数据结构初阶--排序
目录
一.排序的基本概念
1.1.什么是排序
1.2.排序算法的评价指标
1.3.排序的分类
二.插入排序
2.1.直接插入排序
2.2.希尔排序
三.选择排序
3.1.直接选择排序
3.2.堆排序
重建堆
建堆
排序
四.交换排序
4.1.冒泡排序
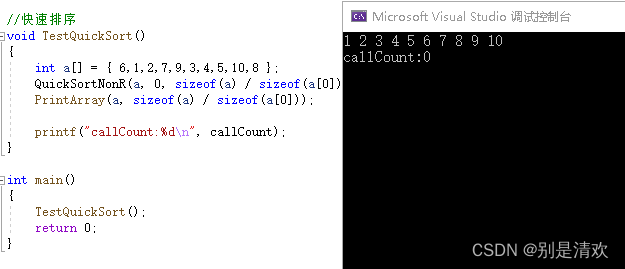
4.2.快速排序
快速排序的递归实现
法一:hoara法
法二:挖坑法
法三:前后指针法
快速排序优化
三数取中法选key
小区间非递归优化
快速排序的非递归实现
五.归并排序
归并排序的递归实现
归并排序的非递归实现
六.非比较排序
一.排序的基本概念

1.1.什么是排序
排序(Sort),就是重新排列表中的元素,使表中的元素满足按关键字有序的过程。
输入:n个记录R1,R2,Rn,对应的关键字为k1,k2,.,kn。
输出:输入序列的一个重排R`1,R`2,…,R’,使得有k`1≤k`2≤...≤k`n(也可递减)。
1.2.排序算法的评价指标
1.时间复杂度,空间复杂度;
2.稳定性。
若待排序表中有两个元素Ri和Rj,其对应的关键字相同即keyi=keyj,且在排序前Ri在Rj的前面,若使用某一排序算法排序后,Ri仍然在Rj的前面,则称这个排序算法是稳定的,否则称排序算法是不稳定的。
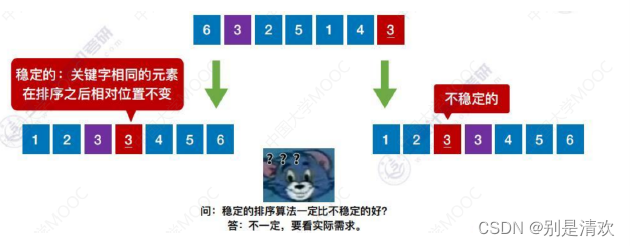
1.3.排序的分类
排序算法可以分为:
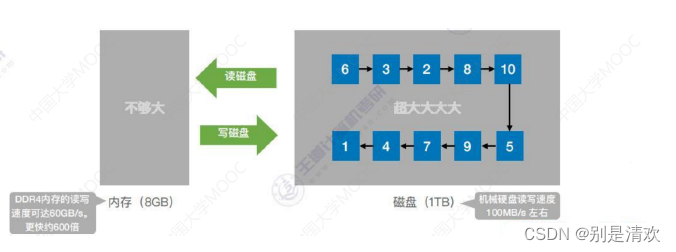
- 内部排序:数据都在内存中;
- 外部排序:数据太多,无法全部放入内存。
之所以有这种分类是因为磁盘的容量一般远大于内存,而运算速度又远不如内存。因此排序算法不仅要关注时间和空间复杂度,有时考虑到内存容量的问题还要关注如何使读/写磁盘次数更少。
二.插入排序
插入排序的基本思想:在一个已排好序的记录子集的基础上,每一步将下一个待排序的记录有序插入到已排好序的记录子集中,直到将所有待排记录全部插入为止。
2.1.直接插入排序
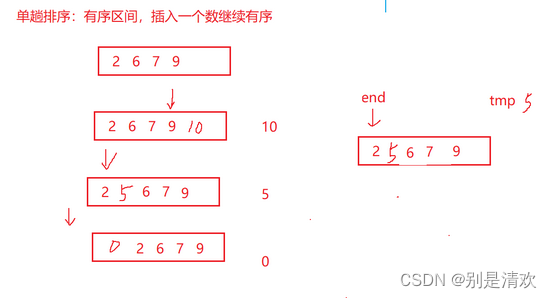
直接插入排序是一种最基本的插入排序方法,其基本操作是将第i个记录插入到前面i-1个已排好序的记录中。
具体过程:将第i个记录的关键字Ki,顺次与其前面记录的关键字Ki-1,Ki-2,…,K1进行比较,将所有关键字大于Ki的记录依次向后移动一个位置,直到遇见一个关键字小于或者等于Ki的记录Kj,此时Kj后面必为空位置,将第i个记录插人空位置即可。
完整的直接插人排序是从i=2开始的,也就是说,将第一个记录视为已排好序的单元素子集合,然后将第二个记录插入到单元素子集合中。i从2循环到n,即可实现完整的直接插入排序。
实现:
void InsertSort(int* a, int n)
{//[0,end]有序,把end+1位置的值插入,继续保持数组有序(升序)for (int i = 0; i < n - 1; i++){//单趟排序int end = i;//有序数组的最后一个元素的下标int tmp = a[end + 1];//tmp为待插入元素while (end >= 0){if (tmp < a[end])//若待插入元素小于有序数组中的最后一个元素{a[end + 1] = a[end];//将最后一个元素往后移动一位--end;//与有序数组的前一个元素继续比较}else{break;}}//1.break出来,也就是tmp>a[end]//2.break出来,也就是tmp比所有的值都小,end--之后变为-1,小于0a[end + 1] = tmp;}
}运行结果:
算法分析:
空间复杂度:O(1)。只需要定义几个所需空间为常数级的辅助变量(如i,j,tmp,a[0]),与问题的规模n无关。
时间复杂度:主要来自对比关键字,移动元素,若有n个元素,则需要n-1趟处理。
- 最好情况:数组原本就有序,O(N)。每一趟while循环只执行一次,只需要对比关键字1次,不用移动元素。
- 最坏情况:数组原本逆序,O(N^2)。while循环中关键字比较次数和移动记录的次数为i-1。
稳定性:稳定。在直接插入排序算法中,由于待插入元素的比较是从后向前进行的,循环的判断条件就保证了后面出现的关键字不可能插入到与前面相同的关键字之前,因此保证了直接插入排序方法的稳定性。
小结:
直接插入排序算法简单,比较适用于待排序记录数目较少且基本有序的情况
2.2.希尔排序
希尔排序又称缩小增量排序法,是一种基于插入思想的排序方法,它利用了直接插入排序的最佳性质。首先将待排序的关键字序列分成若干个较小的子序列,然后对子序列进行直接插入排序,最后再对全部记录进行一次直接插入排序。
- 首选选定记录间的距离为di(i=1),在整个待排序记录序列中将所有间隔为d1的记录分成一组,进行组内直接插入排序;
- 然后取i=i+1,记录间的距离为di(di<di-1),在整个待排序记录序列中,将所有间隔为di的记录分成一组,进行组内直接插入排序。
- 重复步骤2多次,直至记录间的距离di=1,此时整个只有一个子序列,对该序列进行直接插入排序,完成整个排序过程。
注意:
当子序列记录间的间隔为d时,共有d个子序列,需要对d个子序列分别进行插入排序。但是,算法在具体实现时,并不是先对一个子序列完成插入排序,再对另一个子序列进行插入排序,而是从第一个子序列的第二个记录开始,顺序扫描整个待排序记录序列,当前记录属于哪一个子序列,就在哪一个子序列中进行插入排序。
当从第一个子序列的第二个记录开始,顺序扫描整个待排序记录序列时,各子序列的记录将会轮流出现,所以算法将会在每一个子序列中轮流进行插入排序。
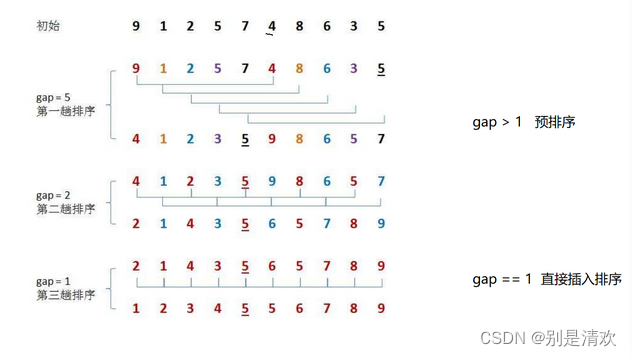
步骤:
- 预排序(接近顺序有序)。分gap组预排,大的数据更快到后面,小的数据更快到前面;
- 直接插入排序(有序)。
预排序法一:
先对一个子序列完成插入排序,再对另一个子序列进行插入排序
void ShellSort(int* a, int n)
{//取gap为3int gap = 3;//一组排完再排下一组for (int j = 0; j < gap; j++){for (int i = j; i < n - gap; i += gap){//每组内进行直接插入排序int end = i;int tmp = a[end + gap];while (end >= 0){//升序if (tmp < a[end]){//将大的数往后移,小的数往前移a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
运行结果:

