【论文阅读】POIROT:关联攻击行为与内核审计记录以寻找网络威胁(CCS-2019)
POIROT: Aligning Attack Behavior with Kernel Audit Records for Cyber Threat Hunting
CCS-2019
伊利诺伊大学芝加哥分校、密歇根大学迪尔伯恩分校
Milajerdi S M, Eshete B, Gjomemo R, et al. Poirot: Aligning attack behavior with kernel audit records for cyber threat hunting[C]//Proceedings of the 2019 ACM SIGSAC conference on computer and communications security. 2019: 1795-1812.
目录
- 0. 摘要
- 1. 引言
- 2. 相关工作
- 3. 方法概述
- 3.1. 溯源图的构建
- 3.2. 查询图的构建
- 3.3. 图对齐(Graph Alignment)
- 4. 算法
- 4.1. 对其度量
- 4.1.1. 影响分数
- 4.1.2. 对齐分数
- 4.2. 尽力相似搜索
0. 摘要
网络威胁情报 (CTI,Cyber threat intelligence) 用于搜索可能已经长期危害企业网络但未被发现的攻击的表征。为了进行更有效的分析,CTI 开放标准纳入了描述性关系,显示表征或可观察值之间的关系。然而,这些关系要么在信息收集中被完全忽略,要么不用于威胁搜寻。
在本文中,我们提出了一个名为 Poirot 的系统,它使用这些相关性来揭示成功攻击活动的步骤。
我们使用内核审计作为可靠来源,涵盖系统实体之间的所有因果关系和信息流,并将威胁搜寻建模为不精确的图形模式匹配问题。们的技术方法基于一种新颖的相似性度量,该度量评估由 CTI 相关性构建的查询图与由内核审计日志记录构建的溯源图之间的一致性。
使用 DARPA 进行评估,评估结果表明,Poirot 能够在包含数百万个节点的图形内部进行搜索,并在几分钟内查明攻击,结果表明 CTI 相关性可以用作威胁搜寻的稳健可靠的工件。
1. 引言
当组织内部检测到的高级持续性威胁 (APT) 相关的妥协表征 (IOC,Indicators of Compromise) 出现时,就需要安全分析师判断企业是否已成为APT的目标,这个过程称为威胁搜寻。高置信度地回答这个问题往往需要对企业的主机和网络日志进行冗长复杂的搜索和分析,从这些日志中识别出现在IOC描述中的实体,最终评估特定APT成功渗透企业的可能性。
一般而言,企业内部的威胁搜寻面临多项挑战:
- 大规模搜索(主要是时间上,对应APT的“P”的特点)
- 鲁棒(robust)地识别和关联威胁相关实体(揭示整个场景)
- 高效匹配(高效率低误报)
通常,有关 APT 活动中使用的恶意软件的知识发布在网络威胁情报 (CTI) 报告中,并以自然语言、结构化和半结构化形式等多种形式呈现。为了以 IOC 的形式促进 CTI 的顺利交换并能够表征对抗性技术、策略和程序 (TTP),安全社区采用了开放标准,例如 OpenIOC、STIX 和 MISP 为了更好地概述攻击,这些标准通常包含描述性关系,显示表征或可观察值如何相互关联。
文章的所使用的IOC来自MISP和STIX
然而,绝大多数当前的威胁搜寻方法要么仅针对网络威胁的碎片化视图,例如签名、可疑文件/进程名称和 IP 地址,要么通过使用时间戳等启发式方法来关联可疑事件。这些方法很有用但也有局限性:
- 无法准确揭示威胁如何展开的全貌,尤其是在长时间内(即APT时间,数周数月甚至数年)
- 容易受到错误信号的影响或无法区分攻击与良性系统活动(即无法应对APT的高隐蔽性和丰富的检测规避手段)
- 依赖低级签名,在面临攻击者更改或更新工具时无效
为了克服这些限制并建立强大的检测系统,必须考虑 IOC 之间的相关性。事实上,IOC 工件之间的关系包含有关受感染系统内部攻击行为的基本线索,这与攻击者的目标相关,因此更难以更改。(因此将 IOC 作为检测依据更可靠)
本文从 CTI 报告和 IOC 描述中形式化了威胁搜寻问题,开发了一种严格的方法来推导表示攻击活动成功可能性的置信度分数,并描述了一个名为 Poirot 的系统来实现这种方法。简而言之,给定一个基于图形的 IOC 表示和它们之间的关系来表达 APT 的整体行为,我们称之为查询图,我们的方法能够有效地在包含长时间内核审计日志的溯源图中查找是否有这个查询图的嵌入。假设内核审计日志不会受到未经授权的篡改,且可靠地包含了系统实体之间的关系。
也即,将IOC用图关系来描述,作为一个子图。作者的方法能够快速在溯源图中查找这个子图得存在性以检测恶意行为。
更准确地说,我们将威胁搜寻表述为图形模式匹配 (GPM) 问题,用于搜索与查询图中描述的系统实体相似的系统实体之间的因果依赖关系或信息流。为了稳健地抵御旨在影响匹配的规避攻击(例如,模仿攻击),我们根据攻击者产生的成本对流进行优先级排序。鉴于图匹配问题的 NP 完全性,我们提出了一个近似函数和一个新颖的相似性度量来评估查询图和溯源图之间的相似度。
我们使用三个不同的数据集测试 Poirot 的有效性和效率,DARPA、公开可用的真实世界事件报告、普通用户产生的无攻击活动。我们已经为 Linux、FreeBSD 和 Windows 实现了不同的内核日志解析器,我们的评估结果表明 Poirot 可以在包含数百万个节点的图形中搜索并在几分钟内查明攻击。
2. 相关工作
这一节作者分别介绍了以下几个方面的前人的相关工作。我这里就不再赘述了。读者感兴趣的话可以自行阅读原文。
- 基于日志的攻击分析
- 溯源图探索
- 查询处理系统(SAQL、AIQL、CamQuery)
- 行为发现
- 图模式匹配
3. 方法概述
方法整体视图如下所示:

3.1. 溯源图的构建
为了确定 APT 的行为是否出现在系统中,我们将内核审计日志建模为带标签的、有类型的和有向图,我们称之为溯源图 ( G p G_p Gp)。在此图中,节点表示内核审计日志中涉及的系统实体,它们具有文件和进程等不同类型,而边缘表示考虑方向的这些节点之间的信息流和因果关系。
POIROT支持利用来自 Microsoft Windows、Linux 和 FreeBSD 的内核审计日志,并在内存中构建一个溯源图。为了支持在此图上进行高效搜索,我们利用其他方法(例如快速散列技术和反向索引)将进程/文件名映射到唯一节点 ID。
3.2. 查询图的构建
我们从与已知攻击相关的 CTI 报告中提取 IOC 以及它们之间的关系。这些 IOC 除了自然语言之外,通常也以结构化或半结构化的方式出现。这些格式包括 OpenIOC、STIX、MISP 等。这些标准描述通常由安全操作员手动创建。
此外,还构建了自动化工具来自动从自然语言中提取 IOC 并补充人类操作员的工作。这些工具可用于执行初始特征提取以生成查询图,然后由安全专家手动完善。我们认为手动细化是查询图构建的重要组成部分,因为自动化方法通常会产生噪音并降低查询图的质量。
人工参与这个点见仁见智吧。从完美主义的角度来看,自然语言的威胁情报数量也不在少数,依赖人工去完善工作量不小且质量参差不齐。而且由于APT中“advance”的特点,致命攻击往往来自能够逃逸检测系统的新型攻击,这种新型攻击的威胁情报在一开始大多都是以非结构化形式出现的,在引起足够重视和深入调查之后才会有结构化数据出现。考虑到这不是作者的主要贡献,而且这个方案也并不追求时效性,只是通过这个让查询图的信息来源覆盖面更广的同时降低误报而已,也就无关紧要了。
我们也将 CTI 报告中出现的行为建模为标记的、类型化的有向图,我们称之为查询图 ( G q G_q Gq)。查询图的节点和边可以进一步与附加信息相关联,例如标签(或名称)、类型(例如,进程、文件、套接字、管道等)和其他注释(例如,哈希值、创建时间等)取决于分析师可能认为匹配所需的信息。在当前的 Poirot 实现中,我们使用名称和类型来指定查询图中的节点与来源图中的节点之间的显式映射。
结构化数据也需要人工了。。。
这个显示映射应该是指用名称和类型的哈希来为节点分配id,确保查询图和溯源图的相同节点能匹配上。
作为查询图构造的示例,考虑以下关于我们评估中使用的 DeputyDog 恶意软件的报告的摘录。
 第一句话清楚地表示一个写入文件的进程(恶意软件在执行时将文件写入一个位置)。我们指出,此摘录中的详细程度在大多数 CTI 报告中都很常见,并且可以由合格的网络分析师转换为可靠的查询图。特别是,表示主体执行的动作的动词通常可以很容易地映射到磁盘或网络的读/写以及进程之间的交互(例如,浏览器下载文件,进程产生另一个进程,用户单击在鱼叉式网络钓鱼链接等上)。
第一句话清楚地表示一个写入文件的进程(恶意软件在执行时将文件写入一个位置)。我们指出,此摘录中的详细程度在大多数 CTI 报告中都很常见,并且可以由合格的网络分析师转换为可靠的查询图。特别是,表示主体执行的动作的动词通常可以很容易地映射到磁盘或网络的读/写以及进程之间的交互(例如,浏览器下载文件,进程产生另一个进程,用户单击在鱼叉式网络钓鱼链接等上)。
既然大多数情报都这么详细全面且易转化的话,那确实不依赖专家知识了,人工成本低了不少。
图 2 显示了与上述摘录相对应的查询图。椭圆形、菱形、矩形和五边形分别代表进程、套接字、文件和注册表项。在图中,节点 B 代表恶意软件进程或进程组(我们使用 * 表示它可以有任何名称),节点 A 代表恶意软件的镜像文件,而节点 C、D 和 E 分别代表一个被丢弃的文件、注册表和 Internet 位置。查询图是对实际攻击图的总结,在我们的实验中,我们获得的查询图通常很小,包含 10-40 个节点和最多 150 条边。

