知识蒸馏开山之作(部分解读)—Distilling the Knowledge in a Neural Network
1、蒸馏温度T
正常的模型学习到的就是在正确的类别上得到最大的概率,但是不正确的分类上也会得到一些概率尽管有时这些概率很小,但是在这些不正确的分类中,有一些分类的可能性仍然是其他类别的很多倍。但是对这些非正确类别的预测概率也能反应模型的泛化能力,例如,一辆宝马车的图片,只有很小的概率被误识别成垃圾车,但是被识别成垃圾车的概率还是比错误识别成胡萝卜的概率高很多倍。(例如一个车,猫,狗3分类的模型识别一张猫的图片,最后结果是:(cat,99%) ; (dog,0.95%);(car,0.05%)错误类别 dog 上的概率仍是错误类别 car 的概率的19倍 )
知识蒸馏
这里一个可行的办法是使用大模型生成的模型类别概率作为“soft targets”(使用蒸馏算法以后的概率,相对应的 head targets 就是正常的原始训练数据集)来训练小模型,由于 soft targets 包含了更多的信息熵,所以每个训练样本都提供给小模型更多的信息用来学习,这样小模型就只需要用更少的样本,及更高的学习率去训练了。
仍然是上面的错误分类概率的例子,在 MNIST 数据集上训练的一个大模型基本都能达到 99 % 以上的准确率,假如现在有一个数字 2 的图片输入到大模型中分类,在得到的结果是数字 3 的概率为 10e-6, 是数字 7 的概率为 10e-9,这就表示了相比于 7 ,3更接近于 2,这从侧面也可以表现数据之间的相关性,但是在迁移阶段,这样的概率在交叉熵损失函数(cross-entropy loss function)只有很小的影响,因为它们的概率都基本为0。 所以这里,本文提出了 “distillation” 的概念, 来软化上述的结果。
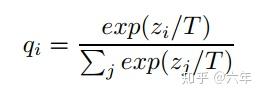
上面的公式就是蒸馏后的 softmax,其中 T 代表 temperature, 蒸馏的温度。那么 T 有什么作用呢?
假设现在有一个数组 x=[2,7,10] ,当T = 1,即为正常的 Softmax函数 输入上式中可得:
T = 1 ——> y = [0.00032,0.04741,0.95227]可以理解为上述的一个车,猫,狗3分类网络,输入一张猫的图片,预测为汽车的概率为0.00032, 预测为狗的概率为 0.04741, 预测为猫的概率为 0.95227。
下面再看一下改变 T 的值概率的输出:
T = 5 ——> y = [0.11532, 0.31348, 0.5712] T = 10 ——> y = [0.20516, 0.33825, 0.45659] T = 20 ——> y = [0.26484, 0.34006, 0.3951]
下面是在(-10,10)之间随机取多个点然后在 不同的 T 值下绘制的图像。
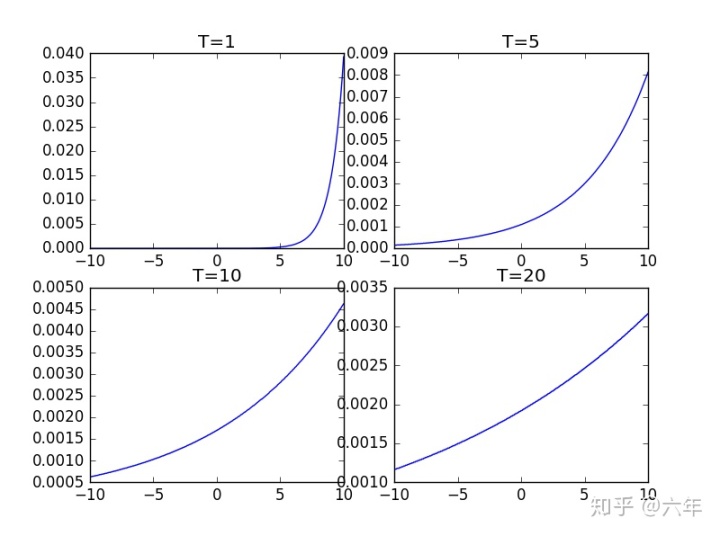
可以看到当 T = 1 是就是常规的 Softmax,而升温T,对softmax进行蒸馏,函数的图像会变得越来越平滑,这也是文中提高的 soft targets 的 soft 一词来源吧。