预排序法二:
顺序扫描整个待排序记录序列,当前记录属于哪一个子序列,就在哪一个子序列中进行插入排序
void ShellSort(int* a, int n)
{//取gap为3int gap = 3;//每个子序列先排前两个元素,待所有子序列都排完之后,再增加一个元素进行新的排序for (int i = 0; i < n - gap; ++i){int end = i;int tmp = a[end + gap];while (end >= 0){//每组内进行直接插入排序if (tmp < a[end]){//将大的数往后移,小的数往前移a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}
}
运行结果:
关于增量的取法:
关于增量d的取法,最初希尔提出取d=⌊d/2⌋,再取d=⌊d/2⌋,直到d=1为止。该思路的缺点是,奇数位置的元素在最后一步才会与偶数位置的元素进行比较,使得希尔排序效率降低。因此,后来有人提出d=⌊d/3⌋+1。
排升序时,gap越大,大的数可以更快到后面,小的数也可以更快到前面,但是越不接近有序。
排升序时,gap越小,越接近有序,当gap==1时,就是直接插入排序。
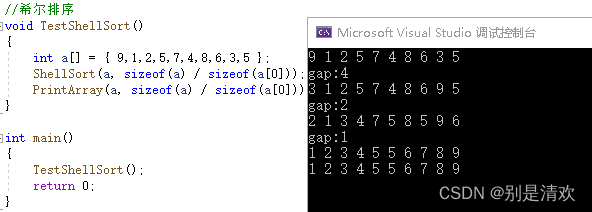
希尔排序实现:
void ShellSort(int* a, int n)
{PrintArray(a, n);//gap大于1时是预排序,gap最后一次等于1时,是直接插入排序int gap = n;while (gap > 1){gap = gap / 3 + 1;//+1是为了保证最后的gap值为1,为直接插入排序for (int i = 0; i < n - gap; ++i){int end = i;int tmp = a[end + gap];while (end >= 0){//每组内进行直接插入排序if (tmp < a[end]){//将大的数往后移,小的数往前移a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}printf("gap:%d\n", gap);PrintArray(a,n);}
}
运行结果:
算法分析:
空间复杂度:O(1)。只需要定义几个所需空间为常数级的辅助变量(如i,j,tmp,a[0]),与问题的规模n无关。
时间复杂度:和增量序列d1,d2,d3,...的选择有关,目前无法用数学手段证明确切的时间复杂度。最
坏时间复杂度为,当n在某个范围内时,可达O(N^1.3)。
稳定性:不稳定。在排序过程中,相同关键字记录的领先关系发生变化,则说明该排序方法是不稳定的。例如,有待排序序列{2,4,1,2},采用希尔排序,设d1=2,则有{2,4,1,2},得到一趟排序结果为{1,2,2,4},说明希尔排序法是不稳定的排序方法。
小结:
希尔排序对于中等规模(n<=1000)的序列具有较高的效率,且希尔排序算法简单,容易执行。因此很多排序应用程序都选了希尔排序算法。
三.选择排序
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
3.1.直接选择排序
具体过程:
- 设begin = 0为数组起始元素的下标,end = n - 1为数组末尾元素的下标,通过遍历数组[begin,end]中找出其中的最大值和最小值,并将最大值与数组末尾元素进行交换,将最小值与数组起始元素进行交换,此时最小值来到数组开头,最大值来到数组末尾。
- 然后将begin+1,来到数组起始第二个元素的位置并将其作为新的数组头;将end-1,来到数组末尾第二个元素的位置并将其作为新的数组尾,继续遍历数组[begin,end]中找出其中的最大值和最小值,并将最大值与数组末尾元素进行交换,将最小值与数组起始元素进行交换。
- 重复上述操作,直到begin >= end时循环结束。
案例:
对数组arr[6]={ 3,4,0,5,1,2 }进行直接插入排序:
- 第一次排序:begin = 0,end = 5,数组arr[6] = { 3,4,0,5,1,2 },最大值为5,最小值为0,排完序得:arr[6] = { 0,4,3,2,1,5 };
- 第二次排序:begin = 1,end = 4,数组arr[6] = { 0,4,3,2,1,5 },最大值为4,最小值为1,排完序得:arr[6] = { 0,1,3,2,4,5 };
- 第三次排序:begin = 2,end = 3,数组arr[6] = { 0,1,3,2,4,5 },最大值为3,最小值为2,排完序得:arr[6] = { 0,1,2,3,4,5 };
- 第四次排序:begin = 3,end = 2,数组已有序,排序完毕。
实现:
void Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}void SelectSort(int* a, int n)
{//判空assert(a);int begin = 0;int end = n - 1;while (begin < end){int mini = begin;//假设起始元素为最小值int maxi = begin;//假设起始元素为最大值//从第二个元素开始比较,找出数组中的最大值和最小值for (int i = begin + 1; i <= end; ++i){//若数组中存在一个比起始元素小的值if (a[i] < a[mini]){mini = i;}//若数组中存在一个比起始元素大的值if (a[i] > a[maxi]){maxi = i;}}//将最小值换到数组的起始位置Swap(&a[begin], &a[mini]);//如果begin和maxi重叠,则要修正一下maxi的位置//如果begin所在下标的值为最大值,在和较小元素互换之后,最大值已不在begin所在下标的位置,而是转到新的mini所在下标的位置if (begin == maxi){maxi = mini;}//将最大值换到数组的最后位置Swap(&a[end], &a[maxi]);++begin;--end;}
}注意:
当最大值maxi和begin发生位置重叠时,在进行最小值mini和begin交换过程中,最大值maxi会被交换到最小值mini的位置。此时,如果直接进行Swap(&a[end], &a[maxi]),排序就会出现问题。因此,在进行最大值maxi和end交换之前,需要判断一下最大值maxi与begin的位置是否发生重叠,若发生重叠,则将最大值maxi进行更新,然后再进行交换。
运行结果:
算法分析:
空间复杂度:O(1)。只需要定义几个所需空间为常数级的辅助变量(如i,j,tmp,a[0]),与问题的规模n无关。
时间复杂度:假设要对n个数据进行选择排序,则总共要进行n/2次最大值和最小值的筛选,第一次排序要遍历n个数据,第二次排序要遍历n-2个数据,...,最后一次排序要遍历2个数据或1个数据。设遍历一次数据就表示要进行一次排序操作,则总共要进行的操作次数为:
![]()
根据大O渐进法规则,选择排序的时间复杂度为:O(N^2)。
稳定性:不稳定。在排序过程中,相同关键字记录的领先关系发生变化,则说明该排序方法是不稳定的。例如,有待排序序列{3,3,2},采用选择排序,第一次交换得{2,3,3},说明希尔排序法是不稳定的排序方法。
3.2.堆排序

堆排序的过程主要需要解决两个问题:一是按堆定义建初堆,二是去掉最大元之后重建堆,得到次大元,以此类推。
我们以升序建大堆为例:
重建堆
向下调整建堆法:
首先将数组中的元素以完全二叉树的形式排列好,然后从倒数第一个非叶子结点开始,调用函数AdjustDown依次向下调整。每调整一次,则将i的值减1,让其来到倒数第二个非叶子结点的位置,重复上述操作,直到i来到根结点的位置。
实现:
//向下调整
void AdjustDown(HPDataType* a, int size, int parent)
{//1.选出左右孩子中小的那一个int child = parent * 2 + 1;//假设左孩子最小while (child < size){//当右孩子存在且右孩子小于左孩子if (child + 1 < size && a[child + 1] > a[child])//大堆:a[child+1]>a[child]{++child;//则将右孩子置为child}//2.小的孩子跟父亲比较,如果比父亲小,则交换,然后继续往下调整;如果比父亲大,则调整结束if (a[child] > a[parent])//大堆:a[child]>a[parent]{//交换数据Swap(&a[child], &a[parent]);//3.继续往下调,最多调整到叶子结点就结束//把孩子的下标赋值给父亲parent = child;//假设左孩子最小child = parent * 2 + 1;}else{break;}}
}建堆
将一个任意序列看成是对应的完全二叉树,由于叶结点可以视为单元素的堆,因而可以反复利用向下调整建堆法,自底向上逐层把所有子树调整为堆,直到将整个完全二叉树调整为堆。
可以证明,上述完全二叉树中,最后一个非叶结点位于第⌊n/2⌋个位置,n为二叉树结点目。因此,向下调整建堆法需从第⌊n/2⌋个结点开始,逐层向上倒退,直到根结点。
实现:
//交换数据
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}//向下调整
void AdjustDown(HPDataType* a, int size, int parent)
{//1.选出左右孩子中小的那一个int child = parent * 2 + 1;//假设左孩子最小while (child < size){//当右孩子存在且右孩子小于左孩子if (child + 1 < size && a[child + 1] > a[child])//大堆:a[child+1]>a[child]{++child;//则将右孩子置为child}//2.小的孩子跟父亲比较,如果比父亲小,则交换,然后继续往下调整;如果比父亲大,则调整结束if (a[child] > a[parent])//大堆:a[child]>a[parent]{//交换数据Swap(&a[child], &a[parent]);//3.继续往下调,最多调整到叶子结点就结束//把孩子的下标赋值给父亲parent = child;//假设左孩子最小child = parent * 2 + 1;}else{break;}}
}void HeapSort(int* a, int n)
{//建堆//建堆方式二:向下调整//向下调整算法的左右子树必须是堆,因此不能使用该方法直接建堆//时间复杂度:O(N)//首先将数组中的元素以完全二叉树的形式排列好,然后从倒数第一个非叶子结点开始,依次向下调整for (int i = (n - 1 - 1) / 2; i >= 0; i--)//n-1为最后一个结点的下标,求最后一个结点的父结点的下标(n-1-1)/2{AdjustDown(a, n, i);}
}int main()
{int a[] = { 27,15,19,18,28,34,65,49,25,37 };HeapSort(a, sizeof(a) / sizeof(a[0]));return 0;
}排序
具体步骤如下:
- 将待排序记录按照堆的定义建初堆,并输出堆顶元素;
- 调整剩余的记录序列,利用向下调整建堆法将前n-i个元素重新筛选建成为一个新堆,再输出堆顶元素;
- 重复执行步骤2,进行n-1次筛选,新筛选成的堆会越来越小,而新堆后面的有序关键字会越来越多,最后使待排序记录序列成为一个有序的序列,这个过程称为堆排序。
实现:
//交换数据
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}//向下调整
void AdjustDown(HPDataType* a, int size, int parent)
{//1.选出左右孩子中小的那一个int child = parent * 2 + 1;//假设左孩子最小while (child < size){//当右孩子存在且右孩子小于左孩子if (child + 1 < size && a[child + 1] > a[child])//大堆:a[child+1]>a[child]{++child;//则将右孩子置为child}//2.小的孩子跟父亲比较,如果比父亲小,则交换,然后继续往下调整;如果比父亲大,则调整结束if (a[child] > a[parent])//大堆:a[child]>a[parent]{//交换数据Swap(&a[child], &a[parent]);//3.继续往下调,最多调整到叶子结点就结束//把孩子的下标赋值给父亲parent = child;//假设左孩子最小child = parent * 2 + 1;}else{break;}}
}void HeapSort(int* a, int n)
{//建堆//建堆方式二:向下调整//向下调整算法的左右子树必须是堆,因此不能使用该方法直接建堆//时间复杂度:O(N)//首先将数组中的元素以完全二叉树的形式排列好,然后从倒数第一个非叶子结点开始,依次向下调整for (int i = (n - 1 - 1) / 2; i >= 0; i--)//n-1为最后一个结点的下标,求最后一个结点的父结点的下标(n-1-1)/2{AdjustDown(a, n, i);}//排序//时间复杂度:O(N*logN),其中N为元素个数,logN为向上调整的次数,也即树的高度int end = n - 1;while (end > 0){//将第一个结点与最后一个结点交换Swap(&a[0], &a[end]);//向下调整选出次大的数AdjustDown(a, end, 0);--end;}
}int main()
{int a[] = { 27,15,19,18,28,34,65,49,25,37 };HeapSort(a, sizeof(a) / sizeof(a[0]));return 0;
}运行结果:
算法分析:
空间复杂度:O(1)。只需要定义几个所需空间为常数级的辅助变量(如i,j,tmp,a[0]),与问题的规模n无关。
时间复杂度:
建堆时间复杂度:
因为堆是一棵完全二叉树,而满二叉树又是一种特殊的完全二叉树,为了简化计算,我们不妨假设此处的堆是一棵满二叉树。

