webassembly003 ggml GGML Tensor Library part-2 官方使用说明
- https://github.com/ggerganov/whisper.cpp/tree/1.0.3
GGML Tensor Library
-
官方有一个函数使用说明,但是从初始版本就没修改过 : https://github1s.com/ggerganov/ggml/blob/master/include/ggml/ggml.h#L3-L173
-
This documentation is still a work in progress. If you wish some specific topics to be covered, feel free to drop a comment:
https://github.com/ggerganov/whisper.cpp/issues/40
Overview
此库实现:
- 张量运算
- 自动微分
- 基本优化算法
这个库的目的是为各种机器学习任务提供一种最小化方法(a minimalistic approach for various machine learning tasks)。包括但不限于以下内容:
- 线性回归
- 支持向量机
- 神经网络
该库允许用户使用可用的张量运算来定义某个函数。该函数定义通过计算图在内部表示。函数定义中的每个张量运算都对应于图中的一个节点。定义了计算图后,用户可以选择计算函数的值和/或其相对于输入变量的梯度。更近一步,可以使用可用的优化算法之一来优化函数。
例如,在这里我们定义函数: f(x) = a*x^2 + b
{struct ggml_init_params params = {.mem_size = 16*1024*1024,.mem_buffer = NULL,};// memory allocation happens herestruct ggml_context * ctx = ggml_init(params);struct ggml_tensor * x = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);ggml_set_param(ctx, x); // x is an input variablestruct ggml_tensor * a = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);struct ggml_tensor * b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 1);struct ggml_tensor * x2 = ggml_mul(ctx, x, x);struct ggml_tensor * f = ggml_add(ctx, ggml_mul(ctx, a, x2), b);...}
请注意,上面的函数定义不涉及任何实际计算。只有当用户明确请求时才执行计算。例如,要计算x=2.0时的函数值:
{...struct ggml_cgraph gf = ggml_build_forward(f);// set the input variable and parameter valuesggml_set_f32(x, 2.0f);ggml_set_f32(a, 3.0f);ggml_set_f32(b, 4.0f);ggml_graph_compute_with_ctx(ctx, &gf, n_threads);printf("f = %f\n", ggml_get_f32_1d(f, 0));...}
实际计算是在ggml_graph_compute()函数中执行的。
-
The ggml_new_tensor_…() functions create new tensors. They are allocated in the memory buffer provided to the ggml_init() function. You have to be careful not to exceed the memory buffer size. Therefore, you have to know in advance how much memory you need for your computation. Alternatively, you can allocate a large enough memory and after defining the computation graph, call the ggml_used_mem() function to find out how much memory was actually needed.
-
The ggml_set_param() function marks a tensor as an input variable. This is used by the automatic differentiation and optimization algorithms.
-
所描述的方法允许定义函数图一次,然后多次计算其正向或反向图。所有计算都将使用在ggml_init()函数中分配的相同内存缓冲区。通过这种方式,用户可以避免运行时的内存分配开销。
-
该库支持多维张量-最多4个维度。FP16和FP32数据类型是一类公民(The FP16 and FP32 data types are first class citizens),但理论上,该库可以扩展为支持FP8和整数数据类型。
-
每个张量运算(tensor operation)产生一个新的张量。最初,该库被设想为只支持使用一元和二元运算。大多数可用的操作属于这两类中的一类。随着时间的推移,很明显,库需要支持更复杂的操作。支持这些行动的方法尚不清楚,但以下行动中展示了几个例子:
- ggml_permute()
- ggml_conv_1d_1s()
- ggml_conv_1d_2s()
-
For each tensor operator, the library implements a forward and backward computation function. The forward function computes the output tensor value given the input tensor values. The backward function computes the adjoint of the input tensors given the adjoint of the output tensor. For a detailed explanation of what this means, take a calculus class, or watch the following video:
What is Automatic Differentiation?
https://www.youtube.com/watch?v=wG_nF1awSSY
Tensor data (struct ggml_tensor)
张量通过ggml_tensor结构存储在内存中。该结构提供关于张量的大小、数据类型以及存储张量数据的存储器缓冲区的信息。此外,它还包含指向“源”张量的指针,即用于计算当前张量的张量。例如:
{struct ggml_tensor * c = ggml_add(ctx, a, b);assert(c->src[0] == a);assert(c->src[1] == b);}
多维张量按行主顺序存储。ggml_tensor结构包含每个维度中元素数(“ne”)和字节数(“nb”,又称步幅)的字段。这允许在存储器中存储不连续的张量,这对于诸如换位和置换之类的操作是有用的。所有张量运算都必须考虑步长,而不是假设张量在内存中是连续的。

