DETR-《End-to-End Object Detection with Transformers》论文精读笔记
DETR(基于Transformer架构的目标检测方法开山之作)
End-to-End Object Detection with Transformers
参考:跟着李沐学AI-DETR 论文精读【论文精读】
摘要
在摘要部分作者,主要说明了如下几点:
- DETR是一个端到端(end-to-end)框架,释放了传统基于CNN框架的一阶段(YOLO等)、二阶段(FasterRCNN等)目标检测器中需要大量的人工参与的步骤,例如:NMS后处理或proposals/anchors/centers生成等。使其成为一个真正意义上的端到端(end-to-end)的目标检测框架;
- DETR还可以很方便地迁移到诸如全景分割等其他任务当中,只需要在最后的FFN(前向传播头)之后增加分割头等即可;
- DETR在当时发表出来的时候(2020年5月左右)已经达到了和经过长时间调参的FasterRCNN基线一样的精度/速度/内存占用(基准为COCO2017);
介绍
DETR模型架构

第一步,将图片输入到一个CNN中,得到feature map。
第二步,将图片拉直,送入到transformer encoder-decoder。其中,encoder的作用是为了进一步学习全局的信息,为最后的decoder(也就是为最后的出预测框做铺垫)。使用transformer的encoder是为使得图片中每一个特征点与图片中的其他特征有交互,这样就知道了哪块是哪个物体。这种全局的特征非常有利于移除冗余的框(全局建模)。
第三步,decoder生成框的输出,其中输入decoder的不只有encoder的输出,还有object query(用来限制decoder输出多少个框),通过object query和特征不停的做交互(在decoder中间去做self-attention操作),从而得到最后输出的框(论文中,作者选择的框数量为N=100)。
第四步,计算出来的N=100个框与Ground Truth做匹配然后计算loss(本部分是DETR这篇文章中最重要的一个贡献)。作者使用二分图匹配的方法去计算loss,从而决定出在预测出来的100个框中,有哪几个框是与ground-truth框对应的。匹配之后,就会和普通的目标检测一样去计算分类的loss、再算bounding box的loss。剩下的没有匹配上的框就会被标记为没有物体,也就是所谓的背景类。
DETR推理流程
推理的时候前三步和训练时保持一样,第四步因为是test过程,因此只需要在最后的输出上设置一下置信度阈值即可得到预测框,(原始论文中,将置信度设置为0.7,即置信度大于0.7的预测就是前景物体,所有置信度小于0.7的就被当做背景)。
DETR特性
对大物体识别效果很好(归功于Transformer架构的全局建模能力,而不是像原来一样,预测的物体大小受限制于你设置的anchor大小),对小物体识别效果较差(后续的Deformable DETR就提出了多尺度的DETR,同时解决了DETR训练太慢的问题);
相关工作
- 集合预测(因为使用集合预测来解决目标检测问题的工作其实并不多);
- Transformer架构(同时也介绍了parallel decoding,如何不像原来的transformer一样去做自回归预测);
- 介绍了一下目标检测之前的相关工作,其中重点引用了一篇当时最近的工作,指出原来的一阶段或二阶段的目标检测器的性能与初始的猜测(proposals/anchors/centers等)密切相关,这里作者重点想讲的就是不想使用这些复杂的人工先验知识,因此DETR在这个方面具有优势;
- 然后作者介绍了基于RNN的目标检测方法,使用的是自回归模型,时效性就比较差,性能也会比较差;DETR使用了不带掩码信息的decoder之后,可以使得预测输出同时进行,所以DETR的时效性大大增强了;
文章主体部分
作者首先介绍了基于二分图匹配的loss目标函数(因为这点比DETR这种架构来说更新,同时DETR架构是比较标准的,比较容易理解的,即便是其中的object query思想,也比较容易讲解,因此作者首先介绍了目标函数),也正是因为这种目标函数,DETR才能做到一对一的预测出框方式。
二分图匹配
举例理解:假如说有三个工人abc,然后需要完成三个工作xyz,因为所有工人的特点不一样,因此三个工人完成工作的时间等都不一致,因此对三个工人和三个不同的工作来说,会有一个 3 × 3 3\times3 3×3的矩阵,矩阵中对应的每个格子具有不同的数值(这个矩阵就叫做cost matrix,也就是损失矩阵);那么,这个二分图匹配的最终目的是:我可以给每个工人找到最擅长的工作,然后使得这三个人完成工作之后的代价最低;
匈牙利算法就是解决这样一个问题的比较好的方式。
scripy库中,包含匈牙利算法的实现:line_sum_assignment。DETR原始论文中使用的也是这个;
这个方法返回的结果就是一个全面的排列:告诉你哪个人应该做哪个事;
其实,DETR将目标检测问题看成是集合预测问题,其中每个工人可以看成是对应的N=100的预测框,然后xyz表示GroundTruth框;
那么,这个cost matrix矩阵的每个格子中放的就是每个预测框与GroundTruth框之间的cost(也就是loss);
这里的每个格子中表示的loss,就是分类损失和bbox loss,总的来说就是遍历所有预测的框,将这些框与GroundTruth进行计算loss,然后使用匈牙利算法得到最匹配的对应的图片中目标数量的框;
然后,作者又说,这里与一阶段/二阶段的目标检测器一样的道理,都是拿着预测出来的框与GroundTruth逐个计算loss。但是,唯一不同的地方在于DETR是只得到一对一的匹配关系,而不像之前方法一样得到一对多的匹配关系,这样DETR就不需要做后边的NMS后处理步骤。
loss目标函数
接下来,由于前边步骤得到了所有匹配的框,那么现在才计算真正的loss来做梯度回传。DETR在计算真正的loss(分类loss和bbox loss),其中对于分类loss,作者和原来的计算分类loss方法不一样,而是将DETR中这个地方的log去掉(作者发现去掉之后效果会更好一些)。然后对于bbox loss这里,与之前的loss计算方式也有所不同,原来计算bbox loss是使用L1 loss,但是l1 loss会出现框越大,计算出来的loss容易越大。而同时DETR这种基于Transformer架构的模型,对大目标(预测出大框很友好),那么得到的loss就会比较大,不利于优化。因此,作者不光使用了l1 loss,还使用了GIoU loss。这里的GIoU loss就是一个与框大小无关的loss函数。
DETR详细架构

