unet pytorch
1.单机多卡版本:代码中的DistributedDataParallel (DDP) 部分对应单机多卡的分布式训练方式
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import RandomHorizontalFlip, RandomVerticalFlip, RandomRotation, RandomResizedCrop, ToTensor
from torch.nn.parallel import DistributedDataParallel as DDP# 定义ResNet块
class ResNetBlock(nn.Module):def __init__(self, in_channels, out_channels):super(ResNetBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):residual = xout = self.conv1(x)out = self.relu(out)out = self.conv2(out)out += residualout = self.relu(out)return out# 定义UNet模型
class UNet(nn.Module):def __init__(self, in_channels, out_channels):super(UNet, self).__init__()self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3, padding=1)self.block1 = ResNetBlock(64, 64)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.block2 = ResNetBlock(128, 128)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.block3 = ResNetBlock(256, 256)self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.Conv2d(256, 512, kernel_size=3, padding=1self.block4 = ResNetBlock(512, 512)self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.conv5 = nn.Conv2d(128, out_channels, kernel_size=1)def forward(self, x):x1 = self.conv1(x)x1 = self.block1(x1)x2 = self.pool1(x1)x2 = self.conv2(x2)x2 = self.block2(x2)x3 = self.pool2(x2)x3 = self.conv3(x3)x3 = self.block3(x3)x4 = self.pool3(x3)x4 = self.conv4(x4)x4 = self.block4(x4)x = self.upconv3(x4)x = torch.cat((x, x3), dim=1)x = self.conv5(x)x = self.upconv2(x)x = torch.cat((x, x2), dim=1)x = self.upconv1(x)x = torch.cat((x, x1), dim=1)x = self.conv5(x)return x# 定义数据集类
class CustomDataset(Dataset):def __init__(self, data_dir, transform=None):self.data = # Load data from data_dirself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):image, mask = self.data[index]if self.transform:image = self.transform(image)mask = self.transform(mask)return image, mask# 设置训练参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 10
batch_size = 4# 创建UNet模型和优化器
model = UNet(in_channels=3, num_classes=2).to(device)
model = DDP(model)optimizer = optim.Adam(model.parameters(), lr=0.001)# 定义数据增强方法
transform = transforms.Compose([RandomHorizontalFlip(),RandomVerticalFlip(),RandomRotation(15),RandomResizedCrop(256, scale=(0.8, 1.0)),ToTensor(),
])# 加载数据集并进行数据增强
dataset = CustomDataset(data_dir="path_to_dataset", transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)# 训练循环
for epoch in range(num_epochs):model.train()total_loss = 0.0for images, masks in dataloader:images = images.to(device)masks = masks.to(device)optimizer.zero_grad()outputs = model(images)loss = nn.CrossEntropyLoss()(outputs, masks)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(dataloader)}")
2.多机多卡版本:使用torch.utils.data.distributed.DistributedSampler和torch.distributed.init_process_group来实现多机多卡的分布式训练,确保在每个进程中都有不同的数据划分和完整的通信。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.nn.parallel import DistributedDataParallel
from torchvision.transforms import transforms
from torchvision.datasets import YourDataset
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist# 定义ResNet块
class ResNetBlock(nn.Module):def __init__(self, in_channels, out_channels):super(ResNetBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):residual = xout = self.conv1(x)out = self.relu(out)out = self.conv2(out)out += residualout = self.relu(out)return out# 定义UNet模型
