《论文阅读18》JoKDNet
一、论文
- 研究领域:用于大尺度室外TLS点云配准的联合关键点检测和特征表达网络
- 论文:JoKDNet: A joint keypoint detection and description network for large-scale
outdoor TLS point clouds registration -
International Journal of Applied Earth Observations and Geoinformation
-
Received 30 June 2021; Received in revised form 17 August 2021; Accepted 28 August 2021
- 论文团队主页
- 论文链接
- 团队公开的数据集WHU-TLS
二、论文概述
提出了一种新的神经网络JoKDNet来联合学习关键点检测和特征描述,以提高大规模室外地面激光扫描(TLS)点云配准的可行性和准确性。
JoKDNet是第一个基于深度学习的方法,专注于 无初始姿态 、不同视场、大规模户外TLS点云配准。该网络将关键点检测和描述集成到一个框架中,提高了对具有重复和对称特征且缺乏明显几何特征的点云的配准能力和鲁棒性。

- 引入一种新的关键点检测模块,自动学习每个采样点的得分(重要性),并将最重要的前k个采样点作为检测到的关键点
- 提出了一个增强的特征描述模块,学习每个关键点的特征表示,将局部和全局特征结合起来。
- 设计了一个损失函数,使检测到的关键点在匹配时具有更高的可区分性,同时最大化非对应关键点之间的特征距离,最小化对应关键点之间的特征距离
- 最后,利用距离矩阵模块和随机样本一致性(RANSAC)确定源云和目标点云的对应关系,进行变换计算。
Loss损失函数:


三、论文详述
- abstract
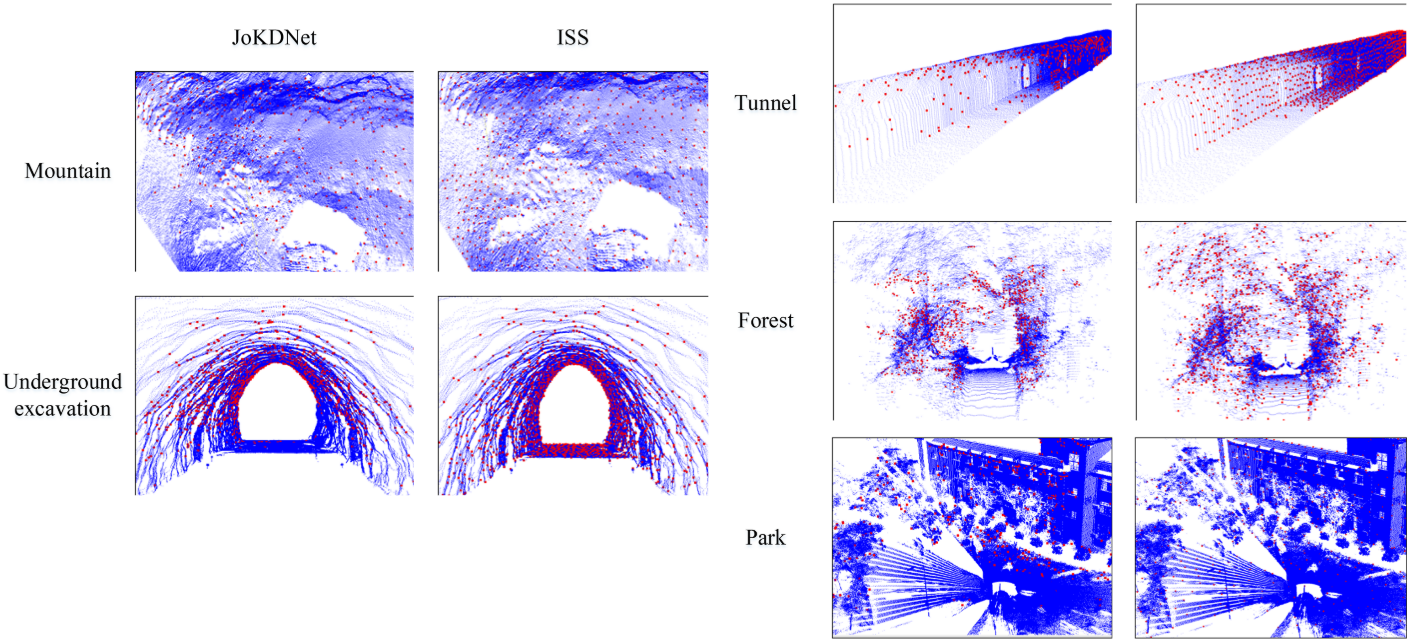
大规模室外地面激光扫描(TLS)点云的配准在具有对称和重复元素(例如,公园、森林和隧道)、弱几何特征(例如,地下挖掘),并且在不同的阶段显著变化(例如,山)。为了解决这些问题,提出了一种新的神经网络JoKDNet来联合学习关键点检测和特征描述,以提高点云配准的可行性和准确性。首先,引入一种新的关键点检测模块,自动学习每个采样点的得分,并将最重要的Top-k采样点作为检测到的关键点。其次,提出了一个增强的特征描述模块,通过融合层次化的局部特征和上下文特征来学习每个关键点的特征表示。再次,设计了一个损失函数,使检测到的关键点在匹配时具有更高的可区分性,同时最大化非对应关键点之间的特征距离,最小化对应关键点之间的特征距离。最后,利用距离矩阵模块和随机样本一致性(RANSAC)确定源云和目标点云的对应关系,进行变换计算。综合实验表明,JoKDNet在五个具有挑战性的场景(例如,公园,森林,隧道,地下挖掘和山脉)从两个数据集(WHU-TLS和ETH-TLS)的配准误差,以及对不同场景的鲁棒性,在无ICP的情况下,最大旋转误差小于0.06◦,最大平移误差小于0.84 m。
- Introduction
3D点云的配准对于诸如数字文化遗产等许多应用起着关键作用(Yang和Zang,2014; Montuori等人,2014)、3D重建(Jung等人,2014; Oesau等人,2014),滑坡监测(Prokop和Panholzer,2009; Vosselman和Maas,2010)和森林清单调查(Liang等人,2016; Kelbe等人,2016年)。地面激光扫描(TLS)点云的自动配准由于空间分布不规则、噪声、结构不完整和遮挡等因素而困难,导致特征/关键点提取困难。
传统的点云配准方法主要包括两步:建立三维对应关系和两点云之间的刚体变换估计。不幸的是,3D-3D点对应的建立是不平凡的(Yew和Lee,2018)。尽管在过去十年中已经提出了若干3D手工制作的关键点检测器和描述符,但是构建3D-3D对应的有效性仍然不令人满意(Weinmann et al.2011; Theiler and Schindler,2012; Guo等人,2014; 2016),在具有高对称性和相似特征结构的场景中对全局定位/姿态估计造成了巨大挑战(Yew和Lee,2018)。这证明了3D手工特征检测器难以满足进一步配准的3D-3D点对应的要求。
传统的点云配准方法主要包括两步:
- 建立三维对应关系
- 两点云之间的刚体变换估计
可重复性和可区分性分别是3D关键点检测器和描述符的主要特征(Tombari等人,2010年)。可重复性涉及获得各种干扰的相同关键点的能力(例如,视点改变、丢失部分和噪声)。可区分性是区分关键点的能力,其可以被有效地描述和匹配,以避免不正确的对应。基于手工特征的关键点检测和描述方法的可重复性和可区分性是有限的。一方面,在各种干扰下的相同关键点(例如,点密度或拓扑变化、视点改变、缺失结构、传感器噪声)呈现不一致的几何形状,因此难以检测对应的关键点。另一方面,特征表示能力依赖于设计者的经验和参数调整能力,因此很难区分具有对称重复或弱几何特征的关键点。
