计算机视觉入门 6) 数据集增强(Data Augmentation)
系列文章目录
- 计算机视觉入门 1)卷积分类器
- 计算机视觉入门 2)卷积和ReLU
- 计算机视觉入门 3)最大池化
- 计算机视觉入门 4)滑动窗口
- 计算机视觉入门 5)自定义卷积网络
- 计算机视觉入门 6) 数据集增强(Data Augmentation)
提示:仅为个人学习笔记分享,若有错漏请各位老师同学指出,Thanks♪(・ω・)ノ
目录
- 系列文章目录
- 一、数据集增强(Data Augmentation)
- 伪造数据
- 使用数据增强
- 二、【代码实现】
- Keras 预处理层类型
- 将预处理层添加到模型中
一、数据集增强(Data Augmentation)
伪造数据
提高机器学习模型性能的最佳方法是在更多数据上进行训练。模型有更多的示例可供学习,它将能够更好地识别图像中的哪些差异是重要的,哪些是不重要的。更多的数据有助于模型更好地泛化。
但是在实践中,我们拥有的数据量是有限的。
获取更多数据的一种简单方法是(使用已经拥有的数据)创建假数据。如果我们能够以保持类别不变的方式转换数据集中的图像,我们可以教会分类器忽略这些类型的变换。例如,照片中的汽车是面向左还是面向右,并不会改变它是汽车而不是卡车的事实。因此,如果我们使用翻转图像来增强我们的训练数据,我们的分类器将学会忽略“左或右”是它应该忽略的差异。
这就是数据增强背后的整个思想:添加一些看起来合理像真实数据的额外伪造数据,从而提高分类器的性能。
使用数据增强
通常,在增强数据集时会使用许多种类型的转换。这些可能包括旋转图像、调整颜色或对比度、扭曲图像或许多其他事情,通常以组合方式应用。以下是一张图像可能经过的不同转换的示例。

数据增强通常是在线进行的,意味着在图像被馈送到网络进行训练时进行。回想一下,训练通常是在小批量数据上进行的。当使用数据增强时,以下是批量包含16个图像的示例。

每次在训练期间使用图像时,都会应用一种新的随机变换。这样,模型始终会看到与以前略有不同的内容。训练数据中的这种额外变化有助于模型适应新数据。
然而,需要记住,使用的任何变换都不应该混淆类别。例如,旋转图像会混淆 ‘9’ 和 ‘6’;‘b’和‘d’ 也并不适合水平翻转。不是每种变换都对特定问题有用。
二、【代码实现】
Keras 预处理层类型
Keras提供了两种方式对数据进行增强。
- 第一种方法是在数据流水线中使用类似于ImageDataGenerator的函数包含增强功能。
- 第二种方法是通过使用Keras的预处理层将其包含在模型定义中。这就是我们将采取的方法。对我们来说,主要优点是图像变换将在GPU上计算,而不是在CPU上计算,这可能加快训练过程。
# 所有的 "factor" 参数表示百分比变化
augment = keras.Sequential([# preprocessing.RandomContrast(factor=0.5),preprocessing.RandomFlip(mode='horizontal'), # 水平翻转# preprocessing.RandomFlip(mode='vertical'), # 垂直翻转# preprocessing.RandomWidth(factor=0.15), # 水平拉伸# preprocessing.RandomRotation(factor=0.20), # 随机旋转# preprocessing.RandomTranslation(height_factor=0.1, width_factor=0.1), # 随机平移
])
将预处理层添加到模型中
这里我们跳过步骤1:导入数据,直接在定义模型中添加一些简单的变换,展示如何使用数据集增强这个工具。
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing# 导入预训练模型
pretrained_base = tf.keras.models.load_model('../input/cv-course-models/cv-course-models/vgg16-pretrained-base',
)
pretrained_base.trainable = Falsemodel = keras.Sequential([# 预处理preprocessing.RandomFlip('horizontal'), # 左右翻转preprocessing.RandomContrast(0.5), # 对比度最多变化50%# 基础pretrained_base,# 头部layers.Flatten(),layers.Dense(6, activation='relu'),layers.Dense(1, activation='sigmoid'),
])
相关文章:
计算机视觉入门 6) 数据集增强(Data Augmentation)
系列文章目录 计算机视觉入门 1)卷积分类器计算机视觉入门 2)卷积和ReLU计算机视觉入门 3)最大池化计算机视觉入门 4)滑动窗口计算机视觉入门 5)自定义卷积网络计算机视觉入门 6) 数据集增强(D…...