class UNet(nn.Module):def __init__(self, in_channels, out_channels):super(UNet, self).__init__()self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3, padding=1)self.block1 = ResNetBlock(64, 64)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.block2 = ResNetBlock(128, 128)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.block3 = ResNetBlock(256, 256)self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.Conv2d(256, 512, kernel_size=3, padding=1self.block4 = ResNetBlock(512, 512)self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.conv5 = nn.Conv2d(128, out_channels, kernel_size=1)def forward(self, x):x1 = self.conv1(x)x1 = self.block1(x1)x2 = self.pool1(x1)x2 = self.conv2(x2)x2 = self.block2(x2)x3 = self.pool2(x2)x3 = self.conv3(x3)x3 = self.block3(x3)x4 = self.pool3(x3)x4 = self.conv4(x4)x4 = self.block4(x4)x = self.upconv3(x4)x = torch.cat((x, x3), dim=1)x = self.conv5(x)x = self.upconv2(x)x = torch.cat((x, x2), dim=1)x = self.upconv1(x)x = torch.cat((x, x1), dim=1)x = self.conv5(x)return x# 定义数据集类
class CustomDataset(Dataset):def __init__(self, data_dir, transform=None):self.data = # Load data from data_dirself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):image, mask = self.data[index]if self.transform:image = self.transform(image)mask = self.transform(mask)return image, maskdef main(rank, world_size):# 设置分布式训练参数torch.cuda.set_device(rank)torch.distributed.init_process_group(backend='nccl', init_method='env://', world_size=world_size, rank=rank)# 设置训练参数num_epochs = 10batch_size_per_gpu = 4# 创建UNet模型和优化器in_channels = 3model = UNet(in_channels=3, num_classes=2).cuda(rank)model = DistributedDataParallel(model, device_ids=[rank])optimizer = optim.Adam(model.parameters(), lr=0.001)# 数据增强方法transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(30),transforms.RandomResizedCrop(256, scale=(0.8, 1.2)),transforms.ToTensor()])# 加载训练集和验证集train_dataset = CustomDataset(transform=transform)train_sampler = DistributedSampler(train_dataset)train_loader = DataLoader(train_dataset, batch_size=batch_size_per_gpu, sampler=train_sampler)# 训练循环for epoch in range(num_epochs):model.train()total_loss = 0.0for images, masks in train_loader:images = images.cuda(rank)masks = masks.cuda(rank)# 执行前向传播和反向传播optimizer.zero_grad()outputs = model(images)loss = F.binary_cross_entropy_with_logits(outputs, masks)loss.backward()optimizer.step()total_loss += loss.item()if world_size > 1:torch.distributed.all_reduce(total_loss)total_loss /= len(train_sampler)print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {total_loss:.4f}")def main_multi_gpu():world_size = torch.cuda.device_count()if world_size > 1:torch.multiprocessing.spawn(main, args=(world_size,), nprocs=world_size, join=True)else:main(0, 1)if __name__ == '__main__':main_multi_gpu()
相关文章:

unet pytorch
1.单机多卡版本:代码中的DistributedDataParallel (DDP) 部分对应单机多卡的分布式训练方式 import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from torchvisi…...
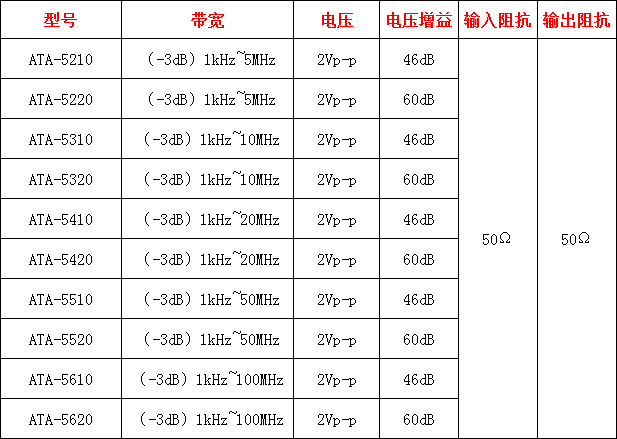
前置微小信号放大器的作用是什么
前置微小信号放大器是一种电子设备,用于将弱信号放大到足够的水平以供后续处理。它在许多领域都有广泛的应用,如通信系统、无线电接收机、传感器接口等。 前置微小信号放大器的主要作用是增加信号的强度。当我们处理微弱信号时,如果不进行放大…...
