[线程/C++]线程同(异)步和原子变量
文章目录
- 1.线程的使用
- 1.1 函数构造
- 1.2 公共成员函数
- 1.2.1 get_id()
- 1.2.2 join()
- 2.2.3 detach()
- 2.2.5 joinable()
- 2.2.6 operator=
- 1.3 静态函数
- 1.4 call_once
- 2. this_thread 命名空间
- 2.1 get_id()
- 2.2 sleep_for()
- 2.3 sleep_until()
- 2.4 yield()
- 3. 线程同步之互斥锁
- 3.1 std:mutex
- 3.1.1 成员函数
- 3.1.2 线程同步
- 3.2 std::lock_guard
- 3.3 std::recursive_mutex
- 3.4 std::timed_mutex
- 4.线程同步之条件变量
- 4.1 condition_variable
- 4.1.1 成员函数
- 4.1.2 生产者和消费者模型
- 4.2 condition_variable_any
- 4.2.1 成员函数
- 4.2.2 生产者和消费者模型
- 5. 原子变量
- 5.1 atomic 类成员
- 5.1.1 构造函数
- 5.1.2 公共成员函数
- 5.1.3 特化成员函数
- 5.1.4 内存顺序约束
- 5.1.5 C++20新增成员
- 5.2 原子变量的使用
- 5.2.1 互斥锁版本
- 5.2.2 原子变量版本
- 6. 多线程异步操作
- 6.1 std:future
- 6.2 std::promise
- 6.2.1 类成员函数
- 6.2.2 promise的使用
- 6.3. std::packaged_task
- 6.3.1 类成员函数
- 6.3.2 packaged_task的使用
- 6.4 std::async
- 6.4.1 方式1
- 6.4.2 方式2
1.线程的使用
C++11中增加了线程以及线程相关的类,支持了并发编程,提高了编写的多线程程序的可移植性
C++11中提供的线程类叫做std::thread,基于这个类创建一个新的线程非常的简单,只需要提供线程函数或者函数对象即可,并且可以同时指定线程函数的参数。
以下了解以下常用API
1.1 函数构造
// 1
thread() noexcept;
// 2
thread(thread&& other) noexcept;
// 3
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );
// 4
thread( const thread& ) = delete;。
-
构造函数①:默认构造函数,构造一个线程对象,在这个线程中不执行任何处理动作
-
构造函数②:移动构造函数,将 other 的线程所有权转移给新的thread 对象。
之后 other 不再表示执行线程。 -
构造函数③:创建线程对象,并在该线程中执行函数f中的业务逻辑,args是要传递给函数f的参数
-
任务函数f的可选类型有很多,具体如下:
- 普通函数,类成员函数,匿名函数,仿函数(这些都是可调用对象类型)
- 可以是可调用对象包装器类型,也可是使用绑定器绑定之后得到的类型(仿函数)
-
-
构造函数④:使用=delete显示删除拷贝构造, 不允许线程对象之间的拷贝
1.2 公共成员函数
1.2.1 get_id()
应用程序启动之后默认只有一个线程,这个线程一般称之为
主线程或父线程,通过线程类创建出的线程一般称之为子线程,每个被创建出的线程实例都对应一个线程ID,这个ID是唯一的,可以通过这个ID来区分和识别各个已经存在的线程实例,这个获取线程ID的函数叫做get_id()
//原型
std::thread::id get_id() const noexcept;
eg:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;void func(int num, string str)
{for (int i = 0; i < 10; ++i){cout << "子线程: i = " << i << "num: " << num << ", str: " << str << endl;}
}void func1()
{for (int i = 0; i < 10; ++i){cout << "子线程: i = " << i << endl;}
}int main()
{cout << "主线程的线程ID: " << this_thread::get_id() << endl;thread t(func, 520, "i love you");thread t1(func1);cout << "线程t 的线程ID: " << t.get_id() << endl;cout << "线程t1的线程ID: " << t1.get_id() << endl;
}
-
thread t(func, 520, “i love you”);
- 线程类的构造函数③是一个
变参函数,因此无需担心线程任务函数的参数个数问题 - 任务函数func()一般返回值为void,因为子线程在调用这个函数的时候
不会处理其返回值
- 线程类的构造函数③是一个
-
thread t1(func1);
- 子线程对象t1中的任务函数func1(),没有参数,因此在线程构造函数中就无需指定了
-
通过线程对象调用
get_id()就可以知道这个子线程的线程ID:t.get_id(),t1.get_id()
但在上面的示例程序中有bug
有可能子线程中的任务还没有执行完毕,主线程就结束了,最后也得不到我们想要的结果。
当启动了一个线程(创建了一个thread对象)之后,在这个线程结束的时候(std::terminate()),我们如何去回收线程所使用的资源呢?thread库给我们两种选择:
加入式(join())分离式(detach())
我们必须要在线程对象销毁之前在二者之间作出选择,否则程序运行期间会有bug产生。
1.2.2 join()
join()字面意思是连接一个线程,意味着主动地等待线程的终止(线程阻塞)。
在某个线程中通过子线程对象调用join()函数,调用这个函数的线程被阻塞
子线程对象中的任务函数会继续执行,当任务执行完毕之后join()会清理当前子线程中的相关资源然后返回,同时,调用该函数的线程解除阻塞继续向下执行。
//原型
void join();
解决后如下:
int main()
{cout << "主线程的线程ID: " << this_thread::get_id() << endl;thread t(func, 520, "i love you");thread t1(func1);cout << "线程t 的线程ID: " << t.get_id() << endl;cout << "线程t1的线程ID: " << t1.get_id() << endl;t.join();t1.join();
}
为了更好的理解join()的使用,再举一个例子,场景如下:
程序中一共有三个线程,其中两个子线程负责分段处理函数,完毕之后,由主线程对这个文件进行下一步处理
#include <iostream>
#include <thread>
using namespace std;void download1()
{...
}void download2()
{...
}void doSomething()
{...
}int main()
{thread t1(download1);thread t2(download2);// 阻塞主线程,等待所有子线程任务执行完毕再继续向下执行t1.join();t2.join();doSomething();
}
2.2.3 detach()
detach()函数的作用是进行线程分离,分离主线程和创建出的子线程。
在线程分离之后,主线程退出也会一并销毁创建出的所有子线程
在主线程退出之前,它可以脱离主线程继续独立的运行
任务执行完毕之后,这个子线程会自动释放自己占用的系统资源。
//原型
void detach();
线程分离函数没有参数也没有返回值,只需要在线程成功之后,通过线程对象调用该函数即可
int main()
{cout << "主线程的线程ID: " << this_thread::get_id() << endl;thread t(func, 520, "i love you");thread t1(func1);cout << "线程t 的线程ID: " << t.get_id() << endl;cout << "线程t1的线程ID: " << t1.get_id() << endl;t.detach();t1.detach();// 让主线程休眠, 等待子线程执行完毕this_thread::sleep_for(chrono::seconds(5));
}
注意:detach()不会阻塞线程
子线程和主线程分离之后,主线程就不能再对这个子线程做任何控制
比如:通过join()阻塞主线程等待子线程中的任务执行完毕,或调用get_id()获取子线程的线程ID。
2.2.5 joinable()
joinable()函数用于判断主线程和子线程是否处理关联(连接)状态
- 返回值为
true:主线程和子线程之间有关联(连接)关系 - 返回值为
false:主线程和子线程之间没有关联(连接)关系
//原型
bool joinable() const noexcept;
eg:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;void foo()
{this_thread::sleep_for(std::chrono::seconds(1));
}int main()
{thread t;cout << "before starting, joinable: " << t.joinable() << endl;t = thread(foo);cout << "after starting, joinable: " << t.joinable() << endl;t.join();cout << "after joining, joinable: " << t.joinable() << endl;thread t1(foo);cout << "after starting, joinable: " << t1.joinable() << endl;t1.detach();cout << "after detaching, joinable: " << t1.joinable() << endl;
}
before starting, joinable: 0
after starting, joinable: 1
after joining, joinable: 0
after starting, joinable: 1
after detaching, joinable: 0
给予结果我们可以得到如下结论
- 在创建的子线程对象的时候,如果没有指定任务函数,那么子线程不会启动,主线程和这个子线程也不会进行连接
- 在创建的子线程对象的时候,如果指定了任务函数,子线程启动并执行任务,主线程和这个子线程自动连接成功
- 子线程调用了detach()函数之后,父子线程分离,同时二者的连接断开,调用joinable()返回false
- 在子线程调用了join()函数,子线程中的任务函数继续执行,直到任务处理完毕
这时join()会清理(回收)当前子线程的相关资源,所以这个子线程和主线程的连接也就断开了,因此,调用join()之后再调用joinable()会返回false。
2.2.6 operator=
线程中的资源是不能被复制的,因此通过=操作符进行赋值操作最终并不会得到两个完全相同的对象。
// move (1)
thread& operator= (thread&& other) noexcept;
// copy [deleted] (2)
thread& operator= (const other&) = delete;
通过以上=操作符的重载声明可以得知:
- 如果other是一个右值,会进行资源所有权的转移
- 如果other不是右值,禁止拷贝,该函数被显示删除(=delete),不可用
1.3 静态函数
thread线程类还提供了一个静态方法,用于获取当前计算机的CPU核心数
根据这个结果可以在程序中创建出数量相等的线程
每个线程独占一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的。
//函数原型
static unsigned hardware_concurrency() noexcept;
eg:
#include <iostream>
#include <thread>
using namespace std;int main()
{int num = thread::hardware_concurrency();cout << "CPU number: " << num << endl;
}
1.4 call_once
在某些特定情况下,某些函数只能在多线程环境下调用一次,比如:要初始化某个对象,而这个对象只能被初始化一次
可以使用std::call_once()来保证函数在多线程环境下只能被调用一次。使用call_once()的时候,需要一个once_flag作为call_once()的传入参数
//函数原型
// 定义于头文件 <mutex>
template< class Callable, class... Args >
void call_once( std::once_flag& flag, Callable&& f, Args&&... args );
flag:once_flag类型的对象,要保证这个对象能够被多个线程同时访问到f:回调函数,可以传递一个有名函数地址,也可以指定一个匿名函数args:作为实参传递给回调函数
eg:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;once_flag g_flag;
void do_once(int a, string b)
{cout << "name: " << b << ", age: " << a << endl;
}void do_something(int age, string name)
{static int num = 1;call_once(g_flag, do_once, 19, "luffy");cout << "do_something() function num = " << num++ << endl;
}int main()
{thread t1(do_something, 20, "ace");thread t2(do_something, 20, "sabo");thread t3(do_something, 19, "luffy");t1.join();t2.join();t3.join();return 0;
}
name: luffy, age: 19
do_something() function num = 1
do_something() function num = 2
do_something() function num = 3
2. this_thread 命名空间
在C++11中不仅添加了线程类,还添加了一个关于线程的命名空间
std::this_thread
在这个命名空间中提供了四个公共的成员函数
2.1 get_id()
所说曾相识,但还是有所不同
调用命名空间std::this_thread中的get_id()方法可以得到当前线程的线程ID
//原型
thread::id get_id() noexcept;
eg:
#include <iostream>
#include <thread>
using namespace std;void func()
{cout << "子线程: " << this_thread::get_id() << endl;
}int main()
{cout << "主线程: " << this_thread::get_id() << endl;thread t(func);t.join();
}
2.2 sleep_for()
线程被创建后有这五种状态:创建态,就绪态,运行态,阻塞态(挂起态),退出态(终止态)
关于状态之间的转换和进程是一样的
线程和进程的执行有很多相似之处,在计算机中启动的多个线程都需要占用CPU资源
但是CPU的个数是有限的并且每个CPU在同一时间点不能同时处理多个任务。
为了实现并发处理,多个线程都是分时复用CPU时间片,快速的交替处理各个线程中的任务。
因此多个线程之间需要争抢CPU时间片,抢到了就执行,抢不到则无法执行
因为默认所有的线程优先级都相同,内核也会从中调度,不会出现某个线程永远抢不到CPU时间片的情况。
命名空间this_thread中提供了一个休眠函数sleep_for()
调用这个函数的线程会马上从运行态变成阻塞态并在这种状态下休眠一定的时长
因为阻塞态的线程已经让出了CPU资源,代码也不会被执行,所以线程休眠过程中对CPU来说没有任何负担。
//原型
template <class Rep, class Period>
void sleep_for (const chrono::duration<Rep,Period>& rel_time);
参数需要指定一个休眠时长,是一个时间段
eg:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;void func()
{for (int i = 0; i < 10; ++i){this_thread::sleep_for(chrono::seconds(1));cout << "子线程: " << this_thread::get_id() << ", i = " << i << endl;}
}int main()
{thread t(func);t.join();
}
在func()函数的for循环中使用了this_thread::sleep_for(chrono::seconds(1));之后,每循环一次程序都会阻塞1秒钟,也就是说每隔1秒才会进行一次输出。
注意:程序休眠完成之后,会从阻塞态重新变成就绪态,就绪态的线程需要再次争抢CPU时间片,抢到之后才会变成运行态,这时候程序才会继续向下运行。
2.3 sleep_until()
命名空间
this_thread中提供了另一个休眠函数sleep_until(),和sleep_for()不同的是它的参数类型不一样
sleep_until():指定线程阻塞到某一个指定的时间点time_point类型,之后解除阻塞