假设你是每次都是进行负重登山,虽然过程很辛苦,但是当有一天你取下负重,正常的登山的时候,你就会变得非常轻松,可以比别人登得高登得远。我们知道对于一个复杂网络来说往往能够得到很好的分类效果,错误的概率比正确的概率会小很多很多,但是对于一个小网络来说它是无法学成这个效果的。我们为了去帮助小网络进行学习,就在小网络的softmax加一个T参数,加上这个T参数以后错误分类再经过softmax以后输出会变大,同样的正确分类会变小。这就人为的加大了训练的难度,一旦将T重新设置为1,分类结果会非常的接近于大网络的分类效果。
最后将小模型在 soft targets 上训练得到的交叉熵损失函数,加上在真实带标签数据(hard targets)上训练得到的交叉熵损失函数乘以 1/T^2 加在一起作为最后总的损失函数。这里hard targets 上面乘以一个系数是因为 soft targets 生成过程中蒸馏后的 softmax 求导会有一个 1/T^2 的系数,为了保持两个 Loss 所产生的影响接近一样(各 50%)。
训练过程
假设这里选取的 T = 10;
Teacher 模型:
( a ) Softmax(T=10)的输出,生成“Soft targets”
Student 模型:
( a ) 对 Softmax(T = 10)的输出与Teacher 模型的Softmax(T = 10)的输出求 Loss1
( b ) 对 Softmax(T = 1)的输出与原始label 求 Loss2
( c ) Loss = Loss1 + (1/T^2)Loss2
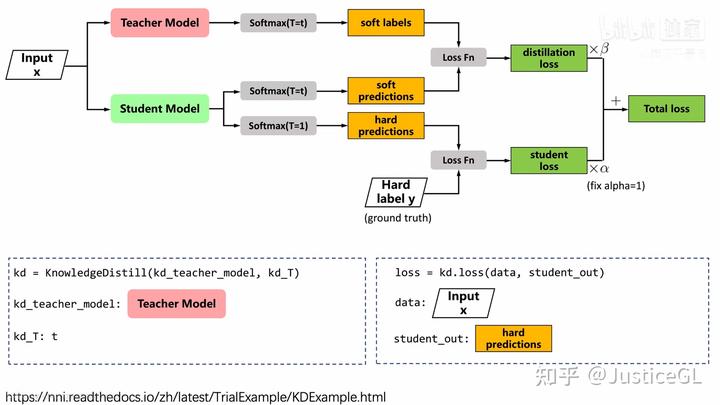
使用soft target会增加信息量,熵高
发现:T参数越大,soft target的分布越均匀。因此,我们可以:
- 首先用较大的T值来训练模型,这时候复杂的神经网络能够产生更均匀分布(更容易让小网络学习)的soft target;
- 之后小规模的神经网络用相同的T值来学习由大规模神经网络产生的soft target,接近这个soft target从而学习到数据的结构分布特征;
- 最后在实际应用中,将T值恢复到1,让类别概率偏向正确类别。
在大数据集上训练专家模型
Training ensembles of specialists on very big datasets
可以用无限大的数据集来使用教师网络训练学生网络
- 当数据集非常巨大以及模型非常复杂时,训练多个模型所需要的资源是难以想象的,因此作者提出了一种新的集成模型(ensemble)方法:
- 一个generalist model:使用全部数据训练。
- 多个specialist model(专家模型):对某些容易混淆的类别进行训练。
- specialist model的训练集中,一半是由训练集中包含某些特定类别的子集(special subset)组成,剩下一半是从剩余数据集中随机选取的。
- 这个ensemble的方法中,只有generalist model是使用完整数据集训练的,时间较长,而剩余的所有specialist model由于训练数据相对较少,且相互独立,可以并行训练,因此训练模型的总时间可以节约很多。
- specialist model由于只使用特定类别的数据进行训练,因此模型对别的类别的判断能力几乎为0,导致非常容易过拟合。
- 解决办法:当 specialist model 通过 hard targets 训练完成后,再使用由 generalist model 生成的 soft targets 进行微调。这样做是因为 soft targets 保留了一些对于其他类别数据的信息,因此模型可以在原来基础上学到更多知识,有效避免了过拟合。
实现流程:

此部分很有意思,但是不知道具体细节,需要再去看论文。
相关文章:
知识蒸馏开山之作(部分解读)—Distilling the Knowledge in a Neural Network
1、蒸馏温度T 正常的模型学习到的就是在正确的类别上得到最大的概率,但是不正确的分类上也会得到一些概率尽管有时这些概率很小,但是在这些不正确的分类中,有一些分类的可能性仍然是其他类别的很多倍。但是对这些非正确类别的预测概率也能反…...

centos 7 安装 docker-compose curl 设置代理
sudo curl -x “http://192.168.1.2:3128” 需要验证的代理 sudo curl -x “http://username:password192.168.1.2:3128” 1.下载 sudo curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/lo…...

3D姿态相关的损失函数
loss_mpjpe: 计算预测3D关键点与真值之间的平均距离误差(MPJPE)。 loss_n_mpjpe: 计算去除尺度后预测3D关键点误差(N-MPJPE),评估结构误差。 loss_velocity: 计算3D关键点的速度/移动的误差,评估运动的平滑程度。 loss_limb_var: 计算肢体长度的方差,引导生成合理的肢体长度…...
ChatGPT取代人类仍然是空想?有没有一种可能是AI在迷惑人类
ChatGPT自从去年发布以来,就掀起了这些大语言模型将如何颠覆一切的激烈讨论,从为学生写作文、输出SEO文章,甚至取代谷歌成为世界上最受欢迎的搜索引擎,影响领域无所不包,甚至可能取代编剧、小说家和音乐家等从事创意工…...

基于swing的旅游管理系统java jsp旅行团信息mysql源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 基于swing的旅游管理系统 系统有1权限:管…...
Windows wsl2支持systemd
背景 很多Linux发行版都是使用systemd来管理程序进程,但是在WSL中默认是用init来管理进程的。 为了符合长久的使用习惯,且省去不必要的学习成本,就在WSL的发行版(我这里安装的是Ubuntu20.04)中支持systemd࿰…...

NLP - 如何解决ModuleNotFoundError: No module named ‘jieba‘的问题
错误描述 在JUPYTER中,使用结巴分词,出错: ModuleNotFoundError: No module named jieba解决方案 在 Anaconda Prompt 中,执行以下指令(可以解决): pip install jieba -i https://pypi.tuna…...
Windows10上VS2022单步调试FFmpeg 4.2源码
之前在 https://blog.csdn.net/fengbingchun/article/details/103735560 介绍过通过VS2017单步调试FFmpeg源码的方法,这里在Windows10上通过VS2022单步调试FFmpeg 4.2的方法:基于GitHub上ShiftMediaProject/FFmpeg项目,下面对编译过程进行说明…...

【tkinter 专栏】菜单组件
文章目录 前言本章内容导图1. Menu 菜单组件Menu 组件的基本使用制作二级下拉菜单为菜单添加快捷键2. Treeview 树形菜单组件Treeview 组件的基本使用菜单项的获取与编辑前言 本专栏将参考《Python GUI 设计 tkinter 从入门到实践》书籍(吉林大学出版社 ISBN: 9787569275001)…...

【LeetCode-经典面试150题-day10】
目录 242.有效的字母异位词 49.字母异位词分组 202.快乐数 219.存在重复元素Ⅱ 383.赎金信 205.同构字符串 290.单词规律 242.有效的字母异位词 题意: 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和…...
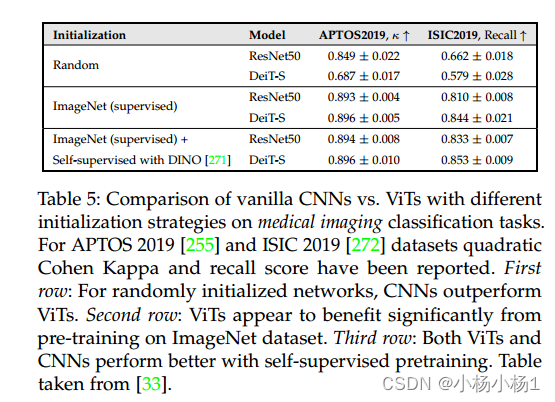
Transformer在医学影像中的应用综述-分类
文章目录 COVID-19 Diagnosis黑盒模型可解释的模型 肿瘤分类黑盒模型可解释模型 视网膜疾病分类小结 总体结构 COVID-19 Diagnosis 黑盒模型 Point-of-Care Transformer(POCFormer):利用Linformer将自注意的空间和时间复杂度从二次型降低到线性型。POCFormer有200…...

