[NLP]深入理解 Megatron-LM
一. 导读
NVIDIA Megatron-LM 是一个基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大型语言模型。Megatron-LM 综合应用了数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)来复现 GPT-3.
在自然语言处理(NLP)领域,大型模型能够提供更精准和强大的语义理解与推理能力。随着计算资源的普及和数据集的增大,模型参数的数量呈指数级增长。然而,训练这样规模庞大的模型面临着一些挑战:
- 显存限制: 即便是目前最大的GPU主内存也难以容纳这些模型的参数。举例来说,一个1750亿参数的GPT-3模型需要约700GB的参数空间,对应的梯度约为700GB,而优化器状态还需额外的1400GB,总计需求高达2.8TB。
- 计算挑战: 即使我们设法将模型适应单个GPU(例如通过在主机内存和设备内存之间进行参数交换),模型所需的大量计算操作也会导致训练时间大幅延长。举个例子,使用一块NVIDIA V100 GPU来训练拥有1750亿参数的GPT-3模型,大约需要耗时288年。
- 并行策略挑战: 不同的并行策略对应不同的通信模式和通信量,这也是一个需要考虑的挑战。
二 . 并行策略和方法简介
1 数据并行
数据并行模式会在每个worker之上复制一份模型,这样每个worker都有一个完整模型的副本。输入数据集是分片的,一个训练的小批量数据将在多个worker之间分割;worker定期汇总它们的梯度,以确保所有worker看到一个一致的权重版本。对于无法放进单个worker的大型模型,人们可以在模型之中较小的分片上使用数据并行。
数据并行扩展通常效果很好,但有两个限制:
- a)超过某一个点之后,每个GPU的batch size变得太小,这降低了GPU的利用率,增加了通信成本;
- b)可使用的最大设备数就是batch size,限制了可用于训练的加速器数量。
2 模型并行
人们会使用一些内存管理技术,如激活检查点(activation checkpointing)来克服数据并行的这种限制,也会使用模型并行来对模型进行分区来解决这两个挑战,使得权重及其关联的优化器状态不需要同时驻留在处理器上。
模型并行模式会让一个模型的内存和计算分布在多个worker之间,以此来解决一个模型在一张卡上无法容纳的问题,其解决方法是把模型放到多个设备之上。
模型并行分为两种:流水线并行和张量并行,就是把模型切分的方式。
- 流水线并行(pipeline model parallel)是把模型不同的层放到不同设备之上,比如前面几层放到一个设备之上,中间几层放到另外一个设备上,最后几层放到第三个设备之上。
- 张量并行则是层内分割,把某一个层做切分,放置到不同设备之上,也可以理解为把矩阵运算分配到不同的设备之上,比如把某个矩阵乘法切分成为多个矩阵乘法放到不同设备之上。
具体如下图,上面是层间并行(流水线并行),纵向切一刀,前面三层给第一个GPU,后面三层给第二个GPU。下面是层内并行(tensor并行),横向切一刀,每个张量分成两块,分到不同GPU之上。
这两种模型切分方式是可以同时存在的,实现正交和互补的效果。