sleep_for():指定线程阻塞一定的时间长度duration类型,之后解除阻塞
//原型
template <class Clock, class Duration>
void sleep_until (const chrono::time_point<Clock,Duration>& abs_time);
eg:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;void func()
{for (int i = 0; i < 10; ++i){// 获取当前系统时间点auto now = chrono::system_clock::now();// 时间间隔为2schrono::seconds sec(2);// 当前时间点之后休眠两秒this_thread::sleep_until(now + sec);cout << "子线程: " << this_thread::get_id() << ", i = " << i << endl;}
}int main()
{thread t(func);t.join();
}
sleep_until()和sleep_for()函数的功能是一样的
只不过前者是基于时间点去阻塞线程
后者是基于时间段去阻塞线程
2.4 yield()
命名空间
this_thread中提供了一个非常绅士的函数yield()
在线程中调用这个函数后,处于运行态的线程会主动让出自己已经抢到的CPU时间片,最终变为就绪态
这样其它的线程就有更大的概率能够抢到CPU时间片了。
注意:线程调用了yield()之后,这个线程会马上参与到下一轮CPU的抢夺中
//原型
void yield() noexcept;
eg:
#include <iostream>
#include <thread>
using namespace std;void func()
{for (int i = 0; i < 100000000000; ++i){cout << "子线程: " << this_thread::get_id() << ", i = " << i << endl;this_thread::yield();}
}int main()
{thread t(func);thread t1(func);t.join();t1.join();
}
在上面的程序中,执行func()中的for循环会占用大量的时间
极端情况下,如果当前线程占用CPU资源不释放就会导致其他线程中的任务无法被处理,或者该线程每次都能抢到CPU时间片,导致其他线程中的任务没有机会被执行。
解决方案就是每执行一次循环,让该线程主动放弃CPU资源,重新和其他线程再次抢夺CPU时间片,如果其他线程抢到了CPU时间片就可以执行相应的任务了。
结论:std::this_thread::yield() 的目的是避免一个线程长时间占用CPU资源,从而导致多线程处理性能下降
3. 线程同步之互斥锁
进行多线程编程,如果多个线程需要对同一块内存进行操作,比如:同时读、同时写、同时读写对于后两种情况来说,如果不做任何的人为干涉就会出现各种各样的错误数据。
这是因为线程在运行的时候需要先得到CPU时间片,时间片用完之后需要放弃已获得的CPU资源,就这样线程频繁地在就绪态和运行态之间切换,更复杂一点还可以在就绪态、运行态、挂起态之间切换,这样就会导致线程的执行顺序并不是有序的,而是随机的混乱的
解决多线程数据混乱的方案就是进行线程同步,最常用的就是互斥锁,在C++11中一共提供了四种互斥锁:
std::mutex:独占的互斥锁,不能递归使用std::timed_mutex:带超时的独占互斥锁,不能递归使用std::recursive_mutex:递归互斥锁,不带超时功能std::recursive_timed_mutex:带超时的递归互斥锁
互斥锁在有些资料中也被称之为互斥量,二者是一个东西。
3.1 std:mutex
不论是在C还是C++中,进行线程同步的处理流程基本上是一致的,C++的mutex类提供了相关的API函数:
3.1.1 成员函数
lock()函数用于给临界区加锁,并且只能有一个线程获得锁的所有权,它有阻塞线程的作用
//函数原型
void lock();
独占互斥锁对象有两种状态:锁定和未锁定。
如果互斥锁是打开的,调用lock()函数的线程会得到互斥锁的所有权,并将其上锁,其它线程再调用该函数的时候由于得不到互斥锁的所有权,就会被lock()函数阻塞。
当拥有互斥锁所有权的线程将互斥锁解锁,此时被lock()阻塞的线程解除阻塞,抢到互斥锁所有权的线程加锁并继续运行,没抢到互斥锁所有权的线程继续阻塞。
除了使用lock()还可以使用try_lock()获取互斥锁的所有权并对互斥锁加锁
//函数原型
bool try_lock();
二者的区别在于try_lock()不会阻塞线程,lock()会阻塞线程:
- 如果互斥锁是未锁定状态,得到了互斥锁所有权并加锁成功,函数返回true
- 如果互斥锁是锁定状态,无法得到互斥锁所有权加锁失败,函数返回false
当互斥锁被锁定之后可以通过unlock()进行解锁,但是需要注意的是只有拥有互斥锁所有权的线程也就是对互斥锁上锁的线程才能将其解锁,其它线程是没有权限做这件事情的。
//函数原型
void unlock();
使用互斥锁进行线程同步的大致思路主要分为以下几步:
- 找到多个线程操作的共享资源(全局变量、堆内存、类成员变量等),也可以称之为临界资源
- 找到和共享资源有关的上下文代码,也就是临界区(下图中的黄色代码部分)
- 在临界区的上边调用互斥锁类的
lock()方法 - 在临界区的下边调用互斥锁的
unlock()方法
线程同步的目的是让多线程按照顺序依次执行临界区代码,这样做线程对共享资源的访问就从并行访问变为了线性访问,访问效率降低,但是保证了数据的正确性。
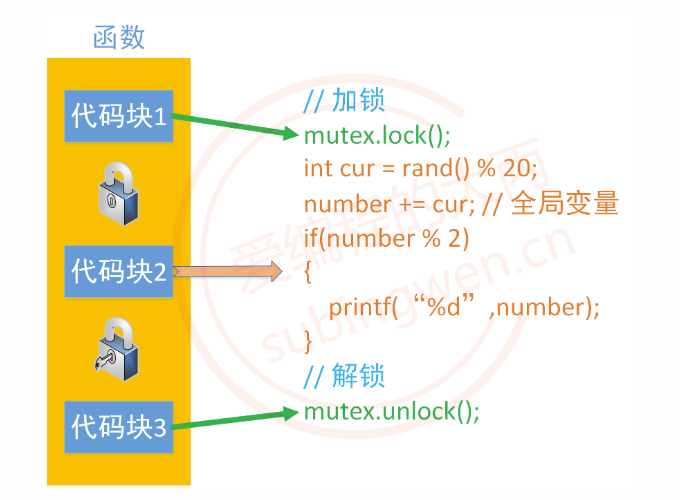
3.1.2 线程同步
让两个线程共同操作一个全局变量,二者交替数数
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>
using namespace std;int g_num = 0; // 为 g_num_mutex 所保护
mutex g_num_mutex;void slow_increment(int id)
{for (int i = 0; i < 3; ++i) {g_num_mutex.lock();++g_num;cout << id << " => " << g_num << endl;g_num_mutex.unlock();this_thread::sleep_for(chrono::seconds(1));}
}int main()
{thread t1(slow_increment, 0);thread t2(slow_increment, 1);t1.join();t2.join();
}
在上面的示例程序中,两个子线程执行的任务的一样的(可以不一样,不同的任务中也可以对共享资源进行读写操作),在任务函数中把与全局变量相关的代码加了锁,两个线程只能顺序访问这部分代码(如果不进行线程同步打印出的数据是混乱且无序的)。
注意:
- 在所有线程的任务函数执行完毕之前,互斥锁对象是不能被析构的,一定要在程序中保证这个对象的可用性。
- 互斥锁的个数和共享资源的个数相等,也就是说每一个共享资源都应该对应一个互斥锁对象。互斥锁对象的个数和线程的个数没有关系。
3.2 std::lock_guard
lock_guard是C++11新增的一个模板类,使用这个类,可以
简化互斥锁lock()和unlock()的写法,同时也更安全。
// 定义和常用的构造函数原型
// 类的定义,定义于头文件 <mutex>
template< class Mutex >
class lock_guard;// 常用构造函数
explicit lock_guard( mutex_type& m );
lock_guard在使用上面的构造函数构造对象时,会自动锁定互斥量
而在退出作用域后进行析构时就会自动解锁,从而保证了互斥量的正确操作,避免忘记unlock()操作而导致线程死锁。
lock_guard使用了RAII技术,就是在类构造函数中分配资源,在析构函数中释放资源,保证资源出了作用域就释放。
使用lock_guard对上面的例子进行修改:
void slow_increment(int id)
{for (int i = 0; i < 3; ++i) {// 使用哨兵锁管理互斥锁lock_guard<mutex> lock(g_num_mutex);++g_num;cout << id << " => " << g_num << endl;this_thread::sleep_for(chrono::seconds(1));}
}
通过修改发现代码被精简了,而且不用担心因为忘记解锁而造成程序的死锁
弊端:在上面的示例程序中整个for循环的体都被当做了临界区,多个线程是线性的执行临界区代码的,因此临界区越大程序效率越低
3.3 std::recursive_mutex
递归互斥锁
std::recursive_mutex允许同一线程多次获得互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题
使用独占非递归互斥量会发生死锁:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;struct Calculate
{Calculate() : m_i(6) {}void mul(int x){lock_guard<mutex> locker(m_mutex);m_i *= x;}void div(int x){lock_guard<mutex> locker(m_mutex);m_i /= x;}void both(int x, int y){lock_guard<mutex> locker(m_mutex);mul(x);div(y);}int m_i;mutex m_mutex;
};int main()
{Calculate cal;cal.both(6, 3);return 0;
}
上面的程序中执行了cal.both(6, 3);调用之后,程序就会发生死锁
在both()中已经对互斥锁加锁了,继续调用mult()函数,已经得到互斥锁所有权的线程再次获取这个互斥锁的所有权就会造成死锁(在C++中程序会异常退出,使用C库函数会导致这个互斥锁永远无法被解锁,最终阻塞所有的线程)。
要解决这个死锁的问题,一个简单的办法就是使用递归互斥锁std::recursive_mutex,它允许一个线程多次获得互斥锁的所有权。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;struct Calculate
{Calculate() : m_i(6) {}void mul(int x){lock_guard<recursive_mutex> locker(m_mutex);m_i *= x;}void div(int x){lock_guard<recursive_mutex> locker(m_mutex);m_i /= x;}void both(int x, int y){lock_guard<recursive_mutex> locker(m_mutex);mul(x);div(y);}int m_i;recursive_mutex m_mutex;
};int main()
{Calculate cal;cal.both(6, 3);cout << "cal.m_i = " << cal.m_i << endl;return 0;
}
虽然递归互斥锁可以解决同一个互斥锁频繁获取互斥锁资源的问题,但是还是建议少用
- 使用递归互斥锁的场景往往都是可以简化的,使用递归互斥锁很容易放纵复杂逻辑的产生,从而导致bug的产生
- 递归互斥锁比非递归互斥锁效率要低一些。
- 递归互斥锁虽然允许同一个线程多次获得同一个互斥锁的所有权,但最大次数并未具体说明,一旦超过一定的次数,就会抛出std::system错误。
3.4 std::timed_mutex
std::timed_mutex是超时独占互斥锁,主要是在获取互斥锁资源时增加了超时等待功能,因为不知道获取锁资源需要等待多长时间,为了保证不一直等待下去,设置了一个超时时长,超时后线程就可以解除阻塞去做其他事情了。
std::timed_mutex比std::_mutex多了两个成员函数:try_lock_for() try_lock_until()
void lock();
bool try_lock();
void unlock();// std::timed_mutex比std::_mutex多出的两个成员函数
template <class Rep, class Period>bool try_lock_for (const chrono::duration<Rep,Period>& rel_time);template <class Clock, class Duration>bool try_lock_until (const chrono::time_point<Clock,Duration>& abs_time);
try_lock_for函数是当线程获取不到互斥锁资源时,让线程阻塞一定的时间长度try_lock_until函数是当线程获取不到互斥锁资源时,让线程阻塞到某一个指定的时间点- 关于两个函数的返回值
当得到互斥锁的所有权之后,函数会马上解除阻塞,返回true
如果阻塞的时长用完或者到达指定的时间点之后,函数也会解除阻塞,返回false
演示std::timed_mutex的使用:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;timed_mutex g_mutex;void work()
{chrono::seconds timeout(1);while (1){// 通过阻塞一定的时长来争取得到互斥锁所有权if (g_mutex.try_lock_for(timeout)){cout << "当前线程ID: " << this_thread::get_id() << ", 得到互斥锁所有权..." << endl;// 模拟处理任务用了一定的时长this_thread::sleep_for(chrono::seconds(10));// 互斥锁解锁g_mutex.unlock();break;}else{cout << "当前线程ID: " << this_thread::get_id() << ", 没有得到互斥锁所有权..." << endl;// 模拟处理其他任务用了一定的时长this_thread::sleep_for(chrono::milliseconds(50));}}
}int main()
{thread t1(work);thread t2(work);t1.join();t2.join();return 0;
}
示例代码输出的结果:
当前线程ID: 125776, 得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 没有得到互斥锁所有权...
当前线程ID: 112324, 得到互斥锁所有权...
在上面的例子中,通过一个while循环不停的去获取超时互斥锁的所有权,如果得不到就阻塞1秒钟,1秒之后如果还是得不到阻塞50毫秒,然后再次继续尝试,直到获得互斥锁的所有权,跳出循环体。
递归超时互斥锁std::recursive_timed_mutex的使用方式和std::timed_mutex是一样的
只不过它可以允许一个线程多次获得互斥锁所有权
而std::timed_mutex只允许线程获取一次互斥锁所有权。
递归超时互斥锁std::recursive_timed_mutex也拥有和`std::recursive_mutex``一样的弊端
4.线程同步之条件变量
条件变量是C++11提供的另外一种用于等待的同步机制,它能阻塞一个或多个线程,直到收到另外一个线程发出的通知或者超时时,才会唤醒当前阻塞的线程。
条件变量需要和互斥量配合起来使用
C++11提供了两种条件变量:
condition_variable:需要配合std::unique_lock<std::mutex>进行wait操作,也就是阻塞线程的操作。condition_variable_any:可以和任意带有lock()、unlock()语义的mutex搭配使用,也就是说有四种:std::mutex:独占的非递归互斥锁std::timed_mutex:带超时的独占非递归互斥锁std::recursive_mutex:不带超时功能的递归互斥锁std::recursive_timed_mutex:带超时的递归互斥锁
条件变量通常用于生产者和消费者模型,大致使用过程如下:
- 拥有条件变量的线程获取互斥量
- 循环检查某个条件,如果条件不满足阻塞当前线程,否则线程继续向下执行
- 产品的数量达到上限,生产者阻塞,否则生产者一直生产
- 产品的数量为零,消费者阻塞,否则消费者一直消费
- 条件满足之后,可以调用
notify_one()或notify_all()唤醒一个或所有被阻塞的线程- 由消费者唤醒被阻塞的生产者,生产者解除阻塞继续生产
- 由生产者唤醒被阻塞的消费者,消费者解除阻塞继续消费
4.1 condition_variable
4.1.1 成员函数
condition_variable的成员函数主要分为两部分:线程等待(阻塞)函数和线程通知(唤醒)函数
这些函数被定义于头文件<condition_variable>
- 等待函数
调用wait()函数的线程会被阻塞
// 1
void wait (unique_lock<mutex>& lck);
// 2
template <class Predicate>
void wait (unique_lock<mutex>& lck, Predicate pred);
-
函数①:调用该函数的线程直接被阻塞
-
函数②:该函数的第二个参数是一个判断条件,是一个返回值为布尔类型的函数
- 该参数可以传递一个有名函数的地址,也可以直接指定一个匿名函数
- 表达式返回
false当前线程被阻塞 - 表达式返回
true当前线程不会被阻塞,继续向下执行
-
独占的互斥锁对象不能直接传递给
wait()函数,需要通过模板类unique_lock进行二次处理,通过得到的对象仍然可以对独占的互斥锁对象做如下操作,使用起来更灵活。
| 公共成员函数 | 说明 |
|---|---|
| lock | 锁定关联的互斥锁 |
| try_lock | 尝试锁定关联的互斥锁,若无法锁定,函数直接返回 |
