数学建模——校园供水系统智能管理
import pandas as pd
data1=pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx")
data2=pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx")
data3=pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx")
data4=pd.read_excel("C://Users//JJH//Desktop//E//附件_四季度.xlsx")
data1| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | |
|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 729278 | 物业 | 3030100102 | 2019/3/31 22:45:00 | 50.9 | 50.9 | 0.0 |
| 729279 | 物业 | 3030100102 | 2019/3/31 23:00:00 | 50.9 | 50.9 | 0.0 |
| 729280 | 物业 | 3030100102 | 2019/3/31 23:15:00 | 50.9 | 50.9 | 0.0 |
| 729281 | 物业 | 3030100102 | 2019/3/31 23:30:00 | 50.9 | 50.9 | 0.0 |
| 729282 | 物业 | 3030100102 | 2019/3/31 23:45:00 | 50.9 | 50.9 | 0.0 |
729283 rows × 6 columns
data1.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data2.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data3.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
data4.isnull().sum()
水表名 0
水表号 0
采集时间 0
上次读数 0
当前读数 0
用量 0
dtype: int64
import numpy as np
# 合并数据
data1['季度'] = pd.Series(["一季度" for i in range(len(data1.index))])
data2['季度'] = pd.Series(["二季度" for i in range(len(data2.index))])
data3['季度'] = pd.Series(["三季度" for i in range(len(data3.index))])
data4['季度'] = pd.Series(["四季度" for i in range(len(data4.index))])
data1| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | 季度 | |
|---|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 729278 | 物业 | 3030100102 | 2019/3/31 22:45:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729279 | 物业 | 3030100102 | 2019/3/31 23:00:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729280 | 物业 | 3030100102 | 2019/3/31 23:15:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729281 | 物业 | 3030100102 | 2019/3/31 23:30:00 | 50.9 | 50.9 | 0.0 | 一季度 |
| 729282 | 物业 | 3030100102 | 2019/3/31 23:45:00 | 50.9 | 50.9 | 0.0 | 一季度 |
729283 rows × 7 columns
data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
dataC:\Users\JJH\AppData\Local\Temp\ipykernel_31264\4019438690.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.data = data1.append([data2,data3,data4],ignore_index=True) # 添加合并
| 水表名 | 水表号 | 采集时间 | 上次读数 | 当前读数 | 用量 | 季度 | |
|---|---|---|---|---|---|---|---|
| 0 | 司法鉴定中心 | 0 | 2019/1/1 00:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 1 | 司法鉴定中心 | 0 | 2019/1/1 00:30:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 2 | 司法鉴定中心 | 0 | 2019/1/1 00:45:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 3 | 司法鉴定中心 | 0 | 2019/1/1 01:00:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| 4 | 司法鉴定中心 | 0 | 2019/1/1 01:15:00 | 2157.1 | 2157.1 | 0.0 | 一季度 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 3086783 | 消防 | 3620303200 | 2019/12/31 22:45:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086784 | 消防 | 3620303200 | 2019/12/31 23:00:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086785 | 消防 | 3620303200 | 2019/12/31 23:15:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086786 | 消防 | 3620303200 | 2019/12/31 23:30:00 | 22.0 | 22.0 | 0.0 | 四季度 |
