【论文阅读】CONAN:一种实用的、高精度、高效的APT实时检测系统(TDSC-2020)
CONAN:A Practical Real-Time APT Detection System With High Accuracy and Efficiency
TDSC-2020
浙江大学
Xiong C, Zhu T, Dong W, et al. CONAN: A practical real-time APT detection system with high accuracy and efficiency[J]. IEEE Transactions on Dependable and Secure Computing, 2020, 19(1): 551-565.
目录
- 0. 摘要
- 1. 引言
- 2. 一个实例和威胁模型
- 3. 检测模型
- 3.1. 动机
- 3.2. 三阶段检测模型
- 3.3. 跟踪可疑代码执行
- 4. 基于状态的框架
- 4.1. 语义识别
- 4.2. 数据结构
- 4.3. 状态转换
- 4.4. 恶意状态
- 4.5. 攻击重构
- 5. 评估
- 5.1. 实施
- 5.2. 数据集
- 5.3. 环境和实验装置
- 5.4. 攻击场景和重建
- 5.5. 大规模真实世界部署
- 5.6. 误报
0. 摘要
现有的实时APT检测机制由于检测模型不准确和来源图尺寸不断增大而存在准确性和效率问题。
- 为了解决准确性问题,我们提出了一种新颖而准确的APT检测模型,该模型消除了不必要的阶段,将重点放在剩余的阶段,并改进了定义。
- 为了解决效率问题,我们提出了一个基于状态的框架,在这个框架中,事件作为流被消耗(consume),每个实体都以类似于FSA(有限状态自动机)的结构表示,而不存储历史数据。
- 通过在数据库中仅存储千分之一的事件来重建攻击场景。
- 在Windows上实现了我们的设计,并在现实场景下进行了全面的实验,以证明CONAN可以准确有效地检测到我们评估中的所有攻击。
所有攻击?
1. 引言
构建基于简单规则检测APT每个阶段并计算可疑分数的模型在HOLMES中得到实质性进展。然而,并不是所有阶段都是必要的,其中一些阶段通常是通过先验知识检测到的,并且会随时间推移而变化。基于来源图的方案保留了上下文信息。然而,随着时间推移,图会持续增长,不可避免存在效率和内存问题,特别是实时监测。因此大多数检测方法依赖时间窗口。
为了高精度地检测未知APT,我们利用控制流(即为什么执行进程或代码)和数据流(即数据如何在对象之间传递)来解释上下文行为,而不是集中在APT攻击中不必要的、不可检测的和易更改的阶段。我们确定了以下三个基本攻击阶段:1)部署并执行攻击者的代码,2)收集敏感信息或造成破坏,3)与C&C服务器通信或窃取敏感数据。我们主要专注于准确地检测这些阶段,并将它们组合起来,以区分恶意行为和良性行为。
CONAN从Windows中收集数据,提取语义,然后使用智能策略进行状态传输和实时检测APT。一旦检测到攻击,它可以自动重建部分攻击链。我们在三种场景下评估CONAN: DARPA、我们的实验室和三家现实世界的公司。结果表明,CONAN能够快速检测出实验中所有潜在的APT攻击,假阳性率接近于零,并能准确地重建攻击图。随着时间的推移,CONAN的内存使用保持不变(1-10 MB)。
接近0误报?
主要贡献如下:
- 提出了一种新的APT检测模型,专注于APT的三个恒定步骤。提出了一套精确跟踪和检测这些步骤的设计,包括检测基于内存的攻击和可疑进程行为。
- 提出了一种新的高效的基于状态的检测框架,其中每个进程和文件都表示为一个类似于FSA的结构。该框架有助于检测具有恒定和有限内存使用和高效率(比数据生成快数百倍)的APT。
- 将设计实现为APT攻击检测系统,能够实时、高精度地检测未知高级攻击,并快速恢复攻击链。我们在真实世界的数据集上测试了我们的系统,并确定它比以前的方法表现得更好,特别是在效率和准确性方面。
本文中的原子可疑指标(ASIs,atomic suspicious indicators)、过渡规则和恶意状态与评估中使用的相同。虽然CONAN可以检测DARPA交战中提出的所有攻击,但我们并不打算证明这些定义足以用于所有攻击;相反,我们想要展示我们的设计,以准确有效地检测和重建APT。此外,可以通过添加更多数据源轻松扩展CONAN,因为ASIs、规则和恶意状态可以在配置文件中自定义。
这里原文是:The atomic suspicious indicators (ASIs), transition rules and malicious states in this paper are the same as those used in evaluation.是指本文的评价指标和前人的评估方式一致吗?还是说就本文来说前后定义是一致的?
检测出了DARPA中的所有攻击,但又不敢保证通用性。涉及到自定义就应该存疑,考虑是多大程度的自定义。
2. 一个实例和威胁模型
想象一下,您正在使用计算机工作,并收到一封来自同事的电子邮件,要求您填写附件中的表格。您在没有收到防病毒软件警报的情况下下载附件,打开它,填写它,然后回复发件人。几天后您可能会忘记这封电子邮件,但几个月后,您会发现一些敏感数据已被竞争对手窃取。
此外,攻击可能更加复杂。例如,攻击者首先准备了一个新的远程访问木马(RAT),该木马从未被反病毒厂商发现。然后,他收集有关您公司的信息,以便他可以模仿员工给你发邮件的方式。附件包含打开文件时执行的混淆宏脚本。它执行 PowerShell 命令以在内存中下载并运行准备好的 RAT,提供对您机器的访问,而不会在硬盘上留下恶意文件。攻击者可以潜伏很长时间,直到他得到他想要的东西,例如敏感文件或您帐户的密码。
在这样的场景中,由于伪装和加密,基于网络流量的分析可能无效。基于沙盒的检测可能会被反沙盒技术通过。静态恶意软件分析无法工作,因为磁盘上没有任何恶意软件,甚至内存中的恶意软件都是全新的,没有记录静态特征。
在我们的威胁模型中,攻击者非常了解他的目标并准备新的攻击,包括零日漏洞、自行开发的恶意软件和新的 DNS。他首先让他的恶意代码在受害者的机器上运行,然后自动或通过接受来自网络的命令执行一些恶意行为来收集信息或造成损害。最后,如果他想获得敏感信息,这些窃取的数据应该通过网络发送。
虽然我们部署此系统是为了检测 APT 攻击,但它也可以检测具有类似目标的一般攻击。但是,我们无法检测旁道攻击和内部攻击,其中攻击具有访问机器的合法途径。CONAN 无法检测到的另一种攻击是面向返回编程 (ROP) 攻击 。通过这种技术,攻击者可以控制调用堆栈来劫持程序控制流,然后小心地执行已经存在于机器内存中的选定机器指令序列。因此,受害者的机器上没有部署恶意代码。
在本文中,我们假设事件日志和数字签名是可信的。评估中使用的所有攻击都无法被传统的反病毒系统检测到。相反,我们不需要假设整个攻击发生在我们系统安装之后。因此,可以检测到预装的恶意软件和恶意代码。
为什么要假设攻击无法被传统的反病毒系统检测到呢?是反病毒系统的行为会干涉CONAN检测吗?
3. 检测模型
我们在主机上开发了一个快速稳定的多级数据收集器,用于收集审计跟踪、调用堆栈和其他数据。然后,这些数据被发送到检测服务器,提取为高级语义并作为进程和文件状态存储在内存结构中。同时,处理所有事件日志以根据预定义规则更改进程和文件的状态。这些事件和状态存储在数据库中,用于以后的攻击重建。每当进程进入恶意状态时,都会触发警报以及重建的攻击图。

