自组织地图 (SOM) — 介绍、解释和实现
自组织地图 (SOM) — 介绍、解释和实现
一、说明
二、关于 SOM
芬兰教授Teuvo Kohonen在1980年代提出的自组织地图或SOM提供了一种在保留数据拓扑的同时对数据集进行低维和离散化表示的方法,称为“地图”。
目标是学习一个以类似方式响应类似输入模式的地图。它被学习为一个权重数组,它被解释为一个神经元数组,其中每个神经元本身都是一个与输入数据点具有相同维度的向量,如下所示。神经元直接受到输入数据的影响。
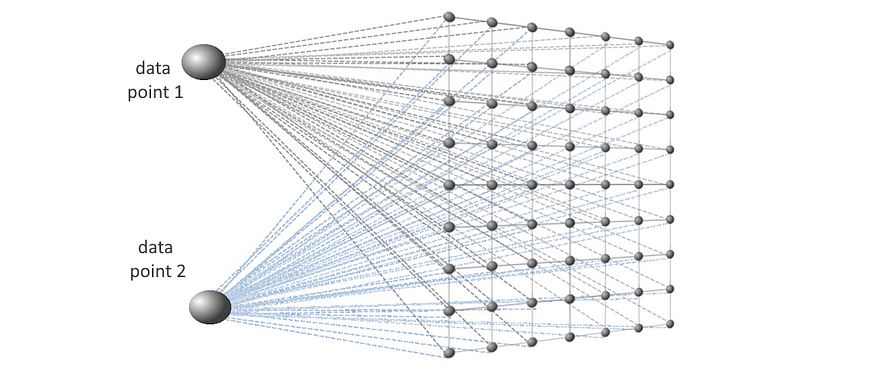
权重数组中神经元之间的距离用于生成表征数据分布的映射。
SOM 具有轻松可视化特征行为的优势。由于可以从学习的表示中访问各个特征,因此表示每个特征的数据行为。
让我们分解一下:
“自组织”
SOM 是一种无监督的人工神经网络。它不是使用误差最小化技术,而是使用竞争性学习。特征向量使用数据点和学习表示之间的基于距离的指标映射到低维表示,不需要任何其他计算,使其“自组织”。
“地图”
学习到的结果权重由U矩阵(统一距离矩阵,下面详细解释)表示,这是一个表示神经元之间距离的“映射”。学习SOM背后的想法是,形成的映射以类似的方式响应类似的输入,在生成的映射的某些区域中将类似的输入组合在一起。
三、在 Python 中的实现
Eklavya 连贯地解释了该算法,提供了带有变量适当表示的分步解释,我们也将用于我们的 Python 实现。
Kohonen自组织地图
一种特殊类型的人工神经网络
towardsdatascience.com
目标是学习一个权重数组,在我们的例子中是一个 3D 数组,但被解释为神经元大小为 x 的 2D 数组,其中每个神经元都是长度的 1D 向量。我们正在学习数据集的 2D 表示。 然后用于生成 U 矩阵 — 整个数据集的单个 2D 地图。Wlengthwidthn_featuresW
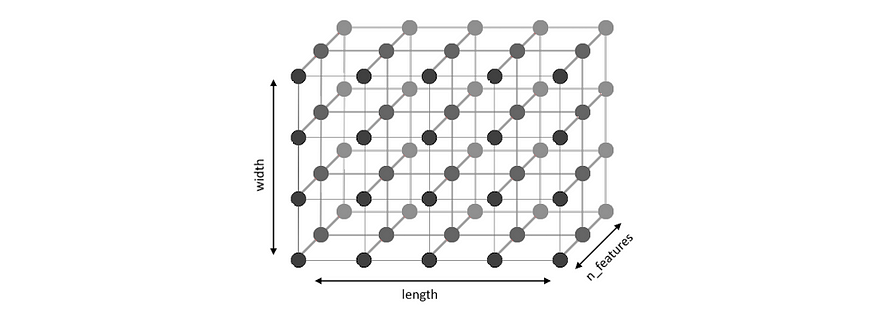
图1 - 权重数组“W”
每个输入向量用于更新 。最接近数据点的神经元是最佳匹配单元(BMU)。其余神经元与BMU的距离用于更新邻域函数,该函数是更新的基础。中较大的值表示相似输入向量的聚类。邻域函数的学习率和半径随时间衰减,因为邻域变小,即相似的输入被分组得更紧密。WWWW
首先,导入所有必要的库。
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import random
import time
from itertools import product四、第一部分:从数据集导入到权重获取
对于数据,我们使用用于预测胎儿健康的数据集,该数据集将胎儿的健康分类为 、 或使用 CTG 数据。它有 22 个功能,但我们只关注前 10 个功能:NormalSuspectPathological
filein = "fetal_health.csv"
data = np.loadtxt(open(filein, "rb"), delimiter = ",", skiprows = 1)
features = ['baseline value', 'accelerations', 'fetal_movement', 'uterine_contractions', 'light_decelerations', 'severe_decelerations', 'prolongued_decelerations', 'abnormal_short_term_variability', 'mean_value_of_short_term_variability', 'percentage_of_time_with_abnormal_long_term_variability']
X_data = np.array(data)[:,0:len(features)]print("Number of datapoints: ", X_data.shape[0])
print("Number of features: ", X_data.shape[1])而且,由于它使用基于距离的指标,我们将继续缩放输入:
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data) # normalizing, scaling现在,深入探讨算法实现的细节。首先,我们看一下超参数:
n_features = X_data.shape[1]
max_iter = 1000 # max. no. of iterations
length = 50 # length of W
width = 50 # width of W
W = np.random.rand([length, width, n_features]) # initial weights
aplha0 = 0.9 # initial learning rate
beta = [[]] # neighbourhood function
sigma0 = max(length, width) # initial radius of beta
TC = max_iter/np.log(sigma0) # time constantlength, , — 权重矩阵的维度,其中 和 指定 feaure 地图的大小,值越高,结果越精细。使用随机值初始化。widthn_feauturesWlengthwidthWmax_iter— 我们想要运行算法的最大迭代次数。TC— 用于学习率和邻域半径衰减的时间常数。alpha0— 动态学习率的初始值。学习率衰减为时间步长或迭代次数t的指数函数:alphat