一个小疑问:既然恶意行为的主体和对象都是*,那名称参与作为节点的唯一ID咋搞。到底是需要节点信息匹配,还是不需要节点信息,只查询相似结构?或者说二者综合,都参与威胁评分?
3.3. 图对齐(Graph Alignment)
我们将威胁搜寻建模为确定攻击的查询图 G q G_q Gq 是否在来源图 G p G_p Gp 中“表现”自身(manifests itself)。我们称这个问题为图对齐问题。
我们注意到 G q G_q Gq 表达了实体之间的几个高级流(进程到文件等)。相比之下, G p G_p Gp 表示系统的完整低级活动。因此, G q G_q Gq 中的一条边可能对应于 G p G_p Gp 中由多条边组成的路径。例如,如果 G q G_q Gq 表示写入系统文件的受损浏览器,那么在 G p G_p Gp 中,这可能对应于表示 Firefox 进程的节点分叉新进程的路径,其中只有一个最终写入系统文件。通常,这种对应关系可能是由攻击者在其活动中添加噪音以逃避检测而创建的。因此,我们需要一种图形对齐技术,可以将 G q G_q Gq 中的单个边与 G p G_p Gp 中的路径匹配。
现有的图匹配工作用于这个场景存在以下几个局限性:
- 不是为每个节点分配了标签和类型的有向图而设计的
- 不会扩展到数百万个节点
- 旨在彻底对齐查询图中的所有节点或边。
出于这些考虑,我们设计了一种新颖的图形模式匹配技术来解决这些限制。
如图 1 中,图形节点以不同的形状表示,以模拟不同的节点类型,例如文件、进程和套接字,但是,为简洁起见,省略了标签。Poirot 首先找到所有可能的候选对齐集合 i : j i : j i:j,其中 i i i 和 j j j 分别代表 V ( G q ) V (Gq) V(Gq) 和 V ( G p ) V (Gp) V(Gp) 中的节点。然后,从最有可能找到匹配项的对齐方式(称为种子节点)开始,我们扩展搜索以找到更多节点对齐方式。种子节点在图 1 中由六边形表示,而两个图中的匹配节点由虚线连接。
为了找到与 CTI 关系中表示的攻击相对应的对齐方式,搜索会沿着更可能受到攻击者影响的路径进行扩展。为了估计这种可能性,我们设计了一个名为影响分数的新指标。使用这个指标可以让我们在很大程度上从搜索中排除不相关的路径,并有效地缓解依赖爆炸问题。
先前的工作还提出了根据长度或成本的分数来确定流优先级的方法。然而,它们可能会被攻击规避,攻击者经常改变他们的方式来逃避检测技术。我们的分数定义明确考虑了潜在攻击者的影响。通过根据攻击者生成流所需的努力来确定流的优先级,从而增加了攻击者逃避我们检测的成本。
在找到对齐 G q : : G p G_q :: G_p Gq::Gp 之后,计算一个分数,表示 G q G_q Gq 和 G p G_p Gp 的对齐子图之间的相似性。当分数高于阈值时,Poirot 会发出警报,宣布攻击的发生,并向系统分析师提供对齐节点的报告,以进行进一步的取证分析。否则,Poirot 从下一个候选种子节点开始对齐。在 Gp 中找到攻击子图后,Poirot 生成一份报告,其中包含对齐的节点、它们之间的信息流以及相应的时间戳。
4. 算法
在本节中,我们讨论了 G q G_q Gq 和 G p G_p Gp 之间对齐的主要方法,方法是:(a) 定义对齐度量来衡量图形对齐的正确程度,以及 (b) 设计基于特定区域特征的最大相似性搜索。
4.1. 对其度量
我们引入了一些符号:

我们定义了两种对齐方式,即两个不同图中两个节点之间的节点对齐方式,以及以一组节点为单位的图对齐方式。通常,当两个节点 i i i 和 j j j 表示同一实体时,它们处于节点对齐中,例如,表示 CTI 报告中提到的常用浏览器的节点(图 3 的查询图 G q G_q Gq 中的节点 % b r o w s e r % \%browser\% %browser%)和代表源图中 F i r e f o x Firefox Firefox 进程的节点。一般情况下,节点对齐关系是从 V ( G q ) V(Gq) V(Gq) 到 V ( G p ) V(Gp) V(Gp) 的多对多关系。因此,给定一个查询图 G q G_q Gq, G q G_q Gq 和许多 G p G_p Gp 的子图之间可能存在大量图对齐。在这些子图中,我们寻找一个与图 G q G_q Gq 最匹配的子图。

