block层:8. deadline调度器
deadline
源码基于5.10
0. 私有数据
struct deadline_data {/** run time data*//** requests (deadline_rq s) are present on both sort_list and fifo_list*/struct rb_root sort_list[2];struct list_head fifo_list[2];/** next in sort order. read, write or both are NULL*/struct request *next_rq[2];unsigned int batching; /* number of sequential requests made */unsigned int starved; /* times reads have starved writes *//** settings that change how the i/o scheduler behaves*/int fifo_expire[2];int fifo_batch;int writes_starved;int front_merges;spinlock_t lock;spinlock_t zone_lock;struct list_head dispatch;
};
1. 函数表
static struct elevator_type mq_deadline = {.ops = {.insert_requests = dd_insert_requests,.dispatch_request = dd_dispatch_request,.prepare_request = dd_prepare_request,.finish_request = dd_finish_request,.next_request = elv_rb_latter_request,.former_request = elv_rb_former_request,.bio_merge = dd_bio_merge,.request_merge = dd_request_merge,.requests_merged = dd_merged_requests,.request_merged = dd_request_merged,.has_work = dd_has_work,.init_sched = dd_init_queue,.exit_sched = dd_exit_queue,},#ifdef CONFIG_BLK_DEBUG_FS.queue_debugfs_attrs = deadline_queue_debugfs_attrs,
#endif.elevator_attrs = deadline_attrs,.elevator_name = "mq-deadline",.elevator_alias = "deadline",// 支持zone设备顺序写.elevator_features = ELEVATOR_F_ZBD_SEQ_WRITE,.elevator_owner = THIS_MODULE,
};
1.1. 属性
#define DD_ATTR(name) \__ATTR(name, 0644, deadline_##name##_show, deadline_##name##_store)static struct elv_fs_entry deadline_attrs[] = {DD_ATTR(read_expire), // 提交读取之前最长时间,默认HZ/2(半秒)DD_ATTR(write_expire), // 写入的最大起时时间,默认5*HZ(5秒)DD_ATTR(writes_starved), // 最大的读取次数会导致写饥饿,默认是2次DD_ATTR(front_merges), // 是否开启前向合并,0/1,默认开DD_ATTR(fifo_batch), // 顺序请求批量最大值,默认16__ATTR_NULL
};
2. 初始化及退出
2.1. 初始化
static int dd_init_queue(struct request_queue *q, struct elevator_type *e)
{struct deadline_data *dd;struct elevator_queue *eq;// 分配一个queue对象eq = elevator_alloc(q, e);if (!eq)return -ENOMEM;// 分配deadline对象dd = kzalloc_node(sizeof(*dd), GFP_KERNEL, q->node);if (!dd) {kobject_put(&eq->kobj);return -ENOMEM;}// 与eq建立关联eq->elevator_data = dd;// 各种初始化INIT_LIST_HEAD(&dd->fifo_list[READ]);INIT_LIST_HEAD(&dd->fifo_list[WRITE]);dd->sort_list[READ] = RB_ROOT;dd->sort_list[WRITE] = RB_ROOT;dd->fifo_expire[READ] = read_expire;dd->fifo_expire[WRITE] = write_expire;// writes_starved,默认为0dd->writes_starved = writes_starved;// 默认打开前向合并dd->front_merges = 1;// fifo里最大的请求数,默认16dd->fifo_batch = fifo_batch;spin_lock_init(&dd->lock);spin_lock_init(&dd->zone_lock);INIT_LIST_HEAD(&dd->dispatch);// 设置到请求队列里q->elevator = eq;return 0;
}struct elevator_queue *elevator_alloc(struct request_queue *q,struct elevator_type *e)
{struct elevator_queue *eq;// 分配一个对象eq = kzalloc_node(sizeof(*eq), GFP_KERNEL, q->node);if (unlikely(!eq))return NULL;// 关联到调度器的函数表eq->type = e;// 一些基本初始化kobject_init(&eq->kobj, &elv_ktype);mutex_init(&eq->sysfs_lock);hash_init(eq->hash);return eq;
}
2.2. 退出
static void dd_exit_queue(struct elevator_queue *e)