- nb[i] 表示在第i纬度移动的步幅
The data of the tensor is accessed via the “data” pointer. For example:
{const int nx = 2;const int ny = 3;struct ggml_tensor * a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, nx, ny);for (int y = 0; y < ny; y++) {for (int x = 0; x < nx; x++) {*(float *) ((char *) a->data + y*a->nb[1] + x*a->nb[0]) = x + y;}}...}
或者,也可以使用一些辅助函数,例如ggml_get_f32_1d() , ggml_set_f32_1d() .
TODO
The matrix multiplication operator (ggml_mul_mat)
TODO
Multi-threading
TODO
Overview of ggml.c
TODO
SIMD optimizations
TODO
Debugging ggml
TODO
example 最小执行demo
76
├── CMakeLists.txt https://github1s.com/ggerganov/whisper.cpp/blob/1.0.3/CMakeLists.txt
├── ggml.c https://github1s.com/ggerganov/whisper.cpp/blob/1.0.3/ggml.c
├── ggml.h https://github1s.com/ggerganov/whisper.cpp/blob/1.0.3/ggml.h
└── main.cpp
CMakeLists.txt
cmake_minimum_required (VERSION 3.0)
project(76 VERSION 1.0.3)set(CMAKE_EXPORT_COMPILE_COMMANDS "on")
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/bin)
set(CMAKE_INSTALL_RPATH "${CMAKE_INSTALL_PREFIX}/lib")if(CMAKE_SOURCE_DIR STREQUAL CMAKE_CURRENT_SOURCE_DIR)set(WHISPER_STANDALONE ON)
# include(cmake/GitVars.cmake)
# include(cmake/BuildTypes.cmake)# # configure project version
# if (EXISTS "${CMAKE_SOURCE_DIR}/bindings/ios/Makefile-tmpl")
# configure_file(${CMAKE_SOURCE_DIR}/bindings/ios/Makefile-tmpl ${CMAKE_SOURCE_DIR}/bindings/ios/Makefile @ONLY)
# endif()
# configure_file(${CMAKE_SOURCE_DIR}/bindings/javascript/package-tmpl.json ${CMAKE_SOURCE_DIR}/bindings/javascript/package.json @ONLY)
else()set(WHISPER_STANDALONE OFF)
endif()if (EMSCRIPTEN)set(BUILD_SHARED_LIBS_DEFAULT OFF)option(WHISPER_WASM_SINGLE_FILE "whisper: embed WASM inside the generated whisper.js" ON)
else()if (MINGW)set(BUILD_SHARED_LIBS_DEFAULT OFF)else()set(BUILD_SHARED_LIBS_DEFAULT ON)endif()
endif()# optionsoption(BUILD_SHARED_LIBS "whisper: build shared libs" ${BUILD_SHARED_LIBS_DEFAULT})option(WHISPER_ALL_WARNINGS "whisper: enable all compiler warnings" ON)
option(WHISPER_ALL_WARNINGS_3RD_PARTY "whisper: enable all compiler warnings in 3rd party libs" OFF)option(WHISPER_SANITIZE_THREAD "whisper: enable thread sanitizer" OFF)
option(WHISPER_SANITIZE_ADDRESS "whisper: enable address sanitizer" OFF)
option(WHISPER_SANITIZE_UNDEFINED "whisper: enable undefined sanitizer" OFF)option(WHISPER_BUILD_TESTS "whisper: build tests" ${WHISPER_STANDALONE})
option(WHISPER_BUILD_EXAMPLES "whisper: build examples" ${WHISPER_STANDALONE})option(WHISPER_SUPPORT_SDL2 "whisper: support for libSDL2" OFF)if (APPLE)option(WHISPER_NO_ACCELERATE "whisper: disable Accelerate framework" OFF)option(WHISPER_NO_AVX "whisper: disable AVX" OFF)option(WHISPER_NO_AVX2 "whisper: disable AVX2" OFF)
else()option(WHISPER_SUPPORT_OPENBLAS "whisper: support for OpenBLAS" OFF)
endif()option(WHISPER_PERF "whisper: enable perf timings" OFF)# sanitizersif (NOT MSVC)if (WHISPER_SANITIZE_THREAD)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=thread")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=thread")endif()if (WHISPER_SANITIZE_ADDRESS)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=address -fno-omit-frame-pointer")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fno-omit-frame-pointer")endif()if (WHISPER_SANITIZE_UNDEFINED)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fsanitize=undefined")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=undefined")endif()
endif()#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -ffast-math")
#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -march=native")# dependenciesset(CMAKE_C_STANDARD 11)
set(CMAKE_CXX_STANDARD 11)find_package(Threads REQUIRED)# on APPLE - include Accelerate framework
if (APPLE AND NOT WHISPER_NO_ACCELERATE)find_library(ACCELERATE_FRAMEWORK Accelerate)if (ACCELERATE_FRAMEWORK)message(STATUS "Accelerate framework found")set(WHISPER_EXTRA_LIBS ${WHISPER_EXTRA_LIBS} ${ACCELERATE_FRAMEWORK})set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_USE_ACCELERATE)else()message(WARNING "Accelerate framework not found")endif()
endif()if (WHISPER_SUPPORT_OPENBLAS)find_library(OPENBLAS_LIBNAMES openblas libopenblas)if (OPENBLAS_LIB)message(STATUS "OpenBLAS found")set(WHISPER_EXTRA_LIBS ${WHISPER_EXTRA_LIBS} ${OPENBLAS_LIB})set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_USE_OPENBLAS)else()message(WARNING "OpenBLAS not found")endif()
endif()# compiler flagsif (NOT CMAKE_BUILD_TYPE AND NOT CMAKE_CONFIGURATION_TYPES)set(CMAKE_BUILD_TYPE Release CACHE STRING "Build type" FORCE)set_property(CACHE CMAKE_BUILD_TYPE PROPERTY STRINGS "Debug" "Release" "RelWithDebInfo")
endif ()if (WHISPER_ALL_WARNINGS)if (NOT MSVC)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} \-Wall \-Wextra \-Wpedantic \-Wshadow \-Wcast-qual \-Wstrict-prototypes \-Wpointer-arith \")else()# todo : msvcendif()
endif()if (NOT MSVC)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Werror=vla")#set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fno-math-errno -ffinite-math-only -funsafe-math-optimizations")
endif()message(STATUS "CMAKE_SYSTEM_PROCESSOR: ${CMAKE_SYSTEM_PROCESSOR}")if (${CMAKE_SYSTEM_PROCESSOR} MATCHES "arm" OR ${CMAKE_SYSTEM_PROCESSOR} MATCHES "aarch64")message(STATUS "ARM detected")
