基础论文学习(4)——CLIP
《Learning Transferable Visual Models From Natural Language Supervision》
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系,预训练模型在未知数据集上实现zero-shot。
1. CLIP模型架构
1.1 文本-图像的预训练方法
CLIP的模型结构其实非常简单:包括两个部分,即文本编码器(Text Encoder)和图像编码器(Image Encoder)。Text Encoder选择的是Text Transformer模型;Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT。
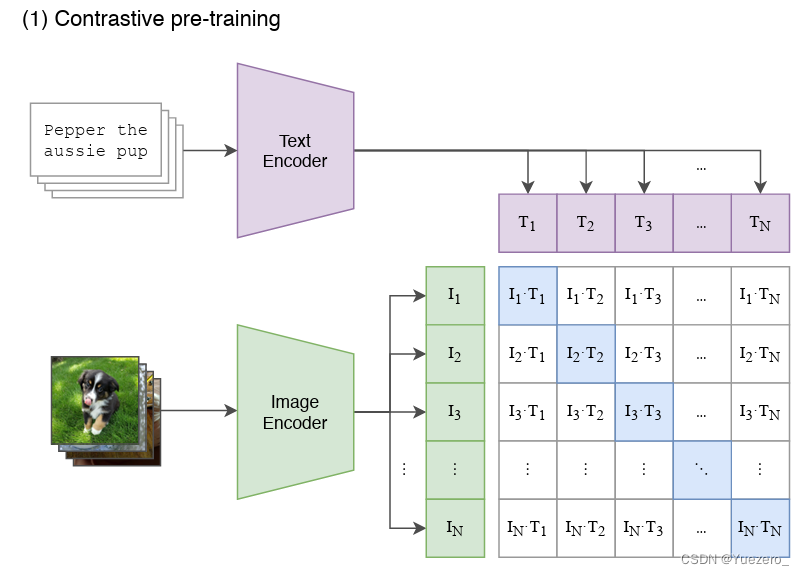
CLIP在文本-图像对数据集上的对比学习训练过程如下:
- 对于一个包含N个<文本-图像>对的训练batch,使用Text Encoder和Image Encoder提取N个文本特征和N个图像特征。
- 这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的 N 2 − N N^2-N N2−N个文本-图像对为负样本。
- 将N个文本特征和N个图像特征两两组合,CLIP模型会预测出 N 2 N^2 N2 个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。
- 那么CLIP的训练目标就是最大化N个正样本的相似度,同时最小化 N 2 − N N^2-N N2−N个负样本的相似度,即最大化对角线中蓝色的数值,最小化其它非对角线的数值: m i n ( ∑ i = 1 N ∑ j = 1 N ( I i ⋅ T j ) i ! = j − ∑ i = 1 ( I i ⋅ T j ) ) min(\sum_{i=1}^{N}\sum_{j=1}^{N}(I_i \cdot T_j)_{i!