G p G_p Gp 边缘显示的数字不是来源图的一部分,但用于在我们的讨论中识别单一路径。此外,由这两个图与 G q G_q Gq 对齐确定的 G p G_p Gp 的子图由 G p G_p Gp 中的虚线边表示。 G p G_p Gp 中的每个流和 G q G_q Gq 中的相应边都用相同的数字标记。因此,问题是要决定在众多对齐中哪一个是最佳候选。对于这个特定的图,比对 ( G q : : G p ) 2 (Gq::Gp)_2 (Gq::Gp)2比 ( G q : : G p ) 1 (Gq::Gp)_1 (Gq::Gp)1更接近 G q G_q Gq,主要是因为其对齐节点的数量高于 ( G q : : G p ) 1 (Gq::Gp)_1 (Gq::Gp)1,并且最重要的是,它的流与查询图 G q G_q Gq 的边有更好的对应关系。
如何去衡量这个对应关系谁更好呢? ( G q : : G p ) 1 (Gq::Gp)_1 (Gq::Gp)1连中心节点都没有对应上,不看边的匹配程度我都知道 ( G q : : G p ) 2 (Gq::Gp)_2 (Gq::Gp)2更匹配
4.1.1. 影响分数
我们必须引入一个路径评分函数,我们称之为影响分数,它为两个节点之间的给定流分配一个数字。
考虑图 3 中图 G p G_p Gp 中的两个节点 f i r e f o x 2 firefox_2 firefox2 和 % r e g i s t r y % / f i r e f o x \%registry\%/firefox %registry%/firefox。存在从 f i r e f o x 2 firefox_2 firefox2 到 % r e g i s t r y % / f i r e f o x \%registry\%/firefox %registry%/firefox的两个流,一个由标有数字 2 的边表示(和通过节点 j a v a 1 java_1 java1 和 j a v a 2 java_2 java2),另一个由标记为 3、3 和 5 的边表示(并通过节点 t m p . d o c tmp.doc tmp.doc 和 w o r d 1 word_1 word1)。假设 f i r e f o x 2 firefox_2 firefox2 在攻击者的控制之下,攻击者更有可能执行第一个流程而不是第二个流程。
事实上,为了执行第二个流程,除了 f i r e f o x 2 firefox_2 firefox2 之外,攻击者还必须控制进程 l a u n c h e r 2 launcher_2 launcher2 或 w o r d 1 word_1 word1。由于 l a u n c h e r 2 launcher_2 launcher2 或 w o r d 1 word_1 word1 在进程树中与 f i r e f o x 2 firefox_2 firefox2 没有共同的祖先,因此这种接管必须涉及对 l a u n c h e r 2 launcher_2 launcher2 或 w o r d 1 word_1 word1 的额外利用,这比简单地执行第一个流程更不可能,在第一个流程中,所有进程共享一个共同的祖先 l a u n c h e r 1 launcher_1 launcher1。我们指出,这种可能性不取决于流程的长度,而是取决于该流程中的流程数量以及这些流程在流程树中共享的不同祖先的数量。
我的理解是,相较于控制 l a u n c h e r 2 launcher_2 launcher2 和 w o r d 1 word_1 word1两个对象达到这个目的,攻击者更可能通过控制 l a u n c h e r 1 launcher_1 launcher1,同时利用 j a v a 1 java_1 java1 和 j a v a 2 java_2 java2 达到目的。此外,不管攻击者控制多少个进程,进程树的祖先数量始终是固定的,并不会因为
除非攻击者支付更高的成本来执行更多不同的妥协,否则,攻击者可能用来增加噪音并试图逃避检测的每项活动都可能具有相同的共同祖先,即攻击的初始妥协点。因此,这种努力在改变路径的影响分数方面是无效的。
由于威胁评分参考的是妥协进程的祖先而不是妥协进程的数量和攻击链长度,因此可以避免噪声的检测。除非攻击者花很高的成本去制造一个新的妥协入口,然后又回到这个可疑点,为子图增加一个祖宗,才能影响这个事件的分数。
基于这些观察,我们定义节点 i i i 和节点 j j j 之间的影响分数 Γ i , j \Gamma_{i,j} Γi,j 如下: Γ i , j = { max i → j 1 C m i n ( i − − > j ) ∃ i → j ∣ C m i n ( i − − > j ) ≤ C t h r 0 otherwise \Gamma_{i,j}=\begin{cases}\max_{i\to j}\dfrac{1}{Cmin(i--> j)}&\exists i\to j\mid C_{min}(i--> j)\leq C_{thr}\\ 0&\text{otherwise}\end{cases} Γi,j=⎩ ⎨ ⎧maxi→jCmin(i−−>j)10∃i→j∣Cmin(i−−>j)≤Cthrotherwise
C m i n ( i − − > j ) C_{min}(i--> j) Cmin(i−−>j) 表示攻击者必须执行的不同、独立的妥协的最小数量,以便能够生成流 i − − > j i--> j i−−>j。该值捕获攻击者对流的控制程度,并根据流中存在的进程的最小共同祖先数计算得出。如果存在从节点 i i i 到节点 j j j 的流程,并且该流程中涉及的所有进程在流程树中都有一个共同的祖先,攻击者只需要破坏该共同的祖先进程即可启动该流程,并且因此 Cmin(i ̶̶◁ j) 等于 1。为了让攻击者控制流 f i r e f o x 2 → t m p . d o c → w o r d 1 → % r e g i s t r y % / f i r e f o x ) firefox2 → tmp.doc → word_1→ \%registry\%/firefox) firefox2→tmp.doc→word1→%registry%/firefox),他需要同时控制 l a u n c h e r 1 launcher_1 launcher1 和 l a u n c h e r 2 launcher_2 launcher2;因此 C m i n C_{min}%= Cmin 等于 2。
在绝大多数记录在案的 APT 中,通常只有一个入口点或极少数入口点可供攻击者进入系统,一旦攻击者有了初步的妥协,他们就不太可能投入额外的资源来发现和利用额外的入口点。因此,我们可以对 C m i n ( i − − > j ) C_{min}(i--> j) Cmin(i−−>j) 值设置一个限制 C t h r C_{thr} Cthr,并合理地假设两个节点之间的任何 C m i n ( i − − > j ) C_{min}(i--> j) Cmin(i−−>j) 大于 C t h r C_{thr} Cthr 的流都不可能由攻击者发起。如果两个节点 i i i 和节点 j j j 之间存在多个流,则影响分数将是所有这些流中的最大值 1 C m i n ( i − − > j ) \dfrac{1}{Cmin(i--> j)} Cmin(i−−>j)1。
4.1.2. 对齐分数
对于特定的一次图形对齐 G q : : G p G_q :: G_p Gq::Gp 。评分函数 S ( G q : : G p ) S(G_q::G_p) S(Gq::Gp) 如下: S ( G q : G p ) = 1 ∣ F ( G q ) ∣ ∑ ( i − − > j ) ∉ F ( G q ) Γ k , l ∣ i : k & j : l S(G_q:G_p)=\frac{1}{|F(G_q)|}\sum\limits_{(i-->j)\notin F(G_q)}\Gamma_{k,l}\mid i:k\&j:l S(Gq:Gp)=∣F(Gq)∣1(i−−>j)∈/F(Gq)∑Γk,l∣i:k&j:l节点 i i i 和 j j j 是 V ( G q ) V(G_q) V(Gq) 的成员,节点 k k k 和 l l l 是 V ( G p ) V(G_p) V(Gp) 的成员。流 i − − > j i --> j i−−>j 是定义在 G q G_q Gq 上的流。 ∣ F ( G q ) ∣ |F(Gq)| ∣F(Gq)∣ 是 G q G_q Gq 中的流数。由于两个节点之间的影响力得分最大值等于1,因此流的数量自动代表影响力得分之和的最大值。
S ( G q : : G p ) S(G_q :: G_p) S(Gq::Gp) 的值越大,节点对齐的数量越多, G q G_q Gq 中的流与 G p G_p Gp 中的流之间的相似度越大,很可能受到影响一个潜在的攻击者。 C t h r C_{thr} Cthr 是我们假设攻击者愿意独立利用的不同入口点进程的最大数量。因此,假定攻击者能够影响影响分数为 1 C t h r \frac{1}{C_{thr}} Cthr1或更高的任何信息流。所以,当对齐分数 S ( G q : : G p ) S(G_q :: G_p) S(Gq::Gp) 超过预定阈值 ( τ ) (\tau) (τ) 时,我们会发出警报。 S ( G q : : G p ) ≥ τ S(G_q::G_p)\geq\tau S(Gq::Gp)≥τ τ = 1 C t h r \tau=\frac{1}{C_{thr}} τ=Cthr1
4.2. 尽力相似搜索
我们假设所有分析都是在 G p G_p Gp 的静态快照上进行的,并且从搜索开始到搜索终止的那一刻,其节点或边缘没有发生任何变化。我们的搜索算法由以下四个步骤组成,其中重复步骤 2-4,直到找到得分高于阈值 τ \tau τ 的对齐方式。
- 列出所有候选节点。这些候选对齐是根据查询图节点上的名称、类型和注释来选择的。例如,在 G q G_q Gq 和 G p G_p Gp 中出现具有相同标签(例如 Firefox)的相同类型的节点(例如,两个进程节点)可能形成候选对齐,其标签与正则表达式匹配的节点(例如,文件系统路径和文件姓名)等。用户还可以手动注释来源图中的节点,并明确指定与查询图中节点的对齐方式。在图 3 中,候选节点对齐由具有相同颜色的节点对表示。
- 选择种子节点。攻击活动通常只占 G p G_p Gp 的一小部分,而良性活动通常会重复多次。因此,特定于攻击的节点更有可能比良性活动的节点具有更少的对齐。基于这一观察,我们按照与每个节点相关的候选对齐数量的递增顺序对 G q G_q Gq 的节点进行排序。我们首先选择对齐最少的种子节点。对于图 3 中的示例,种子节点将为 %browser%,因为它具有最少数量的候选节点对齐。如果存在候选对齐数量相同的种子节点,我们随机选择其中一个。
- 扩展搜索。从种子节点开始,我们遍历 G p G_p Gp 中与其对齐的所有节点,并启动一组向前或向后的图遍历,以确定我们是否可以到达步骤1中找到的其他对齐的节点。一旦种子节点和该路径中最后一个节点之间的影响得分达到 0,我们就可以停止沿该路径扩展搜索。例如,假设我们决定图 3 中的 $C_{thr} 等于 2。然后, 沿路径搜索 ( f i r e f o x 2 → t m p . d o c → w o r d 1 → (firefox2 → tmp.doc → word1 → %registry%\firefox→ word2) (firefox2→tmp.doc→word1→ 不会扩展到节点 w o r d 2 word_2 word2,因为 f i r e f o x 2 firefox_2 firefox2 和沿该路径的任何节点之间的 C m i n C_{min} Cmin 在 w o r d 2 word_2 word2 处变得大于 2,并且因此影响分数变为 0。有时可能需要多个前向/后向跟踪循环才能访问所有节点(例如,如果我们在示例中选择 % b r o w s e r % \%browser\% %browser% 作为种子节点,则 G p G_p Gp 中的节点 240.2.1.1 240.2.1.1 240.2.1.1 无法从 f i r e f o x 1 firefox_1 firefox1 或 f i r e f o x 2 firefox_2 firefox2 开始的向前或向后遍历一遍就访问到)。在这种情况下,我们从与未访问节点相邻但已访问的节点开始重复向后和向前遍历。迭代这个过程,直到我们覆盖查询图 G q G_q Gq 的所有节点。
- 图对齐选择。由于 G q G_q Gq中的每个节点都可能有很多候选节点,为了有效地执行此搜索,我们设计了一个程序,该程序根据测量每个比对对最终比对分数的最大贡献的近似函数,迭代地为 G q G_q Gq 中的每个节点选择最佳候选者。从 G q G_q Gq 中的一个种子节点开始,我们选择 G p G_p Gp 中对对齐分数贡献最大的节点,并固定此节点对齐。
就是从根开始,每次都评估其贡献值,每次都选贡献最大的来比对并固定这个匹配。
最优候选者选择函数。对于 G p G_p Gp 中给定的候选对齐节点 k k k,计算该节点与 G p G_p Gp 中所有其他具备以下条件的候选节点 l l l 之间的最大影响分数 Γ k , l \Gamma_{k,l} Γk,l 之和:1)可从 k 到达或具有到 k 的路径, 2) G q G_q Gq 中其对应的对齐节点 j 具有来自或者去到 G q G_q Gq 中对应于节点 k 的节点的流。例如,考虑节点 % B r o w s e r % \%Browser\% %Browser% 和我们例子中的两个候选对齐节点 f i r e f o x 1 firefox_1 firefox1 和 f i r e f o x 2 firefox_2 firefox2。为了确定 f i r e f o x 1 firefox_1 firefox1的贡献,我们对每个流 ( % B r o w s e r % − − > ∗ . e x e , % B r o w s e r % − − > s p o o l s v , % B r o w s e r % − − > % r e g i s t r y % ) (\%Browser\% --> ∗. exe, \%Browser\% --> spoolsv, \%Browser\% --> \%registry\%) (%Browser%−−>∗.exe,%Browser%−−>spoolsv,%Browser%−−>%registry%)在 G q G_q Gq 中来自或去到 % B r o w s e r % \%Browser\% %Browser% 的最大影响分数,分别为 f i r e f o x 1 firefox_1 firefox1 和与 ∗ . e x e ∗.exe ∗.exe 、 s p o o l s v spoolsv spoolsv 和 % r e g i s t r y % \%registry\% %registry% 对齐的候选节点之间的影响分数。即,在这三种类型里面分别选一个分数最大的,得到一个和,这个和就是 f i r e f o x 1 firefox_1 firefox1 的最大贡献。然后对 f i r e f o x 2 firefox_2 firefox2 重复同样的过程,最后选择贡献值最高的排列组合。评估 A ( i : k ) A(i : k) A(i:k) 节点对齐方式 i : k i : k i:k 的贡献的公式如下:
A ( i : k ) = ∑ j : ( i → → j ) ∈ F ( G q ) ( 1 { j ; I } × Γ k , l + ( 1 − 1 { j ; l } ) × max m ∈ c a n d i d a t e s ( j ) ( Γ k , m ) ) A(i:k)=\sum_{j:(i\to\to j)\in F(G_{q})}\left(1_{\{j;I\}}\times\Gamma_{k,l}+(1-1_{\{j;l\}})\times\max_{m\in c a n d i d a t e s(j)}(\Gamma_{k,m})\right) A(i:k)=j:(i→→j)∈F(Gq)∑(1{j;I}×Γk,l+(1−1{j;l})×m∈candidates(j)max(Γk,m)) + ∑ j ( j → → i ) ∈ F ( G q ) ( 1 { j , I } × Γ l , k + ( 1 − 1 { j ; l } ) × max m ∈ c a n d i d a t e s ( j ) ( Γ m , k ) ) +\sum_{j(j\to\to i)\in F(G_{q})}\left(1_{\left\{j,I\right\}}\times\Gamma_{l,k}+\left(1-1_{\left\{j;l\right\}}\right)\times\max_{m\in c a n d i d a t e s(j)}\left(\Gamma_{m,k}\right)\right) +j(j→→i)∈F(Gq)∑(1{j,I}×Γl,k+(1−1{j;l})×m∈candidates(j)max(Γm,k))其中 1 A 1_{\mathcal A} 1A 为指示函数,若 A \mathcal A A 表示的对齐方式已经固定则为1,否则为0。对于具有第 3 步生成的一组 K 个候选对齐方式的每个节点 i,固定 i 对齐方式的选择函数如下: arg max k ∈ K A ( i : k ) \underset{k\in K}{\operatorname{arg}\max}A(i:k) k∈KargmaxA(i:k)这类似贪心的算法,可能并不总是能带来最好的结果,但在实践中,我们发现它非常有效。
最后,在固定所有节点对齐后,按照等式(2)计算对齐得分。如果分数低于阈值,则再次执行步骤2-4。
相关文章:
【论文阅读】POIROT:关联攻击行为与内核审计记录以寻找网络威胁(CCS-2019)
POIROT: Aligning Attack Behavior with Kernel Audit Records for Cyber Threat Hunting CCS-2019 伊利诺伊大学芝加哥分校、密歇根大学迪尔伯恩分校 Milajerdi S M, Eshete B, Gjomemo R, et al. Poirot: Aligning attack behavior with kernel audit records for cyber thre…...

