视觉注意力收集
参考博文:神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_pynq 注意力机制_Bubbliiiing的博客-CSDN博客
【计算机视觉】详解 自注意力:Non-local 模块与 Self-attention (视觉注意力机制 (一))_自注意力模块_何处闻韶的博客-CSDN博客
参考视频:
SEnet模块实现_哔哩哔哩_bilibili
视觉注意力代码汇总仓库:
GitHub - MenghaoGuo/Awesome-Vision-Attentions: Summary of related papers on visual attention. Related code will be released based on Jittor gradually.
https://github.com/xmu-xiaoma666/External-Attention-pytorch
背景
在计算机视觉中,注意力机制 (attention) 旨在让系统学会注意力 —— 能够忽略无关信息而关注重点信息。
分类1
注意力机制一种是软注意力 (soft attention),另一种则是强注意力 (hard attention)。
软注意力
这种注意力 更关注 区域 或 通道,而且软注意力是 确定性的 注意力,学习完成后直接可以通过网络生成。最关键之处在于软注意力是 可微 的,这意味着其可通过神经网络算出梯度 (如 PyTorch 自动求导),且前向传播和后向反馈来习得注意力的权重。
强注意力
与软注意力不同点在于,首先它 更关注 点,即图像中的 每个点都有可能延伸出注意力;同时强注意力是一个 随机的预测过程,更强调 动态变化。当然,最关键之处在于,强注意力是 不可微的,训练过程往往是通过 强化学习 (reinforcement learning) 来完成的。
本文中主要讲软注意力!
分类2
注意力分成了四种基本类型:通道注意力、空间注意力、时间注意力和分支注意力,以及两种组合注意力:通道-空间注意力和空间-时间注意力。

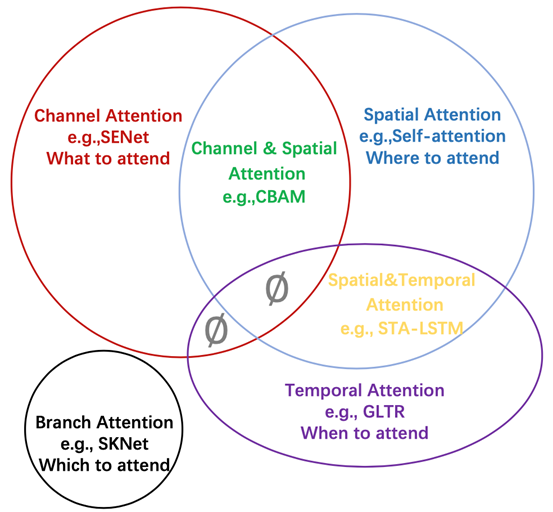
SENet-通道注意力
SENet是通道注意力机制的典型实现。
2017年提出的SENet是最后一届ImageNet竞赛的冠军,其实现示意图如下所示,对于输入进来的特征层,我们关注其每一个通道的权重,对于SENet而言,其重点是获得输入进来的特征层,每一个通道的权值。利用SENet,我们可以让网络关注它最需要关注的通道。
其具体实现方式就是:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
代码
import torch
from torch import nnclass senet(nn.Module):def __init__(self, channel, ratio=16): # channel为输入通道数,ratio为压缩比super(senet, self).__init__() # 初始化父类self.avg_pool = nn.AdaptiveAvgPool2d(1) # 1.全局平均池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图self.fc = nn.Sequential( # 2.两个全连接层nn.Linear(channel, channel // ratio, False), # 第一次全连接神经元个数较少,输入通道数,输出通道数,是否偏置nn.ReLU(inplace=True), # 激活函数nn.Linear(channel // ratio, channel, False), # 第二次全连接神经元个数和输入特征层相同。nn.Sigmoid(), # 激活函数)def forward(self, x):b, c, h, w = x.size() # b为batch_size,c为通道数,h为高,w为宽avg = self.avg_pool(x) # 全局平均池化后,将特征图拉伸成一维向量 b*c*h*w -> b*c*1*1avg = avg.view(b, c) # b*c*1*1 -> b*cfc = self.fc(avg).view([b, c, 1, 1]) # 对平均池化后的特征图进行两次全连接,再view reshape方便后面的处理 #b*c -> b*c*1*1print(fc) # 打印测试一下return x * fc #4.乘上原输入特征层# 测试一下
model = senet(512)
print(model)
inputs = torch.ones([2, 512, 26, 26])
output = model(inputs)
CBAM-通道+空间注意力

CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
通道注意力CAM

图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。这两个池化都是对高,宽进行池化的。在完成池化后可以获得两个特征长条,特征长条长度都是我们输入的通道数。
之后对平均池化和最大池化的结果(特征长条),利用共享的全连接层进行处理,全连接层负责学习通道之间的权重关系,增强重要通道的特征响应,并抑制不重要通道的特征响应,这个过程相当于对每个通道应用一个可学习的权重系数。
全连接后得到特征长条,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。(这个绿色部分和我们原特征层的通道数一样
空间注意力SAM