{struct deadline_data *dd = e->elevator_data;// 这2个列表必须为空BUG_ON(!list_empty(&dd->fifo_list[READ]));BUG_ON(!list_empty(&dd->fifo_list[WRITE]));// 直接释放ddkfree(dd);
}
3. 合并
static bool dd_bio_merge(struct request_queue *q, struct bio *bio,unsigned int nr_segs)
{struct deadline_data *dd = q->elevator->elevator_data;struct request *free = NULL;bool ret;spin_lock(&dd->lock);// 尝试合并, free 会带回被合并的请求ret = blk_mq_sched_try_merge(q, bio, nr_segs, &free);spin_unlock(&dd->lock);// 释放被合并的请求if (free)blk_mq_free_request(free);return ret;
}static int dd_request_merge(struct request_queue *q, struct request **rq,struct bio *bio)
{struct deadline_data *dd = q->elevator->elevator_data;// 结束的扇区sector_t sector = bio_end_sector(bio);struct request *__rq;// 不允许前向合并if (!dd->front_merges)return ELEVATOR_NO_MERGE;// 根据数据方向,找到起点为bio结束扇区的rq__rq = elv_rb_find(&dd->sort_list[bio_data_dir(bio)], sector);if (__rq) {// 找到一个rqBUG_ON(sector != blk_rq_pos(__rq));// 是否可以合并if (elv_bio_merge_ok(__rq, bio)) {*rq = __rq;// 判断丢弃合并if (blk_discard_mergable(__rq))return ELEVATOR_DISCARD_MERGE;// 返回前向合并return ELEVATOR_FRONT_MERGE;}}return ELEVATOR_NO_MERGE;
}static void dd_merged_requests(struct request_queue *q, struct request *req,struct request *next)
{if (!list_empty(&req->queuelist) && !list_empty(&next->queuelist)) {// next的过期时间比req短if (time_before((unsigned long)next->fifo_time,(unsigned long)req->fifo_time)) {// 把req移到next后面list_move(&req->queuelist, &next->queuelist);// 并设置成next的到期时间req->fifo_time = next->fifo_time;}}// 删除next请求deadline_remove_request(q, next);
}static void deadline_remove_request(struct request_queue *q, struct request *rq)
{struct deadline_data *dd = q->elevator->elevator_data;// 删除请求从sort列表里list_del_init(&rq->queuelist);// 如果在红黑树上,则删除它if (!RB_EMPTY_NODE(&rq->rb_node))deadline_del_rq_rb(dd, rq);// 从哈希表里删除elv_rqhash_del(q, rq);// 置空最后合并的请求,如果它等于rqif (q->last_merge == rq)q->last_merge = NULL;
}
4. 插入请求
static void dd_insert_requests(struct blk_mq_hw_ctx *hctx,struct list_head *list, bool at_head)
{struct request_queue *q = hctx->queue;struct deadline_data *dd = q->elevator->elevator_data;spin_lock(&dd->lock);// list里放的是待插入的请求while (!list_empty(list)) {struct request *rq;rq = list_first_entry(list, struct request, queuelist);// 先从list里删除list_del_init(&rq->queuelist);// 插入请求dd_insert_request(hctx, rq, at_head);// 增加调度器插入的数量atomic_inc(&hctx->elevator_queued);}spin_unlock(&dd->lock);
}static void dd_insert_request(struct blk_mq_hw_ctx *hctx, struct request *rq,bool at_head)
{struct request_queue *q = hctx->queue;struct deadline_data *dd = q->elevator->elevator_data;const int data_dir = rq_data_dir(rq);// zone设备解锁blk_req_zone_write_unlock(rq);// 先尝试合并,如果可以合并则直接返回if (blk_mq_sched_try_insert_merge(q, rq))return;// 这里面只打印了insert的trace日志blk_mq_sched_request_inserted(rq);// 插入队前 || 是直通请求if (at_head || blk_rq_is_passthrough(rq)) {// 插在派发队列的前面或后面if (at_head)list_add(&rq->queuelist, &dd->dispatch);elselist_add_tail(&rq->queuelist, &dd->dispatch);} else {// 普通插入// 把请求加入对应读写方向的红黑树,这个红黑树按照扇区起点排序deadline_add_rq_rb(dd, rq);// 如果该请求是可以合并的// 能走到这里表示在上面合并时没有合并if (rq_mergeable(rq)) {// 则把它加到哈希表里,key是扇区请求数量elv_rqhash_add(q, rq);// 如果last_merge没值,则把rq设为它if (!q->last_merge)q->last_merge = rq;}// 设置过期时间rq->fifo_time = jiffies + dd->fifo_expire[data_dir];// 加到fifo_list里list_add_tail(&rq->queuelist, &dd->fifo_list[data_dir]);}
