机器学习深度学习——NLP实战(自然语言推断——注意力机制实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——NLP实战(自然语言推断——数据集)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
NLP实战(自然语言推断——注意力机制实现)
- 引入
- 模型
- 注意(Attending)
- 比较
- 聚合
- 整合代码
- 训练和评估模型
- 读取数据集
- 创建模型
- 训练和评估模型
- 使用模型
- 小结
引入
在之前已经介绍了什么是自然语言推断,并且下载并处理了SNLI数据集。由于许多模型都是基于复杂而深度的架构,因此提出用注意力机制解决自然语言推断问题,并且称之为“可分解注意力模型”。这使得模型没有循环层或卷积层,在SNLI数据集上以更少的参数实现了当时的最佳结果。下面就实现这种基于注意力的自然语言推断方法(使用MLP),如下图所述:
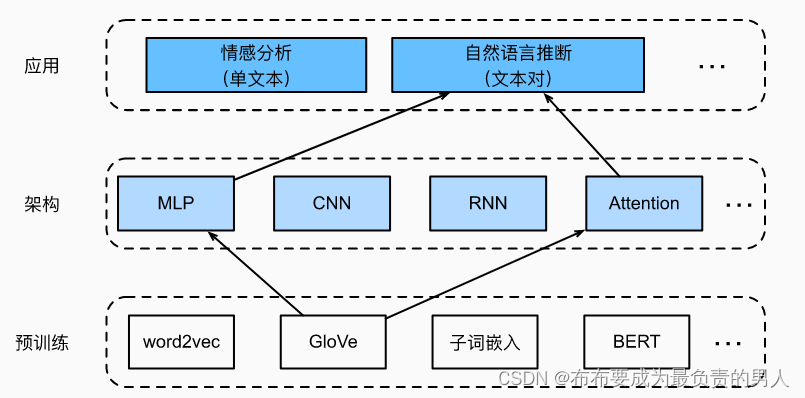
这里的任务就是要将预训练GloVe送到注意力和MLP的自然语言推断架构。
模型
与保留前提和假设中词元的顺序,我们可以将一个文本序列中的词元与另一个文本序列中的每个词元对齐,然后比较和聚合这些信息,以预测前提和假设之间的逻辑关系。这和机器翻译中源句和目标句之间的词元对齐类似,前提和假设之间的词元对齐可以通过注意力机制来灵活完成。如下所示就是使用注意力机制来实现自然语言推断的模型图:
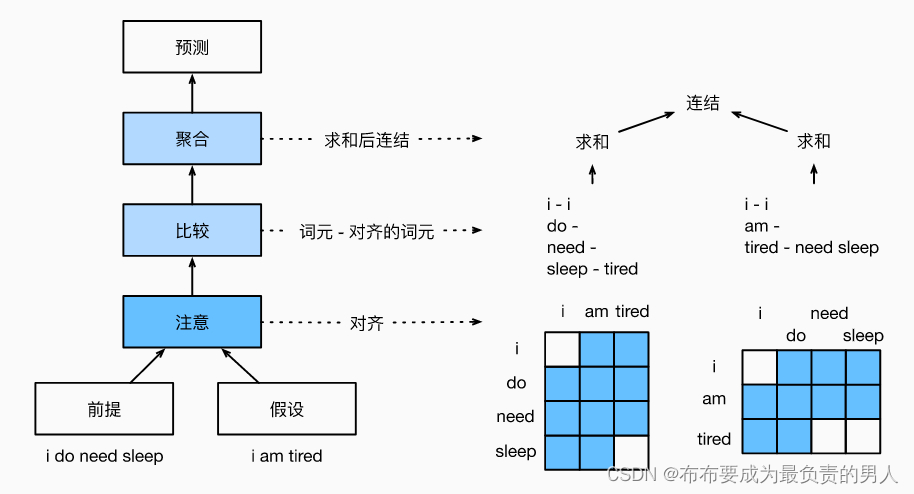
上面的i和i相对,前提中的sleep会对应tired,假设中的tired对应的是need sleep。
从高层次讲,它由三个联合训练的步骤组成:对齐、比较和汇总,下面会通过代码来解释和实现。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
注意(Attending)
第一步是将一个文本序列中的词元与另一个序列中的每个词元对齐。假设前提是“我需要睡眠”,假设是“我累了”。由于语义上的相似性,我们不妨将假设中的“我”与前提中的“我”对齐,将假设中的“累”与前提中的“睡眠”对齐。同样,我们可能希望将前提中的“我”与假设中的“我”对齐,将前提中“需要睡眠”与假设中的“累”对齐。
注意,这种对齐是使用的加权平均的“软”对齐,其中理想情况下较大的权重与要对齐的词元相关联。为了便于演示,上图是用了“硬”对齐的方式来展示。
现在,我们要详细描述使用注意力机制的软对齐。
用
A = ( a 1 , . . . , a m ) 和 B = ( b 1 , . . . , b n ) A=(a_1,...,a_m)和B=(b_1,...,b_n) A=(a1,...,am)和B=(b1,...,bn)
分别表示前提和假设,其词元数量分别为m和n,其中:
a 1 , b j ∈ R d 是 d 维的词向量 a_1,b_j∈R^d是d维的词向量 a1,bj∈Rd是d维的词向量
关于软对齐,我们将注意力权重计算为:
e i j = f ( a i ) T f ( b j ) e_{ij}=f(a_i)^Tf(b_j) eij=f(ai)Tf(bj)
其中函数f是在下面的mlp函数中定义的多层感知机。输出维度f由mlp的num_hiddens参数指定。
def mlp(num_inputs, num_hiddens, flatten):net = []net.append(nn.Dropout(0.2))net.append(nn.Linear(num_inputs, num_hiddens))net.append(nn.ReLU())if flatten:net.append(nn.Flatten(start_dim=1))net.append(nn.Dropout(0.2))net.append(nn.Linear(num_hiddens, num_hiddens))net.append(nn.ReLU())if flatten:net.append(nn.Flatten(start_dim=1))return nn.Sequential(*net)
