【Web系列二十四】使用JPA简化持久层接口开发
目录
环境配置
1、引入依赖
配置文件
代码编写
实体类创建
JPA常用注解
Service与ServiceImpl
Service
ServiceImpl
Controller
Dao
三种实现Dao功能方式
1.继承接口,使用默认接口+实现
2.根据接口命名规则默认生成实现
3.自定义接口+实现(类似MyBatis)
多表关联
1.一对一关联
2.一对多、多对一
3.多对多
参考资料
Spring Data JPA
Spring Data JPA 是Spring提供的一套简化JPA开发的持久层框架,根据实体类自动生成表 (注意库仍旧自己创建),按照约定好的【方法命名规则】写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
Spring Data JPA 可以理解为 JPA 规范的再次封装抽象,底层还是使用了 Hibernate 的 JPA 技术实现。
SpringBoot集成新框架环境往往很容易:引入依赖,编写配置、[启用]、代码编写。
环境配置
1、引入依赖
首先要引入jpa的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>配置文件
spring:jpa:hibernate:ddl-auto: updateshow-sql: true- ddl-auto:自动创建表,有4个选项
- create:每次启动将之前的表和数据都删除,然后重新根据实体建立表。
- create-drop:比上面多了一个功能,就是在应用关闭的时候,会把表删除。
- update:最常用的,第一次启动根据实体建立表结构,之后重启会根据实体的改变更新表结构,不删除表和数据。
- validate:验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值,运行程序会校验实体字段与数据库已有的表的字段类型是否相同,不同会报错
- show-sql:指运行时,是否在控制台展示sql
代码编写
和mybatis主要的区别在于JPA可以根据实体类自动创建表,并且会提供默认的DAO方法。
实体类创建
创建一个models文件夹,并新建文件algo.java
package com.xxx.xxx.xxx.models;import lombok.Data;
import org.springframework.data.annotation.CreatedDate;import javax.persistence.*;
import java.util.Date;@Entity
@Table(name = "algo")
@Data
public class Algo {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "id")private Integer id;@Column(name = "name", length = 200)private String name;@CreatedDate @Column(name = "create_time", updatable = false, nullable = false)private Date createTime;}JPA常用注解
| 注解 | 作用 |
|---|---|
| @Entity | 声明类为实体或表. |
| @Table | 声明表名。 |
| @Basic | 指定非约束明确的各个字段。 |
| @Embedded | 指定类或它的值是一个可嵌入的类的实例的实体的属性。 |
| @Id | 指定的类的属性,用于识别(一个表中的主键)。 |
| @GeneratedValue | 指定如何标识属性可以被初始化,参数strategy有以下选项: TABLE:使用一个特定的数据库表格存放主键。 |
| @Transient | 指定该属性为不持久属性,即:该值永远不会存储在数据库中。 |
| @AccessType | 这种类型的注释用于设置访问类型。如果设置@AccessType(FIELD),则可以直接访问变量并且不需要getter和setter,但必须为public。如果设置@AccessType(PROPERTY),通过getter和setter方法访问Entity的变量。 |
| @JoinColumn | 指定一个实体组织或实体的集合。这是用在多对一和一对多关联。 |
| @UniqueConstraint | 指定的字段和用于主要或辅助表的唯一约束。 |
| @ColumnResult | 参考使用select子句的SQL查询中的列名。 |
| @ManyToMany | 定义了连接表之间的多对多一对多的关系。 |
| @ManyToOne | 定义了连接表之间的多对一的关系。 |
| @OneToMany | 定义了连接表之间存在一个一对多的关系。 |
| @OneToOne | 定义了连接表之间有一个一对一的关系。 |
| @NamedQueries | 指定命名查询的列表。 |
| @NamedQuery | 指定使用静态名称的查询。 |