由上图得,对于高度为h的满二叉树构成的堆,最多进行向上调整的次数设为,有:
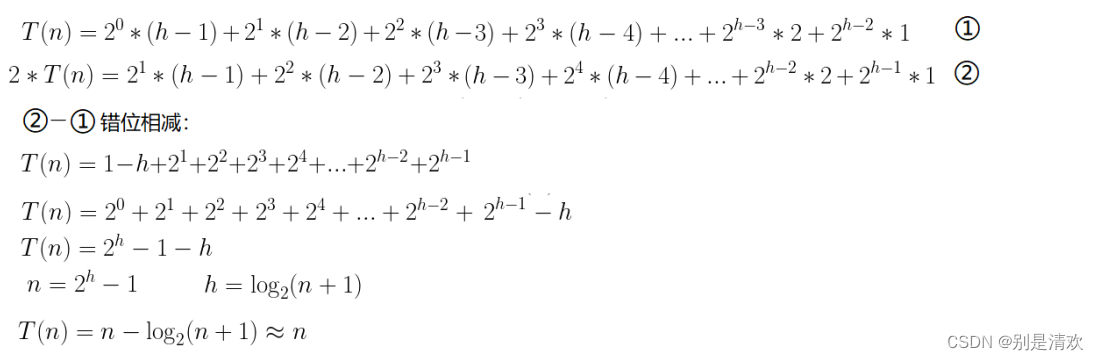
综上,证得向上调整建堆的时间复杂度为O(N)。
排序时间复杂度:
n个结点的完全二叉树的深度为⌊log2(n)⌋+1,n个结点排序时调用向下调整函数n-1次,总共进行的比较次数不超过2(⌊log2(n-1)⌋+⌊log2(n-2)⌋+...+⌊log2(2)⌋)<2n⌊log2(n)⌋,因此,堆排序在最坏情况下,其时间复杂度也为O(N*log2N),这是堆排序的最大优点。
所以堆排序的总的时间复杂度为:O(N*log2N)
稳定性:不稳定。例如,有待排序序列{5,5,3},采用堆排序,第一次排序得{3,5,5},说明希尔排序法是不稳定的排序方法。
四.交换排序
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置。交换排
序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
4.1.冒泡排序
冒泡排序是一种简单的交换类排序方法,它是通过对相邻的数据元素进行交换,逐步将待排序序列变成有序序列的过程。
具体过程:反复扫描待排序记录序列,在扫描的过程中顺次比较相邻的两个元素的大小,若逆序就交换位置。
以升序为例,在第一趟冒泡排序中,从第一个记录开始,扫描整个待排序记录序列,若相邻的
两个记录逆序,则交换位置。
在扫描的过程中,不断地将相邻两个记录中关键字大的记录向后移动,最后必然将待排序记录序列中的最大关键字记录换到待排序记录序列的末尾,这也是最大关键字记录应在的位置。
然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作,其结果是使次大的记录被放在第n-1个记录的位置上。
然后进行第三趟冒泡排序,对前n-2个记录进行同样的操作,其结果是使第三大的记录被放在第n-2个记录的位置上。
如此反复,每一趟冒泡排序都将一个记录排到位,直到剩下一个最小的记录。
若在某一趟冒泡排序过程中,没有发现一个逆序,则可直接结束整个排序过程,所以冒泡过程最多进行n-1趟。
实现:
void BubbleSort(int* a, int n)
{//判空assert(a);//排升序for (int j = 0; j < n - 1; j++){//用于判断是否有数据发生交换int exchange = 0;for (int i = 1; i < n - j; i++){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);//若有数据发生交换,则将exchange置为1exchange = 1;}}//若本趟没有数据发生交换,则说明数组已经有序,直接退出if (exchange == 0){break;}}
}注意:
在排序的过程中,从某一轮开始数组已经变得有序,但是循环还在继续,显然后面的排序都是无用功。为了避免这些时间的消耗,只需在算法中设置一个简单的标志位exchange即可。使用该排序算法,能明显降低时间损耗。而在空间上只是多用了一个int型的变量exchange,空间复杂度仍为一个常数。
运行结果:
算法分析:
空间复杂度:O(1)。只需要定义几个所需空间为常数级的辅助变量(如i,j,tmp,a[0]),与问题的规模n无关。
时间复杂度:最好的情况是初始序列已经满足要求的排序序列,此时时间复杂度为O(N);最坏的情况是初始序列刚好为要求顺序的逆序,此时的时间复杂度为。
设待排序的数据元素个数为N,总共要进行N-1趟冒泡排序,第一趟冒泡排序最多进行N-1次数据交换,第二趟冒泡排序最多进行N-2次数据交换,..,最后一趟冒泡排序最多进行1次数据交换,因此,总共要进行数据交换的次数为:
根据大O渐进法规则,冒泡排序的时间复杂度为。
稳定性:稳定。冒泡排序不会改变两个键值相同记录的先后顺序,因为并不满足循环判断条件,所以无法对它们进行位置交换。因此冒泡排序是稳定的。
4.2.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
快速排序的递归实现
法一:hoara法
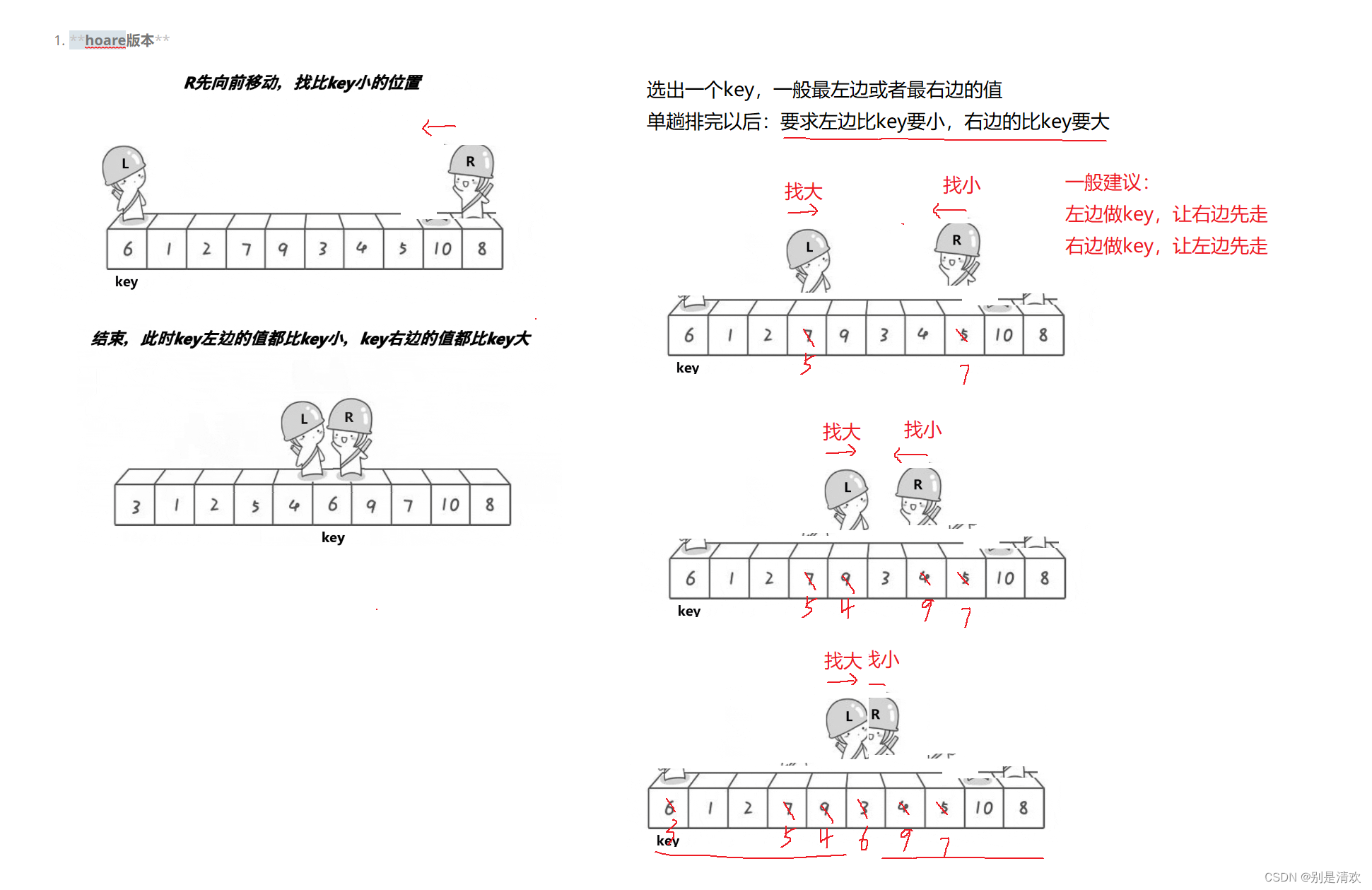
选出一个key,一般选择最左边或者最右边的值,单趟排完之后,要求左边比key要小,右边比key要大。具体步骤:右边先走,R从右向左找,遇到比key小的值就停下,L从左向右找,遇到比key大的值就停下,然后进行交换,重复上述操作,若相遇则停下。
注意:L和R指针并不是同时运动的,而是有一定的先后顺序。
- 如果选取最左边的元素作为key,则R先向左运动。
- 如果选择最右边的元素作为key,在L先向右运动。
为什么选择最左边的值做key时,要让右边先走? 答:因为要保证相遇位置的值,比key要小或者就是key的位置。
- 情况一:R先走,R停下来,L去遇到了R,相遇的位置就是R停下来的位置,R停的位置就是比key要小的位置;
- 情况二:R先走,R没有遇到比key要小的值,R去遇到了L,相遇的位置是L上一轮停下来的位置,要么就是key的位置,要么比key要小。
建议:左边做key,让右边先走;右边做key,让左边先走
实现:
void Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}int PartSort(int* a, int begin, int end)
{int left = begin;//让left指向数组起始位置int right = end;//让right指向数组末尾位置int keyi = left;//将最左边的值选为keywhile (left < right){//右边先走//找小while (left < right && a[right] >= a[keyi])//要取到=号,否则会陷入死循环{--right;}//左边再走//找大while (left < right && a[left] <= a[keyi]){++left;}//R从右向左找,遇到比key小的值就停下,L从左向右找,遇到比key大的值就停下,然后进行交换Swap(&a[left], &a[right]);}//若相遇,则将key放到right和left相遇的位置Swap(&a[keyi], &a[left]);//更新keyi的位置keyi = left;return keyi;
}void QuickSort(int* a, int begin, int end)
{//若begin>=end,则递归结束if (begin >= end){return;}//单趟排序获取key值int key = PartSort(a, begin, end); //递归左区间[begin,keyi-1]QuickSort(a, begin, key - 1);//递归右区间[keyi+1,end]QuickSort(a, key + 1, end);
}法二:挖坑法
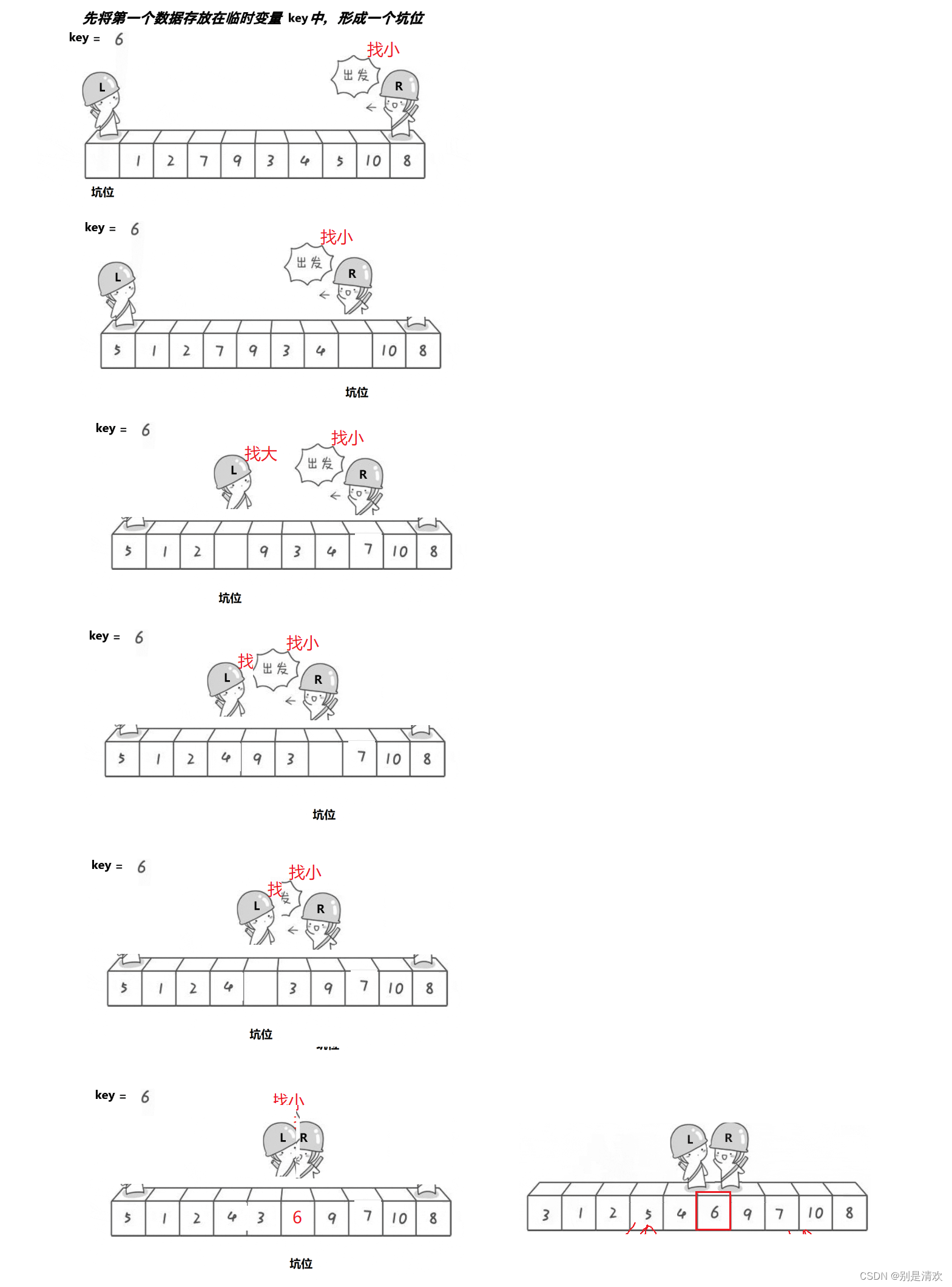
先将第一个数据存放在临时变量key中,形成一个坑位,R开始向前移动,找比key的值小的位置,找到后,将该值放入坑位中,该位置形成新的坑位;L开始向后移动,找比key大的值,找到后,又将该值放入坑位中,再形成新的坑位。R再次向前移动,找比key小的位置,找到后,将该值放入坑位,该位置形成新的坑位;L紧接着向后移动,找到比key小的位置,找到后,将该值放入坑位,该位置形成新的坑位。重复上述操作,直到L和R相遇见,将key中的值放入坑位。结束循环,此时坑位左边的值都比坑位小,右边的值都比坑位大。
实现:
void Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}int PartSort(int* a, int begin, int end)
{//将第一个数据保存在变量key中int key = a[begin];//先将坑位设置在第一个数据的位置int piti = begin;while (begin < end){//从右向左找小于key的值,并将其填到左边的坑里面去,同时这个位置形成新的坑while (begin < end && a[end] >= key)//为了防止越界,以及避免死循环{--end;}a[piti] = a[end];piti = end;//从左向右找大于key的值,并将其填到右边的坑里面去,同时这个位置形成新的坑while (begin < end && a[begin] <= key){++begin;}a[piti] = a[begin];piti = begin;}//若相遇,且一定相遇在坑的位置上a[piti] = key;return piti;
}void QuickSort(int* a, int begin, int end)
{//若begin>=end,则递归结束if (begin >= end){return;}//单趟排序获取key值int key = PartSort(a, begin, end); //递归左区间[begin,keyi-1]QuickSort(a, begin, key - 1);//递归右区间[keyi+1,end]QuickSort(a, key + 1, end);
}法三:前后指针法
初始时,prev指针指向序列开头,cur指针指向prev指针的后一个位置,然后判断cur指针指向的数据是否小于key,若小于,则prev指针后移一位,并将cur指向的内容与prev指向的内容交换,然后cur指针++;若大于,则cur指针继续++。当cur指针已经越界,这时将prev指向的内容与key进行交换,循环结束,此时key左边的数据都比key小,key右边的数据都比key大。