K8S cluster with multi-masters on Azure VM
拓扑参考: 在 Azure VM 实例上部署 KubeSphere 基础模板 需要修改 IP 地址和 VM Image的可以在模板中修改。 {"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#","contentVersion": &q…...
初阶c语言:趣味扫雷游戏
目录 前言 制作菜单 构建游戏选择框架 实现游戏功能 模块化编程:查看前节三子棋的内容 初始化雷区 编辑 优化棋盘 随机埋入地雷 点击后的决策 实现此功能代码 game();的安排 前言 《扫雷》是一款大众类的益智小游戏&…...

JVM——内存模型
1.java内存模型 1.1 原子性 1.2 问题分析 这里与局部变量自增不同,局部变量调用iinc是在局部变量表槽位上进行自增。 静态变量是在操作数栈自增。 这里的主内存和工作内存时再JMM里的说法。 因为操作系统是时间片切换的多个线程轮流使用CPU. 1.3解决方法 JMM中…...

java八股文面试[JVM]——元空间
JAVA8为什么要增加元空间 为什么要移除永久代? 知识来源: 【2023年面试】JVM8为什么要增加元空间_哔哩哔哩_bilibili...

科技云报道:云计算下半场,公有云市场生变,私有云风景独好
科技云报道原创。 大数据、云计算、人工智能,组成了恢弘的万亿级科技市场。这三个领域,无论远观近观,都如此性感和魅力,让一代又一代创业者为之杀伐攻略。 然而高手过招往往一瞬之间便已胜负知晓,云计算市场的巨幕甫…...

Oracle 如何给大表添加带有默认值的字段
一、讲故事 你是否遇到过开发人员添加字段,导致数据库锁表问题? 但是令开发疑惑的事,他们添加字段,有的时候很快,有的时候很慢? 为什么呢? 询问得知,**加的慢时候是带上了default默…...

记录Taro大坑2丢失api无法启动
现象 解决方案 看了很多。很多说要改成一致的版本号。其实没什么用。 正确方案 再新建一个模板跑起来对比config的配置,以及package.json发现关闭预编译即可。预编译导致api丢失...

Java-Maven-解决maven deploy时报 401 Reason Phrase Unauthorized 错误
Java-Maven-解决maven deploy时报 401 Reason Phrase Unauthorized 错误 环境 Java JDK 1.8Maven 3.3.9 引言 项目需要打成jar包上传到私服,供其它项目引用。此时需要执行 mvn clean deploy 命令,执行过程中报 401 错误。 解决401错误 报错信息 执…...