深度学习在基于图像的任务中取得了巨大成功,例如对象检测(雷德蒙等人,2016)和面部识别(Schroff等人,2015年)。还在3D点云的语义分割中研究了3D深度学习中的一些研究(Wu等人,2019年)的报告。然而,对于注册任务,目前的深度学习方法仅适用于小场景,难以处理大规模的户外TLS点云。在本文中,提出了一种新的神经网络JoKDNet,联合学习关键点检测器和描述符,以提高点云配准的准确性和鲁棒性。据我们所知,JoKDNet是第一个基于深度学习的方法,专注于无初始姿态的大规模户外TLS点云配准。它包括关键点检测、关键点特征描述和损失函数公式化。关键点检测模块旨在学习每个下采样点的重要性,并将最重要的TOp-k个点作为检测到的关键点。关键点特征描述模块旨在通过特征描述模块学习每个关键点的特征表示,将局部和全局特征结合起来。以下是本文与当前工作相比的主要贡献:
目前的深度学习方法仅适用于小场景
(1)JoKDNet是第一个基于深度学习的方法,专注于大规模户外TLS点云配准,无需初始姿势,并在配准不同视场的TLS点云方面表现出色。
(2)该网络将关键点检测和描述集成到一个框架中,提高了对具有重复和对称特征且缺乏明显几何特征的点云的配准能力和鲁棒性。
文章的其余部分组织如下:第二节介绍了相关工作。第3节阐述了JoKDNet的结构。第4节说明了JoKDNet的实验和验证。最后,第5节对本文进行了总结,并对未来的工作进行了展望。
- Related work
基于特征的手工方法
基于手工特征的方法,例如快速点特征直方图(Rusu等人,2009)、旋转投影统计(Guo等人,2013)、语义特征线(Yang等人,2016)、自适应协方差(Zai等人,2017)、二进制形状上下文描述符(Dong等人,2017年; 2018年)在大多数情况下都取得了令人满意的结果。不幸的是,点云中的不完整结构、遮挡或杂乱显著地损害了这样的描述符(Guo等人,2016年; Xu等人,2019; Ge等人,2019; Ge和Hu,2020)。此外,该方法受到手工特征依赖于设计者的经验和调整参数的能力的事实的限制。因此,基于特征的手工配准方法在具有对称重复特征、几何特征弱、场景动态变化、重叠区域有限等场景中显得力不从心。
深度学习方法
与手工特征相比,深度学习表现为从大量数据中自动学习特征,可以学习高层次、高描述性的描述符。现有的基于深度学习的点云处理方法根据输入数据格式的不同分为三种:
(1)基于体素的网络,将点云转换为体素,从而实现从无序和非结构化数据到有序和结构化数据的转换,可以直接使用3D卷积神经网络来消费点云。
(2)多视图卷积神经网络(CNN)将点云投影到图像中并使用2D图像处理方法;
(3)直接处理不规则、非结构化点集的基于点的网络。
基于体素的深度网络结构采用卷积架构来有效地处理数据,这已被证明是最先进的精度(Maturana和谢勒,2015; Milletari等人,2016; Dai等人,2017; Song等人,2017年)。Voxnet是基于3D卷积运算进行对象识别的特征提取的开创性工作(Maturana和谢勒,2015)。类似地,对于形状识别和完成,3D ShapeNet学习形状的深度体积表示(Wu等人,2009年,2009年,2015年)。3D U-Net是应用于医学图像处理的基于体素的网络的流行示例(Çiçek O ¨等人,2016年)。然而,基于体素的Deep网络将空间划分为3D网格,导致数据稀疏性问题。为了解决这个问题,OctNet提出通过对OctTree数据结构使用卷积来在深度学习上下文中引入OctTree(Riegler等人,2017年)。Klokov和Lempitsky提供了另一种引入Kd树的方法(Klokov和Lempitsky,2017)。
3DMatch是使用3D卷积运算来计算特征描述符将基于体素的网络应用于RGB-D数据配准的先驱工作(Zeng等人,2017年)。由于点云被转换为体素,因此它可以利用图像处理的成熟网络结构并扩展到3D卷积运算。基于3DMatch,Zhang et al.(2019)使用均匀样本方法来获得关键点,并使用基于体素的深度学习模型来计算3D特征描述符,然后利用RANSAC方法来消除离群值并计算变换。
多视图深度网络通过以一定的方式从不同的视角投影三维点云数据来获得大量的2D渲染。然后,直接在图像上使用图像卷积神经网络结构来学习和识别3D对象的特征(Su等人,2015年)。Qi等人(2016)研究了用于3D对象分类的点云的体积和多视图表达,这两个实验的结果相差甚远,这表明当前的体积卷积神经网络不可否认地发展3D表示的能力。Chen等人(2017)通过计算前视图中鸟瞰图和柱面坐标的特征图,介绍了点云的多视图表达。Huang等人(2018)通过为每个3D关键点锚定三个本地相机并收集多视图特征图来学习半全局表达式。Pujol-Mir 'o等人(2019)修改了Huang et al.(2018),计算最佳投影方向生成2D渲染图像,并通过实验选择最佳邻域范围和图像大小,最后使用2D卷积神经网络计算特征描述。多视图DP网络受邻域点的数量和2D渲染图像的大小的影响。此外,3D数据信息在投影期间丢失。
