机器学习基础09-审查分类算法(基于印第安糖尿病Pima Indians数据集)
算法审查是选择合适的机器学习算法的主要方法之一。审查算法前并
不知道哪个算法对问题最有效,必须设计一定的实验进行验证,以找到对问题最有效的算法。本章将学习通过
scikit-learn来审查六种机器学习的分类算法,通过比较算法评估矩阵的结果,选择合适的算法。
如何审查机器学习的分类算法?
审查算法前没有办法判断哪个算法对数据集最有效、能够生成最优模
型,必须通过一系列实验判断出哪些算法对问题最有效,然后再进一步来选择算法。这个过程被叫作算法审查。
在选择算法时,应该换一种思路,不是针对数据应该采用哪种算法,而是应该用数据来审查哪些算法。应该先猜测一下,什么算法会具有最好的效果。这是训练我们对数据敏感性的好方法。我非常建议大家对同一个数据集运用不同的算法,来审查算法的有效性,然后找到最有效的算法。
下面是审查算法的几点建议:
- 尝试多种代表性算法。
- 尝试多种机器学习的算法。
- 尝试多种模型。
接下来会介绍几种常见的分类算法。
在分类算法中,目前存在很多类型的分类器:线性分类器、贝叶斯分类器、基于距离的分类器等。接下来会介绍六种分类算法,先介绍两种线性算法:
- 逻辑回归。
- 线性判别分析。
再介绍四种非线性算法:
- K近邻。
- 贝叶斯分类器。
- 分类与回归树。
- 支持向量机。
下面继续使用Pima Indians数据集来审查算法,同时会采用10折交叉验证来评估算法的准确度。使用平均准确度来标准化算法的得分,以减少数据分布不均衡对算法的影响。
逻辑回归和线性判别分析都是假定输入的数据符合高斯分布。
逻辑回归
回归是一种极易理解的模型,相当于y=f (x),表明自变量x与因变
量y的关系。犹如医生治病时先望、闻、问、切,再判定病人是否生病或生了什么病,此处的“望、闻、问、切”就是获取自变量x,即特征数据;判断是否生病就相当于获取因变量y,即预测分类。
逻辑回归其实是一个分类算法而不是回归算法,通常是利用已知的自变量来预测一个离散型因变量的值(如二进制值0/1、是/否、真/假)。简单来说,它就是通过拟合一个逻辑函数(Logit Function)来预测一个事件发生的概率。所以它预测的是一个概率值,它的输出值应该为 0~1,因此非常适合处理二分类问题。在scikit-learn 中的实现类是LogisticRegression。代码如下:
数据集下载
import pandas as pdfrom sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#打印标签名称
print(data.columns)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7#特征选择
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
model = LogisticRegression()result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.776 (0.045)
线性判别分析
线性判别分析(Linear Discriminant Analysis,LDA),也叫作Fisher线性判别(Fisher Linear
Discriminant,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。
线性判别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
因此,它是一种有效的特征抽取方法。使用这种方法能够使投影后模式样本的类间散布矩阵最大,并且类内散布矩阵最小。就是说,它能够保证投影后模式样本在新的空间中有最小的类内距离和最大的类间距离,即模式在该空间中有最佳的可分离性。线性判别分析与主要成分分析一样,被广泛应用在数据降维中。
在 scikit-learn 中的实现类是LinearDiscriminantAnalysis。代码如下:
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysisfrom sklearn.model_selection import KFold, cross_val_score#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#打印标签名称
print(data.columns)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7#特征选择
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
model = LinearDiscriminantAnalysis()result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
Index(['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin','BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'],dtype='object')
算法评估结果:0.767 (0.048)
非线性算法
下面介绍四种非线性算法:K近邻(KNN)、贝叶斯分类器、分类与回归树和支持向量机算法。
K近邻算法
K 近邻算法是一种理论上比较成熟的方法,也是最简单的机器学习算法之一。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性
指标,避免了对象之间的匹配问题,距离一般使用欧氏距离或曼哈顿距离;同时,KNN通过依据k个对象中占优的类别进行决策,而不是通过单一的对象类别决策。这就是 KNN 算法的优势。在 scikit-learn 中的实现类是KNeighborsClassifier。代码如下:
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysisfrom sklearn.model_selection import KFold, cross_val_score
from sklearn.neighbors import KNeighborsClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7#特征选择
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