=j}-\sum_{i=1}(I_i \cdot T_j)) min(∑i=1N∑j=1N(Ii⋅Tj)i!=j−∑i=1(Ii⋅Tj))
对应的伪代码实现如下所示:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
通过大批量的文本-图像预训练后, CLIP可以先通过编码,计算输入的文本和图像的余弦相似度,来判断数据对的匹配程度。

1.2 迁移预训练模型实现zero-shot
可以看到训练后的CLIP其实是两个模型:视觉模型+文本模型,与CV中常用的先预训练然后微调不同,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。
经过在文本-图像对数据上训练的模型,有能力判断给定的文本和图像是否匹配。这时CLIP已经完成了其全部训练过程,完全不需要Imagenet或其它数据集中的图像-类别标签,即可以直接做图像分类了。
这也是CLIP这个模型最大的亮点:zero-shot图像分类。这是如何实现的呢,其实也非常简单:
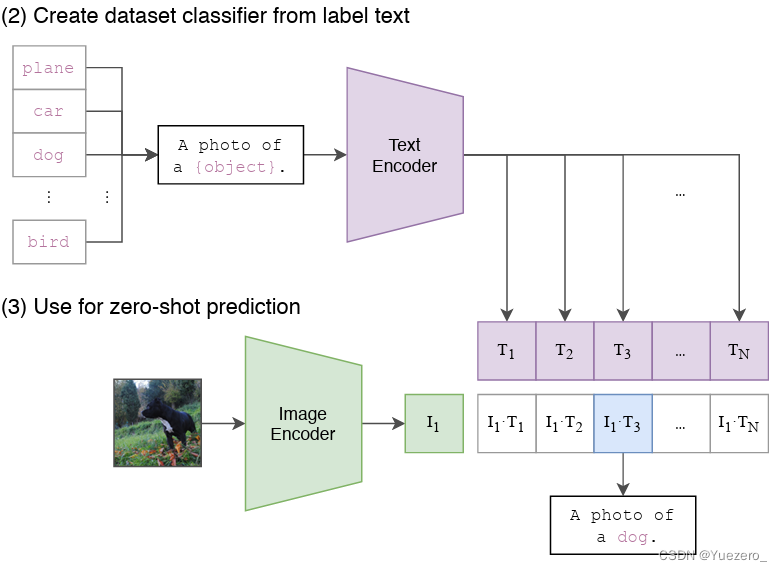
- 根据任务的分类标签构建每个类别的描述文本(以Imagenet有N=1000类为例):
A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;
# 首先生成每个类别的文本描述(例如6个类别文本)
labels = ["dog", "cat", "bird", "person", "mushroom", "cup"]
text_descriptions = [f"A photo of a {label}" for label in labels]