从另一个角度看看,两种切分同时存在,是正交和互补的(orthogonal and complimentary)。

通信分析
对于模型并行的通信状况。
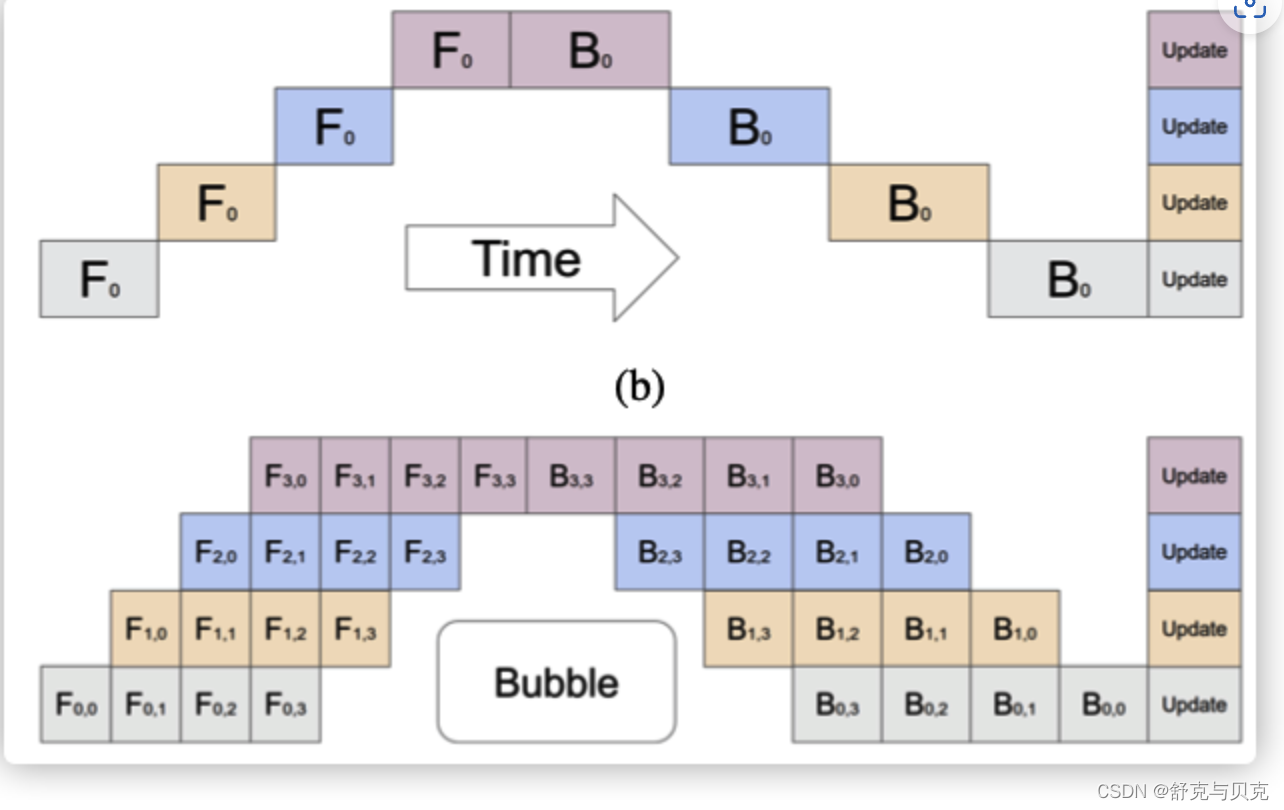
流水线并行:通信在流水线阶段相邻的切分点之上,通信类型是P2P通信,单词通信数据量较少但是比较频繁,而且因为流水线的特点,会产生GPU空闲时间,这里称为流水线气泡(Bubble)。
比如下图之中,上方是原始流水线,下面是流水线并行,中间给出了 Bubble 位置。
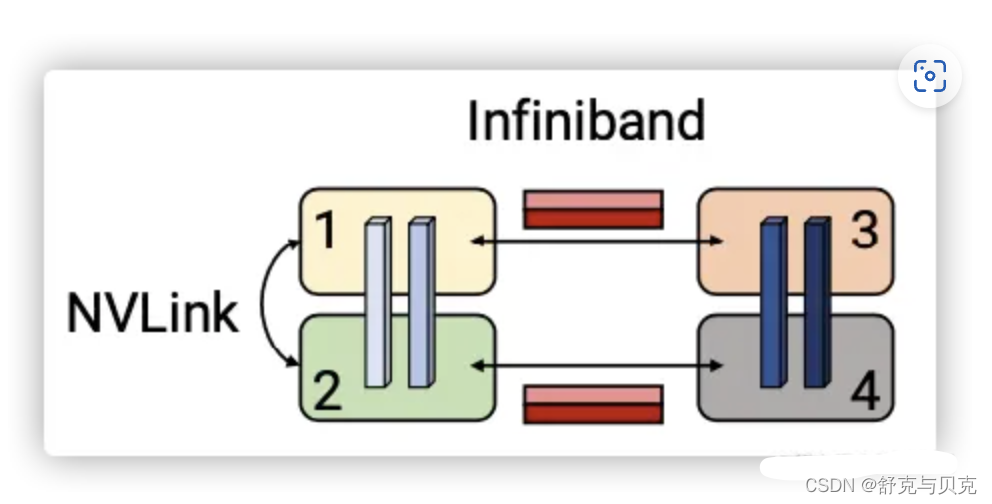
张量并行:通信发生在每层的前向传播和后向传播过程之中,通信类型是all-reduce,不但单次通信数据量大,并且通信频繁。
张量并行一般都在同一个机器之上,所以通过 NVLink 来进行加速,对于流水线并行,一般通过 Infiniband 交换机进行连接。
2.1 张量并行
张量模型并行化(tensor model parallelism)将每个transformer 层内的矩阵乘法被分割到多个GPU上,虽然这种方法在NVIDIA DGX A100服务器(有8个80GB-A100 GPU)上对规模不超过200亿个参数的模型效果很好,但对更大的模型就会出现问题。因为较大的模型需要在多个multi-GPU服务器上分割,这导致了两个问题。
- 张量并行所需的all-reduce通信需要通过服务器间的链接,这比multi-GPU服务器内的高带宽NVLink要慢;
- 高度的模型并行会产生很多小矩阵乘法(GEMMs),这可能会降低GPU的利用率。
2.2 流水线并行
流水线模型并行化是另一项支持大型模型训练的技术。在流水线并行之中,一个模型的各层会在多个GPU上做切分。一个批次(batch)被分割成较小的微批(micro-batches),并在这些微批上进行流水线式执行。
通过流水线并行,一个模型的层被分散到多个设备上。当用于具有相同transformer块重复的模型时,每个设备可以被分配相同数量的transformer层。Megatron不考虑更多的非对称模型架构,在这种架构下,层的分配到流水线阶段是比较困难的。在流水线模型并行中,训练会在一个设备上执行一组操作,然后将输出传递到流水线中下一个设备,下一个设备将执行另一组不同操作。
原始的流水线并行会有这样的问题:一个输入在后向传递中看到的权重更新并不是其前向传递中所对应的。所以,流水线方案需要确保输入在前向和后向传播中看到一致的权重版本,以实现明确的同步权重更新语义。
模型的层可以用各种方式分配给worker,并且对于输入的前向计算和后向计算使用不同的schedule。层的分配策略和调度策略导致了不同的性能权衡。无论哪种调度策略,为了保持严格的优化器语义,优化器操作步骤需要跨设备同步,这样,在每个批次结束时需要进行流水线刷新来完成微批执行操作(同时没有新的微批被注入)。Megatron-LM引入了定期流水线刷新。
在每个批次的开始和结束时,设备是空闲的。我们把这个空闲时间称为流水线bubble,并希望它尽可能的小。根据注入流水线的微批数量(micro-batches),多达50%的时间可能被用于刷新流水线。微批数量与流水线深度(size)的比例越大,流水线刷新所花费的时间就越少。因此,为了实现高效率,通常需要较大的batch size。
一些方法将参数服务器与流水线并行使用。然而,这些都存在不一致的问题。TensorFlow的GPipe框架通过使用同步梯度下降克服了这种不一致性问题。然而,这种方法需要额外的逻辑来处理这些通信和计算操作流水线,并且会遇到降低效率的流水线气泡,或者对优化器本身的更改会影响准确性。
某些异步和bounded-staleness方法,如PipeMare、PipeDream和PipeDream-2BW完全取消了刷新,但这样会放松了权重更新语义。Megatron会在未来的工作中考虑这些方案。
2.3 技术组合
用户可以使用多种技术来训练大型模型,每种技术都涉及不同的权衡考量。此外,这些技术也可以结合使用。然而,技术的结合可能导致复杂的相互作用,特别是在系统拓扑方面的设计,不仅需要根据算法特点对模型进行合理切割,还需要在软硬件一体的系统架构设计中进行推敲,以实现良好的性能。因此,以下问题显得尤为重要:
如何组合并行技术,以在保留严格的优化器语义的同时,在给定的批量大小下最大限度地提高大型模型的训练吞吐量?
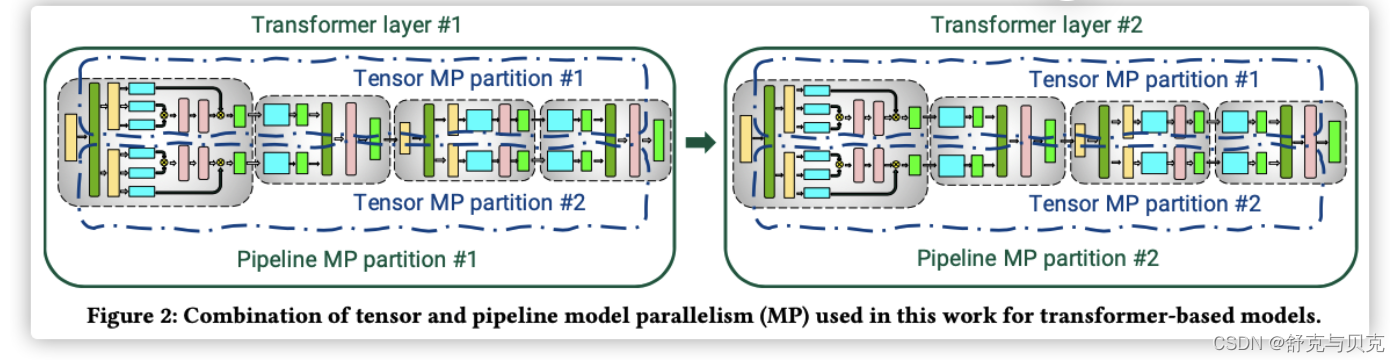