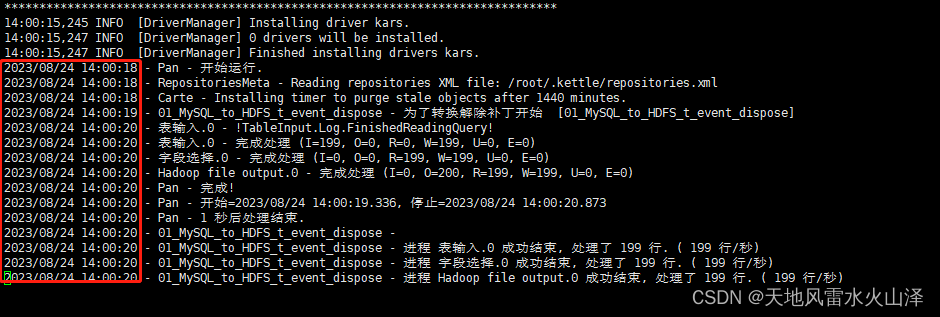
一百六十五、Kettle——用海豚调度器调度Linux资源库中的kettle任务脚本(亲测、附流程截图)
一、目的 在Linux上脚本运行kettle的转换任务、无论是Linux本地还是Linux资源库都成功后,接下来就是用海豚调度Linux上kettle任务 尤其是团队开发中,基本都要使用共享资源库,所以我直接使用海豚调度Linux资源库的kettle任务脚本 二、前提条…...

xfs ext4 结合lvm 扩容、缩容 —— 筑梦之路
ext4 文件系统扩容、缩容操作 扩容系统根分区 根文件系统在 /dev/VolGroup/lv_root 逻辑卷上,文件系统类型为ext4,大小为10G,现在要将其扩容成20G。 给空闲空间分区# 调整分区类型为LVM,也就是8e类型 fdisk /dev/sdb# 选定分区后使…...
)
如何修改由 img 标签引入的 svg 图片颜色 (react环境)
网上试了好几个方法都不行,问了一下身边同事的处理方法,终于搞定了。话不多说,直接上代码: 此处是 jsx 中的图标引入 <img className{STYLE.contactIcon}onClick{() > {你的一些操作}} style{{WebkitMaskImage: url(${ite…...
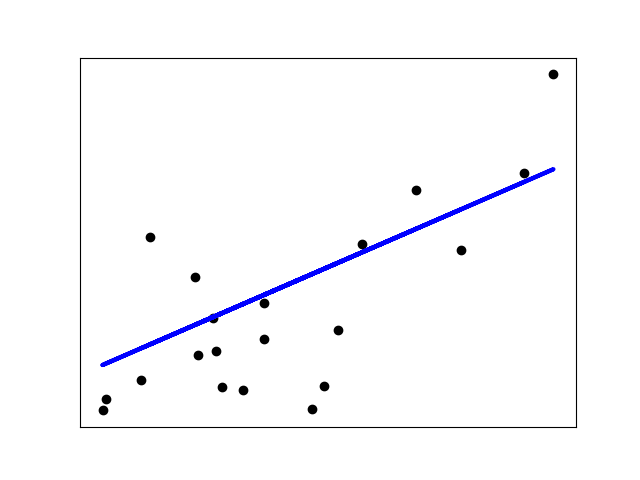
归一化的作用,sklearn 安装
目录 归一化的作用: 应用场景说明 sklearn 准备工作 sklearn 安装 sklearn 上手 线性回归实战 归一化的作用: 归一化后加快了梯度下降求最优解的速度; 归一化有可能提高精度(如KNN) 应用场景说明 1)概率模型不需要归一化ÿ…...

半导体企业如何进行跨网数据传输,又能保护核心数据安全?
为了保护设计文档、代码文件等内部核心数据,集成电路半导体企业一般会将内部隔离成多个网络,比如研发网、办公网、生产网、测试网等。常规采取的网络隔离手段如下: 1、云桌面隔离:一方面实现数据不落地,终端数据安全有…...
lvs-DR模式:
lvs-DR数据包流向分析 客户端发送请求到 Director Server(负载均衡器),请求的数据报文(源 IP 是 CIP,目标 IP 是 VIP)到达内核空间。 Director Server 和 Real Server 在同一个网络中,数据通过二层数据链路…...