def aplhaUpdate(t):return aplha0*np.exp(-t/TC)sigma0— 邻域函数的动态(收缩)半径的初始值。我们从一个半径开始,该半径覆盖了神经元的整个 2D 映射。它的更新方式与 相同。Walpha
def sigmaUpdate(t):return sigma0*np.exp(-t/TC)beta一个 2D 向量,用于存储 中每个节点的邻域函数的值。BMUBMU— est atching nit 是最接近输入数据点的节点,即与它的距离最短,在我们的例子中,欧几里得距离,如下所示。BMUx_n
def winningNode(x_n, W): # Find the winning node and distance to itdist = np.linalg.norm(x_n - W, ord =2 , axis = 2)d = np.min(dist)BMU = np.argwhere(dist == np.min(dist))return d, BMU- 要更新,我们首先需要找到权重向量中每个节点与 . 是表示每个长向量到每个其他向量的欧几里得距离的向量,其中每个向量由其 x 和 y 坐标表示。
betaBMUhardDistn_featureWWcoords
hardDist = np.zeros([length, width, length, width])
for i,j,k,l in product(range(length),range(width),range(length),range(width)):hardDist[i,j,k,l]= ((i-k)**2 + (j-l)**2)**0.5gridDistances用于访问表示距离或每个向量在位置 的 2D 数组。coords
def gridDistances(coords):return hardDist[coords[0][0],coords[0][1],:,:]- 然后我们可以更新 .对于每个输入向量,计算为最接近 的点提供最小值。
betabetaBMU
def betaUpdate(coords, sigma): # neighbourhood functionreturn np.exp(-gridDistances(coords)**2/(2*sigma**2))- 下图显示了一个权重数组,在第二张图中可以想象为矢量神经元的 2D 数组。以红色突出显示的矢量是 BMU。蓝色表面显示了每个神经元的值,在BMU处最高。的值表示二维正态分布。
Wbetabeta
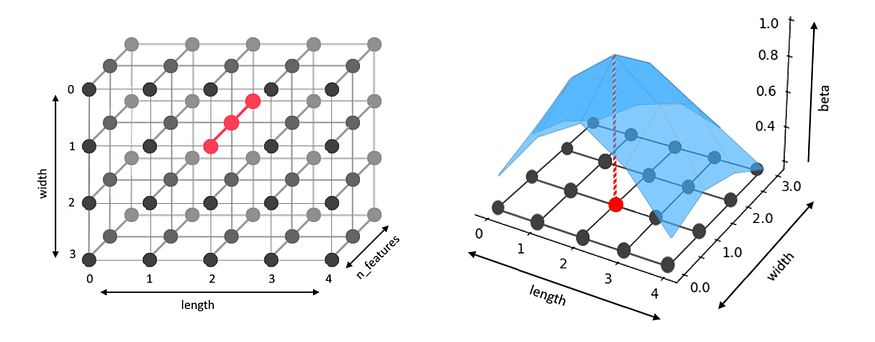
图 2 — W,BMU 以红色突出显示(左和右),为 sigma=1.5 绘制的 beta 值,显示 BMU 处的 beta 值最高。
- 最后,我们可以更新 .我们看到有三个因素影响了更新:(1),它在数据集的一次迭代中是恒定的;(2)、每个向量与输入向量的差值;和(3) .将因子添加到 ,因此对于靠近输入的向量,的值更大,从而导致 中的向量值更大。
WWalphaf=x_n-WWbetaalpha*beta*fWWbetaW
def weightUpdate(W, aplha, beta, x_t):f= (x_t-W)beta = np.reshape(beta,[beta.shape[0],beta.shape[1],1])return W+aplha*beta*f现在,我们已经讨论了初步内容,我们可以将它们放在一起:
errors=np.zeros([max_iter])for t in range(max_iter): t1 = time.time()alpha = aplhaUpdate(t)sigma = sigmaUpdate(t)np.random.shuffle(X_data)n_sample = len(X_data) # iterating over whole datasetQE = 0for n in range(n_sample):d, BMU = winningNode(X_data[n,:], W)QE = QE + dbeta = betaUpdate(BMU, sigma)W = weightUpdate(W, alpha, beta, X_data[n,:])W /= np.linalg.norm(W, axis=2).reshape((length, width, 1))QE /= n_sampleerrors[t]=QEt1 = time.time() - t1print("Iteration: ", "{:05d}".format(t), " | Quantization Error: ", "{:10f}".format(QE), " | Time: ", "{:10f}".format(t1))让我们一步一步地看一下。
- 对于每次迭代,并略微衰减以适应 中的逐渐变化。
alphasigmaW - 对于数据集中的每个输入向量,我们找到 BMU 和 BMU 与输入向量的距离 .
d beta根据BMU进行更新,然后用于更新.WW被归一化,以便在不同的值下保持可比性。Wt- 为了监控学习过程,我们使用量化误差,这是每个数据点到其BMU的距离的平均值。如果更新正确,它应该在迭代中减少。
QEW
当我们在数据集上运行它时,我们得到以下输出:

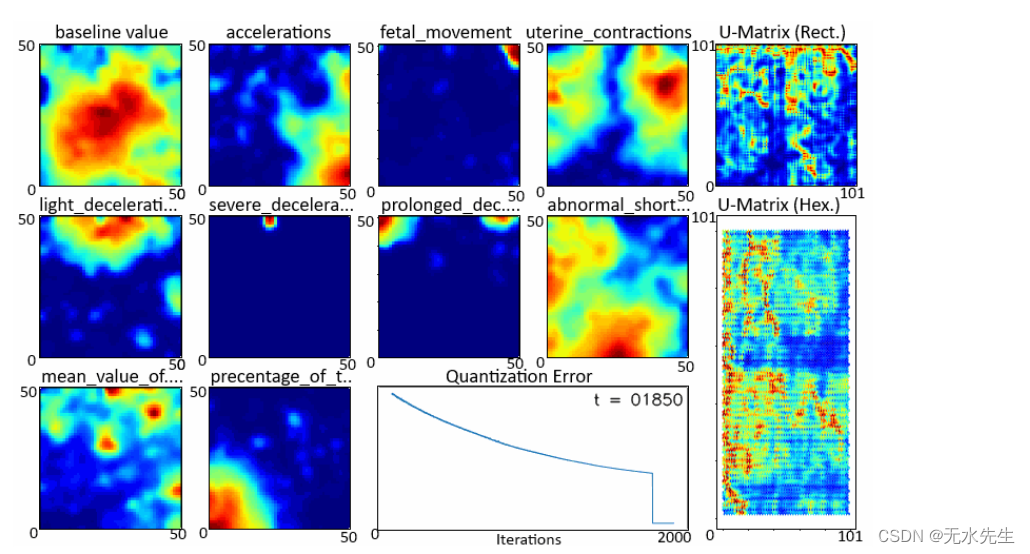
我们可以通过沿其代表特征的最后一个维度切片来绘制各个特征图。W
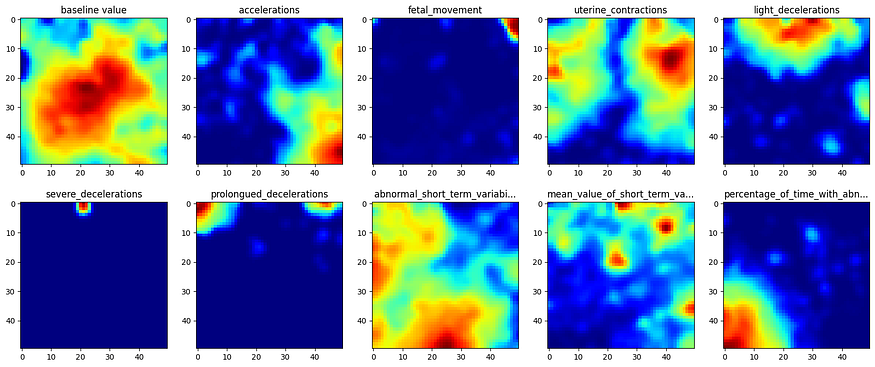
图3 - 特征图
这样就完成了学习获取单个特征图的第一步。W
五、第二部分:U矩阵获取
第二部分是简单地计算神经元之间的距离以获得U矩阵(Unified-distance矩阵),它可以是六边形或矩形。在下图中,我们看到了查看 中神经元 2D 数组的两种方式。W
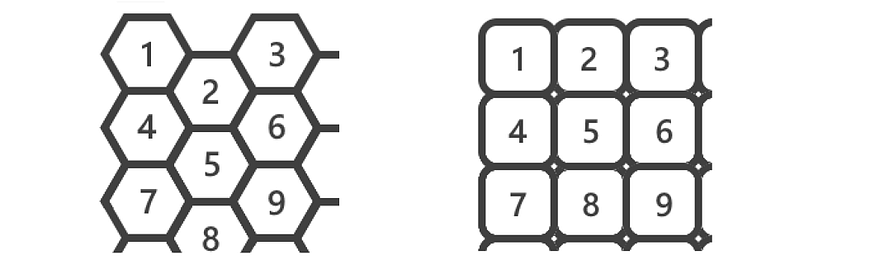
图 5 — W、六边形(左)和矩形(右)的不同解释
U矩阵表示神经元之间的距离。下图显示了六边形和矩形表示的 U 矩阵。在两张图像中,黄色细胞表示相邻神经元之间的距离,例如,{1,2}是上图中神经元1和2之间的距离。橙色单元格表示从神经元数到周围神经元的距离的平均值,即 {1}=mean({1,2}, {1,4}) 或 {5}=mean({2,5}, {4,5}, {5,6}, {5,7}, {5,8}, {5,9}) 对于六边形 U 矩阵,{5}=mean({2,5}, {4,5}, {5,6}, {5,8}) 对于矩形矩阵。