Megatron-LM的开发人员演示了一种名为PTD-P的技术,它结合了流水线、张量和数据并行。这种技术在1000个GPU上训练大型语言模型,以良好的计算性能(达到峰值设备吞吐量的52%)。 PTD-P利用跨多GPU服务器的流水线并行、多GPU服务器内的张量并行和数据并行的组合,利用了在同一服务器和跨服务器的GPU之间具有高带宽链接的优化集群环境,能够训练具有一万亿参数的模型,并具备良好的扩展性。
这种技术示范了如何在大规模分布式系统中充分发挥不同并行技术的优势,以实现高效的大型模型训练。
要实现这种规模化的吞吐量,需要在多个方面进行创新和精心设计:
- 高效的核实现: 关键是实现高效的核(kernel),使大部分计算操作成为计算绑定而不是内存绑定。这意味着计算任务能够更快地完成,从而提高整体的计算效率。
- 智能的计算图分割: 针对设备上的计算图进行智能的分割,以减少通过网络传输的数据量。通过将计算分散到多个设备上,不仅减少了数据传输的成本,还可以限制设备的空闲时间,从而提高整体的计算效率。
- 通信优化和高速硬件利用: 在特定领域实施通信优化,利用高速硬件如先进的GPU,以及在同一服务器内和不同服务器GPU之间使用高带宽链接,可以大幅提升数据传输的速度和效率。这对于分布式系统中的数据交换至关重要。
通过在上述方面进行创新和优化,可以有效地提高大型模型训练的规模化吞吐量,实现更高的训练效率和性能。这需要结合领域专业知识和系统设计,以解决各种挑战并取得成功。
2.4 指导原则
Megatron开发者对不同的并行模式组合以及其之间的影响进行了研究,并总结出了分布式训练的一些指导原则:
- 并行模式的相互作用: 不同的并行化策略之间以复杂的方式相互影响。并行模式的选择会影响通信量、计算核的效率以及由于流水线刷新(流水线气泡)而导致的worker空闲时间。例如,张量模型并行在多GPU服务器上表现良好,但对于大型模型,最好采用流水线模型并行。
- 流水线并行的调度影响: 用于流水线并行的调度方式会影响通信量、流水线气泡的大小以及存储激活所需的内存。Megatron提出了一种新的交错调度方式,相比先前的调度方式,它在稍微增加内存占用的基础上,可以提高多达10%的吞吐量。
- 超参数的影响: 超参数的值,如微批量大小(microbatch size),会影响内存占用、在worker上执行的核效果以及流水线气泡的大小。
- 通信密集性: 分布式训练是通信密集型的过程。使用较慢的节点间连接或者更多的通信密集型分区会限制性能表现。
综合上述指导原则,Megatron开发者通过深入研究不同并行技术的相互作用,超参数的调优以及通信密集性等因素,为分布式训练提供了更加明确的方向,以实现更高效的大型模型训练吞吐量。
Megatron在训练拥有万亿参数的大型模型时,采用了PTD-P(Pipeline, Tensor, and Data Parallelism)方法,从而实现了高度聚合的吞吐量(502 petaFLOP/s)。
在该方法中,Tensor模型并行用于intra-node transformer层,这使得在基于HGX系统的平台上能够高效运行。同时,Pipeline模型并行则被应用于inter-node transformer层,充分利用了集群中多网卡的设计,提升了模型训练的效率。
除此之外,数据并行也在前述两种并行策略的基础上进行了加强,从而使得训练能够扩展到更大规模,并且实现更快的训练速度。
三 张量模型并行(Tensor Model Parallelism)
3.1 原理
这里通过 GEMM 来看看如何进行模型并行,这里要进行的是 XA=Y ,对于模型来说, � 是输入, A是权重, Y 是输出。从数学原理的角度来看,对于神经网络中的线性层(Linear层),可以将其看作是将输入矩阵分块进行计算,然后将计算结果合并成输出矩阵。这个过程涉及矩阵乘法和加法操作,其中矩阵乘法涉及到权重矩阵和输入数据之间的乘法,然后再加上偏置向量。
对于非线性层(例如激活函数层),通常不需要进行额外的设计。这些层的计算过程是基于输入数据应用某种非线性函数,例如ReLU(修正线性单元)、Sigmoid、Tanh等。这些函数在数学上是已知的,只需要将输入数据传递给这些函数,然后得到输出。
整体来看,神经网络的计算可以被抽象为一系列的矩阵和向量操作,其中线性层涉及矩阵乘法和加法,而非线性层涉及特定的函数计算。这些操作在深度学习框架中会被高度优化,以提高计算效率和训练速度。
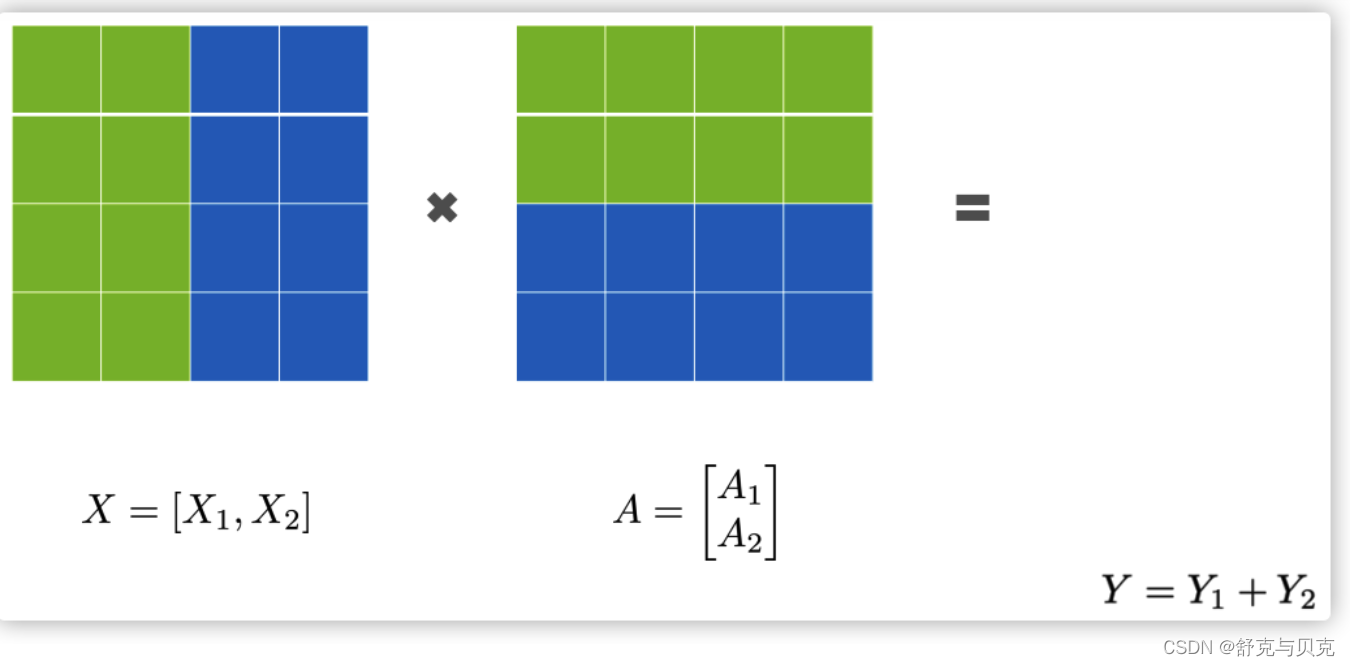
3.2 行并行(Row Parallelism)
我们先看看Row Parallelism,就是把 A 按照行分割成两部分。为了保证运算,同时我们也把 X 按照列来分割为两部分,这里 X1的最后一个维度等于 A1 最前的一个维度,理论上是:

所以,X1和 A1 就可以放到GPU1之上计算,X2 和 A2 可以放到 GPU2 之上,然后把结果相加。
我们接下来进行计算。第一步是把图上横向红色箭头和纵向箭头进行点积,得到Y中的绿色。

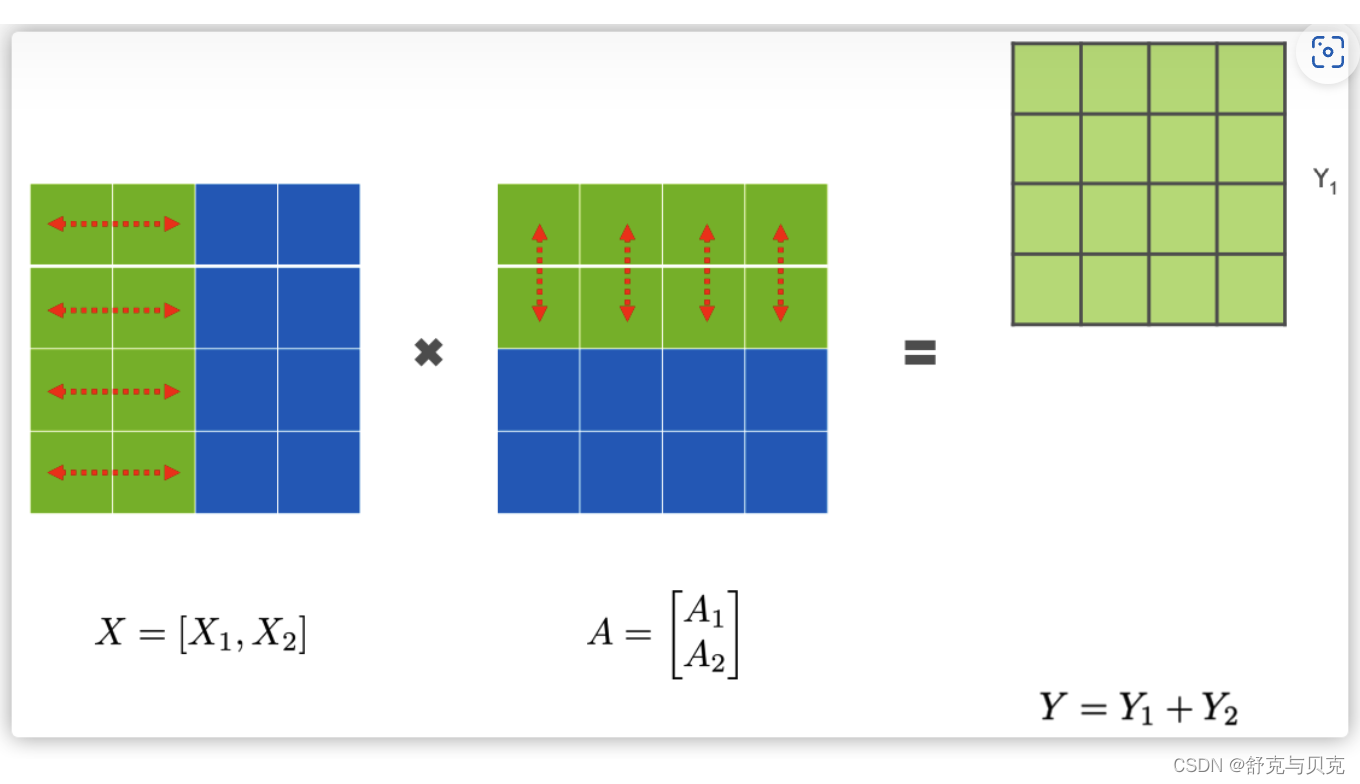
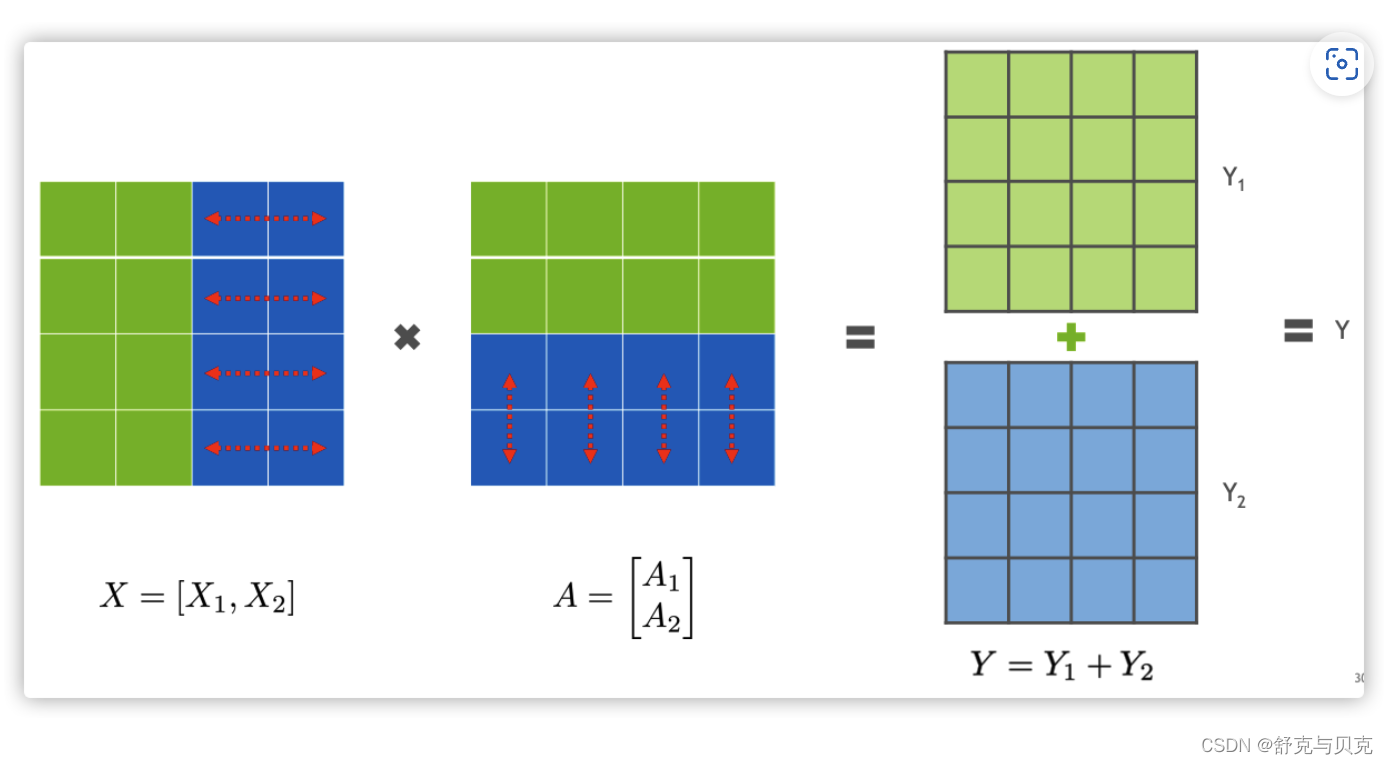
得出了绿色Y1 与蓝色的 Y2,此时,可以把 Y1,Y2 加起来,得到最终的输出 Y 。
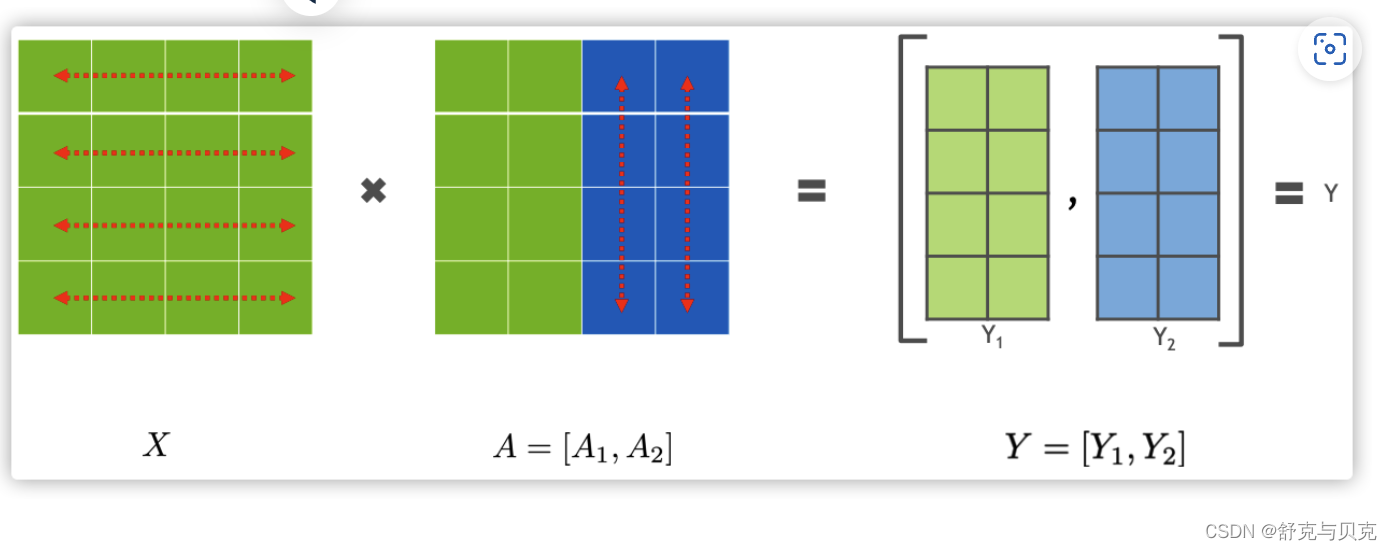
3.2 列并行(Column Parallelism)
接下来看看另外一种并行方式Column Parallelism,就是把 A按照列来分割。
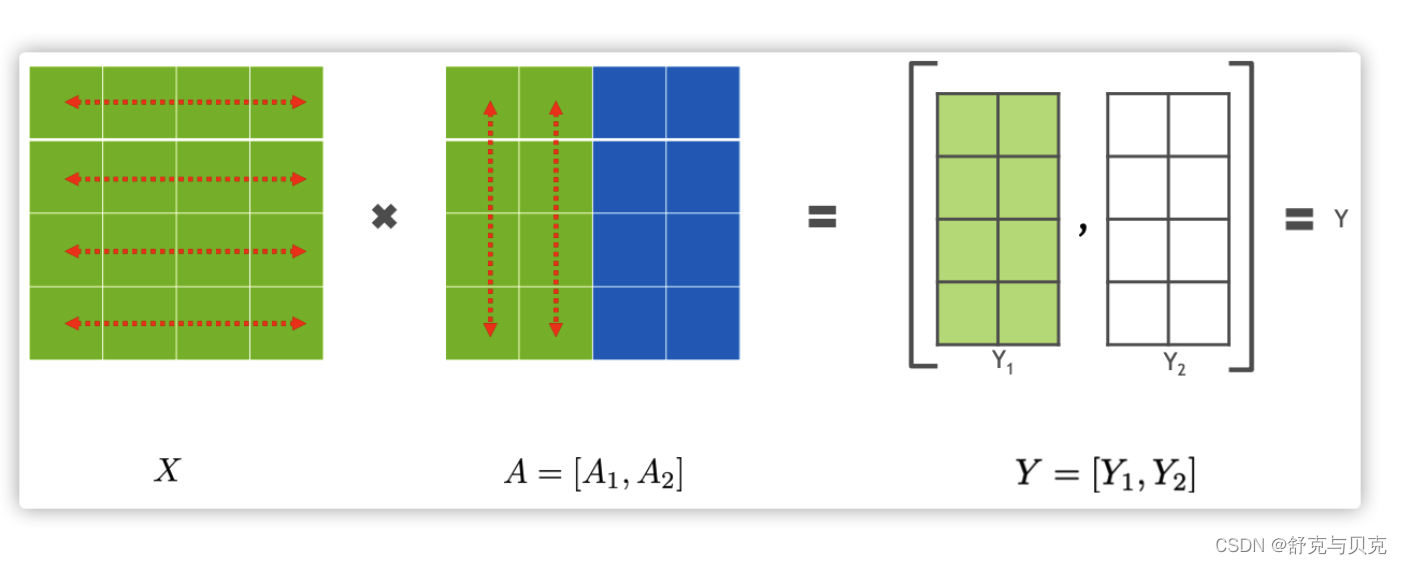
最终计算结果如下:
四 Transformer 张量并行
这里Transformer的模型并行,特指层内切分,即 Tensor Model Parallel。
4.1 Transformer
自从2018年Google的Attention论文推出之后,近年的模型架构都是在 Transformer基础之上完成,模型有多少层,就意味着模型有多少个Transformer块,所以语言模型的计算量主要是Transformer的计算,而Transformer本质上就是大量的矩阵计算,适合GPU并行操作。
Transformers层由一个Masked Multi Self Attention和Feed Forward两部分构成,Feed Forward 部分是一个MLP网络,由多个全连接层构成,每个全连接层是由矩阵乘操作和GeLU激活层或者Dropout构成。
Transformer的每个块包含以下两个主要部分:
- Masked Multi-Head Self Attention: 这是Transformer中的关键机制,用于建立输入序列中各个位置之间的关系。它涉及多个头(head)的自注意力计算,其中每个头会学习不同的上下文关系。在计算过程中,涉及到大量的矩阵乘法操作,这些操作可以被高效地并行执行。
- Feed Forward Neural Network: 这部分也被称为“位置前馈网络”。它包含多个全连接层,每个全连接层都涉及矩阵乘法、激活函数(通常是GeLU)和可能的Dropout层。这些操作也是高度并行化的,可以在GPU上迅速执行。
Megatron 的 Feed Forward 是一个两层多层感知器(MLP),第一层是从 H变成4H,第二层是从 4H 变回到 H,所以Transformer具体架构如下,紫色块对应于全连接层。每个蓝色块表示一个被复制N次的transformer层,红色的 x L 代表此蓝色复制 L 次。