值得注意的是,上式中,f分别输入ai和bi,而不是把它们一对放在一起作为输入。这种分解技巧导致f只有m+n次计算(线性复杂度),而不是mn次计算(二次复杂度)。
对上式中的注意力权重进行规范化,我们计算假设中所有词元向量的加权平均值,以获得假设的表示,该假设与前提中索引i的词元进行软对齐:
β i = ∑ j = 1 n e x p ( e i j ) ∑ k = 1 n e x p ( e i k ) b j β_i=\sum_{j=1}^n\frac{exp(e_{ij})}{\sum_{k=1}^nexp(e_{ik})}b_j βi=j=1∑n∑k=1nexp(eik)exp(eij)bj
同理,我们计算假设中索引为j的每个词元与前提词元的软对齐:
α j = ∑ i = 1 m e x p ( e i j ) ∑ k = 1 m e x p ( e k j ) a i α_j=\sum_{i=1}^m\frac{exp(e_{ij})}{\sum_{k=1}^mexp(e_{kj})}a_i αj=i=1∑m∑k=1mexp(ekj)exp(eij)ai
下面,我们定义Attend类来计算假设(beta)与输入前提A的软对齐以及前提(alpha)与输入假设B的软对齐。
class Attend(nn.Module):def __init__(self, num_inputs, num_hiddens, **kwargs):super(Attend, self).__init__(**kwargs)self.f = mlp(num_inputs, num_hiddens, flatten=False)def forward(self, A, B):# A/B的形状:(批量大小,序列A/B的词元数,embed_size)# f_A/f_B的形状:(批量大小,序列A/B的词元数,num_hiddens)f_A = self.f(A)f_B = self.f(B)# e的形状:(批量大小,序列A的词元数,序列B的词元数)e = torch.bmm(f_A, f_B.permute(0, 2, 1))# beta的形状:(批量大小,序列A的词元数,embed_size),# 意味着序列B被软对齐到序列A的每个词元(beta的第1个维度)beta = torch.bmm(F.softmax(e, dim=-1), B)# beta的形状:(批量大小,序列B的词元数,embed_size),# 意味着序列A被软对齐到序列B的每个词元(alpha的第1个维度)alpha = torch.bmm(F.softmax(e.permute(0, 2, 1), dim=-1), A)return beta, alpha
比较
在下一步中,我们将一个序列中的词元与和该词元软对齐的另一个序列进行比较。注意,软对齐中,一个序列中的所有词元(尽管可能具有不同的注意力权重)将与另一个序列中的词元进行比较。
在比较步骤中,我们将来自一个序列的词元的连结(运算符[·,·])和来自另一个序列的对其的词元送入函数g(一个多层感知机):
v A , i = g ( [ a i , β i ] ) , i = 1 , . . . , m v B , j = g ( [ b j , α j ] ) , j = 1 , . . . , n 其中, v A , i 指:所有假设中的词元与前提中词元 i 软对齐,再与词元 i 的比较; v B , j 指:所有前提中的词元与假设中词元 j 软对齐,再与词元 j 的比较。 v_{A,i}=g([a_i,β_i]),i=1,...,m\\ v_{B,j}=g([b_j,α_j]),j=1,...,n\\ 其中,v_{A,i}指:所有假设中的词元与前提中词元i软对齐,再与词元i的比较;\\ v_{B,j}指:所有前提中的词元与假设中词元j软对齐,再与词元j的比较。 vA,i=g([ai,βi]),i=1,...,mvB,j=g([bj,αj]),j=1,...,n其中,vA,i指:所有假设中的词元与前提中词元i软对齐,再与词元i的比较;vB,j指:所有前提中的词元与假设中词元j软对齐,再与词元j的比较。
下面的Compare类定义了比较的步骤:
class Compare(nn.Module):def __init__(self, num_inputs, num_hiddens, **kwargs):super(Compare, self).__init__(**kwargs)self.g = mlp(num_inputs, num_hiddens, flatten=False)def forward(self, A, B, beta, alpha):V_A = self.g(torch.cat([A, beta], dim=2))V_B = self.g(torch.cat([B, alpha], dim=2))return V_A, V_B
聚合
现在我们有两组比较向量:
v A , i 和 v B , j v_{A,i}和v_{B,j} vA,i和vB,j
在最后一步中,我们将聚合这些信息以推断逻辑关系。我们首先求和这两组比较向量:
v A = ∑ i = 1 m v A , i , v B = ∑ j = 1 n v B , j v_A=\sum_{i=1}^mv_{A,i},v_B=\sum_{j=1}^nv_{B,j} vA=i=1∑mvA,i,vB=j=1∑nvB,j
接下来,我们将两个求和结果的连结提供给函数h(一个多层感知机),以获得逻辑关系的分类结果:
y ^ = h ( [ v A , v B ] ) \hat{y}=h([v_A,v_B]) y^=h([vA,vB])
聚合步骤在以下Aggregate类中定义。
class Aggregate(nn.Module):def __init__(self, num_inputs, num_hiddens, num_outputs, **kwargs):super(Aggregate, self).__init__(**kwargs)self.h = mlp(num_inputs, num_hiddens, flatten=True)self.linear = nn.Linear(num_hiddens, num_outputs)def forward(self, V_A, V_B):# 对两组比较向量分别求和V_A = V_A.sum(dim=1)V_B = V_B.sum(dim=1)# 将两个求和结果的连结送到多层感知机中Y_hat = self.linear(self.h(torch.cat([V_A, V_B], dim=1)))return Y_hat
整合代码
通过将注意步骤、比较步骤和聚合步骤组合在一起,我们定义了可分解注意力模型来联合训练这三个步骤:
class DecomposableAttention(nn.Module):def __init__(self, vocab, embed_size, num_hiddens, num_inputs_attend=100,num_inputs_compare=200, num_inputs_agg=400, **kwargs):super(DecomposableAttention, self).__init__(**kwargs)self.embedding = nn.Embedding(len(vocab), embed_size)self.attend = Attend(num_inputs_attend, num_hiddens)self.compare = Compare(num_inputs_compare, num_hiddens)# 有3种可能的输出:蕴涵、矛盾和中性self.aggregate = Aggregate(num_inputs_agg, num_hiddens, num_outputs=3)def forward(self, X):premises, hypotheses = XA = self.embedding(premises)B = self.embedding(hypotheses)beta, alpha = self.attend(A, B)V_A, V_B = self.compare(A, B, beta, alpha)Y_hat = self.aggregate(V_A, V_B)return Y_hat
训练和评估模型