| 3086787 | 消防 | 3620303200 | 2019/12/31 23:45:00 | 22.0 | 22.0 | 0.0 | 四季度 |
3086788 rows × 7 columns
x=data[['水表名','用量','采集时间']]
x
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 0 | 司法鉴定中心 | 0.0 | 2019/1/1 00:15:00 |
| 1 | 司法鉴定中心 | 0.0 | 2019/1/1 00:30:00 |
| 2 | 司法鉴定中心 | 0.0 | 2019/1/1 00:45:00 |
| 3 | 司法鉴定中心 | 0.0 | 2019/1/1 01:00:00 |
| 4 | 司法鉴定中心 | 0.0 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
3086788 rows × 3 columns
x1=x[x['水表名']=='消防']
x1
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 1500912 | 消防 | 0.0 | 2019/4/22 12:15:00 |
| 1500913 | 消防 | 0.0 | 2019/4/22 12:30:00 |
| 1500914 | 消防 | 0.0 | 2019/4/22 12:45:00 |
| 1500915 | 消防 | 0.0 | 2019/4/22 13:00:00 |
| 1500916 | 消防 | 0.0 | 2019/4/22 13:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
23984 rows × 3 columns
import matplotlib.pyplot as plt
print(len(x1))
23984
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签
x = range(23984)# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x1['采集时间'],x1['用量'],color='black',linewidth=0.5)
plt.show()

x=data[['水表名','用量','采集时间']]
x
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 0 | 司法鉴定中心 | 0.0 | 2019/1/1 00:15:00 |
| 1 | 司法鉴定中心 | 0.0 | 2019/1/1 00:30:00 |
| 2 | 司法鉴定中心 | 0.0 | 2019/1/1 00:45:00 |
| 3 | 司法鉴定中心 | 0.0 | 2019/1/1 01:00:00 |
| 4 | 司法鉴定中心 | 0.0 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 3086783 | 消防 | 0.0 | 2019/12/31 22:45:00 |
| 3086784 | 消防 | 0.0 | 2019/12/31 23:00:00 |
| 3086785 | 消防 | 0.0 | 2019/12/31 23:15:00 |
| 3086786 | 消防 | 0.0 | 2019/12/31 23:30:00 |
| 3086787 | 消防 | 0.0 | 2019/12/31 23:45:00 |
3086788 rows × 3 columns
x2=x[x['水表名']=='XXX第一学生宿舍']
x2
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x2) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x2['采集时间'],x2['用量'],color='black',linewidth=0.5)
plt.show()

x=data[['水表名','用量','采集时间']]
x3=x[x['水表名']=='留学生楼(新)']
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x3) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x3['采集时间'],x3['用量'],color='black',linewidth=0.3)
plt.show()

x=data[['水表名','用量','采集时间']]
x4=x[x['水表名']=='XXX教学大楼总表']
# 自定义x轴刻度
xticks = ['Jan', 'Mar', 'May', 'Jul', 'Sep','Nov'] # 自定义刻度标签# 自定义x轴刻度
num_ticks = 6 # 指定刻度数量
step = len(x4) // num_ticks # 计算刻度步长
xtick_positions = [i * step for i in range(num_ticks)] # 生成刻度位置
plt.xticks(xtick_positions, xticks)
plt.plot(x4['采集时间'],x4['用量'],color='black',linewidth=0.3)
plt.show()

import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 指定字体为SimHei
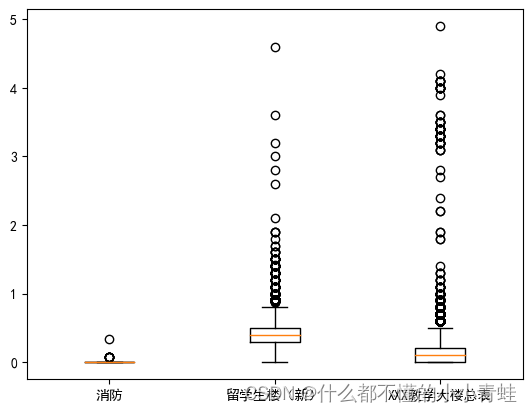
