【爬虫】实验项目一:文本反爬网站的分析和爬取
目录
一、实验目的
二、实验预习提示
编辑
三、实验内容
四、实验要求
五、实验过程
1. 基本要求:
2. 改进要求A
3. 改进要求B:
六、资料
1.实验框架代码:
2.OpenSSL:Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions (slproweb.com)
3.Josn存储,先安装json包:
4.实验小提示
七、源码
一、实验目的
熟悉使用Selenium、Pyppeteer等工具爬取网站基本内容,通过分析具有文本反爬技术网站,设计爬取策略来获取文本正确的内容。
二、实验预习提示
- 安装Python环境 (Python 3.x):Pychram+Anaconda
- 为Python安装Selenium、PyQuery库(打开pycharm新建项目,选择Anaconda创建的Python环境,在下面对应Console窗口执行):
pip install selenium
pip install pyquery- 安装Chrome和对应ChromeDriver:
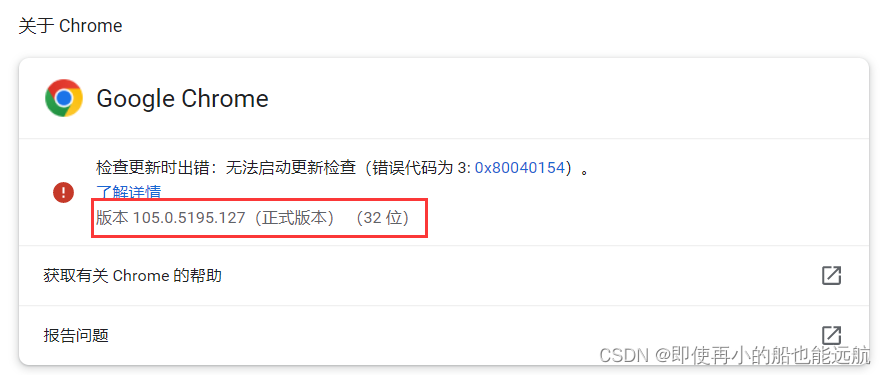
下载安装完后查看Chrome版本:点击 Chrome 的菜单,帮助 -> 关于 Chrome,即可查看 Chrome 的版本号105.0.5195.127,如图所示:
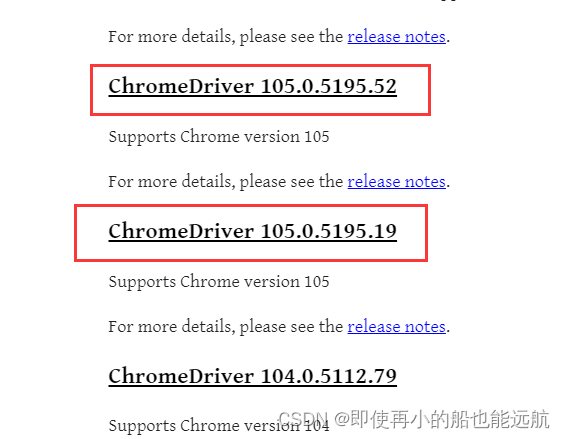
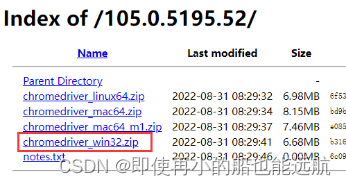