实现:
void Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}int PartSort(int* a, int begin, int end)
{int pre = begin;//prev指针指向序列开头int cur = begin + 1;//cur指针指向prev指针的后一个位置int keyi = begin;//将最左边的值选为keywhile (cur <= end){//如果cur位置的值小于keyi位置的值if (a[cur] < a[keyi] && ++pre != cur)//若pre++之后指向与cur同一个位置,此时指向的内容相同,则不交换{Swap(&a[pre], &a[cur]);}++cur;}//当cur已经越界时Swap(&a[pre], &a[keyi]);//更新keyikeyi = pre;return keyi;
}void QuickSort(int* a, int begin, int end)
{//若begin>=end,则递归结束if (begin >= end){return;}//单趟排序获取key值int key = PartSort(a, begin, end); //递归左区间[begin,keyi-1]QuickSort(a, begin, key - 1);//递归右区间[keyi+1,end]QuickSort(a, key + 1, end);
}快速排序优化
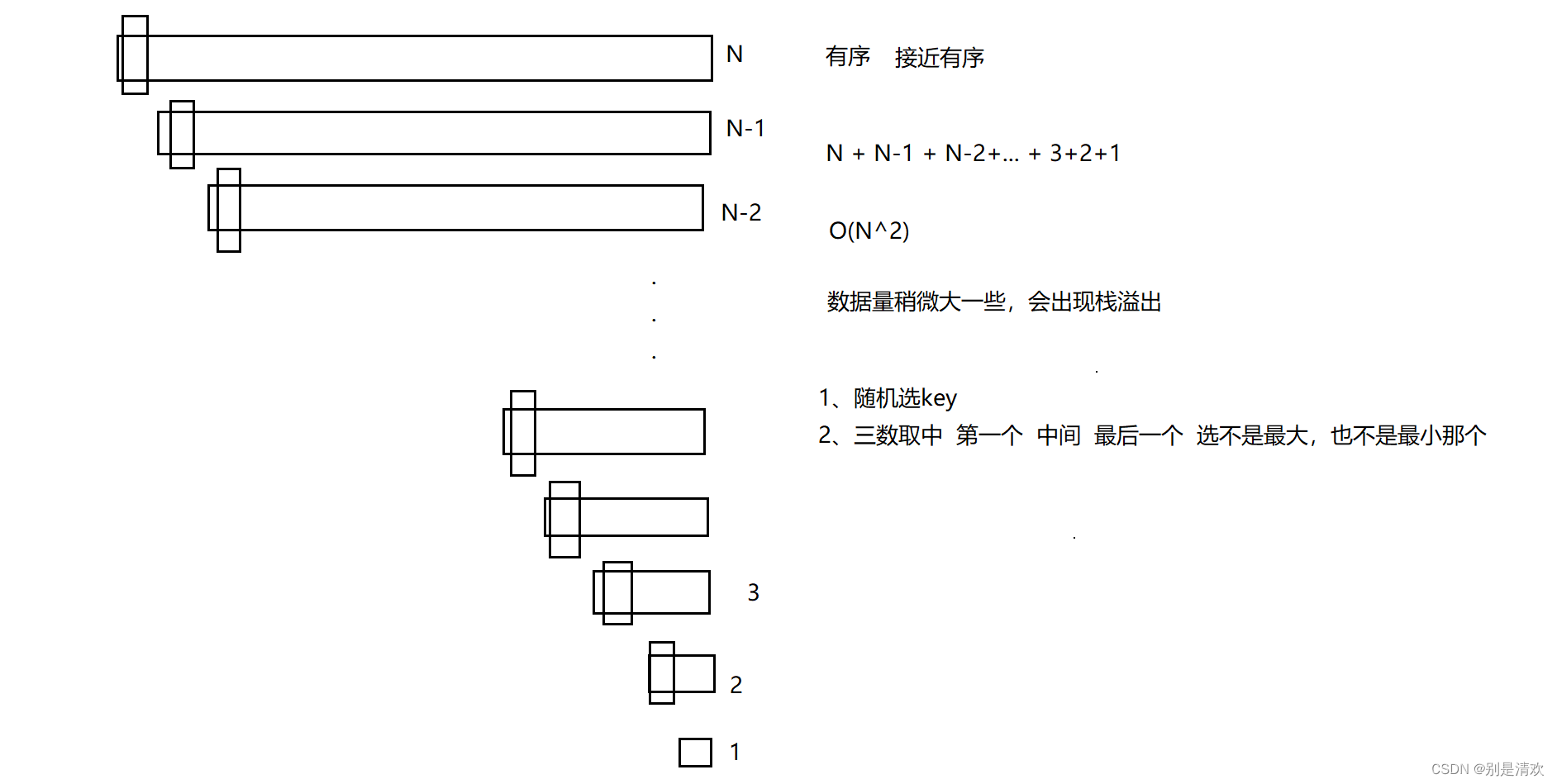
三数取中法选key
第一个数,中间的数以及最后一个数,选一个不是最大也不是最小那一个。
为什么说找出来的mid是最适合做key?
答:一般选取的key都是数组起始值或者末尾值,若此时的key值是最大值或者最小值,那么就会造成快速排序性能退化。所以若能找出一个介于最大值与最小值之间的中间值,就能大大提高快速排序的性能。
实现:
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end]){return mid;}else if (a[begin] < a[end]){return end;}else{return begin;}}else//a[begin] > a[mid]{if (a[mid] > a[end]){return mid;}else if (a[begin] < a[end]){return begin;}else{return end;}}
}小区间非递归优化
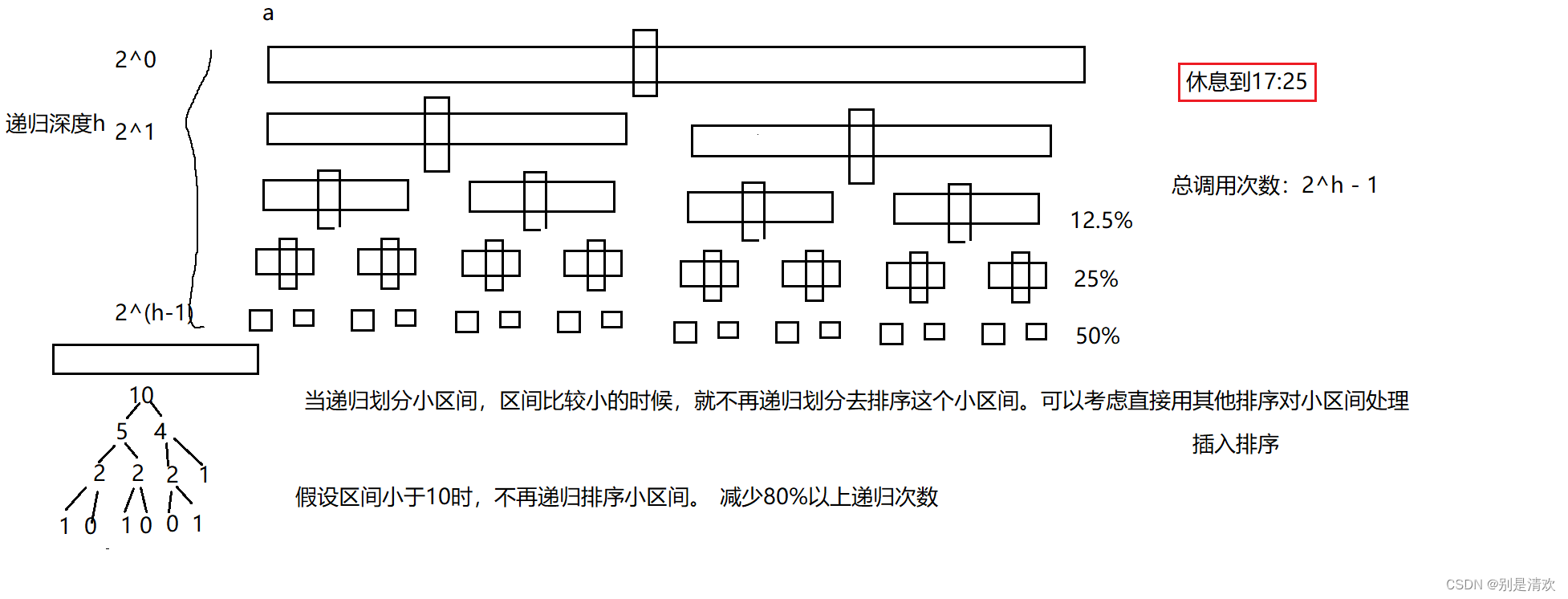
随着递归次数的增加,那么程序在递归过程中所消耗的内存也会越来越多,当数据量稍微大一些时,甚至可能会导致栈溢出。所以为了提高系统的效率,我们将递归过程中产生的小区间改用非递归的方式。递归划分小区间,当区间较小时,就不再采用递归的方式去对这个小区间进行排序,而是考虑用其他排序方法,比如插入排序,对小区间进行处理。假设区间小于10时,不再递归排序小区间,则可以减少80%以上的递归次数。
这里以前后指针法为例,将快速排序进行优化
//直接插入排序
void InSertSort(int* a, int n)
{//[0,end]有序,把end+1位置的值插入,保持有序for (int i = 0; i < n - 1; i++){//单趟排序int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];--end;}else{break;}}//1.break出来,也就是tmp>a[end]//2.tmp比所有的值都小,end--之后变为-1,小于0a[end + 1] = tmp;}
}//数据交换
void Swap(int* px, int* py)
{int tmp = *px;*px = *py;*py = tmp;
}/三数取中法选key
int GetMidIndex(int* a, int begin, int end)
{int mid = (begin + end) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end]){return mid;}else if (a[begin] < a[end]){return end;}else{return begin;}}else//a[begin] > a[mid]{if (a[mid] > a[end]){return mid;}else if (a[begin] < a[end]){return begin;}else{return end;}}
}//前后指针法
int PartSort(int* a, int begin, int end)
{int pre = begin;//prev指针指向序列开头int cur = begin + 1;//cur指针指向prev指针的后一个位置int keyi = begin;//将最左边的值选为keyint midi = GetMidIndex(a, begin, end);Swap(&a[keyi], &a[midi]);while (cur <= end){//如果cur位置的值小于keyi位置的值if (a[cur] < a[keyi] && ++pre != cur)//若pre++之后指向与cur同一个位置,此时指向的内容相同,则不交换{Swap(&a[pre], &a[cur]);}++cur;}//当cur已经越界时Swap(&a[pre], &a[keyi]);//更新keyikeyi = pre;return keyi;
}//初始化
int callCount = 0;//需在头文件进行声明再使用//[begin,end]
void QuickSort(int* a, int begin, int end)
{callCount++;//当区间不存在,或者只有一个值时则不需要再处理if (begin >= end){return;}//递归到小的子区间时,可以考虑使用插入排序if (end - begin > 10){int keyi = PartSort(a, begin, end);//[begin,keyi-1] keyi [keyi+1,end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{//插入排序InSertSort(a + begin, end - begin + 1);}
}
运行结果:
快速排序的非递归实现
如果对大量有序数据或者接近有序的数据进行排序,则可能会造成栈溢出。为了避免递归层数太深,或让快速排序适用于规模较大且接近有序的数据,用非递归的方法实现快排显得尤为重要。
递归大问题,极端场景下面,如果递归深度太深,会出现栈溢出。 解决方法:
- 将递归改成循环,比如斐波那契数列,归并排序等;
- 用数据结构栈模拟递归过程。
思路分析:
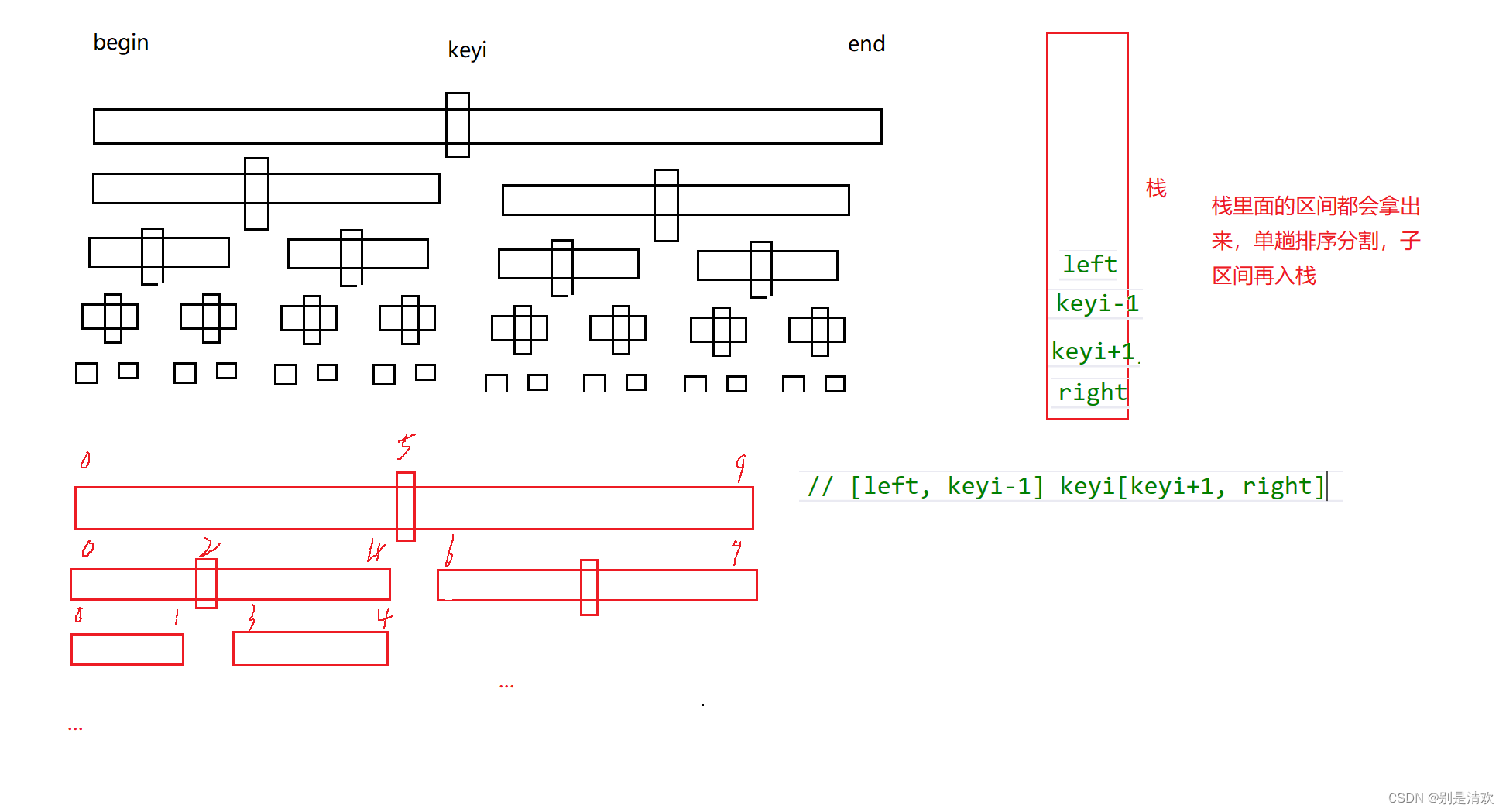
1.首先将待排序数组的起始元素下标设为begin,末尾元素下标设为end,则此时的待排序数组转化为[begin,end]。然后让该数组的末尾元素和起始元素分别进栈。接着读取栈顶的两个元素,也就是读取数组的起始元素和末尾元素,并将它们分别出栈。最后对该数组[begin,end]进行第一次单趟快排,找出第一个满足条件的key值。
2.在找出第一个key值之后,记录其对应位置为keyi。此时原数组[left,right]被划分为三个部分:[left,keyi-1],keyi,[keyi+1,right]。
3.对划分出来的两个子区间[left,keyi-1]和[keyi+1,right]分别进行上述操作,即先让右小区间[keyi+1,right]入栈,再让左小区间[left,keyi-1]入栈,然后读取栈顶两个元素并分别出栈,同时进行相应的快排操作。
4.重复上述操作,当栈为空时,则表明排序结束,数组已经有序。