Service与ServiceImpl
Service
public interface AlgoService {//查询全部List<Algo> findAlgoList();//查询一条User findAlgoById(int id);//添加void insertAlgo(Algo algo);//删除void deleteAlgo(int id);//修改void updateAlgo(Algo algo);
}ServiceImpl
查询一条数据时没有直接使用User而是使用Optional< User >,这是由于Dao层直接使用了默认的方法。Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
修改和添加都是save方法,修改时对象id有值,添加时id无值。
@Service
public class AlgoServiceImpl implements AlgoService {@Autowiredprivate AlgoRepository algoRepository;@Overridepublic List<Algo> findAlgoList() {return algoRepository.findAll();}@Overridepublic AlgofindAlgoById(int id) {//Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。Optional<Algo> ao = algoMapper.findById(id);return ao.orElse(null);}@Overridepublic void insertAlgo(Algo algo) {algoRepository.save(algo);}@Overridepublic void deleteAlgo(int id) {algoRepository.deleteById(id);}@Overridepublic void updateAlgo(Algo algo) {Algo emp = algoRepository.findById(algo.getId()).orElse(null);assert emp != null;BeanUtils.copyProperties(algo,emp); //属性值拷贝algoRepository.save(emp);}
}Controller
@RestController
public class JpaController {@Autowiredprivate AlgoService algoService;@PostMapping("/add")public Map<String,String> addAlgo(){Algo algo = new Algo();algo.setName("张三");algo.setPassword("123456");algo.setSex("男");algoService.insertAlgo(algo);Map<String,String> map = new HashMap<>();map.put("msg","操作成功");return map;}
}Dao
继承JpaRepository,它默认的提供了一些常见dao方法,主要是完成一些增删改查的操作。
@Repository
public interface AlgoRepository extends JpaRepository<Algo, Integer> {//约束1为实体类类型、约束2为主键类型
}三种实现Dao功能方式
1.继承接口,使用默认接口+实现
| 接口 | 作用 |
|---|---|
| CrudRepository | 提供默认增删改查方法 |
| PagingAndSortingRepository | CRUD方法+分页、排序 |
| JpaRepository | 针对关系型数据库优化 |
2.根据接口命名规则默认生成实现
默认提供了常见方法,但仍可以根据命名规则自动生成方法。
此表内容来源于官网:
Spring Data JPA - Reference Documentation
| 关键词 | 示例 | JPQL片段 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is, Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull, Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull, NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 |
| Containing | Containing | … where x.firstname like ?1 |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
3.自定义接口+实现(类似MyBatis)
使用注解方式 @Query