图 6 — U 矩阵,六边形(左)和矩形(右)
在矩形 U 矩阵中,还有一种其他类型的单元格,以蓝色突出显示。我们不能将其视为蓝色单元格角上的橙色单元格之间的距离,例如平均值({1},{5})或平均值({2},{4}),因为这些值对蓝色单元格都有效,但不相等,这将是矛盾的。因此,我们将该值作为其周围黄色单元格的平均值,从而允许最终 U 矩阵中的单元格之间更平滑地过渡。有关进一步说明,请参阅此文章。下面给出了两种类型的 U 矩阵的计算。
对于黄色单元格,我们计算相邻神经元之间的距离,橙色和蓝色单元格计算为它们上方、下方和两侧单元格的平均值。
# CALCULATION OF RECTANGULAR U-MATRIX FROM W
def make_u_rect(W):U = np.zeros([W.shape[0]*2-1, W.shape[1]*2-1], dtype=np.float64)# YELLOW CELLSfor i in range(W.shape[0]): # across columnsk=1for j in range(W.shape[1]-1):U[2*i, k]= np.linalg.norm(W[i,j]-W[i,j+1], ord=2)k += 2for j in range(W.shape[1]): # down rowsk=1for i in range(W.shape[0]-1):U[k,2*j] = np.linalg.norm(W[i,j]-W[i+1,j], ord=2)k+=2# ORANGE AND BLUE CELLS - average of cells top, bottom, left, right.for (i,j) in product(range(U.shape[0]), range(U.shape[1])):if U[i,j] !=0: continueall_vals = np.concatenate((U[(i-1 if i>0 else i): (i+2 if i<=U.shape[0]-1 else i), j],U[i, (j-1 if j>0 else j): (j+2 if j<=U.shape[1]-1 else j)]))U[i,j] = all_vals[all_vals!=0].mean()# Normalizing in [0-1] range for better visualization.scaler = MinMaxScaler()return scaler.fit_transform(U) 对于六边形矩阵,我们使用神经元本身的值作为位置{1}、{2}、...以简化 中 {1,2}、{2,3} 等的计算。{1}, {2}, ...然后替换为其周围值的平均值。U
# CALCULATION OF HEXAGONAL U-MATRIX FROM W
def make_u_hex(W): # Creating arrays with extra rows to accommodate hexagonal shape.U_temp = np.zeros([4*W.shape[0]-1, 2*W.shape[1]-1, W.shape[2]])U = np.zeros([4*W.shape[0]-1, 2*W.shape[1]-1])"""The U matrix is mapped to a numpy array as shown below.U_temp holds neuron at postion 1 in place of {1} for easy computationof {1,2}, {2,3} etc. in U. {1}, {2}, {3}, ... are computed later.