model = KNeighborsClassifier()result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.711 (0.051)
贝叶斯分类器
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其在所有类别上的后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化。
各个类别出现的概率,哪个最大就认为此待分类项属于哪个类别。贝叶斯分类器的特点如下:
- 贝叶斯分类器是一种基于统计的分类器,它根据给定样本属于某一个具体类的概率来对其进行分类。
- 贝叶斯分类器的理论基础是贝叶斯理论。
- 贝叶斯分类器的一种简单形式是朴素贝叶斯分类器,与随机森林、神经网络等分类器都具有可比的性能。
- 贝叶斯分类器是一种增量型的分类器。
在贝叶斯分类器中,对输入数据同样做了符合高斯分布的假设。在
scikit-learn中的实现类是GaussianNB。
代码如下:
import pandas as pdfrom sklearn.model_selection import KFold, cross_val_score
from sklearn.naive_bayes import GaussianNB#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7#特征选择
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
#高斯朴素贝叶斯
model = GaussianNB()result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.759 (0.039)
分类与回归树
分类与回归树的英文缩写是 CART,也属于一种决策树,树的构建基于基尼指数。
CART假设决策树是二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归二分每个特征,将输入空间(特征空间)划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
CART算法由以下两步组成。
- 树的生成:基于训练数据集生成决策树,生成的决策树要尽量大。
- 树的剪枝:用验证数据集对已生成的树进行剪枝,并选择最优子树,这时以损失函数最小作为剪枝的标准。
决策树的生成就是通过递归构建二叉决策树的过程,对回归树用平方误差最小化准则,或对分类树用基尼指数最小化准则,进行特征选择,生成二叉树。可以通过scikit-learn中的DecisionTreeClassifier类来构建一个CART模型。代码如下:
import pandas as pdfrom sklearn.model_selection import KFold, cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7#特征选择
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
#高斯朴素贝叶斯
model = DecisionTreeClassifier()result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.695 (0.051)
支持向量机
支持向量机是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM)是与相关的学习算法有关的监督学习模型,可以分析数据、识别模式,用于分类和回归分析。给定一组训练样本,每条记录标记所属类别,使用支持向量机算法进行训练,并建立一个模型,对新数据实例进行分类,使其成为非概率二元线性分类。
一个SVM模型的例子是,如在空间中的不同点的映射,使得所属不同类别的实例是由一个差距明显且尽可能宽的划分表示。新的实例则映射到相同的空间中,并基于它们落在相同间隙上预测其属于同一个类别。现在SVM也被扩展到处理多分类问题,可以通过scikit-learn中的SVC类来构建一个SVM模型。
代码如下:
import pandas as pdfrom sklearn.model_selection import KFold, cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7#特征选择
kfold = KFold(n_splits=num_folds, random_state=seed, shuffle=True)
#高斯朴素贝叶斯
model = SVC()result = cross_val_score(model, X, Y, cv=kfold)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))算法评估结果:0.760 (0.035)
介绍了六种分类算法,以及它们在 scikit-learn 中的实现。算法主
要分为:线性算法、距离算法、树算法、统计算法等。每一种算法都有不同的适用场景,对数据集有不同的要求。
本次利用 Pima Indians 数据集对这几种算法进行了审查,这是选择合适的算法模型的有效方法。
6个算法评估表如下:
| 算法名称 | 算法评估结果 |
|---|---|
| 逻辑回归LogisticRegression | 算法评估结果:0.776 (0.045) |
| 线性判别分析 LinearDiscriminantAnalysis | 算法评估结果:0.767 (0.048) |
| K近邻算法 KNeighborsClassifier | 算法评估结果:0.711 (0.051) |
| 贝叶斯分类器GaussianNB | 算法评估结果:0.759 (0.039) |
| 分类与回归树DecisionTreeClassifier | 算法评估结果:0.695 (0.051) |
| 支持向量机SVC() | 算法评估结果:0.760 (0.035) |
相关文章:
)
机器学习基础09-审查分类算法(基于印第安糖尿病Pima Indians数据集)
算法审查是选择合适的机器学习算法的主要方法之一。审查算法前并 不知道哪个算法对问题最有效,必须设计一定的实验进行验证,以找到对问题最有效的算法。本章将学习通过 scikit-learn来审查六种机器学习的分类算法,通过比较算法评估矩阵的结果…...