PointNet(Qi等人,2017 a)是一种直接在点上操作的开创性方法,并显示了直接与点一起工作的改进,并且在连续空间中,它学习更精确的点分布。在多个点云数据处理任务中,例如分类、零件分割和场景分割任务,PointNet可获得最先进的结果。之后,大量基于不规则点的深度学习模型被提出并应用于点云的各个领域,包括点云配准(Qi et al.2017 b; Deng等人,2018a; 2018b; Deng等人,2019; Aoki等人,2019年; Wang等人,2019; Wang和所罗门,2019)。
PPFNet将点对特征(PPF)作为输入,并使用PointNet来学习几何特征描述(Deng等人,2018年a)。该方法采用随机采样来获取关键点,鲁棒性不强,且结构受样本数的限制,导致不适合大规模场景。此外,MLP用于获得局部特征,并使用最大池化操作来获得具有所有补丁的全局特征。然后将全局特征和局部特征通过MLP运算连接起来得到最终的几何特征描述。仅使用像PointNet这样的MLP很难获得更好的特征描述。因此,PPF-FoldNet用FoldingNet代替PointNet进行基于PPFNet的特征嵌入,并获得端到端网络对每个补丁的特征进行编码(Deng et al.2018年b)。该方法还以PPF作为输入,使用mini-PointNet和skip-links作为编码器,使用FoldingNet作为解码器来重建PPF。该方法的效果取决于点对特征的可分辨性和鲁棒性。PointNetLK组合PointNet和Lucas-Kanade(LK)算法以通过迭代获得旋转和变换(Aoki等人,2019年)的报告。然而,该方法涉及迭代计算,其迭代次数依赖于从实验获得的阈值。另一方面,该方法收集整个点云进行特征提取,不能应用于大规模场景。Deng等人(2019)提出了一种端到端神经网络来注册点云,它结合了FoldingNet和RelativeNet。该方法利用MLP直接获得最终的旋转和平移参数。同样,(Wang and所罗门,2019)的工作采用DGCNN(Wang et al.,2019)网络作为特征提取方法和评分模块,以创建一个考虑到两点云关系的新嵌入。最后,采用奇异值分解模块学习平移参数,取得了比MLP更好的精度。
目前,只有少数深度学习网络可以处理Kitti数据集(盖革等人,2012)注册。3DFateNet是基于深度学习的关键点检测的先驱工作,然而,这种方法预测了整个场景的所有输入和密集推理的权重,在大规模户外TLS点云中实现具有挑战性(Yew和Lee,2018)。DeepVCP是一种解决精细配准问题的新架构,它使用PointNet++来检测关键点,然后通过初始姿态和PointNet来生成相应的点(Lu et al.2019年)的报告。然而,它受到初始位姿的限制,并且在没有初始位姿的点云配准中存在困难。
- JoKDNet
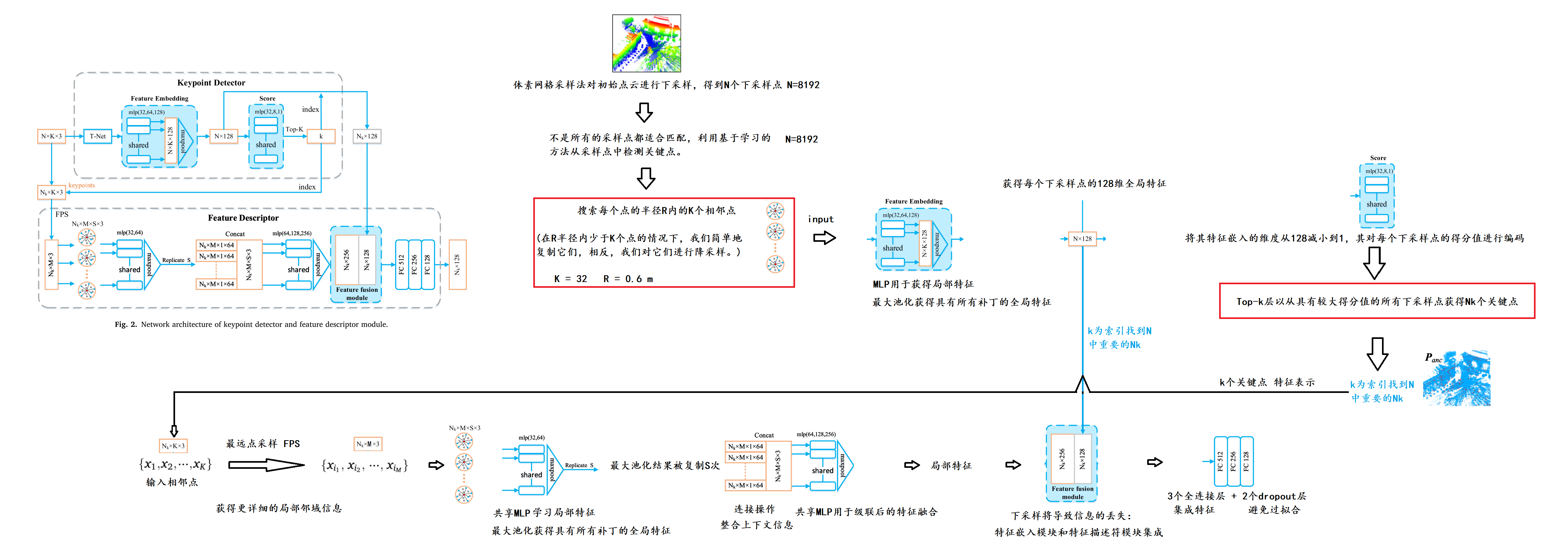
JoKDNet被提出来通过联合学习关键点检测器和描述符来提高可重复性和区分可验证性。JoKDNet主要包括关键点检测器模块(表示为紫色),特征嵌入模块(其是关键点检测器模块的一部分),特征描述符模块(表示为蓝色)和损失函数公式(表示为绿色),如图1.
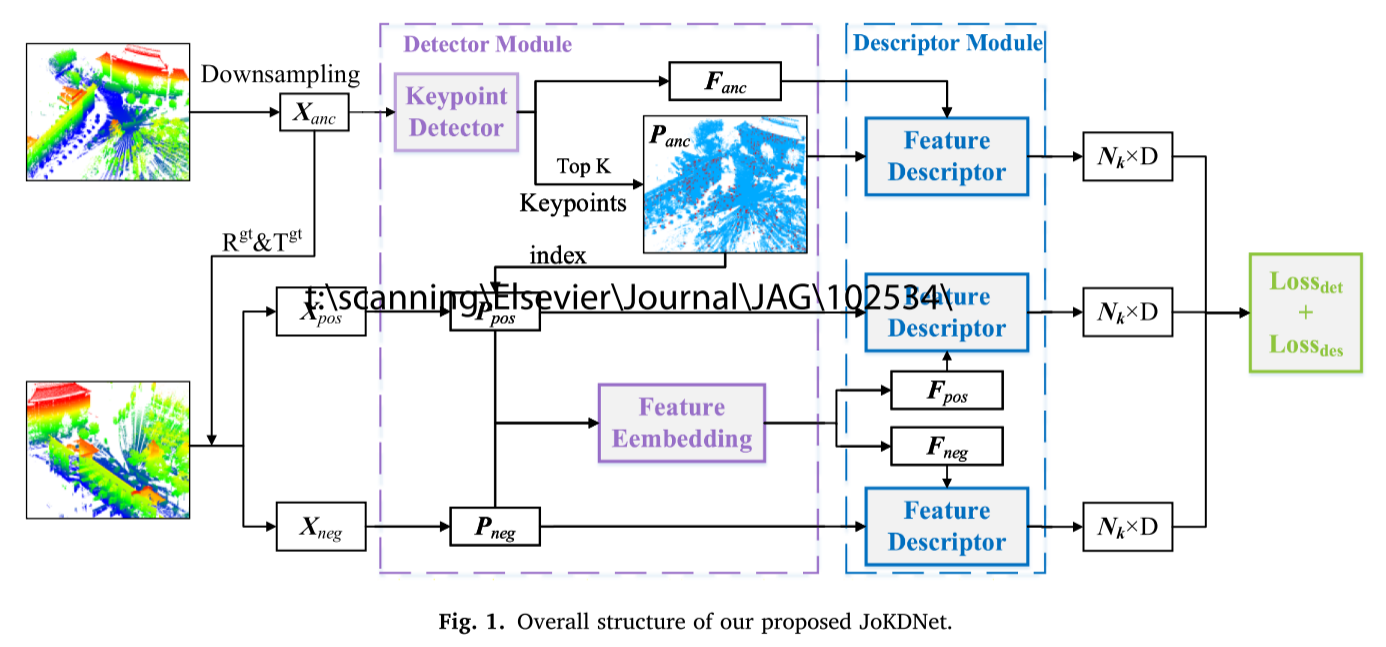
JoKDNet将源点云和目标点云作为输入。
Xanc是源点云中的下采样点
Xpos、Xneg是根据Rgt和Tgt的地面真值在目标点云中选择的匹配点和非匹配点。
具有相邻点的Xanc作为补丁输入到关键点检测器模块以学习特征描述符Fanc和每个锚点的得分。然后,使用顶部K层来获取对配准最重要的贡献的K个点Panc。
通过Panc的索引从Xpos和Xneg中选择的Ppos和Pneg被馈送到特征嵌入模块以获得特征描述符Fpos和Fneg。
将Panc和Fanc、Ppos和Fpos、Pneg和Fneg分别作为特征描述符模块的三对输入来学习区分特征。
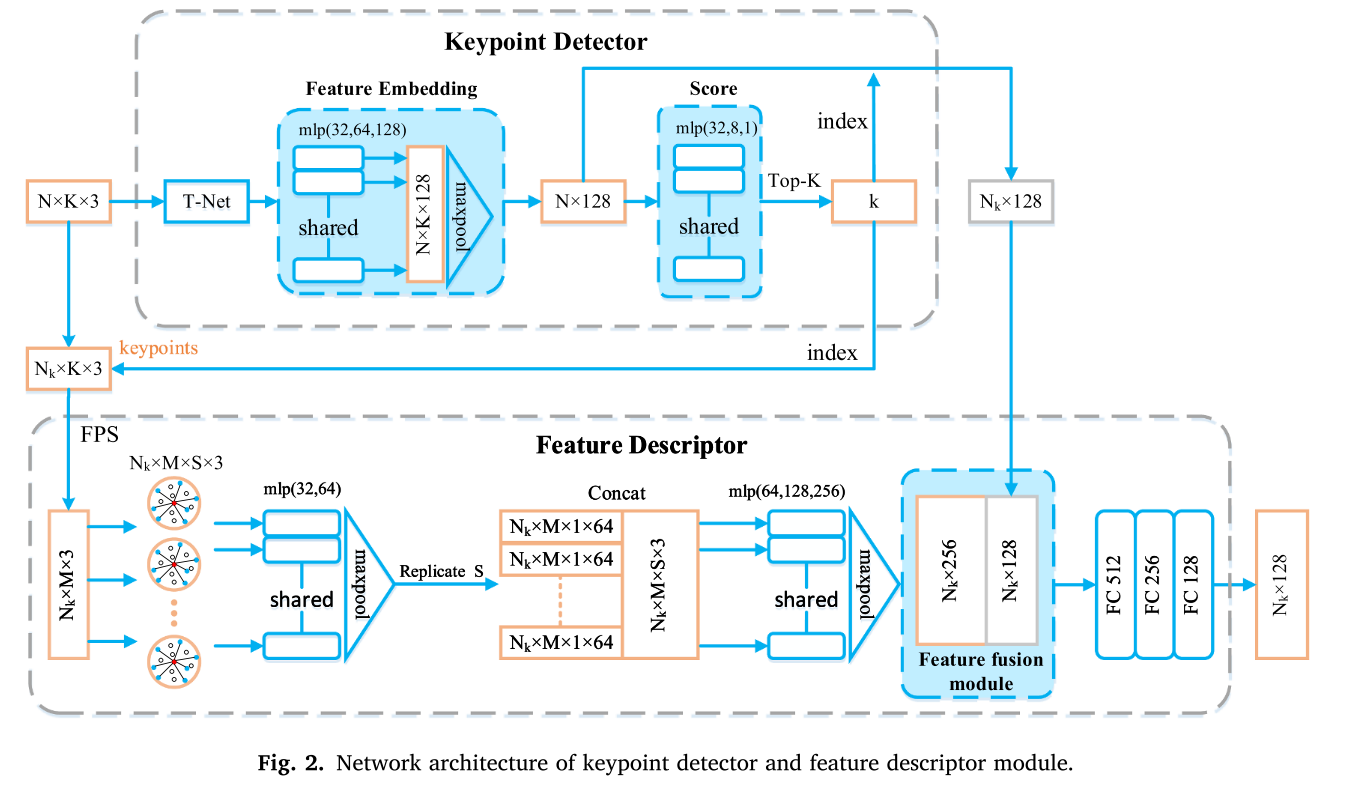
关键点检测器模块
图2中的第一行关键点检测器模块的细节。首先,采用网格采样法对初始点云进行下采样,得到N个下采样点。下采样点均匀分布在整个场景中,但并不是所有的采样点都适合匹配,因此进一步利用基于学习的方法从采样点中检测关键点。
其次,搜索每个点的半径R内的K个相邻点以形成作为特征嵌入层的输入的贴片。在R半径内少于K个点的情况下,我们简单地复制它们,相反,我们对它们进行降采样。在本文中,相邻点的数量K和搜索半径R分别设置为32和0.6米。
第三,共享多层感知器(MLP)应用于每个相邻点,以学习它们的特征嵌入,其由4个隐藏层组成,神经元大小为32,64,128。然后,使用最大池化层组合来自K个相邻点的信息,从而获得每个下采样点的128维全局特征。最后,在每个下采样点上应用另一个共享MLP以将其特征嵌入的维度从128减小到1,其对每个下采样点的得分值进行编码(即,用于配准的下采样点的重要性)。然后,应用前k层以从具有较大得分值的所有下采样点获得Nk个关键点。