新服务器基本环境下载conda + docker + docker-compose + git
文章目录 Ubuntu 允许root用户登录 centos无所谓condadockerubuntucentos docker-compose官方下载docker-compose国内镜像 gitUbuntuCentos Ubuntu 允许root用户登录 centos无所谓 # 以普通用户登录系统,创建root用户的密码 sudo passwd root# SSH 放行 sudo sed -…...
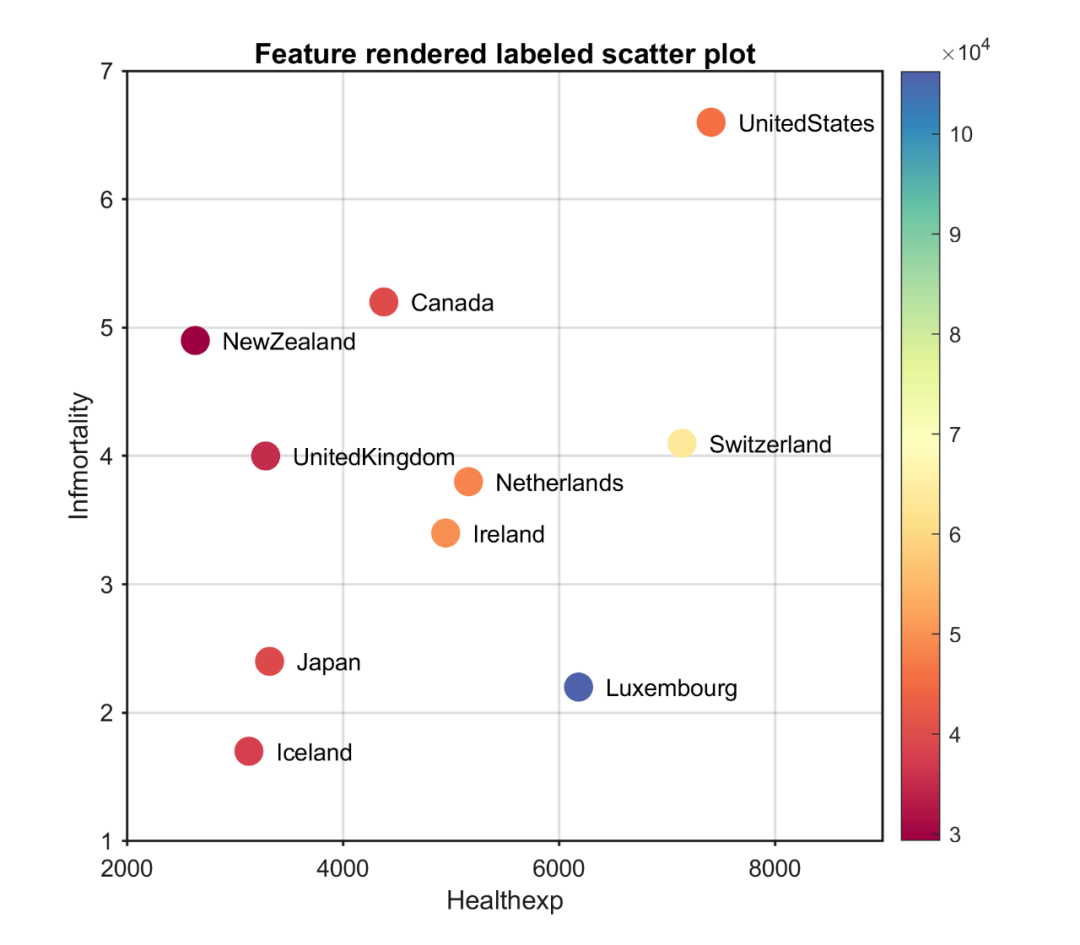
Matlab论文插图绘制模板第108期—特征渲染的标签散点图
在之前的文章中,分享了Matlab标签散点图的绘制模板: 进一步,再来分享一下特征渲染的标签散点图的绘制模板,以便再添加一个维度的信息。 先来看一下成品效果: 特别提示:本期内容『数据代码』已上传资源群中…...
设计模式之中介者模式(Mediator)的C++实现
1、中介者模式的提出 在软件组件开发过程中,如果存在多个对象,且这些对象之间存在的相互交互的情况不是一一对应的情况,这种功能组件间的对象引用关系比较复杂,耦合度较高。如果有一些新的需求变化,则不易扩展。中介者…...