C++ sort与优先队列排序的区别
int main() {vector<int> data{3, 1, 2};cout << "从小到大排序" << endl;sort(data.begin(), data.end(), std::less<int>());printContainer(data);auto cmp1 [](int x, int y) { return x < y; };sort(data.begin(), data.end(), cmp…...
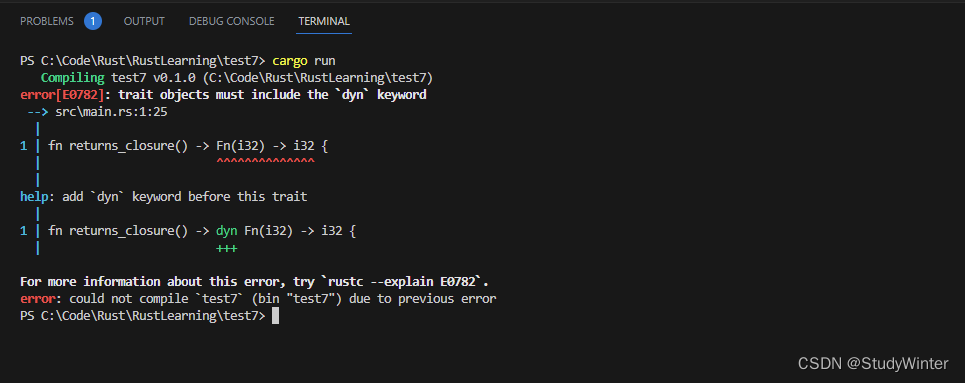
【Rust】Rust学习 第十九章高级特征
现在我们已经学习了 Rust 编程语言中最常用的部分。在第二十章开始另一个新项目之前,让我们聊聊一些总有一天你会遇上的部分内容。你可以将本章作为不经意间遇到未知的内容时的参考。本章将要学习的功能在一些非常特定的场景下很有用处。虽然很少会碰到它们…...

C++ 纯虚函数和虚函数的区别
在 C 中,虚函数(Virtual Function)和纯虚函数(Pure Virtual Function)都是用于实现多态性的机制,但它们之间有一些关键的不同。 虚函数(Virtual Function) 定义:在基类…...

Go中的有限状态机FSM的详细介绍 _
1、FSM简介 1.1 有限状态机的定义 有限状态机(Finite State Machine,FSM)是一种数学模型,用于描述系统在不同状态下的行为和转移条件。 状态机有三个组成部分:状态(State)、事件(…...