使用 @Query()注解来生成sql语句,注意此注解默认value属性值与myBatis有点不同,它使用的是JPQL。
如果想使value值为原生SQL,则添加属性:nativeQuery = true 即可。
表名映射:可以直接使用表对应类名,如果想用表名:#{#entityName}
参数映射:?n表示第n个参数、:参数名(参数可用@Param指定)
#{#entityName}:SPEL表达式,实体类使用了@Entity后,它的值为实体类名,如果@Entity的name属性有值,则它的值为该name值。
@Modifying:标记仅映射参数的方法。
@Transactional:开启事务,并将只读改为非只读。
@Repository
//约束1为实体类、约束2为主键
public interface AlgoRepository extends JpaRepository<Algo,Integer> {//添加:使用了原生sql@Transactional//开启事务为非只读@Modifying@Query(value = "insert into jpa_test(name, userId) values(:#{#algo.name}, :#{#algo.userId}) ", nativeQuery = true)void addAlgo(@Param("algo") Algo algo);//删除@Transactional(timeout = 10)@Modifying@Query("delete from Algo where id=:id")void deleteAlgoById(@Param("id") Integer id);//修改@Transactional(timeout = 10)@Modifying@Query("update Algo u set u.name=:#{#algo.name}, u.createTime=:#{#algo.createTime}, u.userId=:#{#algo.userId} where u.id=:#{#algo.id}")void updateAlgo (@Param("algo")Algo algo);//查询一条@Query("select u from Algo u where u.id=?1 ")User findAlgoById(Integer id);//查询全部@Query("select u from Algo u")List<Algo> findAllAlgo();
}对象属性的绑定:使用 @Param(映射名) 注解 + :#{#映射名.属性}
多表关联
JPA中一般只需要创建关联性即可,默认方法会自动关联查询。
1.一对一关联
两张表a、b,a的每条对应着b最多一条数据。
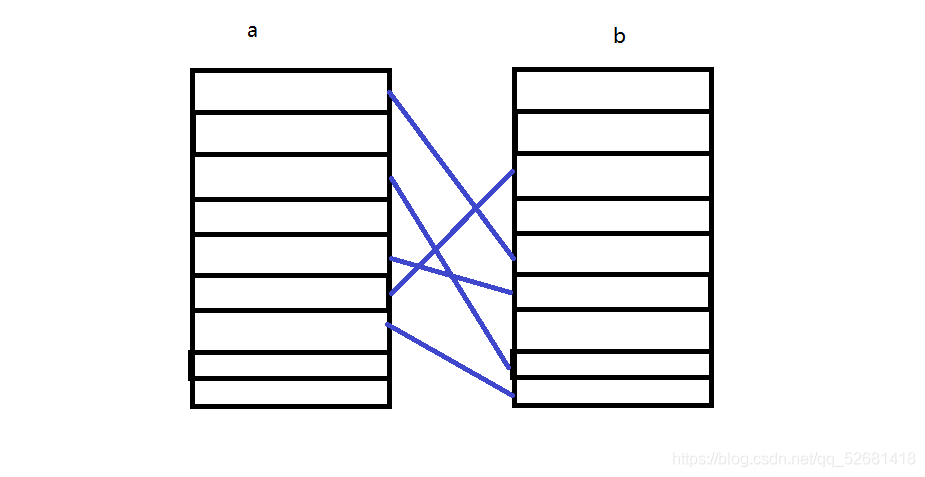
jpa实现如下:
/*** 表A*/
@Entity
@Table(name = "a")
public class A{@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@OneToOne(cascade = {CascadeType.ALL})//一对一关系,级联删除@JoinColumn(name="b",referencedColumnName = "id")//关联 b的id字段private B b;
}/*** 表B*/
@Entity
@Table(name = "b")
public class B{@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;
}
上面是A级联B,即可以通过A查到B,如果想通过B查到A则需要为B添加级联属性。
2.一对多、多对一
一对多: 两张表A、B,A的一条记录对应B的多条记录,B每条只能对应1个A。A对B的关系为一对多;B对 A的关系为多对一。
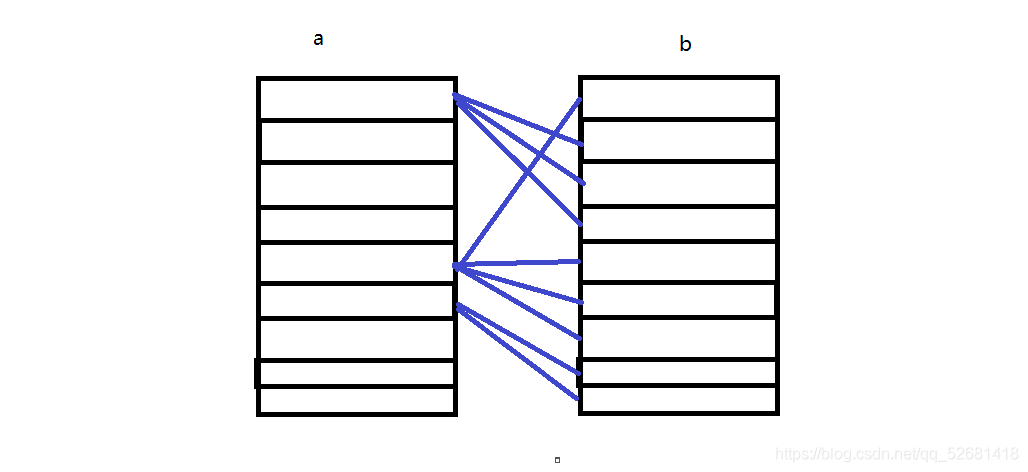
jpa实现如下:
/*** 球员表*/
@Entity//球员表
@Table(name = "sportmans")
public class SportMan implements Serializable {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private long id;private String sportManName;@ManyToOne(cascade = {CascadeType.MERGE,CascadeType.PERSIST})@JoinColumn(name="duty") //库中添加的外键字段private Duty duty;}/*** 位置表*/
@Data
@Entity
@Table(name = "dutys")