css弹性布局的方式
概述 任何一个容器都可以定义为弹性布局容器,使用display:flex(display:inline-flex)开启弹性布局。 2个方向轴:水平主轴和垂直交叉轴 6个容器属性 1.flex-direction :主轴的方向 2.justify-content:子元素在主轴的对齐方式 …...

阿里云源 Python、npm、git、goproxy
阿里云源 Python、npm、git、goproxy 各种设置源的方式也都比较常见,但是根本记不住,每次都查感觉也不太好。 正好发现了个宝藏地址,看起来还挺全的,以后找源也可以先在这个地方翻翻,顺便就搞了几个放到一个脚本里边…...

微服务架构1.0
微服务架构 微服务架构是一种应用程序架构模式,将一个应用程序划分为一组小型、独立、自治的服务,每个服务专注于一个特定的业务功能。 每个微服务都可以独立开发、部署、扩展和维护,通过定义良好的接口和协议,它们可以相互通信…...

iOS开发Swift-基础部分
1.常量 let maxNum 10 //单个常量赋值 let maxNum 10, minNum 2 //多个常量赋值用逗号隔开2.变量 var x 0.0 //单个变量赋值 var x 0.0, y 0.1 //多个变量赋值用逗号隔开3.类型注解 系统可通过赋初始值进行自动推断。 var name&#…...

【LeetCode-经典面试150题-day11】
目录 128.最长连续序列 228.汇总区间 56.合并区间 57.插入区间 452.用最少数量的箭引爆气球 128.最长连续序列 题意: 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并…...
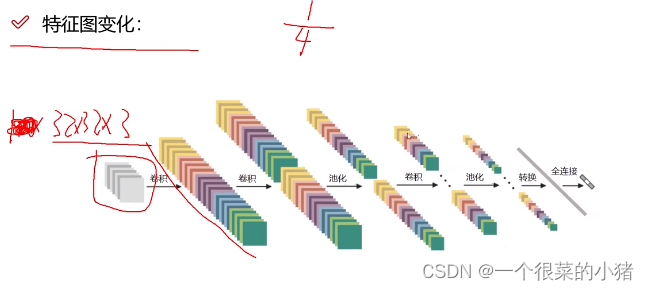
深度学习入门(三):卷积神经网络(CNN)
引入 给定一张图片,计算机需要模型判断图里的东西是什么? (car、truck、airplane、ship、horse) 一、卷积神经网络整体架构 CONV:卷积计算层,线性乘积求和RELU:激励层,激活函数P…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。
如何删除论文脚注横线的方法——视图-草稿-引用——显示备注——删除脚注分隔符-即可。 Word中脚注线不会删?这里有妙招!,教育,职业教育,好看视频...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

别让依赖毁了你的实验:记一次Vision Mamba复现中causal_conv1d与mamba-ssm的版本“打架”事件
Vision Mamba复现实战:破解依赖冲突的工程化解决方案在深度学习项目的复现过程中,依赖管理往往是最容易被忽视却又最常导致问题的环节。最近在复现Vision Mamba模型时,我遭遇了一场典型的Python依赖"战争"——causal_conv1d与mamba…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...

云厂商认证的价值变迁:从AWS到阿里云,哪个含金量更高?
当测试工程师开始关注云认证过去十年,软件测试领域的认证风向悄然生变。十年前,测试工程师手中的王牌是ISTQB(国际软件测试资格委员会)基础级或高级证书,这份全球通用的“测试护照”足以敲开大多数企业的大门。然而&am…...