"T-Net" 可能是指 "Transformation Network",它是一种在神经网络中用于学习输入数据的空间变换的架构。Transformation Network 通常用于处理具有平移、旋转、缩放等变换不变性的任务,如点云、图像和其他空间数据。
在点云处理中,T-Net 可以用于实现点云的对齐和配准,以及进行点云分类、分割等任务。它可以学习适应性的变换,使得输入点云可以在不同变换下保持一致。T-Net 的架构通常包括共享的特征提取网络和用于估计变换矩阵的部分。
例如,在点云处理中,T-Net 可以被嵌入到一个更大的网络中,用于点云的预处理、特征提取和变换估计。通过训练网络,T-Net 可以学习识别输入点云的特定变换,并输出变换矩阵,从而将点云变换为一个规范的形式。
总之,T-Net 是一种在神经网络中用于学习输入数据的变换的架构,常常用于处理具有空间变换特性的任务,如点云处理。这个概念通常在深度学习和计算机视觉领域中使用。
MLP 是 "Multilayer Perceptron" 的缩写,中文翻译为 "多层感知器"。它是一种基本的神经网络模型,用于解决各种机器学习任务,如分类、回归和其他模式识别任务。
MLP 由多个神经元层组成,每一层都与前一层和后一层连接。它至少包括一个输入层、一个或多个隐藏层和一个输出层。每个神经元层包含多个神经元(也称为节点),并且每个神经元都与前一层的所有神经元相连。
典型的 MLP 结构如下:
输入层:接受原始输入数据的特征。每个输入特征对应一个输入神经元。
隐藏层:包含多个神经元,每个神经元都与前一层的所有神经元相连。隐藏层通常用于提取数据的高级特征表示。
输出层:输出模型的预测结果,可以是分类、回归等任务的输出。
在训练过程中,MLP 通过反向传播算法来调整神经元之间的连接权重,从而最小化模型的损失函数。通过多次迭代训练,MLP 可以学习到适合特定任务的模式和特征。
虽然 MLP 在许多任务上表现出色,但也有一些限制,例如对于复杂的非线性关系可能需要更深层的网络结构。因此,在现代深度学习中,MLP 通常作为更复杂网络的基本组件,如卷积神经网络(CNN)和循环神经网络(RNN)。
Max-pooling 是一种用于卷积神经网络(CNN)中的池化操作,用于减小特征图的尺寸,并提取出重要的特征。
在卷积神经网络中,卷积层可以从输入数据中提取特征,但随着网络层数的增加,特征图的尺寸可能会变得很大,导致计算和内存需求增加。为了解决这个问题,池化操作被引入,其中的一种就是 Max-pooling。
Max-pooling 操作的步骤如下:
1. **定义池化窗口大小**:选择一个固定大小的池化窗口,通常是一个小矩形区域。
2. **在窗口内寻找最大值**:在每个池化窗口内,找到特征图中的最大值。这个最大值就是该窗口的池化输出。
3. **滑动窗口**:将池化窗口按步长(stride)滑动,以覆盖整个特征图,从而生成池化后的特征图。
Max-pooling 的效果是将每个池化窗口内的最大值提取出来,从而在减小特征图的尺寸的同时,保留了重要的特征。这种池化操作有助于减少模型对位置的敏感性,提高模型的鲁棒性。
需要注意的是,随着深度学习技术的发展,有些先进的模型在某些情况下已经采用了其他类型的池化操作,如平均池化、自适应池化等,以更好地适应不同的数据分布和任务需求。
"Concatenation operation"(连接操作)是指将两个或多个张量沿着某个维度进行拼接的操作。在深度学习中,这是一种常见的操作,用于在神经网络中将不同的特征或信息进行组合。
在深度学习中,特征通常表示为张量,而这些张量可以具有不同的维度。通过连接操作,您可以将这些张量沿着某个维度(通常是特征维度)进行堆叠,从而生成一个更大的张量。这可以用于多种情况,例如:
1. **特征拼接**:在卷积神经网络(CNN)中,您可能有多个不同层的特征图,您可以将它们沿着通道维度连接,以生成更丰富的特征表示。
2. **序列合并**:在处理序列数据(如文本或时间序列)时,您可以将不同的序列沿着序列维度连接,以构建更长的序列。
3. **多模态数据融合**:当处理多模态数据(例如图像和文本的组合)时,您可以将不同模态的特征进行连接,以实现不同信息源之间的融合。
4. **残差连接**:在残差网络(Residual Networks,ResNets)中,连接操作用于将输入张量与经过卷积层处理后的张量进行连接,以实现跳跃连接。
连接操作可以通过各种深度学习库(如TensorFlow、PyTorch等)中的函数来实现。通常,连接操作会在网络的某个中间层进行,以实现特征的融合或组合。通过合理使用连接操作,您可以构建更复杂、更灵活的神经网络架构。
"Dropout" 是一种用于神经网络的正则化技术,旨在防止过拟合(overfitting)。它是通过在训练过程中随机关闭一些神经元来实现的,从而减少神经网络对特定神经元的依赖,提高模型的泛化能力。
在神经网络中,每个神经元都可以被视为模型中的一个参数,通过神经元之间的连接权重来表示。当神经网络过拟合时,模型可能会过度依赖于某些特定的神经元和连接权重,导致在训练数据上表现很好,但在未见过的数据上表现较差。
Dropout 的工作原理如下:
1. 在每次训练迭代中,随机选择一部分神经元并关闭它们。这意味着在当前迭代中,这些神经元不会参与前向传播和反向传播。
2. 通过随机关闭神经元,强制网络学习更加鲁棒的特征表示,因为网络不再可以过度依赖于特定的神经元。
3. 在前向传播和反向传播过程中,关闭的神经元权重乘以零,不会影响权重的更新。
在测试阶段,Dropout 通常被关闭,因为此时模型应该使用所有的神经元来进行预测。
在深度学习框架中,您可以通过添加 Dropout 层来实现 Dropout 技术。例如,使用 TensorFlow 或 PyTorch,您可以这样创建一个 Dropout 层:
```python
import tensorflow as tf
from tensorflow.keras.layers import Dropout# 创建一个 Dropout 层
dropout_layer = Dropout(rate=0.5) # rate 表示关闭的神经元比例# 在模型中应用 Dropout 层
model = tf.keras.Sequential([
# 其他层
dropout_layer,
# 其他层
])
```通过在模型中添加 Dropout 层,您可以在训练过程中实现神经元的随机关闭,从而帮助提高模型的泛化能力。
"FC" 层是 "Fully Connected Layer"(全连接层)的缩写,也被称为 "Dense Layer"(稠密层)。全连接层是神经网络中的一种基本层,其所有输入神经元都与输出神经元相连接,每个连接都有一个权重。全连接层在神经网络中用于将前一层的所有特征连接到当前层的所有神经元。
全连接层的工作原理如下:
1. **输入数据传递**:全连接层接收前一层的输出,这通常是一个向量(或矩阵,如果批次中有多个样本)。
2. **权重和偏差**:每个输入特征都与每个输出神经元连接,每个连接都有一个权重。此外,每个输出神经元还有一个偏差(或称为阈值)。
3. **权重相乘和求和**:对于每个输出神经元,将其对应的所有输入特征与权重相乘,然后将这些乘积相加,加上偏差。这会产生每个输出神经元的输出。
4. **激活函数**:通常,在全连接层的输出上应用一个激活函数,以引入非线性性。这有助于模型学习复杂的非线性关系。
全连接层在深度学习中扮演着重要角色,特别是在传统的前馈神经网络(多层感知器)中。通常,神经网络的最后一层是全连接层,用于产生最终的预测结果或特征表示。
以下是使用 TensorFlow 创建全连接层的示例代码:
```python
import tensorflow as tf
from tensorflow.keras.layers import Dense# 创建一个全连接层
fc_layer = Dense(units=128, activation='relu') # 128 个神经元,使用 ReLU 激活函数# 在模型中应用全连接层
model = tf.keras.Sequential([
# 其他层
fc_layer,
# 其他层
])
```在这个示例中,`Dense` 层代表全连接层,它有 128 个神经元,并使用 ReLU 激活函数。通过在模型中添加全连接层,您可以实现特征的组合和转换,从而使神经网络能够从输入数据中学习更高级的表示。
特征描述符模块
在特征描述子模块中,采用局部特征学习、上下文信息融合、全局和局部特征融合等方法,得到更具鉴别力的特征描述。
构建局部邻域信息
图中的第二行。2示出了特征描述符模块的体系结构,该模块被应用于学习每个关键点的特征表示。从关键点检测器模块获得每个关键点的邻近点,结合更丰富的邻近属性信息来提高特征描述的可区分性。对于输入的相邻点{x1,x2,,xK},采用最远点采样(FPS,Moenning and Dodgson,2003)选取一个点子集{xi 1,xi 2,,xiM},对每个采样点xij搜索S个相邻点,则该层的输出为Nk ×M × S × 3,可以得到更详细的局部邻域信息。
考虑到面片的稀疏性和FPS算法能够保持面片的几何特征,本文采用FPS算法。此外,FPS的效率不会因为邻域点的数量少而受到影响。
集成上下文信息
共享MLP在每个局部邻域中用于学习局部特征,其由具有神经元大小32、64的2个隐藏层组成。然后,最大池化层用作对称函数以联合收割机来自S个相邻点的信息。实际上,通过在特征描述符期间聚合上下文信息对特征表示更有帮助。因此,最大池化结果被复制S次,并连接Nk × M × S × 3张量以整合上下文信息(图12中的Concat操作)。2)的情况。
在点云配准(Point Cloud Registration)中,"点云 anchor keypoints" 是指被用作参考的稳定关键点或锚点,以帮助实现点云之间的对齐。点云配准旨在将多个点云(可能来自不同时间、不同视角或传感器)对齐在同一坐标系中,以便进行后续处理,如物体识别、3D建模等。
在点云配准中使用点云 anchor keypoints 的过程如下:
1. **提取关键点**:首先,从每个点云中提取关键点。这些关键点可能是具有显著特征的点,如边缘、角点、表面凹凸点等。这些关键点有助于捕捉点云的结构和形状。