}static void
deadline_add_rq_rb(struct deadline_data *dd, struct request *rq)
{// 根据请求方向,获取根节点struct rb_root *root = deadline_rb_root(dd, rq);// 把请求加到红黑树里elv_rb_add(root, rq);
}static inline struct rb_root *
deadline_rb_root(struct deadline_data *dd, struct request *rq)
{// 根据请求方向,获取根节点return &dd->sort_list[rq_data_dir(rq)];
}void elv_rb_add(struct rb_root *root, struct request *rq)
{struct rb_node **p = &root->rb_node;struct rb_node *parent = NULL;struct request *__rq;// 按照请求扇区的起点,找到需要插入的位置while (*p) {parent = *p;__rq = rb_entry(parent, struct request, rb_node);if (blk_rq_pos(rq) < blk_rq_pos(__rq))p = &(*p)->rb_left;else if (blk_rq_pos(rq) >= blk_rq_pos(__rq))p = &(*p)->rb_right;}// 插入结点rb_link_node(&rq->rb_node, parent, p);// 插入颜色?rb_insert_color(&rq->rb_node, root);
}
5. 派发
static bool dd_has_work(struct blk_mq_hw_ctx *hctx)
{struct deadline_data *dd = hctx->queue->elevator->elevator_data;// 没有入队的直接返回if (!atomic_read(&hctx->elevator_queued))return false;// 这3个队列有1个不空就表示有任务return !list_empty_careful(&dd->dispatch) ||!list_empty_careful(&dd->fifo_list[0]) ||!list_empty_careful(&dd->fifo_list[1]);
}static struct request *dd_dispatch_request(struct blk_mq_hw_ctx *hctx)
{struct deadline_data *dd = hctx->queue->elevator->elevator_data;struct request *rq;spin_lock(&dd->lock);// 取出一个待派发的请求rq = __dd_dispatch_request(dd);spin_unlock(&dd->lock);// 如果取出一个,则减少调度器的计数if (rq)atomic_dec(&rq->mq_hctx->elevator_queued);return rq;
}static struct request *__dd_dispatch_request(struct deadline_data *dd)
{struct request *rq, *next_rq;bool reads, writes;int data_dir;// 派发列表不为空,则直接取出一个请求if (!list_empty(&dd->dispatch)) {rq = list_first_entry(&dd->dispatch, struct request, queuelist);list_del_init(&rq->queuelist);goto done;}// 读写里是否有请求reads = !list_empty(&dd->fifo_list[READ]);writes = !list_empty(&dd->fifo_list[WRITE]);// 获取下一个写请求rq = deadline_next_request(dd, WRITE);// 如果没获取到,则获取下一个读请求if (!rq)rq = deadline_next_request(dd, READ);// 有请求 && 发出的连续请求数量 < fifo的最大批量, 则派发if (rq && dd->batching < dd->fifo_batch)/* we have a next request are still entitled to batch */goto dispatch_request;/** 走到这儿表示rq为空或者batching已经到达限制*/// 有读的请求if (reads) {// 怎么会为空?BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ]));// 如果有写请求 && 写饥饿超过了限制值if (deadline_fifo_request(dd, WRITE) &&(dd->starved++ >= dd->writes_starved))// 派发写请求goto dispatch_writes;// 走到这儿表示写不饥饿// 数据方向为读data_dir = READ;// 找一个请求派发goto dispatch_find_request;}// 走到这儿表示没有读请求,或者写饥饿if (writes) {