| try_lock_for | 试图锁定关联的可定时锁定互斥锁,若互斥锁在给定时长中仍不能被锁定,函数返回 |
| try_lock_until | 试图锁定关联的可定时锁定互斥锁,若互斥锁在给定的时间点后仍不能被锁定,函数返回 |
| unlock | 将互斥锁解锁 |
- 如果线程被该函数阻塞,这个线程会释放占有的互斥锁的所有权
当阻塞解除之后这个线程会重新得到互斥锁的所有权,继续向下执行(这个过程是在函数内部完成的,其目的是为了避免线程的死锁)。
wait_for()函数和wait()的功能是一样的,只不过多了一个阻塞时长
假设阻塞的线程没有被其他线程唤醒,当阻塞时长用完之后,线程就会自动解除阻塞,继续向下执行。
template <class Rep, class Period>
cv_status wait_for (unique_lock<mutex>& lck,const chrono::duration<Rep,Period>& rel_time);template <class Rep, class Period, class Predicate>
bool wait_for(unique_lock<mutex>& lck,const chrono::duration<Rep,Period>& rel_time, Predicate pred);
wait_until()函数和wait_for()的功能是一样的,它是指定让线程阻塞到某一个时间点,假设阻塞的线程没有被其他线程唤醒,当到达指定的时间点之后,线程就会自动解除阻塞,继续向下执行。
template <class Clock, class Duration>
cv_status wait_until (unique_lock<mutex>& lck,const chrono::time_point<Clock,Duration>& abs_time);template <class Clock, class Duration, class Predicate>
bool wait_until (unique_lock<mutex>& lck,const chrono::time_point<Clock,Duration>& abs_time, Predicate pred);
- 通知函数
void notify_one() noexcept;
void notify_all() noexcept;
notify_one():唤醒一个被当前条件变量阻塞的线程
notify_all():唤醒全部被当前条件变量阻塞的线程
4.1.2 生产者和消费者模型
我们可以使用条件变量来实现一个同步队列,这个队列作为生产者线程和消费者线程的共享资源
#include <iostream>
#include <thread>
#include <mutex>
#include <list>
#include <functional>
#include <condition_variable>
using namespace std;class SyncQueue
{
public:SyncQueue(int maxSize) : m_maxSize(maxSize) {}void put(const int& x){unique_lock<mutex> locker(m_mutex);// 判断任务队列是不是已经满了while (m_queue.size() == m_maxSize){cout << "任务队列已满, 请耐心等待..." << endl;// 阻塞线程m_notFull.wait(locker);}// 将任务放入到任务队列中m_queue.push_back(x);cout << x << " 被生产" << endl; // 通知消费者去消费m_notEmpty.notify_one();}int take(){unique_lock<mutex> locker(m_mutex);while (m_queue.empty()){cout << "任务队列已空,请耐心等待。。。" << endl;m_notEmpty.wait(locker);}// 从任务队列中取出任务(消费)int x = m_queue.front();m_queue.pop_front();// 通知生产者去生产m_notFull.notify_one();cout << x << " 被消费" << endl;return x;}bool empty(){lock_guard<mutex> locker(m_mutex);return m_queue.empty();}bool full(){lock_guard<mutex> locker(m_mutex);return m_queue.size() == m_maxSize;}int size(){lock_guard<mutex> locker(m_mutex);return m_queue.size();}private:list<int> m_queue; // 存储队列数据mutex m_mutex; // 互斥锁condition_variable m_notEmpty; // 不为空的条件变量condition_variable m_notFull; // 没有满的条件变量int m_maxSize; // 任务队列的最大任务个数
};int main()
{SyncQueue taskQ(50);auto produce = bind(&SyncQueue::put, &taskQ, placeholders::_1);auto consume = bind(&SyncQueue::take, &taskQ);thread t1[3];thread t2[3];for (int i = 0; i < 3; ++i){t1[i] = thread(produce, i+100);t2[i] = thread(consume);}for (int i = 0; i < 3; ++i){t1[i].join();t2[i].join();}return 0;
}
条件变量condition_variable类的wait()还有一个重载的方法
可以接受一个条件,这个条件也可以是一个返回值为布尔类型的函数,条件变量会先检查判断这个条件是否满足
如满足条(布尔值为true),则当前线程重新获得互斥锁的所有权,结束阻塞,继续向下执行;
如不满足(布尔值为false),当前线程会释放互斥锁(解锁)同时被阻塞,等待被唤醒。
上面示例程序中的put()、take()函数可以做如下修改:
- put()函数
void put(const int& x)
{unique_lock<mutex> locker(m_mutex);// 根据条件阻塞线程m_notFull.wait(locker, [this]() {return m_queue.size() != m_maxSize;});// 将任务放入到任务队列中m_queue.push_back(x);cout << x << " 被生产" << endl;// 通知消费者去消费m_notEmpty.notify_one();
}
- take()函数
int take()
{unique_lock<mutex> locker(m_mutex);m_notEmpty.wait(locker, [this]() {return !m_queue.empty();});// 从任务队列中取出任务(消费)int x = m_queue.front();m_queue.pop_front();// 通知生产者去生产m_notFull.notify_one();cout << x << " 被消费" << endl;return x;
}
修改之后可以发现,程序变得更加精简了,而且执行效率更高了,因为在这两个函数中的while循环被删掉了,但是最终的效果是一样的,推荐使用这种方式的wait()进行线程的阻塞。
4.2 condition_variable_any
4.2.1 成员函数
condition_variable_any的成员函数也是分为两部分:线程等待(阻塞)函数 和线程通知(唤醒)函数,这些函数被定义于头文件
<condition_variable>
- 等待函数
// 1
template <class Lock> void wait (Lock& lck);
// 2
template <class Lock, class Predicate>
void wait (Lock& lck, Predicate pred);
- 函数①:调用该函数的线程直接被阻塞
- 函数②:该函数的第二个参数是一个判断条件,是一个返回值为布尔类型的函数
- 该参数可以传递一个有名函数的地址,也可以直接指定一个匿名函数
- 表达式返回false当前线程被阻塞,表达式返回true当前线程不会被阻塞,继续向下执行
- 可以直接传递给wait()函数的互斥锁类型有四种,分别是:
std::mutex、std::timed_mutex、std::recursive_mutex、std::recursive_timed_mutex - 如果线程被该函数阻塞,这个线程会释放占有的互斥锁的所有权,当阻塞解除之后这个线程会重新得到互斥锁的所有权,继续向下执行(这个过程是在函数内部完成的,了解这个过程即可,其目的是为了避免线程的死锁)。
wait_for()函数和wait()的功能是一样的,只不过多了一个阻塞时长,假设阻塞的线程没有被其他线程唤醒,当阻塞时长用完之后,线程就会自动解除阻塞,继续向下执行。
template <class Lock, class Rep, class Period>
cv_status wait_for (Lock& lck, const chrono::duration<Rep,Period>& rel_time);template <class Lock, class Rep, class Period, class Predicate>
bool wait_for (Lock& lck, const chrono::duration<Rep,Period>& rel_time, Predicate pred);
wait_until()函数和wait_for()的功能是一样的,它是指定让线程阻塞到某一个时间点,假设阻塞的线程没有被其他线程唤醒,当到达指定的时间点之后,线程就会自动解除阻塞,继续向下执行。
template <class Lock, class Clock, class Duration>
cv_status wait_until (Lock& lck, const chrono::time_point<Clock,Duration>& abs_time);template <class Lock, class Clock, class Duration, class Predicate>
bool wait_until (Lock& lck, const chrono::time_point<Clock,Duration>& abs_time, Predicate pred);
- 通知函数
void notify_one() noexcept;
void notify_all() noexcept;
notify_one():唤醒一个被当前条件变量阻塞的线程
notify_all():唤醒全部被当前条件变量阻塞的线程
4.2.2 生产者和消费者模型
使用条件变量condition_variable_any同样可以实现上面的生产者和消费者的例子
代码只有个别细节上有所不同:
#include <iostream>
#include <thread>
#include <mutex>
#include <list>
#include <functional>
#include <condition_variable>
using namespace std;class SyncQueue
{
public:SyncQueue(int maxSize) : m_maxSize(maxSize) {}void put(const int& x){lock_guard<mutex> locker(m_mutex);// 根据条件阻塞线程m_notFull.wait(m_mutex, [this]() {return m_queue.size() != m_maxSize;});// 将任务放入到任务队列中m_queue.push_back(x);cout << x << " 被生产" << endl;// 通知消费者去消费m_notEmpty.notify_one();}int take(){lock_guard<mutex> locker(m_mutex);m_notEmpty.wait(m_mutex, [this]() {return !m_queue.empty();});// 从任务队列中取出任务(消费)int x = m_queue.front();m_queue.pop_front();// 通知生产者去生产m_notFull.notify_one();cout << x << " 被消费" << endl;return x;}bool empty(){lock_guard<mutex> locker(m_mutex);return m_queue.empty();}bool full(){lock_guard<mutex> locker(m_mutex);return m_queue.size() == m_maxSize;}int size(){lock_guard<mutex> locker(m_mutex);return m_queue.size();}private:list<int> m_queue; // 存储队列数据mutex m_mutex; // 互斥锁condition_variable_any m_notEmpty; // 不为空的条件变量condition_variable_any m_notFull; // 没有满的条件变量int m_maxSize; // 任务队列的最大任务个数
};int main()
{SyncQueue taskQ(50);auto produce = bind(&SyncQueue::put, &taskQ, placeholders::_1);auto consume = bind(&SyncQueue::take, &taskQ);thread t1[3];thread t2[3];for (int i = 0; i < 3; ++i){t1[i] = thread(produce, i + 100);t2[i] = thread(consume);}for (int i = 0; i < 3; ++i){t1[i].join();t2[i].join();}return 0;
}
总结:以上介绍的两种条件变量各自有各自的特点
condition_variable 配合 unique_lock 使用更灵活,可以在在任何时候自由地释放互斥锁
condition_variable_any 如果和lock_guard 一起使用必须要等到其生命周期结束才能将互斥锁释放。
condition_variable_any 可以和多种互斥锁配合使用,应用场景也更广
condition_variable 只能和独占的非递归互斥锁(mutex)配合使用,有一定的局限性。
5. 原子变量
C++11提供了一个原子类型std::atomic<T>,通过这个原子类型管理的内部变量就可以称之为原子变量,我们可以给原子类型指定bool、char、int、long、指针等类型作为模板参数(不支持浮点类型和复合类型)。
原子指的是一系列不可被CPU上下文交换的机器指令,这些指令组合在一起就形成了原子操作。在多核CPU下,当某个CPU核心开始运行原子操作时,会先暂停其它CPU内核对内存的操作,以保证原子操作不会被其它CPU内核所干扰。
由于原子操作是通过指令提供的支持,因此它的性能相比锁和消息传递会好很多。
相比较于锁而言,原子类型不需要开发者处理加锁和释放锁的问题,同时支持修改,读取等操作,还具备较高的并发性能,几乎所有的语言都支持原子类型。
可以看出原子类型是无锁类型,但是无锁不代表无需等待,因为原子类型内部使用了CAS循环,当大量的冲突发生时,该等待还是得等待,但是总归比锁要好。
C++11内置了整形的原子变量,这样就可以更方便的使用原子变量了。在多线程操作中,使用原子变量之后就不需要再使用互斥量来保护该变量了,用起来更简洁。
因为对原子变量进行的操作只能是一个原子操作(atomic operation),原子操作指的是不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何上下文切换。
多线程同时访问共享资源造成数据混乱的原因就是因为CPU的上下文切换导致的,使用原子变量解决了这个问题,因此互斥锁的使用也就不再需要了。
CAS全称是Compare and swap
它通过一条指令读取指定的内存地址,然后判断其中的值是否等于给定的前置值
如果相等,则将其修改为新的值
5.1 atomic 类成员
类定义
// 定义于头文件 <atomic>
template< class T >
struct atomic;
通过定义可得知:在使用这个模板类的时候,一定要指定模板类型。
5.1.1 构造函数
// 1
atomic() noexcept = default;
// 2
constexpr atomic(T desired) noexcept;
// 3
atomic(const atomic&) = delete;
- 构造函数①:默认无参构造函数。
- 构造函数②:使用 desired 初始化原子变量的值。
- 构造函数③:使用=delete显示删除拷贝构造函数,
不允许进行对象之间的拷贝
5.1.2 公共成员函数
原子类型在类内部重载了=操作符,并且不允许在类的外部使用 = 进行对象的拷贝。
T operator=( T desired ) noexcept;
T operator=( T desired ) volatile noexcept;atomic& operator=( const atomic& ) = delete;
atomic& operator=( const atomic& ) volatile = delete;
以
desired替换当前值。按照order的值影响内存。
void store( T desired, std::memory_order order = std::memory_order_seq_cst ) noexcept;
void store( T desired, std::memory_order order = std::memory_order_seq_cst ) volatile noexcept;