上图中,CONV卷积神经网络的输出向量维度为:2048x25x34,然后使用1x1的卷积将该向量维度减少到256,得到256x25x34的向量,然后使用positional embeddings进行位置编码得到的向量维度也是256x25x34,然后将两个向量相加。
相加之后,将对应的256x25x34这个向量的HW维度进行拉直得到850x256的向量,其中850就是序列的长度,256就是Transformer的head dimension。然后,经过encoder仍然得到850x256的向量。DETR中作者使用了6个encoder。
然后,将最后一个encoder的输出向量(维度为:850x256),输入到decoder中。这里,一同输入的还有object queries(可以看作是learned embeddings,可学习的嵌入),准确地说,它就是一个可学习的positional embeddings。其维度为100x256。这里可以将这个object queries作为一个条件condition,就是告诉模型,我给你一个条件,你需要得到什么结果。接着,将两个输入(一个来自encoder编码器的输出,一个来自object queries)反复做cross attention自注意力操作。最后得到一个100x256的特征。
然后,将最后一个decoder的输出100x256维度的向量通过一个FFN(feed forward network,标准检测头,全连接层)。然后FFN做出来两个预测,一个是类别,一个是bbox位置。原始的DETR是在COCO2017上进行实验的,因此,这里的类别数量就是91类。
最后,将FFN的输出与Ground Truth根据匈牙利算法计算最佳匹配,然后根据最佳匹配计算loss,然后将loss反向传播,更新模型权重。
DETR中的一些细节
-
decoder部分,首先在object query做自注意力操作,目的是为了移除冗余的框。因为这些object query做自注意力操作之后,就大概之后每个query可能得到什么样的一个框。
-
最后做loss的时候,作者为了让这个模型收敛得更快或训练更稳定。作者在decoder之后加了auxiliary loss。作者在6个decoder的输出之后都做了这个loss。这里的FFN都是共享权重。
文章实验部分