4.2 切分Transformer
分布式张量计算是一种正交且更通用的方法,它将张量操作划分到多个设备上,以加速计算或增加模型大小。FlexFlow是一个进行这种并行计算的深度学习框架,并且提供了一种选择最佳并行化策略的方法。最近,Mesh TensorFlow引入了一种语言,用于指定TensorFlow中的一般分布式张量计算。用户在语言中指定并行维度,并使用适当的集合原语编译生成一个计算图。我们采用了Mesh TensorFlow的相似见解,并利用transformer's attention heads 的计算并行性来并行化Transformer模型。然而,Megatron没有实现模型并行性的框架和编译器,而是对现有的PyTorch transformer实现进行了一些有针对性的修改。Megatron的方法很简单,不需要任何新的编译器或代码重写,只是通过插入一些简单的原语来完全实现,
Megatron就是要把 Masked Multi Self Attention 和Feed Forward 都进行切分以并行化,利用Transformers网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现。
4.2.1 切分MLP

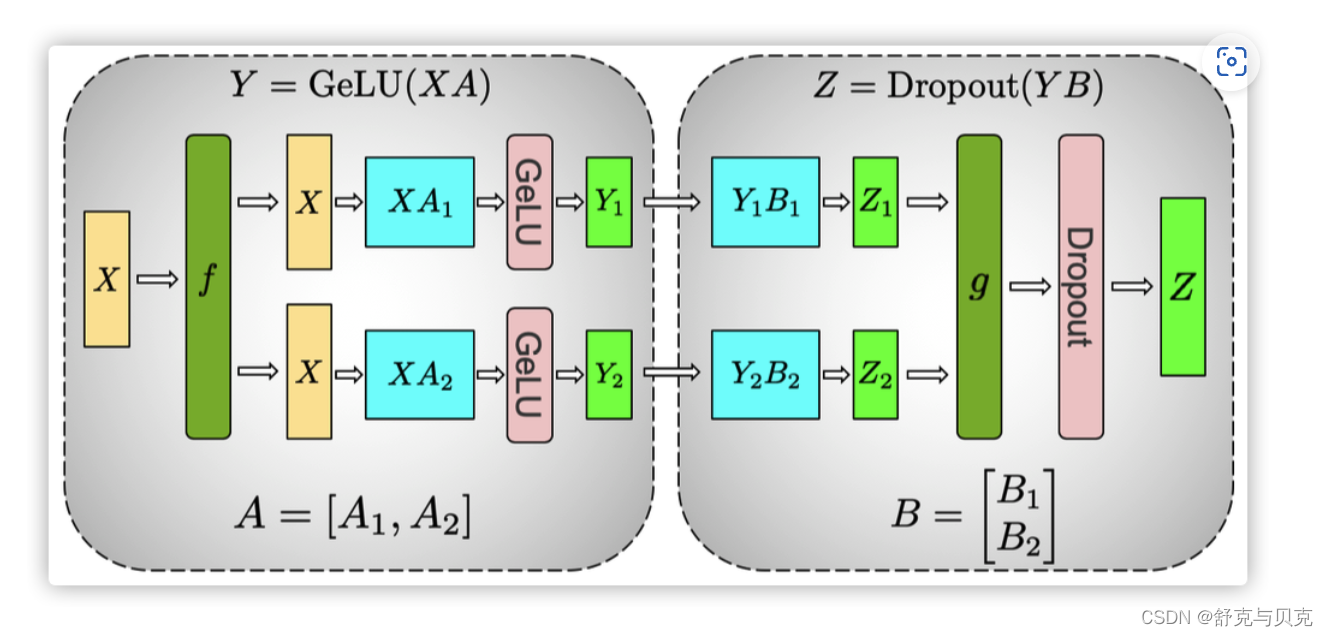
上图第一个是 GeLU 操作,第二个是 Dropout操作,具体逻辑如下:
1. MLP的整个输入 X 通过 f 放置到每一块 GPU 之上。
2. 对于第一个全连接层:
- 使用列分割,把权重矩阵切分到两块 GPU 之上,得到 A1,A2。
- 在每一块 GPU 之上进行矩阵乘法得到第一个全连接层的输出 Y1和 Y2。
3. 对于第二个全连接层:
- 使用行切分,把权重矩阵切分到两个 GPU 之上,得到 B1,B2。
- 前面输出 Y1 和 Y2 正好满足需求,直接可以和 B 的相关部分(B1,B2)做相关计算,不需要通信或者其他操作,就得到了 Z1,Z2。分别位于两个GPU之上。
4. Z1,Z2通过 g 做 all-reduce(这是一个同步点),再通过 dropout 得到了最终的输出 Z。
然后在GPU之上,第二个GEMM的输出在传递到dropout层之前进行规约。这种方法将MLP块中的两个GEMM跨GPU进行拆分,并且只需要在前向过程中进行一次 all-reduce 操作(g 操作符)和在后向过程中进行一次 all-reduce 操作(f 操作符)。
这两个操作符是彼此共轭体,只需几行代码就可以在PyTorch中实现。作为示例,f 运算符的实现如下所示:
f算子的实现。g类似于f,在后向函数中使用identity,在前向函数中使用all-reduce。