text_tokens = clip.tokenize(text_descriptions).cuda()# 提取文本特征
with torch.no_grad():text_features = model.encode_text(text_tokens).float()text_features /= text_features.norm(dim=-1, keepdim=True)
- 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
# 读取待预测图像
original_images = []
images = []
texts = []for label in labels:image_file = os.path.join("images", label+".jpg")name = os.path.basename(image_file).split('.')[0]image = Image.open(image_file).convert("RGB")original_images.append(image)images.append(preprocess(image))texts.append(name)image_input = torch.tensor(np.stack(images)).cuda()# 提取图像特征
with torch.no_grad():image_features = model.encode_image(image_input).float()image_features /= image_features.norm(dim=-1, keepdim=True)# 计算余弦相似度(未缩放)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T# 对得到的余弦相似度计算softmax,得到每个预测类别的概率值
logit_scale = np.exp(model.logit_scale.data.item())
text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
2. 实验分析
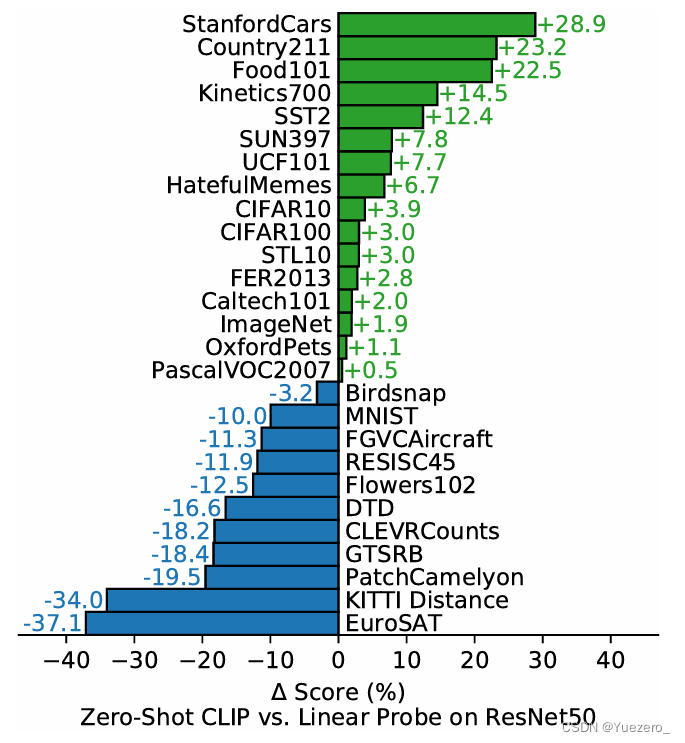
我们从左图中看到,CLIP在16个数据集上可以超过全监督的ResNet50;但是在一些较为特殊的数据集上,CLIP表现差于ResNet50,例如MNIST等。这个原因来自于MNIST中手写体数字图片,在其搜集的4亿文本-图像对中很少出现,导致CLIP没有学习到这么特殊的图像/文本。而ResNet50采取全监督的训练方式,将数据集的特殊性都学习到了,因此分类准确率较高。(个人猜测: 如果Open AI收集一些相似于特殊数据集中的图像,加入其文本-图像对数据集中,也可以在这些特殊数据集上提升效果)
同时,我们从右图中看到,CLIP和全监督训练的ResNet101在ImageNet验证集上都能达到76.2%的准确率,而在下面一些分布漂移(数据集中不同类别图像的数量分布不均衡)的数据集上,CLIP更是远超全监督训练的ResNet101。最明显的是,在ImageNet-A数据集上,CLIP可以达到77.1%,而ResNet只有2.7%(基本属于瞎猜)。这证明了使用文本-图像做预训练的CLIP具备更强的鲁棒性。
除了图像分类任务,CLIP还实现了文本-图像的预训练。这也为其后续做文本-图像生成及更多下游任务做了铺垫。
2.1 局限性
论文的最后也对CLIP的局限性做了讨论,这里简单总结其中比较重要的几点:
- CLIP的zero-shot性能虽然和有监督的ResNet50相当,但是还不是SOTA,作者估计要达到SOTA的效果,CLIP还需要增加1000x的计算量,这是难以想象的;