labels = ['消防', '留学生楼(新)', 'XXX教学大楼总表']plt.boxplot([x1['用量'],x3['用量'],x4['用量']])plt.xticks(range(1, 4), labels)
# 显示图形
plt.show()
x5=x[x['水表名']=='XXX第四学生宿舍']
x5
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 246289 | XXX第四学生宿舍 | 0.4 | 2019/1/1 00:15:00 |
| 246290 | XXX第四学生宿舍 | 0.4 | 2019/1/1 00:30:00 |
| 246291 | XXX第四学生宿舍 | 0.4 | 2019/1/1 00:45:00 |
| 246292 | XXX第四学生宿舍 | 0.4 | 2019/1/1 01:00:00 |
| 246293 | XXX第四学生宿舍 | 0.4 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2560037 | XXX第四学生宿舍 | 0.7 | 2019/12/31 22:45:00 |
| 2560038 | XXX第四学生宿舍 | 0.6 | 2019/12/31 23:00:00 |
| 2560039 | XXX第四学生宿舍 | 0.6 | 2019/12/31 23:15:00 |
| 2560040 | XXX第四学生宿舍 | 0.5 | 2019/12/31 23:30:00 |
| 2560041 | XXX第四学生宿舍 | 1.2 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
x6=x[x['水表名']=='茶园+']
x6
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 611260 | 茶园+ | 0.0 | 2019/1/3 16:15:00 |
| 611261 | 茶园+ | 0.0 | 2019/1/3 16:30:00 |
| 611262 | 茶园+ | 0.0 | 2019/1/3 16:45:00 |
| 611263 | 茶园+ | 0.0 | 2019/1/3 17:00:00 |
| 611264 | 茶园+ | 0.0 | 2019/1/3 17:15:00 |
| ... | ... | ... | ... |
| 2945006 | 茶园+ | 0.0 | 2019/12/31 22:45:00 |
| 2945007 | 茶园+ | 0.0 | 2019/12/31 23:00:00 |
| 2945008 | 茶园+ | 0.0 | 2019/12/31 23:15:00 |
| 2945009 | 茶园+ | 0.0 | 2019/12/31 23:30:00 |
| 2945010 | 茶园+ | 0.0 | 2019/12/31 23:45:00 |
34249 rows × 3 columns
x7=x[x['水表名']=='XXX4舍热泵热水舍']
x7
| 水表名 | 用量 | 采集时间 |
|---|
x21=x[x['水表名']=='XXX第一学生宿舍']
x21
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
x22=x[x['水表名']=='XXX第二学生宿舍']
x22
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 229011 | XXX第二学生宿舍 | 0.9 | 2019/1/1 00:15:00 |
| 229012 | XXX第二学生宿舍 | 0.7 | 2019/1/1 00:30:00 |
| 229013 | XXX第二学生宿舍 | 0.8 | 2019/1/1 00:45:00 |
| 229014 | XXX第二学生宿舍 | 0.7 | 2019/1/1 01:00:00 |
| 229015 | XXX第二学生宿舍 | 0.1 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2542373 | XXX第二学生宿舍 | 0.1 | 2019/12/31 22:45:00 |
| 2542374 | XXX第二学生宿舍 | 0.1 | 2019/12/31 23:00:00 |
| 2542375 | XXX第二学生宿舍 | 0.2 | 2019/12/31 23:15:00 |
| 2542376 | XXX第二学生宿舍 | 0.1 | 2019/12/31 23:30:00 |
| 2542377 | XXX第二学生宿舍 | 0.1 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
x21.set_index('采集时间', inplace=True)
x22.set_index('采集时间', inplace=True)
print(x21['用量'].dtypes,x21['水表名'])
print(x22['用量'].dtypes,x22['水表名'])
x_sum = x21.add(x22, fill_value=0)# 打印结果
x_sum
float64 采集时间
2019/1/1 00:15:00 XXX第一学生宿舍
2019/1/1 00:30:00 XXX第一学生宿舍
2019/1/1 00:45:00 XXX第一学生宿舍
2019/1/1 01:00:00 XXX第一学生宿舍
2019/1/1 01:15:00 XXX第一学生宿舍...
2019/12/31 22:45:00 XXX第一学生宿舍
2019/12/31 23:00:00 XXX第一学生宿舍
2019/12/31 23:15:00 XXX第一学生宿舍
2019/12/31 23:30:00 XXX第一学生宿舍
2019/12/31 23:45:00 XXX第一学生宿舍
Name: 水表名, Length: 35039, dtype: object
float64 采集时间
2019/1/1 00:15:00 XXX第二学生宿舍
2019/1/1 00:30:00 XXX第二学生宿舍
2019/1/1 00:45:00 XXX第二学生宿舍
2019/1/1 01:00:00 XXX第二学生宿舍
2019/1/1 01:15:00 XXX第二学生宿舍...