else()message(STATUS "x86 detected")if (MSVC)set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /arch:AVX2")set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /arch:AVX2")else()if (EMSCRIPTEN)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -pthread")set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pthread")else()if(NOT WHISPER_NO_AVX)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx")endif()if(NOT WHISPER_NO_AVX2)set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mavx2")endif()set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -mfma -mf16c")endif()endif()
endif()if (WHISPER_PERF)set(WHISPER_EXTRA_FLAGS ${WHISPER_EXTRA_FLAGS} -DGGML_PERF)
endif()#
# whisper - this is the main library of the project
#set(TARGET 76)add_library(GGML ggml.c )
add_executable(76 main.cpp)
target_link_libraries(${TARGET} GGML)
Forward && Backward
#include "ggml.h"
#include <stdio.h>
#include <stdlib.h>int main(int argc, const char ** argv) {const int n_threads = 2;struct ggml_init_params params = {.mem_size = 128*1024*1024,.mem_buffer = NULL,
// .no_alloc = false,};struct ggml_context * ctx0 = ggml_init(params);{struct ggml_tensor * x = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);ggml_set_param(ctx0, x);struct ggml_tensor * a = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);struct ggml_tensor * b = ggml_mul(ctx0, x, x);struct ggml_tensor * f = ggml_mul(ctx0, b, a);// a*x^2// 2*a*xggml_print_objects(ctx0);struct ggml_cgraph gf = ggml_build_forward(f);struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);ggml_set_f32(x, 2.0f);ggml_set_f32(a, 3.0f);// FORWARDggml_graph_compute(ctx0, &gf);printf("f = %f\n", ggml_get_f32_1d(f, 0));// FORWARD + BACKWARDggml_graph_reset(&gf);ggml_set_f32(f->grad, 1.0f);ggml_graph_compute(ctx0, &gb);printf("f = %f\n", ggml_get_f32_1d(f, 0));printf("df/dx = %f\n", ggml_get_f32_1d(x->grad, 0));// SAVE GRAPHggml_graph_dump_dot(&gf, NULL, "test1-1-forward.dot");ggml_graph_dump_dot(&gb, &gf, "test1-1-backward.dot");}return 0;
}
OUTPUT
ggml_print_objects: objects in context 0x560856e9d2a8:- ggml_object: offset = 32, size = 176, next = 0x7f888aa7f0e0- ggml_object: offset = 240, size = 176, next = 0x7f888aa7f1b0- ggml_object: offset = 448, size = 176, next = 0x7f888aa7f280- ggml_object: offset = 656, size = 176, next = 0x7f888aa7f350- ggml_object: offset = 864, size = 176, next = 0x7f888aa7f420- ggml_object: offset = 1072, size = 176, next = 0x7f888aa7f4f0- ggml_object: offset = 1280, size = 176, next = (nil)
ggml_print_objects: --- end ---
f = 12.000000
f = 12.000000
df/dx = 12.000000
f = 27.000000
df/dx = 18.000000
ggml_graph_dump_dot: dot -Tpng test1-1-forward.dot -o test1-1-forward.dot.png && open test1-1-forward.dot.png
ggml_graph_dump_dot: dot -Tpng test1-1-backward.dot -o test1-1-backward.dot.png && open test1-1-backward.dot.pngProcess finished with exit code 0
Vector Example
#include "ggml.h"
#include <stdio.h>
#include <cstring>int main(int argc, const char ** argv) {const int n_threads = 2;struct ggml_init_params params = {.mem_size = 128*1024*1024,.mem_buffer = NULL,};struct ggml_context * ctx0 = ggml_init(params);{struct ggml_tensor * x = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 5);ggml_set_param(ctx0, x);struct ggml_tensor * a = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 5);struct ggml_tensor * b = ggml_mul(ctx0, x, x);struct ggml_tensor * f = ggml_mul(ctx0, b, a);// a*x^2ggml_print_objects(ctx0);struct ggml_cgraph gf = ggml_build_forward(f);struct ggml_cgraph gb = ggml_build_backward(ctx0, &gf, false);std::vector<float> digit={1,2,3,4,5};memcpy(x->data, digit.data(), ggml_nbytes(x));
// ggml_set_f32(x, 2.0f);ggml_set_f32(a, 3.0f);// FORWARDggml_graph_compute(ctx0, &gf);printf("f = %f\n", ggml_get_f32_1d(f, 0));printf("f = %f\n", ggml_get_f32_1d(f, 1));printf("f = %f\n", ggml_get_f32_1d(f, 2));printf("f = %f\n", ggml_get_f32_1d(f, 3));printf("f = %f\n", ggml_get_f32_1d(f, 4));}return 0;
}
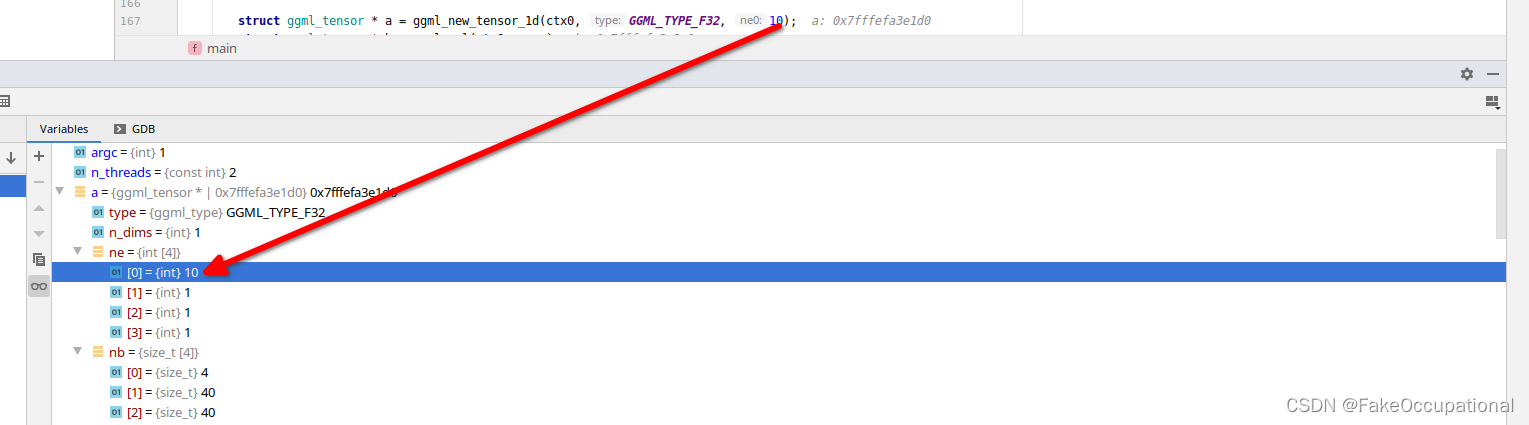
Compute Graph
- 只有在这个过程才执行真正的计算,之前都是在构建树,遍历树
构建计算图的语句 struct ggml_cgraph gf = ggml_build_forward(f);
计算图的定义及地址
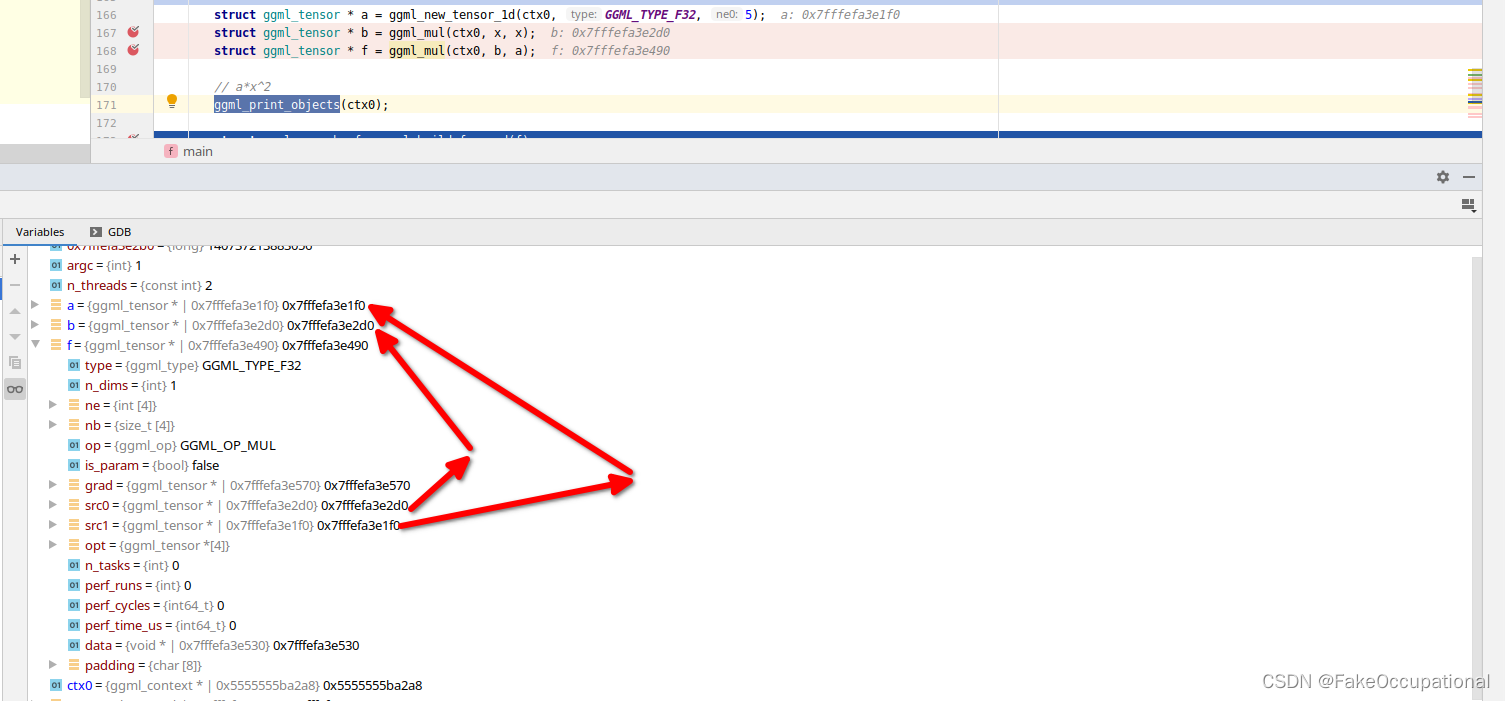
构建过程 ggml_build_forward
struct ggml_cgraph ggml_build_forward(struct ggml_tensor * tensor) {struct ggml_cgraph result = {/*.n_nodes =*/ 0,/*.n_leafs =*/ 0,/*.n_threads =*/ 0,/*.work_size =*/ 0,/*.work =*/ NULL,/*.nodes =*/ { NULL },/*.grads =*/ { NULL },/*.leafs =*/ { NULL },/*.perf_runs =*/ 0,/*.perf_cycles =*/ 0,/*.perf_time_us =*/ 0,};ggml_build_forward_impl(&result, tensor, false);return result;
}
void ggml_build_forward_impl(struct ggml_cgraph * cgraph, struct ggml_tensor * tensor, bool expand) {if (!expand) {cgraph->n_nodes = 0;cgraph->n_leafs = 0;}const int n0 = cgraph->n_nodes;UNUSED(n0);ggml_visit_parents(cgraph, tensor);// 函数会递归地遍历节点的src0、src1和opt数组中的节点,并将它们添加到计算图中。这样可以确保所有的父节点都会被添加到计算图中。最后,函数会根据节点的op和grad属性来判断节点的类型。如果op为GGML_OP_NONE且grad为NULL,则说明该节点是一个叶子节点,不是梯度图的一部分(例如常量节点)。此时,函数会将该节点添加到计算图的leafs数组中。否则,函数会将该节点添加到计算图的nodes数组中,并将其grad属性添加到计算图的grads数组中。const int n_new = cgraph->n_nodes - n0;GGML_PRINT_DEBUG("%s: visited %d new nodes\n", __func__, n_new);if (n_new > 0) {// the last added node should always be starting pointassert(cgraph->nodes[cgraph->n_nodes - 1] == tensor);}