- CLIP的zero-shot在某些数据集上表现较差,如细粒度分类,抽象任务等;
- CLIP在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题,即如果测试数据集的分布和训练集相差较大,CLIP会表现较差;
- CLIP并没有解决深度学习的数据效率低下难题,训练CLIP需要大量的数据;
2.2 总结
CLIP 的最大贡献在于打破了固定种类标签的桎梏,让下游任务的推理变得更灵活,并且在 zero-shot 的情况下,它的效果很不错。
-
有监督预训练模型仍需微调,无法实现zero-shot:在计算机视觉领域,最常采用的迁移学习方式就是先在一个
较大规模的数据集如ImageNet上预训练,然后在具体的下游任务上再进行微调。这里的预训练是基于有监督训练的,需要大量的数据标注,因此成本较高。 -
很多自监督预训练模型也需要下游微调:近年来,出现了一些基于自监督的方法,这包括
基于对比学习的方法如MoCo和SimCLR、基于图像掩码的方法如MAE和BeiT,自监督方法的好处是不再需要标注,但是无论是有监督还是自监督方法,它们在迁移到下游任务时,还是需要进行有监督微调,而无法实现zero-shot。 -
CLIP解决了自监督预训练模型需要下游微调的现状!
在这篇工作发表之后,涌现出了一大批在其他领域的应用,包括物体检测、物体分割、图像生成、视频动作检索等。在创新度、有效性、影响力方面都非常出色。如扩展到文本-视频,VideoCLIP就是将CLIP应用在视频领域来实现一些zero-shot视频理解任务。
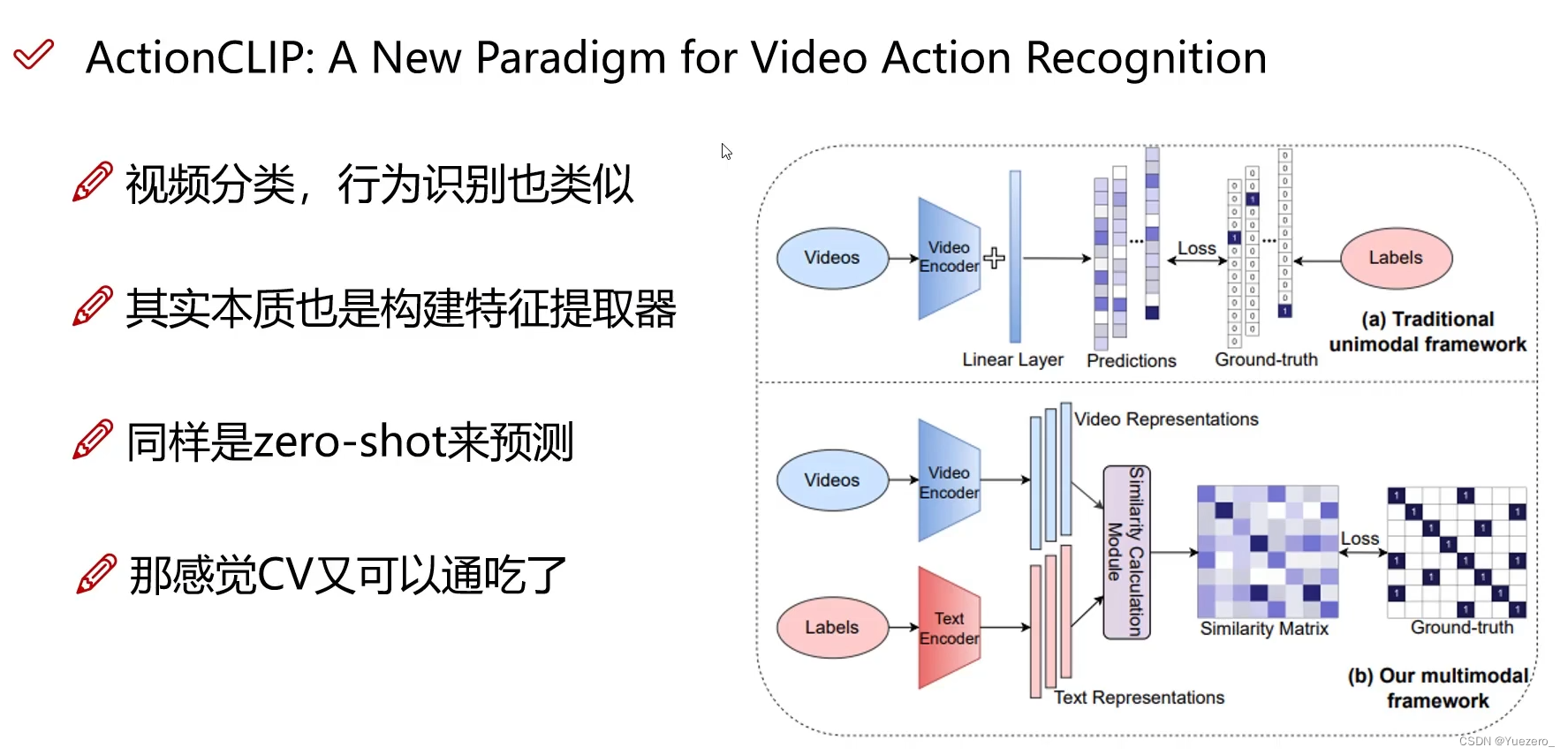
Actionclip: A new paradigm for video action recognition
CLIP4Caption: CLIP for Video Caption