[[ (1), 0, 0, 0, (3)],[ 0, (1,2), 0, (2,3), 0],[ (1,4), 0, (2), 0, (3,6)],[ 0, (2,4), 0 , (2,6), 0],[ (4), 0, (2,5), 0, (6)],[ 0, (4,5), 0, (5,6), 0],[ (4,7), 0, (5), 0, (6,9)],[ 0, (2,4), 0, (5,9), 0],[ (7), 0, (5,8), 0, (9)],[ 0, (7,8), 0, (8,9), 0],[ 0, 0, (8), 0, 0]]"""# Creating a temporary array placing neuron vectors in # place of orange cells.k=0indices = []for i in range(W.shape[0]):l=0for j in range(W.shape[1]):U_temp[k+2 if l%4!=0 else k,l,:] = W[i,j,:]indices.append((k+2 if l%4!=0 else k,l))l+=2k += 4# Finding distances for YELLOW cells.for (i,j),(k,l) in product(indices, indices):if abs(i-k)==2 and abs(j-l)==2: # Along diagonalsU[int((i+k)/2), int((j+l)/2)] = np.linalg.norm(U_temp[i,j,:]-U_temp[k,l,:], ord=2)if abs(i-k)==4 and abs(j-l)==0: # In vertical directionU[int((i+k)/2), int((j+l)/2)] = np.linalg.norm(U_temp[i,j,:]-U_temp[k,l,:], ord=2)# Calculating ORANGE cells as mean of immediate surrounding cells.for (i,j) in indices:all_vals = U[(i-2 if i-1>0 else i): (i+3 if i+2<U.shape[0]-1 else i), (j-1 if j>0 else j): (j+2 if j<=U.shape[1]-1 else j)]U[i,j] = np.average(all_vals[all_vals!=0])# To remove extra rows introduced in above function.new_U = collapse_hex_u(U)# Normalizing in [0-1] range for better visualization.scaler = MinMaxScaler()return scaler.fit_transform(new_U)def collapse_hex_u(U):new_U = np.zeros([int((U.shape[0]+1)/2), U.shape[1]])# Moving up values in every alternate columnfor j in range(1, U.shape[1], 2):for i in range(U.shape[0]-1):U[i,j]=U[i+1,j]# Removing extra rowsfor i in range(new_U.shape[0]): new_U[i,:] = U[2*i,:]return new_U 要绘制六边形网格,我们需要自己在图上绘制六边形。对于折叠的六边形,我们可以绘制 U 矩阵,方法是为每个点绘制一个六边形,每两列有一个轻微的 y 偏移量,以制作一个网格,如图 6 所示。U