dispatch_writes:BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE]));// 重置饥饿值dd->starved = 0;// 方向为写data_dir = WRITE;// 找一个请求派发goto dispatch_find_request;}// 走到这儿表示即没有写,与没有读return NULL;dispatch_find_request:// 根据操作方向找一个请求next_rq = deadline_next_request(dd, data_dir);// 在data_dir上有请求过期 || 没有下一个请求if (deadline_check_fifo(dd, data_dir) || !next_rq) {// 重新取一个rqrq = deadline_fifo_request(dd, data_dir);} else {// 没有过期的请求,继续派发next_rqrq = next_rq;}/** 对于zoned设备来说,如果我们只有写请求入队,它们不能被派发,rq将是NULL*/if (!rq)return NULL;// batch重置dd->batching = 0;dispatch_request:dd->batching++;// 从各种列表里删除rq请求, 并设置next请求deadline_move_request(dd, rq);
done:// 如果是zone设备需要加锁blk_req_zone_write_lock(rq);// 标记请求已开始rq->rq_flags |= RQF_STARTED;return rq;
}static struct request *
deadline_next_request(struct deadline_data *dd, int data_dir)
{struct request *rq;unsigned long flags;// 只处理读写if (WARN_ON_ONCE(data_dir != READ && data_dir != WRITE))return NULL;// 获取下一个请求rq = dd->next_rq[data_dir];// 下一请求为空if (!rq)return NULL;// 请求是读 || 是写但是不是zone设备if (data_dir == READ || !blk_queue_is_zoned(rq->q))return rq;// 处理zone设备.todo: zone设备相关看面再看spin_lock_irqsave(&dd->zone_lock, flags);while (rq) {if (blk_req_can_dispatch_to_zone(rq))break;rq = deadline_latter_request(rq);}spin_unlock_irqrestore(&dd->zone_lock, flags);return rq;
}static struct request *
deadline_fifo_request(struct deadline_data *dd, int data_dir)
{struct request *rq;unsigned long flags;// 只处理读或写if (WARN_ON_ONCE(data_dir != READ && data_dir != WRITE))return NULL;// 对应的列表为空if (list_empty(&dd->fifo_list[data_dir]))return NULL;// 取出第1个元素rq = rq_entry_fifo(dd->fifo_list[data_dir].next);// 方向是读 || 方向是写但是不是zoned请求if (data_dir == READ || !blk_queue_is_zoned(rq->q))return rq;// 走到这儿表示方向是写的zone设备. todo: zone设备后面再看spin_lock_irqsave(&dd->zone_lock, flags);list_for_each_entry(rq, &dd->fifo_list[WRITE], queuelist) {if (blk_req_can_dispatch_to_zone(rq))goto out;}rq = NULL;
out:spin_unlock_irqrestore(&dd->zone_lock, flags);return rq;
}static inline int deadline_check_fifo(struct deadline_data *dd, int ddir)
{// 获取下一个请求struct request *rq = rq_entry_fifo(dd->fifo_list[ddir].next);// 如果rq达到了过期时间返回1if (time_after_eq(jiffies, (unsigned long)rq->fifo_time))return 1;return 0;
}static void
deadline_move_request(struct deadline_data *dd, struct request *rq)
{const int data_dir = rq_data_dir(rq);// 先把读写全置空dd->next_rq[READ] = NULL;dd->next_rq[WRITE] = NULL;// 在红黑树上获取rq的下一个节点,根据扇区号dd->next_rq[data_dir] = deadline_latter_request(rq);// 从排序列表和fifo列表,哈希表里删除此请求deadline_remove_request(rq->q, rq);
}static inline struct request *
deadline_latter_request(struct request *rq)
{// 获取下一个结点struct rb_node *node = rb_next(&rq->rb_node);if (node)return rb_entry_rq(node);return NULL;
}
假设在初始状态下,所有列表全空, writes_starved=2, fifo_batch=3:
- 插入请求顺序如下:r1 r2 w1 w2 w3 r3 w4 r4 w5 w6 w7 r5 r6
- w1派发, next_rq[write]=w2,batching=1
- w2派发, next_rq[write]=w3,batching=2
- w3派发, next_rq[write]=w4,batching=3
- 触发fifo_batch限制, next_rq[read]是NULL,派发r1, next_rq[read]=r2,next_rq[write]=NULL,batching=1
- r2派发, next_rq[read]=r3,batching=2
- r3派发, next_rq[read]=r4,batching=3
- 触发writes_starved限制,派发写请求w4,next_rq[read]=NULL,next_rq[write]=w5
相关文章:

block层:8. deadline调度器
deadline 源码基于5.10 0. 私有数据 struct deadline_data {/** run time data*//** requests (deadline_rq s) are present on both sort_list and fifo_list*/struct rb_root sort_list[2];struct list_head fifo_list[2];/** next in sort order. read, write or both ar…...

DTO,VO,PO的意义与他们之间的转换
DTO(Data Transfer Object):数据传输对象,这个概念来源于J2EE的设计模式,原来的目的是为了EJB的分布式应用提供粗粒度的数据实体,以减少分布式调用的次数,从而提高分布式调用的性能和降低网络负…...

Java 集合框架2
一、关于set接口的常用类 1.HashSet类 用来处理无序的单列数据,没有重复的元素,重复的元素算一个 i.构造方法 //HashSet类是set接口的子类,是无序的单列数据,没有重复的元素,重复的元素算一个 //HashSet的构造方法 //HashSet() …...
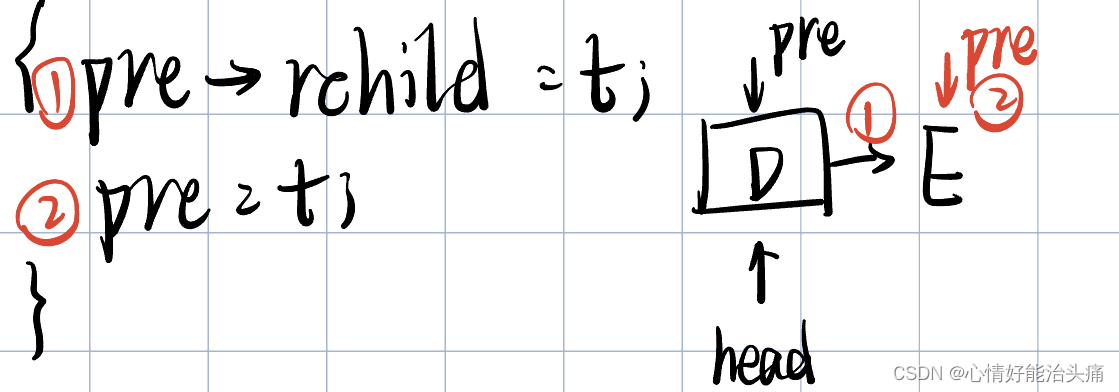
2024王道408数据结构P144 T16
2024王道408数据结构P144 T16 思考过程 首先看题目,要求我们把二叉树的叶子结点求出来并且用链表的方式存储,链接时用叶结点的右指针来存放单链表指针。我们很清楚可以看出来能用中序遍历递归的方式实现,因为第一个叶子结点在整棵树的最左下…...