2019/12/31 22:45:00 XXX第二学生宿舍
2019/12/31 23:00:00 XXX第二学生宿舍
2019/12/31 23:15:00 XXX第二学生宿舍
2019/12/31 23:30:00 XXX第二学生宿舍
2019/12/31 23:45:00 XXX第二学生宿舍
Name: 水表名, Length: 35039, dtype: object
| 水表名 | 用量 | |
|---|---|---|
| 采集时间 | ||
| 2019/1/1 00:15:00 | XXX第一学生宿舍XXX第二学生宿舍 | 1.02 |
| 2019/1/1 00:30:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.82 |
| 2019/1/1 00:45:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.92 |
| 2019/1/1 01:00:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.82 |
| 2019/1/1 01:15:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.22 |
| ... | ... | ... |
| 2019/12/31 22:45:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.50 |
| 2019/12/31 23:00:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.50 |
| 2019/12/31 23:15:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.70 |
| 2019/12/31 23:30:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.60 |
| 2019/12/31 23:45:00 | XXX第一学生宿舍XXX第二学生宿舍 | 0.60 |
35039 rows × 2 columns
x26=x[x['水表名']=='茶园+']
x26
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 611260 | 茶园+ | 0.0 | 2019/1/3 16:15:00 |
| 611261 | 茶园+ | 0.0 | 2019/1/3 16:30:00 |
| 611262 | 茶园+ | 0.0 | 2019/1/3 16:45:00 |
| 611263 | 茶园+ | 0.0 | 2019/1/3 17:00:00 |
| 611264 | 茶园+ | 0.0 | 2019/1/3 17:15:00 |
| ... | ... | ... | ... |
| 2945006 | 茶园+ | 0.0 | 2019/12/31 22:45:00 |
| 2945007 | 茶园+ | 0.0 | 2019/12/31 23:00:00 |
| 2945008 | 茶园+ | 0.0 | 2019/12/31 23:15:00 |
| 2945009 | 茶园+ | 0.0 | 2019/12/31 23:30:00 |
| 2945010 | 茶园+ | 0.0 | 2019/12/31 23:45:00 |
34249 rows × 3 columns
x21=x[x['水表名']=='XXX第一学生宿舍']
x21
| 水表名 | 用量 | 采集时间 | |
|---|---|---|---|
| 220372 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 |
| 220373 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 |
| 220374 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 |
| 220375 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 |
| 220376 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 |
| ... | ... | ... | ... |
| 2533541 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 |
| 2533542 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 |
| 2533543 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 |
| 2533544 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 |
| 2533545 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 |
35039 rows × 3 columns
df_merged = pd.merge(x21, x26, on='采集时间', how='inner')
df_merged
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | |
|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:15:00 | 茶园+ | 0.0 |
| 1 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:30:00 | 茶园+ | 0.0 |
| 2 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:45:00 | 茶园+ | 0.0 |
| 3 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:00:00 | 茶园+ | 0.0 |
| 4 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:15:00 | 茶园+ | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 34244 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 |
| 34245 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 |
| 34246 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 |
| 34247 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 |
| 34248 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 |
34249 rows × 5 columns
df_merged['总用水量'] = df_merged['用量_x'] + df_merged['用量_y']
df_merged
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | 总用水量 | |
|---|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:15:00 | 茶园+ | 0.0 | 0.22 |
| 1 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:30:00 | 茶园+ | 0.0 | 0.22 |
| 2 | XXX第一学生宿舍 | 0.22 | 2019/1/3 16:45:00 | 茶园+ | 0.0 | 0.22 |
| 3 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:00:00 | 茶园+ | 0.0 | 0.22 |
| 4 | XXX第一学生宿舍 | 0.22 | 2019/1/3 17:15:00 | 茶园+ | 0.0 | 0.22 |
| ... | ... | ... | ... | ... | ... | ... |
| 34244 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 | 0.40 |
| 34245 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 | 0.40 |
| 34246 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 | 0.50 |
| 34247 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 | 0.50 |
| 34248 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 | 0.50 |