}
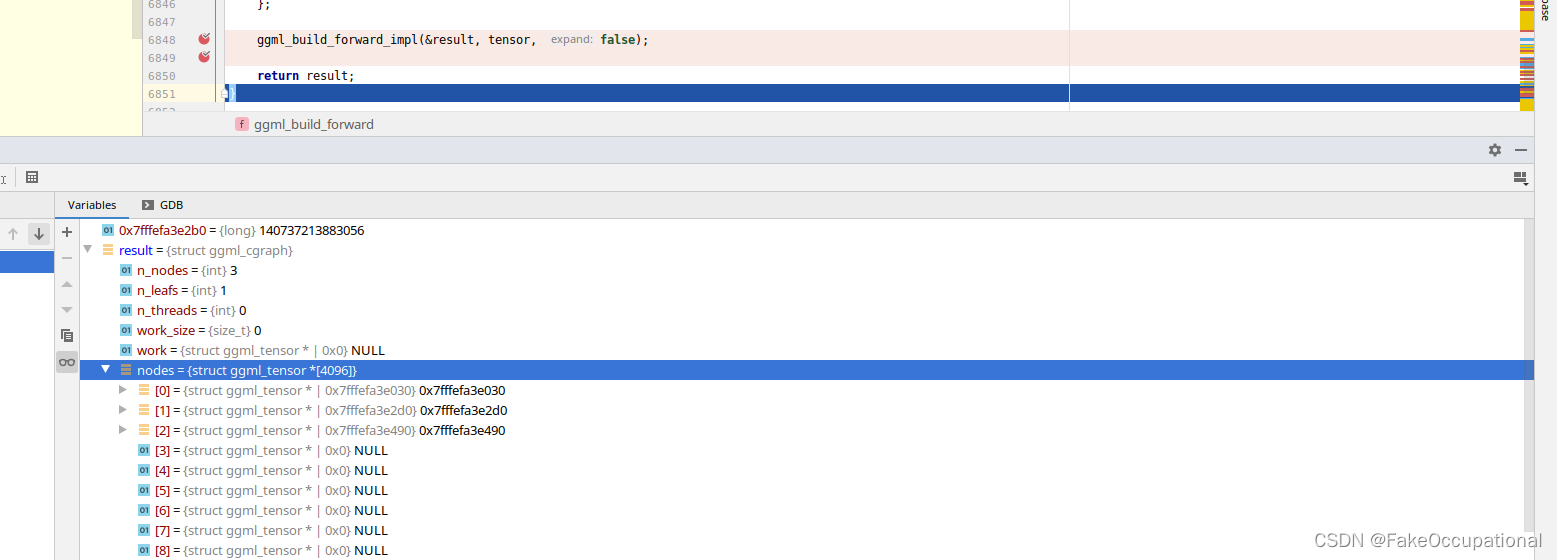
计算过程 ggml_graph_compute
void ggml_graph_compute(struct ggml_context * ctx, struct ggml_cgraph * cgraph) {if (cgraph->n_threads <= 0) {cgraph->n_threads = 8;}const int n_threads = cgraph->n_threads;struct ggml_compute_state_shared state_shared = {/*.spin =*/ GGML_LOCK_INITIALIZER,/*.n_threads =*/ n_threads,/*.n_ready =*/ 0,/*.has_work =*/ false,/*.stop =*/ false,};struct ggml_compute_state * workers = n_threads > 1 ? alloca(sizeof(struct ggml_compute_state)*(n_threads - 1)) : NULL;
create thread pool
在程序启动时创建一定数量的线程,然后将待处理的任务分配给这些线程进行执行。线程池能够在任务到达时立即执行,节省了线程创建和销毁的开销。
// create thread poolif (n_threads > 1) {ggml_lock_init(&state_shared.spin);atomic_store(&state_shared.has_work, true); // 将true存储到state_shared.has_work位置,并确保该操作是原子的//创建了n_threads-1个线程for (int j = 0; j < n_threads - 1; j++) {workers[j] = (struct ggml_compute_state) {.thrd = 0,.params = {.type = GGML_TASK_COMPUTE,.ith = j + 1,.nth = n_threads,.wsize = cgraph->work ? ggml_nbytes(cgraph->work) : 0,.wdata = cgraph->work ? cgraph->work->data : NULL,},.node = NULL,.shared = &state_shared,};int rc = pthread_create(&workers[j].thrd, NULL, ggml_graph_compute_thread, &workers[j]);// 创建一个线程。// ggml_graph_compute_thread是一个函数指针,指向要在新创建的线程中执行的函数。assert(rc == 0);UNUSED(rc);// 使用`UNUSED(rc)`来消除编译器的未使用变量警告。}}
initialize tasks + work buffer
这段代码的作用是初始化任务和工作缓冲区。它首先遍历计算图中的每个节点,并根据节点的操作类型分配任务数量。然后根据节点类型确定工作缓冲区的大小,并分配相应大小的内存空间。
具体地,对于每个节点,根据其操作类型,分配相应数量的任务。例如,对于GGML_OP_NONE,GGML_OP_MUL操作,分配1个任务;对于GGML_OP_ADD操作,分配n_threads个任务(与线程数相同)。
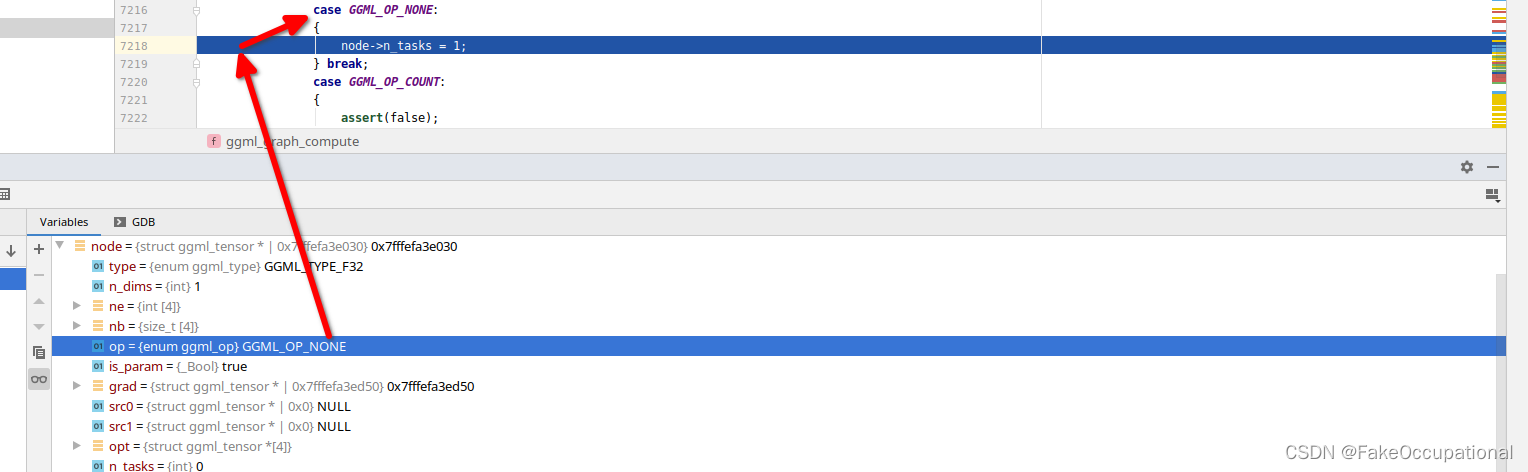
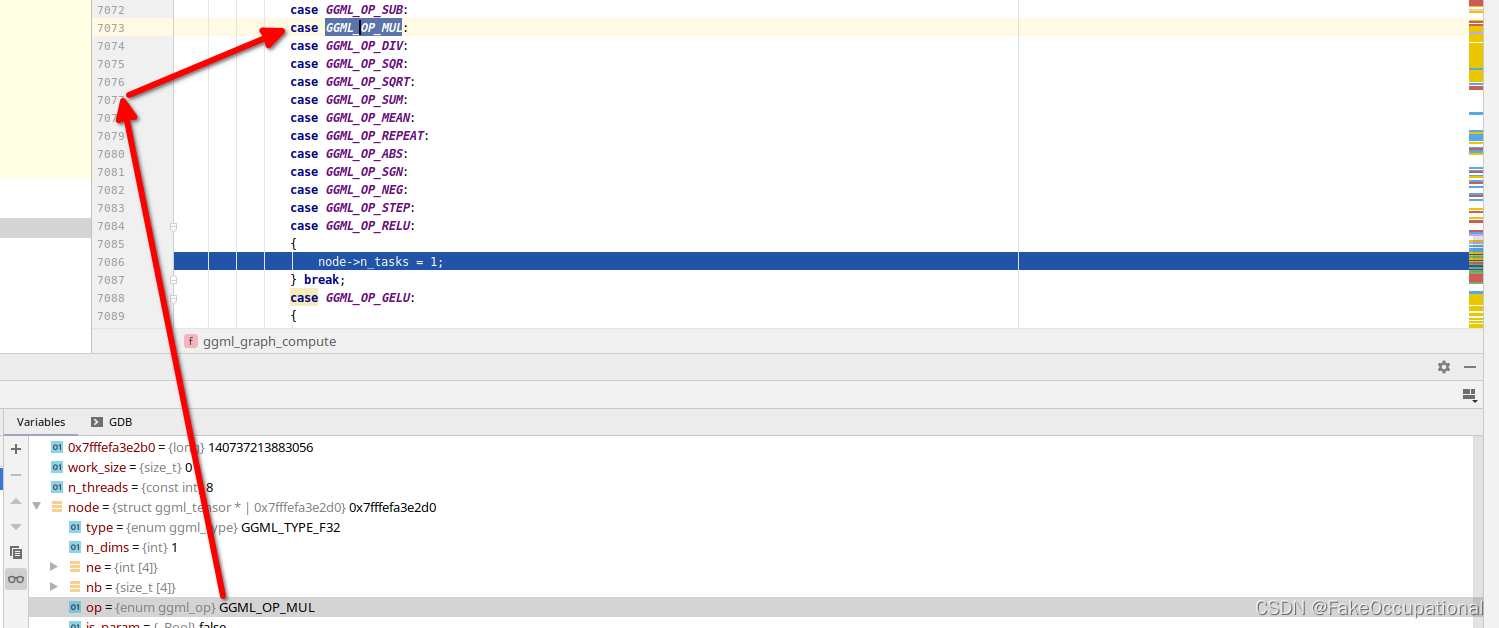
在分配任务数量时,还会计算工作缓冲区的大小。例如,对于GGML_OP_MUL_MAT操作,根据矩阵的大小和是否转置等因素确定任务数量,并更新工作缓冲区的大小。最后,根据工作缓冲区的大小,如果需要分配内存空间并且当前未分配,则分配相应大小的内存空间。
但是本例的node->n_tasks > 1都为false,直接运行ggml_compute_forward即可。
// initialize tasks + work buffer{size_t work_size = 0;// thread scheduling for the different operationsfor (int i = 0; i < cgraph->n_nodes; i++) {struct ggml_tensor * node = cgraph->nodes[i];switch (node->op) {case GGML_OP_DUP:{node->n_tasks = 1;} break;case GGML_OP_ADD:{node->n_tasks = n_threads;} break;case GGML_OP_SUB:case GGML_OP_MUL:case GGML_OP_DIV:case GGML_OP_SQR:case GGML_OP_SQRT:case GGML_OP_SUM:case GGML_OP_MEAN:case GGML_OP_REPEAT:case GGML_OP_ABS:case GGML_OP_SGN:case GGML_OP_NEG:case GGML_OP_STEP:case GGML_OP_RELU:{node->n_tasks = 1;} break;case GGML_OP_GELU:{node->n_tasks = n_threads;} break;case GGML_OP_NORM:{node->n_tasks = n_threads;} break;case GGML_OP_MUL_MAT:{// TODO: use different scheduling for different matrix sizesnode->n_tasks = n_threads;size_t cur = 0;// TODO: better way to determine if the matrix is transposedif (node->src0->nb[1] < node->src0->nb[0]) {cur = ggml_nbytes(node)*node->n_tasks; // TODO: this can become (n_tasks-1)} else {if (node->src0->type == GGML_TYPE_F16 &&node->src1->type == GGML_TYPE_F32) {
#if defined(GGML_USE_ACCELERATE) || defined(GGML_USE_OPENBLAS)if (ggml_compute_forward_mul_mat_use_blas(node->src0, node->src1, node)) {cur = sizeof(float)*(node->src0->ne[0]*node->src0->ne[1]);} else {cur = sizeof(ggml_fp16_t)*ggml_nelements(node->src1);}
#elsecur = sizeof(ggml_fp16_t)*ggml_nelements(node->src1);
#endif} else if (node->src0->type == GGML_TYPE_F32 &&node->src1->type == GGML_TYPE_F32) {cur = 0;} else {GGML_ASSERT(false);}}work_size = MAX(work_size, cur);} break;case GGML_OP_SCALE:{node->n_tasks = n_threads;} break;case GGML_OP_CPY:case GGML_OP_RESHAPE:case GGML_OP_VIEW:case GGML_OP_PERMUTE:case GGML_OP_TRANSPOSE:case GGML_OP_GET_ROWS:case GGML_OP_DIAG_MASK_INF:{node->n_tasks = 1;} break;case GGML_OP_SOFT_MAX:{node->n_tasks = n_threads;} break;case GGML_OP_ROPE:{node->n_tasks = 1;} break;case GGML_OP_CONV_1D_1S:case GGML_OP_CONV_1D_2S:{node->n_tasks = n_threads;GGML_ASSERT(node->src0->ne[3] == 1);GGML_ASSERT(node->src1->ne[2] == 1);GGML_ASSERT(node->src1->ne[3] == 1);size_t cur = 0;const int nk = node->src0->ne[0];if (node->src0->type == GGML_TYPE_F16 &&node->src1->type == GGML_TYPE_F32) {cur = sizeof(ggml_fp16_t)*(nk*ggml_up32(node->src0->ne[1])*node->src0->ne[2] +( 2*(nk/2) + node->src1->ne[0])*node->src1->ne[1]);} else if (node->src0->type == GGML_TYPE_F32 &&node->src1->type == GGML_TYPE_F32) {cur = sizeof(float)*(nk*ggml_up32(node->src0->ne[1])*node->src0->ne[2] +( 2*(nk/2) + node->src1->ne[0])*node->src1->ne[1]);} else {GGML_ASSERT(false);}work_size = MAX(work_size, cur);} break;case GGML_OP_FLASH_ATTN:{node->n_tasks = n_threads;size_t cur = 0;if (node->src1->type == GGML_TYPE_F32) {cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2}if (node->src1->type == GGML_TYPE_F16) {cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2}work_size = MAX(work_size, cur);} break;case GGML_OP_FLASH_FF:{node->n_tasks = n_threads;size_t cur = 0;if (node->src1->type == GGML_TYPE_F32) {cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2}if (node->src1->type == GGML_TYPE_F16) {cur = sizeof(float)*node->src1->ne[1]*node->n_tasks; // TODO: this can become (n_tasks-1)cur += sizeof(float)*node->src1->ne[1]*node->n_tasks; // this is overestimated by x2}work_size = MAX(work_size, cur);} break;case GGML_OP_NONE:{node->n_tasks = 1;} break;case GGML_OP_COUNT:{assert(false);} break;};}if (cgraph->work != NULL && work_size > cgraph->work_size) {assert(false); // TODO: better handling}if (work_size > 0 && cgraph->work == NULL) {cgraph->work_size = work_size + CACHE_LINE_SIZE*(n_threads - 1);GGML_PRINT_DEBUG("%s: allocating work buffer for graph (%zu bytes)\n", __func__, cgraph->work_size);cgraph->work = ggml_new_tensor_1d(ctx, GGML_TYPE_I8, cgraph->work_size);}}