【数据结构】 栈(Stack)的应用场景
文章目录 🌏前言🍀改变元素的序列🚩场景一📌解析: 🚩场景二📌解析: 🎍将递归转化为循环🌳[括号匹配](https://leetcode.cn/problems/valid-parentheses/)&…...
人力资源小程序的设计原则与实现方法
随着移动互联网的快速发展,小程序成为了各行各业推广和服务的新利器。对于人力资源行业来说,开发一款定制化的小程序不仅可以提升服务效率,还可以增强品牌形象和用户粘性。那么,如何定制开发人力资源类的小程序呢?下面…...
检查Javascript对象数组中是否存在对象值,如果没有向数组添加新对象
需求: 如果我有以下对象数组: [ { id: 1, username: fred }, { id: 2, username: bill }, { id: 2, username: ted } ]有没有办法循环遍历数组,以检查特定的用户名值是否已经存在,如果它什么都不做,但是如果它没有用…...
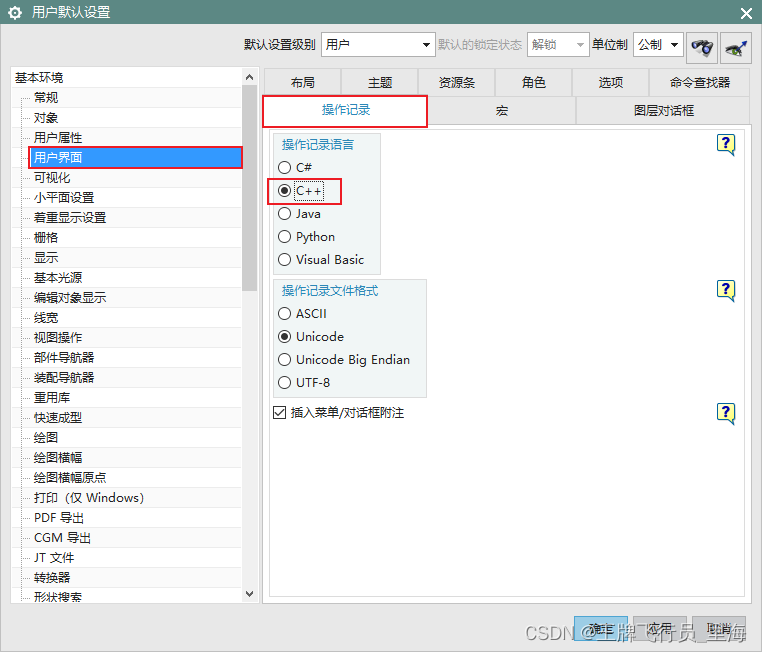
UG\NX二次开发 使用录制功能录制操作记录时,如何设置默认的开发语言?
文章作者:里海 来源网站:王牌飞行员_里海_里海NX二次开发3000例,C\C,Qt-CSDN博客 简介: NX二次开发使用BlockUI设计对话框时,如何设置默认的代码语言? 效果: 方法: 依次打开“文件”->“实用…...
【业务功能篇83】微服务SpringCloud-ElasticSearch-Kibanan-docke安装-应用层实战
五、ElasticSearch应用 1.ES 的Java API两种方式 Elasticsearch 的API 分为 REST Client API(http请求形式)以及 transportClient API两种。相比来说transportClient API效率更高,transportClient 是通过Elasticsearch内部RPC的形式进行请求…...
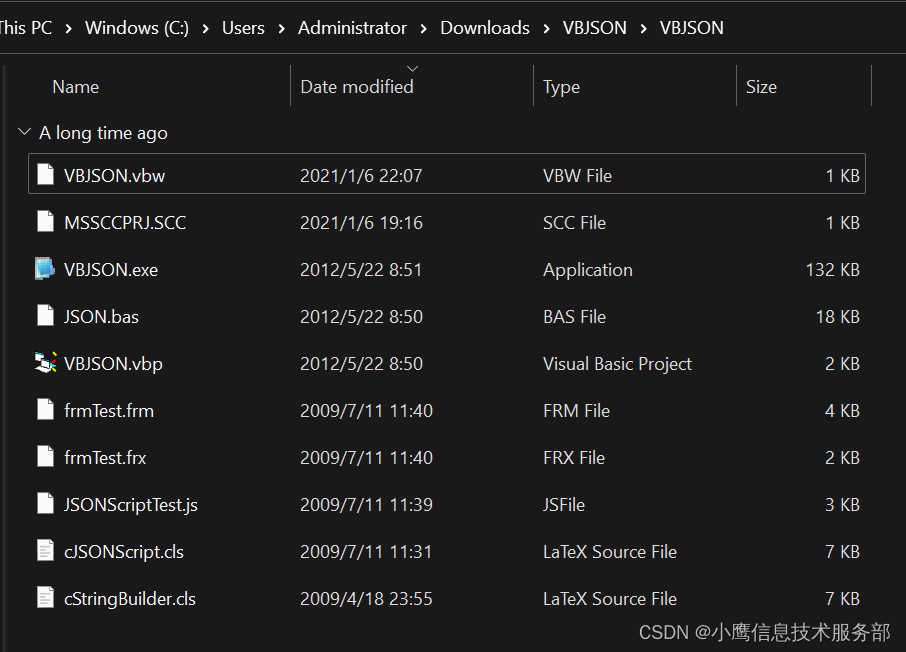
VBJSON报错:缺少:语句结束
项目中使用JSON库VBJSON时报错: 编译错误:缺少:语句结束 cJSONScript和cStringBuilder报相同的错误,都在第一行: VERSION 1.0 CLASS 研究了半天没啥结果,之前使用这个库的时候没有什么问题,所以判定是当前…...
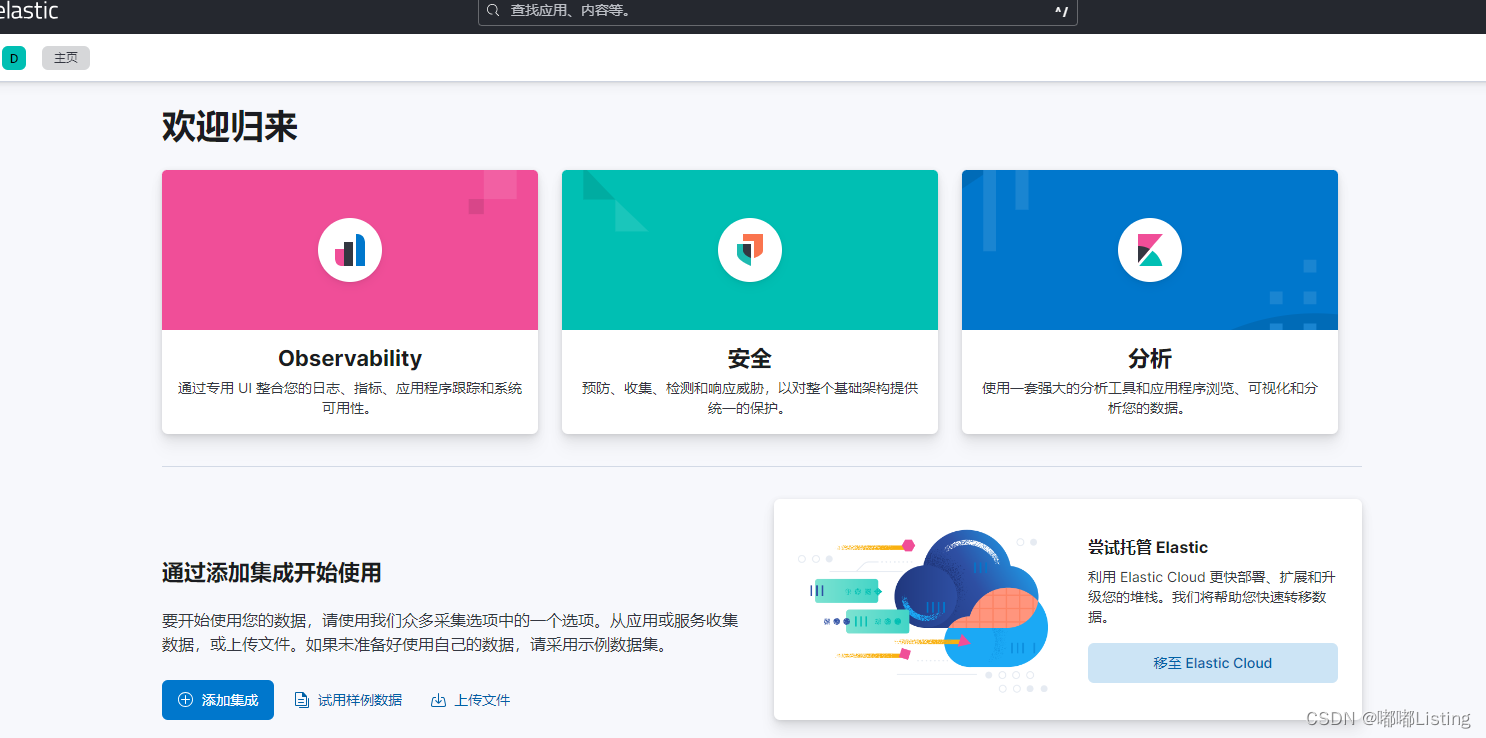
Docker安装ES+kibana8.9.1
参考:基于Docker安装Elasticsearch【保姆级教程、内含图解】_docker elasticsearch_Acloasia的博客-CSDN博客 创建网络 docker network create es-net 基于Docker安装Elasticsearch 拉取镜像 docker pull elasticsearch:8.9.1 挂载文件 mkdir -p /usr/local/e…...

12. Oracle中case when详解
格式: case expression when condition_01 then result_01 when condition_02 then result_02 ...... when condition_n then result_n else result_default end 表达式expression符合条件condition_01,则返回…...
【电路设计】220V AC转低压DC电路概述
前言 最近因项目需要,电路板上要加上一个交流220V转低压直流,比如12V或者5V这种。一般来说,比较常见也比较简单的做法是使用一个变压器将220V AC进行降压,比如降到22V AC,但是很遗憾的是,支持220V的变压器一般体积很大,而板子留给电源部分的面积又非常有限,所以不得不研…...
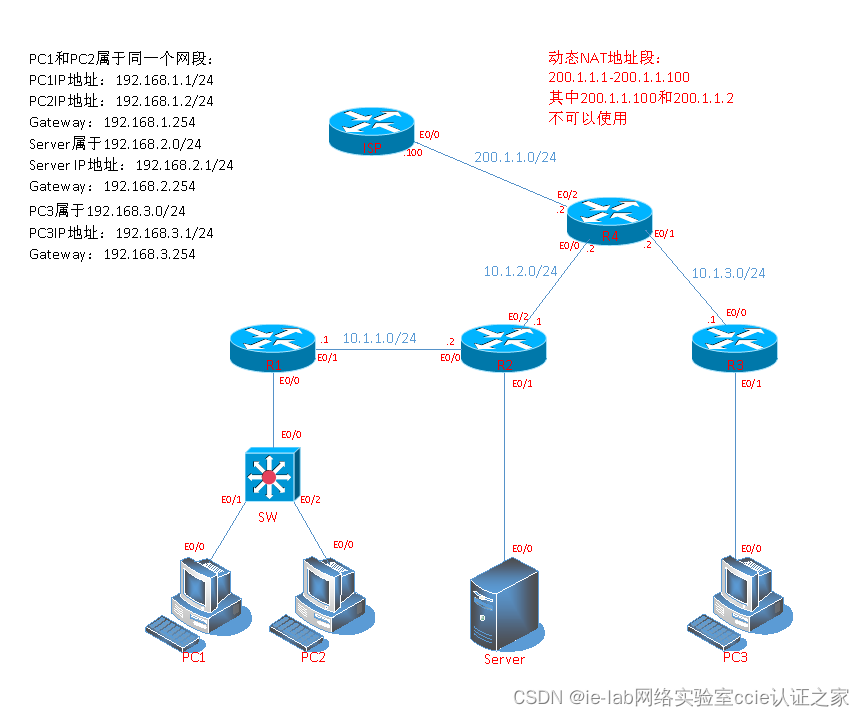
网络地址转换NAT-动态NAT的使用范围和配置-思科EI,华为数通
网络地址转换NAT-动态NAT的使用范围和配置 什么是动态NAT? 使用公有地址池,并以先到先得的原则分配这些地址。当具有私有 IP 地址的主机请求访问 Internet 时,动态 NAT 从地址池中选择一个未被其它主机占用的 IP 地址一对一的转化。当数据会话…...
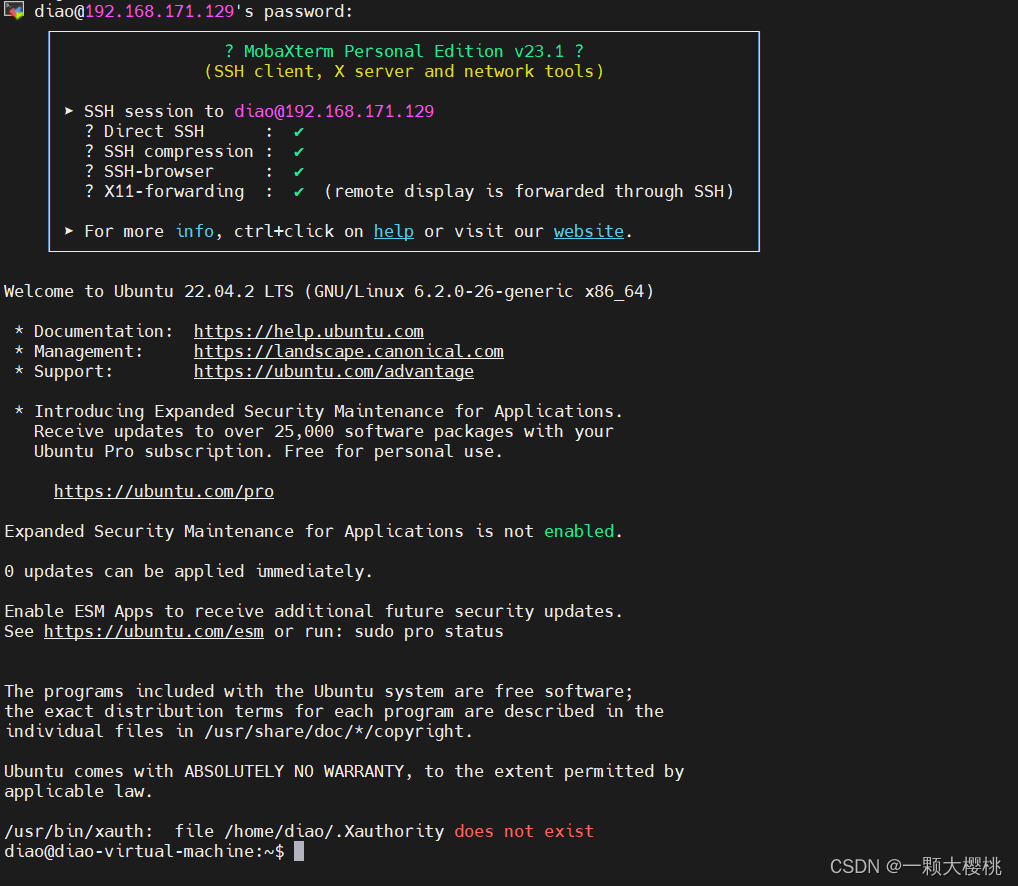
远程连接虚拟机中ubuntu报错:Network error:Connection refused
ping检测一下虚拟机 可以ping通,说明主机是没问题 #检查ssh是否安装: ps -e |grep ssh发现ssh没有安装 #安装openssh-server sudo apt-get install openssh-server#启动ssh service ssh startps -e |grep ssh检查一下防火墙 #防火墙状态查看 sudo ufw…...
快速排序三种思路详解!
一、快速排序的介绍 快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,…...