public class Duty implements Serializable {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private long id;private String dutyName;@JsonIgnore//不反向查询//级联保存、更新、删除,删除时会删除所有球员@OneToMany(mappedBy = "duty",cascade = CascadeType.ALL,fetch = FetchType.LAZY)private List<SportMan> sportManList;}不使用@JsonIgnore注解时,查询球员,球员里关联出位置,位置反向关联球员,会无限递归查询,因此添加此注解,防止此字段被查出来时自动回查。
3.多对多
两张表A、B,一条A记录对应多条B,一条B记录对应多条A。
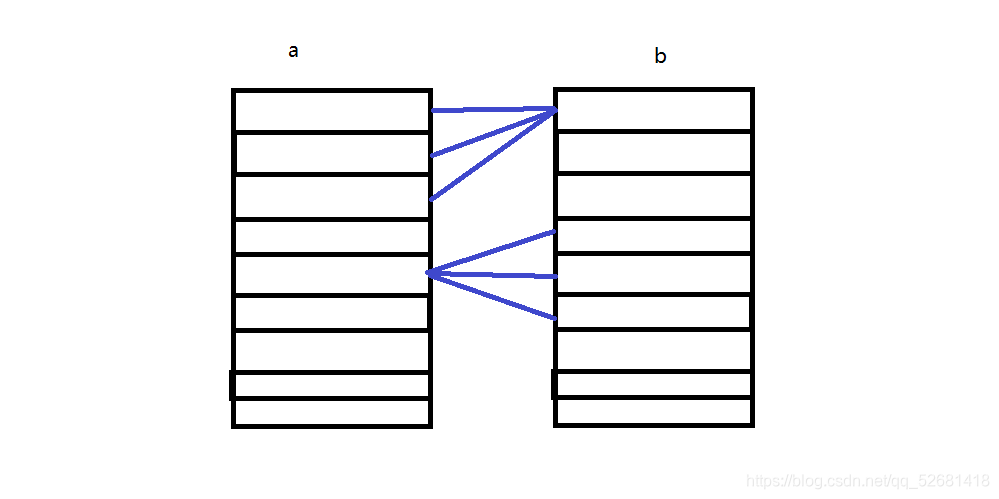
jpa实现如下:
/*** 表A*/
@Entity
@Table(name = "a")
public class A{@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToMany(cascade = {CascadeType.ALL})@JoinColumn(name="b",referencedColumnName = "id")//关联 b的id字段private B b;}/*** 表B*/
@Entity
@Table(name = "b")
public class B{@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;@ManyToMany(cascade = {CascadeType.ALL})@JoinColumn(name="a",referencedColumnName = "id")//关联 a的id字段private A a;}
参考资料
SpringBoot 一文搞懂Spring JPA_springboot jpa_马踏飞燕&lin_li的博客-CSDN博客
使用springJpa创建数据库表_jpa可以动态创建数据库表吗_阿圣同学的博客-CSDN博客
【Spring JPA总结】@GeneratedValue注解介绍 - 简书 (jianshu.com)
spring boot 中使用 jpa(详细操作)_springboot jpa_熬菜的博客-CSDN博客
Spring Boot+JPA_springboot+jpa_火恐龙的博客-CSDN博客
相关文章:
【Web系列二十四】使用JPA简化持久层接口开发
目录 环境配置 1、引入依赖 配置文件 代码编写 实体类创建 JPA常用注解 Service与ServiceImpl Service ServiceImpl Controller Dao 三种实现Dao功能方式 1.继承接口,使用默认接口实现 2.根据接口命名规则默认生成实现 3.自定义接口实现(类似MyBatis…...
Flink流批一体计算(16):PyFlink DataStream API
目录 概述 Pipeline Dataflow 代码示例WorldCount.py 执行脚本WorldCount.py 概述 Apache Flink 提供了 DataStream API,用于构建健壮的、有状态的流式应用程序。它提供了对状态和时间细粒度控制,从而允许实现高级事件驱动系统。 用户实现的Flink程…...

软考高级系统架构设计师系列论文九十三:论计算机网络的安全性设计
软考高级系统架构设计师系列论文九十三:论计算机网络的安全性设计 一、计算机网络安全性设计相关知识点二、摘要三、正文四、总结一、计算机网络安全性设计相关知识点 软考高级系统架构设计师:计算机网络...

山西电力市场日前价格预测【2023-08-29】
日前价格预测 预测明日(2023-08-29)山西电力市场全天平均日前电价为321.48元/MWh。其中,最高日前电价为372.80元/MWh,预计出现在19: 30。最低日前电价为272.85元/MWh,预计出现在12: 30。 价差方向预测 1: 实…...

计算机毕设 基于深度学习的人脸专注度检测计算系统 - opencv python cnn
文章目录 1 前言2 相关技术2.1CNN简介2.2 人脸识别算法2.3专注检测原理2.4 OpenCV 3 功能介绍3.1人脸录入功能3.2 人脸识别3.3 人脸专注度检测3.4 识别记录 4 最后 1 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新…...

ES 7.6 - APi基础操作篇
ES7.6-APi基础操作篇 前言相关知识索引相关创建索引查询索引查询所有索引删除索引关闭与打开索引关闭索引打开索引 冻结与解冻索引冻结索引解冻索引 映射相关创建映射查看映射新增字段映射 文档相关(CURD)新增文档根据ID查询修改文档全量覆盖根据ID选择性修改根据条件批量更新 …...

【Go 基础篇】Go语言循环结构:实现重复执行与迭代控制
介绍 循环结构是编程中的重要概念,它允许我们重复执行一段代码块,或者按照一定的条件进行迭代控制。Go语言提供了多种循环结构,包括for、while和do-while等,用于不同的场景下实现循环操作。本篇博客将深入探讨Go语言中的循环结构…...