const int64_t perf_start_cycles = ggml_perf_cycles(); #计时用const int64_t perf_start_time_us = ggml_perf_time_us();#计时用for (int i = 0; i < cgraph->n_nodes; i++) {GGML_PRINT_DEBUG_5("%s: %d/%d\n", __func__, i, cgraph->n_nodes);struct ggml_tensor * node = cgraph->nodes[i];// TODO: this could be used to avoid unnecessary computations, but it needs to be improved//if (node->grad == NULL && node->perf_runs > 0) {// continue;//}const int64_t perf_node_start_cycles = ggml_perf_cycles();const int64_t perf_node_start_time_us = ggml_perf_time_us();
INIT
// INITstruct ggml_compute_params params = {/*.type =*/ GGML_TASK_INIT,/*.ith =*/ 0,/*.nth =*/ node->n_tasks,/*.wsize =*/ cgraph->work ? ggml_nbytes(cgraph->work) : 0,/*.wdata =*/ cgraph->work ? cgraph->work->data : NULL,};ggml_compute_forward(¶ms, node);
COMPUTE
// COMPUTEif (node->n_tasks > 1) {if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {atomic_store(&state_shared.has_work, false);}while (atomic_load(&state_shared.has_work)) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}// launch thread poolfor (int j = 0; j < n_threads - 1; j++) {workers[j].params = (struct ggml_compute_params) {.type = GGML_TASK_COMPUTE,.ith = j + 1,.nth = n_threads,.wsize = cgraph->work ? ggml_nbytes(cgraph->work) : 0,.wdata = cgraph->work ? cgraph->work->data : NULL,};workers[j].node = node;}atomic_fetch_sub(&state_shared.n_ready, 1);while (atomic_load(&state_shared.n_ready) > 0) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}atomic_store(&state_shared.has_work, true);}params.type = GGML_TASK_COMPUTE;ggml_compute_forward(¶ms, node);// wait for thread poolif (node->n_tasks > 1) {if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {atomic_store(&state_shared.has_work, false);}while (atomic_load(&state_shared.has_work)) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}atomic_fetch_sub(&state_shared.n_ready, 1);while (atomic_load(&state_shared.n_ready) != 0) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}}
FINALIZE
// FINALIZEif (node->n_tasks > 1) {if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {atomic_store(&state_shared.has_work, false);}while (atomic_load(&state_shared.has_work)) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}// launch thread poolfor (int j = 0; j < n_threads - 1; j++) {workers[j].params = (struct ggml_compute_params) {.type = GGML_TASK_FINALIZE,.ith = j + 1,.nth = n_threads,.wsize = cgraph->work ? ggml_nbytes(cgraph->work) : 0,.wdata = cgraph->work ? cgraph->work->data : NULL,};workers[j].node = node;}atomic_fetch_sub(&state_shared.n_ready, 1);while (atomic_load(&state_shared.n_ready) > 0) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}atomic_store(&state_shared.has_work, true);}params.type = GGML_TASK_FINALIZE;ggml_compute_forward(¶ms, node);// wait for thread poolif (node->n_tasks > 1) {if (atomic_fetch_add(&state_shared.n_ready, 1) == n_threads - 1) {atomic_store(&state_shared.has_work, false);}while (atomic_load(&state_shared.has_work)) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}atomic_fetch_sub(&state_shared.n_ready, 1);while (atomic_load(&state_shared.n_ready) != 0) {ggml_lock_lock (&state_shared.spin);ggml_lock_unlock(&state_shared.spin);}}// performance stats (node){int64_t perf_cycles_cur = ggml_perf_cycles() - perf_node_start_cycles;int64_t perf_time_us_cur = ggml_perf_time_us() - perf_node_start_time_us;node->perf_runs++;node->perf_cycles += perf_cycles_cur;node->perf_time_us += perf_time_us_cur;}}
join thread pool
// join thread poolif (n_threads > 1) {atomic_store(&state_shared.stop, true);atomic_store(&state_shared.has_work, true);for (int j = 0; j < n_threads - 1; j++) {int rc = pthread_join(workers[j].thrd, NULL);assert(rc == 0);UNUSED(rc);}ggml_lock_destroy(&state_shared.spin);}// performance stats (graph){int64_t perf_cycles_cur = ggml_perf_cycles() - perf_start_cycles;int64_t perf_time_us_cur = ggml_perf_time_us() - perf_start_time_us;cgraph->perf_runs++;cgraph->perf_cycles += perf_cycles_cur;cgraph->perf_time_us += perf_time_us_cur;GGML_PRINT_DEBUG("%s: perf (%d) - cpu = %.3f / %.3f ms, wall = %.3f / %.3f ms\n",__func__, cgraph->perf_runs,(double) perf_cycles_cur / (double) ggml_cycles_per_ms(),(double) cgraph->perf_cycles / (double) ggml_cycles_per_ms() / (double) cgraph->perf_runs,(double) perf_time_us_cur / 1000.0,(double) cgraph->perf_time_us / 1000.0 / cgraph->perf_runs);}
}
相关文章:
webassembly003 ggml GGML Tensor Library part-2 官方使用说明
https://github.com/ggerganov/whisper.cpp/tree/1.0.3 GGML Tensor Library 官方有一个函数使用说明,但是从初始版本就没修改过 : https://github1s.com/ggerganov/ggml/blob/master/include/ggml/ggml.h#L3-L173 This documentation is still a work in progres…...