我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值,与上面对高宽进行池化不同,此处对通道进行池化。相当于把输入图像压瘪了,通道数为1。
将这些压瘪的图像堆叠之后得到高宽为2(HxWx2)的特征层。
对高宽为2的特征图利用一次通道数为1的卷积调整通道数,获得高宽为1(HxWx1)的特征层,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
代码
# 是通道注意力和空间注意力的结合
import torch
from torch import nn# 通道注意力
class channel_attention(nn.Module):def __init__(self,channel, ratio = 16): # channel为输入通道数,ratio为压缩比super(channel_attention, self).__init__() # 初始化父类self.max_pool = nn.AdaptiveMaxPool2d(1) # 全局最大池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图self.fc = nn.Sequential( # 2.两个全连接层nn.Linear(channel, channel//ratio, False) # 第一次全连接神经元个数较少,输入通道数,输出通道数,是否偏置,nn.ReLU(inplace=True) # 激活函数,nn.Linear(channel//ratio, channel, False) # 第二次全连接神经元个数和输入特征层相同。)self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):b, c, h, w = x.size()max_pool_out = self.max_pool(x).view([b,c]) # 全局最大池化后,将特征图拉伸成一维向量 b*c*h*w -> b*c*1*1, 再view reshape方便后面的处理, b*c*1*1 -> b*cavg_pool_out = self.avg_pool(x).view([b,c]) # 全局平均池化后,将特征图拉伸成一维向量 b*c*h*w -> b*c*1*1, 再view reshape方便后面的处理, b*c*1*1 -> b*c#再用全连接层进行处理max_fc_out = self.fc(max_pool_out).view([b,c,1,1]) # b*c -> b*c*1*1avg_fc_out = self.fc(avg_pool_out).view([b,c,1,1]) # b*c -> b*c*1*1#相加out = max_fc_out + avg_fc_outout = self.sigmoid(out) # 激活函数return x * out # 通道注意力机制的输出# 空间注意力
class spatial_attention(nn.Module):def __init__(self,kernel_size = 7): # kernel_size为卷积核的大小super(spatial_attention, self).__init__() # 初始化父类self.conv = nn.Conv2d(2, 1, kernel_size, 1, padding=kernel_size//2,bias=False) # 1.卷积层self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):max_out,_ = torch.max(x, dim=1, keepdim=True) # 最大池化, _为最大值的索引,这里不需要;keepdim=True保持维度不变avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化pool_out = torch.cat([avg_out,max_out], dim=1) # 拼接out = self.conv(pool_out) # 卷积out = self.sigmoid(out) # 激活函数return x * out # 空间注意力机制的输出# CBAM模块, 结合通道注意力机制和空间注意力机制
class CBAM(nn.Module):def __init__(self, channel, ratio = 16, kernel_size = 7):super(CBAM, self).__init__()# 定义通道注意力机制self.channel_attention = channel_attention(channel, ratio)# 定义空间注意力机制self.spatial_attention = spatial_attention(kernel_size)def forward(self,x):x = self.channel_attention(x) # 通道注意力机制的输出x = self.spatial_attention(x) # 空间注意力机制的输出return x# 测试一下
model = CBAM(512)
print(model)
inputs = torch.ones([2, 512, 26, 26])
output = model(inputs)
ECA-通道注意力的改进版
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。1D卷积是一种应用于序列数据(或一维数据)的卷积操作。在计算机视觉中,我们熟悉的卷积通常是应用于图像数据的2D卷积,而1D卷积则主要用于处理一维序列数据,例如文本、语音和时间序列数据等。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。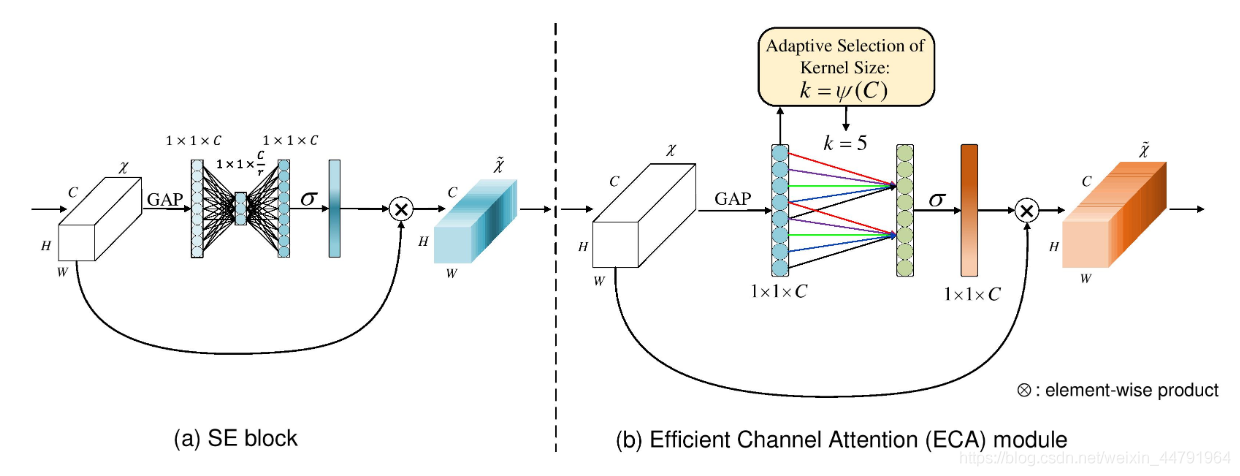
代码