def draw_hex_grid(ax, U):def make_hex(ax, x, y, colour):if x%2==1: y=y+0.5xs = np.array([x-0.333,x+0.333,x+0.667,x+0.333,x-0.333,x-0.667])ys = np.array([ y+0.5, y+0.5, y, y-0.5, y-0.5, y])ax.fill(xs, ys, facecolor = colour)ax.invert_yaxis()cmap = matplotlib.cm.get_cmap('jet')for (i,j) in product(range(U.shape[0]), range(U.shape[1])):if U[i,j]==0: rgba='white'else: rgba = cmap(U[i,j])make_hex(ax, i, j, rgba)ax.set_title("U-Matrix (Hexagonal)")图 3 所示的两种类型的 U 矩阵结果为:W
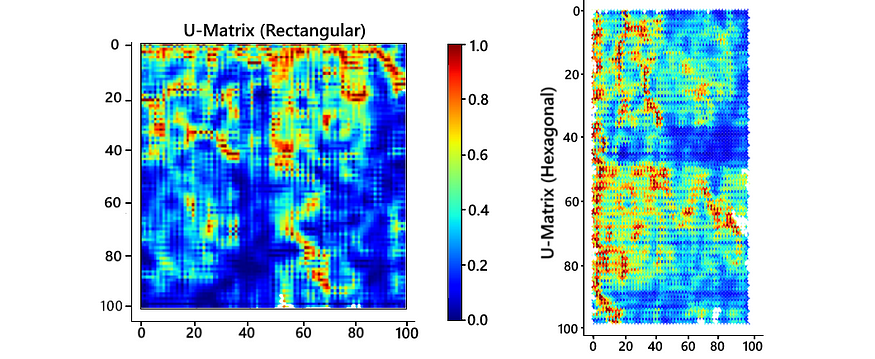
图 7 — U 矩阵
在学习过程中拍摄如图 3 所示的快照,我们可以观察每个特征图和 U 矩阵的学习情况。上面显示的颜色图显示,红色表示最大值,表示该区域中聚集的更多输入数据点,而模糊区域表示输入数据点稀疏出现的空间。W
随着迭代的进行,学习速度变慢了。在开始的迭代中,特征图变化很大,而在以后的迭代中,它们变得有些稳定。矩阵也出现了同样的趋势,社区的规模在缩小。这也反映在 中,其下降速率随时间而降低。哈尼亚·安尤姆
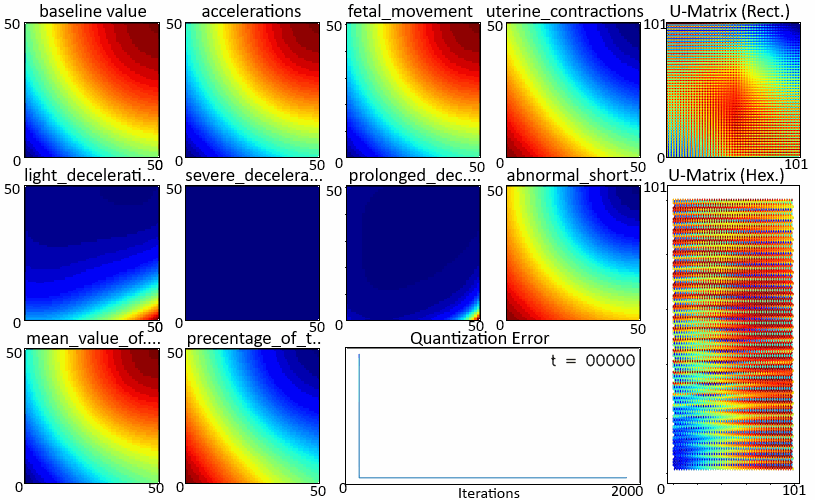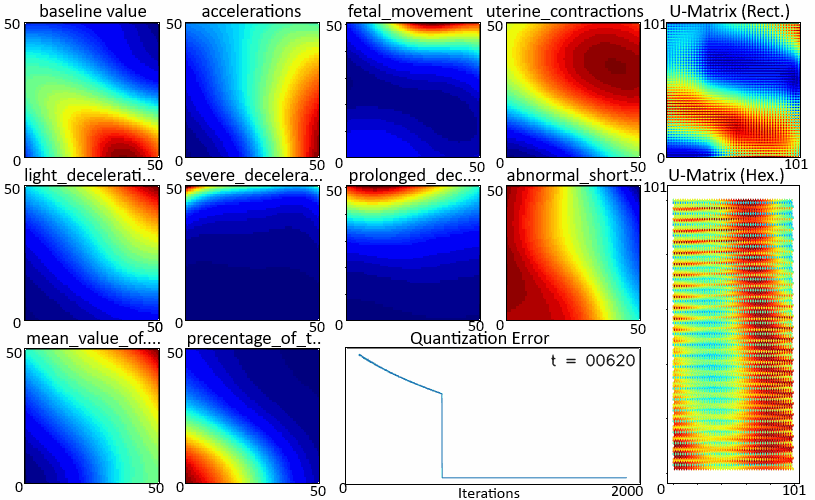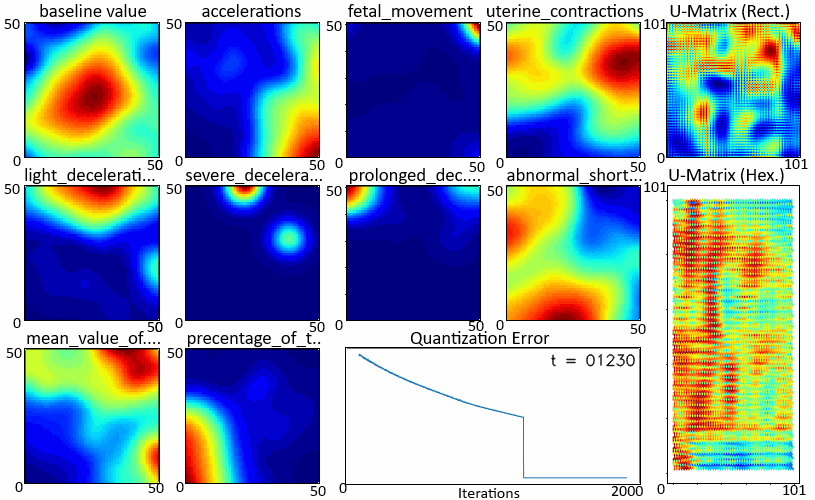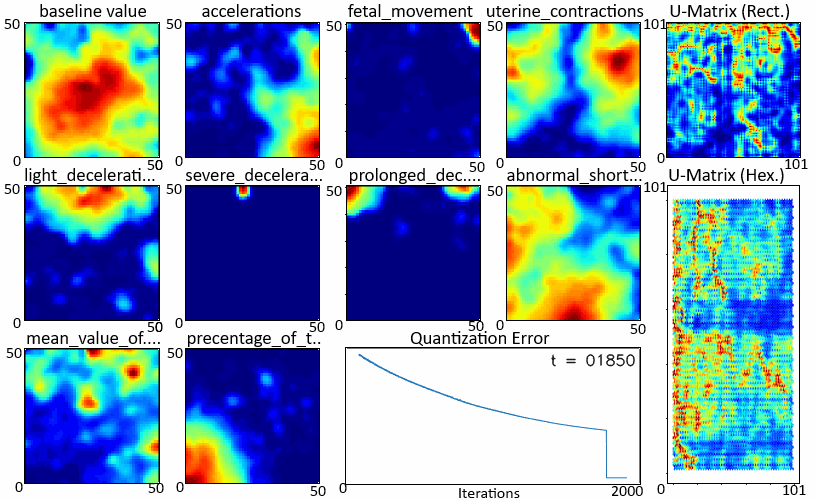
显示“W”和“U”学习的.gif图像(在新选项卡中打开以再次播放)
相关文章:
自组织地图 (SOM) — 介绍、解释和实现
自组织地图 (SOM) — 介绍、解释和实现 一、说明 什么是SOM(self orgnize map)自组织地图,是GNN类似的图神经网络的概念。因为神经网络实质上可以解释为二部图的权重,因此无论GNN还是SOM都有共同的神经网络…...
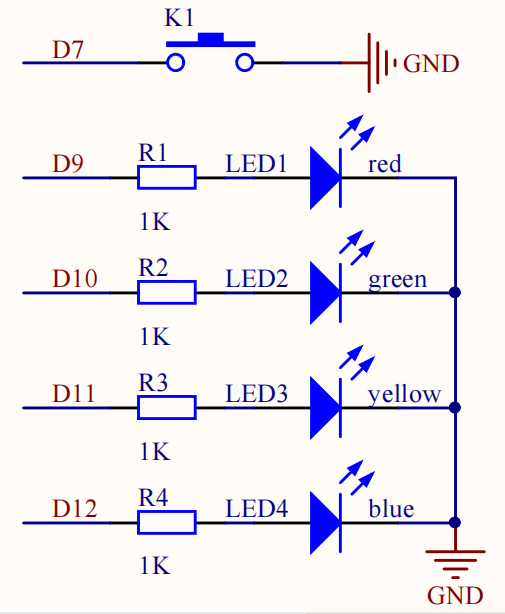
Arduino程序设计(四)按键消抖+按键计数
按键消抖按键计数 前言一、按键消抖二、按键计数1、示例代码2、按键计数实验 参考资料 前言 本文主要介绍两种按键控制LED实验:第一种是采用软件消抖的方法检测按键按下的效果;第二种是根据按键按下次数,四个LED灯呈现不同的流水灯效果。 一…...
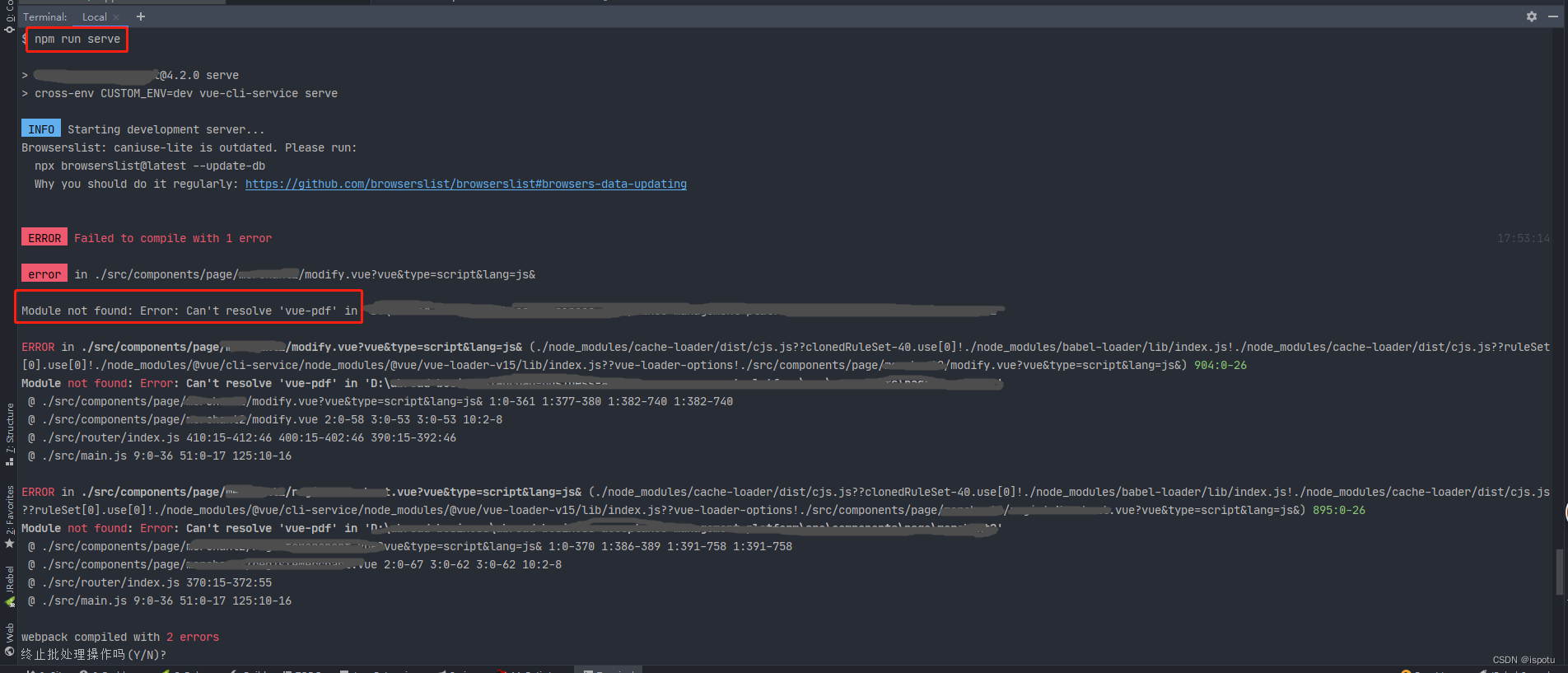
Module not found: Error: Can‘t resolve ‘vue-pdf‘ in ‘xxx‘
使用命令npm run serve时vue项目报错: Module not found: Error: Cant resolve vue-pdf in xxx 解决方案: 运行命令: npm install vue-pdf --save --legacy-peer-deps 即可解决。 再次顺利执行npm run serve...