4.2.2 切分self attention
如下图所示。
- 首先,对于自我注意力块,Megatron 利用了多头注意力操作中固有的并行性,以列并行方式对与键(K)、查询(Q)和值(V)相关联的GEMM进行分区,从而在一个GPU上本地完成与每个注意力头对应的矩阵乘法。这使我们能够在GPU中分割每个attention head参数和工作负载,每个GPU得到了部分输出。
- 其次,对于后续的全连接层,因为每个GPU之上有了部分输出,所以对于权重矩阵B就按行切分,与输入的 Y1,Y2 进行直接计算,然后通过 g 之中的 all-reduce 操作和Dropout 得到最终结果 Z。

具有模型并行性的transformer块。f和g是共轭的。f在前向传播中使用一个identity运算符,在后向传播之中使用了all reduce,而g在前向传播之中使用了all reduce,在后向传播中使用了identity运算符。
4.2.3 通信成本
来自线性层(在 self attention 层之后)输出的后续GEMM会沿着其行实施并行化,并直接获取并行注意力层的输出,而不需要GPU之间的通信。这种用于MLP和自我注意层的方法融合了两个GEMM组,消除了中间的同步点,并导致更好的伸缩性。这使我们能够在一个简单的transformer层中执行所有GEMM,只需在正向路径中使用两个all-reduce,在反向路径中使用两个all-reduce。

Transformer语言模型输出了一个嵌入,其维数为隐藏大小(H)乘以词汇量大小(v)。由于现代语言模型的词汇量约为数万个(例如,GPT-2使用的词汇量为50257),因此将嵌入GEMM的输出并行化是非常有益的。然而,在transformer语言模型中,想让输出嵌入层与输入嵌入层共享权重,需要对两者进行修改。
我们沿着词汇表维度 E=[E1,E2](按列)对输入嵌入权重矩阵E(h*v)进行并行化。因为每个分区现在只包含嵌入表的一部分,所以在输入嵌入之后需要一个all-reduce(g操作符)。对于输出嵌入,一种方法是执行并行 GEMM[Y1,Y2]=[XE1,XE2]以获得logit,然后添加一个all-gather Y=all−gather([Y1,Y2]),并将结果发送到交叉熵损失函数。但是,在这种情况下,由于词汇表的很大,all-gather 将传递b×s×v个元素(b是batch size,s是序列长度)。为了减小通信规模,我们将并行GEMM[Y1,Y2]的输出与交叉熵损失进行融合,从而将维数降低到b×s.
五 流水线并行与混合并行
5.1 流水线模型并行(Pipeline Model Parallelism)
目前主流的流水线并行方法包括了两种:Gpipe和PipeDream。与这两者相比,Megatron中的流水线并行实现略有不同,它采用了Virtual Pipeline的方法。简而言之,传统的流水线并行通常会在一个设备上放置几个模块,通过在计算强度和通信强度之间取得平衡来提高效率。然而,虚拟流水线则采取相反的策略。在设备数量不变的前提下,它将流水线阶段进一步细分,以承载更多的通信量,从而降低空闲时间的比率,以缩短每个步骤的执行时间。
5.2 混合并行设置(Mix Parallelism)
参考的 Megatron 的论文,先对使用的符号做一个说明。

5.2.1 张量和流水线模型并行 (Tensor and Pipeline Model Parallelism)

不同GPU之间通信量也受 p和 t 的影响。流水线模型并行具有开销更小的点对点通信;另一方面,张量模型并行性使用更消耗带宽的all-reduce通信(向前和向后传递中各有两个all-reduce操作)。
- 使用流水线并行,在每对连续设备(向前或向后传播)之间为每个微批次(micro-batch)执行的通信总量为 b⋅s⋅h , s 是序列长度, h是隐藏大小(hidden size)。
- 使用张量模型并行,每个层前向传播和后向传播中,总大小 b⋅s⋅h 的张量需要在 t个模型副本之中 all-reduce 两次。
因此,这里看到张量模型并行性增加了设备之间的通信量。当 t大于单个节点中的GPU数量时,在较慢的节点间链路上执行张量模型并行是不合算的。
所以,当考虑不同形式的模型并行时,当使用 g台-GPU服务器,通常应该把张量模型并行度控制在 g 之内,然后使用流水线并行来跨服务器扩展到更大的模型。

5.2.2 数据和模型并行 (Data and Model Parallelism)
数据并行和流水线并行

数据并行和张量并行


5.2.3 Microbatch Size


5.2.4 对比
Tensor versus Pipeline Parallelism.
在节点内部(如DGX A100服务器),张量模型的并行性表现最佳,因为这可以降低通信量。另一方面,流水线模型并行性采用更经济的点对点通信方式,可以跨节点执行,而不会受到整个计算的限制。然而,流水线并行性可能会在流水线“气泡”中消耗大量时间,因此应该限制流水线的总数,以确保流水线中微批次(micro-batches)的数量是流水线深度的合理倍数。
因此,当张量模型的并行大小等于单个节点中GPU的数量(例如DGX A100有8个GPU的节点)时,性能会达到峰值。这一结果表明,仅使用张量模型的并行性(如Megatron V1)或仅使用流水线模型的并行性(如PipeDream),都无法与将这两种技术结合使用时的性能相媲美。
Pipeline versus Data Parallelism.
通过实验观察发现,针对每个批次大小(batch size),随着流水线并行规模的增加,吞吐量逐渐减少。因此,流水线模型并行的主要应用场景是支持不适合单个处理单元的大型模型训练,而数据并行则适用于扩大训练规模。
Tensor versus Data Parallelism.
接下来我们来看看数据并行性和张量模型并行性对性能的影响。在处理较大批次量和微批次为1的情况下,数据并行通信并不频繁;而张量模型并行则需要对批次中的每个微批次进行全对全(all-to-all)通信。这种全对全通信在张量模型并行中占据主导地位,对整个端到端的训练时间产生影响,尤其是当通信需要跨多个GPU节点进行时。此外,随着张量模型并行规模的增加,每个GPU上执行的较小矩阵乘法也降低了每个GPU的利用率。
需要注意的是,虽然数据并行可以有效地扩展训练,但不能仅凭数据并行来处理训练批次受限的大型模型,原因如下:a)内存容量不足,b)数据并行的扩展受限(例如,GPT-3的训练批次为1536,因此数据并行仅支持最多1536个GPU的并行化;然而,该模型的训练涉及约10000个GPU)。
六 总结
模型并行方法旨在减少通信和控制GPU计算范围的。不是让一个GPU计算dropout、layer normalization或 residual connection,并将结果广播给其他GPU,而是选择跨GPU复制计算。
模型并行性与数据并行性是正交的,因此我们可以同时使用二者在来训练大型模型。下图显示了一组用于混合模型并行和数据并行性的GPU。
- 一个模型需要占据8张卡,模型被复制了64分,一共启动了512个即成。
- 模型并行。同一服务器内的多个GPU形成模型并行组(model parallel group),例如图中的GPU 1到8,并包含分布在这些GPU上的模型实例。其余的GPU可能位于同一台服务器内,也可能位于其他服务器中,它们运行其他模型并行组。每个模型并行组内的GPU执行组内所有GPU之间的all-reduce。
- 数据并行。在每个模型并行组中具有相同位置的GPU(例如图中的GPU 1,9,…,505)形成数据并行组(data parallel group),即,具有相同模型参数的进程被分配到同一个数据并行组之中。对于数据并行,每个all-reduce操作在每个模型并行组中一个GPU之上执行。
- 所有通信都是通过pytorch调用NCCL来实现的。
在反向传播过程中,我们并行运行多个梯度all-reduce操作,以规约每个不同数据并行组中的权重梯度。所需GPU的总数是模型和数据并行组数量的乘积。
Megatron使用了PTD-P(节点间流水线并行、节点内张量并行和数据并行)在训练具有万亿参数的大型模型时候达到了高聚合吞吐量(502 petaFLOP/s)。
- Tensor模型并行被用于intra-node transformer 层,这样在HGX based系统上高效运行。
- Pipeline 模型并行被用于inter-node transformer 层,其可以有效利用集群中多网卡设计。
- 数据并行则在前两者基础之上进行加持,使得训练可以扩展到更大规模和更快的速度。
深入理解 Megatron-LM(1)基础知识 - 知乎 (zhihu.com)
深入理解 Megatron-LM(2)原理介绍 - 知乎 (zhihu.com)
[源码解析] 模型并行分布式训练Megatron (1) --- 论文&基础 - 掘金 (juejin.cn)
相关文章:
[NLP]深入理解 Megatron-LM
一. 导读 NVIDIA Megatron-LM 是一个基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大型语言模型。Megatron-LM 综合应用了数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并…...