Clip4clip: An empirical study of clip for end to end video clip retrieval
Prompting Visual-Language Models for Efficient Video Understanding
3. CLIP视频域知识迁移中的时间建模
<图像-文本>预训练模型CLIP、BEiT、CoCa等已经取得不错的效果:
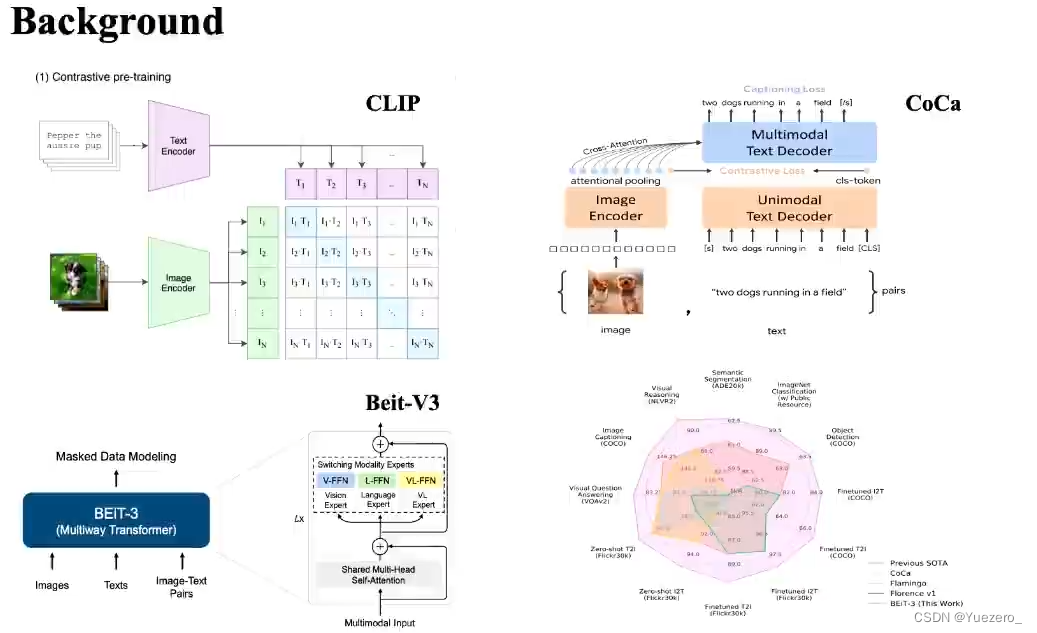
但<视频-文本>预训练模型面临两大挑战:1.视频-文本对数据难以收集。2.计算资源消耗大。
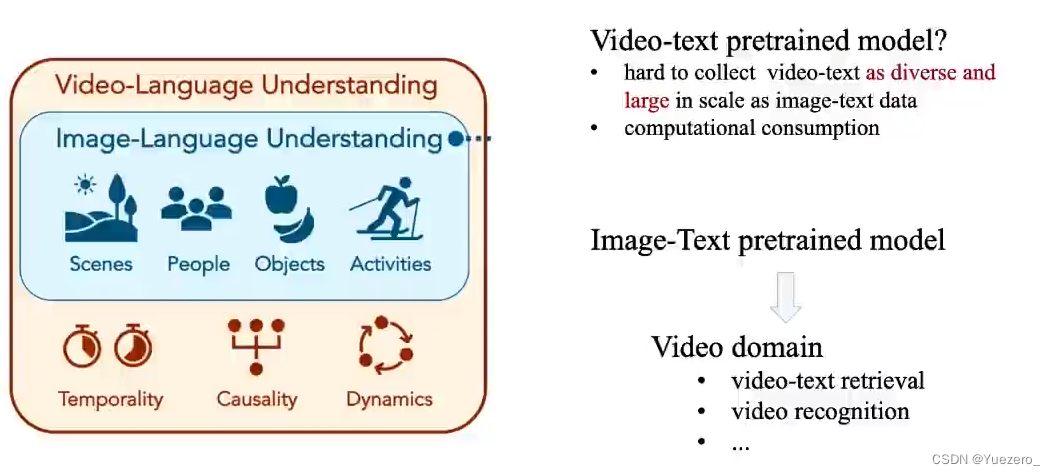
解决办法:将 image-text 模型迁移到 video-text 模型
关键:如何做好时序建模!
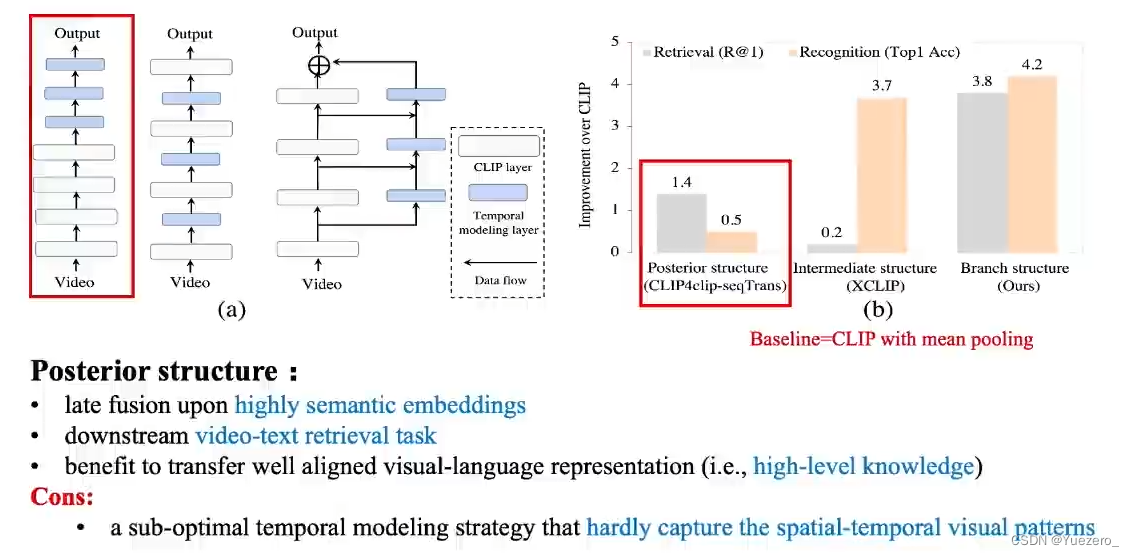
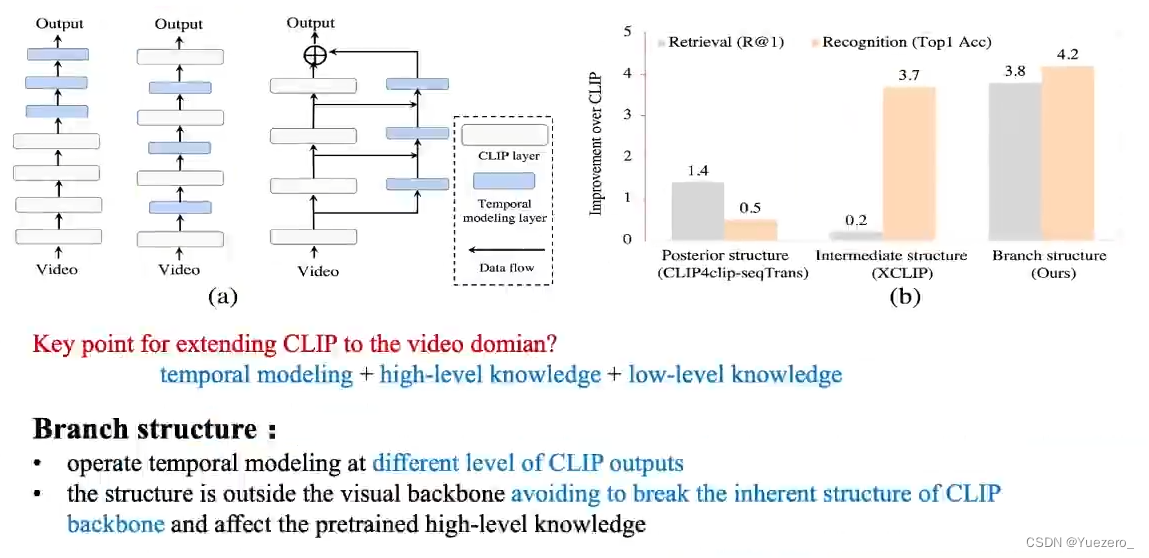
Psterior structure:如CLIP4clip,先做embedding,后时序建模。
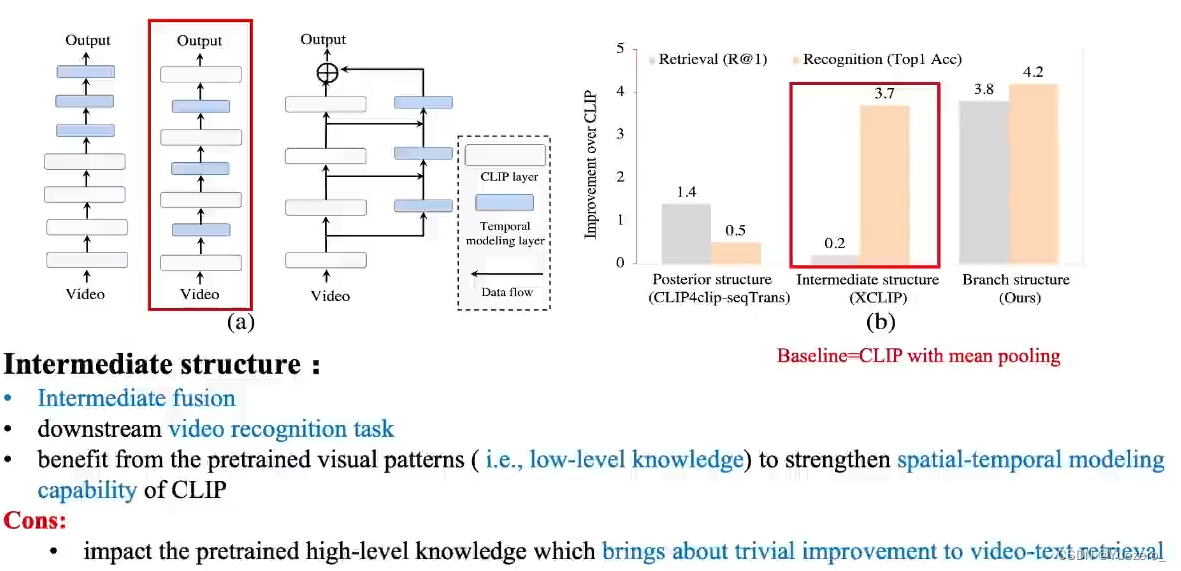
Intermediate structure:如XCLIP,一遍embedding,一遍时序建模。
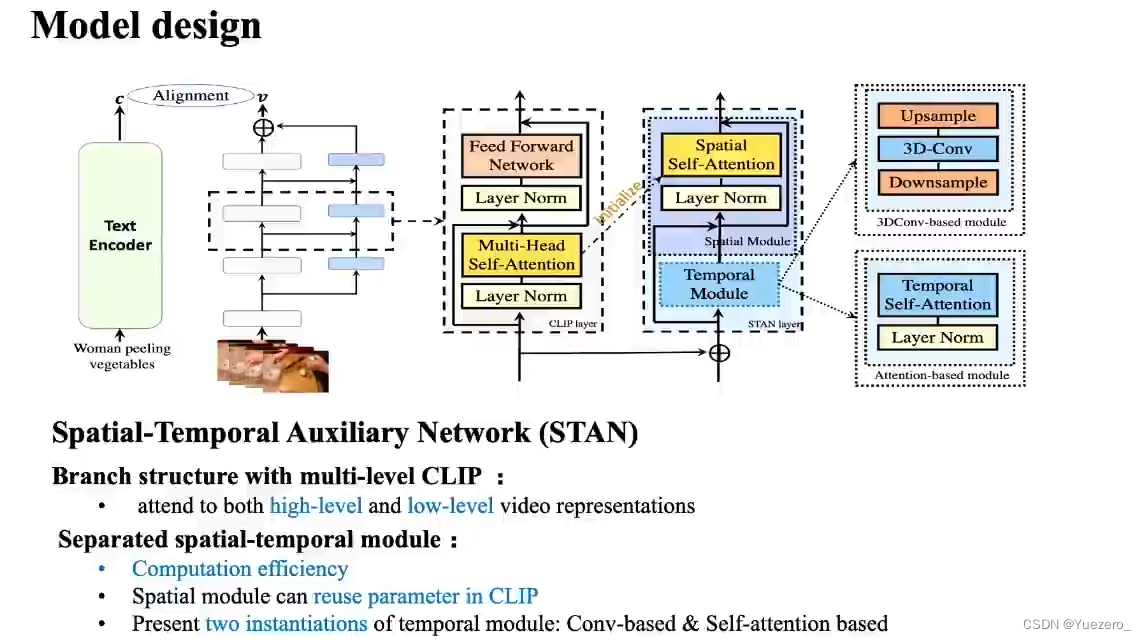
STAN:embedding的同时,在旁支结构进行时序建模
相关文章:
基础论文学习(4)——CLIP
《Learning Transferable Visual Models From Natural Language Supervision》 CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moc…...