首先,作者介绍了DETR和FasterRCNN在COCO数据集上的结果。发现DETR在大物体上检测的性能更好,而小物体上还是FasterRCNN模型更好一些。这说明DETR使用了Transformer架构,具有较高的全局建模能力,因此DETR想检测多大的目标就检测多大的目标,所以对大目标友好一些。
(延伸)写论文的技巧:当你的想法在一个数据集a上不work的时候,有可能在数据集b上work,如果你的想法很好,但是就是不work的时候,找到一个合适的研究动机其实也是很重要的,找到一个合适的切入点也很重要。

上图中,作者将Transformer encoder-decoder的自注意力机制可视化。可以看到自注意力机制的巨大威力,三只牛基本上的轮廓基本上都出来了。
实际上,当你使用transformer的encoder之后,图像上的东西就可以分的很开了,那么这个时候再去做检测、分割等任务就很简单了。

上图展示了不同的encoder数量对DETR最后目标检测精度AP的影响。可以发现,随着encoder层数的增加,AP精度是一直在上升的,且没有饱和的趋势,但是层数的增加带来了计算量的增加。

上图中展示了DETR中decoder attention的分布情况,可以明显看到在遮挡很严重的情况下,大象和小象身上的不同颜色注意力也是很区分开来的。总之,DETR这里的encoder-decoder架构的作用与CNN的encoder-decoder架构的作用其实差不多是一致的。