软考高级系统架构设计师系列论文七十八:论软件产品线技术
软考高级系统架构设计师系列论文七十八:论软件产品线技术 一、摘要二、正文三、总结一、摘要 本人作为某软件公司负责人之一,通过对位于几个省的国家甲级、乙级、丙级设计院的考查和了解,我决定采用软件产品线方式开发系列《设计院信息管理平台》产品。该产品线开发主要有如…...
yolov5中添加ShuffleAttention注意力机制
ShuffleAttention注意力机制简介 关于ShuffleAttention注意力机制的原理这里不再详细解释.论文参考如下链接here yolov5中添加注意力机制 注意力机制分为接收通道数和不接受通道数两种。这次属于接受通道数注意力机制,这种注意力机制由于有通道数要求,所示我们添加的时候…...
)
Effective C++条款17——以独立语句将newed 对象置入智能指针(资源管理)
假设我们有个函数用来揭示处理程序的优先权,另一个函数用来在某动态分配所得的widget上进行某些带有优先权的处理: void priority(); void processWidget(std::tr1::shared_ptr<Widget>pw, int priority);由于谨记“以对象管理资源”(条款13&…...

奇迹MU服务器如何选择配置?奇迹MU服务器租用
不同的服务器,根据其特点与性能适用于不同的应用场景,为了让你们更好的理解,我们对服务器进行了分类归纳,结合了服务器不同的特点以及价位进行一个区分,帮助我们更好的选择合适的服务器配置。 VPS服务器 VPS服务器又…...
如何远程管理服务器详解
文章目录 前言一、远程管理类型二、远程桌面三、telnet 命令行远程四、查看本地开放端口 前言 很多公司是有自己的机房的,机房里面会有若干个服务器为员工和用户提供服务。大家可以想想:假设这家公司有上百台服务器,我们作为网络工程师&…...

JavaScript——为什么静态方法不能调用非静态方法
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

Python实现常见的排序算法
当涉及到排序算法时,一些常见的排序算法包括插入排序、选择排序、冒泡排序、快速排序、归并排序和堆排序。以下是使用Python实现这些常见排序算法的示例代码: 插入排序(Insertion Sort): def insertionSort(arr):for…...

【git】fatal: refusing to merge unrelated histories
在一次重新初始化本地仓库后,拉取远程仓库时提示: fatal: refusing to merge unrelated histories 在“fatal: refusing to merge unrelated histories”(即,不知道彼此的存在,并已不匹配的项目提交历史)…...

在编辑器中使用正则
正则是一种文本处理工具,常见的功能有文本验证、文本提取、文本替换、文本切割等。有一些地方说的正则匹配,其实是包括了校验和提取两个功能。 校验常用于验证整个文本的组成是不是符合规则,比如密码规则校验。提取则是从大段的文本中抽取出…...
如果获取UUID(通用唯一标识符))
【Linux】腾讯云服务器(Linux版)如果获取UUID(通用唯一标识符)
1、通过命令获取 sudo /usr/local/qcloud/YunJing/YDEyes/YDService -uuid -v2、通过API获取 curl http://metadata.tencentyun.com/latest/meta-data/uuid3、获取实例唯一ID curl http://metadata.tencentyun.com/latest/meta-data/instance-id4、实例元数据 实例元数据包…...
 - CSerialPort在QT中的使用)
CSerialPort教程4.3.x (4) - CSerialPort在QT中的使用
CSerialPort教程4.3.x (4) - CSerialPort在QT中的使用 环境: QT: 5.6.3前言 CSerialPort项目是一个基于C/C的轻量级开源跨平台串口类库,可以轻松实现跨平台多操作系统的串口读写,同时还支持C#, Java, Python, Node.js等。 CSerialPort项目…...
-[基础知识])
自然语言处理从入门到应用——LangChain:链(Chains)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 在本文中,我们将学习如何在LangChain中创建简单的链式连接并添加组件以及运行它。链式连接允许我们将多个组件组合在一起,创建一个统一的应用程序。例如,我们可以创建一个链式连接&a…...

[ubuntu]linux服务器每次重启anaconda环境变量失效
云服务器每次重启后conda不能用了,应该是系统自动把设置环境变量清除了。如果想继续使用,则可以运行一下 minconda3激活方法: source ~/miniconda3/bin/activate anaconda3激活方法: source ~/anaconda3/bin/activate 你也修改b…...
【数据结构】如何用栈实现队列?图文解析(LeetCode)
LeetCode链接:232. 用栈实现队列 - 力扣(LeetCode) 注:本文默认读者已掌握栈与队列的基本操作 可以看这篇文章熟悉知识点:【数据结构】栈与队列_字节连结的博客-CSDN博客 目录 做题思路 代码实现 1. MyQueue 2. …...