SpringBoot利用ConstraintValidator实现自定义注解校验
一、前言 ConstraintValidator是Java Bean Validation(JSR-303)规范中的一个接口,用于实现自定义校验注解的校验逻辑。ConstraintValidator定义了两个泛型参数,分别是注解类型和被校验的值类型。在实现ConstraintValidator接口时&…...
十、pikachu之php反序列化
文章目录 1、php反序列化概述2、实战3、关于Magic function4、__wakeup()和destruct() 1、php反序列化概述 在理解这个漏洞前,首先搞清楚php中serialize(),unserialize()这两个函数。 (1)序列化serialize():就是把一个…...
PHP“牵手”拼多多商品详情数据获取方法,拼多多API接口批量获取拼多多商品详情数据说明
拼多多商品详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取拼多多商品的详细信息,包括商品的标题、描述、图片等信息。在拼多多电商平台的开发中,拼多多详情接口 API 是非常常用的 API,因此本文将详细介绍拼多多…...

前端面试:【Redux】状态管理的精髓
嘿,亲爱的Redux探险家!在前端开发的旅程中,有一个强大的状态管理工具,那就是Redux。Redux是一个状态容器,它以一种可预测的方式管理应用的状态,通过Store、Action、Reducer、中间件和异步处理等核心概念&am…...

element-ui中的el-table的summary-method(合计)的使用
场景图片: 图片1: 图片2: 一:使用element中的方法 优点: 直接使用summary-method方法,直接,方便 缺点: 只是在表格下面添加了一行,如果想有多行就不行了 1:h…...