上图展示了20个object query的可视化结果,其中每个正方形代表一个object query,每个object query中出现的多个点表示bounding box。其中,绿色的点表示小目标物体,红色点表示水平方向的目标物体,蓝色点表示垂直方向的目标物体。实际上,这里的object query和一阶段目标检测器中的anchors差不多,只不过anchors是预先设定的,而这里的object query是通过学习得到的。总之,这100个query中就像100个问问题的人一样,每个人都会有不同的问问题的方式。需要注意的是,这些object query中都在中间有一个红线,这表示,每个query都会去询问图片中间是否包含大的目标物体,这是因为COCO数据集的问题,因为COCO数据集中很多图片中心都会有一些大物体。
总结
一些基于DETR改进的新工作:
Omni DETR, Up DETR, PnP DETR, Smac DETR, Deformable DETR, DAB DETR, Sam DETR, DN DETR, OW DETR, OV DETR,
pixel to sequence(把输入输出全部搞成序列形式,从而与NLP那边完美兼容)
相关文章:
DETR-《End-to-End Object Detection with Transformers》论文精读笔记
DETR(基于Transformer架构的目标检测方法开山之作) End-to-End Object Detection with Transformers 参考:跟着李沐学AI-DETR 论文精读【论文精读】 摘要 在摘要部分作者,主要说明了如下几点: DETR是一个端到端&am…...
网络流量监控-sniffnet
{alert type“info”} 今天来分享一个监控流量的应用sniffnet。 github项目地址:https://github.com/GyulyVGC/sniffnet {/alert} 可以在github的readme上看到这个程序有的特性: 为什么要介绍它呢:主要是多线程、跨平台、可靠、操作简单 我…...
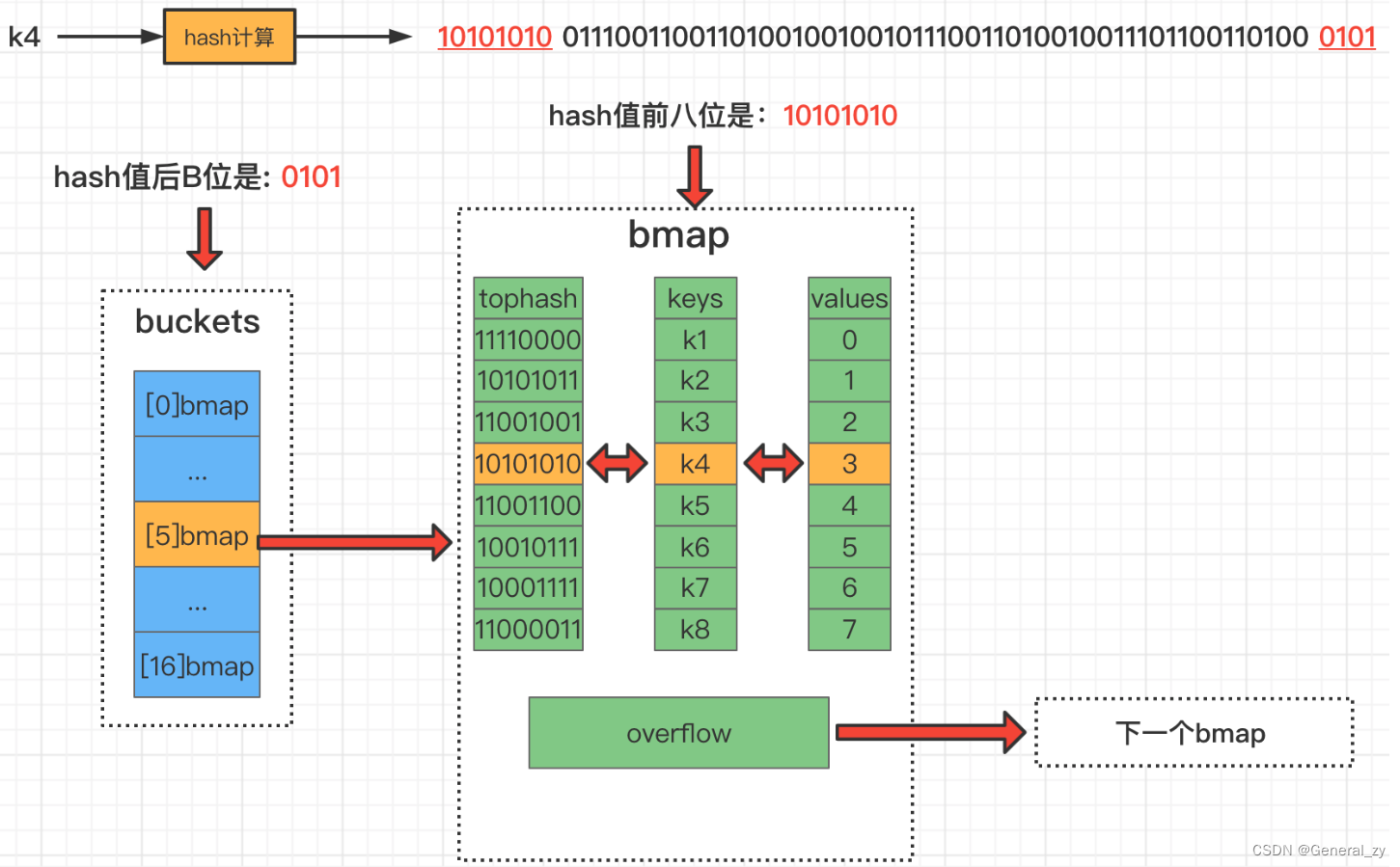
验证go循环删除slice,map的操作和map delete操作不会释放底层内存的问题
目录 切片 for 循环删除切片元素其他循环中删除slice元素的方法方法1方法2(推荐)方法3 官方提供的方法结论 切片 for 循环删除map元素goalng map delete操作不会释放底层内存go map原理源码CRUD查询新增 操作注意事项map元素是无法取址的map是线程不安全…...

C++二级题2
数字字符求和 #include<iostream> #include<string.h> #include<stdio.h> #include<iomanip> #include<cmath> #include<bits/stdc.h> int a[2000][2000]; int b[2000]; char c[2000]; long long n; using namespace std; int main() {ci…...
DataWhale 机器学习夏令营第三期——任务二:可视化分析
DataWhale 机器学习夏令营第三期 学习记录二 (2023.08.23)——可视化分析1.赛题理解2. 数据可视化分析2.1 用户维度特征分布分析2.2 时间特征分布分析 DataWhale 机器学习夏令营第三期 ——用户新增预测挑战赛 学习记录二 (2023.08.23)——可视化分析 2023.08.17 已跑通baseli…...

ubuntu 上安装flutter dart android studio
因为国内网站不能使用 使用一下: vi ~/.bashrc 最后添加 export FLUTTER_STORAGE_BASE_URLhttps://mirrors.cloud.tencent.com/flutter export PUB_HOSTED_URLhttps://mirrors.tuna.tsinghua.edu.cn/dart-pub export PATH$PATH:/usr/local/go/bin export GOPROXY…...