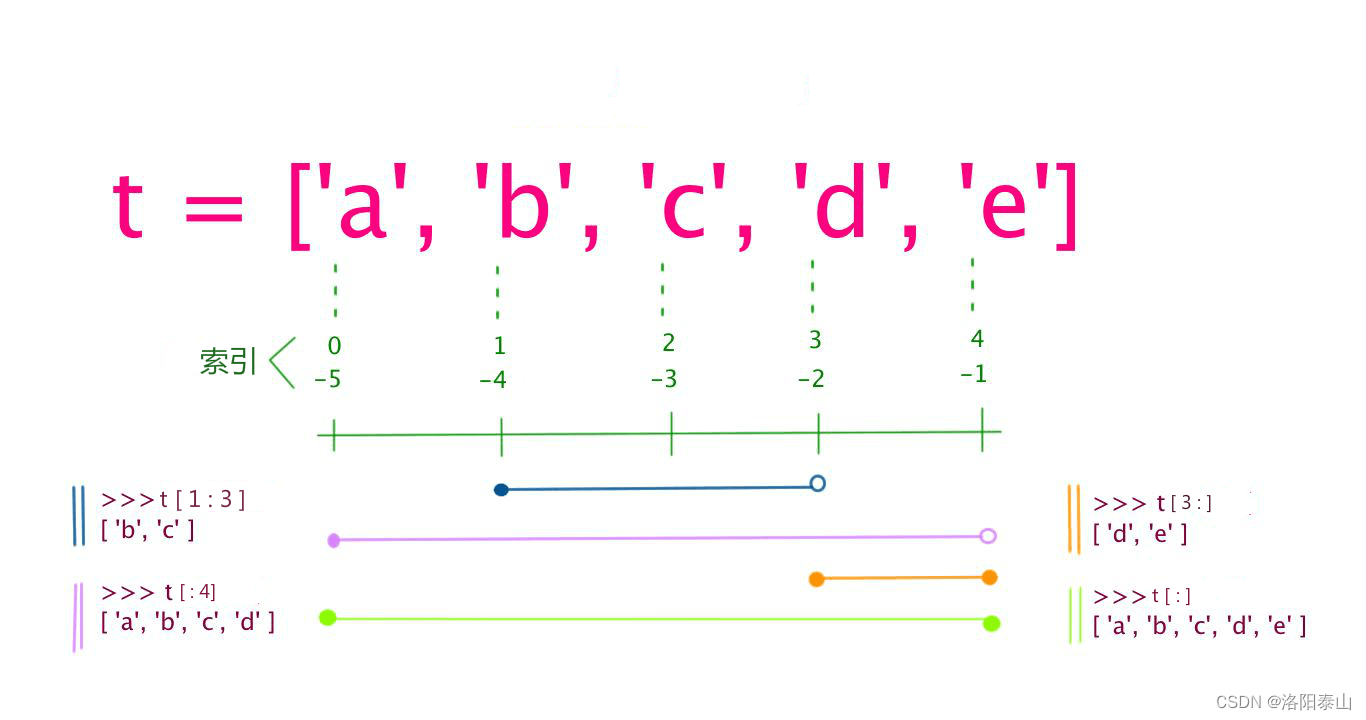
Python入门教程 | Python3 基本数据类型
赋值 Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。 在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。 等号(ÿ…...

STM32移植u8g2玩转oled 用软件iic实现驱动oled
移植u8g2到stm int fputc(int ch,FILE *f) {ITM_SendChar(ch);return (ch); }void delay_us(uint32_t time) {uint32_t i8*time;while(i--); }uint8_t STM32_gpio_and_delay(u8x8_t *u8x8, uint8_t msg, uint8_t arg_int, void *arg_ptr) {//printf("%s:msg %d,arg_int …...

C++ 学习系列 -- string 实现
string是C标准库的重要部分,主要用于字符串处理。这里我们自己实现一个简单版本的 string. 一 思路 string 类中应该包含如下: 1. 类成员变量:char* m_data,利用 char* 指针存放字符串 2. 成员函数: 2.1 size(…...

C语言小练习(三)
🌞 “也许你感觉自己与周遭格格不入,但正是那些你一人度过的时光,让你变得越来越有意思,等有天别人终于注意到你的时候,他们就会发现一个比他们想象中更酷的人。”-《生活大爆炸》 Day03 📝 一.选择题&…...