【 图片翻译】:数据收集器部署在客户端,它尝试以低开销从多层收集痕迹。这些轨迹在客户端进行预处理以减小数据大小,然后发送到服务器端的检测器。检测器构建一个主内存结构,以按照预定义的规则维护进程和文件的状态。状态和必要的事件同步到数据库。一旦发出警报,就可以从数据库中重建攻击链。
3.1. 动机
MITRE ATT&CK 引入了一个十一阶段的 APT 攻击模型来描述 APT 攻击中使用的策略、技术和程序 (TTPs)。然而,过于复杂的多相模型只能用于更好地理解 APT,而不能用于检测它们。
例如,HOLMES的作者开发了一个系统来检测每个策略(阶段)的技术,并通过信息流(包括数据流和控制流)将这些阶段连接起来作为攻击链。在每个攻击链中,检测到的阶段越多,攻击的可能性就越大。但是,存在三个主要问题。
- 首先,每个阶段都使用了数百种技术。该系统必须检测数百种技术,这很难实现并且会导致高检测开销。
- 其次,传统方法的检测点,例如漏洞,仍在考虑中。要检测这些阶段,需要先验知识。
- 此外,攻击所使用的技术很容易发生变化;因此,很难检测到未知的攻击。
作者认为,虽然他们无法准确检测所有阶段,但作为所有阶段的子集,检测到的阶段足以区分攻击和良性活动。换句话说,没有必要检测所有阶段( phase)。此外,引入一些常见的和不必要的阶段会增加误报率。
阶段多不能说明攻击,阶段少不能证明其合法性。例如,一个新安装的浏览器可以触发 MITRE ATT&CK 十一阶段模型中的 6 个阶段(初始访问、执行、持久性、凭证访问、发现和渗漏),并将触发 HOLMES 的错误警报。同时,高级攻击者通过零日漏洞访问机器并下载恶意软件。然后,它使用未知方法实现持久化(或者在某些情况下它不想持久化,例如在永不关闭的服务器上)。它记录击键并通过命令和控制通道泄露数据,这可能很难检测到。最后,在这种攻击中唯一可以检测到的阶段是执行和收集,因此它们不能被 HOLMES 视为攻击。
个人觉得,如果说用检测到的阶段数量来描述一个攻击的威胁性和真实性不合理,那完全可以给某些阶段加权进行威胁评分。作者的这个理由不是很成立。但是同时,我个人又是很赞同减少检测阶段的。ATT&CK只能用作学习和参考,或者辅助用于攻击场景重建,用来作为APT的检测依据不太合理。就如作者所说,高级攻击多用0-day漏洞和新技术、新工具,哪能步步被检测并得到一个完成攻击链。
3.2. 三阶段检测模型
为了检测未知的 APT 攻击,我们首先找到它们的不变部分。
- 攻击者必须首先将他们的代码部署到受害者身上。不同之处在于恶意软件可以定制或仅在内存中执行以逃避传统的基于静态文件的检测系统。
- 攻击者的最终目标多年来保持不变(数据)。
- 攻击者会与 C&C 服务器通信并泄露机密数据,恶意程序应该始终具有访问网络的能力。
为此,我们提出了一个三阶段模型来检测 APT:
(1)部署并执行攻击者的代码
任何进程行为都是代码执行的结果。攻击者必须首先向受害者部署代码才能实现他的目标。为了检测这个阶段,我们监控来自外部的数据流,包括网络和便携式设备,我们称之为不受信任的数据流。拥有不受信任的数据流是发起攻击的必要条件,无论攻击者使用任何漏洞或技术来部署他的代码。在另一种情况下,攻击者可能会使用合法的进程来达到他的目的。例如,攻击者可以使用预装的 Windows SnappingTool 捕获屏幕。在这里,不受信任的控制流可以提供帮助。如果进程或线程由可疑线程启动,则进程或线程也被标记为可疑。
(2)收集敏感信息或造成损害
攻击者通常试图窃取机密数据或破坏受害者的数据或机器,这就是攻击者实施攻击的原因,也是受害者希望避免这种结果的原因。我们不将获得对受害者的访问权限但不会导致有害行为的入侵视为真正的攻击。从文件窃取机密数据可以通过监视来自机密目标的数据流作为机密数据流来检测。
(3)与 C&C 服务器通信或泄露敏感数据
这两个操作在 APT 中都是必需的。没有这些操作,就无法完成攻击。虽然有很多方法可以实现这一点(例如,可移动磁盘),但典型的现实世界攻击方法是通过网络连接。
这三个阶段对于大多数 APT 攻击来说是直接且必要的。因此,我们尝试检测执行可疑代码以开展恶意行为的进程。此外,我们还提供了其他功能来说明不同的攻击场景。与 SLEUTH 不同,我们不分配分数或简单的标签;相反,我们使用更详细的描述来描述攻击的组成部分,以便在不增加额外开销的情况下更好地理解和进一步分析。
不分配分数也不用标签,有点好奇。
3.3. 跟踪可疑代码执行
基于内存的攻击,包括注入和无文件攻击,可以帮助攻击者在良性应用程序的内存中执行他们的代码,因为传统的检测系统对它们视而不见而越来越多地被使用。虽然现有研究将进程视为存储上下文信息的实体,但它们容易受到基于内存的攻击且攻击技术多种多样。我们不关注攻击使用的技术,而是提出了一种通过跟踪可疑数据流和检查执行调用堆栈来检测可疑代码执行的方法。
如果攻击者想要执行恶意行为,他必须 1) 直接执行恶意代码或 2) 借助良性进程来实现。检测的主要挑战是确定 1) 执行了哪些代码,2) 它来自何处以及 3) 如何执行。虽然污点跟踪在跟踪细粒度的数据流时有很大帮助,但由于其高开销,这种方法不能实时使用。为了应对第一个挑战,我们采用了堆栈调用(call stack)。堆栈调用是一种堆栈数据结构,用于存储生成事件时有关活动子例程的信息。堆栈调用中的地址是属于不同代码块的返回地址。
如果一个调用堆栈中的所有地址都来自可信代码块,我们将此线程称为执行可信代码。由于良性进程很容易被强制执行外部代码,因此我们根据代码执行将一个进程分成多个子单元(线程)。如图所示,这些执行未知或可疑代码的线程与完全良性的线程分开。