ELK之LogStash介绍及安装配置
一、logstash简介 集中、转换和存储数据 Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。 Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的…...
)
docker学习(1)
1、容器与虚拟机的对比: 虚拟机(virtual machine)就是带环境安装的一种解决方案。 它可以在一种操作系统里面运行另一种操作系统,比如在Windows10系统里面运行Linux系统CentOS7。 应用程序对此毫无感知,因为虚拟机看…...

UE5 Niagara基础知识讲解
文章目录 前言官方文档发射器生成(Emitter Spawn)发射器更新(Emitter Update)Spawn Rate(生成速率)粒子生成(Particle Spawn)Initialize Particle(初始化粒子)粒子生命周期粒子颜色粒子大小Shape Location(形状位置)形状位置Add Velocity(添加速度)粒子速度Curl …...
缓存穿透、缓存击穿和缓存雪崩
👏作者简介:大家好,我是爱发博客的嗯哼,爱好Java的小菜鸟 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦 📝社区论坛:希望大家能加入社区共同进步…...
自动化编排工具Terraform介绍(一)
Terraform是什么?: Terraform 是 HashiCorp 公司旗下的 Provision Infrastructure 产品, 是 AWS APN Technology Partner 与 AWS DevOps Competency Partner。Terraform 是一个 IT 基础架构自动化编排工具,它的口号是“Write, Plan, and Create …...
zhm_real/MotionPlanning运动规划库中A*算法源码详细解读
本文主要对zhm_real/MotionPlanning运动规划库中A*算法源码进行详细解读,即对astar.py文件中的内容进行详细的解读,另外本文是 Hybrid A * 算法源码解读的前置文章,为后续解读Hybrid A * 算法源码做铺垫。 astar.py文件中的源码如下ÿ…...
SpringMVC中Controller层获取前端请求参数的几种方式
SpringMVC中Controller层获取前端请求参数的几种方式 1、SpringMVC自动绑定2、使用RequestParam 注解进行接收3、RequestBody注解(1) 使用实体来接收JSON(2)使用 Map 集合接收JSON(3) 使用 List集合接收JSO…...

