算术运算符关系运算符位运算符逻辑运算符赋值运算符其他运算符 算术运算符 算术运算符用在数学表达式中,它们的作用和在数学中的作用一样。下表列出了所有的算术运算符。 表格中的实例假设整数变量A的值为10,变量B的值为20: …...

推荐三款Scrum敏捷项目管理工具/敏捷管理实践
免费版敏捷工具推荐: Leangoo领歌 Leangoo领歌是ScrumCN(scrum.cn)旗下的一款永久免费的专业敏捷开发管理工具,提供端到端敏捷研发管理解决方案,涵盖敏捷需求管理、任务协同、进展跟踪、缺陷管理、统计度量等。包括小…...

WARNING: undefined behavior - version of Delve is too old for Go version
在更新了 go 版本后,使用 goland 进行调试会报错 WARNING: undefined behavior - version of Delve is too old for Go version 1.20.5 (maximum supported version 1.19)这是因为 go 的版本升级后,相对 dlv 的版本就低了。 所以解决办法就是升级对应的…...
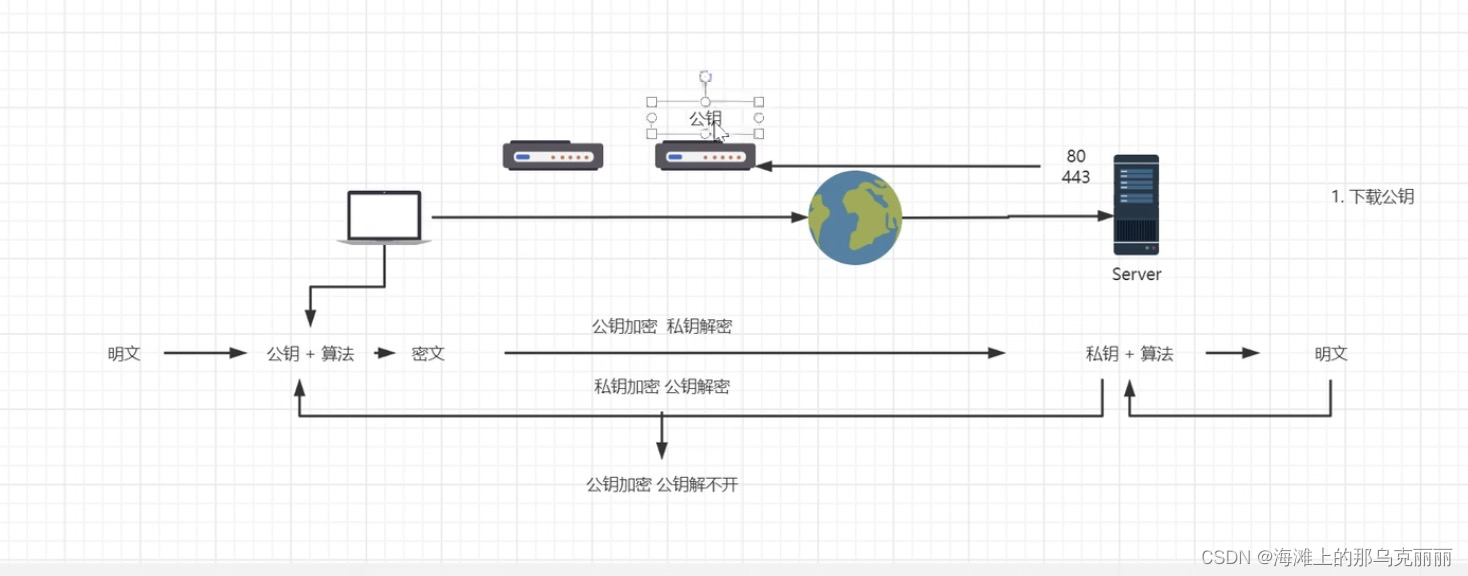
https非对称加密算法
非对称加密算法原理 在客户端公开公钥,服务端保存私钥 1.客户端第一次请求先请求443端口,从443端口下载公钥。 2.客户端将数据进行公钥算法进行加密,将秘文发送到服务端 服务端收到秘文后,通过私钥算法进行解密得到明文数据。…...