2023 js逆向爬虫 有道翻译 代码
前置条件:nodejs环境、安装 crypto 和 python3环境 js.js文件: const crypto require("crypto")function decode(resp_data) {g_o ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHlg_n ydsecre…...
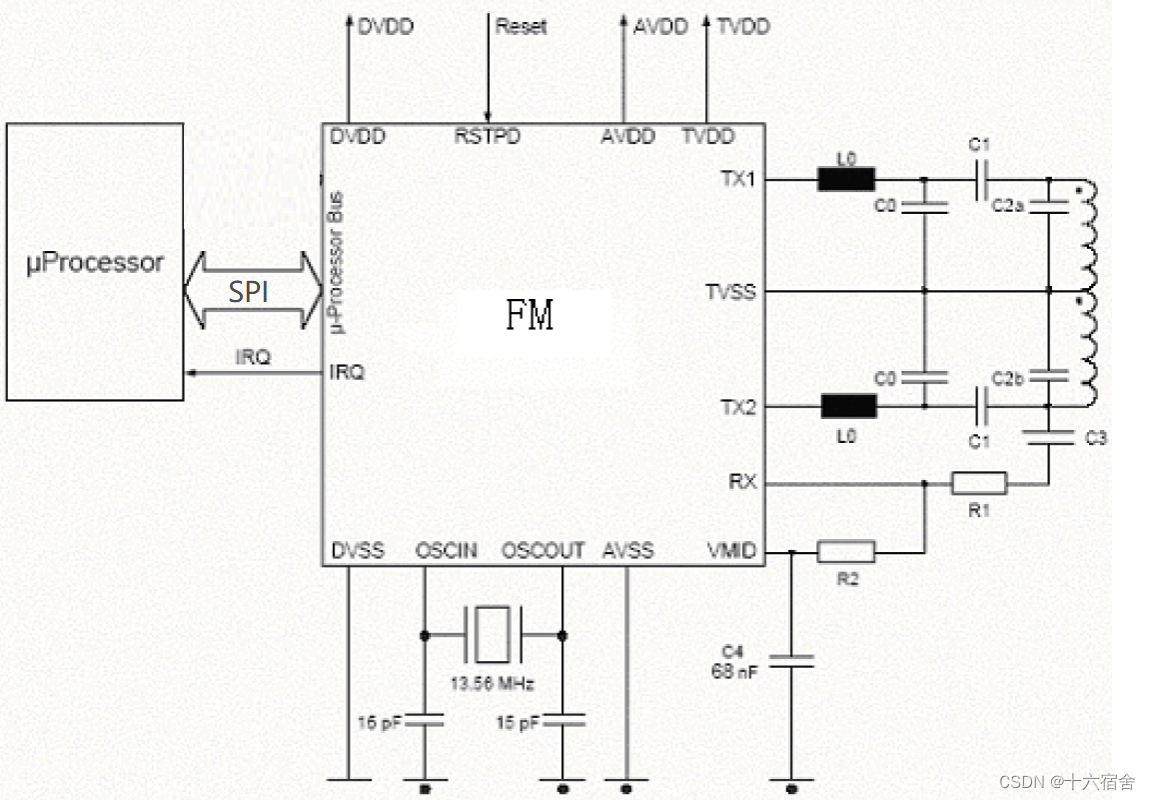
【物联网无线通信技术】NFC从理论到实践(FM17XX)
NFC,全称是Near Field Communication,即“近场通信”,也叫“近距离无线通信”。NFC诞生于2004年,是基于RFID非接触式射频识别技术演变而来,由当时的龙头企业NXP(原飞利浦半导体)、诺基亚以及索尼联合发起。NFC采用13.5…...