现在,我们将在SNLI数据集上对定义好的可分解注意力模型进行训练和评估。我们从读取数据集开始。
读取数据集
我们使用上节定义的函数下载并读取SNLI数据集,批量大小和序列长度分别设为256和50:
batch_size, num_steps = 256, 50
train_iter, test_iter, vocab = d2l.load_data_snli(batch_size, num_steps)
创建模型
我们将预训练好的100维GloVe嵌入来表示输入词元。我们将向量ai和bj的维数定义为100。f和g的输出维度被设置为200。然后我们创建一个模型实例,初始化参数,并加载GloVe嵌入来初始化输入词元的向量。
embed_size, num_hiddens, devices = 100, 200, d2l.try_all_gpus()
net = DecomposableAttention(vocab, embed_size, num_hiddens)
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
训练和评估模型
现在我们可以在SNLI数据集上训练和评估模型。
lr, num_epochs = 0.001, 4
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
d2l.plt.show()
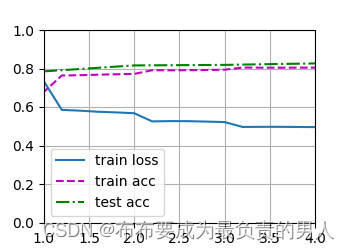
运行结果:
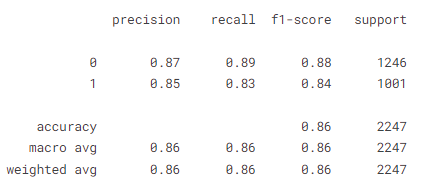
loss 0.495, train acc 0.805, test acc 0.826
443.5 examples/sec on [device(type=‘cpu’)]
运行图片:
使用模型
定义预测函数,输出一对前提和假设之间的逻辑关系。
#@save
def predict_snli(net, vocab, premise, hypothesis):"""预测前提和假设之间的逻辑关系"""net.eval()premise = torch.tensor(vocab[premise], device=d2l.try_gpu())hypothesis = torch.tensor(vocab[hypothesis], device=d2l.try_gpu())label = torch.argmax(net([premise.reshape((1, -1)),hypothesis.reshape((1, -1))]), dim=1)return 'entailment' if label == 0 else 'contradiction' if label == 1 \else 'neutral'
我们可以使用训练好的模型来获得对实例句子的自然语言推断结果:
print(predict_snli(net, vocab, ['he', 'is', 'good', '.'], ['he', 'is', 'bad', '.']))
预测结果:
‘contradiction’
小结
1、可分解注意模型包括三个步骤来预测前提和假设之间的逻辑关系:注意、比较和聚合。
2、通过注意力机制,我们可以将一个文本序列中的词元与另一个文本序列中的每个词元对齐,反之亦然。这种对齐是使用加权平均的软对齐,其中理想情况下,较大的权重与要对齐的词元相关联。
3、在计算注意力权重时,分解技巧会带来比二次复杂度更理想的线性复杂度。
4、我们可以使用预训练好的词向量作为下游自然语言处理任务的输入表示。
相关文章:
机器学习深度学习——NLP实战(自然语言推断——注意力机制实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——NLP实战(自然语言推断——数据集) 📚订阅专栏:机器学习&…...
mac垃圾清理软件有哪些
随着使用时间的增加,mac系统会产生一些垃圾文件,影响系统的性能和稳定性。为了保持mac系统的高效,用户需要定期使用mac垃圾清理软件来清理系统缓存、日志、语言包等无用文件。CleanMyMac是一款功能强大的mac垃圾清理软件,它可以帮…...