【Golang】go交叉编译
交叉编译是用来在一个平台上生成另一个平台的可执行程序 。Go 命令集是原生支持交叉编译的。 Mac下编译:Linux 或 Windows 的可执行程序 # linux 可执行程序 CGO_ENABLED0 GOOSlinux GOARCHamd64 go build main.go # Windows可执行程序 CGO_ENABLED0 GOOSwindow…...
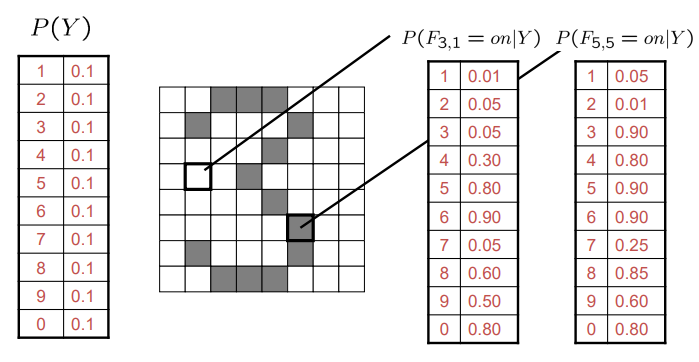
【人工智能】—_贝叶斯网络、概率图模型、全局语义、因果链、朴素贝叶斯模型、枚举推理、变量消元
文章目录 频率学派 vs. 贝叶斯学派贝叶斯学派Probability(概率):独立性/条件独立性:Probability Theory(概率论):Graphical models (概率图模型)什么是图模型(Graphical Models&…...
)
学习笔记:ROS使用经验( 查看rostopic的信息)
查看topic的信息 要查看ROS中的话题信息,你可以使用以下命令: 1.查看所有活动话题: $ rostopic list这将列出当前运行的所有活动话题。 2.查看特定话题的消息类型: $ rostopic info <topic_name>将<topic_name>替…...

数据库——redis内存淘汰,持久化机制
文章目录 Redis 内存淘汰机制了解么?⭐了解操作系统中lru并尝试用java实现lru 2.Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)快照(snapshotting)持久化(RDB)AOF(append-only file&am…...

亚马逊云科技 云技能孵化营 我也说ai
自从chatgpt大火以后,我也关注了人工智能方面的东西,偶尔同学推荐参加了亚马逊云科技云技能孵化营活动,免费学习了亚马逊云科技和机器学习方面的知识,还获得了小礼品,现在将活动及心得分享给大家。 活动内容ÿ…...

『PyQt5-基础篇』| 04 Qt Designer的初步快速了解
04 Qt Designer的初步快速了解 1 Qt Designer入口2 Qt Designer-Widget Box2.1 窗口部件盒(Widget Box)2.2 Layouts布局2.3 Spacers间隔部件2.4 Button按钮2.5 Item Views(Model-Based)2.6 Item Widgets(Item-Based)2.7 Containers容器2.8 Input Widget输入部件2.9 Display W…...
_Hystrix仪表盘)
SpringCloud学习笔记(十一)_Hystrix仪表盘
我们来看一下如何使用它吧 1.引入依赖 1 2 3 4 5 6 7 8 9 10 11 12 | <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </depende…...

# ruby安装设置笔记
ruby安装设置笔记 文章目录 ruby安装设置笔记1 克隆并设置环境变量2 安装ruby3 设置ruby4 设置源5 安装bundler6 检查安装后的软件版本7 ubuntu 20.04 默认ruby环境 系统自带的ruby版本低了,需要手动安装更高版本(使用rbenv方式) 环境&#x…...