Python爬虫猿人学逆向系列——第六题
题目:采集全部5页的彩票数据,计算全部中奖的总金额(包含一、二、三等奖) 地址:https://match.yuanrenxue.cn/match/6 本题比较简单,只是容易踩坑。话不多说请看分析。 两个参数,一个m一个f&…...
idea使用tomcat
1. 建立javaweb项目 2. /WEB-INF/web.xml项目配置文件 如果javaweb项目 先建立项目,然后在项目上添加框架支持,选择javaee 3. 项目结构 4.执行测试:...

搭建Tomcat HTTP服务:在Windows上实现外网远程访问的详细配置与设置教程
文章目录 前言1.本地Tomcat网页搭建1.1 Tomcat安装1.2 配置环境变量1.3 环境配置1.4 Tomcat运行测试1.5 Cpolar安装和注册 2.本地网页发布2.1.Cpolar云端设置2.2 Cpolar本地设置 3.公网访问测试4.结语 前言 Tomcat作为一个轻量级的服务器,不仅名字很有趣࿰…...

Java学习笔记——继承(包括this,super的使用总结)
继承: 使用情景:当类与类之间,存在相同(共性)的内容,并满足子类是父类的一种,就可以考虑使用继承,来优化代码 Java中提供一个关键字extends,用这个关键字,我…...

Android 获取应用sha1和sha256