ES主集群的优化参考点
因为流量比较大, 导致ES线程数飙高,cpu直往上窜,查询耗时增加,并传导给所有调用方,导致更大范围的延时。如何解决这个问题呢? ES负载不合理,热点问题严重。ES主集群一共有几十个节点࿰…...

全国范围内-二手房小区数据-2023-8月更新
收录融合去重多个平台数据:80万,仅供数字参考 数据纬度字段名注释枚举值基础信息id主键id:名称城市来源生成 md5值00001073838501125ec4473463ead9ccname名称瑞祥安文创园address地址(朝阳)双桥路东柳村口南口lng经度116.581903lat纬度39.89…...

第4章 循环变换
4.1 适配体系结构特征的关键技术 由于高级语言隐藏了底层硬件体系结构的大量细节,如果不经过优化直接将高级程序设计语言编写的程序部署在底层硬件上,往往无法充分利用底层硬件体系结构的处理能力。 算子融合不仅可以提…...

spring cloud使用git作为配置中心,git开启了双因子认证,如何写本地配置文件
问题 spring cloud使用git作为配置中心,git开启了双因子认证,死活认证不成功!!!!! 报错关键字 org.eclipse.jgit.api.errors.TransportException: https://git.qualink.com/zhaoxin15/sc-confi…...
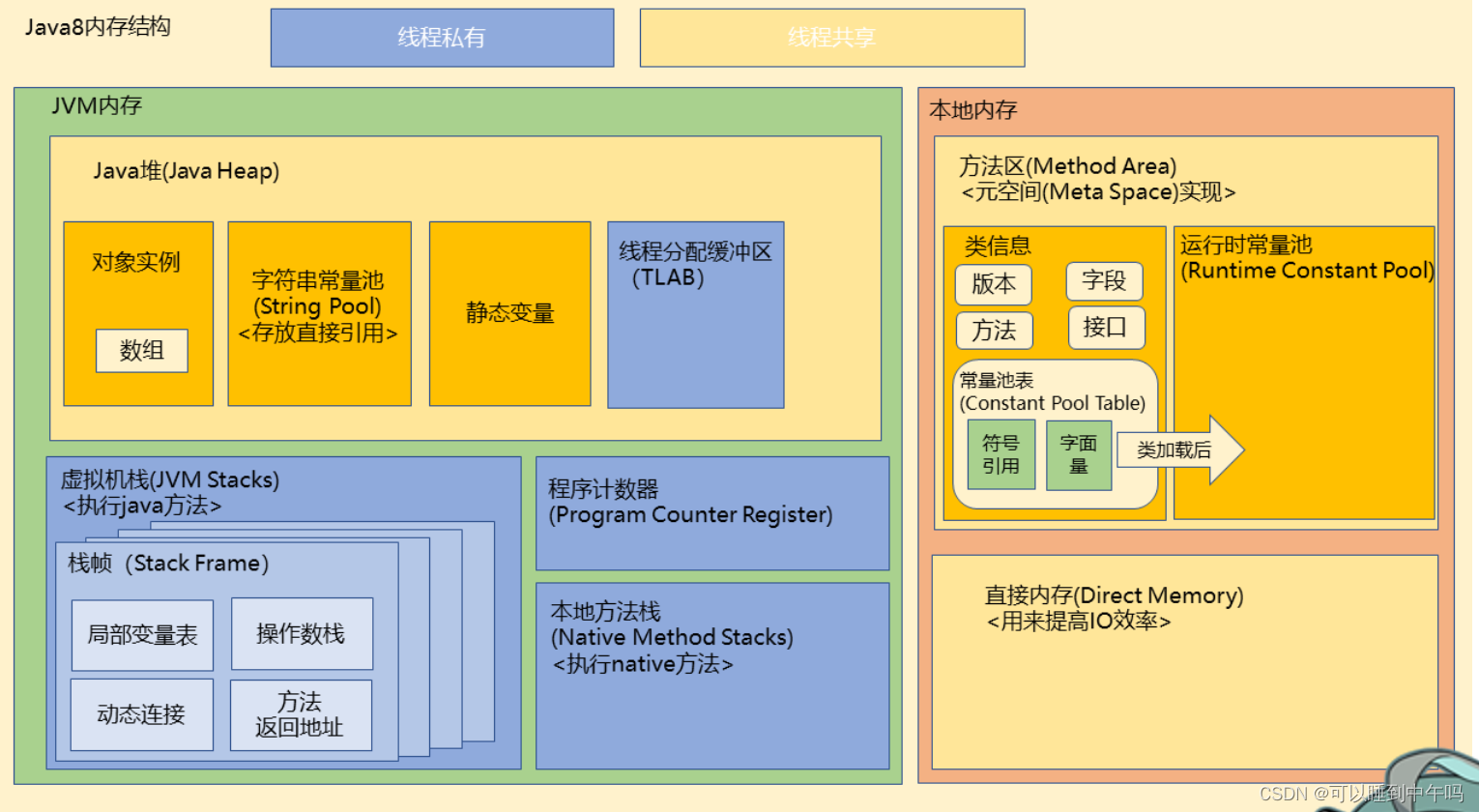
JVM内存管理、内存分区:堆、方法区、虚拟机栈、本地方法栈、程序计数器
内存管理 内存分区 线程共享 堆 存放实例,字符串常量(直接引用),静态变量,线程分配缓冲区(TLAB线程私有)。垃圾收集器管理的区域 方法区 非堆,和堆相对的概念。存储已被虚拟机加载的…...
 测试点全过)
L1-047 装睡(Python实现) 测试点全过
题目 你永远叫不醒一个装睡的人 —— 但是通过分析一个人的呼吸频率和脉搏,你可以发现谁在装睡!医生告诉我们,正常人睡眠时的呼吸频率是每分钟15-20次,脉搏是每分钟50-70次。下面给定一系列人的呼吸频率与脉搏,请你找…...
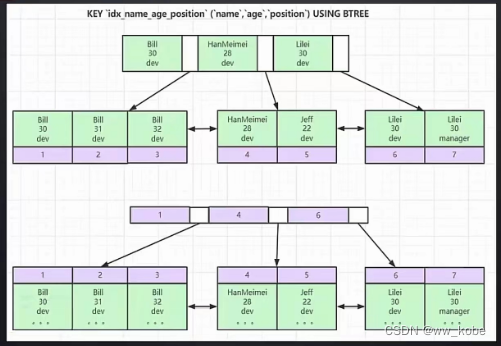
Mysql优化原理分析
一、存储引擎 1.1 MyISAM 一张表生成三个文件 xxx.frm:存储表结构xxx.MYD:存储表数据xxx.MYI:存储表索引 索引文件和数据文件是分离的(非聚集) select * from t where t.col1 30; 先去t.MYI文件查找30对应的索引…...