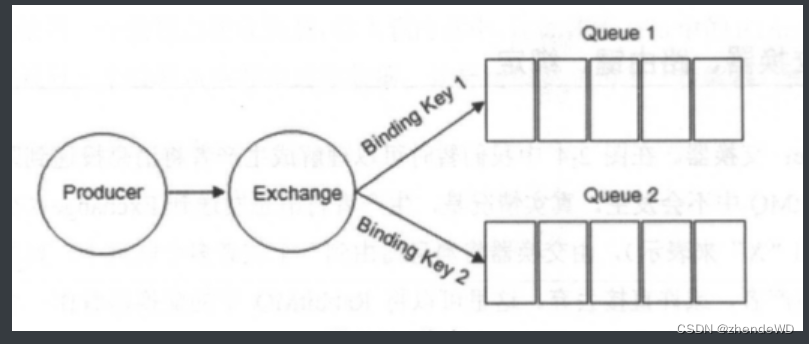
RabbitMQ笔记-RabbitMQ基本术语
RabbitMQ基本术语 相关概念; 生产者(Producer):投递消息。消息:消息体(payload)标签(label);生产者把消息交给rabbitmq,rabbitmq会根据标签把消息发给感兴趣…...
Git向远程仓库与推送以及拉取远程仓库
理解分布式版本控制系统 1.中央服务器 我们⽬前所说的所有内容(⼯作区,暂存区,版本库等等),都是在本地也就是在你的笔记本或者计算机上。⽽我们的 Git 其实是分布式版本控制系统!什么意思呢? 那我们多人…...

PostgreSQL+SSL链路测试
SSL一个各种证书在此就不详细介绍了,PostgreSQL要支持SSL的前提需要打开openssl选项,包括客户端和服务器端。 测试过程。 1. 生成私钥 root用户: mkdir -p /opt/ssl/private mkdir -p /opt/ssl/share/ca-certificateschmod 755 -R /opt/ss…...
服务器(容器)开发指南——code-server
文章目录 code-server简介code-server的安装与使用code-server的安装code-server的启动code-server的简单启动指定配置启动code-server code-server环境变量配置 code-server端口转发自动端口转发手动添加转发端口 nginx反向代理code-servercode-server打包开发版镜像 GitHub官…...
C++贪吃蛇(控制台版)
C自学精简实践教程 目录(必读) 目录 主要考察 需求 输入文件 运行效果 实现思路 枚举类型 enum class 启动代码 输入文件data.txt 的内容 参考答案 学生实现的效果 主要考察 模块划分 文本文件读取 UI与业务分离 控制台交互 数据抽象 需求 用户输入字母表示方…...