实现:
void QuickSortNonR(int* a, int begin, int end)
{ST st;//栈:后进先出//初始化StackInit(&st);//进栈StackPush(&st, end);StackPush(&st, begin);while (!StackEmpty(&st)){int left = StackTop(&st);StackPop(&st);int right = StackTop(&st);StackPop(&st);int keyi = PartSort3(a, left, right);//[left,keyi-1] keyi [keyi+1,right]//栈里面的区间都会拿出来,单趟排序分割,子区间再入栈if (left < keyi - 1){StackPush(&st, keyi - 1);StackPush(&st, left);}if (keyi + 1 < right){StackPush(&st, right);StackPush(&st, keyi + 1);}}//销毁StackDestory(&st);
}运行结果:
算法分析:
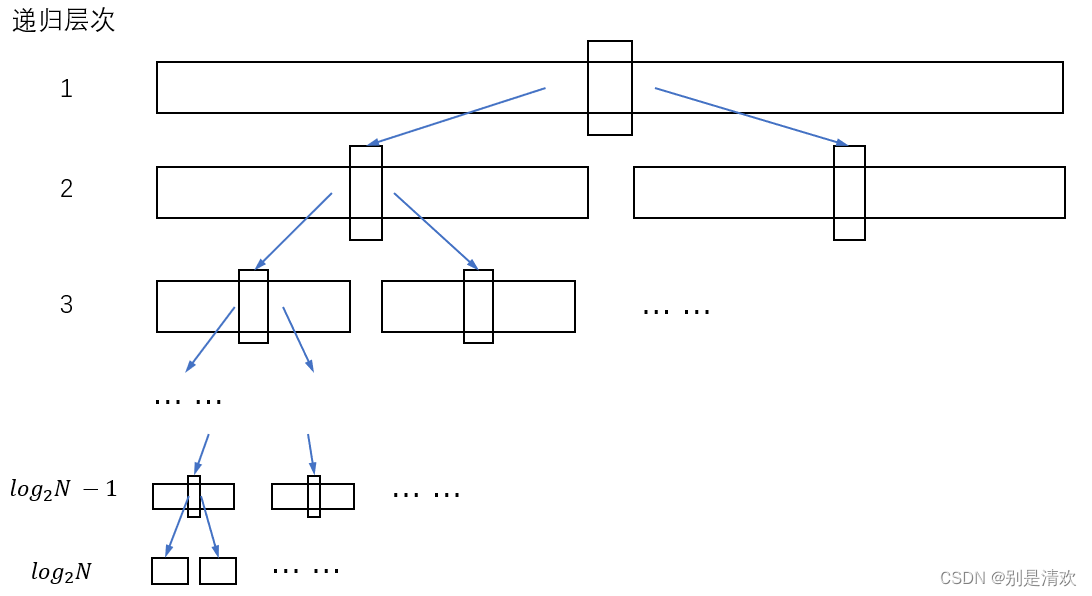
空间复杂度:快速排序递归算法的执行过程对应一棵二叉树,理想情况下是一棵完全二叉树,递归工作栈的大小与上述递归调用二叉树的深度对应,平均情况下辅助空间复杂度为O(logN)。
时间复杂度:分析快速排序的时间耗费,共需要进行多少趟排序,取决于递归调用深度。 快速排序的最好情况是每趟将序列一分两半,正好在表中间,将表分成两个大小相等的子表,类似于折半查找。时间复杂度为:O(n*logN)。
快速排序的最坏情况是已经排好序,第一趟经过n-1次比较,第一个记录定在原位置左部子表为空表,右部子表为n-1个记录。第二趟n-1个记录经过n-2次比较,第二个记录定在原位置,左部子表为空表,右部子表为n-2个记录,以此类推,共需进行n-1趟排序,其比较次数为(n-1)+(n-2)+…+1=n*(n-1)/2。时间复杂度为:O(n^2)。