2. **选择锚点**:从提取的关键点中选择一部分作为锚点。这些锚点通常是在所有点云中都可以稳定检测到的点,具有良好的可重复性和区分性。
3. **配准过程**:在点云配准的过程中,锚点充当参考点,帮助算法找到不同点云之间的变换(平移、旋转、缩放等),使其在共同坐标系中对齐。
4. **优化**:通过优化方法,比如最小二乘法、迭代最近点(ICP)算法等,调整其他点的位置,使得点云之间的误差最小化。这样,可以将多个点云对齐到一个参考点云或共同的坐标系中。
使用点云 anchor keypoints 可以提高点云配准的效果,特别是在点云之间存在较大姿态变化或噪声的情况下。选择稳定的锚点有助于提高配准的准确性和可靠性,从而为后续的点云分析任务提供更好的基础。
在点云配准或特征匹配的任务中,一种常见的方法是计算点云中的锚关键点与其对应的关键点之间的特征距离,以衡量它们的相似性或匹配程度。这有助于确定点云之间的对应关系,进而实现点云的对齐或匹配。
特征距离的计算可以基于锚关键点和对应关键点之间的特征描述子或特征向量。一般来说,特征描述子是通过对点云中的局部区域进行特征提取得到的,用于表示点云的形状、法线、曲率等信息。计算特征距离的一种常见方法是使用欧氏距离或其他相似性度量方法。
以下是计算点云 锚关键点到对应的关键点的特征距离的一般步骤:
1. **特征提取**:对于点云中的锚关键点和对应关键点,分别提取特征描述子。这些描述子可以是点的法线、颜色直方图、表面特征等。
2. **计算特征距离**:使用适当的距离度量(如欧氏距离、余弦距离等),计算锚关键点的特征描述子与对应关键点的特征描述子之间的距离。
3. **相似性评价**:根据计算得到的特征距离,可以定义一个相似性度量,例如使用相似性分数或相似性矩阵,以衡量锚关键点与对应关键点之间的相似性。
4. **匹配策略**:基于相似性度量,可以使用不同的匹配策略,如最近邻匹配、最佳匹配等,来确定点云之间的对应关系。
需要注意的是,特征描述子的选择和距离度量方法会对特征距离的计算结果产生影响。在实际应用中,根据任务的需求和数据的特点,您可能需要尝试不同的方法和参数来获得最佳的匹配效果。
"Epoch" 是在机器学习和深度学习中常用的术语,用来表示一次完整的训练数据集在神经网络中的前向传播、反向传播的训练循环。在每个 epoch 中,训练数据会被输入到神经网络中进行训练,并且模型的权重会根据损失函数的反向传播进行更新。
在训练神经网络时,通常需要经过多个 epoch 才能使模型充分地学习训练数据中的模式和特征。每个 epoch 都可以看作是一个训练周期,其中模型对整个训练数据集进行了一次学习。
在每个 epoch 中,以下步骤通常会发生:
1. **前向传播**:将训练数据输入到神经网络中,通过网络的各层计算输出,得到预测值。
2. **计算损失**:将预测值与真实标签进行比较,计算模型的损失或误差。
3. **反向传播**:根据损失值,使用反向传播算法计算相对于每个参数的梯度。
4. **参数更新**:根据计算得到的梯度,使用优化算法(如梯度下降)来更新模型的参数,以减小损失函数。
5. **重复训练**:重复以上步骤,直到所有的训练数据都被用于训练,并且模型的参数逐渐收敛。
通常情况下,神经网络的训练会经过多个 epoch,以使模型逐渐优化并提高在训练数据以外的数据上的泛化能力。epoch 的数量是一个超参数,需要根据具体任务和数据集的大小来进行调整。较小的 epoch 数量可能导致模型欠拟合,而较大的 epoch 数量可能导致模型过拟合。因此,在训练神经网络时,选择适当的 epoch 数量是一个需要进行实验和调优的重要因素。
相关文章:
《论文阅读18》JoKDNet
一、论文 研究领域:用于大尺度室外TLS点云配准的联合关键点检测和特征表达网络论文:JoKDNet: A joint keypoint detection and description network for large-scale outdoor TLS point clouds registration International Journal of Applied Earth Ob…...

buuctf [CISCN 2019 初赛]Love Math
这题主要利用了php的一些特性 变量函数数字转字符串 源码 <?php error_reporting(0); //听说你很喜欢数学,不知道你是否爱它胜过爱flag if(!isset($_GET[c])){show_source(__FILE__); }else{//例子 c20-1$content $_GET[c];if (strlen($content) > 80) {…...
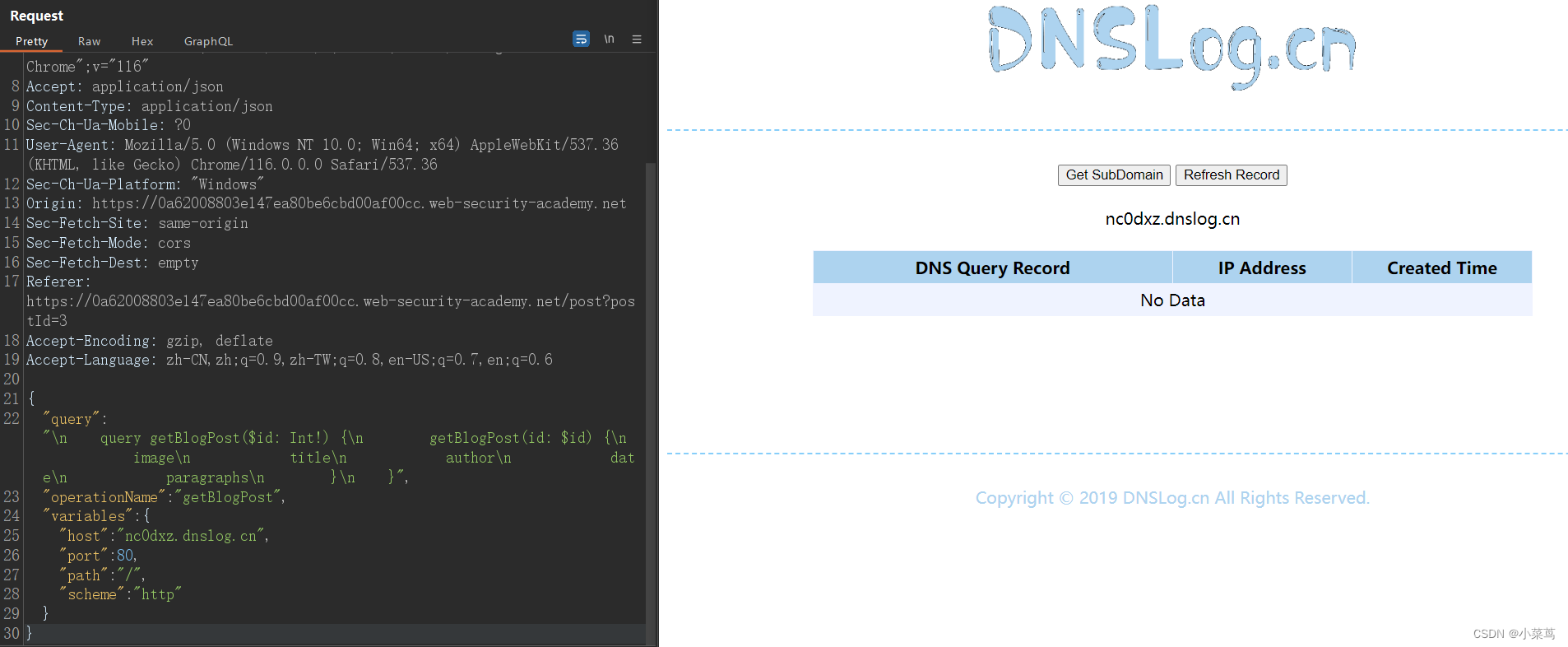
GraphQL渗透测试案例及防御办法
什么是GraphQL GraphQL 是一种 API 查询语言,旨在促进客户端和服务器之间的高效通信。它使用户能够准确指定他们在响应中所需的数据,从而有助于避免有时使用 REST API 看到的大型响应对象和多个调用。 GraphQL 服务定义了一个合约,客户端可…...