Java之字符串实践
功能概述 字符串是Java编程中常用的数据类型,本文对String部分常见功能做了对应实践以及分析。 功能实践 场景1:字符串比较 用例代码 Test public void test_string_compare() {String s1 "abc";String s2 s1;String s5 "abc&quo…...
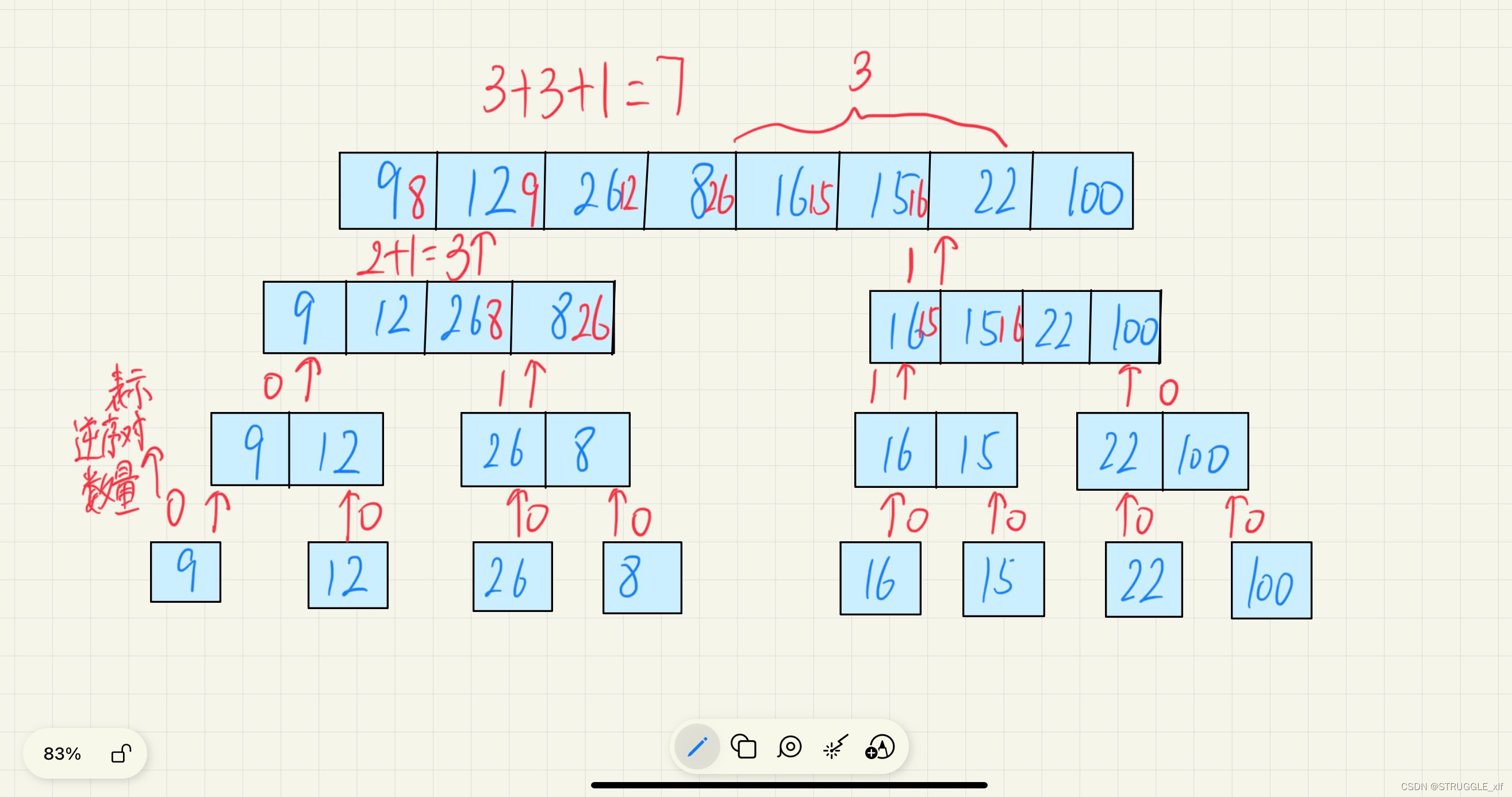
BM20 数组中的逆序对
描述 解题思路:归并排序 分治:分治即“分而治之”,“分”指的是将一个大而复杂的问题划分成多个性质相同但是规模更小的子问题,子问题继续按照这样划分,直到问题可以被轻易解决;“治”指的是将子问题单独进…...

高德猎鹰轨迹查询相关接口
高德猎鹰轨迹官网:服务管理-API文档-开发指南-猎鹰轨迹服务 | 高德地图API 轨迹查询 httpclient的post // post方法请求 创建轨迹 private static void createTrace() {String key "高德注册的key";String sid "服务id"; // 服务idString…...

整理总结新手开始抖音小店经营:常见问题及解决办法
抖音小店作为一种新兴的电商模式,在短时间内获得了广泛的关注和使用。然而,对于新手来说,抖音小店经营可能会遇到一些问题。下面是四川不若与众总结的一些常见的问题以及相应的解决办法。 问题一:产品选择困难 对于新手来说&#…...
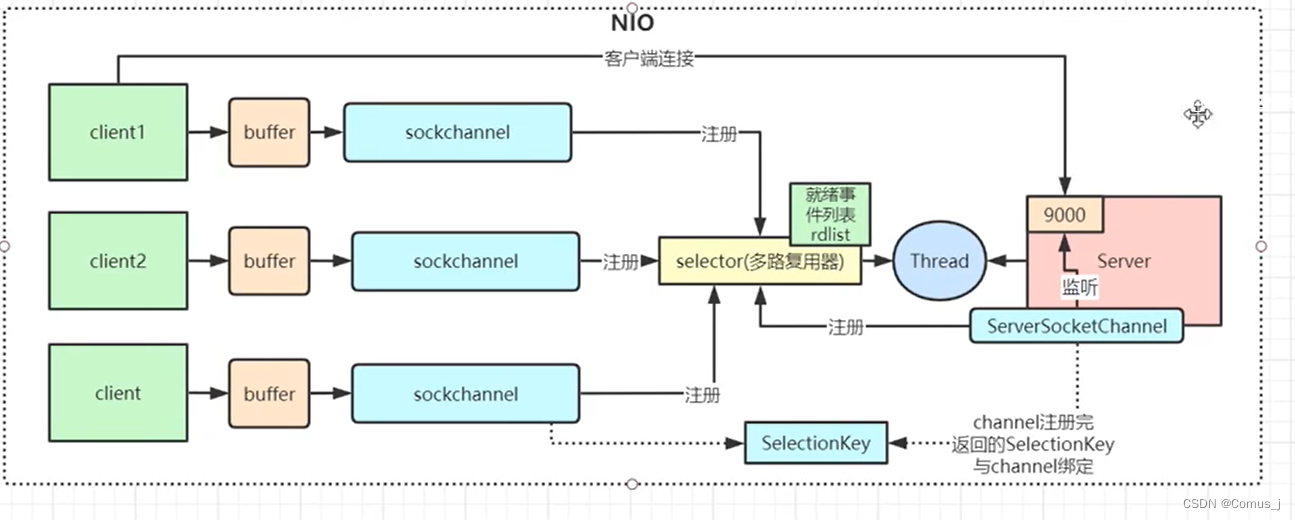
4-1-netty
非阻塞io 服务端就一个线程,可以处理无数个连接 收到所有的连接都放到集合channelList里面 selector是有事件集合的 对server来说优先关注连接事件 遍历连接事件...