import mathimport torch
import torch.nn as nnclass eca_block(nn.Module):def __init__(self,channel,gamma= 2,b = 1):super(eca_block,self).__init__() # 初始化父类kernel_size = int(abs((math.log(channel, 2)+b )/ gamma)) # 计算卷积核大小kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1 # 卷积核大小必须为奇数padding = kernel_size//2 # 填充大小self.avg_pool = nn.AdaptiveAvgPool2d(1) # 1.全局平均池化.由于是在高和宽上进行的,所以输出的是一个1*1的特征图,这里的1表示输出的通道数# 定义1D卷积self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=padding, bias=False) # 2.一维卷积,这里的1,1是把它当作序列模型来看self.sigmoid = nn.Sigmoid() # 激活函数def forward(self, x):b, c, h, w = x.size() # b为batch_size,c为通道数,h为高,w为宽avg = self.avg_pool(x).view([b,1,c]) # 全局平均池化后,将特征图拉伸成一维向量 b*c*h*w -> b*1*c, 第一个维度是batchsize, 第二个维度是通道数,第二个维度是特征长度,第三个维度代表每个时序out = self.conv(avg) # 一维卷积out = self.sigmoid(out).view(b,c,1,1) # 激活函数,再reshape成b*c*1*1return out*x# 测试一下
model = eca_block(512)
print(model)
inputs = torch.ones([2, 512, 26, 26])
output = model(inputs)自注意力
首先我们要区分一般的注意力机制和自注意力机制
一般注意力的过程是通过一个查询变量 Q,去找到 V 里面比较重要的东西:
1)它先假设 K==V,然后 QK 相乘求相似度A,然后 AV 相乘得到注意力值Z,这个 Z 就是 V 的另外一种形式的表示
Q 可以是任何一个东西,V 也是任何一个东西, K往往是等同于 V 的(同源),但是不同源也可以!!!
总之,注意力机制是一个很宽泛(宏大)的一个概念,QKV 相乘就是注意力,但是他没有规定 QKV是怎么来的,他只规定 QKV 怎么做
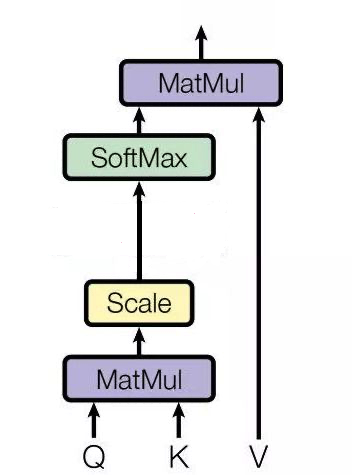
而QKV如果从同一个矩阵中获得,那么就叫做自注意力,不仅规定了 QKV 同源,而且固定了 QKV 的做法
QKV不同源呢,就是交叉注意力机制
感觉还蛮流行的,到时候单独写一篇好了
注意力机制应用
注意力机制是一个即插即用的模块,理论上可以放在任何一个特征层后面,可以放在主干网络,也可以放在加强特征提取网络。
由于放置在主干会导致网络的预训练权重无法使用,一般将注意力机制应用加强特征提取网络上。
下面是一些添加注意力模块时的常见情况,以及可能会产生好坏效果的因素:
添加效果会好的情况:
-
大尺寸图像或复杂任务:当处理大尺寸图像或者复杂的任务时,网络需要处理更多的信息和细节。此时,注意力机制可以帮助网络在解码器阶段集中注意力,关注对任务更重要的局部信息,而忽略不重要的区域。
-
长距离依赖:在一些任务中,像语义分割或图像生成等,信息的联系可能存在长距离的依赖。注意力机制可以帮助捕获远距离区域之间的关系,从而更好地理解图像的语义。
-
不平衡数据:当数据集存在类别不平衡时,注意力机制可以帮助网络更好地处理少数类别,从而提高模型对少数类别的分割效果。
添加会起到反作用的情况:
-
小数据集:对于小规模数据集,引入复杂的注意力机制可能导致过拟合,因为模型可能会在训练数据中过度关注细节,而无法泛化到新数据上。
-
简单任务:在处理相对简单的任务或者小尺寸图像时,注意力机制可能会引入额外的计算负担,而无法给模型带来明显的性能提升。
-
不恰当的设计:如果注意力模块的设计不当,例如过于复杂、参数量过大或者超参数设置不合理,可能会导致模型收敛困难或者性能下降。
未来展望
-
注意力机制的充分必要条件
-
更加通用的注意力模块
-
注意力机制的可解释性
-
注意力机制中的稀疏激活
-
基于注意力机制的预训练模型
-
适用于注意力机制的优化方法
-
部署注意力机制的模型
相关文章:
视觉注意力收集
参考博文:神经网络学习小记录64——Pytorch 图像处理中注意力机制的解析与代码详解_pynq 注意力机制_Bubbliiiing的博客-CSDN博客 【计算机视觉】详解 自注意力:Non-local 模块与 Self-attention (视觉注意力机制 (一))_自注意力模块_何处闻韶的博客-CS…...
StableVideo:使用Stable Diffusion生成连续无闪烁的视频
使用Stable Diffusion生成视频一直是人们的研究目标,但是我们遇到的最大问题是视频帧和帧之间的闪烁,但是最新的论文则着力解决这个问题。 本文总结了Chai等人的论文《StableVideo: Text-driven consistency -aware Diffusion Video Editing》ÿ…...
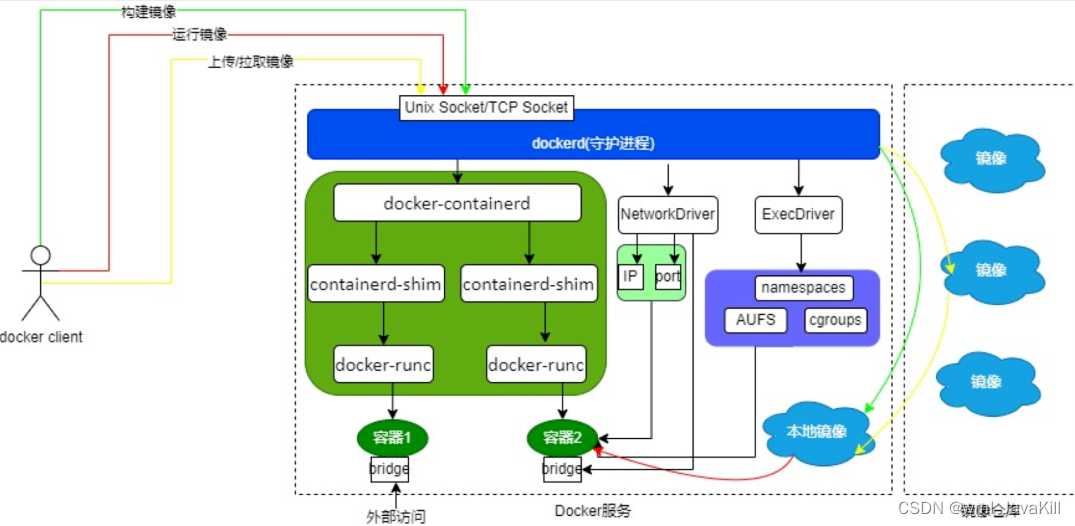
「快学Docker」Docker容器安全性探析
「快学Docker」Docker容器安全性探析 引言容器安全性威胁Docker容器安全性目录容器镜像安全性主机与容器隔离访问控制运行时监控与防御网络安全性Docker容器安全性最佳实践 总结 引言 在当今快速发展的软件开发和部署领域,容器化技术已经成为一种不可或缺的工具。然…...