34249 rows × 6 columns
df_merged1 = pd.merge(x21, x26, on='采集时间', how='outer')
df_merged1
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | |
|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 | NaN | NaN |
| 1 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 | NaN | NaN |
| 2 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 | NaN | NaN |
| 3 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 | NaN | NaN |
| 4 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 | NaN | NaN |
| ... | ... | ... | ... | ... | ... |
| 35034 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 |
| 35035 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 |
| 35036 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 |
| 35037 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 |
| 35038 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 |
35039 rows × 5 columns
df_merged1['用量_y'] = df_merged1['用量_y'].replace(np.nan, 0)
df_merged1
# df_merged1['总用水量'] = df_merged1['用量_x'] + df_merged1['用量_y']
# df_merged1
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | 总用水量 | |
|---|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 | NaN | 0.0 | 0.12 |
| 1 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 | NaN | 0.0 | 0.12 |
| 2 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 | NaN | 0.0 | 0.12 |
| 3 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 | NaN | 0.0 | 0.12 |
| 4 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 | NaN | 0.0 | 0.12 |
| ... | ... | ... | ... | ... | ... | ... |
| 35034 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 | 0.40 |
| 35035 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 | 0.40 |
| 35036 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 | 0.50 |
| 35037 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 | 0.50 |
| 35038 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 | 0.50 |
35039 rows × 6 columns
df_merged1['总用水量'] = df_merged1['用量_x'] + df_merged1['用量_y']
df_merged1
| 水表名_x | 用量_x | 采集时间 | 水表名_y | 用量_y | 总用水量 | |
|---|---|---|---|---|---|---|
| 0 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:15:00 | NaN | 0.0 | 0.12 |
| 1 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:30:00 | NaN | 0.0 | 0.12 |
| 2 | XXX第一学生宿舍 | 0.12 | 2019/1/1 00:45:00 | NaN | 0.0 | 0.12 |
| 3 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:00:00 | NaN | 0.0 | 0.12 |
| 4 | XXX第一学生宿舍 | 0.12 | 2019/1/1 01:15:00 | NaN | 0.0 | 0.12 |
| ... | ... | ... | ... | ... | ... | ... |
| 35034 | XXX第一学生宿舍 | 0.40 | 2019/12/31 22:45:00 | 茶园+ | 0.0 | 0.40 |
| 35035 | XXX第一学生宿舍 | 0.40 | 2019/12/31 23:00:00 | 茶园+ | 0.0 | 0.40 |
| 35036 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:15:00 | 茶园+ | 0.0 | 0.50 |
| 35037 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:30:00 | 茶园+ | 0.0 | 0.50 |
| 35038 | XXX第一学生宿舍 | 0.50 | 2019/12/31 23:45:00 | 茶园+ | 0.0 | 0.50 |
35039 rows × 6 columns
相关文章:
数学建模——校园供水系统智能管理
import pandas as pd data1pd.read_excel("C://Users//JJH//Desktop//E//附件_一季度.xlsx") data2pd.read_excel("C://Users//JJH//Desktop//E//附件_二季度.xlsx") data3pd.read_excel("C://Users//JJH//Desktop//E//附件_三季度.xlsx") data4…...
分布式集群——搭建Hadoop环境以及相关的Hadoop介绍
系列文章目录 分布式集群——jdk配置与zookeeper环境搭建 分布式集群——搭建Hadoop环境以及相关的Hadoop介绍 文章目录 前言 一 hadoop的相关概念 1.1 Hadoop概念 补充:块的存储 1.2 HDFS是什么 1.3 三种节点的功能 I、NameNode节点 II、fsimage与edits…...

Python的os.walk()函数使用案例
在Python中,os模块是一个非常实用的工具,它可以让我们与操作系统进行交互,操作文件和目录。在本文中,我们将详细介绍os模块中的遍历文件功能,并通过具体案例和使用场景来解释。 首先,导入os模块。在Pytho…...

学习JAVA打卡第四十五天
StringBuffer类 StringBuffer对象 String对象的字符序列是不可修改的,也就是说,String对象的字符序列的字符不能被修改、删除,即String对象的实体是不可以再发生变化,例如:对于 StringBuffer有三个构造方法ÿ…...
创建K8s pod Webhook
目录 1.前提条件 2.开始创建核心组件Pod的Webhook 2.1.什么是Webhook 2.2.在本地k8s集群安装cert-manager 2.3.创建一个空的文件夹 2.4. 生成工程框架 2.5. 生成核心组件Pod的API 2.6.生成Webhook 2.7.开始实现Webhook相关代码 2.7.1.修改相关配置 2.7.2.修改代码 2…...

抓包-要抓取Spring Boot应用程序的请求
要抓取Spring Boot应用程序的请求,可以按照以下步骤进行操作: 1. 确保你已经按照之前提到的方法设置了Charles代理,并在Charles的SSL代理设置中添加了Spring Boot应用程序的域名。 2. 在Spring Boot应用程序的代码中,添加以下配…...

jmeter+nmon+crontab简单的执行接口定时压测
一、概述 临时接到任务要对系统的接口进行压测,上面的要求就是:压测,并发2000 在不熟悉系统的情况下,按目前的需求,需要做的步骤: 需要有接口脚本需要能监控系统性能需要能定时执行脚本 二、观察 >针…...