hive 动态分区-动态分区数量太多也会导致效率下降只设置非严格模式也能执行动态分区
hive 动态分区-动态分区数量太多也会导致效率下降&只设置非严格模式也能执行动态分区 结论 在非严格模式下不开启动态分区的功能的参数(配置如下),同样也能进行动态分区数据写入,目测原因是不严格检查SQL中是否指定分区或者…...
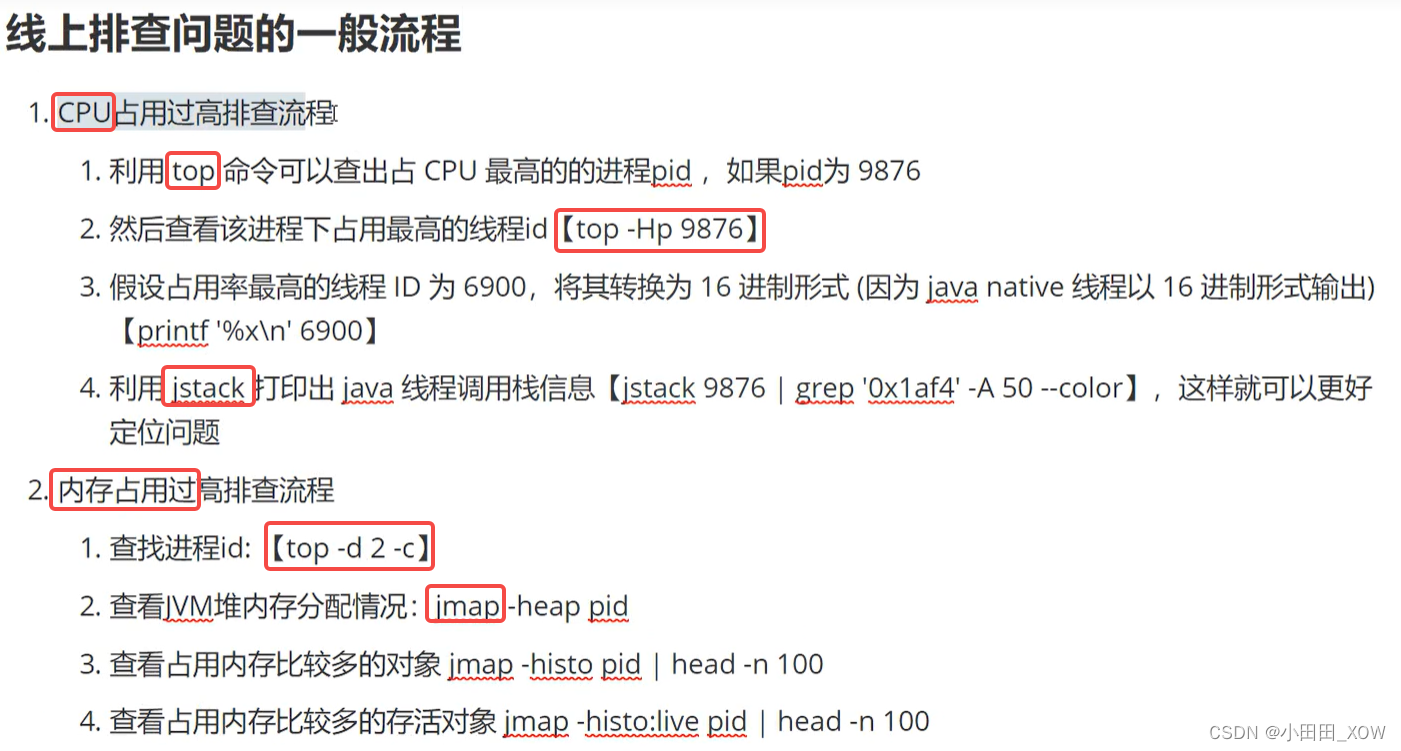
java八股文面试[JVM]——JVM调优
知识来源: 【2023年面试】JVM性能调优实战_哔哩哔哩_bilibili...