执行未签名代码的可疑线程与完全良性的代码分开。此功能对于检测可疑代码执行很重要,包括未签名镜像(image)和内存攻击。
我们考虑以下场景:
(1)镜像加载和内存执行
镜像加载是一种基本操作,在该操作中,进程将可执行文件加载到其内存中。攻击者可以将良性镜像文件替换为恶意镜像文件或强制良性应用程序加载恶意镜像,然后在良性进程的幌子下进行攻击。此外,攻击者可以将恶意代码直接写入另一个进程的内存空间,或者从内存而不是从磁盘加载镜像,因而不会触发系统事件。前者被称为进程注入,常用于攻击,后者是一种称为反射加载的技术,已在最近的高级攻击中使用。我们的系统监控加载镜像的动态事件,并存储每个进程分配的内存的基址和大小。当未签名图像或已分配内存的内存地址出现在调用堆栈中时,表示该线程中已执行了一些未知代码;因此,该线程应与其他线程分开。为了减少解析完整调用堆栈时的开销,我们对每个线程进行了低频率的样本检查。
(2)脚本执行
基于脚本的攻击近年来变得普遍,因为主机进程完全是良性的,进程读取执行代码,例如 PowerShell 和 VBscript,而不是加载它。检测此类攻击具有挑战性。我们的系统枚举了大多数常见的脚本宿主,并将它们与正常进程分开对待。为了解决第二个挑战,我们通过基于粗粒度数据流的推理来跟踪可疑数据。例如,如果一个进程有网络连接,那么这个进程写入的任何文件都可能包含来自网络的数据。粗粒度的数据流可能会导致高误报率,但真报率保持不变。第 5 节的结果表明,即使使用粗粒度的数据流,我们的系统也可以以低误报率检测 APT。为了解决第三个挑战,我们跟踪控制流(特别是可疑线程创建的进程)。尽管它们可能是良性进程,但它们可用于实现攻击者的目标,例如抓取屏幕和泄露敏感数据。
枚举脚本能接受,毕竟确实不好检测。但是具体是怎么与正常进程区分开的呢?单独检测还是直接把宿主当作可疑的?
为什么粗粒度理论上会带来高误报,然而在没有任何改进的情况下实际误报率却很低?
4. 基于状态的框架
检测持久性技术是不切实际的。一方面,有 59 种已知的持久性技术并且检测它们可能很昂贵。另一方面,即使检测到进程是持久的,也不能将其视为恶意软件。攻击者可以在没有任何可疑行为的情况下潜伏很长时间。此外,恶意文件可以在下载几天后打开。因此,很难根据上下文信息检测攻击。
为了检测此类攻击,系统事件日志应长期存储,每天需要 GB 级的硬盘空间。多项研究旨在减小日志大小,但此类措施只能缓解此问题,因为攻击可能持续数年,数据应长期存储。此外,通过浏览这些日志来识别相关事件也需要时间。因此,来源图,也称为依赖图或信息图,通常用于更快地遍历日志。基于起源图的实时检测系统通常将它们存储在内存中,以便在计算和图匹配方面获得更好的性能,但图会随着时间的推移不断增长。由于 APT 可以在没有可疑行为的情况下长时间处于休眠状态,因此这些方法会遇到与存储不断增长的图形相关的内存问题以及与跟踪长期攻击相关的效率问题。如图 (a) 所示,实时和长期攻击几乎不可能执行这种类型的检测。