8.18 校招 内推 面经
绿泡泡: neituijunsir 交流裙,内推/实习/校招汇总表格 1、校招 | 小米集团2024届全球校园招聘正式启动(内推) 校招 | 小米集团2024届全球校园招聘正式启动(内推) 2、2023校招总结--软件测试岗位 - 2 2…...

docker的web管理平台docker.ui
docker.ui安装 docker run --name docker.ui \ -p 8999:8999 \ --restartalways \ -v /var/run/docker.sock:/var/run/docker.sock \ -d joinsunsoft/docker.ui参数说明: docker run:启动container–name:容器命名–restartalwaysÿ…...
20230822 Windows上使用find_package引入OpenCV报错
报错信息 打开Cmake项目时,find_package 报错: Found OpenCV Windows Pack but it has no binaries compatible with yourconfiguration.You should manually point CMake variable OpenCV_DIR to your build of OpenCVlibrary.原因 大概率原项目是在 …...

MySQL下载安装配置
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

3D WEB轻量化引擎HOOPS产品助力NAPA打造船舶设计软件平台
NAPA(Naval Architectural PAckage,船舶建筑包),来自芬兰的船舶设计软件供应商,致力于提供世界领先的船舶设计、安全及运营的解决方案和数据分析服务。NAPA拥有超过30年的船舶设计经验,年营业额超过2560万欧…...
lesson9: C++多线程
1.线程库 1.1 thread类的简单介绍 C11 中引入了对 线程的支持 了,使得 C 在 并行编程时 不需要依赖第三方库 而且在原子操作中还引入了 原子类 的概念。要使用标准库中的线程,必须包含 < thread > 头文件 函数名 功能 thread() 构造一个线程对象…...

安卓修改SwitchCompat色值
SwitchCompat控件色值跟系统设置的主题有关,但是主题效果不是能轻易就能改的,因为涉及到整个APP的样式。网上方案基本都是通过修改style文件来改变色值,经过多次尝试修改最终觉得单独修改控件色值比较好。 一、控件属性 //修改开关色值就是最…...
pytorch内存泄漏
问题描述: 内存泄漏积累过多最终会导致内存溢出,当内存占用过大,进程会被killed掉。 解决过程: 在代码的运行阶段输出内存占用量,观察在哪一块存在内存剧烈增加或者显存异常变化的情况。但是在这个过程中要分级确认…...
)
20230821-字符串相乘-给树命名(unordered_map)
字符串相乘 有两个非负整数字符串num1,num2,计算num1和num2所表达整数的乘积,结果以字符串形式存储。注意:不能通过强制转换方法解题。 示例1: 输入: "4", "3" 输出: "12" …...

[Go版]算法通关村第十二关黄金——字符串冲刺题
目录 题目:最长公共前缀解法1:纵向对比-循环内套循环写法复杂度:时间复杂度 O ( n ∗ m ) O(n*m) O(n∗m)、空间复杂度 O ( 1 ) O(1) O(1)Go代码 解法2:横向对比-两两对比(类似合并K个数组、合并K个链表)复…...

neovim为工作区添加本地clangd配置
1 背景 尝试使用neovim开发stm32,使用clangd作为LSP提供代码补全等功能。 2 思路 使用stm32cubeMX生成一个基于makefile的stm32工程。 使用bear或compiledb基于makefile生成compile_commands.json文件。 为clangd配置--query-driver选项,使其使用arm…...