记Flask-Migrate迁移数据库失败的两个Bug——详解循环导入问题
文章目录 Flask-Migrate迁移数据库失败的两个Bug1、找不到数据库:Unknown database ***2、迁移后没有效果:No changes in schema detected. Flask-Migrate迁移数据库失败的两个Bug 1、找不到数据库:Unknown database ‘***’ 若还没有创建数…...

在线求助。。npm i 报错,连公司内部网,无法连外网
各位前端朋友 ,有没有遇到我这种npm i 报错的问题。 公司内网,无法连外网,使用公司内部的Nexus镜像源 我在公司内网执行npm i 报错,报network连接失败。 我都已经在npm设置了内部镜像源,它为啥还要去外网下载呢。而…...

TCP/UDP/IP协议简介
IP协议简介 特指为实现一个相互连接的网络系统上从源地址到目的地址传输数据包(互联网数据包) 所提供必要功能的协议 特点: 不可靠:不能保证IP数据包能够成功的到达它的目的地只能提供尽力而为的传输服务。 无连接:IP并不维护任何关于后续数…...

写点感想3:关于本人近期的说明与一点感受
按照我今年以来7月之前的更新频率,我已经好久没有更新博文了(或者说静下来写点东西)。 我其实有规划蛮多的有意思的且想要去研究下的topic,最近好久没能更新主要的原因包括: 开启了我职业生涯的第二份工作:在某研究院工作2年零3…...

opencv-全景图像拼接
运行环境 python3.6 opencv 3.4.1.15 stitcher.py import numpy as np import cv2class Stitcher:#拼接函数def stitch(self, images, ratio0.75, reprojThresh4.0,showMatchesFalse):#获取输入图片(imageB, imageA) images#检测A、B图片的SIFT关键特征点,并计算…...
如何将下载的安装包导入PyCharm
1. 下载安装包 这里以pyke为例。下载好之后解压缩,然后放入/Lib/site-packages/pyke-1.1.1 2. 打开PyCharm的终端进行安装 python setup.py install 3. 安装好之后导入即可使用 import pyke...

【redis问题】Caused by: io.netty.channel
遇到的问题: 在使用 RedisTemplate 连接 Redis 进行操作的时候,发生了如下报错: 测试代码为: 配置文件: 问题根源: redis没有添加端口映射解决方案: 删除原来的redis容器,添加新…...

Elasticsearch 处理地理信息
1、GeoHash GeoHash是一种地理坐标编码系统,可以将地理位置按照一定的规则转换为字符串,以方便对地理位置信息建立空间索引。首先要明确的是,GeoHash代表的不是一个点而是一个区域。GeoHash具有两个显著的特点:一是通过改变 G…...
ARM开发,stm32mp157a-A7核IIC实验(采集温湿度传感器值)
1.实验目标:采集温湿度传感器值; 2.分析框图(模拟IIC控制器); 3.代码; ---iic.h封装时序协议头文件--- #ifndef __IIC_H__ #define __IIC_H__ #include "stm32mp1xx_gpio.h" #include "st…...

告别复杂操作:DCT-Net人像卡通化一键部署与使用全攻略
告别复杂操作:DCT-Net人像卡通化一键部署与使用全攻略 想把自己的照片变成可爱的卡通头像,或者为家人朋友制作一份独特的卡通礼物,却苦于不会画画、不懂PS?过去,这可能需要专业的技能和复杂的软件操作。但现在&#x…...

GLM-OCR惊艳效果展示:竖排中文古籍OCR,支持从右至左阅读顺序还原
GLM-OCR惊艳效果展示:竖排中文古籍OCR,支持从右至左阅读顺序还原 注意:本文所有展示效果基于GLM-OCR模型实际生成,模型文件已预置在镜像环境中,开箱即用。 1. 古籍OCR的技术挑战与突破 传统OCR技术在处理现代横排文档…...

DeepSeek、Kimi、笔灵谁最好用?5款网文作者亲测的AI写作神器横评
作为在网文圈一路摸爬滚打过来的我,面对“AI写小说”这个现象,心情其实挺复杂的。 这有点像工业革命时期的纺织工人看着蒸汽机——恐惧是真的,但效率的碾压也是真的。 不是纯用AI生成,而是用AI搭建了极其高效的“外挂工作流”。 …...

全案与年度陪跑方法拆解:从判断到落地的完整框架
先给一个结论:当问题已经跨越方向、认知、路径和组织时,单点项目无法真正解决企业增长问题。如果再往前一步看,什么企业已经不该再“补动作”,而应该进入全案重建或年度陪跑?本质上都不是单点动作问题,而是…...

探索 COMSOL 中的激光打孔熔池:为激光研究人员和工程师开启新视野
COMSOL 激光 激光打孔熔池 名称:激光打孔熔池 适用人群:激光研究人员/工程师 服务:模型视频教程嘿,各位激光研究的小伙伴和工程师们!今天咱来唠唠 COMSOL 里超有趣的激光打孔熔池相关内容。 为啥关注激光打孔熔池 在激…...
)
手把手教你用SOEM和SOES搭建EtherCAT主从站(基于LAN9252/9253)
基于SOEM/SOES的EtherCAT主从站开发实战指南 1. 环境准备与硬件选型 在工业自动化领域,EtherCAT以其卓越的实时性能和灵活的拓扑结构成为主流现场总线协议之一。对于开发者而言,使用开源库SOEM(主站)和SOES(从站&#…...

Cloudflare CDN自动更换优质IP实战:15分钟搞定腾讯云+DNSPod配置
Cloudflare CDN智能优化实战:腾讯云DNSPod自动化IP优选方案 当你的网站访问者遍布全球时,Cloudflare的免费CDN就像一把双刃剑——它既可能成为性能瓶颈,也可能成为加速利器。关键在于如何驾驭这套系统,特别是对亚洲地区的用户而言…...

Vue3 源码学习和解读保姆级教程
哈喽,各位前端小伙伴!是不是已经用 Vue3 开发过多个项目,熟练使用 setup、ref、reactive,但被面试官追问「Vue3 响应式原理和 Vue2 有什么区别」「Composition API 为什么更灵活」时,却只能含糊其辞?想进阶中高级前端,却因不懂 Vue3 源码底层逻辑,始终无法突破技术瓶颈…...

遗传算法实战:TSP问题的高效路径优化与可视化分析
1. 遗传算法与TSP问题的奇妙碰撞 第一次听说遗传算法能解决旅行商问题(TSP)时,我的反应和大多数人一样:"这玩意儿真能行?"直到亲手实现了整个流程,看着屏幕上那条不断优化的路径,才真…...

Windows智能自动化:重新定义Windows效率的AI系统控制方案
Windows智能自动化:重新定义Windows效率的AI系统控制方案 【免费下载链接】Windows-MCP Lightweight MCP Server for automating Windows OS in the easy way. 项目地址: https://gitcode.com/gh_mirrors/wi/Windows-MCP 在数字化办公的浪潮中,Wi…...