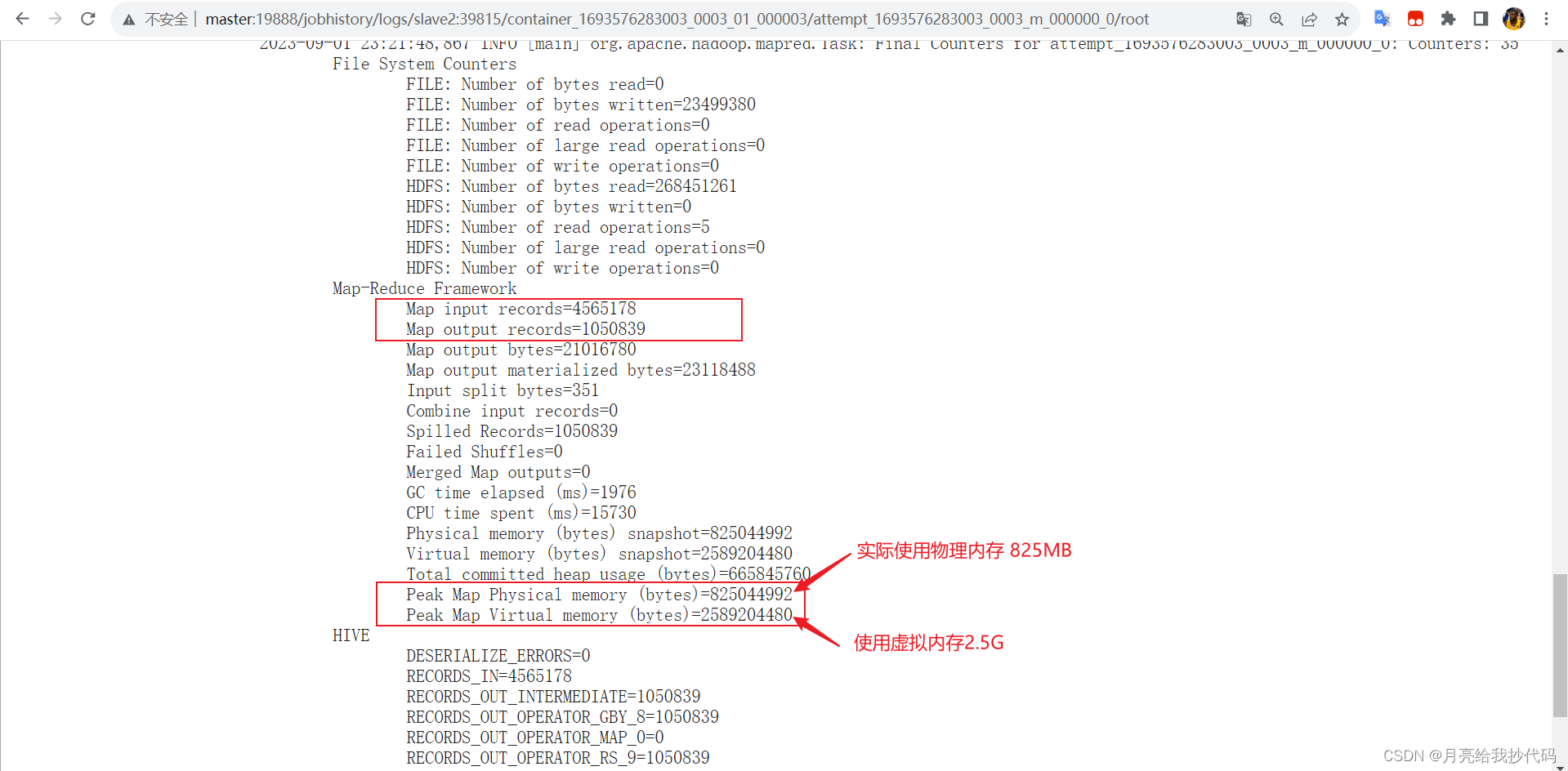
Hive SQL 优化大全(参数配置、语法优化)
文章目录 参数配置优化yarn-site.xml 配置文件优化mapred-site.xml 配置文件优化 分组聚合优化 —— Map-Side优化参数解析优化案例 服务器环境说明 机器名称内网IP内存CPU承载服务master192.168.10.1084NodeManager、DataNode、NameNode、JobHistoryServer、Hive、HiveServer…...
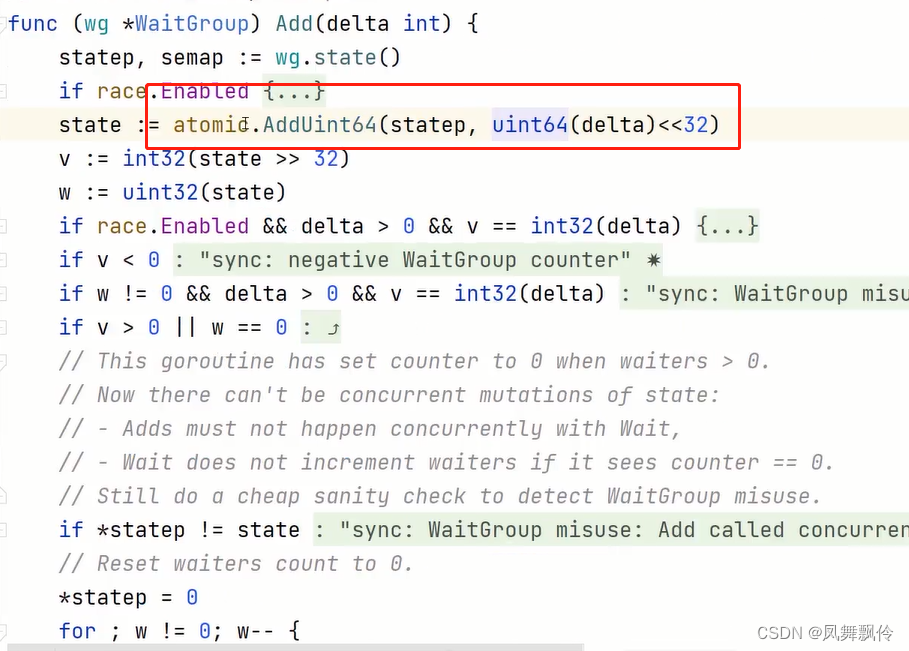
go锁-waitgroup
如果被等待的协程没了,直接返回 否则,waiter加一,陷入sema add counter 被等待协程没做完,或者没人在等待,返回 被等待协程都做完,且有人在等待,唤醒所有sema中的协程 WaitGroup实现了一组协程…...
访问0xdddddddd内存地址引发软件崩溃的问题排查
目录 1、问题描述 2、访问空指针或者野指针 3、常见的异常值 4、0xdddddddd内存访问违例问题分析与排查 5、关于0xcdcdcdcd和0xfeeefeee异常值的排查案例 6、最后 VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)ht…...