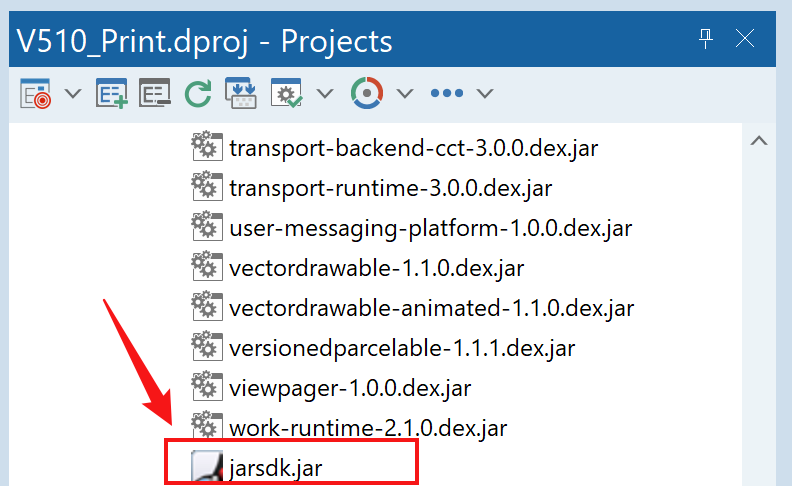
Delphi 开发手持机(android)打印机通用开发流程(举一反三)
目录 一、场景说明 二、厂家应提供的SDK文件 三、操作步骤: 1. 导出Delphi需要且能使用的接口文件: 2. 创建FMX Delphi项目,将上一步生成的接口文件(V510.Interfaces.pas)引入: 3. 将jarsdk.jar 包加入到 libs中…...

nodejs替换模版中${}的内容
要在js中想要替换替换模板中的${},可以使用字符串的replace()方法结合正则表达式或者函数来实现替换操作。 