- desired:存储到原子变量中的值
- order:强制的内存顺序
原子地加载并返回原子变量的当前值。按照 order 的值影响内存。直接访问原子对象也可以得到原子变量的当前值。
T load(std::memory_order order = std::memory_order_seq_cst) const noexcept;
T load(std::memory_order order = std::memory_order_seq_cst) const volatile noexcept;
5.1.3 特化成员函数
- 复合赋值运算符重载,主要包含以下形式:
当模板类型T为整数:
| 操作符重载 | 描述 |
|---|---|
| T operator+= (T val) volatile noexcept; | 原子地执行加法并赋值,返回新的值 (volatile版本) |
| T operator+= (T val) noexcept; | 原子地执行加法并赋值,返回新的值 |
| T operator-= (T val) volatile noexcept; | 原子地执行减法并赋值,返回新的值 (volatile版本) |
| T operator-= (T val) noexcept; | 原子地执行减法并赋值,返回新的值 |
| T operator&= (T val) volatile noexcept; | 原子地执行按位与操作并赋值,返回新的值 (volatile版本) |
| T operator&= (T val) noexcept; | 原子地执行按位与操作并赋值,返回新的值 |
| T operator | = (T val) volatile noexcept; |
| T operator | = (T val) noexcept; |
| T operator^= (T val) volatile noexcept; | 原子地执行按位异或操作并赋值,返回新的值 (volatile版本) |
| T operator^= (T val) noexcept; | 原子地执行按位异或操作并赋值,返回新的值 |
当模板类型T为指针:
| 操作符重载 | 描述 |
|---|---|
| T operator+= (ptrdiff_t val) volatile noexcept; | 原子地执行指针加法并赋值,返回新的指针 (volatile版本) |
| T operator+= (ptrdiff_t val) noexcept; | 原子地执行指针加法并赋值,返回新的指针 |
| T operator-= (ptrdiff_t val) volatile noexcept; | 原子地执行指针减法并赋值,返回新的指针 (volatile版本) |
| T operator-= (ptrdiff_t val) noexcept; | 原子地执行指针减法并赋值,返回新的指针 |
- 以上各个 operator 都会有对应的 fetch_* 操作,详细见下表:
| 操作符 | 操作符重载函数 | 等级的成员函数 | 整形 | 指针 | 其他 |
|---|---|---|---|---|---|
| + | atomic::operator+= | atomic::fetch_add | 是 | 是 | 否 |
| - | atomic::operator-= | atomic::fetch_sub | 是 | 是 | 否 |
| & | atomic::operator&= | atomic::fetch_and | 是 | 否 | 否 |
| | | atomic::operator|= | atomic::fetch_or | 是 | 否 | 否 |
| ^ | atomic::operator^= | atomic::fetch_xor | 是 | 否 | 否 |
5.1.4 内存顺序约束
通过上面的 API 函数我们可以看出,在调用 atomic类提供的 API 函数的时候,需要指定原子顺序
在C++11给我们提供的 API中使用枚举用作执行原子操作的函数的实参,以指定如何同步不同线程上的其他操作。
定义如下:
typedef enum memory_order {memory_order_relaxed, // relaxedmemory_order_consume, // consumememory_order_acquire, // acquirememory_order_release, // releasememory_order_acq_rel, // acquire/releasememory_order_seq_cst // sequentially consistent
} memory_order;
memory_order_relaxed,这是最宽松的规则,它对编译器和CPU不做任何限制,可以乱序memory_order_release释放,设定内存屏障(Memory barrier),保证它之前的操作永远在它之前,但是它后面的操作可能被重排到它前面memory_order_acquire获取, 设定内存屏障,保证在它之后的访问永远在它之后,但是它之前的操作却有可能被重排到它后面,往往和Release在不同线程中联合使用memory_order_consume:改进版的memory_order_acquire,开销更小memory_order_acq_rel,它是Acquire和Release的结合,同时拥有它们俩提供的保证。比如你要对一个 atomic 自增 1,同时希望该操作之前和之后的读取或写入操作不会被重新排序memory_order_seq_cst顺序一致性,memory_order_seq_cst就像是memory_order_acq_rel的加强版,它不管原子操作是属于读取还是写入的操作
只要某个线程有用到memory_order_seq_cst的原子操作,线程中该memory_order_seq_cst操作前的数据操作绝对不会被重新排在该memory_order_seq_cst操作之后,且该memory_order_seq_cst操作后的数据操作也绝对不会被重新排在memory_order_seq_cst操作前。
5.1.5 C++20新增成员
在C++20版本中添加了新的功能函数,可以通过原子类型来阻塞线程,和条件变量中的等待/通知函数是一样的。
| 公共成员函数 | 说明 |
|---|---|
| wait (C++20) | 阻塞线程直至被提醒且原子值更改 |
| notify_one (C++20) | 通知(唤醒)至少一个在原子对象上阻塞的线程 |
| notify_all (C++20) | 通知(唤醒)所有在原子对象上阻塞的线程 |
类型别名
| 别名 | 原始类型定义 |
|---|---|
| atomic_bool (C++11) | std::atomic<bool> |
| atomic_char (C++11) | std::atomic<char> |
| atomic_schar (C++11) | std::atomic<signed char> |
| atomic_uchar (C++11) | std::atomic<unsigned char> |
| atomic_short (C++11) | std::atomic<short> |
| atomic_ushort (C++11) | std::atomic<unsigned short> |
| atomic_int (C++11) | std::atomic<int> |
| atomic_uint (C++11) | std::atomic<unsigned int> |
| atomic_long (C++11) | std::atomic<long> |
| atomic_ulong (C++11) | std::atomic<unsigned long> |
| atomic_llong (C++11) | std::atomic<long long> |
| atomic_ullong (C++11) | std::atomic<unsigned long long> |
| atomic_char8_t (C++20) | std::atomic<char8_t> |
| atomic_char16_t (C++11) | std::atomic<char16_t> |
| atomic_char32_t (C++11) | std::atomic<char32_t> |
| atomic_wchar_t (C++11) | std::atomic<wchar_t> |
| atomic_int8_t (C++11) | std::atomic<std::int8_t> |
| atomic_uint8_t (C++11) | std::atomic<std::uint8_t> |
| atomic_int16_t (C++11) | std::atomic<std::int16_t> |
| atomic_uint16_t (C++11) | std::atomic<std::uint16_t> |
| atomic_int32_t (C++11) | std::atomic<std::int32_t> |
| atomic_uint32_t (C++11) | std::atomic<std::uint32_t> |
| atomic_int64_t (C++11) | std::atomic<std::int64_t> |
| atomic_uint64_t (C++11) | std::atomic<std::uint64_t> |
| atomic_int_least8_t (C++11) | std::atomic<std::int_least8_t> |
| atomic_uint_least8_t (C++11) | std::atomic<std::uint_least8_t> |
| atomic_int_least16_t (C++11) | std::atomic<std::int_least16_t> |
| atomic_uint_least16_t (C++11) | std::atomic<std::uint_least16_t> |
| atomic_int_least32_t (C++11) | std::atomic<std::int_least32_t> |
| atomic_uint_least32_t (C++11) | std::atomic<std::uint_least32_t> |
| atomic_int_least64_t (C++11) | std::atomic<std::int_least64_t> |
| atomic_uint_least64_t (C++11) | std::atomic<std::uint_least64_t> |
| atomic_int_fast8_t (C++11) | std::atomic<std::int_fast8_t> |
| atomic_uint_fast8_t (C++11) | std::atomic<std::uint_fast8_t> |
| atomic_int_fast16_t (C++11) | std::atomic<std::int_fast16_t> |
| atomic_uint_fast16_t (C++11) | std::atomic<std::uint_fast16_t> |
| atomic_int_fast32_t (C++11) | std::atomic<std::int_fast32_t> |
| atomic_uint_fast32_t (C++11) | std::atomic<std::uint_fast32_t> |
| atomic_int_fast64_t (C++11) | std::atomic<std::int_fast64_t> |
| atomic_uint_fast64_t (C++11) | std::atomic<std::uint_fast64_t> |
| atomic_intptr_t (C++11) | std::atomic<std::intptr_t> |
| atomic_uintptr_t (C++11) | std::atomic<std::uintptr_t> |
| atomic_size_t (C++11) | std::atomic<std::size_t> |
| atomic_ptrdiff_t (C++11) | std::atomic<std::ptrdiff_t> |
| atomic_intmax_t (C++11) | std::atomic<std::intmax_t> |
| atomic_uintmax_t (C++11) | std::atomic<std::uintmax_t> |
5.2 原子变量的使用
假设我们要制作一个多线程交替数数的计数器,我们使用互斥锁和原子变量的方式分别进行实现,对比一下二者的差异:
5.2.1 互斥锁版本
#include <iostream>
#include <thread>
#include <mutex>
#include <atomic>
#include <functional>
using namespace std;struct Counter
{void increment(){for (int i = 0; i < 10; ++i){lock_guard<mutex> locker(m_mutex);m_value++;cout << "increment number: " << m_value << ", theadID: " << this_thread::get_id() << endl;this_thread::sleep_for(chrono::milliseconds(100));}}void decrement(){for (int i = 0; i < 10; ++i){lock_guard<mutex> locker(m_mutex);m_value--;cout << "decrement number: " << m_value << ", theadID: " << this_thread::get_id() << endl;this_thread::sleep_for(chrono::milliseconds(100));}}int m_value = 0;mutex m_mutex;
};int main()
{Counter c;auto increment = bind(&Counter::increment, &c);auto decrement = bind(&Counter::decrement, &c);thread t1(increment);thread t2(decrement);t1.join();t2.join();return 0;
}
5.2.2 原子变量版本
#include <iostream>
#include <thread>
#include <atomic>
#include <functional>
using namespace std;struct Counter
{void increment(){for (int i = 0; i < 10; ++i){m_value++;cout << "increment number: " << m_value<< ", theadID: " << this_thread::get_id() << endl;this_thread::sleep_for(chrono::milliseconds(500));}}void decrement(){for (int i = 0; i < 10; ++i){m_value--;cout << "decrement number: " << m_value<< ", theadID: " << this_thread::get_id() << endl;this_thread::sleep_for(chrono::milliseconds(500));}}// atomic<int> == atomic_intatomic_int m_value = 0;
};int main()
{Counter c;auto increment = bind(&Counter::increment, &c);auto decrement = bind(&Counter::decrement, &c);thread t1(increment);thread t2(decrement);t1.join();t2.join();return 0;
}
通过代码的对比可以看出,使用了原子变量之后,就不需要再定义互斥量了,在使用上更加简便,并且这两种方式都能保证在多线程操作过程中数据的正确性,不会出现数据的混乱。
原子类型atomic<T> 可以封装原始数据最终得到一个原子变量对象,操作原子对象能够得到和操作原始数据一样的效果,当然也可以通过store()和load()来读写原子对象内部的原始数据。
6. 多线程异步操作
6.1 std:future
C++11中增加的线程类,使得我们能够非常方便的创建和使用线程
但有时会有些不方便,比如需要获取线程返回的结果,就不能通过join()得到结果,只能通过一些额外手段获得,比如:定义一个全局变量,在子线程中赋值,在主线程中读这个变量的值,整个过程比较繁琐。
C++提供的线程库中提供了一些类用于访问异步操作的结果。
那么,什么叫做异步呢?
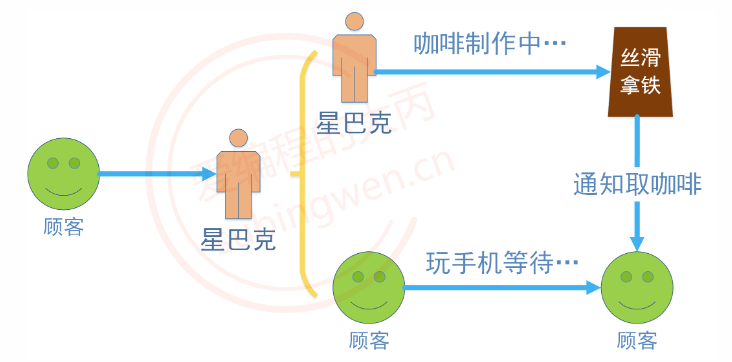
我们去星巴克买咖啡,因为都是现磨的,所以需要等待,但是我们付完账后不会站在柜台前死等,而是去找个座位坐下来玩玩手机打发一下时间,当店员把咖啡磨好之后,就会通知我们过去取,这就叫做异步。
- 顾客(主线程)发起一个任务(子线程磨咖啡),磨咖啡的过程中顾客去做别的事情了,有两条时间线(异步)
- 顾客(主线程)发起一个任务(子线程磨咖啡),磨咖啡的过程中顾客没去做别的事情而是死等,这时就只有一条时间线(同步),此时效率相对较低。
因此多线程程序中的任务大都是异步的,主线程和子线程分别执行不同的任务,如果想要在主线中得到某个子线程任务函数返回的结果可以使用C++11提供的std:future类,这个类需要和其他类或函数搭配使用
先来介绍一下这个类的API函数:
类的定义
通过类的定义可以得知,future是一个模板类,也就是这个类可以存储任意指定类型的数据。
// 定义于头文件 <future>
template< class T > class future;
template< class T > class future<T&>;