关于对文件路径权限判断的记录
首先需要添加引用 using System.Security.AccessControl;以下为具体代码,其中fileServerPath为需要判断的文件路径 #region Authority judgmentDirectorySecurity fileAcl Directory.GetAccessControl(fileServerPath);var rules fileAcl.GetAccessRules(true, t…...
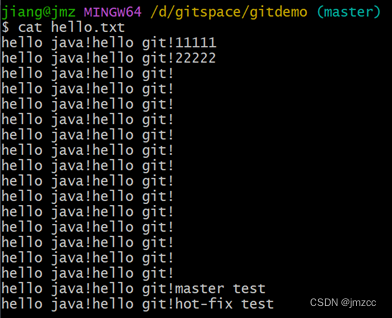
git 基础
1.下载安装Git(略) 2.打开git bash窗口 3.查看版本号、设置用户名和邮箱 用户名和邮箱可以随意起,与GitHub的账号邮箱没有关系 4.初始化git 在D盘中新建gitspace文件夹,并在该目录下打开git bash窗口 git init 初始化完成后会…...

C语言网络编程实现广播
1.概念 如果同时发给局域网中的所有主机,称为广播 我们可以使用命令查看我们Linux下当前的广播地址:ifconfig 2.广播地址 以192.168.1.0 (255.255.255.0) 网段为例,最大的主机地址192.168.1.255代表该网段的广播地址(具体以ifcon…...
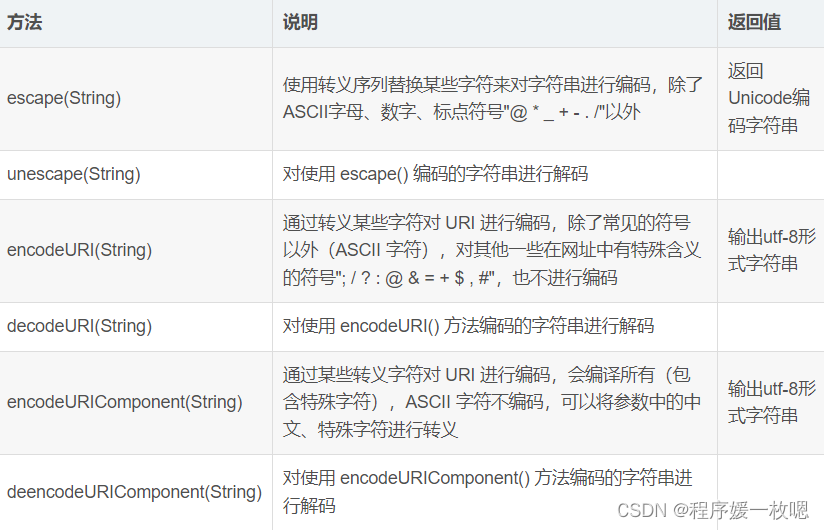
js对url进行编码解码(三种方式)
第一种:escape 和 unescape escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值 它的具体规则是,除了ASCII字母、数字、标点符号" * _ - . /"以外,对其他所有字符进行编码。在u0000到u00ff之间…...
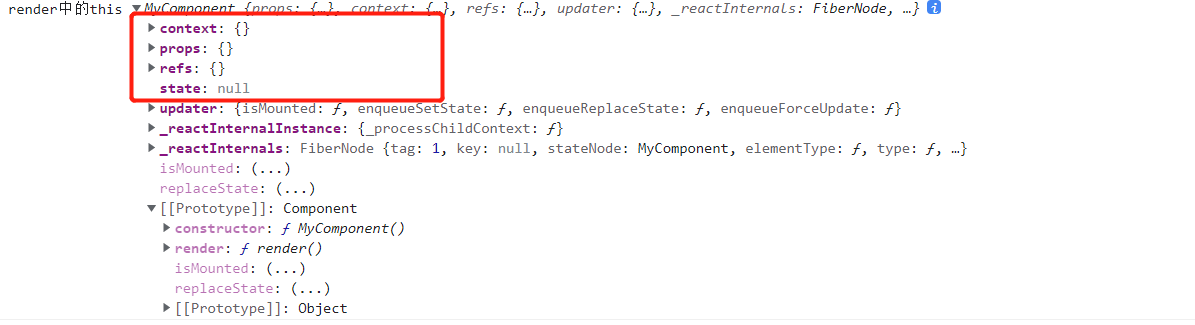
React面向组件编程
往期回顾:# React基础入门之虚拟Dom【一】 面向组件编程 react是面向组件编程的一种模式,它包含两种组件类型:函数式组件及类式组件 函数式组件 注:react17开始,函数式组件成为主流 一个基本的函数组件长这个样子 …...