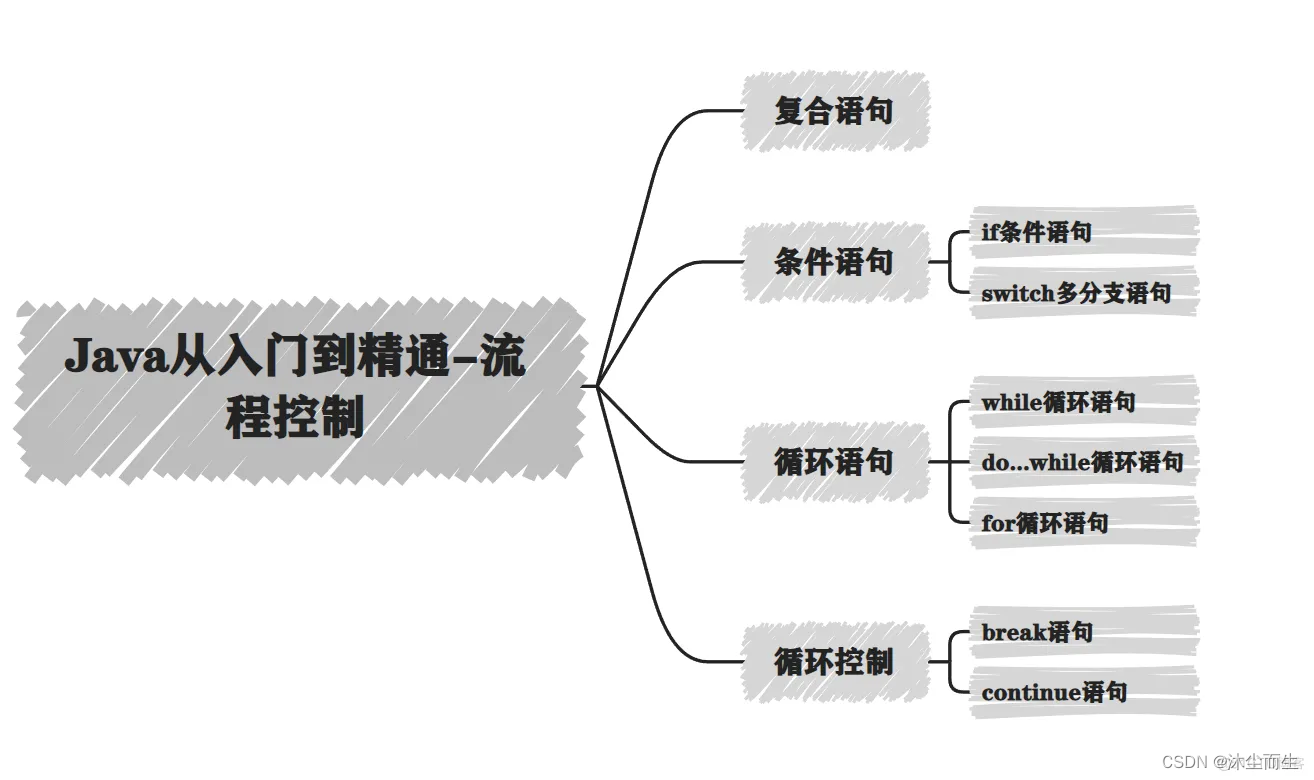
Java从入门到精通-流程控制(一)
流程控制 1.复合语句 复合语句,也称为代码块,是一组Java语句,用大括号 {} 括起来,它们可以被视为单个语句。复合语句通常用于以下情况: - 在控制结构(如条件语句和循环)中包含多个语句。 - …...

MybatisPlus(2)
前言🍭 ❤️❤️❤️SSM专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️ Spring Spring MVC MyBatis_冷兮雪的博客-CSDN博客 上篇我们简单介绍了MybatisPlus的方便之处,这篇来深入了解Myb…...

iOS UITableView上拉加载解决偶然跳动的Bug
最近做项目,测试测出来一个Bug,列表添加了上拉刷新和下拉加载,当我弹窗消失时,调用刷新列表后,在某个手机型号上,偶发列表刷新跳动的bug。(一般在列表上拉加载刷新到最后一页后,再弹窗消失,reload列表,会出现此bug) Bug复现如下:RPReplay_Final1693296737 解决方案…...

MySQL 外键使用详解
1、MySQL 外键约束语法 MySQL 支持外键,允许在表之间进行相关数据的交叉引用,并有助于保持相关数据的一致性。 一个外键关系涉及到一个父表,该父表保存初始列值,和一个子表,子表的列值引用父表的列值。外键约束定义在…...

MongoDB实验——在MongoDB集合中查找文档
在MongoDB集合中查找文档 一、实验目的二、实验原理三、实验步骤1.启动MongoDB数据库、启动MongoDB Shell客户端2.数据准备-->person.json3.指定返回的键4 .包含或不包含 i n 或 in 或 in或nin、$elemMatch(匹配数组)5.OR 查询 $or6.Null、$exists7.…...

事务的总结
数据库事务 数据库事务是一个被视为单一的工作单元的操作序列。这些操作应该要么完整地执行,要么完全不执行。事务管理是一个重要组成部分,RDBMS 面向企业应用程序,以确保数据完整性和一致性。事务的概念可以描述为具有以下四个关键属性描述…...
[ROS]yolov5-7.0部署ROS
YOLOv5是一种目标检测算法,它是YOLO(You Only Look Once)系列算法的最新版本。与其它目标检测算法相比,YOLOv5在速度和准确性方面取得了显著的提升。在ROS(Robot Operating System)中使用Python部署YOLOv5可…...

Java抽象方法、抽象类和接口——第七讲
前言 上一讲,我们深入了解面向对象,介绍了面向对象有三个特征——封装、继承、多态,以及介绍方法的重载和重写,这些都是开发中很常用的特征,基本都尊重面向对象思想。再上一讲我们了解到了继承的时候,子类要重新写父类的方法,才能遵循子类的规则,那么忘记重写怎么办呢?…...
kafka集群之kraft模式
一、概要 Kafka作为一种高吞吐量的分布式发布订阅消息系统,在消息应用中广泛使用,尤其在需要实时数据处理和应用程序活动跟踪的场景,kafka已成为首选服务;在Kafka2.8之前,Kafka强依赖zookeeper来来负责集群元数据的管理…...

虹科案例 | 缆索挖掘机维护—小传感器,大作用!
一、 应用背景 缆索挖掘机 缆索挖掘机的特点是具有坚固的部件,如上部结构、回转环和底盘。底盘是用于移动挖掘机的下部机械部件,根据尺寸和型号的不同,由轮子或履带引导,并承载可转动的上部车厢。回转环连接上部和下部机器部件&am…...
Windows安装FFmpeg说明
下载地址 官网 Download FFmpeg Csdn ffmpeg安装包,ffmpeg-2023-08-28-git-b5273c619d-full-build.7z资源-CSDN文库 解压安装,添加环境变量 命令行输入ffmpeg 安装成功...

电子电路原理题目整理(1)
电子电路原理题目整理(1) 最近在学习《电子电路原理》,记录一下书后面试题目,答案为个人总结,欢迎讨论。 1.电压源和电流源的区别? 电压源在不同的负载电阻下可提供恒定的负载电压,而电流源对于…...
iPhone 15预售:获取关键信息
既然苹果公司将于9月12日正式举办iPhone 15发布会,我们了解所有新机型只是时间问题。如果你是苹果的狂热粉丝,或者只是一个早期用户,那么活动结束后,你会想把所有的注意力都集中在iPhone 15的预购上——这样你就可以保证自己在发布日会有一款机型。 有很多理由对今年的iPh…...
Kind创建本地环境安装Ingress
目录 1.K8s什么要使用Ingress 2.在本地K8s集群安装Nginx Ingress controller 2.1.使用Kind创建本地集群 2.1.1.创建kind配置文件 2.1.2.执行创建命令 2.2.找到和当前k8s版本匹配的Ingress版本 2.2.1.查看当前的K8s版本 2.2.2.在官网中找到对应的合适版本 2.3.按照版本安…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...

Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析
Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析 一、第一轮基础概念问题 1. Spring框架的核心容器是什么?它的作用是什么? Spring框架的核心容器是IoC(控制反转)容器。它的主要作用是管理对…...
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡 背景 我们以建设星云智控官网来做AI编程实践,很多人以为AI已经强大到不需要程序员了,其实不是,AI更加需要程序员,普通人…...
Android屏幕刷新率与FPS(Frames Per Second) 120hz
Android屏幕刷新率与FPS(Frames Per Second) 120hz 屏幕刷新率是屏幕每秒钟刷新显示内容的次数,单位是赫兹(Hz)。 60Hz 屏幕:每秒刷新 60 次,每次刷新间隔约 16.67ms 90Hz 屏幕:每秒刷新 90 次,…...