【ARM Coresight 系列文章 22 -- linux frace 与 trace-cmd】
文章目录 ftrace 介绍trace-cmd 介绍trace-cmd 常用跟踪事件ftrace 与 trace-cmd 关系ftrace 编译依赖 ftrace 介绍 ftrace 是 Linux 内核中的一个跟踪工具,主要用于帮助开发者分析和调试内核的行为。ftrace 的名字来源于 “function tracer”,它最初是…...

MyBatis的一级缓存和二级缓存是怎么样的?
目录 1. 一级缓存 2. 一级缓存失效的几种情况 3. 二级缓存 4.二级缓存失效的情况 5. 二级缓存的相关配置 6. 缓存的查询顺序 MyBatis 的缓存共分为一级缓存和二级缓存。 1. 一级缓存 一级缓存是 SqlSession 级别的,通过同一个 SqlSession 查询到的数据会被缓…...

下载的文件被Windows 11 安全中心自动删除
今天从CSDN上下载了自己曾经上传的文件,但是浏览器下载完之后文件被Windows安全中心自动删除,说是带病毒。实际是没有病毒的,再说了即便有病毒也不应该直接删除啊,至少给用户一个保留或删除的选项。 研究了一番,可以暂…...
)
【Java List与数组】List<T>数组和数组List<T>的区别(124)
List数组:存储List的数组,即:数组中的元素是:List; 数组List:存储数组的List,即:List中的数据是类型的数组; 测试案例: import java.util.ArrayList; impor…...

Nuxt 菜鸟入门学习笔记四:静态资源
文章目录 public 目录assets 目录全局样式导入 Nuxt 官网地址: https://nuxt.com/ Nuxt 使用以下两个目录来处理 CSS、fonts 和图片等静态资源: public 目录 public 目录用作静态资产的公共服务器,可通过应用程序定义的 URL 公开获取。 换…...

C语言 - 结构体、结构体数组、结构体指针和结构体嵌套
结构体的意义 问题:学籍管理需要每个学生的下列数据:学号、姓名、性别、年龄、分数,请用 C 语言程序存储并处理一组学生的学籍。 单个学生学籍的数据结构: 学号(num): int 型姓名(…...

python安装playwright问题记录
python安装playwright这个时候,有得时候会https timeout 有的时候会 not found。 我最后使用的方法三,挺好用的。 PyPI The Python Package Index 可以尝试使用的方法 1. 更换pip源:使用国内的pip源可以提高下载速度并减少超时问题。例如,…...

关于gRPC微服务利弊之谈
gRPC微服务架构包括以下几个主要组件: 服务定义:定义服务的接口和消息格式,使用Protocol Buffers或其他的消息格式进行描述。服务实现:实现定义的服务接口和消息处理逻辑。服务器端实现:在服务器端,需要实…...

【Terraform学习】使用 Terraform创建Lambda函数启动EC2(Terraform-AWS最佳实战学习)
本站以分享各种运维经验和运维所需要的技能为主 《python》:python零基础入门学习 《shell》:shell学习 《terraform》持续更新中:terraform_Aws学习零基础入门到最佳实战 《k8》暂未更新 《docker学习》暂未更新 《ceph学习》ceph日常问题解…...

Mac软件删除方法?如何删除不会有残留
Mac电脑如果有太多无用的应用程序,很有可能会拖垮Mac系统的运行速度。因此,卸载电脑中无用的软件是优化Mac系统运行速度的最佳方式之一。Mac卸载应用程序的方式是和Windows有很大的区别,特别对于Mac新用户来说,如何无残留的卸载删…...

编程之道:【性能优化】提高软件效率的实际建议和避免常见陷阱
在今天的数字化世界中,软件性能是应用程序成功的关键之一。无论是网页加载速度、移动应用的响应时间还是后端服务器的处理速度,性能都直接影响着用户满意度。在追求高性能时,开发人员需要采取一系列实际建议,同时避免常见的陷阱。…...
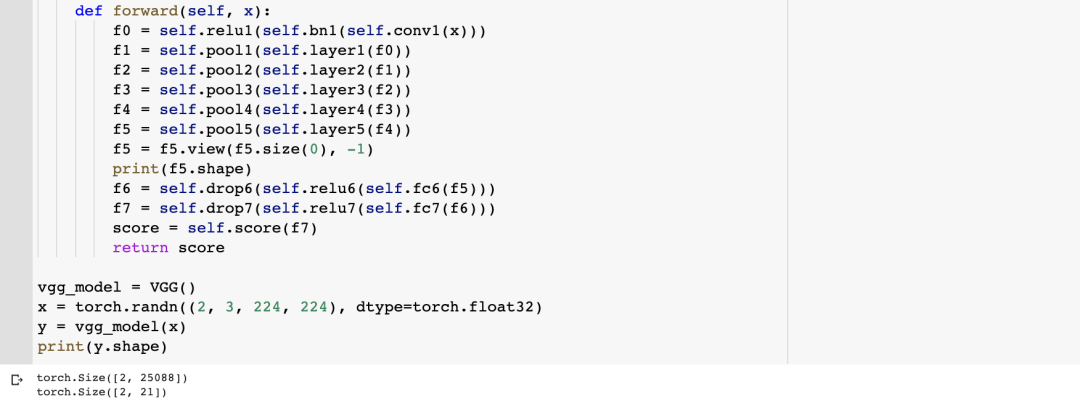
VGG的结构:视觉几何组(Visual Geometry Group)
目录 1. VGG 的结构 2. VGG 的网络细节 3. VGG 的代码实现 1. VGG 的结构 牛津大学的视觉几何组(Visual Geometry Group)设计了 VGGNet(也称为 VGG),一种经典的卷积神经网络 (CNN) 架构。在 2014 年 ILSVRC 分类任务中,VGG 取…...