Python分享之redis(2)
Hash 操作 redis中的Hash 在内存中类似于一个name对应一个dic来存储 hset(name, key, value) #name对应的hash中设置一个键值对(不存在,则创建,否则,修改) r.hset("dic_name","a1","aa&quo…...

springboot aop方式实现敏感数据自动加解密
一、前言 在实际项目开发中,可能会涉及到一些敏感信息,那么我们就需要对这些敏感信息进行加密处理, 也就是脱敏,比如像手机号、身份证号等信息。如果我们只是在接口返回后再去做替换处理,则代码会显得非常冗余…...
RabbitMQ---work消息模型
1、work消息模型 工作队列或者竞争消费者模式 在第一篇教程中,我们编写了一个程序,从一个命名队列中发送并接受消息。在这里,我们将创建一个工作队列,在多个工作者之间分配耗时任务。 工作队列,又称任务队列。主要思…...
GitRedisNginx合集
目录 文件传下载 Git常用命令 Git工作区中文件的状态 远程仓库操作 分支操作 标签操作 idea中使用git 设置git.exe路径 操作步骤 linux配置jdk 安装tomcat 查看是否启动成功 查看tomcat进程 防火墙操作 开放指定端口并立即生效 安装mysql 修改mysql密码 安装lrzsz软…...
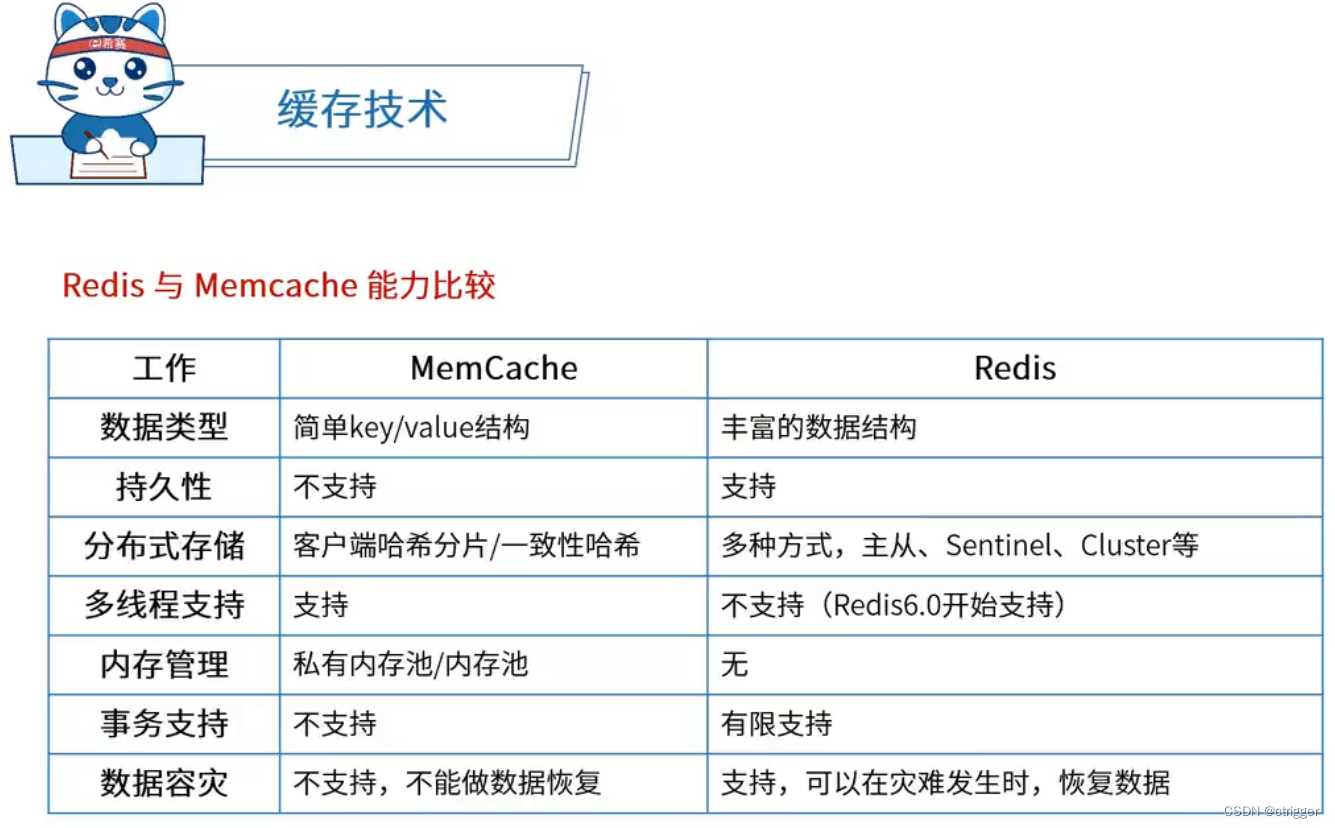
系统架构设计师之缓存技术:Redis与Memcache能力比较
系统架构设计师之缓存技术:Redis与Memcache能力比较...
02.sqlite3学习——嵌入式数据库的基本要求和SQLite3的安装
目录 嵌入式数据库的基本要求和SQLite3的安装 嵌入式数据库的基本要求 常见嵌入式数据库 sqlite3简介 SQLite3编程接口模型 ubuntu 22.04下的SQLite安装 嵌入式数据库的基本要求和SQLite3的安装 嵌入式数据库的基本要求 常见嵌入式数据库 sqlite3简介 SQLite3编程接口模…...
AIGC ChatGPT 按年份进行动态选择的动态图表
动态可视化分析的好处与优势: 1. 提高信息理解性:可视化分析使得大量复杂的数据变得易于理解,通过图表、颜色、形状、尺寸等方式,能够直观地表现不同的数据关系和模式。 2. 加快决策速度:数据可视化可以帮助用户更快…...
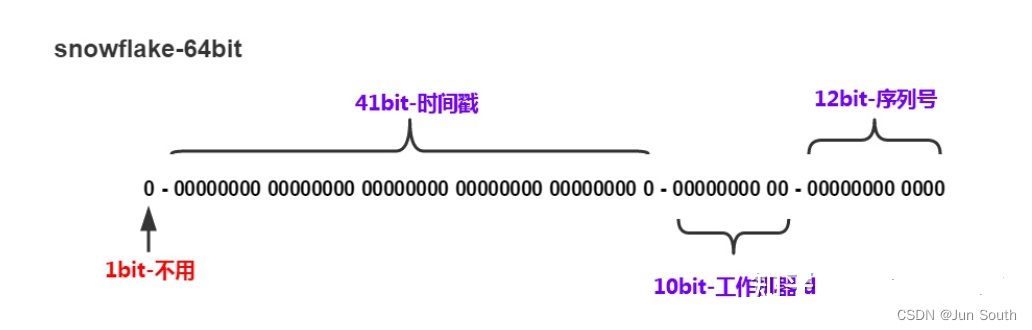
分布式—雪花算法生成ID
一、简介 1、雪花算法的组成: 由64个Bit(比特)位组成的long类型的数字 0 | 0000000000 0000000000 0000000000 000000000 | 00000 | 00000 | 000000000000 1个bit:符号位,始终为0。 41个bit:时间戳,精确到毫秒级别&a…...