软考高级系统架构设计师系列案例考点专题一:软件架构设计
软考高级系统架构设计师系列案例考点专题一:软件架构设计 一、考点梳理及精讲1.质量属性判断与质量属性效用树2.必备概念3.架构风格对比4.MVC架构5.J2EE架构6.面向服务的架构SOA7.企业服务总线ESB一、考点梳理及精讲 系统架构设计师方面的知识在案例分析中每年必考1~2题,并且…...

css实现垂直上下布局的两种常用方法
例子:将两个<span>元素在<div>内垂直居中放置. 方法一:使用 Flexbox 来实现。 在下面的示例中,我将为 <div> 元素添加样式,使其成为一个 Flex 容器,并使用 Flexbox 属性将其中的两个 <span>…...
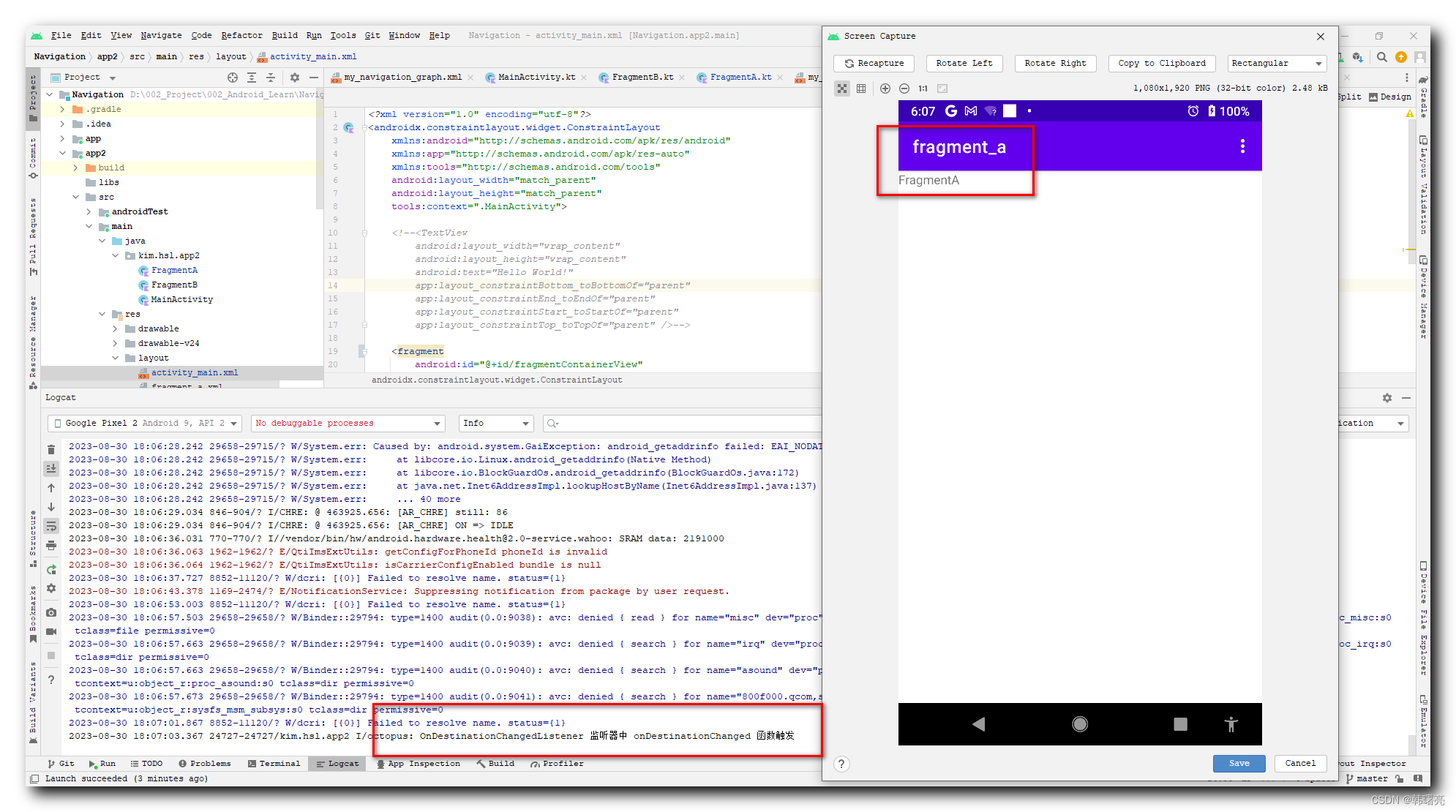
【Jetpack】Navigation 导航组件 ⑤ ( NavigationUI 类使用 )
文章目录 一、NavigationUI 类简介二、NavigationUI 类使用流程1、创建 Fragment2、创建 NavigationGraph3、Activity 导入 NavHostFragment4、创建菜单5、Activity 界面开发 NavigationUI 的主要逻辑 ( 重点 )a、添加 Fragment 布局b、处理 Navigation 导航逻辑 ( 重点 )c、启…...
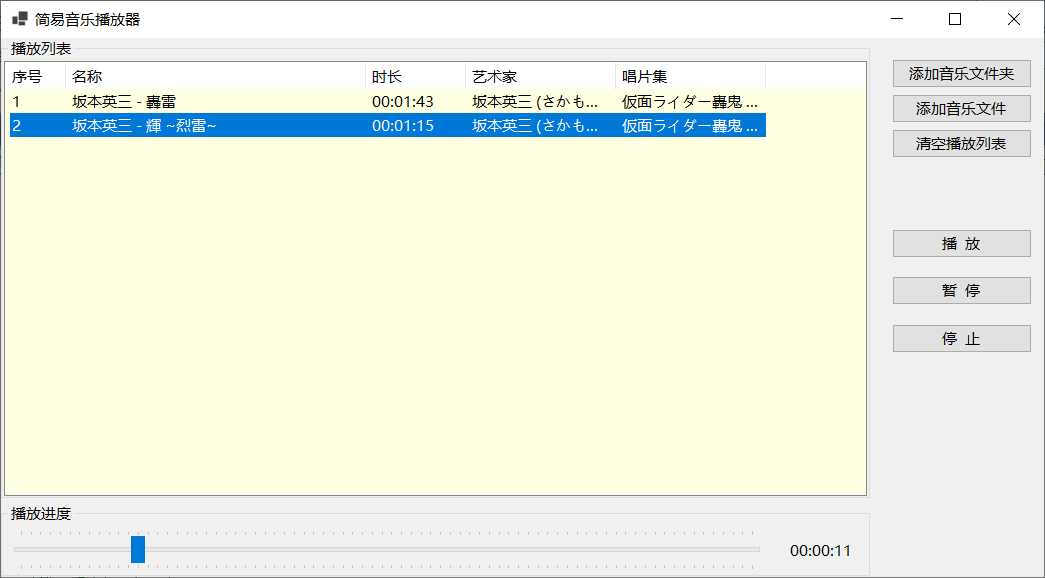
基于NAudio实现简单的音乐播放器
《测试.net开源音频库NAudio》介绍了使用NAudio实现音乐播放和录音的基本用法,本文基于NAudio的音乐播放功能实现简单的mp3音乐播放器程序,主要实现以下功能: 1)导入文件夹中的mp3音乐文件,直接导入多个mp3音乐文件…...