在本节中,我们提出了一个基于状态的框架。在这个框架中,进程和文件的每个实例都类似于一组自动机,这使我们能够通过聚合所有用于帮助检测的每个进程中的上下文信息,以低开销实时检测不同的攻击场景。如图 (b) 所示,我们首先制定语义识别、数据结构、状态转换条件和恶意状态的概念。接下来,我们将解释基于我们的框架重构攻击的方法。
4.1. 语义识别
我们的语义状态定义受到取证分析的启发;能够自动识别数据流、控制流和流程行为的高级语义。这些语义代表了在基于上下文的检测中使用的基本证据。我们将这种语义称为原子可疑指标 (ASIs)。一个ASI 包括以下语义类型之一,并通过相应的痕迹检测或推断:
- 攻击者为实现其目标而执行的行为。通常由 API 检测或由机密数据流推断
- 可疑代码的来源,即一个进程为什么会执行这样的行为;由不受信任的数据流推断
- 进行外部通信的能力,由网络活动推断
- 由不受信任的控制流推断出执行流程的原因
- 描述攻击的附加特征
每个 ASI 都可以描述为一个三元组: ⟨ N o , T y , D e ⟩ \langle N_o,T_y,D_e\rangle ⟨No,Ty,De⟩。每个 ASI 都分配了一个唯一的编号 N o N_o No,代表它在位图(bitmap)中的位置以记录状态。 T y T_y Ty 代表类别,包括以下几类: 1) 可疑代码源(CS,code source),跟踪潜在的不可信代码执行; 2) 可疑行为(Beh. ,suspicious behaviors); 3)网络连接(Net., network connections); 4)特征( Fea.,features),这是说明不同攻击场景的附加特征。 D e D_e De 表示用于以人类可读的语义解释检测结果的描述。这些 ASI 通过从源数据中直接提取或通过规则推断来识别。如果 1) 它具有与现有 ASI 不同的语义或 2) 有多种方法可以以不同的准确性识别相同的语义,则应声明一个可以帮助检测 APT 的新 ASI。表 1 列出了一组精选的 ASI。

一些 ASI 可以很容易地检测到或通过基于系统事件日志的推断生成。虽然攻击者通常执行的行为是最重要的 ASI 之一,但还没有成熟的方法来检测它们。为了应对这一挑战,我们对具有此类 ASI 的真实世界恶意软件进行了最大规模的研究,称为远程访问木马 (RAT)。
结果表明,RAT通常配备了数十个ASI,并且这些ASI的实现基本相同。我们开发了在不同层的数据源上检测它们的方法。为了平衡准确性和效率,我们按照[51]的思想(例如,如图4所示;箭头表示API之间的数据流,因此,行为必须按这样的顺序实现),基于它们的代码实现手动生成一组拓扑API签名来识别这些行为。 API 签名的覆盖率和真阳性率很高(90%),但可能存在歧义。例如,用于截屏的 API 也用于在 windows 中绘制图片;甚至序列保持不变(对于这两种用途,这些 API 用于将设备上下文的内容从一个复制到另一个)。为了应对这个挑战,我们采用一些外部信息来提高准确性(例如,我们发现屏幕抓取的API序列也可以用于绘制窗口,我们的解决方案是:当一个进程在没有可见窗口的情况下抓取屏幕那时,我们可以将其视为截图操作而不是绘图操作)。
[51] C. Kolbitsch, P. M. Comparetti, C. Kruegel, E. Kirda, X.-Y. Zhou, and X. Wang, “Effective and efficient malware detection at the end host,” in Proc. USENIX Secur. Symp., 2009, pp. 351–366.

【图片描述翻译】截屏签名的一个简单示例。同一框架中的API是实现相似功能的备选方案。签名根据其代码实现生成,顺序根据API之间的数据流转。
这里可能不太好理解,大概意思是,作者研究了很多远程访问木马 (RAT),根据他们的行为共同点,利用别人的技术生成了这些签名拓扑(其实就是这行为会如何调用哪些API、如何调用),并在状态自动机中通过匹配这些 API 拓扑来实现检测木马的恶意行为。同时对于有歧义会产生误报的特例(如截屏和绘图),作者进行了特殊处理。
为了实时高效地匹配这些拓扑 API 签名,我们将这些拓扑转换为 FSA 以将签名与流数据进行匹配,并且这些 API 应该在一个窗口中匹配到以减少误报。在实践中,我们采用 6 秒的时间窗口。我们不使用系统调用,因为它们的级别太低,无法反映语义。API调用通常使用沙盒API hook来记录,性能和稳定性较差,不能用于实时检测系统。我们使用 ETW 内核调用堆栈跟踪来恢复 API 调用。 ETW 可以捕获内核事件(包括 SysCallEnter 事件,表示对系统调用的调用)及其调用堆栈。我们有效地从调用堆栈中恢复 API。
4.2. 数据结构
为了支持实时分析和长期监控,我们提出了一种类似于主存 FSA 的结构来记录可能参与攻击的每个进程和文件的状态。我们不需要存储任何历史事件来执行检测,但为了重建攻击的额外目标,我们只保留一小部分使状态发生变化的事件到数据库中。

数据结构和操作。标签 P1、P10、P15、F1和F2是表1描述的状态;R1、R2和R6是表2描述的规则。这个例子记录了一个偷渡式下载攻击的过程。
还是依赖规则。本来能检测的阶段就少,然后检测的对象又是针对已有的木马进行分析得出来的通用规则,特殊性太强了。
如图5所示,我们将每个进程和文件处于特定状态时的基本信息和状态保存在内存中。每个进程实例都可以描述为一个五元组: ⟨ N a , P i , C l , U i , S t ⟩ \langle N_a,P_i,C_l,U_i,S_t\rangle ⟨Na,Pi,Cl,Ui,St⟩,包含了一个进程的基本信息。 N a N_a Na 是进程名称, P i P_i Pi 是进程 ID, C l C_l Cl 是命令行。由于 N a N_a Na 和 P i P_i Pi 可以重复,我们为每个实例分配一个唯一的 ID ( U i U_i Ui)。 S t S_t St 代表这个进程的状态。
每个文件实例都是一个三元组: ⟨ N a , U i , S t ⟩ \langle N_a,U_i,S_t\rangle ⟨Na,Ui,St⟩。 N a N_a Na代表文件路径, U i U_i Ui是唯一ID, S t S_t St 是状态。状态是预定义的,如第 4.1 节所述。一旦一个实例包含一个特定的状态,相应的位就被设置为真。
所有不活动的进程和文件都从内存中删除到数据库中,以确保内存不变。文件只有在被另一个进程操作时才会被覆盖。
4.3. 状态转换
我们的方法基于这样一种洞察力( insight),即相同类型的事件具有不同的高级语义,具体取决于所涉及的主体和客体之间的差异。例如,读取下载的文件不同于读取个人目录中的文件。前者涉及访问未知数据源,可能导致不可信代码执行,而后者涉及访问个人数据,最终可能导致用户数据泄露。这部分的目的是跟踪机密数据流、不可信数据流和不可信控制流。为了自动区分这些事件并记录语义,我们创建了一组预定义规则来为事件分配更详细的语义。表 2 中有一组选择性规则。