“深入探索JVM:Java虚拟机背后的奥秘“
标题:深入探索JVM:Java虚拟机背后的奥秘 摘要:本文将深入探索Java虚拟机(JVM)的内部工作原理和关键组成部分,揭示JVM背后的奥秘。通过对类加载机制、内存管理、垃圾回收、即时编译等方面的详细介绍&#x…...

如何5分钟解锁中兴光猫隐藏权限:zteOnu工厂模式终极指南
如何5分钟解锁中兴光猫隐藏权限:zteOnu工厂模式终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾因中兴光猫的管理限制而困扰?是否想深入了解设…...

揭秘书匠策AI:论文降重与降AIGC的“独门秘籍”
在学术的浩瀚海洋中,每一篇论文都是探索者留下的独特足迹。然而,随着信息爆炸时代的到来,论文的原创性与独特性面临着前所未有的挑战。重复率高、AIGC(人工智能生成内容)痕迹过重,成为了许多学者和学生的心…...
)
Swoole WebSocket + LLM流式响应架构升级(2026企业级避坑手册)
更多请点击: https://intelliparadigm.com 第一章:Swoole WebSocket LLM流式响应架构升级(2026企业级避坑手册) 在高并发实时交互场景中,传统 HTTP 轮询或长连接难以支撑 LLM 流式输出的低延迟、高吞吐需求。Swoole …...

OpenCV视频处理:从基础读取到高级优化技巧
1. 视频处理基础与OpenCV简介计算机视觉领域处理视频流就像人类观看电影一样,需要逐帧解析动态画面。OpenCV作为跨平台的计算机视觉库,其视频处理能力相当于给开发者配备了一套专业的数字摄影机控制台。与传统图像处理不同,视频处理引入了时间…...

告别混乱!用Hbuilder这几个跳转技巧,轻松管理大型Vue/Uni-app项目
大型Vue/Uni-app项目导航革命:Hbuilder高阶跳转技巧实战手册 在代码量超过10万行的Vue/Uni-app项目中,开发者平均每天要执行超过200次文件跳转操作。传统的手动文件搜索不仅耗时(每次平均浪费1.5分钟),还会打断编程思维…...

React Sortable Tree动画效果实现:平滑过渡和视觉反馈终极指南
React Sortable Tree动画效果实现:平滑过渡和视觉反馈终极指南 【免费下载链接】react-sortable-tree Drag-and-drop sortable component for nested data and hierarchies 项目地址: https://gitcode.com/gh_mirrors/re/react-sortable-tree React Sortable…...

MCP 2026资源调度智能分配:3个被厂商隐瞒的关键参数、2个未公开的API限流阈值,及1套可立即上线的灰度验证Checklist
更多请点击: https://intelliparadigm.com 第一章:MCP 2026资源调度智能分配:技术演进与现实困境 MCP(Multi-Cluster Planner)2026 是面向超大规模异构云边端协同场景的新一代资源调度框架,其核心目标是在…...

MPC-BE:你的Windows电脑需要一个什么样的播放器?5个场景告诉你答案
MPC-BE:你的Windows电脑需要一个什么样的播放器?5个场景告诉你答案 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы …...
)
不止于CRC:深入聊聊微信小程序里处理文本编码的那些事儿(TextEncoder平替方案盘点)
微信小程序文本编码处理实战:从标准缺失到工程化解决方案 微信小程序的JavaScript运行环境与标准浏览器环境存在诸多差异,其中对Web标准API的支持不完整是最令开发者头疼的问题之一。当我们需要在小程序中处理复杂的文本编码转换时,突然发现T…...

Maya glTF插件终极指南:5分钟掌握3D模型跨平台导出
Maya glTF插件终极指南:5分钟掌握3D模型跨平台导出 【免费下载链接】maya-glTF glTF 2.0 exporter for Autodesk Maya 项目地址: https://gitcode.com/gh_mirrors/ma/maya-glTF 还在为Maya模型在WebGL、游戏引擎和移动应用中的兼容性问题烦恼吗?m…...