鲍威尔“放鹰”,美联储或将再加息?
KlipC报道:美联储主席鲍威尔8月25日举行的杰克逊霍尔全球央行年会上表示,尽管过去一年通胀总体持续下行,但住房和服务通胀仍处于高位,鲍威尔也表达了通胀上行风险的担忧,多次表示可能会在适当的情形进一步加息。演讲结…...

docker go安装库失败
在 Docker 容器中使用 Go 获取包时超时,可能是由于网络问题或者是由于特定的网络限制。以下是一些建议和解决方法: 更改下载源: Go 默认使用 proxy.golang.org 作为模块代理。在某些地区或网络环境中,这可能会导致超时。你可以尝试更改 Go 的…...

利用python进行键盘模拟输入
记一次利用python模拟键盘输入,由于键盘中英文切换较为麻烦,所以写了两个小程序分别进行英文字符模拟或中文字符模拟。 #用于键盘英文字符输入模拟 import pyautogui import timedef simulate_typing(text):# Give some time to switch to the desired …...
--spring篇)
2024年java面试(二)--spring篇
文章目录 1.spring事务传播机制2.spring事务失效原因3.Bean的生命周期4.Bean作用域5.依赖注入三种方式(Ioc的三种实现方式)6.实例化bean的三种方式7.IOC容器初始化加载Bean流程 1.spring事务传播机制 声明式事务虽然优于编程式事务,但也有不…...
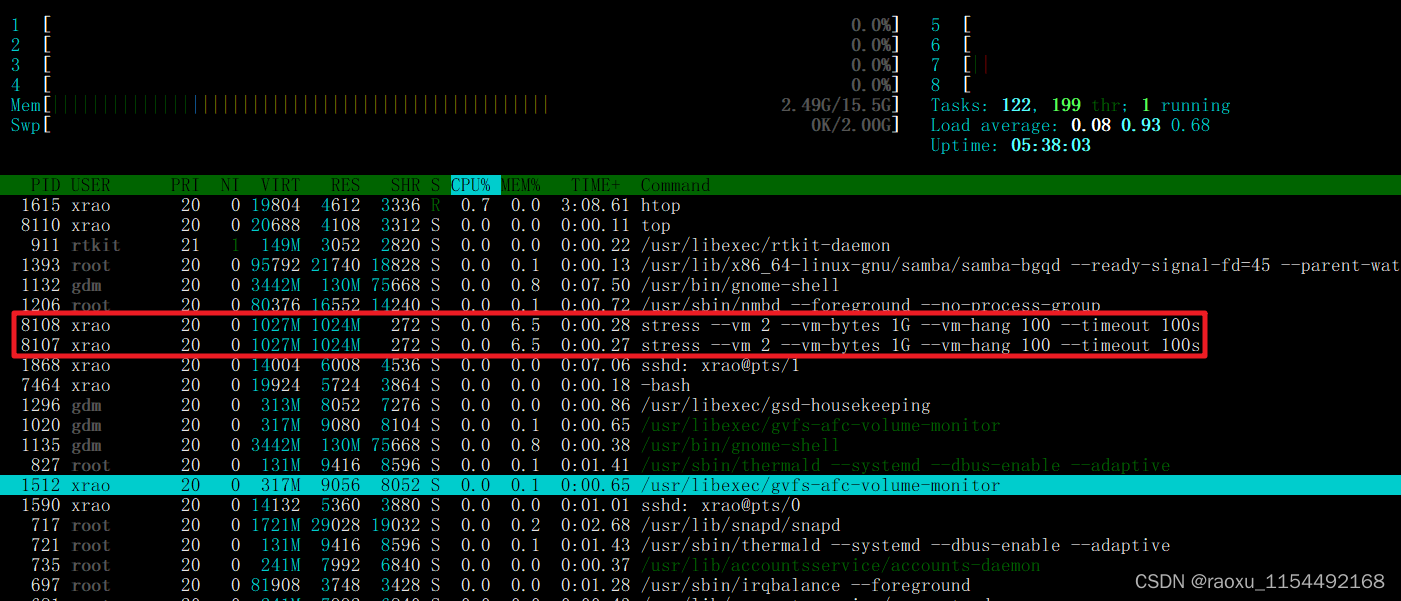
cyclictest stress 工具 使用
工具介绍 1. Cyclictest 准确且重复地测量线程的预期唤醒时间与它实际唤醒的时间之间的差异,以提供有关系统延迟的统计数据。 它可以测量由硬件、固件和操作系统引起的实时系统延迟 2.stress是Linux的一个压力测试工具,可以对CPU、Memory、IO、磁盘进行…...