每个规则都是一个六元组: ⟨ N o , S s , E v , S o , D i , D e ⟩ \langle N_o,S_s,E_v,S_o,D_i,D_e\rangle ⟨No,Ss,Ev,So,Di,De⟩;
- N o N_o No 是规则的序号,用在一条边上,表示这个操作是如何产生的;
- S s S_s Ss 代表一个主体(object)的特定状态。在我们的设计中,主体始终是一个进程。
- S o S_o So 代表一个对象的特定状态。对象是进程、文件或 IP;
- E v E_v Ev 是主体对客体执行的事件;
- D i D_i Di,向前或向后,表示一个实体影响另一个实体的方向。
- D e D_e De 是对规则目的的描述,用于说明重构的攻击链。
当主体处于某种状态并对客体(subject)执行事件时,客体的状态发生了我们所说的正向变化,主体和客体分别是源和目的。相反,如果主体受到客体的影响,我们称之为反向。请注意,当 S s S_s Ss 和 S o S_o So 作为源时,它们可以是一种或多种状态。 系统中的每个实体都像一个DFA一样,由一个五元组表示: ⟨ S , Σ , δ , S 0 , F ⟩ \langle S,\Sigma,\delta,S_0,F\rangle ⟨S,Σ,δ,S0,F⟩。
- S S S:状态集
- Σ \Sigma Σ:输入,由系统事件 E v E_v Ev组成
- δ \delta δ:状态转换函数。状态 S f S_f Sf 已经存在于一个实体中,而状态 S l S_l Sl 则是在这个 E v E_v Ev涉及的另一个实体中新生成的
δ : S f × Σ → S l \delta:S_f\times\Sigma\to S_l δ:Sf×Σ→Sl - S 0 S_0 S0:初始状态。一旦一个新的进程或文件出现在我们的系统中,我们就会在内存中创建一个相应的实例。 S S S 中的所有位都设置为 f a l s e false false,只有可能包含机密数据的文件被初始化为 F5 状态。
- F F F:最终状态集。一旦进程进入其中一种状态,就会触发警报。
如图5所示,一个文件被推断是从网络下载的,因为一个有网络连接的进程向它写入数据。然后,一个新的进程加载这个下载的文件,结果,这个进程变成了一个表示这个语义的状态。换句话说,状态包括来自先前对象状态和此事件的语义。因此,在我们的系统中,我们不需要存储任何历史事件并且可以有效地检测攻击。
我觉得这里大概可以理解为,处于某个状态是由历史状态导致的,所以用状态做到了既不存储历史数据,又包含了上下文信息。
为了重建攻击以便更好地理解和进一步分析,我们将导致状态更改的事件存储到数据库中。事件存储有四个属性:规则号、时间戳、源和目的。
4.4. 恶意状态
恶意状态是指示检测所需的上下文信息的各个状态的各种组合。ASI 可分为 4 种不同类型:可疑代码源、网络连接、可疑行为和特征。如果一个进程包含前三个类别(不包括特征)中的每一个的至少一个 ASI,我们说它进入了恶意状态。每个恶意状态都说明了不同的攻击场景。例如,如果一个进程加载了从网络下载的未签名图像,执行恶意行为并连接到网络,我们将其识别为“下载并执行”攻击,并根据其执行的恶意行为知道攻击者的目标。如果主机中已经存在未签名的镜像,则可以将其识别为“现有恶意软件”。因此,我们不需要假设攻击的所有阶段都发生在 CONAN 开始监视系统之后,所有的检测过程都可以通过简单地检查一个进程的状态来完成。
利用多个通用特征来识别不同的攻击场景。例如,“人机交互”特征反映了一个进程是否自动运行,“无可见窗口”特征表明用户是否能够通过视觉识别出该进程的存在。如果特征越多,则恶意行为的置信度得分越高,代表不同的攻击场景。我们不使用任何文件、进程或域的白名单。在部署我们的系统之前安装的恶意软件也可以被检测为一种特殊的攻击场景。
4.5. 攻击重构
因为我们的系统将数据库中每个 ASI 的来源保存为状态之间的边,所以可以通过边回溯在线性时间内找到攻击的来源。对于正向分析,由于我们的系统可以立即检测到恶意进程,因此可疑进程几乎不会造成额外的影响;因此,前向跟踪没有依赖性爆炸。
5. 评估
5.1. 实施
采用 Windows 事件跟踪 (ETW) 作为主要数据提供者,主要内容包括系统调用、调用栈、应用级日志等。通过添加数据源来扩展 ETW,例如二进制文件的证书、人工交互和剪贴板。
所有状态、规则和恶意状态都是可定制的,并在大约 112 行的配置文件中指定。
5.2. 数据集
实验室、DARPA、真实企业。前 3 行对应于红队作为 DARPA 透明计算 (TC) 计划的一部分开展的攻击活动,后两行分别对应于我们研究实验室收集的攻击和良性数据,由我们的收集器在 Windows 上收集的。
- 文件读写不仅包括文件读/写,还包括一些额外的数据流,比如剪贴板。
每个数据集中原始文件读取事件的数量接近 40%,但通过以下优化,数量减少了大约 100 倍:当进程读取文件时,收集器忽略两个相邻写入事件之间的重复读取事件,因为该文件的状态在写入之前无法更改,因此该过程不会受到这些读取事件的影响。 - 进程/线程列包括进程和线程启动/结束事件。
- 网络仅包含 TCP 和 UDP 包,因为 ETW 无法提供低级网络事件。
- “其他”列包括我们为更好地理解攻击而收集的特征,包括图像证书、可见窗口和人机交互。 L-2 中的网络事件数量很大,因为用户在测试期间观看了很多电影。