蓝桥杯上岸每日N题 (闯关)
大家好 我是寸铁 希望这篇题解对你有用,麻烦动动手指点个赞或关注,感谢您的关注 不清楚蓝桥杯考什么的点点下方👇 考点秘籍 想背纯享模版的伙伴们点点下方👇 蓝桥杯省一你一定不能错过的模板大全(第一期) 蓝桥杯省一你一定不…...
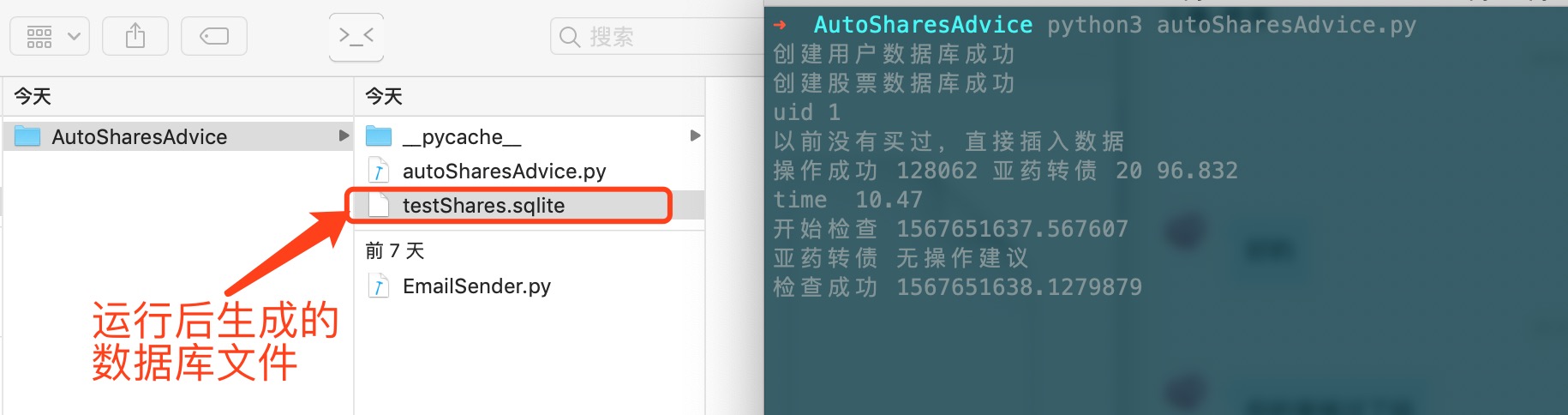
基于Python3 的 简单股票 可转债 提醒逻辑
概述 通过本地的定时轮训,结合本地建议数据库。检查股票可转债价格的同事,进行策略化提醒 详细 前言 为什么会有这么个东西出来呢,主要是因为炒股软件虽然有推送,但是设置了价格之后,看到推送也未必那么及时&#…...
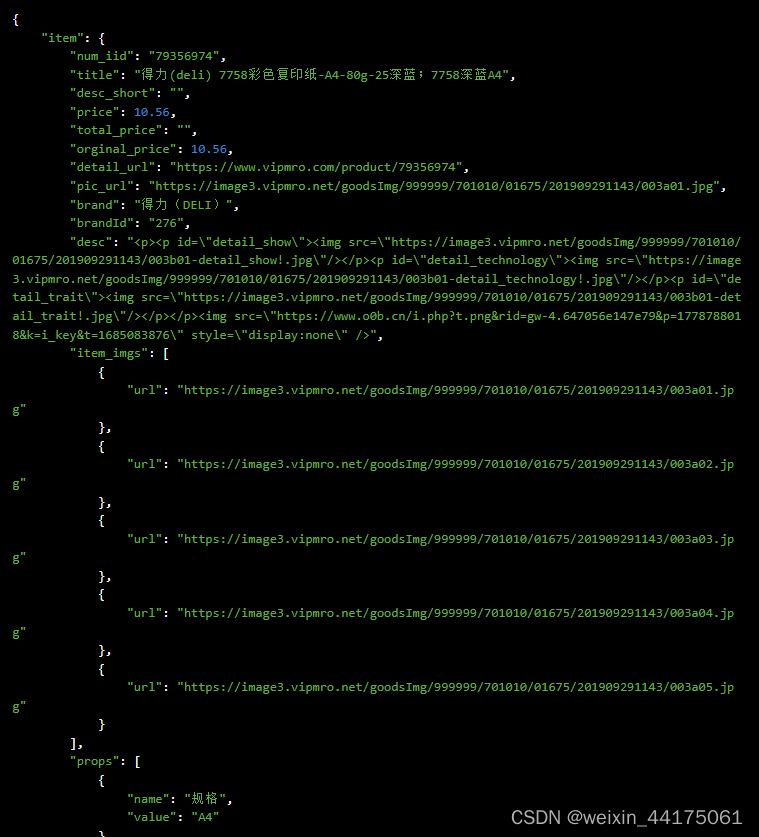
Python“牵手”京东工业商品详情数据采集方法,京东工业商数据API申请步骤说明
京东工业平台介绍 京东工业平台是京东集团旗下的一个B2B电商平台,主要面向企业客户提供一站式的采购服务。京东工业平台依托京东强大的供应链和配送能力,为企业用户提供全品类、全渠道、全场景的采购解决方案,涵盖电子元器件、机械配件、办公…...
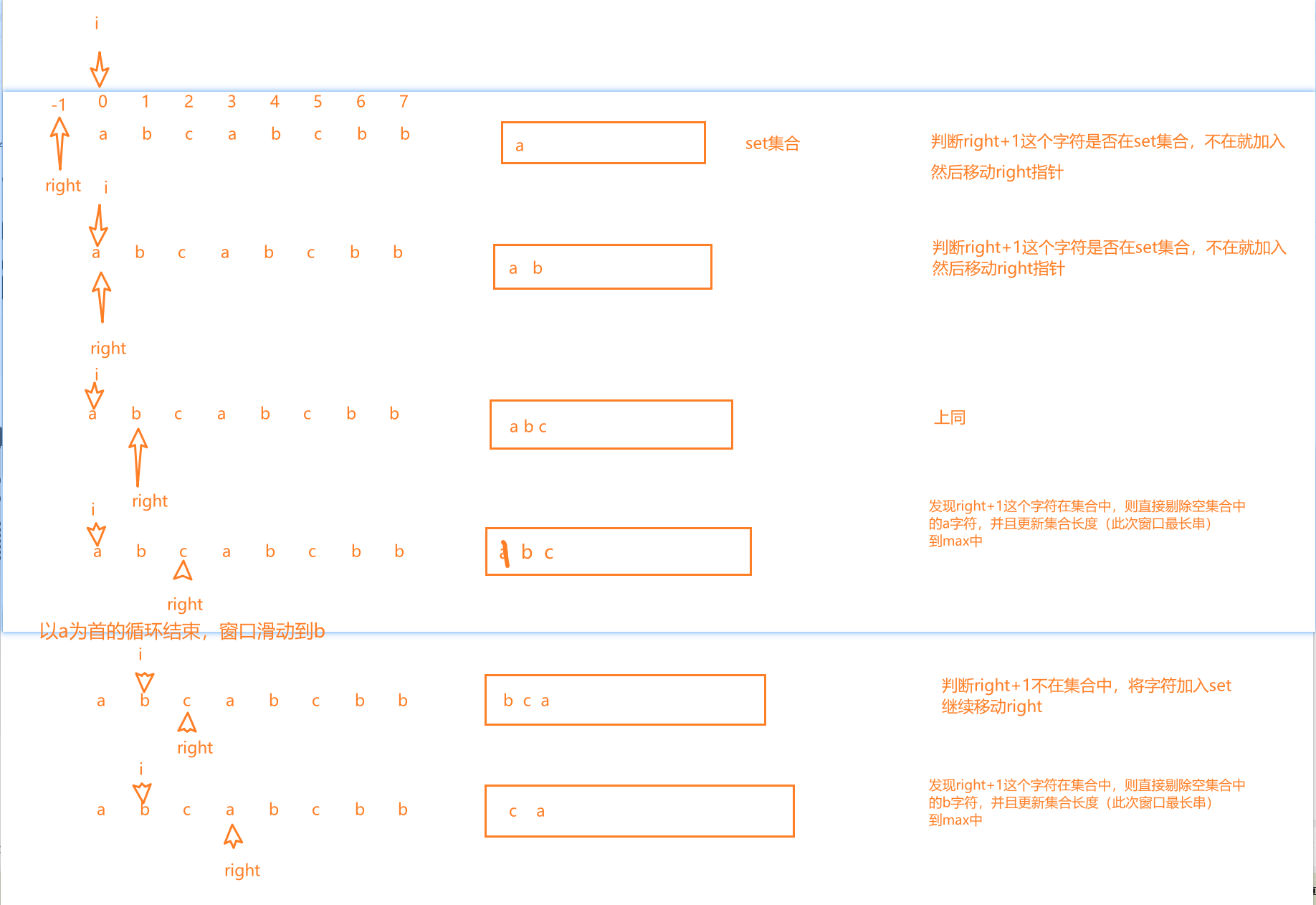
【LeetCode-中等题】3. 无重复字符的最长子串
题目 题解一:单指针,滑动窗口 思路: 设置一个左指针,来判断下一个元素是否在set集合中,如果不在,就加入集合,right继续,如果在,就剔除重复的元素,计算串的长度…...

【教程】Java 集成Mongodb
【教程】Java 集成Mongodb 依赖 <dependency><groupId>org.mongodb</groupId><artifactId>mongo-java-driver</artifactId><version>3.12.14</version></dependency> <dependency><groupId>cn.hutool</groupId…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...