天合翔宇荣获 HICOOL 2023 全球创业者大赛决赛二等奖
8 月 25 日晚,主题为“聚势创新 向光而行”的 HICOOL2023 全球创业者峰会开幕式,在中国国际展览中心(顺义馆)举行。北京市委书记尹力宣布开幕,市委副书记、市长殷勇致辞,市委副书记刘伟出席。 开幕式之后&…...
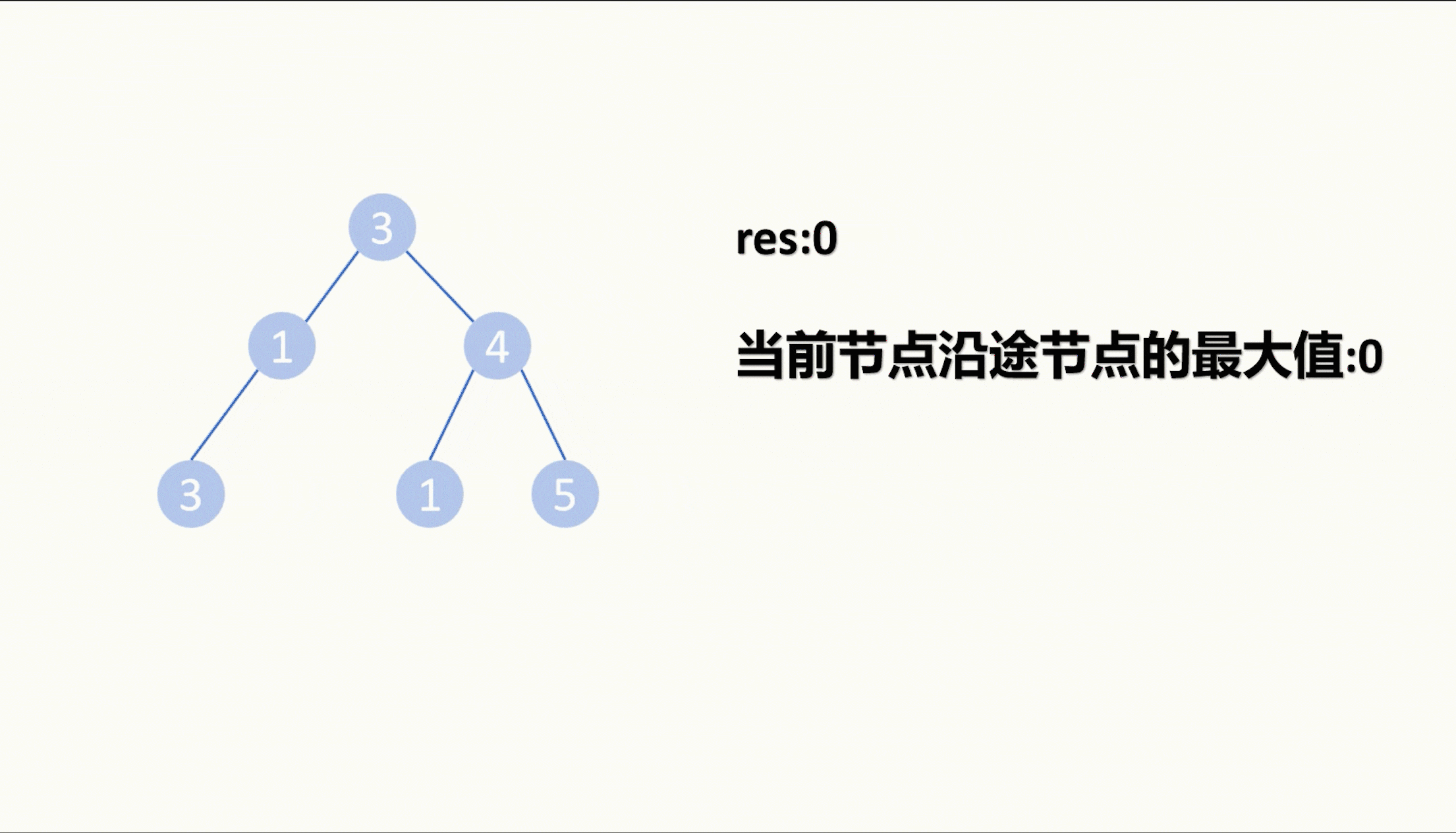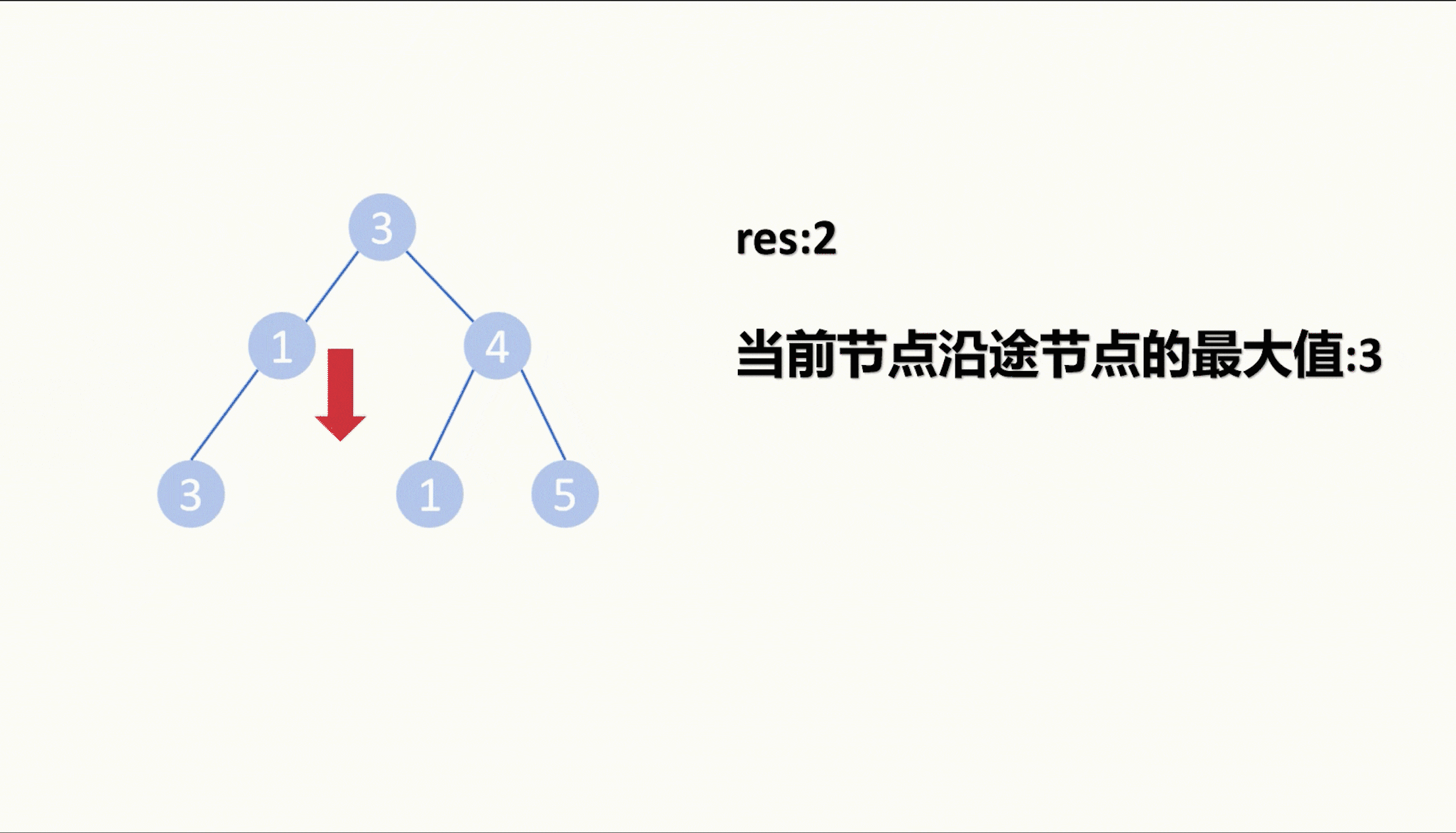