“深入探索JVM:解析Java虚拟机的工作原理与性能优化“
标题:深入探索JVM:解析Java虚拟机的工作原理与性能优化 摘要:本文将深入探讨Java虚拟机(JVM)的工作原理和性能优化。我们将首先介绍JVM的基本组成和工作流程,然后重点讨论JVM内存管理、垃圾回收算法以及性…...
【后端】Core框架版本和发布时间以及.net 6.0启动文件的结构
2023年,第35周,第1篇文章。给自己一个目标,然后坚持总会有收货,不信你试试! .NET Core 是一个跨平台的开源框架,用于构建现代化的应用程序。它在不同版本中有一些重要的区别和发布时间 目录 一、Core版本和…...
Linux 定时任务 crontab 用法学习整理
一、linux版本 lsb_release -a 二、crontab 用法学习 2.1,crontab 简介 linux中crontab命令用于设置周期性被执行的指令,该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行。cron 系统调度进程。…...

看板之道:如何利用Kanban优化您的项目流程
引言 在项目管理的世界中,如何确保任务的流畅进行并及时交付是每个团队都面临的挑战。Kanban,作为一种敏捷项目管理方法,为此提供了一个答案。它不仅提供了一种可视化的方式来跟踪任务的进度,还鼓励团队持续改进其工作流程&#…...
Docker的基础操作
1.安装docker服务,配置镜像加速器 1.1 使用yum进行安装 添加docker-ce的源信息 [rootlocalhost ~]# yum install yum-utils device-mapper-persistent-data lvm2 -y [rootlocalhost ~]# yum-config-manager --add-repo https://mirrors.tuna.tsinghua.edu.cn/doc…...

14、缓存预热+缓存雪崩+缓存击穿+缓存穿透
缓存预热缓存雪崩缓存击穿缓存穿透 ● 缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况? ● 缓存预热你是怎么做到的? ● 如何避免或者减少缓存雪崩? ● 穿透和击穿有什么区别?它两一个意思还是截然不同&am…...
【PostGreSQL】PostGreSQL到Oracle的数据迁移
项目需要,有个数据需要导入,拿到手一开始以为是mysql,结果是个PostGreSQL的数据,于是装数据库,但这个也不懂呀,而且本系统用的Oracle,于是得解决迁移转换的问题。 总结下来两个思路。 1、Postg…...

jupyter notebook出现ERR_SSL_VERSION_OR_CIPHER_MISMATCH解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

前端进阶Html+css10----定位的参照对象(高频面试题)
1.relative的参照对象 1)元素按照标准流进行排布; 2)定位参照对象是元素自己原来的位置,可以通过left、right、top、bottom来进行位置调整; 2.absolute(子绝父相) 1)元素脱离标准流…...

总结记录Keras开发构建神经网络模型的三种主流方式:序列模型、函数模型、子类模型
Keras是一个易于使用且功能强大的神经网络建模库,它是基于Python语言开发的。Keras提供了高级API,使得用户能够轻松地定义和训练神经网络模型,无论是用于分类、回归还是其他任务。 Keras的主要特点如下: 简单易用:Kera…...

python环境建设
1. 查看通过pip安装包的路径 问题:devchat vscode中配置需要查找devchat的安装路径,使用pip相关的命令查看 pip list | grep package_name 命令显示获取已安装包的信息(包名与版本号)pip show package_name命令能显示该安装的包…...
)
Python学习笔记第五十九天(Matplotlib 安装)
Python学习笔记第五十九天 Matplotlib 安装后记 Matplotlib 安装 本章节,我们使用 pip 工具来安装 Matplotlib 库,如果还未安装该工具,可以参考 Python pip 安装与使用。 如果您还没有安装Matplotlib,您可以按照以下步骤在Pytho…...

(6)(6.3) 自动任务中的相机控制
文章目录 前言 6.3.1 概述 6.3.2 自动任务类型 6.3.3 创建合成图像 前言 本文介绍 ArduPilot 的相机和云台命令,并说明如何在 Mission Planner 中使用这些命令来定义相机勘测任务。这些说明假定已经连接并配置了相机触发器和云台(camera trigger and gimbal ha…...

什么是cssreset ?为什么要用到cssreset?
1,什么是cssreset ? 顾名思义,css reset,样式重置。即重新设置界面的样式。 CSS reset,又叫做 CSS 重写或者 CSS 重置,用于改写HTML标签的默认样式。 有些HTML标签在浏览器里有默认的样式,例如 p 标签有上…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...