Python语言实现React框架
迷途小书童的 Note 读完需要 6分钟 速读仅需 2 分钟 1 reactpy 介绍 reactpy 是一个用 Python 语言实现的 ReactJS 框架。它可以让我们使用 Python 的方式来编写 React 的组件,构建用户界面。 reactpy 的目标是想要将 React 的优秀特性带入 Python 领域,…...
Netty入门学习和技术实践
Netty入门学习和技术实践 Netty1.Netty简介2.IO模型3.Netty框架介绍4. Netty实战项目学习5. Netty实际应用场景6.扩展 Netty 1.Netty简介 Netty是由JBOSS提供的一个java开源框架,现为 Github上的独立项目。Netty提供异步的、事件驱动的网络应用程序框架和工具&…...
MySQL详细安装与配置
免安装版的Mysql MySQL关是一种关系数据库管理系统,所使用的 SQL 语言是用于访问数据库的最常用的 标准化语言,其特点为体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,在 Web 应用方面 MySQL 是最好的 RDBMS(Relation…...

裸露土堆识别算法
裸露土堆识别算法首先利用图像处理技术,提取出图像中的土堆区域。裸露土堆识别算法首通过计算土堆中被绿色防尘网覆盖的比例,判断土堆是否裸露。若超过40%的土堆没有被绿色防尘网覆盖,则视为裸露土堆。当我们谈起计算机视觉时,首先…...

说说你对Redux的理解?其工作原理?
文章目录 redux?工作原理如何使用后言 redux? React是用于构建用户界面的,帮助我们解决渲染DOM的过程 而在整个应用中会存在很多个组件,每个组件的state是由自身进行管理,包括组件定义自身的state、组件之间的通信通…...