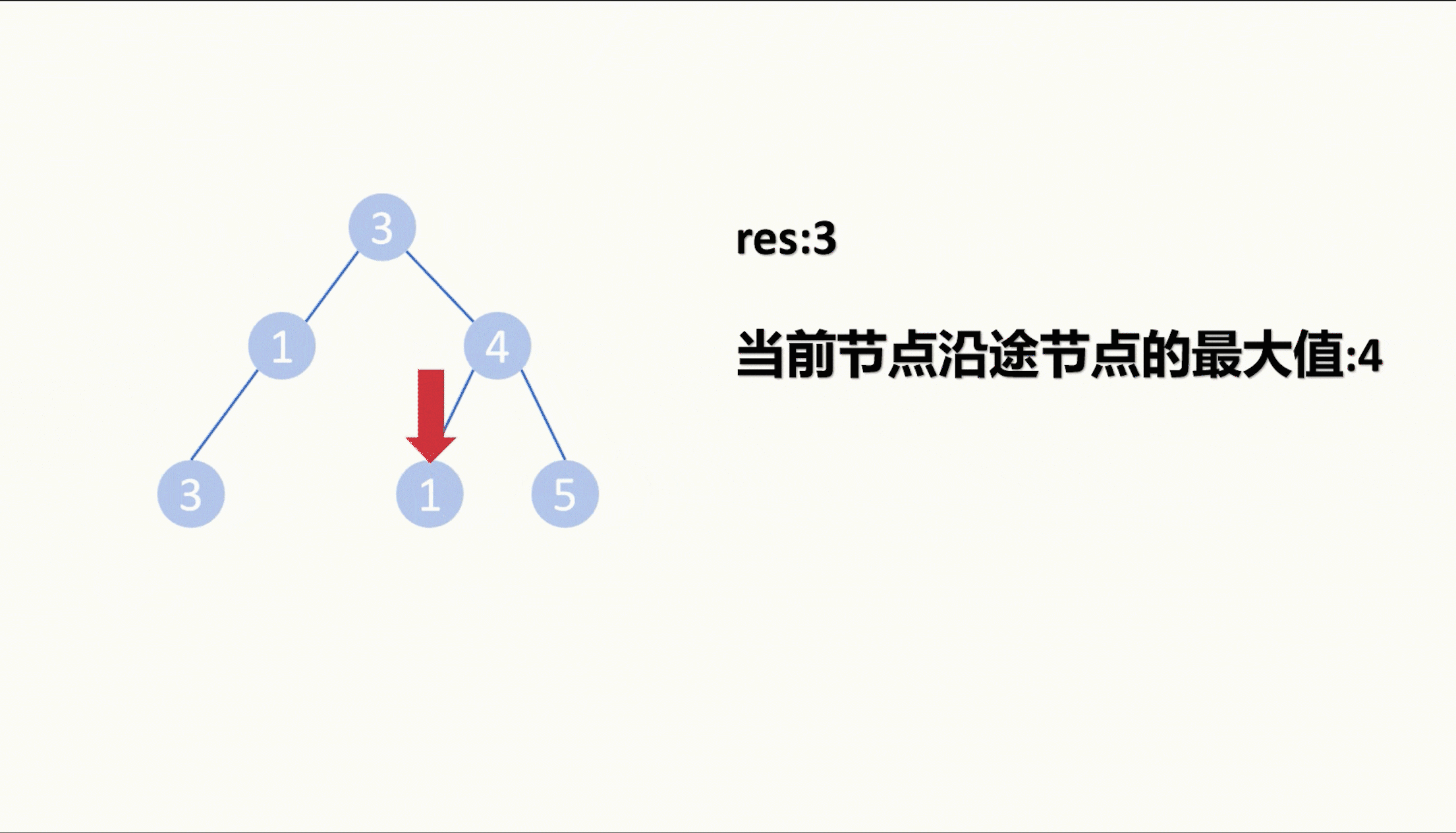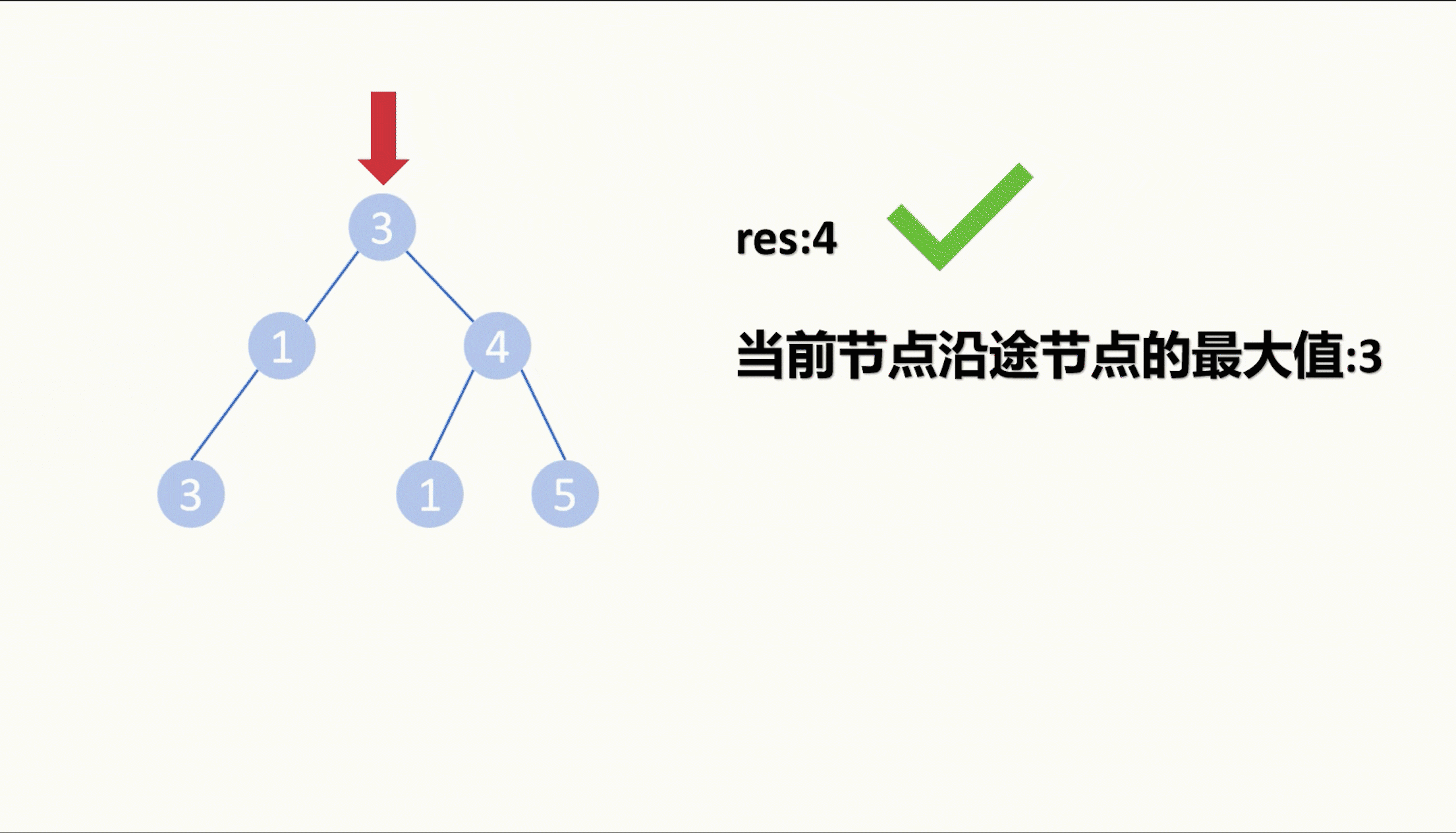
【LeetCode75】第三十五题 统计二叉树中好节点的数目
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 给我们一棵二叉树,让我们统计这棵二叉树中好节点的数目。 那么什么是好节点,题目中给出定义,从根节点…...