以下是两种常见的替换方式: 使用正则表达式: 方法一: const template "Hello, ${name}! Today is ${day}."…...
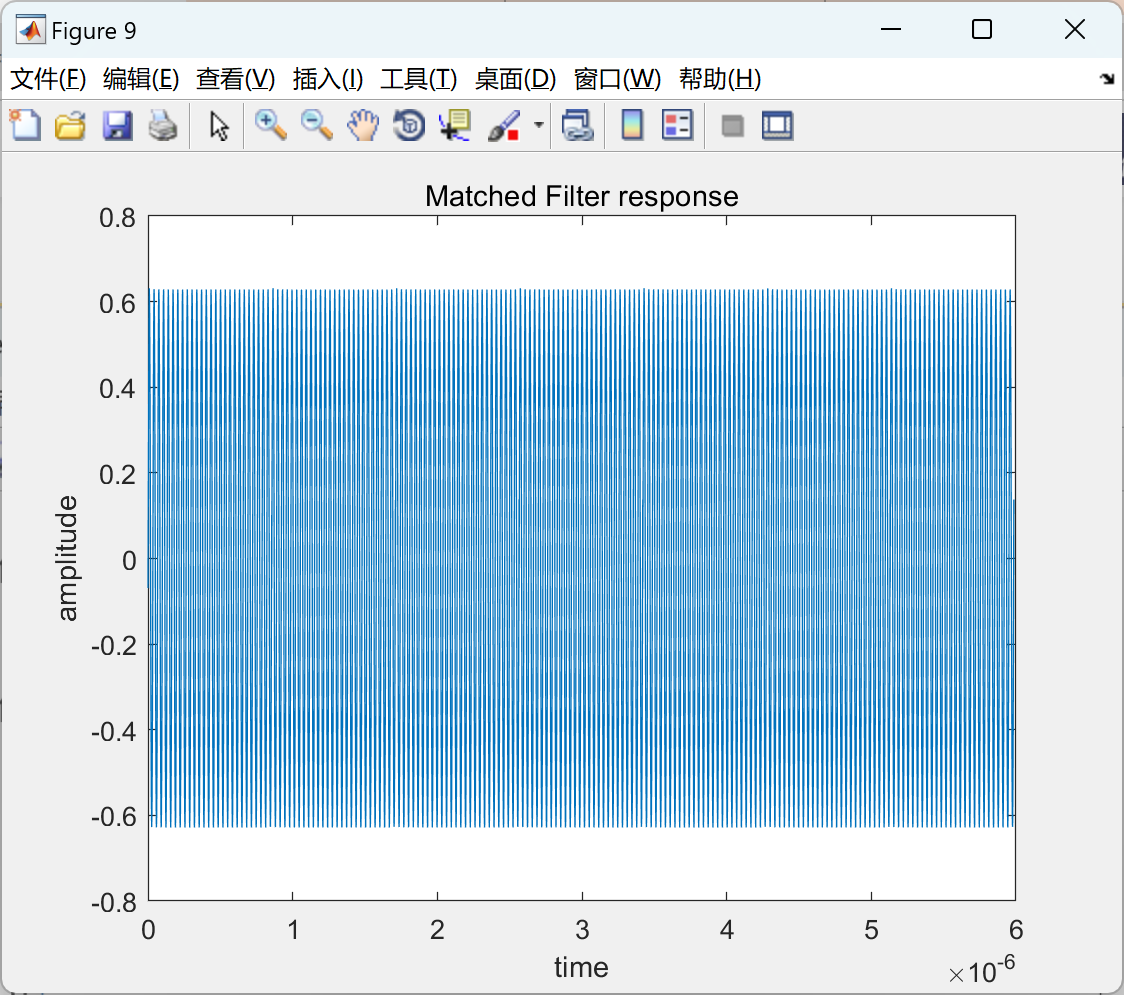
【快速傅里叶变换(fft)和逆快速傅里叶变换】生成雷达接收到的经过多普勒频移的脉冲雷达信号(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
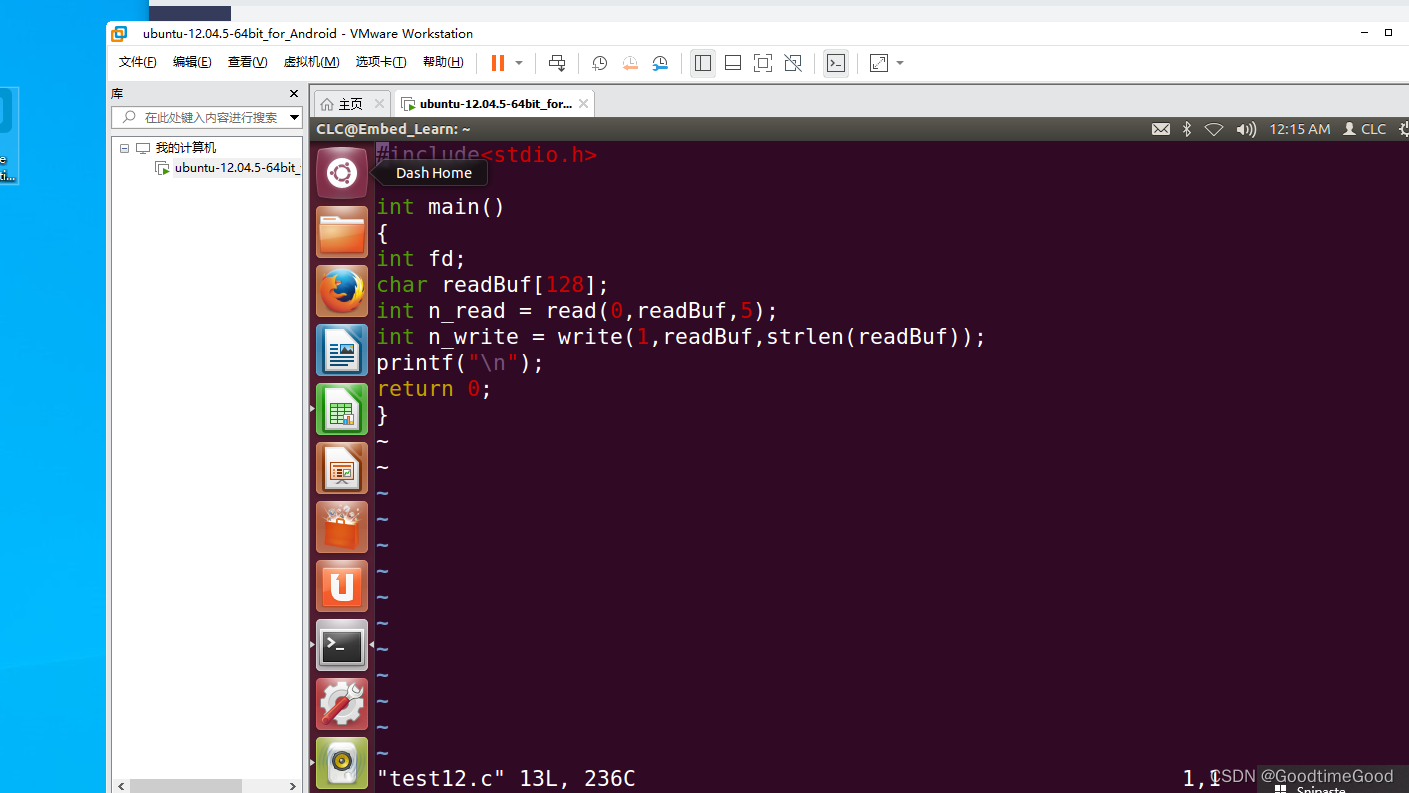
嵌入式学习之linux
今天,主要对linux文件操作原理进行了学习,主要学习的内容就是对linux文件操作原理进行理解。写的代码如下:...

自动驾驶合成数据科普一:不做真实数据的“颠覆者”,做“杠杆”