ZooKeeper基础命令和Java客户端操作
1、zkCli的常用命令操作 (1)Help (2)ls 使用 ls 命令来查看当前znode中所包含的内容 (3)ls2查看当前节点数据并能看到更新次数等数据 (4)stat查看节点状态 (5…...

【数据分享】2000-2020年全球人类足迹数据(无需转发\免费获取)
人类足迹(Human Footprint)是生态过程和自然景观变化对生态环境造成的压力,是世界各国对生物多样性和生态保护的关注重点。那如何才能获取长时间跨度的人类足迹时空数据呢? 之前我们分享了来自于中国农业大学土地科学与技术学院的城市环境监测及建模&am…...
基于机器学习的fNIRS信号质量控制方法
摘要 尽管功能性近红外光谱(fNIRS)在神经系统研究中的应用越来越广泛,但fNIRS信号处理仍未标准化,并且受到经验和手动操作的高度影响。在任何信号处理过程的开始阶段,信号质量控制(SQC)对于防止错误和不可靠结果至关重要。在fNIRS分析中&…...
分布式锁的三种实现方式是什么?
分布式锁三种实现方式: 基于数据库实现分布式锁;基于缓存(Redis等)实现分布式锁;基于Zookeeper实现分布式锁; 一, 基于数据库实现分布式锁 悲观锁 利用select … where … for update 排他锁…...
华为云软件精英实战营——感受软件改变世界,享受Coding乐趣
机器人已经在诸多领域显现出巨大的商业价值,华为云计算致力于以云助端的方式为机器人产业带来全新机会 如果您是开发爱好者,想了解华为云,想和其他自由开发者交流经验; 如果您是学生,想和正在从事软件开发行业的大佬…...
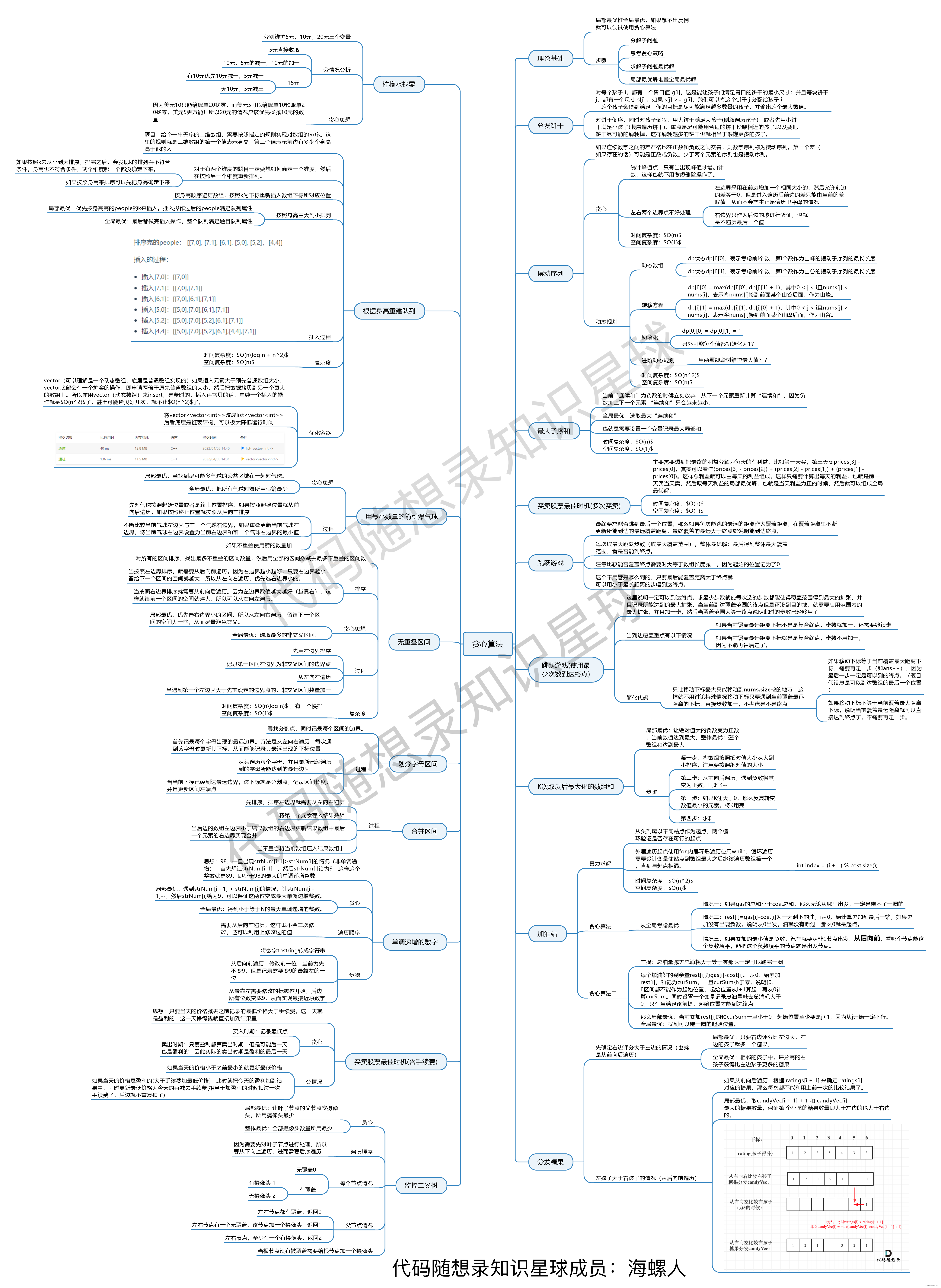
贪心算法总结篇
文章转自代码随想录 贪心算法总结篇 我刚刚开始讲解贪心系列的时候就说了,贪心系列并不打算严格的从简单到困难这么个顺序来讲解。 因为贪心的简单题可能往往过于简单甚至感觉不到贪心,如果我连续几天讲解简单的贪心,估计录友们一定会不耐…...