5.3. 环境和实验装置
在我们实验室的两台主机上部署了 CONAN,并在一台主机 (L-1) 上实施了图 3a 中描述的攻击,此外还下载并安装了一组具有类似行为的良性应用程序。在另一台主机上运行我们的系统数周,以确保其长期稳定性和低误报率 (L-2)。
DARPA:检测到所有攻击都没有误报。因为在这些场景中,测试团队试图模拟严格的商业或政府环境,所以没有实施那些可能产生误报的行为,例如未签名的应用程序安装。重建结果并未涵盖攻击产生的所有活动。
真实环境:所有部署的机器都在他们的办公网络而不是他们的业务网络中。所有机器均可上网,由员工在办公时间操作。网络和机器也受到其他安全产品的保护,例如防病毒软件和防火墙。
5.4. 攻击场景和重建
介绍一次活动的详细检测结果,以说明 CONAN 如何检测这些攻击。表 4 列出了具有特定状态的所有检测结果。

如图 7a 所示,攻击者将网站重定向到另一个 IP 地址。
- 当用户尝试浏览该站点时,firefox.exe 进程将导航到伪造的 IP 地址 138.113.2.43。此时firefox被标记为P1,表示这个进程有外网流量
- 然后,攻击者就可以利用 Firefox 的漏洞成功远程执行代码。CONAN 会使用动态调用堆栈检测它,将此线程与受信任的线程分开并将其标记为 P12
- firefox被攻破后,攻击者首先执行 hostname 和 tasklist ,读取 Deafult.rdp,收集主机信息。 CONAN 记录分离的实体执行敏感命令和访问敏感文件
- 此时,由于该实体进入恶意状态而触发警报。该实体包括表 4 (D-1 firefox) 中列出的状态
- 然后,Firefox 下载二进制文件 cloud.exe。这个文件被标记为F1,这意味着它是从网络上下载的
- Firefox 创建进程 cloud,并加载未签名的映像 cloud.exe
- 最后,可疑进程进行截图,执行 whoami,将截图发送到一个新的IP地址,78.184.214.212
重构的攻击链如图 7b 和 7c所示。



5.5. 大规模真实世界部署
金融、通信、能源三家公司、64位 Windows 7/8/10、226台办公机器运行三个多月。3600万个进程中422个告警,14524个程序,如表5所示。
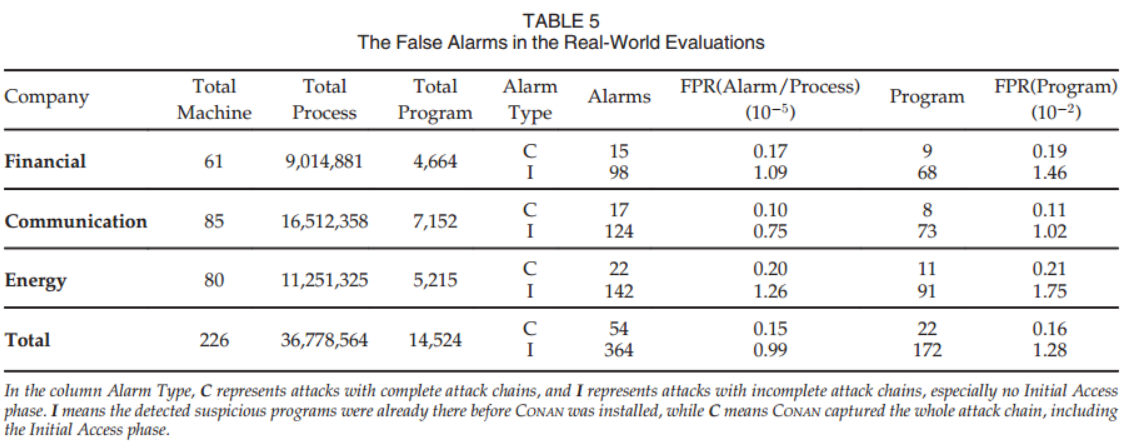
C代表攻击链完整的攻击,I 代表不完整的,没有初始访问阶段
不幸的是,我们使用威胁情报和沙盒检查所有这些警报。迄今为止,它们都没有被归类为恶意。我们将在下一节讨论误报。
5.6. 误报
实验室中 0 误报。真实环境中,有一些破解程序和重新打包的程序,很难确定它们是恶意的还是灰色的。部署CONAN之前就已存在的软件无法追踪下载源。
相关文章:
【论文阅读】CONAN:一种实用的、高精度、高效的APT实时检测系统(TDSC-2020)
CONAN:A Practical Real-Time APT Detection System With High Accuracy and Efficiency TDSC-2020 浙江大学 Xiong C, Zhu T, Dong W, et al. CONAN: A practical real-time APT detection system with high accuracy and efficiency[J]. IEEE Transactions on Dep…...
P1328 [NOIP2014 提高组] 生活大爆炸版石头剪刀布
题目描述 石头剪刀布是常见的猜拳游戏:石头胜剪刀,剪刀胜布,布胜石头。如果两个人出拳一样,则不分胜负。在《生活大爆炸》第二季第 8 集中出现了一种石头剪刀布的升级版游戏。 升级版游戏在传统的石头剪刀布游戏的基础上,增加了两个新手势: 斯波克:《星际迷航》主…...
基于Android水果蔬菜果蔬到家商城系统 微信小程序uniAPP的开发与实现
果蔬到家是商家针对用户必不可少的一个部分。在商铺发展的整个过程中,果蔬到家担负着最重要的角色。为满足如今日益复杂的管理需求,各类果蔬到家程序也在不断改进。本课题所设计的springboot基于HBuilder X的果蔬到家APP,使用SpringBoot框架&…...
【Python】从入门到上头—Python基础(2)
文章目录 一.基础语法1.编码2.标识符3.保留字4.注释5.行与缩进6.多行语句7.数字(Number)类型8.字符串(String)9.空行10.等待用户输入11.同一行显示多条语句12.多个语句构成代码组13.print 输出14.import 与 from...import 二.基本数据类型1.变量和赋值2.多个变量赋值3.标准数据…...
leetcode刷题之283:移动零
问题 实现思路 首先, 将dest指向-1 位置, cur指向下标为0 的位置, 在cur遍历的过程中: 1) 遇到非零元素则与下标dest1 位置的元素交换, 2) 若遇到零元素则只继续cur遍历. 下标为1 的位置上是 非零元素 执行1) 交换得到右图结果 随后cur 得到下图结果 下标为2 的位置上是零…...