template<> class future<void>;
构造函数
// 1
future() noexcept;
// 2
future( future&& other ) noexcept;
// 3
future( const future& other ) = delete;
- 构造函数①:默认无参构造函数
- 构造函数②:移动构造函数,转移资源的所有权
- 构造函数③:使用=delete显示删除拷贝构造函数, 不允许进行对象之间的拷贝
常用成员函数(public)
一般情况下使用
=进行赋值操作就进行对象的拷贝,但是future对象不可用复制
因此会根据实际情况进行处理:
- 如果other是右值,那么转移资源的所有权
- 如果other是非右值,不允许进行对象之间的拷贝(该函数被显示删除禁止使用)
future& operator=( future&& other ) noexcept;
future& operator=( const future& other ) = delete;
取出
future对象内部保存的数据,其中void get()是为future<void>准备的
此时对象内部类型就是void,该函数是一个阻塞函数,当子线程的数据就绪后解除阻塞就能得到传出的数值了。
T get();
T& get();
void get();
因为
future对象内部存储的是异步线程任务执行完毕后的结果,是在调用之后的将来得到的,因此可以通过调用wait()方法,阻塞当前线程,等待这个子线程的任务执行完毕,任务执行完毕当前线程的阻塞也就解除了。
//函数原型
void wait() const;
wait()方法就会死等,直到子线程任务执行完毕将返回值写入到future对象中
wait_for()只会让线程阻塞一定的时长,但是这样并不能保证对应的那个子线程中的任务已经执行完毕了。
wait_until()和wait_for()函数功能是差不多
前者是阻塞到某一指定的时间点,后者是阻塞一定的时长。
template< class Rep, class Period >
std::future_status wait_for( const std::chrono::duration<Rep,Period>& timeout_duration ) const;template< class Clock, class Duration >
std::future_status wait_until( const std::chrono::time_point<Clock,Duration>& timeout_time ) const;
当wait_until()和wait_for()函数返回之后,并不能确定子线程当前的状态,因此我们需要判断函数的返回值,这样就能知道子线程当前的状态了:
| 常量 | 解释 |
|---|---|
| future_status::deferred | 子线程中的任务函仍未启动 |
| future_status::ready | 子线程中的任务已经执行完毕,结果已就绪 |
| future_status::timeout | 子线程中的任务正在执行中,指定等待时长已用完 |
6.2 std::promise
std::promise是一个协助线程赋值的类,它能够将数据和future对象绑定起来,为获取线程函数中的某个值提供便利。
6.2.1 类成员函数
类定义
通过std::promise类的定义可以得知,这也是一个模板类,我们要在线程中传递什么类型的数据,模板参数就指定为什么类型。
// 定义于头文件 <future>
template< class R > class promise;
template< class R > class promise<R&>;
template<> class promise<void>;
构造函数
// ①
promise();
// ②
promise( promise&& other ) noexcept;
// ③
promise( const promise& other ) = delete;
- 构造函数①:默认构造函数,得到一个空对象
- 构造函数②:移动构造函数
- 构造函数③:使用=delete显示删除拷贝构造函数, 不允许进行对象之间的拷贝
公共成员函数
在
std::promise类内部管理着一个future类对象,调用get_future()就可以得到这个future对象了
//函数原型
std::future<T> get_future();
存储要传出的 value 值,并立即让状态就绪,这样数据被传出其它线程就可以得到这个数据了。重载的第四个函数是为promise<void>类型的对象准备的。
void set_value( const R& value );
void set_value( R&& value );
void set_value( R& value );
void set_value();
存储要传出的 value 值,但是不立即令状态就绪。在当前线程退出时,子线程资源被销毁,再令状态就绪。
void set_value_at_thread_exit( const R& value );
void set_value_at_thread_exit( R&& value );
void set_value_at_thread_exit( R& value );
void set_value_at_thread_exit();
6.2.2 promise的使用
通过promise传递数据的过程一共分为5步:
- 在主线程中创建std::promise对象
- 将这个std::promise对象通过引用的方式传递给子线程的任务函数
- 在子线程任务函数中给std::promise对象赋值
- 在主线程中通过std::promise对象取出绑定的future实例对象
- 通过得到的future对象取出子线程任务函数中返回的值。
子线程任务函数执行期间,让状态就绪
#include <iostream>
#include <thread>
#include <future>
using namespace std;int main()
{promise<int> pr;thread t1([](promise<int> &p) {p.set_value(100);this_thread::sleep_for(chrono::seconds(3));cout << "睡醒了...." << endl;}, ref(pr));future<int> f = pr.get_future();int value = f.get();cout << "value: " << value << endl;t1.join();return 0;
}
示例程序输出的结果:
value: 100
睡醒了....
示例程序的中子线程的任务函数指定的是一个匿名函数,在这个匿名的任务函数执行期间通过p.set_value(100);传出了数据并且激活了状态
数据就绪后,外部主线程中的int value = f.get();解除阻塞,并将得到的数据打印出来,5秒钟之后子线程休眠结束,匿名的任务函数执行完毕。
子线程任务函数执行结束,让状态就绪
#include <iostream>
#include <thread>
#include <future>
using namespace std;int main()
{promise<int> pr;thread t1([](promise<int> &p) {p.set_value_at_thread_exit(100);this_thread::sleep_for(chrono::seconds(3));cout << "睡醒了...." << endl;}, ref(pr));future<int> f = pr.get_future();int value = f.get();cout << "value: " << value << endl;t1.join();return 0;
}
示例程序输出的结果:
睡醒了....
value: 100
在示例程序中,子线程的这个匿名的任务函数中通过p.set_value_at_thread_exit(100);在执行完毕并退出之后才会传出数据并激活状态
数据就绪后,外部主线程中的int value = f.get();解除阻塞,并将得到的数据打印出来,因此子线程在休眠5秒钟之后主线程中才能得到传出的数据。
注意:在外部主线程中创建的promise对象必须要通过引用的方式传递到子线程的任务函数中,在实例化子线程对象的时候,如果任务函数的参数是引用类型,那么实参一定要放到std::ref()函数中,表示要传递这个实参的引用到任务函数中。
6.3. std::packaged_task
std::packaged_task类包装了一个可调用对象包装器类对象(可调用对象包装器包装的是可调用对象,可调用对象都可以作为函数来使用),恶补一下可调用对象和可调用对象包装器
这个类可以将内部包装的函数和future类绑定到一起,以便进行后续的异步调用,和std::promise有点类似
std::promise内部保存一个共享状态的值,而std::packaged_task保存的是一个函数。
6.3.1 类成员函数
类的定义
通过类的定义可以看到这也是一个模板类,模板类型和要在线程中传出的数据类型是一致的。
// 定义于头文件 <future>
template< class > class packaged_task;
template< class R, class ...Args >
class packaged_task<R(Args...)>;
构造函数
// ①
packaged_task() noexcept;
// ②
template <class F>
explicit packaged_task( F&& f );
// ③
packaged_task( const packaged_task& ) = delete;
// ④
packaged_task( packaged_task&& rhs ) noexcept;
- 构造函数①:无参构造,构造一个无任务的空对象
- 构造函数②:通过一个可调用对象,构造一个任务对象
- 构造函数③:显示删除,不允许通过拷贝构造函数进行对象的拷贝
- 构造函数④:移动构造函数
常用公共成员函数
通过调用任务对象内部的get_future()方法就可以得到一个future对象,基于这个对象就可以得到传出的数据了。
//函数原型
std::future<R> get_future();
6.3.2 packaged_task的使用
packaged_task其实就是对子线程要执行的任务函数进行了包装,和可调用对象包装器的使用方法相同,包装完毕之后直接将包装得到的任务对象传递给线程对象就可以了。
#include <iostream>
#include <thread>
#include <future>
using namespace std;int main()
{packaged_task<int(int)> task([](int x) {return x += 100;});thread t1(ref(task), 100);future<int> f = task.get_future();int value = f.get();cout << "value: " << value << endl;t1.join();return 0;
}
在上面的示例代码中,通过packaged_task类包装了一个匿名函数作为子线程的任务函数,最终的得到的这个任务对象需要通过引用的方式传递到子线程内部,这样才能在主线程的最后通过任务对象得到future对象,再通过这个future对象取出子线程通过返回值传递出的数据。
6.4 std::async
std::async函数比前面提到的std::promise和packaged_task更高级一些
因为通过这函数可以直接启动一个子线程并在这个子线程中执行对应的任务函数,异步任务执行完成返回的结果也是存储到一个future对象中
当需要获取异步任务的结果时,只需要调用future类的get()方法即可
如果不关注异步任务的结果,只是简单地等待任务完成的话,可以调用future类的wait()或者wait_for()方法。
// 函数原型
// 定义于头文件 <future>
// 1
template< class Function, class... Args>
std::future<std::result_of_t<std::decay_t<Function>(std::decay_t<Args>...)>>async( Function&& f, Args&&... args );// 2
template< class Function, class... Args >
std::future<std::result_of_t<std::decay_t<Function>(std::decay_t<Args>...)>>async( std::launch policy, Function&& f, Args&&... args );
可以看到这是一个模板函数,在C++11中这个函数有两种调用方式:
-
函数①:直接调用传递到函数体内部的可调用对象,返回一个
future对象 -
函数②:通过指定的策略调用传递到函数内部的可调用对象,返回一个
future对象
函数参数: -
f:可调用对象,这个对象在子线程中被作为任务函数使用 -
Args:传递给 f 的参数(实参) -
policy:可调用对象·f的执行策略
| 策略 | 说明 |
|---|---|
| std::launch::async | 调用async函数时创建新的线程执行任务函数 |
| std::launch::deferred | 调用async函数时不执行任务函数,直到调用了future的get()或者wait()时才执行任务(这种方式不会创建新的线程) |
关于std::async()函数的使用,对应的示例代码如下:
6.4.1 方式1
调用async()函数直接创建线程执行任务
#include <iostream>
#include <thread>
#include <future>
using namespace std;int main()
{cout << "主线程ID: " << this_thread::get_id() << endl;// 调用函数直接创建线程执行任务future<int> f = async([](int x) {cout << "子线程ID: " << this_thread::get_id() << endl;this_thread::sleep_for(chrono::seconds(5));return x += 100;}, 100);future_status status;do {status = f.wait_for(chrono::seconds(1));if (status == future_status::deferred){cout << "线程还没有执行..." << endl;f.wait();}else if (status == future_status::ready){cout << "子线程返回值: " << f.get() << endl;}else if (status == future_status::timeout){cout << "任务还未执行完毕, 继续等待..." << endl;}} while (status != future_status::ready);return 0;
}
示例程序输出的结果为:
主线程ID: 8904
子线程ID: 25036
任务还未执行完毕, 继续等待...
任务还未执行完毕, 继续等待...
任务还未执行完毕, 继续等待...
任务还未执行完毕, 继续等待...
任务还未执行完毕, 继续等待...
子线程返回值: 200
调用async()函数时不指定策略就是直接创建线程并执行任务,示例代码的主线程中做了如下操作
status = f.wait_for(chrono::seconds(1));
其实直接调用f.get()就能得到子线程的返回值。
为了演示`wait_for()``的使用,所以写的复杂了些。
6.4.2 方式2
调用async()函数不创建线程执行任务
#include <iostream>
#include <thread>
#include <future>
using namespace std;int main()
{cout << "主线程ID: " << this_thread::get_id() << endl;// 调用函数直接创建线程执行任务future<int> f = async(launch::deferred, [](int x) {cout << "子线程ID: " << this_thread::get_id() << endl;return x += 100;}, 100);this_thread::sleep_for(chrono::seconds(5));cout << f.get();return 0;
}
示例程序输出的结果:
主线程ID: 24760
主线程开始休眠5秒...
子线程ID: 24760
200
由于指定了launch::deferred 策略,因此调用async()函数并不会创建新的线程执行任务
当使用future类对象调用了get()或者wait()方法后才开始执行任务(此处一定要注意调用wait_for()函数是不行的)。
通过测试程序输出的结果可以看到,两次输出的线程ID是相同的,任务函数是在主线程中被延迟(主线程休眠了5秒)调用了。
最终总结:
- 使用
async()函数,是多线程操作中最简单的一种方式,不需要自己创建线程对象,并且可以得到子线程函数的返回值。 - 使用
std::promise类,在子线程中可以传出返回值也可以传出其他数据,并且可选择在什么时机将数据从子线程中传递出来,使用起来更灵活。 - 使用
std::packaged_task类,可将子线程的任务函数进行包装,并可得到子线程返回值。
相关文章:
[线程/C++]线程同(异)步和原子变量
文章目录 1.线程的使用1.1 函数构造1.2 公共成员函数1.2.1 get_id()1.2.2 join()2.2.3 detach()2.2.5 joinable()2.2.6 operator 1.3 静态函数1.4 call_once 2. this_thread 命名空间2.1 get_id()2.2 sleep_for()2.3 sleep_until()2.4 yield() 3. 线程同步之互斥锁3.1 std:mute…...