在 Android 应用开发中,SHA-1(Secure Hash Algorithm 1)值是一种哈希算法,常用于生成应用的数字签名。这个数字签名用于验证应用的身份,并确保应用在发布到设备上时没有被篡改。 以下是生成 Android 应用的 SHA-1 值的…...
的区别)
c# 方法参数修饰符(out、ref、in)的区别
在C#中,ref、out和in是三种方法参数修饰符,它们在传递参数的方式和作用上有所不同。 ref修饰符: 传递方式:使用ref修饰符的参数可以是输入输出参数,即在方法调用前后都可以对其进行修改。 作用:通过ref修…...
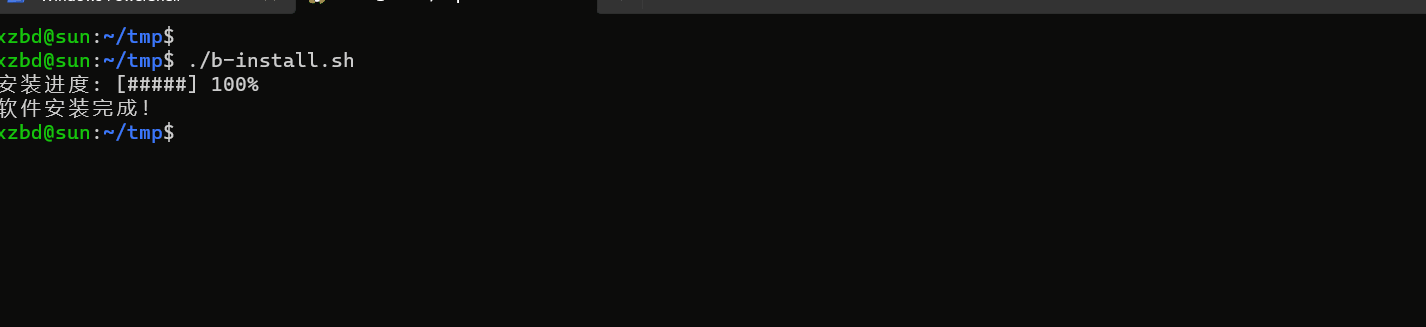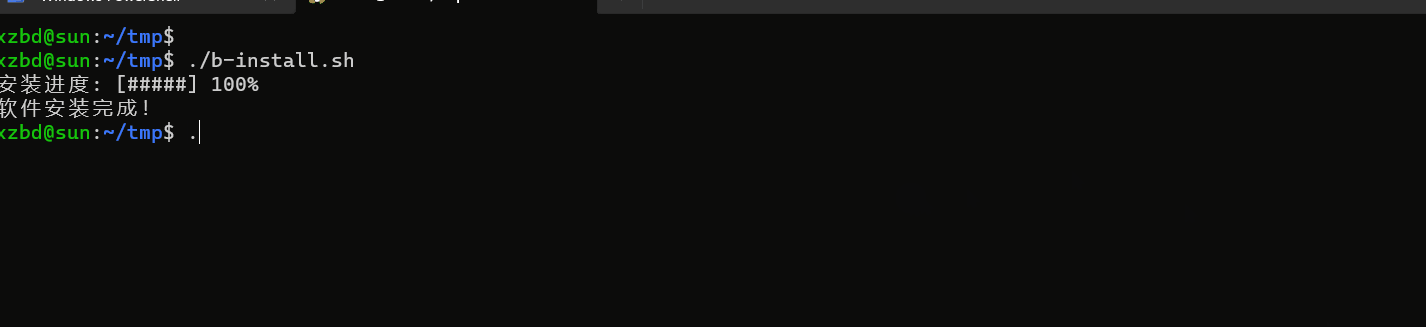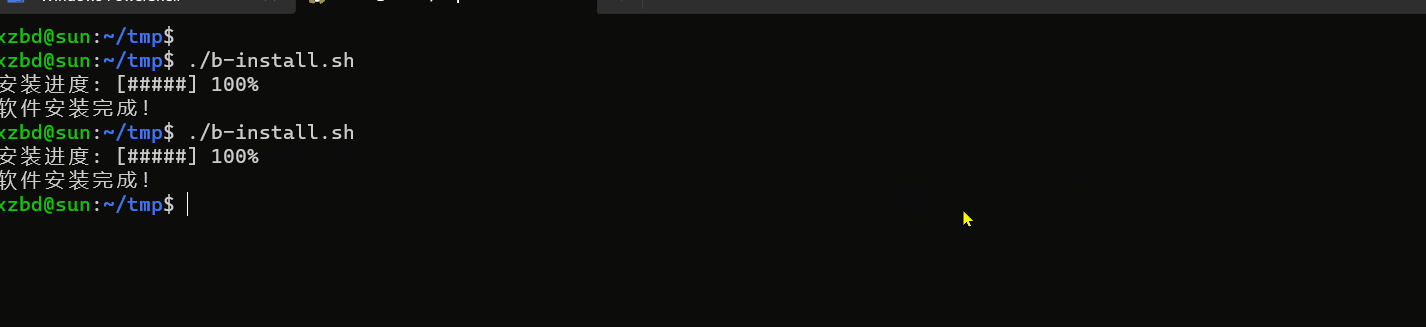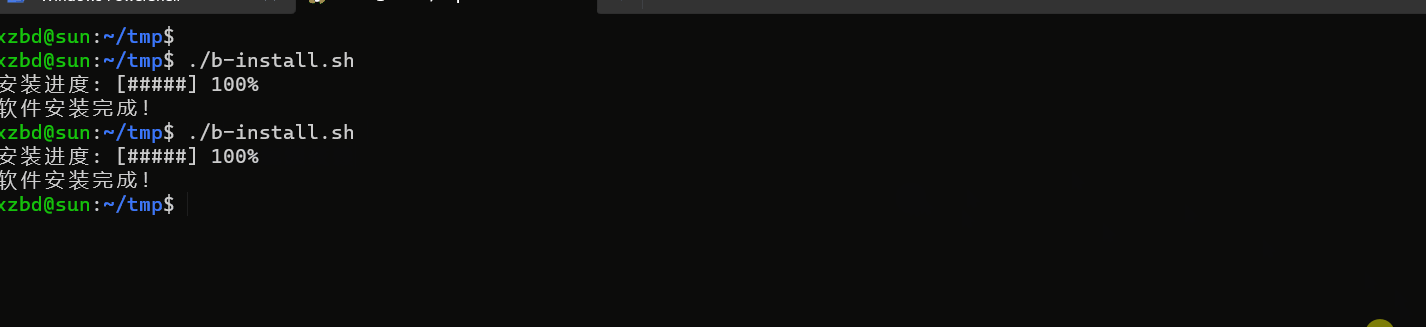
shell 编写一个带有进度条的程序安装脚本
需求 使用 shell 写一个 软件安装脚本,带有进度条 示例 #!/bin/bash# 模拟软件安装的步骤列表 steps("解压文件" "安装依赖" "配置设置" "复制文件" "")# 计算总步骤数 total_steps${#steps[]}# 安装进度的初…...