ICCV 2023 | 港中文MMLab: 多帧光流估计模型VideoFlow,首次实现亚像素级别误差
本文提出了一个多帧光流估计模型 VideoFlow,旨在充分挖掘视频中的时序信息和运动规律,避免当前主流方法只以两帧图片作为输入而面临的信息瓶颈,显著提升了光流估计的性能。 在公开的 Sintel Bechmark 上,VideoFlow 在 Clean 和 Fi…...
【python爬虫】—图片爬取
图片爬取 需求分析Python实现 需求分析 从https://pic.netbian.com/4kfengjing/网站爬取图片,并保存 Python实现 获取待爬取网页 def get_htmls(pageslist(range(2, 5))):"""获取待爬取网页"""pages_list []for page in pages:u…...

自动化运维工具—Ansible
一、Ansible概述1.1 Ansible是什么1.2 Ansible的特性1.3 Ansible的特点1.4 Ansible数据流向 二、Ansible 环境安装部署三、Ansible 命令行模块(1)command 模块(2)shell 模块(3)cron 模块(4&…...
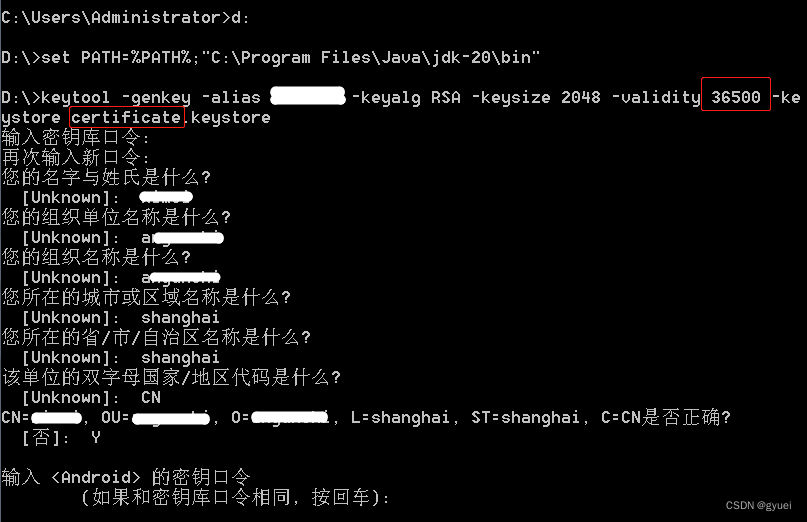
uniapp 安卓平台签名证书(.keystore)生成
安装JRE环境 下载jre安装包:https://www.oracle.com/java/technologies/downloads/#java8安装jre安装包时,记录安装目录(例:C:\Program Files\Java\jdk-20)打开命令行(cmd),将JRE安装路径添加到系统环境变量 d: se…...