全球网络加速器GA和内容分发网络CDN,哪个更适合您的组织使用?
对互联网用户来说,提供最佳的用户体验至关重要:网页加载时间过长、视频播放断断续续以及服务忽然中断等问题都足以在瞬间失去客户。因此可以帮助提高您的网站或APP提高加载性能的解决方案就至关重要:全球网络加速器和CDN就是其中的两种解决方…...
蓝凌OA custom.jsp 任意文件读取
曾子曰:“慎终追远,民德归厚矣。” 漏洞复现 访问漏洞url: 出现漏洞的文件为 custom.jsp,构造payload: /sys/ui/extend/varkind/custom.jsp var{"body":{"file":"file:///etc/passwd&q…...
(二)结构型模式:7、享元模式(Flyweight Pattern)(C++实例)
目录 1、享元模式(Flyweight Pattern)含义 2、享元模式的UML图学习 3、享元模式的应用场景 4、享元模式的优缺点 5、C实现享元模式的简单实例 1、享元模式(Flyweight Pattern)含义 享元模式(Flyweight)…...

laravel 多次查询请求,下次请求清除上次请求的where 条件
在Laravel中,可以使用where方法来添加查询条件,但是每次添加where条件时,都会在查询构造器中持久化这些条件,直到你手动重置它们。所以,如果你想在下一次查询中清除上次查询的where条件,有以下几种选择&…...