服务器数据恢复-AIX PV完整镜像方法以及误删LV的数据恢复方案
AIX中的PV相当于物理磁盘(针对于存储来说,PV相当于存储映射过来的卷;针对操作系统来说,PV相当于物理硬盘),若干个PV组成一个VG,AIX可以将容量不同的存储空间组合起来统一分配。AIX把同一个VG的所…...

首席执行官Adam Selipsky解读“亚马逊云科技的技术产品差异化”
迄今为止,亚马逊云科技已经参与了21世纪几乎所有的大型计算变革,亚马逊云科技是一个很传奇的故事,它始于大约20年前的一项实验,当时亚马逊试图出售其过剩的服务器。人们确实对此表示怀疑。为什么在线书店试图销售云服务࿱…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...
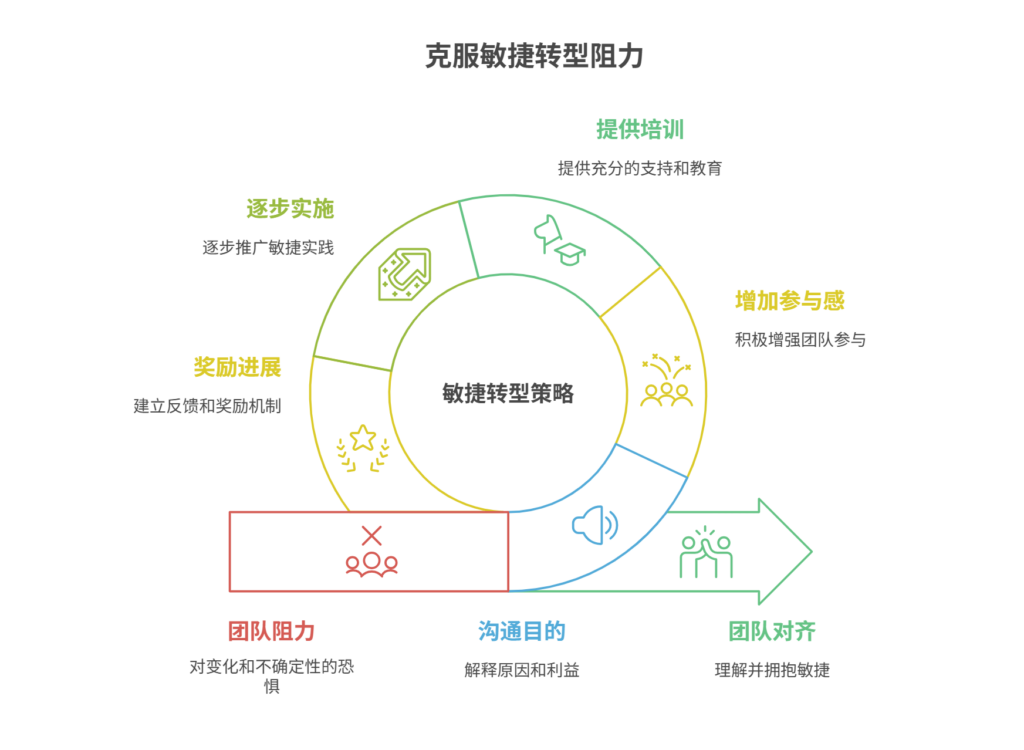
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...