缓存中间件Redis常考知识点
缓存中间件Redis常考知识点 1 什么是RDB和AOF2 Redis的过期键的删除策略3 简述Redis事务实现4 Redis 主从复制的核⼼原理5 Redis有哪些数据结构?分别有哪些典型的应⽤场景?6 Redis分布式锁底层是如何实现的?7 Redis主从复制的核⼼原理8 Redis…...
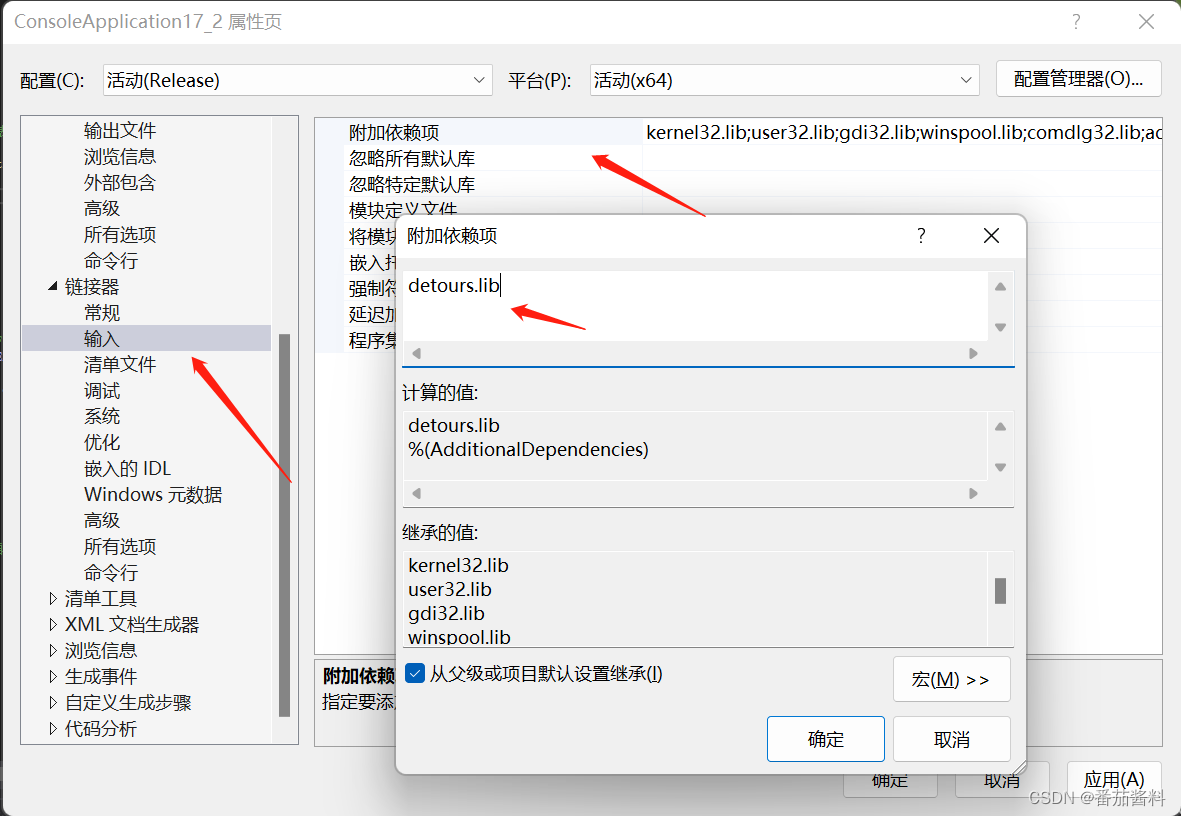
detour编译问题及导入visual studio
Detours是经过微软认证的一个开源Hook库,Detours在GitHub上,网址为 https://github.com/Microsoft/Detours 注意版本不一样的话也是会出问题的,因为我之前是vs2022的所以之前的detours.lib不能使用,必须用对应版本的x64 Native To…...

江西武功山旅游攻略(周末两日游)
一、 往返路线 1: 出发路线 周五晚上上海出发坐火车🚄到江西萍乡(11.5小时,卧铺550左右) 打车到江西武功山景区,120-150元左右,人均30元,1小时10分左右到达 或者 🚗到达萍乡北之后 出站后步行200米到长途汽车站,乘旅游巴士直达武功山游…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...