快速排序的空间复杂度分析:快速排序递归算法的执行过程对应一棵二叉树,理想情况下是一棵完全二叉树,递归工作栈的大小与上述递归调用二叉树的深度对应,平均情况下辅助空间复杂度为:O(logN)。
稳定性:不稳定。如数组{3,3,2},当发生第一次数据交换时,原数组变为:{2,3,3}。所以快速排序是不稳定的算法。
五.归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
二路归并:假设初始序列含有n个记录,首先将这n个记录看成n个有序的子序列,每个子序列的长度为1,然后两两归并,得到⌈n/2⌉个长度为2(n为奇数时,最后一个序列的长度为1)的有序子序列。在此基础上,再对长度为2的有序子序列进行两两归并,得到若干个长度为4的有序子序列。如此重复,直到得到一个长度为n的有序序列为止。
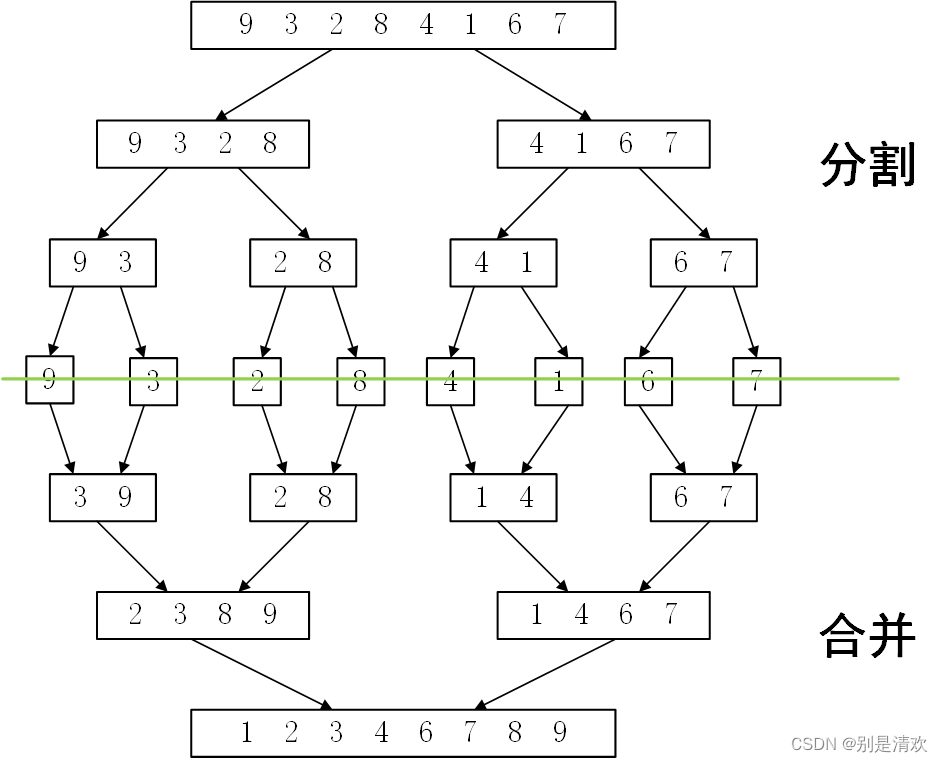
归并排序的递归实现
具体步骤:
- 假设有待排序数组[begin,end],首先判断begin是否小于end,若小于则表明数组存在,否则直接退出,然后将数组从中间mid=(begin+end)/2分开;
- 接着对左半部分子区间[begin,mid]和右半部分子区间[mid+1,end]分别递归地进行归并排序,让子区间变得有序;
- 当子区间变得有序之后,再进行归并,将左右两个有序子序列归并为一个;
- 最后再将归并好的数据拷回原数组。
实现:
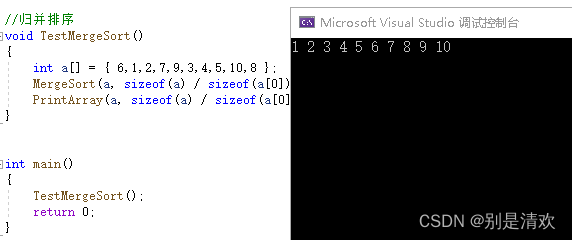
void _MergeSort(int* a, int begin, int end, int* tmp)
{if (begin >= end){return;}int mid = (begin + end) / 2;//分治递归,让子区间有序 [begin,mid][mid+1,end]//递归左区间_MergeSort(a, begin, mid, tmp);//递归右区间_MergeSort(a, mid + 1, end, tmp);//归并 [begin,mid][mid+1,end]int begin1 = begin;int end1 = mid;int begin2 = mid + 1;int end2 = end;int i = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}//当begin1还没走完while (begin1 <= end1){tmp[i++] = a[begin1++];}//当begin2还没走完while (begin2 <= end2){tmp[i++] = a[begin2++];}//把归并后的数据拷贝回原数组memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}_MergeSort(a, 0, n - 1, tmp);free(tmp);
}
递归分析:

运行结果:
归并排序的非递归实现
如何对数组进行分解并将分解后的子区间进行排序呢?
这里主要是通过控制变量gap来对数组进行分解和归并的。将gap的初始值设为1,从数组起始位置开始每次选取两个子区间[i,i+gap-1]和[i+gap,i+2*gap-1],起始状态的子区间元素个数为1,然后将两个子区间进行归并处理。待所有子区间都处理完之后再将gap扩大为原来的2倍,从数组起始位置开始每次选取两个子区间[i,i+gap-1]和[i+gap,i+2*gap-1],起始状态的子区间元素个数为2,然后将两个子区间进行归并处理。重复上述操作,直到整个数组变得有序。

但是这样进行子区间的划分,可能会造成区间越界问题,那又该如何处理?
我们将两个子区间[i,i+gap-1]和[i+gap,i+2*gap-1]的边界值分别设为begin1,end1和begin2,end2,则子区间转换为[begin1,end1]和[begin2,end2]。可以肯定的是,在四个边界值中只有begin1不会发生越界,其余三个边界值均有可能发生越界。此时又可分为三种情况进行讨论:
- end1不越界,begin2和end2越界;
- end1、begin2和end2均越界;
- end1和begin2不越界,end2越界。
 处理方式:
处理方式:
法一:分析越界的三种情况,然后对其分别进行处理,也就是将已经发生越界的区间修改为在合理范围内的不存在的区间;
法二:若end1越界或者begin2越界,则可以不归并,直接退出循环;若只有end2发生越界,则直接将已经发生越界的区间修改为在合理范围内的不存在的区间。
实现:整个数组归并完之后进行整体拷贝
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n){printf("gap=%d->", gap);for (int i = 0; i < n; i += 2 * gap){//[i,i+gap-1][i+gap,i+2*gap-1]//归并 [begin,mid][mid+1,end]int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;//越界问题处理-修正边界//注意:只有begin1不会越界//若end1越界if (end1 >= n){end1 = n - 1;//begin2和end2已经越界 将[begin2,end2]修正为一个不存在的区间begin2 = n;end2 = n - 1;}else if (begin2 >= n)//若begin2越界{//begin2和end2已经越界 将[begin2,end2]修正为一个不存在的区间begin2 = n;end2 = n - 1;}else if (end2 >= n)//若end2越界{end2 = n - 1;}printf("[%d,%d][%d,%d]--", begin1, end1, begin2, end2);int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}//当begin1还没走完while (begin1 <= end1){tmp[j++] = a[begin1++];}//当begin2还没走完while (begin2 <= end2){tmp[j++] = a[begin2++];}}printf("\n");//把归并数据拷贝回原数组memcpy(a, tmp, sizeof(int) * n);gap *= 2;}free(tmp);
}运行结果:

实现:归并完一组数据则拷贝一组数据
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){printf("malloc fail\n");exit(-1);}int gap = 1;while (gap < n){printf("gap=%d->", gap);for (int i = 0; i < n; i += 2 * gap){//[i,i+gap-1][i+gap,i+2*gap-1]//归并 [begin,mid][mid+1,end]int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;//end1越界或者begin2越界,则可以不归并了if (end1 >= n || begin2 >= n){break;}else if (end2 >= n){end2 = n - 1;}printf("[%d,%d][%d,%d]--", begin1, end1, begin2, end2);int m = end2 - begin1 + 1;//统计元素个数int j = begin1;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}//当begin1还没走完while (begin1 <= end1){tmp[j++] = a[begin1++];}//当begin2还没走完while (begin2 <= end2){tmp[j++] = a[begin2++];}//把归并数据拷贝回原数组memcpy(a + i, tmp + i, sizeof(int) * m);}printf("\n");gap *= 2;}free(tmp);
}运行结果:

算法分析:
空间复杂度:O(N)。在实现归并排序时,需要和待排记录等数量的辅助空间,因而空间复杂度为O(N)。
时间复杂度:O(N*logN)。使用归并排序算法时,一趟归并需要将序列中的n个有序小序列进行两两归并,并且将结果存放到中间数组tmp[]中,这个操作需要扫描序列中的所有记录,因此耗费的时间为O(N)。而归并排序过程中的序列分组类似于一棵树,所以归并排序需要进行logN次。因为这两种操作是嵌套关系,所以归并排序算法的时间复杂度为O(N*logN)。
稳定性:归并排序是一种稳定的排序算法。
小结:
一般情况下,由于要求附加和待排记录等数量的辅助空间,因此很少利用二路归并排序进行内部排序,归并的思想主要用于外部排序。
六.非比较排序
计数排序是一个非比较排序算法,又称为鸽巢原理,是对哈希直接定址法的变形应用。其核心在于将输入的数值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
具体操作:
- 找出待排序数组中最大值max和最小值min,并新建一个长度为(range=max-min +1)的数组count;
- 统计待排序数组中每个值为i的元素出现的次数,并存入数组count的第i项;
- 根据每个值为i的元素出现的次数,将对应的元素回写到原数组。

实现:
void CountSort(int* a, int n)
{int min = a[0], max = a[0];//寻找数组中的最大值和最小值for (int i = 0; i < n; i++){if (a[i] < min){min = a[i];}if (a[i] > max){max = a[i];}}//开辟一个统计次数的数组int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){printf("malloc fail\n");exit(-1);}//将数组初始化为0memset(count, 0, sizeof(int) * range);//统计次数for (int i = 0; i < n; i++){count[a[i] - min]++;}//回写排序到原数组int j = 0;for (int i = 0; i < range; ++i){//出现几次就回写几个i+minwhile (count[i]--){a[j++] = i + min;}}
}运行结果:
![]()
局限性:
1.如果是浮点数,字符串,则不可以;
2.如果数据范围很大,空间复杂度就会很高,则相对不适合。比较适合范围集中,且重复数据多。
算法分析:
假设要对含有N个元素的数组进行排序,range为数组的最大值与最小值之差+1,count用于记录待排序数组中各个元素出现的次数。
空间复杂度:O(range)。计数排序只需要一个大小为range的辅助空间,用于统计各个元素所出现的次数。
时间复杂度:O(max(N,range))。当range <= N,也就是当待排序数组的元素较为集中时,对应的时间复杂度为O(N);当range > N,也就是当待排序数组的元素较为分散时,对应的时间复杂度为O(range)。
稳定性:稳定。计数排序并不会改变相同元素在待排序数组中的先后顺序,因为它不涉及元素间的交换。
相关文章:

数据结构初阶--排序
目录 一.排序的基本概念 1.1.什么是排序 1.2.排序算法的评价指标 1.3.排序的分类 二.插入排序 2.1.直接插入排序 2.2.希尔排序 三.选择排序 3.1.直接选择排序 3.2.堆排序 重建堆 建堆 排序 四.交换排序 4.1.冒泡排序 4.2.快速排序 快速排序的递归实现 法一&a…...

赴日IT 如何提高去日本做程序员的几率?
其实想去日本做IT工作只要满足学历、日语、技术三个必要条件,具备这些条件应聘就好,不具备条件你就想办法具备这些条件,在不具备条件之前不要轻易到日本去,日本IT行业虽然要求技术没有国内那么高,但也不是随便好进入的…...

c# 使用了 await、asnync task.run 三者结合使用
在 C# 异步编程中,await 和 async 关键字结合使用可以让你更方便地编写异步代码,而无需直接使用 Task.Run。然而,有时候你可能仍然需要使用 Task.Run 来在后台线程上执行某些工作,这取决于你的代码逻辑和需求。 await 和 async 关…...

C#获取屏幕缩放比例
现在1920x1080以上分辨率的高分屏电脑渐渐普及了。我们会在Windows的显示设置里看到缩放比例的设置。在Windows桌面客户端的开发中,有时会想要精确计算窗口的面积或位置。然而在默认情况下,无论WinForms的Screen.Bounds.Width属性还是WPF中SystemParamet…...

Rn实现省市区三级联动
省市区三级联动选择是个很频繁的需求,但是查看了市面上很多插件不是太老不维护就是不满足需求,就试着实现一个 这个功能无任何依赖插件 功能略简单,但能实现需求 核心代码也尽力控制在了60行左右 pca-code.json树型数据来源 Administrative-d…...

SpringCloud学习笔记(十)_SpringCloud监控
今天我们来学习一下actuator这个组件,它不是SpringCloud之后才有的,而是SpringBoot的一个starter,Spring Boot Actuator。我们使用SpringCloud的时候需要使用这个组件对应用程序进行监控与管理 在SpringBoot2.0版本中,actuator可以…...

测试理论与方法----测试流程的第二个环节:测试计划
二、软件测试分类与测试计划 1、软件测试的分类(理解掌握) 根绝需求规格说明书,在设计阶段会产出的两个文档: 概要设计(HLD):设计软件的结构,包含软件的组成,模块之间的层次关系,模块与模块之间的调用关系…...
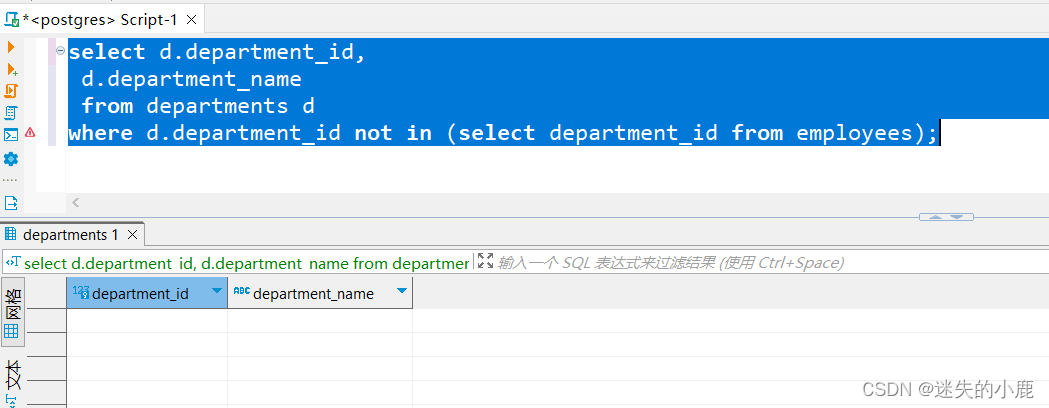
postgresql-子查询
postgresql-子查询 简介派生表IN 操作符ALL 操作符ANY 操作符关联子查询横向子查询EXISTS 操作符 简介 子查询(Subquery)是指嵌套在其他 SELECT、INSERT、UPDATE 以及 DELETE 语句中的 查询语句。 子查询的作用与多表连接查询有点类似,也是为…...