VBA:按照Excel工作表中的名称列自动汇总多个工作薄中对应sheet中所需要的数据
需求如下: B列为产品名为合并单元格,C列为供应商名,G、H列为金额数据;数据源放在同一个文件夹内,B列产品名来源于工作薄名称中间的字符串,C列供应商名来源于工作薄中的sheet名;G、H列金额数据来…...
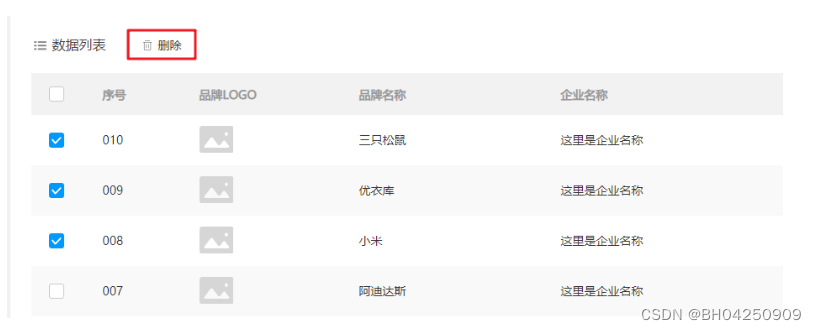
Mybatis1.9 批量删除
1.9 批量删除 1.9.1 编写接口方法1.9.2 编写SQL语句1.9.3 编写测试方法 如上图所示,用户可以选择多条数据,然后点击上面的 删除 按钮,就会删除数据库中对应的多行数据。 1.9.1 编写接口方法 在 BrandMapper 接口中定义删除多行数据的方法。…...
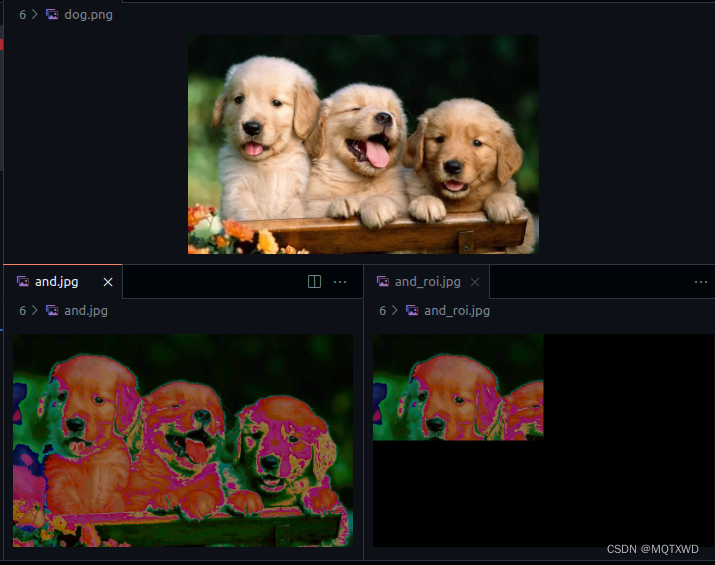
CUDA小白 - NPP(2) -图像处理-算数和逻辑操作(2)
cuda小白 原始API链接 NPP GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》 常见的NppStatus…...
)
python+redis实现布隆过滤器(含redis5.0版本以上和5.0以下版本的两份代码)
布隆过滤器是一种空间效率极高的概率数据结构,用于测试一个元素是否是集合的成员。如果布隆过滤器返回 False,则元素绝对不在集合中。如果返回 True,则元素可能在集合中,但也可能是一个误报。布隆过滤器利用了多个不同的哈希函数对…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...