FairyGUI-Unity 异形屏适配
本文中会修改到FairyGUI源代码,涉及两个文件Stage和StageCamera,需要对Unity的屏幕类了解。 在网上查找有很多的异形屏适配操作,但对于FairyGUI相关的描述操作很少,这里我贴出一下自己在实际应用中的异形屏UI适配操作。 原理 获…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
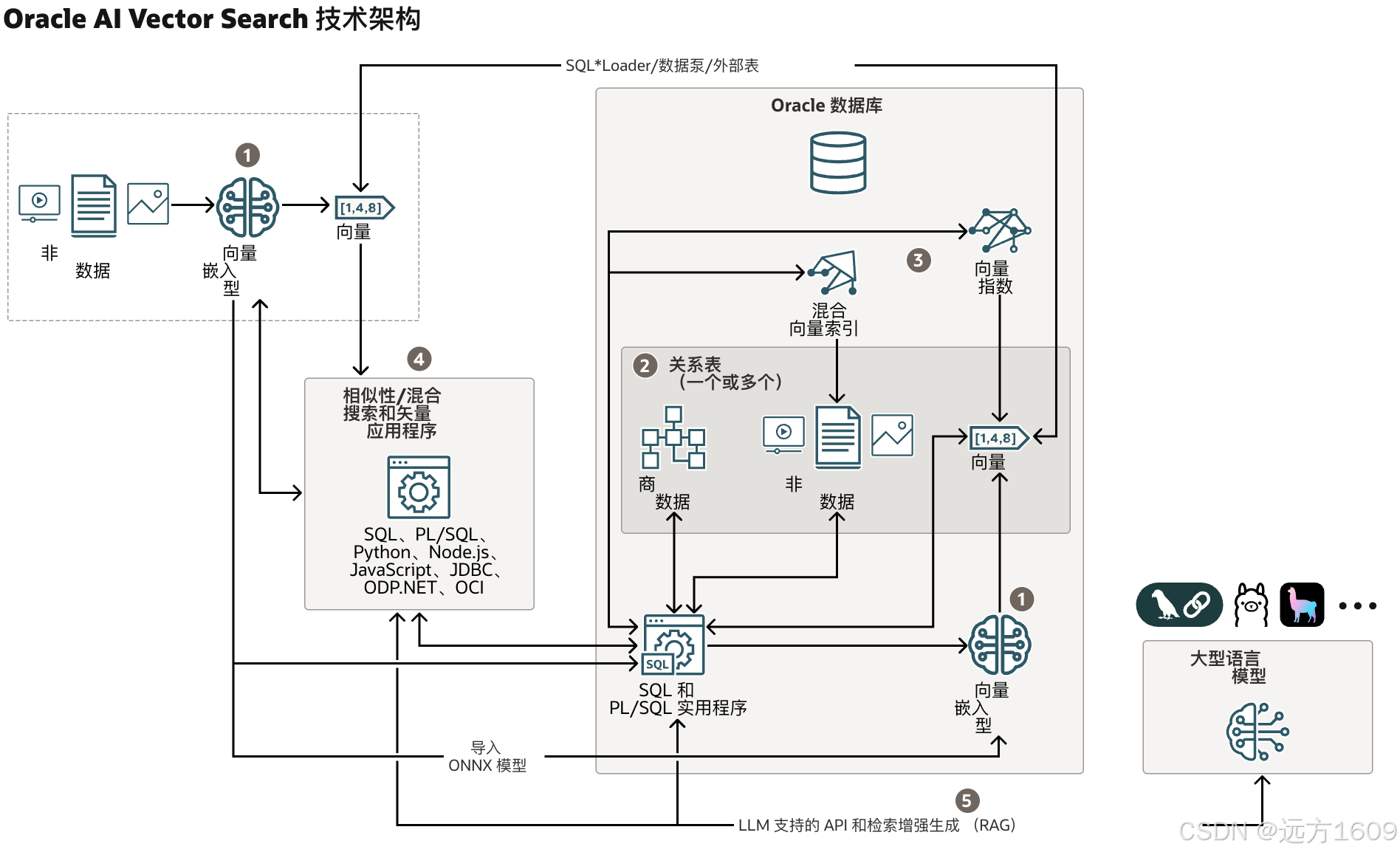
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...
【51单片机】4. 模块化编程与LCD1602Debug
1. 什么是模块化编程 传统编程会将所有函数放在main.c中,如果使用的模块多,一个文件内会有很多代码,不利于组织和管理 模块化编程则是将各个模块的代码放在不同的.c文件里,在.h文件里提供外部可调用函数声明,其他.c文…...