C++根据如下使用类MyDate的程序,写出类MyDate的定义,MyDate中有三个数据成员:年year,月month,日day完成以下要求
题目: 根据如下使用类MyDate的程序,写出类MyDate的定义,MyDate中有三个数据成员: 年year,月month,日day int year,month,day; void main() { MyDate d1, d2; d1.set(2015, 12, 31); d2.set(d1); d1.…...
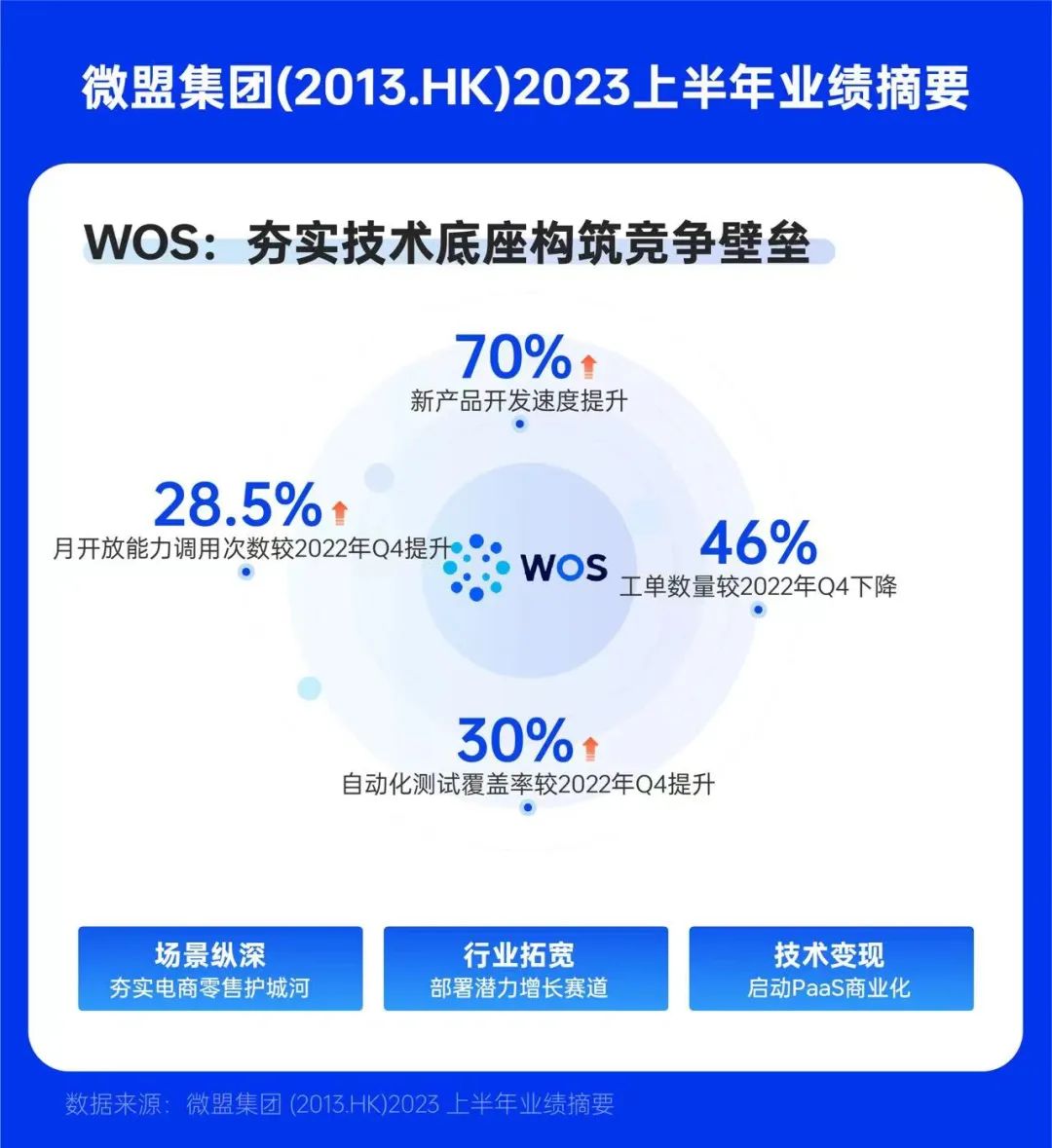
微盟集团中报增长稳健 重点发力智慧零售AI赛道
零售数字化进程已从渠道构建走向了用户的深度运营。粗放式用户运营体系无法适应“基于用户增长所需配套的精细化运营能力”,所以需要有个体、群体、个性化、自动化运营——即在对的时候、以对的方式、把对的内容推给用户。 出品|产业家 2023年已经过半,经济复苏成为…...
模板方法模式)
设计模式(7)模板方法模式
一、定义: 定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。它是一种类行为型模式。 //模板方法抽象类 public abstract class AbstractClass {//模板方法publ…...