【二叉树入门指南】链式结构的实现
【二叉树入门指南】链式结构的实现 一、前置说明二、二叉树的遍历2.1前序遍历2.2中序遍历2.3 后序遍历 三、以前序遍历为例,递归图解四、层序遍历五、节点个数以及高度等5.1 二叉树节点个数5.2二叉树叶子节点个数5.3 二叉树第k层节点个数5.4 二叉树查找值为x的节点5…...
【位运算】算法实战
文章目录 一、算法原理常见的位运算总结 二、算法实战1. leetcode面试题01.01. 判断字符是否唯一2. leetcode268 丢失的数字3. leetcode371 两整数之和4. leetcode004 只出现一次的数字II5. leetcode面试题17.19. 消失的两个数字 三、总结 一、算法原理 计算机中的数据都以二进…...
C++构建系统
收集C构建系统(2023): 跟我一起写Makefile (PDF重制版)CMake tutorialConan, software package manager for C and C developersvcpkg-repovcpkgGoogle Bazel Build System { Fast, Correct } — Choose twoGN gn_quick_start当前Chromium构建系统 GYP Generate You…...
“深入探索JVM内部机制:理解Java虚拟机的运行原理“
标题:深入探索JVM内部机制:理解Java虚拟机的运行原理 摘要:本篇博客将深入探索Java虚拟机(JVM)的内部机制,帮助读者理解JVM的运行原理。我们将介绍JVM的组成结构,包括类加载器、运行时数据区域…...

java八股文面试[JVM]——双亲委派模型
1.当AppClassLoader去加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委托给父加载器ExtClassLoader去完成。 2.当ExtClassLoader去加载一个class时,它首先也不会去尝试加载这个类,而是把类加载请求委托给父加载…...

NLP与大模型主题全国师资培训班落地,飞桨持续赋能AI人才培养
为了推动大模型及人工智能相关专业人员的培养,8月11日-8月13日,由中国计算机学会主办、机械工业出版社、北京航空航天大学、百度飞桨联合承办 “CCF群星计划之文心高校行- NLP与大模型”主题师资培训班(以下简称培训班)在北京天信…...

Jupyter Notebook 配置根目录
注:本文是在 Windows 10 上配置 Jupyter Notebook 打开的默认根目录,Linux 同。 步骤一:创建 Jupyter Notebook 配置文件 使用以下命令创建 Jupyter Notebook 配置文件(如果尚未创建): jupyter notebook …...
算法 位运算
文章目录 一、&(按位与)运算符二、|(按位或)运算符三、^(异或)运算符四、~(取反)运算符五、<<(左移)运算符六、>>(右移ÿ…...
Linux 虚拟机常用命令
一、文件/文件夹管理 1. ls命令 就是 list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。 ls -a 列出目录所有文件,包含以.开始的隐藏文件ls -A 列出除.…...
解决抖音semi-ui的Input无法获取到onChange事件
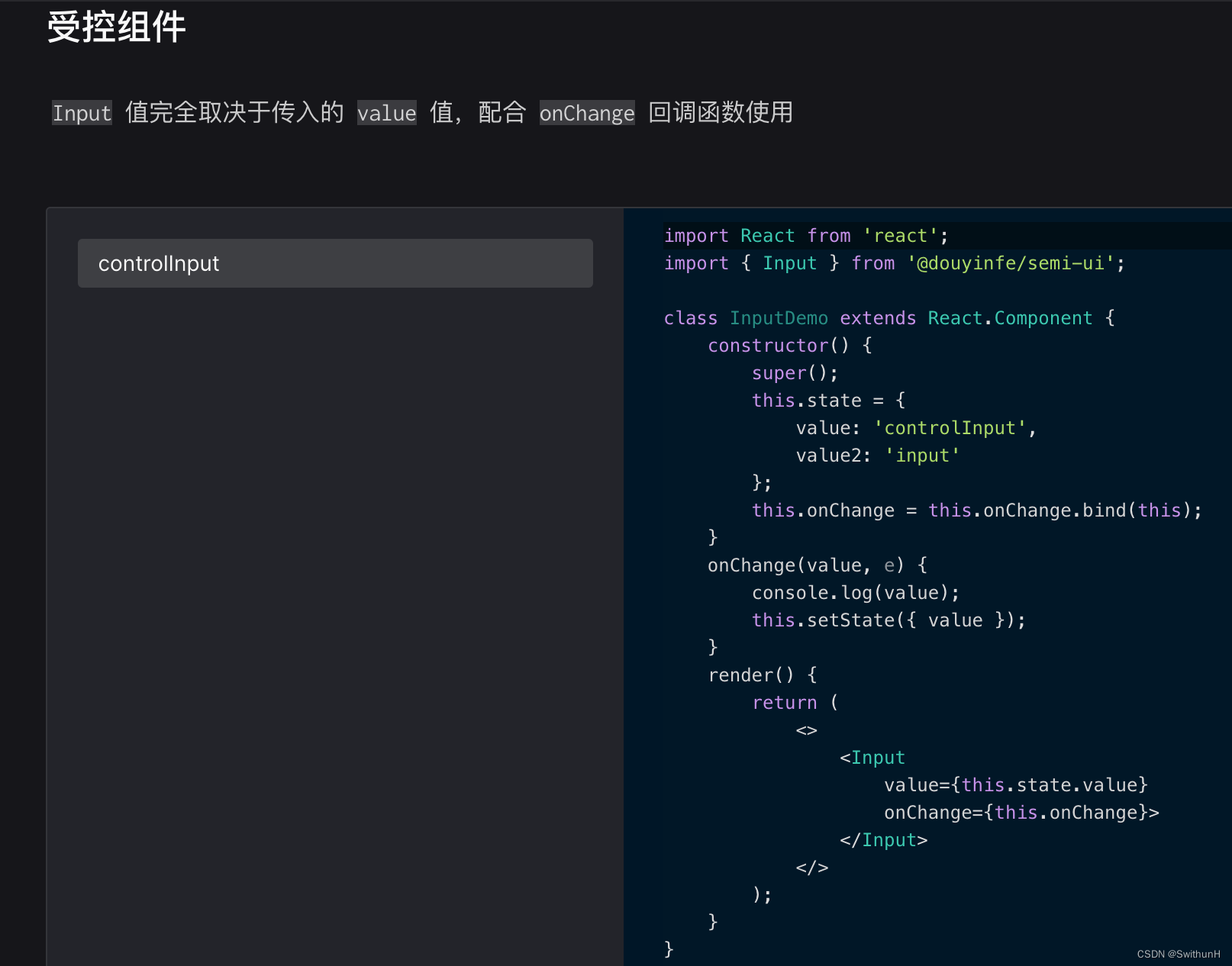
最近在使用semi-ui框架的Input实现一个上传文件功能时遇到了坑,就是无法获取到onChange事件,通过console查看只是拿到了一个文件名。但若是把<Input>换成原生的<input>,就可以正常获取到事件。仔细看了下官方文档,发现…...
免费的png打包plist工具CppTextu,一款把若干资源图片拼接为一张大图的免费工具
经常做游戏打包贴图的都知道,要把图片打包为一张或多张大图,要使用打包工具TexturePacker。 TexturePacker官方版可以直接导入PSD、SWF、PNG、BMP等常见的图片格式,主要用于网页、游戏和动画的制作,它可以将多个小图片汇聚成一个…...
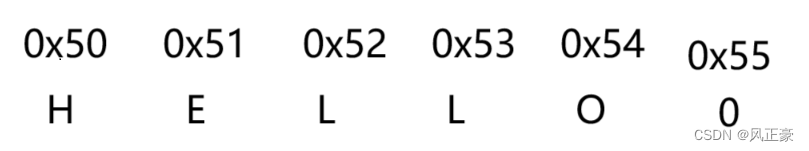
深层次分析字符数组和字符串的区别是什么?
前言 (1)休闲时刻刷B站,看到一个卖课的,发视频问,char arr1[]{‘H’,‘E’,‘L’,‘L’,‘O’};和char arr2[]“HELLO”;区别是什么。 (2)看那个卖课博主一顿分析,最后成功得出&…...
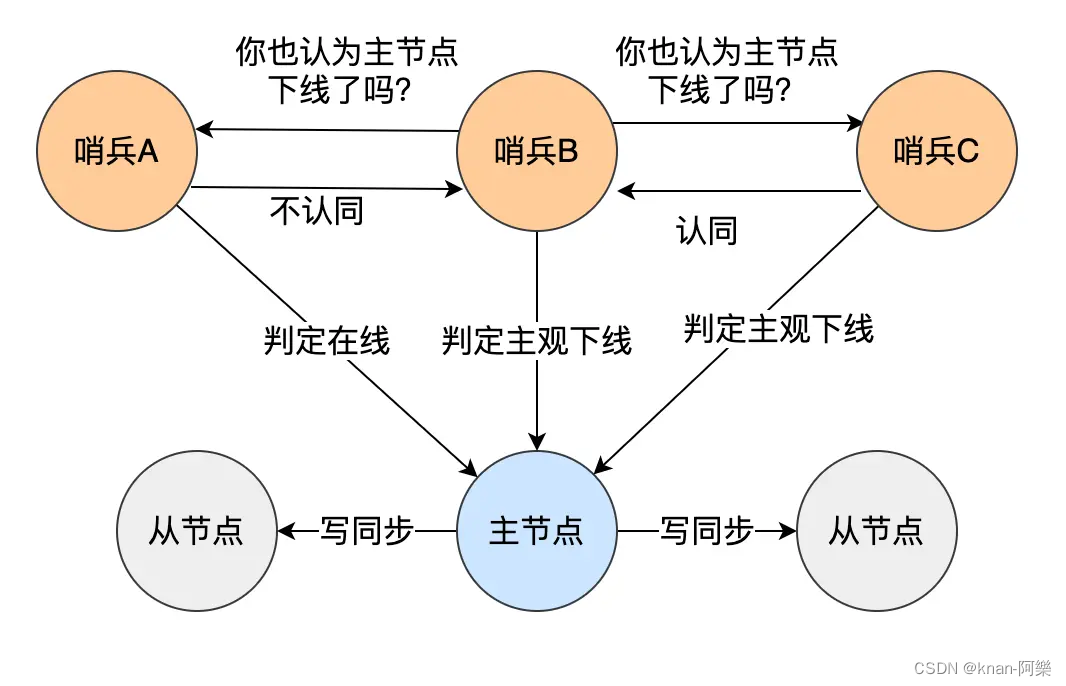
Redis 的主从复制、哨兵模式、集群脑裂
主从复制 主从复制是 Redis 高可用服务最基础的保证,将一台 Redis 主服务器,同步数据到多台 Redis 从服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。 主服务器可以进行读写操作,当发生写操…...