信号处理--基于EEG脑电信号的眼睛状态的分析
本实验为生物信息学专题设计小项目。项目目的是通过提供的14导联EEG 脑电信号,实现对于人体睁眼和闭眼两个状态的数据分类分析。每个脑电信号的时长大约为117秒。 目录 加载相关的库函数 读取脑电信号数据并查看数据的属性 绘制脑电多通道连接矩阵 绘制两类数据…...
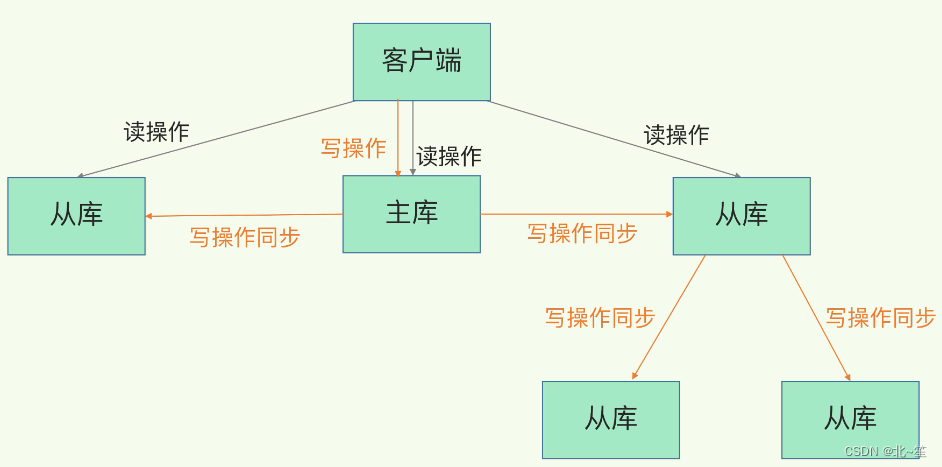
Redis高可用:主从复制详解
目录 1.什么是主从复制? 2.优势 3.主从复制的原理 4.全量复制和增量复制 4.1 全量复制 4.2 增量复制 5.相关问题总结 5.1 当主服务器不进行持久化时复制的安全性 5.2 为什么主从全量复制使用RDB而不使用AOF? 5.3 为什么还有无磁盘复制模式ÿ…...
 {})报错?)
[Flutter]有的时候调用setState(() {})报错?
先看FlutterSDK的原生类State中有一个变量mounted。 abstract class State<T extends StatefulWidget> with Diagnosticable {/// mounted的作用是,此State对象当前是否在树中。/// 在创建State对象之后,在调用initState之前,框架通过…...
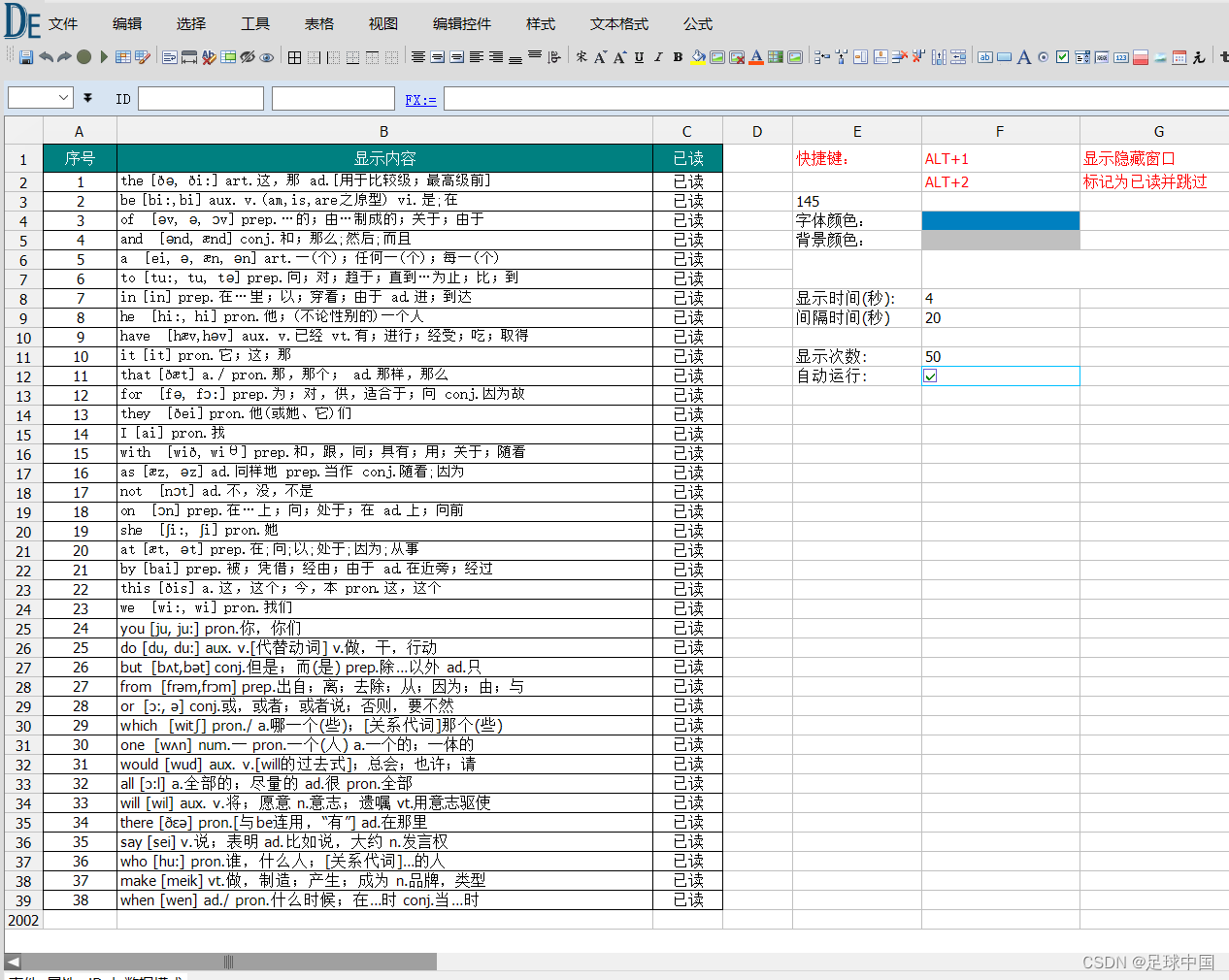