2308C++协程流程9
参考 #include <协程> #include "简异中.cpp" //用来中文定义的.元<类 T>构 P;元<类 T>构 任务{用 承诺型P<T>;任务()默认;动 符号 协待()常 无异{构 等待器{极 直接协()常 无异{中 p.是准备好();}协柄 挂起协(协柄<>o)常 无异{p.连续…...

基于学习交流社区的自动化测试实现
一 项目介绍 项目名称 项目名称: 学习交流社区 项目介绍 项目介绍: 学习交流社区是一个基于Spring的前后端分离的在线论坛系统。使用了MySQL数据库来存储相关信息,项目完成后使用Xshell将其部署到云服务器上。 前端页面: 前端共由…...

2023-08-21力扣每日一题
链接: 2337. 移动片段得到字符串 题意: L可以和左边的_交换,R可以和右边的_交换,求判断A是否能通过交换(不限次数)变成B 解: 观察可知,如果存在RL,一定不能交换出LR,…...

对象存储服务-MinIO基本集成
是什么 MinIO 是一个高性能的分布式对象存储服务,适合存储非结构化数据,如图片,音频,视频,日志等。对象文件最大可以达到5TB。 安装启动 mkdir -p /usr/local/minio cd /usr/local/minio# 下载安装包 wget https:/…...

Yarn介绍及快速安装 - Debian/Ubuntu Linux
1.Yarn介绍 Yarn 是一个用于管理 JavaScript 包的快速、可靠和安全的包管理器。它是由 Facebook、Google、Exponent 和 Tilde 团队共同开发的,旨在提供比 npm 更快速、可靠的包管理体验。 以下是 Yarn 的一些主要特点和优势: 快速安装:Yarn…...
】第10課 中国の生活に慣れるかどうか少し心配です)
【新日语(2)】第10課 中国の生活に慣れるかどうか少し心配です
第10課 中国の生活に慣れるかどうか少し心配です 注释: ~かどうか:“是否”。 练习A 一、例句 田中さんは鈴木さんに、30分ぐらい遅れると言いました。 田中先生告诉铃木先生,他会迟到大约30分钟。 注释: &…...

Python 网页解析初级篇:BeautifulSoup库的入门使用
在Python的网络爬虫中,网页解析是一项重要的技术。而在众多的网页解析库中,BeautifulSoup库凭借其简单易用而广受欢迎。在本篇文章中,我们将学习BeautifulSoup库的基本用法。 一、BeautifulSoup的安装与基本使用 首先,我们需要使…...

Spring Schedular 定时任务
大家好 , 我是苏麟 , 今天带来定时任务的实现 . Spring网站 : 入门 |计划任务 (spring.io) 什么是定时任务 通过时间表达式来进行调度和执行的一类任务被称为定时任务 定时任务实现 1.Spring Schedule (Spring boot 默认整合了) 2.Quartz(独立于Spring 存在的定时任务框架…...

营业额统计
营业额统计 # 题目描述 Tiger 最近被公司升任为营业部经理,他上任后接受公司交给的第一项任务便是统计并分析公司成立以来的营业情况。 Tiger 拿出了公司的账本,账本上记录了公司成立以来每天的营业额。分析营业情况是一项相当复杂的工作。由于节假日&…...

使用lodash的throttle函数会触发两次
当使用lodash的throttle函数时会触发两次,分别在最开始和最后。 严格来说不算是bug,因为官方文档写的很清楚。throttle函数其实有三个参数: _.throttle(func, [wait0], [options]) func: 要节流的函数 wait: 等待时间 options: 选项 op…...

如何使用CSS实现一个瀑布流布局?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用CSS实现瀑布流布局⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、刚刚…...

dfs之有重复字符串的排列组合
https://leetcode.cn/problems/permutation-ii-lcci/description/ ■ 题目描述 考古问题,假设以前的石碑被打碎成了很多块,每块上面都有一个或若干个字符,请你写个程序来把之前石碑上文字可能的组合全部写出来,按升序进行排列。…...
)
MATLAB实战:手把手教你实现FM调制解调(附完整代码与避坑指南)
MATLAB实战:从零构建FM通信系统的完整指南 在无线通信领域,频率调制(FM)技术因其出色的抗噪声性能,至今仍广泛应用于广播、对讲机等场景。对于通信工程学生和MATLAB初学者而言,亲手实现一个完整的FM调制解调系统,是理解…...

小白也能懂:Qwen3-TTS-Tokenizer-12Hz的API调用与Python示例
小白也能懂:Qwen3-TTS-Tokenizer-12Hz的API调用与Python示例 1. 前言:音频编解码器能做什么? 想象一下,你录制了一段重要的会议录音,文件大小有50MB,想通过微信发给同事,却发现超过了文件大小…...

专访越擎科技创始人: 外骨骼的设计与仿真该如何入门
具身智能机器人领域的技术创新如火如荼,从轮式机器人,人形机器人,四足机器狗等不一而足。而从分类来看,外骨骼机器人作为增强人的能力的典型应用,不仅在医疗领域发挥重要作用,在工业应用等场景中也大大的增…...

AI大模型入门指南:泛化、通用、涌现三大特征解析,小白也能学会收藏!
本文深入浅出地介绍了AI大模型的主要特征,包括泛化性、通用性和涌现性,并以ChatGPT为例,阐述了其如何通过巨量参数和深度网络结构展现强大的自然语言理解和生成能力。文章还详细分类并介绍了云侧大模型(如通用大模型和行业大模型&…...

智能提取视频转文档:自动化工具提升内容处理效率
智能提取视频转文档:自动化工具提升内容处理效率 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 在数字化学习与办公场景中,视频内容提取已成为知识管理的重要…...
)
GIL已死,GIL万岁?——2024大厂Python并发岗面试题库首发(含性能压测对比数据)
第一章:GIL已死,GIL万岁?——2024大厂Python并发岗面试题库首发(含性能压测对比数据)一道高频真题:为什么 asyncio.run() 启动的协程无法被 multiprocessing.Process 并发执行? 该问题直指 Pyth…...
)
Cursor最新版0.44.11配置DeepSeek-R1模型保姆级教程(含报错解决方案)
Cursor 0.44.11深度适配DeepSeek-R1模型全流程指南 当技术爱好者第一次在Cursor中尝试调用DeepSeek-R1模型时,往往会遇到各种"水土不服"的情况。就像刚拿到新相机的摄影师需要调整镜头焦距一样,我们需要对Cursor进行精确配置才能充分发挥这个强…...

Windows下OpenClaw实战:30分钟接入Qwen3.5-4B-Claude模型
Windows下OpenClaw实战:30分钟接入Qwen3.5-4B-Claude模型 1. 为什么选择WindowsOpenClaw组合 去年我在尝试自动化办公流程时,发现很多AI工具对Windows支持并不友好。直到遇到OpenClaw,这个开源的智能体框架让我眼前一亮——它不仅能像人类一…...

基于关键链方法的遗传算法求解项目调度问题
一、问题背景与核心思想 项目调度问题(Project Scheduling Problem, PSP)是在满足活动逻辑关系(紧前约束)和资源约束(如人力、设备)的前提下,确定各活动开始/结束时间,以最小化项目工…...

【Mojo+Python混合部署失效真相】:92%开发者忽略的编译期符号冲突、运行时上下文隔离与调试断点丢失问题
第一章:MojoPython混合部署失效真相全景概览Mojo 作为新兴的高性能系统编程语言,设计初衷是与 Python 生态无缝互操作;然而在真实生产部署中,“Mojo Python 混合部署”常出现静默失败、ABI 不兼容、运行时崩溃或性能断崖式下降等…...