Pycharm通过SSH配置centos上Spark环境
直接在shell进行pyspark进行编程,程序没有办法写得太长,而且我们希望能够实现一个及时给出结果的编程环境,可以使用pycharm连接centos上的spark,进行本地编程,同步到centos系统中运行程序,并把结果返回pych…...
leetcode做题笔记98. 验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 思路一:递归 …...
C# 中Lambda中的的匿名函数
/// <summary>/// 根据设备号,获取故障列表/// </summary>/// <param name"scanCode">主键</param>/// <returns></returns>[HttpGet]public async Task<IActionResult> GetItemPageList(string scanCode){//v…...

铰接式车辆的横向动力学仿真提供车辆模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Ubuntu20 安装 libreoffice
1 更新apt-get sudo apt-get update2 安装jdk 查看jdk安装情况 Command java not found, but can be installed with:sudo apt install default-jre # version 2:1.11-72, or sudo apt install openjdk-11-jre-headless # version 11.0.138-0ubuntu1~20.04 sud…...

HTTP协议(JavaEE初阶系列15)
目录 前言: 1.HTTP协议 1.1HTTP协议是什么 1.2HTTP协议的报文格式 1.2.1抓包工具的使用 1.2.2HTTP请求 1.2.3HTTP响应 2.HTTP请求 2.1首行的组成 2.2.1URL的组成 2.2认识“方法”(method) 2.2.1GET方法 2.2.2POST方法 2.2.3GET…...
机器学习基础10-审查回归算法(基于波士顿房价的数据集)
上一节介绍了如何审查分类算法,并介绍了六种不同的分类算法,还 用同一个数据集按照相同的方式对它们做了审查,本章将用相同的方式对回归算法进行审查。 在本节将学到: 如何审查机器学习的回归算法。如何审查四种线性分类算法。如…...
基于 CentOS 7 构建 LVS-DR 群集。配置nginx负载均衡。
1、基于 CentOS 7 构建 LVS-DR 群集。 [root132 ~]# nmcli c show NAME UUID TYPE DEVICE ens33 c89f4a1a-d61b-4f24-a260-6232c8be18dc ethernet ens33 [root132 ~]# nmcli c m ens33 ipv4.addresses 192.168.231.200/24 [r…...
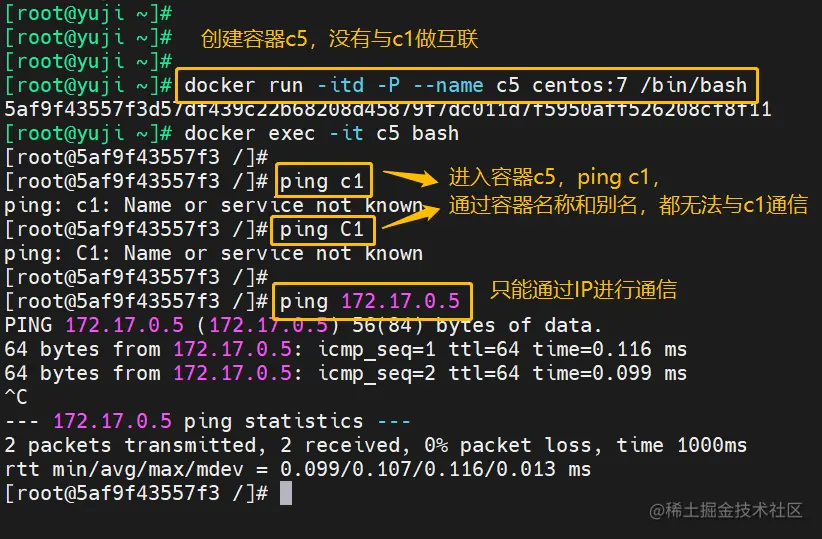
【云原生】Docker的数据管理(数据卷、容器互联)
目录 一、数据卷(容器与宿主机之间数据共享) 二、数据卷容器(容器与容器之间数据共享) 三、 容器互联(使用centos镜像) 总结 用户在使用Docker的过程中,往往需要能查看容器内应用产生的数据…...
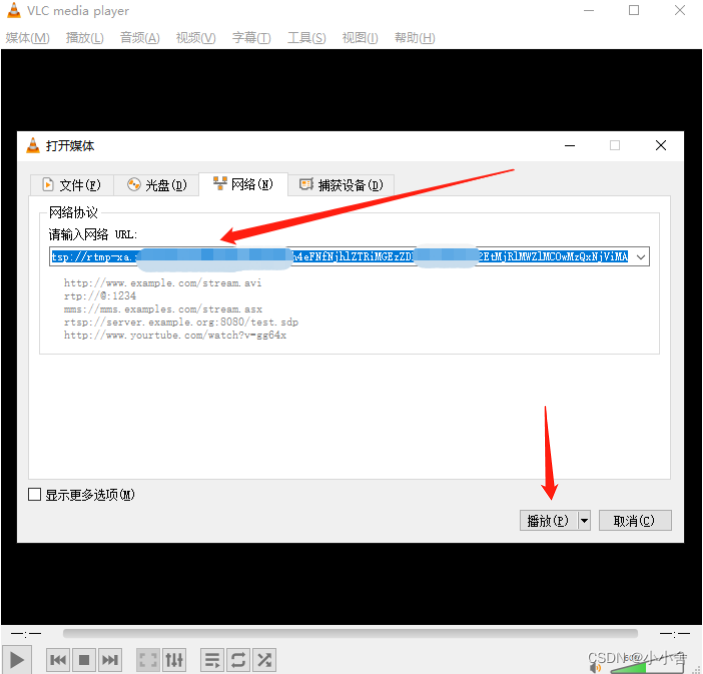
使用vlc在线播放rtsp视频url
1. 2. 3. 工具链接: https://download.csdn.net/download/qq_43560721/88249440...
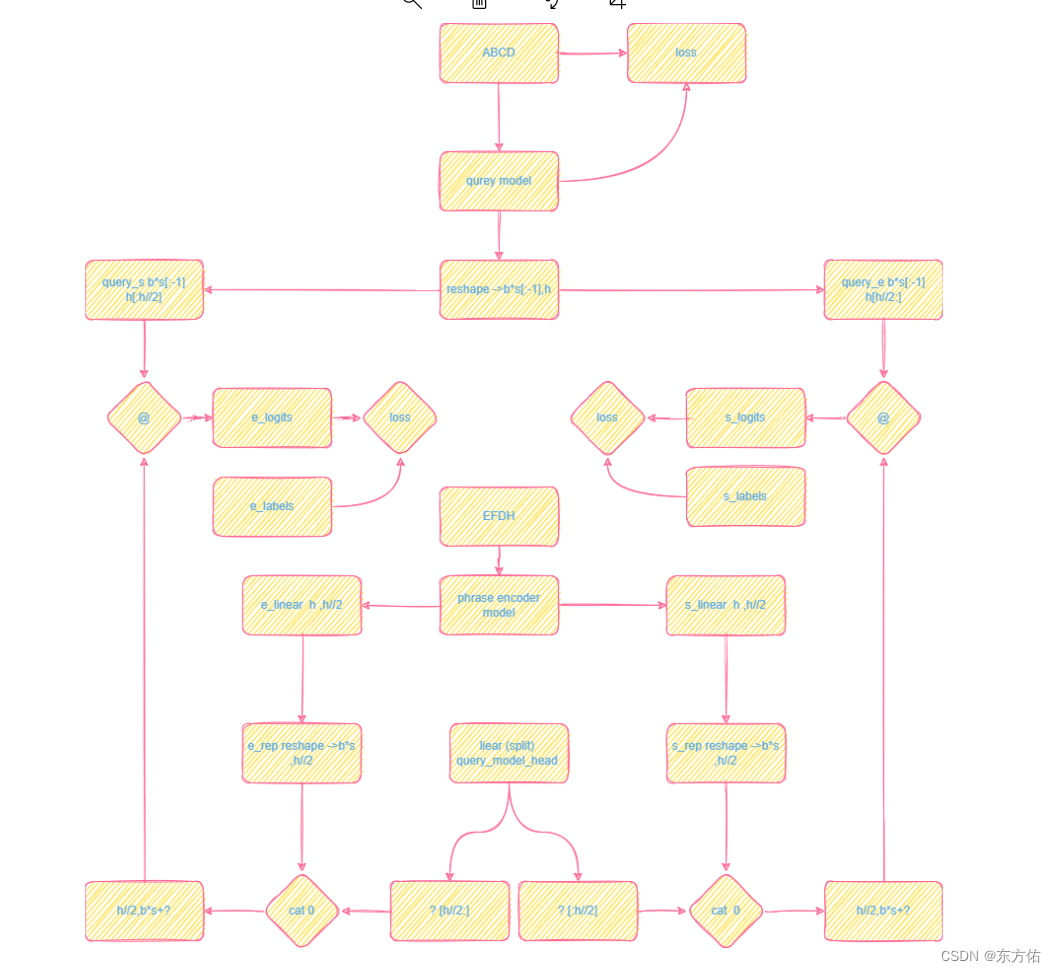
copy is all you need前向绘图 和疑惑标记
疑惑的起因 简化前向图 GPT4解释 这段代码实现了一个神经网络模型,包含了BERT、GPT-2和MLP等模块。主要功能是给定一个文本序列和一个查询序列,预测查询序列中的起始和结束位置,使其对应文本序列中的一个短语。具体实现细节如下:…...