【Spring Boot】SpringBoot和数据库交互: 使用Spring Data JPA
文章目录 1. 数据库和Java应用程序1.1 为什么需要数据库交互1.2 传统的数据库交互方法 2. 什么是JPA2.1 JPA的定义2.2 JPA的优势 3. Spring Data JPA介绍3.1 Spring Data JPA的特性3.2 如何简化数据库操作 4. 在SpringBoot中集成Spring Data JPA4.1 添加依赖4.2 配置数据源 5. …...
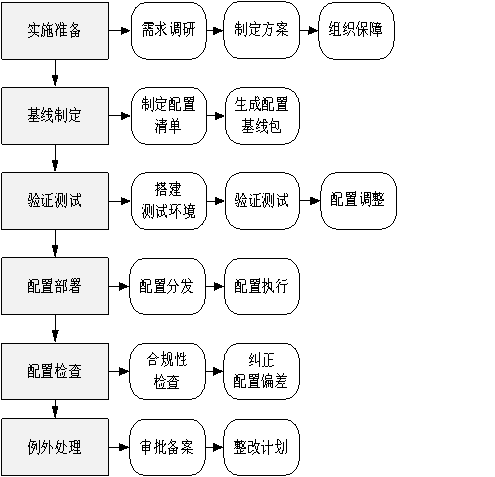
自动化部署及监测平台基本架构
声明 本文是学习 政务计算机终端核心配置规范. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 核心配置自动化部署及监测技术要求 自动化部署及监测平台基本架构 对于有一定规模的政务终端核心配置应用,需要配备自动化部署及监测平台&am…...
基于NXP i.MX 6ULL核心板的物联网模块开发案例(1)
目录 前 言 1 SDIO WIFI模块测试 1.1 STA模式测试 1.2 AP模式测试 1.3 SDIO WIFI驱动编译 前言 本文主要介绍基于创龙科技TLIMX6U-EVM评估板的物联网模块开发案例,适用开发环境: Windows开发环境:Windows 7 64bit、Windows 10 64bit …...
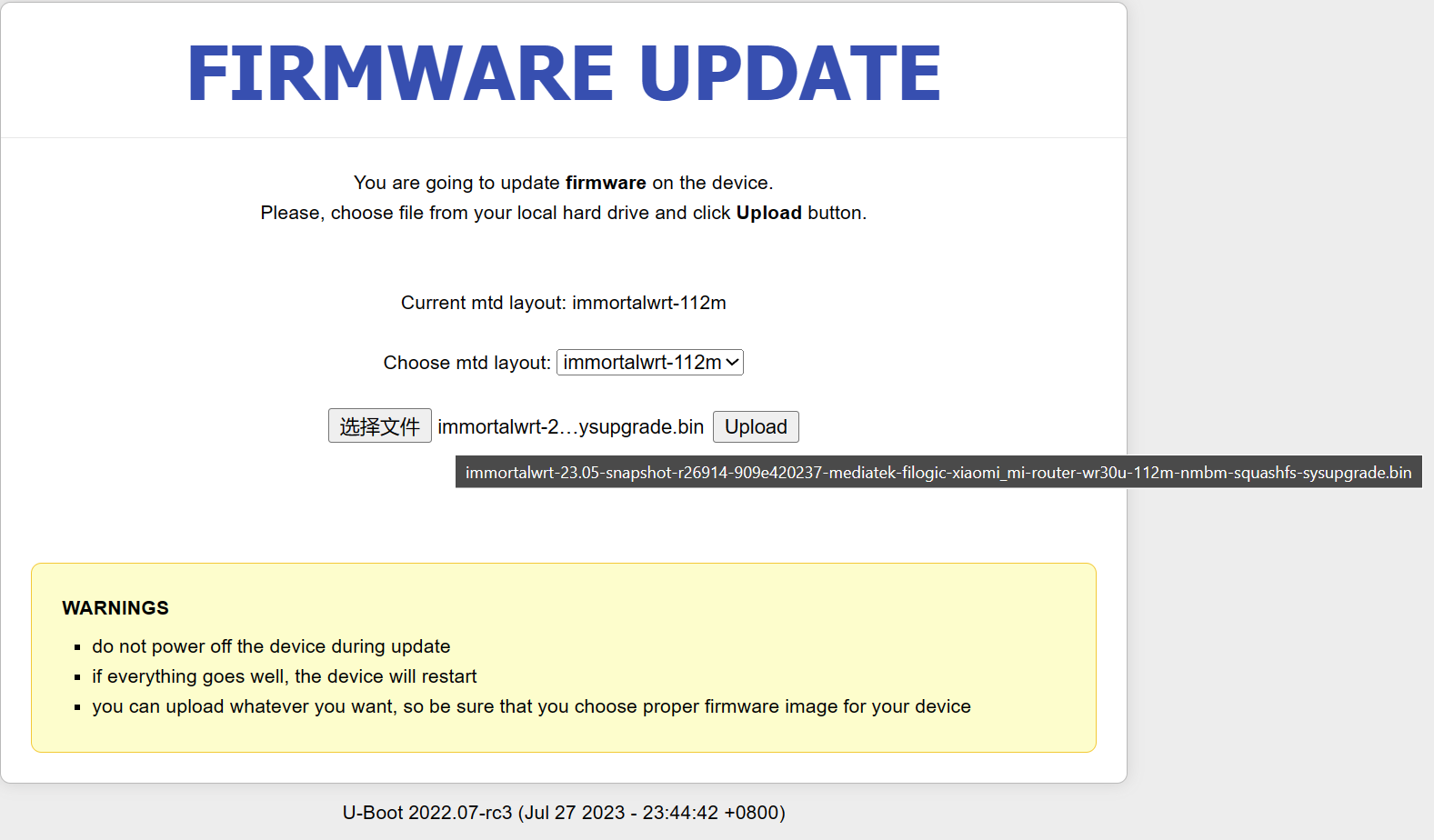
【路由器】小米 WR30U 解锁并刷机
文章目录 解锁 ssh环境准备解锁过程 刷入 mt798x uboot简介刷入流程 刷入 ImmortalWrt简介刷入流程 刷为原厂固件参考资料 本文主要记录个人对小米 WR30U 路由器的解锁和刷机过程,整体步骤与 一般安装流程 类似,但是由于 WR30U 的解锁 ssh 和刷机的过程中…...