利用屏幕水印学习英语单词,无打扰英语单词学习
1、利用屏幕水印学习英语单词,不影响任何鼠标键盘操作,不影响工作 2、利用系统热键快速隐藏(ALT1键 隐藏与显示) 3、日积月累单词会有进步 4、软件下载地址: 免安装,代码未加密,安全的屏幕水印学习英语…...

开学必备物品清单!这几款优先考虑!
马上就要开学了,同学们也要准备一系列开学用品,方便我们的学习生活,那有哪些数码物品可以在开学前准备的呢,接下来给大家安利几款很不错很实用的数码好物! 推荐一:南卡00压开放式蓝牙耳机 南卡00压开放式…...

聊聊调制解调器
目录 1.什么是调制解调器 2.调制解调器的工作原理 3.调制解调器的作用 4.调制解调器未来发展 1.什么是调制解调器 调制解调器(Modem)是一种用于在数字设备和模拟设备之间进行数据传输的设备。调制解调器将数字数据转换为模拟信号进行传输,…...
Go语言入门指南:基础语法和常用特性(下)
上一节,我们了解Go语言特性以及第一个Go语言程序——Hello World,这一节就让我们更深入的了解一下Go语言的**基础语法**吧! 一、行分隔符 在 Go 程序中,一行代表一个语句结束。每个语句不需要像 C 家族中的其它语言一样以分号 ;…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...