【附安装包】Vred2023安装教程
软件下载 软件:Vred版本:2023语言:简体中文大小:2.39G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.0GHz 内存4G(或更高)下载通道①百度网盘丨64位下载链接:https://pan.baidu.com…...
ASP.NET Core 中的 Dependency injection
依赖注入(Dependency Injection,简称DI)是为了实现各个类之间的依赖的控制反转(Inversion of Control,简称IoC )。 ASP.NET Core 中的Controller 和 Service 或者其他类都支持依赖注入。 依赖注入术语中&a…...

优化物料编码规则,提升物料管理效率
导 读 ( 文/ 2358 ) 物料是生产过程的必需品。对物料进行身份的唯一标识,可以更好的管理物料库存、库位,更方便的对物料进行追溯。通过编码规则的设计,可以对物料按照不同的属性、类别或特征进行分类,从而更好地进行库存分析、计划…...
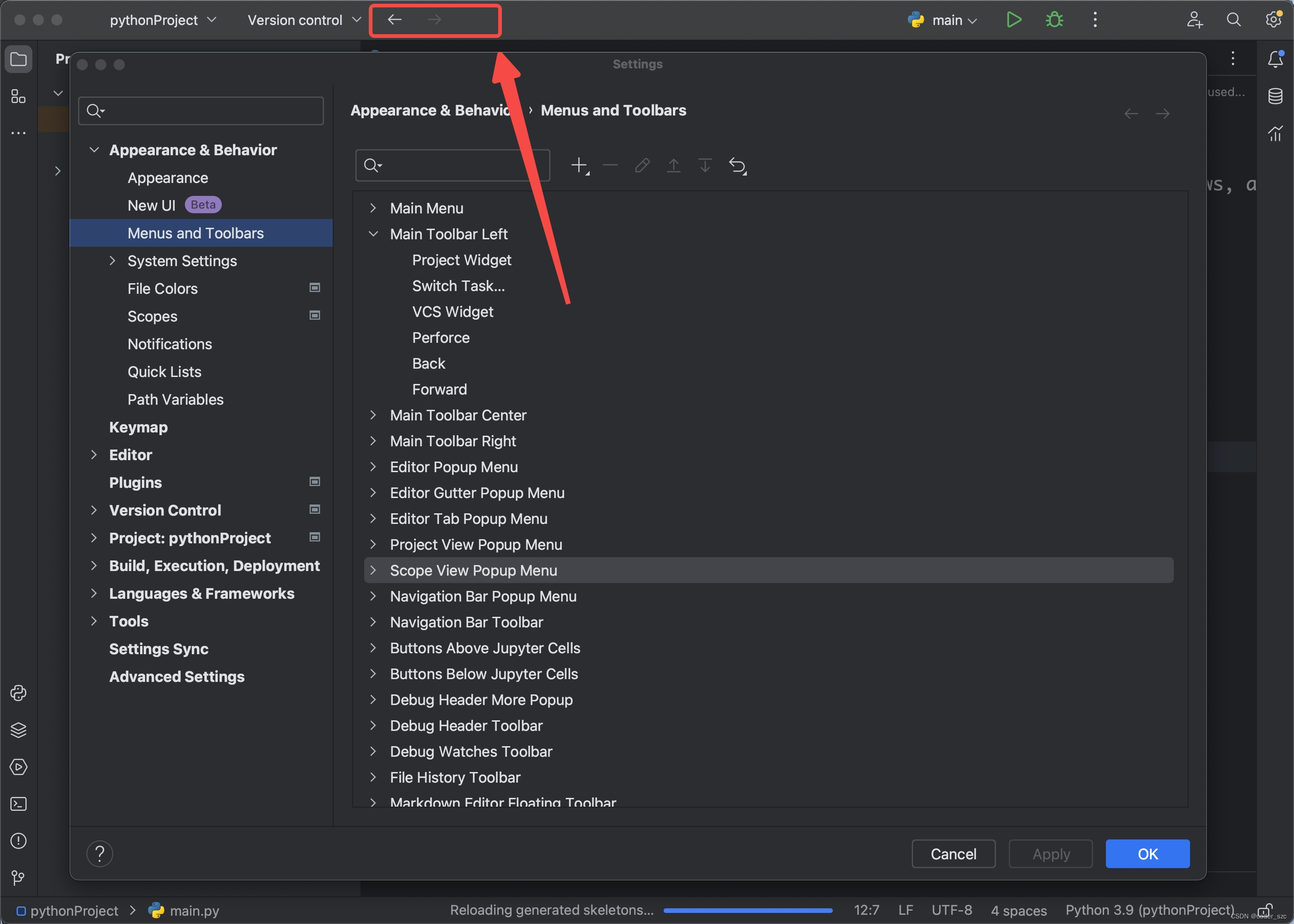
Jetbrains IDE新UI设置前进/后退导航键
背景 2023年6月,Jetbrains在新发布的IDE(Idea、PyCharm等)中开放了新UI选项,我们勾选后重启IDE,便可以使用这一魔性的UI界面了。 但是前进/后退这对常用的导航键却找不到了,以前的设置方式(Vi…...
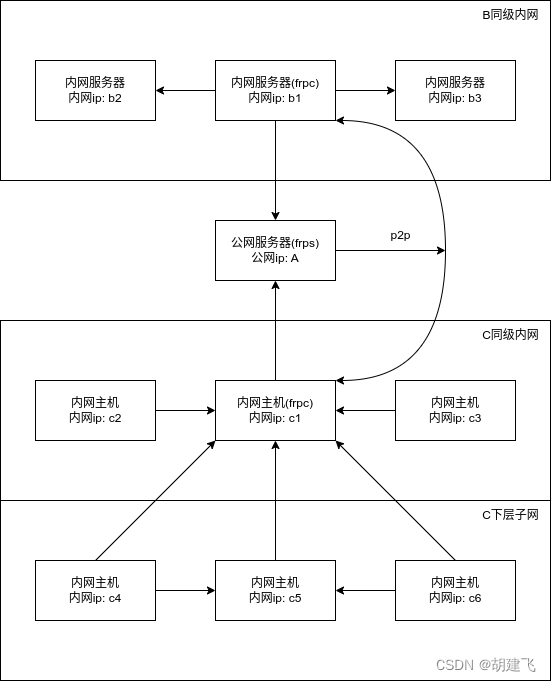
借助frp的xtcp+danted代理打通两边局域网p2p方式访问
最终效果 实现C内网所有设备借助c1内网代理访问B内网所有服务器 配置公网服务端A frps 配置frps.ini [common] # 绑定frp穿透使用的端口 bind_port 7000 # 使用token认证 authentication_method token token xxxx./frps -c frps.ini启动 配置service自启(可选) /etc/…...