前言: 在7月底的一篇文章中,九章智驾提到,数据闭环能力是自动驾驶下半场的“入场券”,这一观点在行业内引起了广泛共鸣。 在数据闭环体系中,仿真技术无疑是非常关键的一环。仿真的起点是数据,而数据又分为真…...
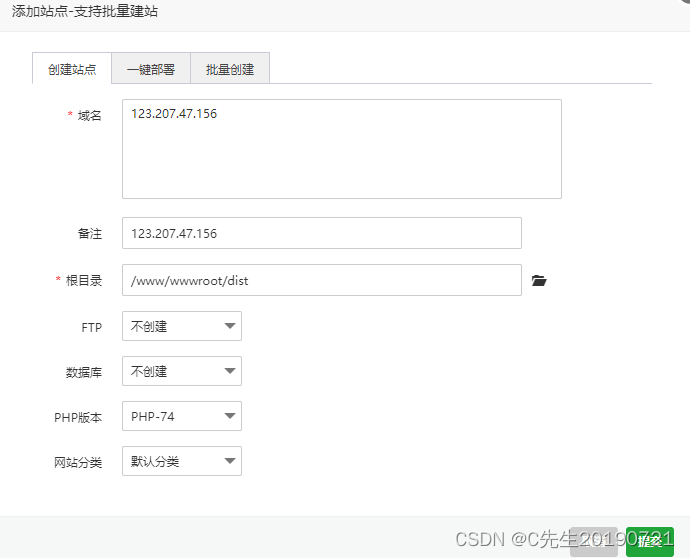
云服务器 宝塔(每次更新)
su root 输入密码 使用 root 权限 /etc/init.d/bt default 获取宝塔登录 位置和账号密码。进入宝塔 删除数据库 删除php前端站点 删除PM2后端项目 前端更改完配置打包dist文件 后端更改完配置项目打包 数据库结构导出 导入数据库 配置 PM2 后端 安装依赖...