《基于 Vue 组件库 的 Webpack5 配置》7.路径别名 resolve.alias 和 性能 performance
路径别名 resolve.alias const path require(path);module.exports {resolve: {alias: {"": path.resolve(__dirname, "./src/"),"assets": path.resolve(__dirname, "./src/assets/"),"mixins": path.resolve(__dirname,…...
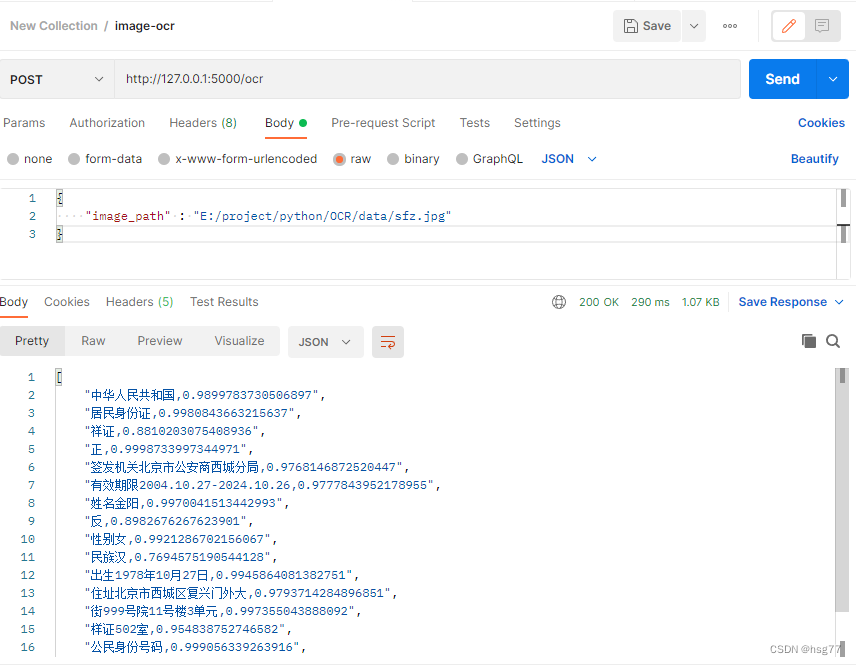
基于PaddleOCR2.7.0发布WebRest服务测试案例
基于PaddleOCR2.7.0发布WebRest服务测试案例 #WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. #警告:这是一个开发服务器。不要在生产部署中使用它。请改用生产WSGI服务器。 输出结果…...
)
Solidity 合约安全,常见漏洞 (下篇)
Solidity 合约安全,常见漏洞 (下篇) Solidity 合约安全,常见漏洞 (上篇) 不安全的随机数 目前不可能用区块链上的单一交易安全地产生随机数。区块链需要是完全确定的,否则分布式节点将无法达…...

nodejs根据pdf模板填入中文数据并生成新的pdf文件
导入pdf-lib库和fontkit npm install pdf-lib fs npm install pdf-lib/fontkit 具体代码 const { PDFDocument, StandardFonts } require(pdf-lib); const fs require(fs); const fontkit require(pdf-lib/fontkit) let pdfDoc let font async function fillPdfForm(temp…...

UE4与pycharm联合仿真的调试问题及一些仿真经验
文章目录 ue4与pycharm联合仿真的调试问题前言ue4端的debug过程pycharm端 一些仿真经验小结 ue4与pycharm联合仿真的调试问题 前言 因为在实验中我需要用到py代码输出控制信息给到ue4中,并且希望看到py端和ue端分别在运行过程中的输出以及debug调试。所以…...
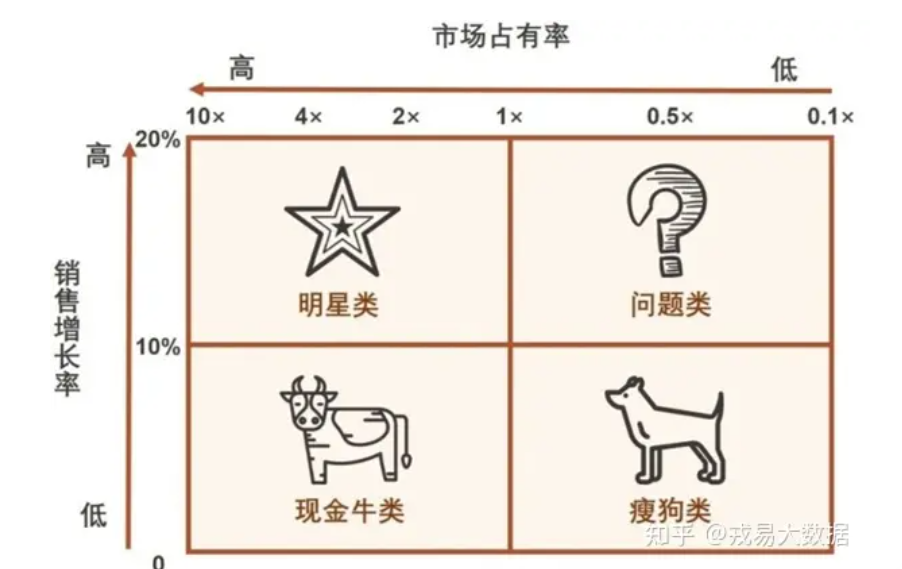
【数据分析】波士顿矩阵
波士顿矩阵是一种用于分析市场定位和企业发展战略的管理工具。由美国波士顿咨询集团(Boston Consulting Group)于1970年提出,并以该集团命名。 波士顿矩阵主要基于产品生命周期和市场份额两个维度,将企业的产品或业务分为四个象限…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...