探究排序算法:比较与非比较排序算法及性能分析
探究排序算法:比较与非比较排序算法及性能分析 排序算法是计算机科学中的基本问题,它涉及将一组元素按照特定的顺序排列。本文将深入介绍比较排序算法和非比较排序算法,包括每个算法的原理、Java代码示例以及它们的性能分析和比较。 比较排…...
如何输出高质量软文,媒介盒子教你4大技巧
作为一名软文作者,只有知道软文写作的要求,才能打造一篇成功的软文,以便为企业或产品带来较高的关注度和曝光率,提高企业的知名度和品牌形象。下面就随小编一起来看看吧! 1、吸引眼球的标题 标题是软文写作的灵魂&am…...

用centos7镜像做yum仓库
用centos7镜像做yum仓库,公司全部服务器使用。 小白教程,一看就会,一做就成。 1.先下载对应版本的centos7的DVD版或Everything版 我用的是DVD的,比Everything版小,功能也挺全,这里里centos7.5的镜像做实验…...

【无法联网】电脑wifi列表为空的解决方案
打开电脑, 发现wifi列表为空, 点击设置显示未连接 首先检查是不是网卡驱动有问题, cmd, devmgmt.msc 找到网络适配器, 看看网卡前面是否有感叹号, 如果没有则说明网卡没问题, 有问题则重装驱动 看看网络协议是否设置正确 找到"控制面板\所有控制面板项\网络和共享中心&…...

Ajax-Axios的快速入门
Ajax 概念:Asynchronous Javascript Anderson XML,异步的JavaScript和XML 作用:数据交换:通过Ajax可以给服务器发送请求,并获取服务器相应数据 异步交互:可以在不重新加载整个页面的情况下,与…...

mysql insert出现主键冲突错误的解决方法
mysql insert出现主键冲突错误的解决方法 insert 时防止出现主键冲突错误的方法 在mysql中插入数据的时候常常因为主键存在而冲突报错,下面有两个解决方法: 1 在insert 语句中添加ignore 关键字 insert ignore into table (id,name) values (1,username)…...
Visual Studio2022史诗级更新,增加多个提高生产力的功能
Visual Studio 2022发布了17.7x版,这次更新中,增加多个提高生产力的功能以及性能进一步改进。 如果要体验新功能,需要将Visual Studio 2022的版本升级到17.7及以上 下面我们看看新增的功能以及改进的功能! 目录 文件比较自动修复代…...
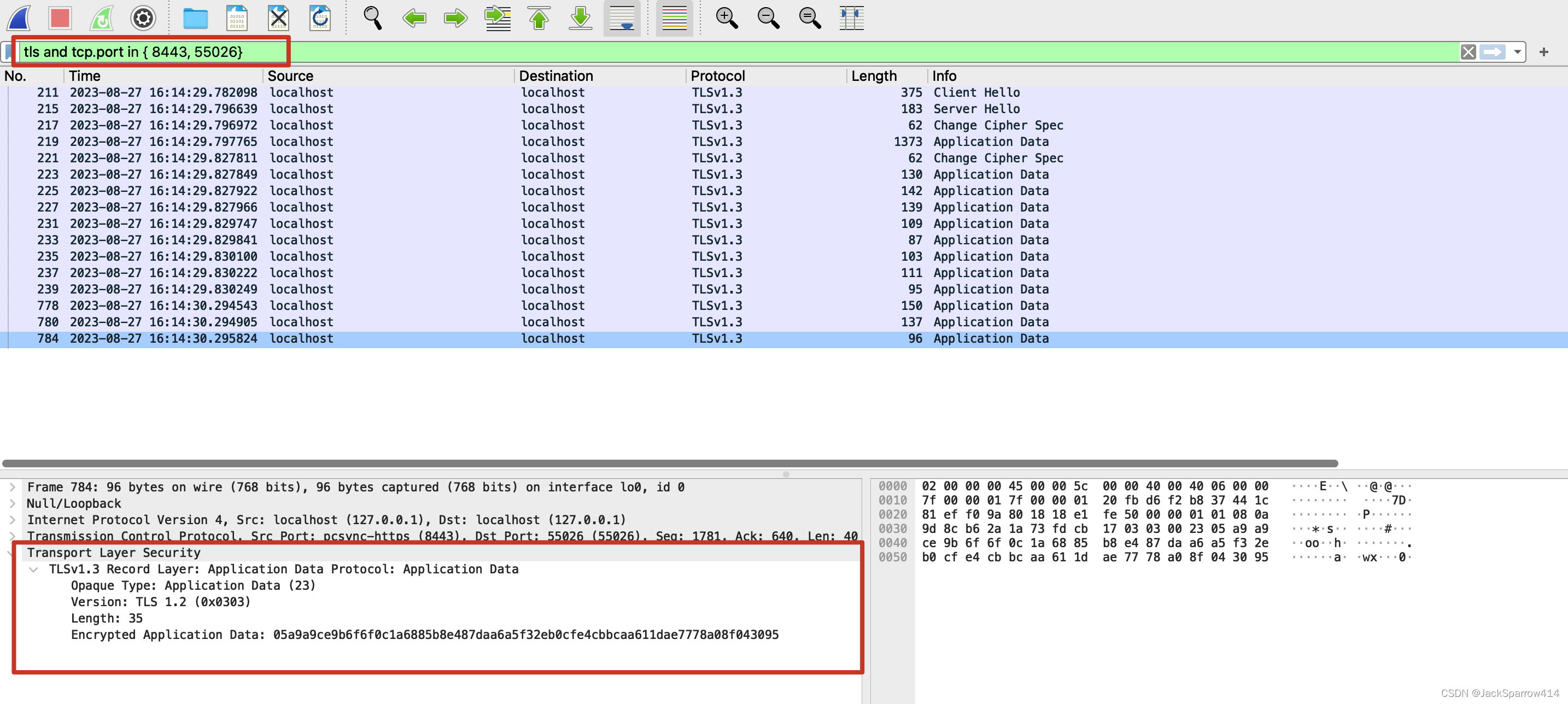
理解HTTPS/TLS/SSL(一)基础概念+配置本地自签名证书
文章目录 没有HTTPS时的样子场景模拟WireShark的Capture Filter和Display Filter设置Capture Filter启动程序设置Display Filter过滤抓到的包 结论 关于为什么加密更简洁有力的回答对称加密和非对称加密和CA证书密钥交换对称加密非对称加密CA机构和证书如何解决客户端和CA机构之…...
前端需要理解的Vue知识
1 模板语法 Vue使用基于 HTML 的模板语法,能声明式地将其组件实例的数据绑定到DOM。所有Vue 模板可以被符合规范的浏览器和 HTML 解析器解析。Vue 会将模板编译成高度优化的 JavaScript 代码。结合响应式系统,当应用状态变更时,Vue 能够智能…...