数据库操作语句
一,SQL分类 DDL:数据定义语言 DML:数据操纵语言 DQL:数据查询语言 DCL:数据控制语言 创建数据库和表 #创建数据库 create database 数据库名; #创建数据表 create table 表名 (字段1 字段1类型(字段长度) 字段限制,字…...
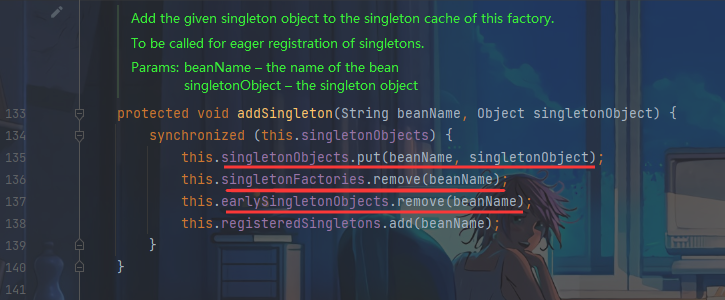
Mr. Cappuccino的第64杯咖啡——Spring循环依赖问题
Spring循环依赖问题 什么是循环依赖问题示例项目结构项目代码运行结果 Async注解导致的问题使用Lazy注解解决Async注解导致的问题开启Aop使用代理对象示例项目结构项目代码运行结果 Spring是如何解决循环依赖问题的原理源码解读 什么情况下Spring无法解决循环依赖问题 什么是循…...

Adapting Language Models to Compress Contexts
本文是LLM系列文章,针对《Adapting Language Models to Compress Contexts》的翻译。 使语言模型适应上下文压缩 摘要1 引言2 相关工作3 方法4 实验5 上下文学习6 压缩检索语料库实现高效推理7 结论不足 摘要 1 引言 2 相关工作 3 方法 4 实验 5 上下文学习 …...

Kubernetes(K8S)使用PV和PVC做存储安装mysql
Kubernetes使用PV和PVC做存储安装mysql 环境准备什么是PV和PVC环境准备配置nfs安装nfs配置nfs服务端 创建命名空间配置pv和pvcpv的yaml文件pvc的yaml文件 部署mysql创建mysql的root密码的secret创建mysql部署的yaml部署mysql链接mysql外部链接内部链接 环境准备 首先你需要一个…...

Ansible Playbook 常用变量
以下是 Ansible Playbook 常用变量 ansible_connection: 指定连接类型(如 ssh、winrm) ansible_user: 指定远程用户 ansible_ssh_pass: 指定远程用户密码 ansible_become: 指定是否切换为超级用户 ansible_become_user: 指定切换到的用户 ansible_b…...
0103水平分片-jdbc-shardingsphere-中间件
文章目录 1 准备服务器1.1 创建server-order0容器1.2 创建server-order1容器 2、基本水平分片2.1、基本配置2.2、数据源配置2.3、标椎分片表配置2.4、行表达式2.5、分片算法配置2.6、分布式序列算法 3、多表关联3.1、创建关联表3.2、创建实体类3.3、创建Mapper3.4、配置关联表3…...
Vue2.0+webpack 引入字体文件(eot,ttf,woff)
webpack.base.config.js 需要配置 {test:/\/(woff2?|eot|ttf|otf)(\?.*)?$/,loader: url-loader,options: {limit: 10000,name: utils.assetsPath(fonts/[name].[hash:7].[ext])}} 如果 Vue2.0webpack3.6引入字体文件(eot,ttf,woff&…...


WPF入门到精通:3.MVVM简单应用及全局异常处理
MVVM简介 在WPF应用程序开发中,MVVM(Model-View-ViewModel)是一种非常流行的架构模式。它为应用程序的设计提供了良好的分层结构和可扩展性。 结构分为下列三部分 Model:定义了应用程序的数据模型 就是系统中的对象,…...

Springboot+mybatis-plus+dynamic-datasource+Druid 多数据源 分布式事务
Springbootmybatis-plusdynamic-datasourceDruid 多数据源事务,分布式事务 文章目录 Springbootmybatis-plusdynamic-datasourceDruid 多数据源事务,分布式事务0.前言1. 基础介绍ConnectionFactoryAbstractRoutingDataSource 动态路由数据源的抽象类 Dyn…...

673. 最长递增子序列的个数
673. 最长递增子序列的个数 原题链接:完成情况:解题思路:方法一:动态规划方法二:贪心 前缀和 二分查找 参考代码:__673最长递增子序列的个数__动态规划__673最长递增子序列的个数__贪心_前缀和_二分查找…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...
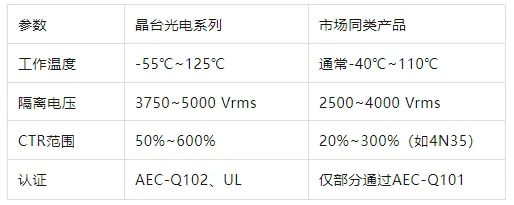
高抗扰度汽车光耦合器的特性
晶台光电推出的125℃光耦合器系列产品(包括KL357NU、KL3H7U和KL817U),专为高温环境下的汽车应用设计,具备以下核心优势和技术特点: 一、技术特性分析 高温稳定性 采用先进的LED技术和优化的IC设计,确保在…...

计算机系统结构复习-名词解释2
1.定向:在某条指令产生计算结果之前,其他指令并不真正立即需要该计算结果,如果能够将该计算结果从其产生的地方直接送到其他指令中需要它的地方,那么就可以避免停顿。 2.多级存储层次:由若干个采用不同实现技术的存储…...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...