Linux 系统运维工具之 OpenLMI
一、前要 OpenLMI(全称 Open Linux Management Infrastructure)即开放式的 Linux 管理基础架构。OpenLMI 是一个开源项目,用于管理 Linux 系统管理的通用基础架构。它建立在现有工具基础上,充当抽象层,以便向系统管理…...
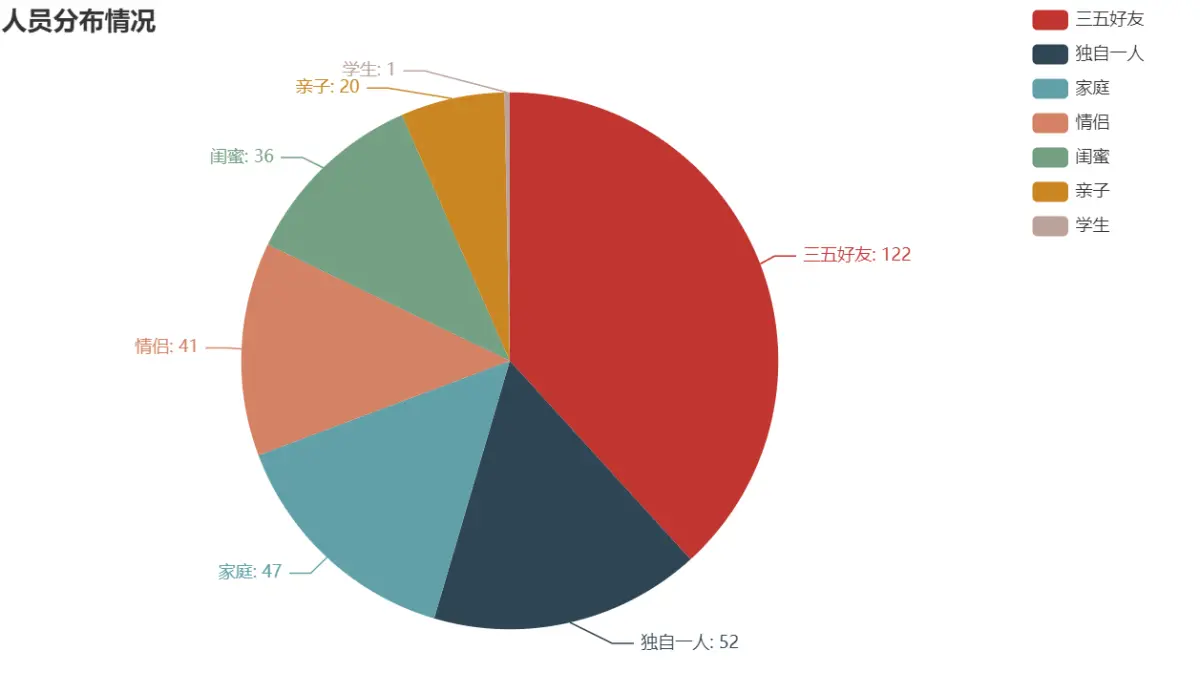
8天长假快来了,Python分析【去哪儿旅游攻略】数据,制作可视化图表
目录 前言环境使用模块使用数据来源分析 代码实现导入模块请求数据解析保存 数据可视化导入模块、数据年份分布情况月份分布情况出行时间情况费用分布情况人员分布情况 前言 2023年的中秋节和国庆节即将来临,好消息是,它们将连休8天!这个长假…...

【HSPCIE仿真】输入网表文件(5)基本仿真输出
仿真输出 1. 概述1.1 输出变量1.2 输出分析类型 2. 显示仿真结果2.1 .print语句基本语法示例 2.2 .probe 语句基本语法示例 2.3 子电路的输出2.4 打印控制选项.option probe.option post.option list.option ingold 2.5 .model_info打印模型参数 3. 仿真输出参数的选择3.1 直流…...
uni-app中使用iconfont彩色图标
uni-app中使用iconfont彩色图标 大家好,今天我们来学习一下uni-app中使用iconfont彩色图标,好好看,好好学,超详细的 第一步 首先,从iconfont官网(iconfont-阿里巴巴矢量图标库)选择自己需要的图…...
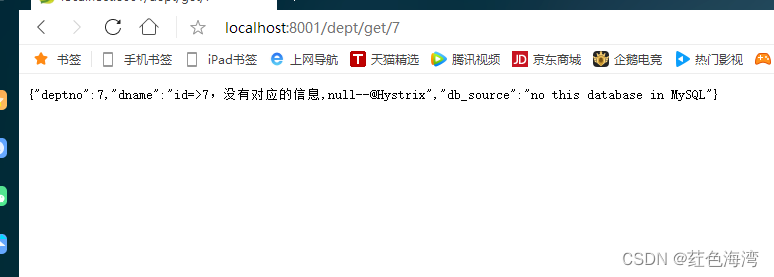
Hystrix: Dashboard流监控
接上两张服务熔断 开始搭建Dashboard流监控 pom依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocat…...

iconfont 图标在vue里的使用
刚好项目需要使用一个iconfont的图标,所以记录一下这个过程 1、iconfont-阿里巴巴矢量图标库 这个注册一个账号,以便后续使用下载代码时需要 2、寻找自己需要的图标 我主要是找两个图标 ,一个加号,一个减号,分别加入到…...
QT登陆注册界面练习
一、界面展示 二、主要功能界面代码 #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QMainWindow(parent), ui(new Ui::Widget) {ui->setupUi(this);this->setFixedSize(540,410); //设置固定尺寸th…...

MySQL DATE_SUB的实践
函数简介DATE_SUB()函数从DATE或DATETIME值中减去时间值(或间隔)。 下面说明了DATE_SUB()函数的语法: DATE_SUB(start_date,INTERVAL expr unit); DATE_SUB()函数接受两个参数: start_date是DATE或DATETIME的起始值。 expr是一个字符串,用于确…...

OpenCV最常用的50个函数
Python版:OpenCV提供了众多图像处理算子和函数,涵盖了各种任务和技术。以下是OpenCV中一些常用的50个算子和函数: cv2.imread:用于读取图像文件。cv2.imshow:用于显示图像。cv2.imwrite:用于保存图像。cv2…...
Android AGP8.1.0组件化初探
Android AGP8.1.0组件化初探 前言: 前面两篇完成了从AGP4.2到 AGP8.1.0的升级,本文是由于有哥们留言说在AGP8.0中使用ARouter组件化有问题,于是趁休息时间尝试了一下,写了几个demo,发现都没有问题,跳转和传…...
文件修改时间能改吗?怎么改?
文件修改时间能改吗?怎么改?修改时间是每个电脑文件具备的一个属性,它代表了这个电脑文件最后一次的修改时间,是电脑系统自动赋予文件的,相信大家都应该知道。我们右击鼠标某个文件,然后点击弹出菜单里面的…...

2023年下半年软考报名注意事项!
考试注意事项: 分数线:所有科目成绩全部在45分以上(含45分)通过考试;三科目的话,必须每科目都及格才算通过考试,只有一个不合格的,本次考试其他两个无效。 出成绩时间:预…...

Qwen3-Reranker-0.6B代码实例:异步批处理接口设计,支持千级Query/s吞吐
Qwen3-Reranker-0.6B代码实例:异步批处理接口设计,支持千级Query/s吞吐 1. 项目概述 Qwen3-Reranker-0.6B是一个专为RAG(检索增强生成)场景设计的语义重排序服务,基于通义千问的轻量级模型构建。这个项目最大的亮点在…...

ElastixAI 携 FPGA 方案打造新一代人工智能超级计算技术,打破神秘面纱
近年来,大模型训练几乎完全依赖 GPU,但随着生成式 AI 应用的爆发,一个新的问题逐渐显现:大模型推理(Inference)与 GPU 架构并不完全匹配。美国 AI 硬件初创公司 ElastixAI 提出了一种不同思路:利…...
)
MySQL 教程(超详细,零基础可学、第一篇)
目录 一、MySQL数据库概述 二、MySQL 连接 1、使用 MySQL 二进制方式连接 2、使用 PHP 脚本连接 MySQL 三、MySQL 创建数据库 1、使用 mysqladmin 创建数据库 2、使用 PHP脚本 创建数据库 四、MySQL 删除数据库 1、使用 mysqladmin 删除数据库 2、使用 PHP 脚本删除数…...

网络安全岗位薪水多少?
网络安全行业薪资一直备受关注,也是很多人入行的重要原因。其薪酬受城市、经验、岗位影响较大,整体高于普通IT岗位,那么网络安全薪水一般多少?以下是具体内容介绍。网络安全岗位的薪水跨度较大,具体区间如下:初级职位…...

2026国际国内大中型PLC行业市场分析
当前,中国大中型PLC市场正处于“外资主导”向“外资与国产并存”的结构性转折期。2025年市场规模已达95–100亿元,外资品牌仍占据约81%份额,但国产品牌加速突围。在国际供应链波动、国家自主可控政策加速落地、国产品牌技术成熟度提升三重因素…...

86745238
86745238...

AnOpc:轻松实现OPC操作的利器
AnOpc:轻松实现OPC操作的利器 【免费下载链接】AnOpc An Opc Library and a command line to perform OPC operations with ease and transparency among different protocols. Currently supports synchronous operation over UA and DA protocols. 项目地址: ht…...

如何快速设置theHarvester监控告警:关键信息发现通知完全指南
如何快速设置theHarvester监控告警:关键信息发现通知完全指南 【免费下载链接】theHarvester E-mails, subdomains and names Harvester - OSINT 项目地址: https://gitcode.com/GitHub_Trending/th/theHarvester theHarvester是一款强大的开源OSINT&#x…...

终极指南:Devbox环境变量加密方案——保护敏感信息的安全实践
终极指南:Devbox环境变量加密方案——保护敏感信息的安全实践 【免费下载链接】devbox Instant, easy, and predictable development environments 项目地址: https://gitcode.com/GitHub_Trending/dev/devbox 在现代软件开发中,保护敏感信息&…...

如何使用Yii 2框架构建高效微服务架构:完整拆分与集成指南
如何使用Yii 2框架构建高效微服务架构:完整拆分与集成指南 【免费下载链接】yii2 Yii 2: The Fast, Secure and Professional PHP Framework 项目地址: https://gitcode.com/gh_mirrors/yi/yii2 Yii 2是一个快速、安全且专业的PHP框架,它不仅适用…...