【Go 基础篇】Go语言中的自定义错误处理
错误是程序开发过程中不可避免的一部分,而Go语言以其简洁和高效的特性闻名。在Go中,自定义错误(Custom Errors)是一种强大的方式,可以为特定应用场景创建清晰的错误类型,以便更好地处理和调试问题。本文将详…...

别再到处找了!这12个三维点云开源数据集,够你从入门到项目实战
三维点云实战指南:12个精选开源数据集与精准匹配策略 当你第一次打开三维点云处理软件,面对空白的项目界面,最迫切的问题往往是:"我该从哪里获取高质量的训练数据?"这个问题困扰过每一位初学者,…...

实战应用:基于快马平台ai,开发并部署一个功能齐全的instagram内容下载web应用
今天想和大家分享一个实战项目:基于InsCode(快马)平台快速开发并部署一个功能完备的Instagram内容下载Web应用。这个项目从需求分析到上线只用了不到半天时间,特别适合想验证产品原型的开发者。 项目需求分析 首先明确核心功能需求:需要支持I…...
)
保姆级教程:用OpenAI Whisper给视频自动生成字幕(附Python代码)
视频创作者必备:用Whisper打造高效字幕工作流 每次剪辑视频最头疼的就是加字幕?作为过来人,我完全理解那种对着时间轴逐帧调整的痛苦。直到发现Whisper这个神器,我的工作效率直接翻了三倍。今天就把这套全自动字幕生成方案完整分享…...
 实战:如何用USRP搭建你的第一个5G仿真环境(附避坑指南))
OpenAirInterface (OAI) 实战:如何用USRP搭建你的第一个5G仿真环境(附避坑指南)
OpenAirInterface (OAI) 实战:如何用USRP搭建你的第一个5G仿真环境(附避坑指南) 当5G技术从实验室走向商业化时,开源软件无线电平台OpenAirInterface(OAI)正成为开发者验证创新想法的关键工具。不同于商业设…...

Local AI MusicGen商业应用:电商视频智能配乐
Local AI MusicGen商业应用:电商视频智能配乐 你是不是也遇到过这样的烦恼?制作电商短视频时,翻遍了免费音乐库,要么版权有问题,要么风格不搭,要么就是千篇一律的背景音。自己配乐?没那个时间和…...

mkcert 命令文档 - 本地 HTTPS 开发证书生成工具详解
1. 命令简介mkcert 是一个用 Go 语言编写的、零配置的本地开发用自签名证书生成工具。它能够自动创建并安装本地证书颁发机构(CA)到系统的信任存储中,并生成受本地信任的开发证书,大幅简化 HTTPS 本地开发环境的搭建过程ÿ…...

Qwerty Learner字体优化:提升阅读体验的细节处理
Qwerty Learner字体优化:提升阅读体验的细节处理 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://gitcode.…...

FreeRTOS进阶:任务优先级与调度策略深度解析
1. FreeRTOS任务优先级基础 在嵌入式实时操作系统中,任务优先级决定了任务执行的先后顺序。FreeRTOS采用数值越大优先级越高的设计,优先级范围通常为0到(configMAX_PRIORITIES-1)。我刚开始接触FreeRTOS时,经常混淆这个概念,直到在…...
)
避坑指南:MoE训练中AllToAll通信的配置与性能调优(以DeepSpeed为例)
MoE训练实战:AllToAll通信性能调优与DeepSpeed配置避坑指南 当你在500张GPU的集群上启动MoE模型训练时,控制台突然刷出"AllToAll timeout"的红色警告——这不是假设场景,而是去年我们在训练千亿参数模型时真实遭遇的噩梦。AllToAll…...

Linux系统管理必备:常用命令在Phi-3-vision模型部署与运维中的应用
Linux系统管理必备:常用命令在Phi-3-vision模型部署与运维中的应用 1. 前言:为什么需要掌握这些命令 部署和管理AI模型服务时,熟练使用Linux命令就像拥有了一把瑞士军刀。特别是对于Phi-3-vision这样的视觉大模型,从查看日志到监…...