C++之“00000001“和“\x00\x00\x00\x01“用法区别(一百八十六)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生…...
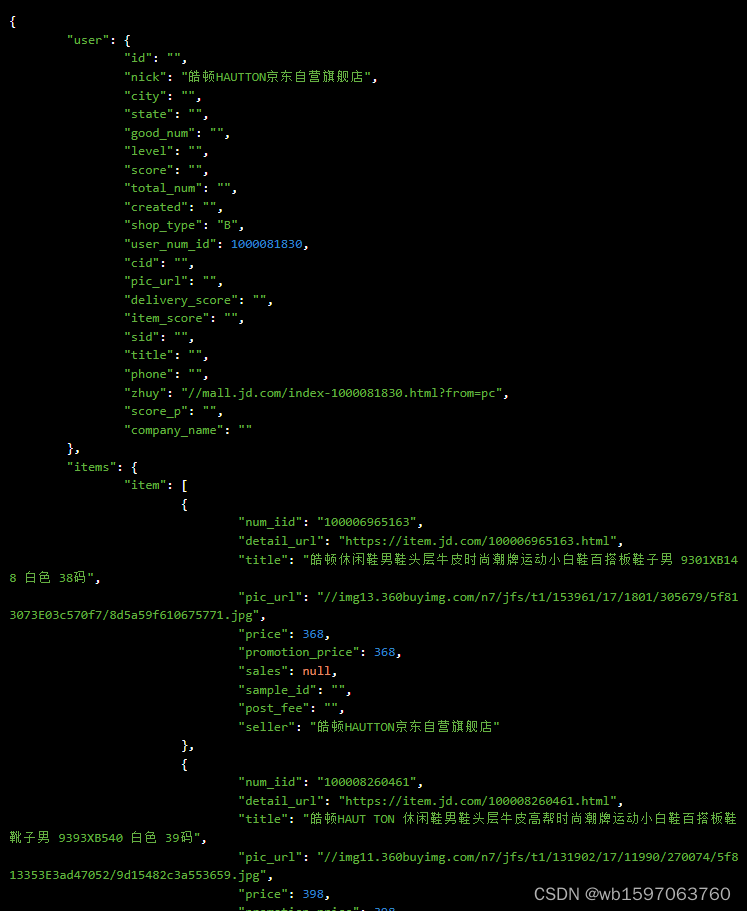
Java“魂牵”京东店铺所有商品数据接口,京东店铺所有商品API接口,京东API接口申请指南
要通过京东的API获取店铺所有商品数据,您可以使用京东开放平台提供的接口来实现。以下是一种使用Java编程语言实现的示例,展示如何通过京东开放平台API获取整店商品数据: 首先,确保您已注册成为京东开放平台的开发者,…...

vuex详细用法
Vuex是一个专门为Vue.js应用程序开发的状态管理模式。它可以帮助我们在Vue组件之间共享和管理数据,以及实现更好的代码组织和调试。 在Vue.js中,组件之间的数据通信可以通过props和事件来实现。然而,随着应用程序规模的增长,组件…...

微前端-monorepo-无界
文章目录 前言一、微前端二 、monorepo三 、pnpm硬链接软链接(符号链接)幽灵依赖依赖安装耗时长monorepo项目搭建子模块复用 四、无界接入无界无界预加载无界传参 总结 前言 本文主要记录微前端框架 无界 的使用与理解以及monorepo代码管理方式。 一、微…...

阿里云矢量图标透明背景转换/展示时变为黑色解决方法
下载了一个矢量图标,背景是透明的 上传到minio然后在前端展示,发现透明(白色)的地方变成黑色了 处理方法:去除透明的底色。使用window的画图程序打开保存一遍,将透明色转为白色 OK...
)
Linux之Shell(二)
Linux之Shell 函数系统函数basenamedirname 自定义函数 正则表达式入门常规匹配常用特殊字符 文本处理工具cutawk 综合应用案例归档文件发送消息 函数 系统函数 basename 基本语法 basename [string / pathname] [suffix] 功能描述:basename 命令会删掉所有的前缀…...

以太网POE供电浪涌静电防护推荐TVS二极管
POE是一种传输技术,可在以太网电缆上传输电力和数据。1000M千兆以太网POE供电端口广泛用于安防、视频监控以及智能电网等工业系统,以实现系统内的数据、视频传输、流量控制、以及通过总线实现供电。由于工业以太网工作环境非常严酷苛刻,对于以…...

如何在 JavaScript 中查看结构体数组?
调试 JavaScript 代码的最简单方法是使用许多开发人员使用的 console.log()。有时,我们需要了解数组的结构和存储的值以进行调试。以下介绍如何查看结构数组。 JavaScript 的各种方法允许我们检查数组的结构。例如,我们可以知道数组是否包含对象、嵌套数…...

ESP32嵌入式系统工具库:运行时监控、资源池与高精度时间管理
1. 项目概述sys_utils是一个面向 ESP32 平台、深度适配 ESP-IDF(Espressif IoT Development Framework)生态的系统级工具库。其定位并非通用 C 标准库的替代品,而是聚焦于嵌入式实时系统开发中高频、易错、跨模块复用的底层支撑需求——在裸机…...

虚拟同步发电机这玩意儿搞并网真心刺激!今天咱们直接拆解一个双机并联的MATLAB/Simulink仿真模型,手把手看它怎么扛住240kW的暴力测试
MATLAB/Simulink虚拟同步发电机(vsg) 双机并联 仿真模型,附参考文献。 电压电流双闭环控制,SPWM调制技术:运用正弦波脉宽调制(SPWM)技术,优化波形输出。 总负荷承载 轻松应对240kW有功功率及10k…...

Java中的5大AI框架!
前言在AI技术爆发的这两年里,我一直在思考一个问题:Python有LangChain,JavaScript有LangChain.js,我们Java开发者拿什么来构建AI应用?这个问题在2024-2025年终于有了答案。随着Spring AI的1.0 GA发布、LangChain4j的持…...

Python开发者实战:用pg-mcp轻松搞定PostgreSQL集群读写分离与连接池管理
Python开发者实战:用pg-mcp轻松搞定PostgreSQL集群读写分离与连接池管理 现代Web应用对数据库的要求越来越高,特别是在高并发场景下,传统的单一数据库连接方式往往成为性能瓶颈。作为Python开发者,我们经常需要在Flask或Django项目…...
,并放置任务栏中,.desktop文件使用)
[ linux添加应用图标到桌面 ] : 中将应用程序添加图标(快捷方式 ),并放置任务栏中,.desktop文件使用
.desktop文件格式在你的主目录中打开终端(ctrlaltt),接着输入以下代码:touch test.desktop vim test.desktop这里我选择的是vim的编辑方式,当然如果你没有vim或者说不太熟练的话,你可以直接双击打开该文件。代码解释:t…...
)
保姆级教程:用PHPStudy+红日靶场复现一次完整的内网渗透(从外网打到域控)
从零构建内网渗透实战:PHPStudy环境下的红日靶场攻防演练 在网络安全领域,内网渗透测试是检验企业防御体系完整性的重要手段。本文将带领读者使用常见的PHPStudy环境搭建红日靶场,通过模拟真实攻击路径,从外网Web渗透逐步深入内网…...

新手必看:在快马平台学习排列组合公式的代码实现
新手必看:在快马平台学习排列组合公式的代码实现 作为一个编程新手,当我第一次接触排列组合公式时,那些数学符号和递归逻辑让我一头雾水。直到在InsCode(快马)平台上找到了带详细注释的示例代码,才真正理解了Cn和An公式的实现原理…...

等保测评后,我的CentOS/Ubuntu服务器安全加固清单还加了这些
等保测评后,我的CentOS/Ubuntu服务器安全加固清单还加了这些 在完成等保测评基础整改后,许多安全工程师常陷入"合规即安全"的误区。实际上,等保要求只是安全基线的最低标准。本文将分享我在实际运维中积累的合规之上的实战加固技巧…...

云容笔谈在自媒体内容生产中的提效实践:日更国风配图效率提升300%
云容笔谈在自媒体内容生产中的提效实践:日更国风配图效率提升300% 1. 自媒体内容创作的痛点与挑战 作为自媒体创作者,每天最头疼的就是配图问题。特别是做国风内容的账号,既要保持东方美学韵味,又要保证日更频率,传统…...

BetterNCM Installer:3步完成网易云音乐插件框架安装
BetterNCM Installer:3步完成网易云音乐插件框架安装 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer BetterNCM Installer 是一个专为网易云音乐PC版客户端设计的插件管理器…...