Linux 多线程同步机制(上)
文章目录 前言一、线程同步二、互斥量 mutex三、死锁总结 前言 一、线程同步 在多线程环境下,多个线程可以并发地执行,访问共享资源(如内存变量、文件、网络连接 等)。 这可能导致 数据不一致性, 死锁, 竞争条件等 问题。 为了解…...
)
全学科适用AI写作辅助软件排名(2026 精选)
基于功能完整性、学术适配性、用户满意度和操作便捷性,以下是当前主流AI论文写作工具的权威测评结果,按综合使用价值从高到低排序,并详细说明各工具的核心优势与适用领域。🏆 第一梯队:全流程学术解决方案(…...

人大金仓KingbaseES分区表‘挂载’与‘摘除’功能详解:像搭积木一样管理你的数据
人大金仓KingbaseES分区表‘挂载’与‘摘除’功能实战指南:数据管理的乐高式玩法 想象一下,你的数据库表像一堆积木,可以随时拆解、重组,而无需担心数据丢失或性能下降。这正是人大金仓KingbaseES分区表"挂载(ATTACH)"和…...
)
告别昂贵下载器!用20块的CH347芯片在Vivado里玩转FPGA调试(保姆级XVC配置)
20元打造专业级FPGA调试环境:CH347芯片Vivado全攻略 在电子设计领域,FPGA开发一直被视为硬件工程师的"高端玩具",但配套调试工具的高昂价格往往让个人开发者和学生望而却步。一块正版Xilinx下载器动辄数千元的价格,足以…...

Nomulus多租户架构:如何在单一系统中管理多个TLD
Nomulus多租户架构:如何在单一系统中管理多个TLD 【免费下载链接】nomulus Top-level domain name registry service on Google Cloud Platform 项目地址: https://gitcode.com/gh_mirrors/no/nomulus Nomulus是一个开源的顶级域名注册系统,它采用…...

零代码自动化终极指南:用taskt在5分钟内解放你的双手
零代码自动化终极指南:用taskt在5分钟内解放你的双手 【免费下载链接】taskt taskt (pronounced tasked and formely sharpRPA) is free and open-source robotic process automation (rpa) built in C# powered by the .NET Framework 项目地址: https://gitcode…...

SGLang 未来演进与生态集成:从推理到 Agent 与多模态
系列导读 你现在看到的是《SGLang 推理加速与生产级服务化部署实战》的第 10/10 篇,当前这篇会重点解决:帮助读者建立对 SGLang 生态的全局视野,并规划后续深入方向,完成从入门到精通的闭环。 上一篇回顾:第 9 篇《SGLang 生产级部署排错指南:10 个常见问题与解决方案》…...

长期使用Taotoken Token Plan套餐对项目研发成本的控制效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐对项目研发成本的控制效果 在项目研发中,大模型API调用成本是预算管理的重要一环。对…...

Win11Debloat:让你的Windows系统告别臃肿,重获极速体验的完整指南
Win11Debloat:让你的Windows系统告别臃肿,重获极速体验的完整指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other chang…...

5个简单步骤掌握GanttProject:免费开源的项目管理工具终极指南
5个简单步骤掌握GanttProject:免费开源的项目管理工具终极指南 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject GanttProject是一款功能强大的免费开源项目管理软件,…...
)
如何用1条提示生成可商用超现实IP?:Midjourney商业级输出的6道合规校验流程(含版权链存证路径)
更多请点击: https://codechina.net 第一章:超现实IP的商业价值与Midjourney生成范式跃迁 超现实IP正从边缘创意实验走向主流商业基础设施——其核心驱动力并非单纯视觉奇观,而是对用户心智注意力的结构性重构。当品牌不再依赖写实叙事建立信…...