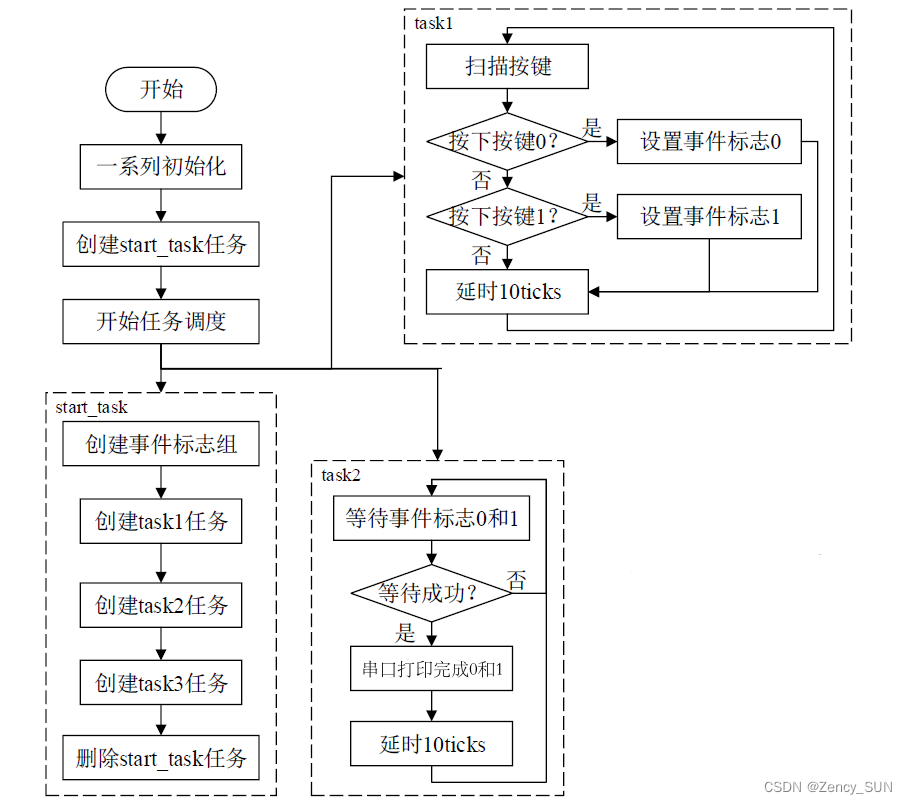
【学习FreeRTOS】第16章——FreeRTOS事件标志组
1.事件标志组简介 事件标志位:用一个位,来表示事件是否发生 事件标志组是一组事件标志位的集合, 可以简单的理解事件标志组,就是一个整数。 事件标志组的特点: 它的每一个位表示一个事件(高8位不算&…...

Echarts 柱状图的 itemStyle的normal中label如何format?
在 Echarts 中,可以通过设置 formatter 属性来对柱状图的标签进行自定义格式化。例如: itemStyle: {normal: {label: {show: true,formatter: function(params) {return params.value.toFixed(2); // 将标签内容保留两位小数}}} } 在上面的例子中&…...

我的笔记:数据体系规则
1、中台数据体系特征 覆盖全域数据:数据集中建设,覆盖所有业务过程数据; 结构层次清晰:纵向数据分层,横向主题域,业务过程划分,让整个层析结构清晰易理解; 数据准确一致:…...

苍穹外卖 day2 反向代理和负载均衡
一 前端发送的请求,是如何请求到后端服务 前端请求地址:http://localhost/api/employee/login 路径并不匹配 后端接口地址:http://localhost:8080/admin/employee/login 二 查找前端接口 在这个页面上点击f12 后转到networ验证࿰…...

【SpringBoot】SpringBoot完整实现电子商务系统
一个完整的电子商务系统需要涉及到前台展示、后台管理、商品管理、订单管理、用户管理等各方面。这里提供一个简单的实现示例,供参考。 前端代码 前端使用Vue框架,以下是部分代码示例: 商品列表页: <template><div>…...
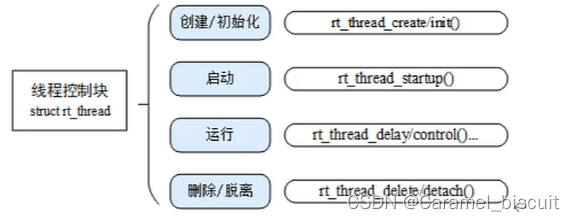
RT-Thread 线程管理(学习二)
线程相关操作 线程相关的操作包括:创建/初始化、启动、运行、删除/脱离。 动态线程与静态线程的区别:动态线程是系统自动从动态内存堆上分配栈空间与线程句柄(初始化heap之后才能使用create创建动态线程),静态线程是…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...