在ChromeDriver 官方网站ChromeDriver - WebDriver for Chrome - Downloads (chromium.org)下载Chrome版本对应的驱动(105.0.5195.x, 看主版本号105都行),点击下划线的链接,根据系统型号下载。windows下chromedriver_win32.zip,其他系统找到对应版本下载:
下面这部分配置环境变量内容【到图片结束(包含图片)】可以省略,参考最新内容【爬虫】5.2 Selenium编写爬虫程序_即使再小的船也能远航的博客-CSDN博客
运行代码前配置系统环境变量Path前指定chrome driver位置:
Path=替换为chrome driver解压后的位置
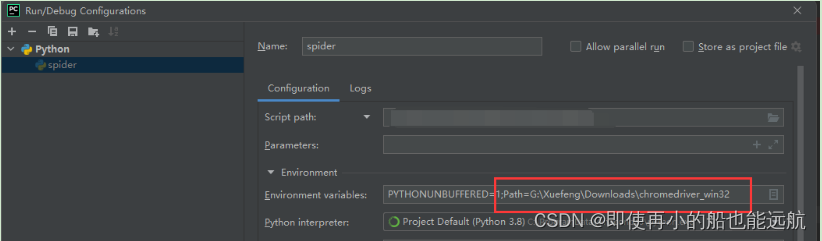
或者在Pycharm运行配置指定:
三、实验内容
爬取网站:Scrape | Book
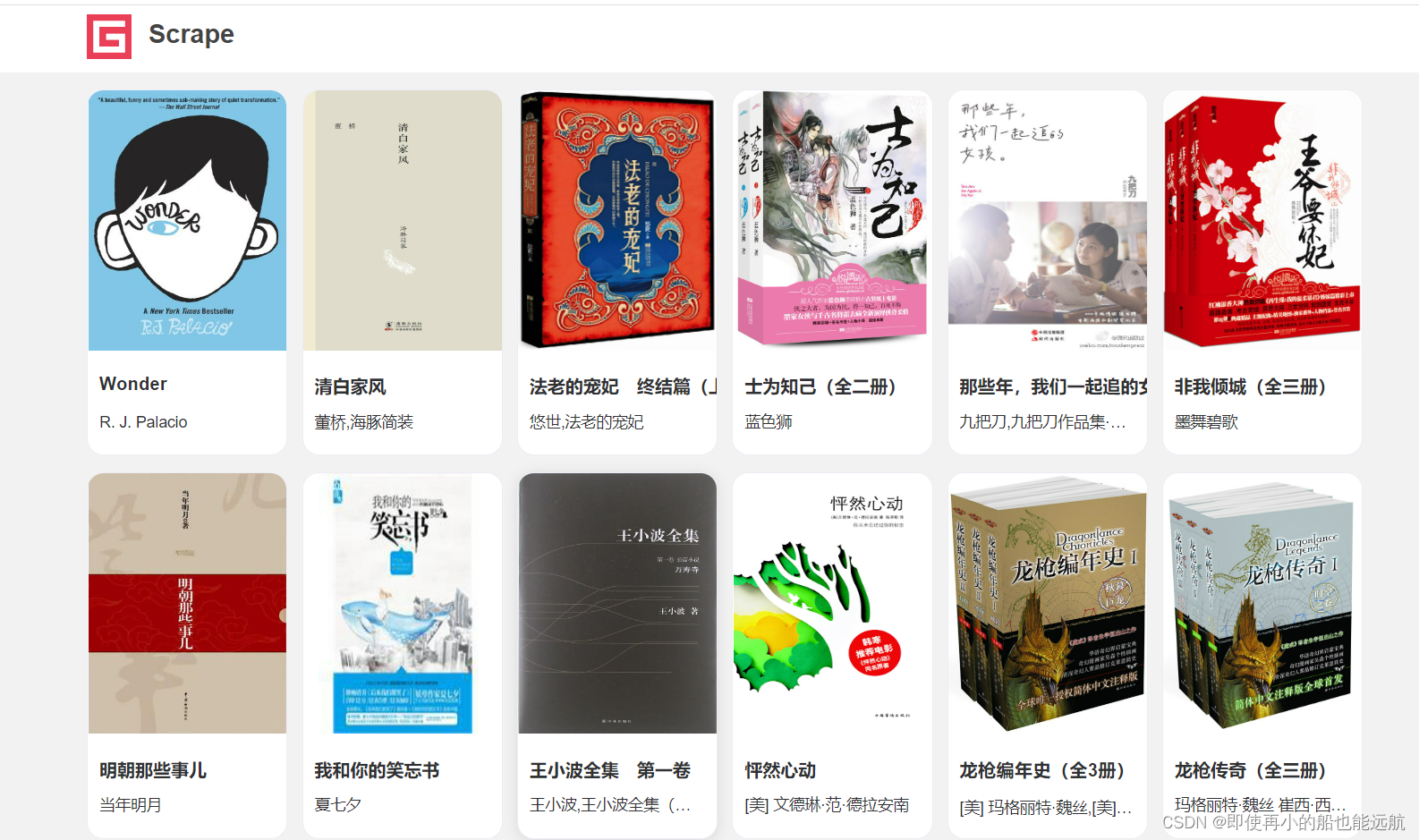 使用浏览器开发者工具(F12),分析网站结构和其中文本反爬机制,编码实现获取该网站每本书的封面图片URL、书名和作者信息。实验基框架代码见文档末资料。
使用浏览器开发者工具(F12),分析网站结构和其中文本反爬机制,编码实现获取该网站每本书的封面图片URL、书名和作者信息。实验基框架代码见文档末资料。
四、实验要求
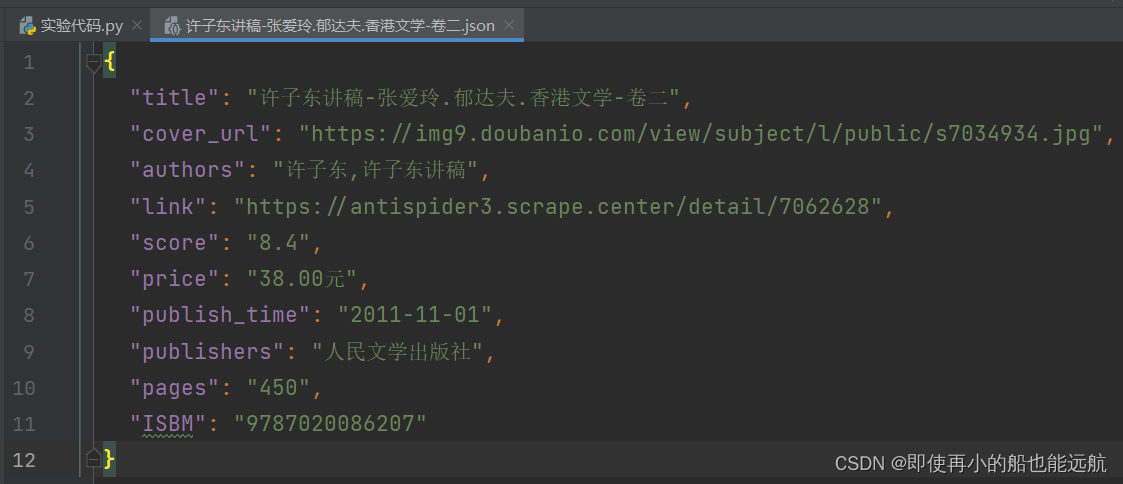
基本要求:将网站一页每本书的信息保存在一个josn文件中,每个json文件命名为:书名.json,其内容为保存书籍相应的信息:
{"title": "Wonder","cover_url":"https://img1.doubanio.com/view/subject/l/public/s27252687.jpg","authors":"R. J. Palacio"
}实现方法不一定要用Selenium、Pyppeteer,但是必须是Python编写的,并以完成实验要求为准,并附上代码运行结果。
改进要求A:在完成基本要求的基础上,选项一:实现可以遍历网站的每一页来爬取书籍信息。或指定爬取条目数量,当爬取总条目满足数量后停止爬取。选项二:或者举例至少三个其他网站的文本爬虫技术,分析并给出解决方案,不需要实现。
改进要求B:在完成改进要求A的选项一的基础上,可以爬取书籍的额外信息,如评分,出版时间,出版社,ISBM, 价格等。
五、实验过程
1. 基本要求:
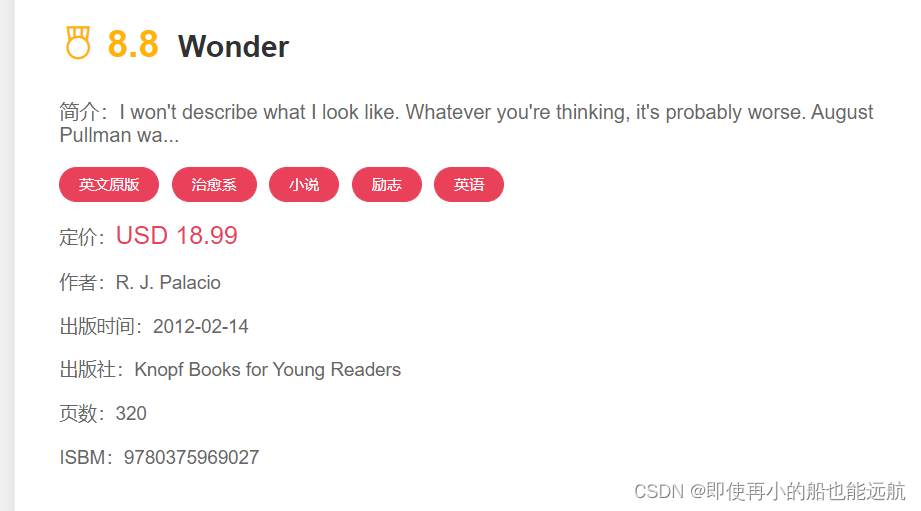
想要爬取网页内容,首先得分析网页结构,查看源代码如下图所示,

- 点击封面有对应该书得二级页面(详情)后半部分地址(改进要求B用);
- 书的封面URL可以用img.class查询;
# 获取书籍封面图片url
for tag in soup.select("img.cover"):pics.append(tag.attrs['src'])- 书名都在h3标题中,如果是英文书名,直接h3.name即可,但中文书名由多个class="char"的SPAN元素组成,这里用到了文本反爬机制,利用CSS控制文本偏移来实现文本顺序改变。但不难发现其文本偏移由left属性决定原文正确顺序,因此需要按偏移left属性值大小升序排序获取正确的文本顺序。
# 获取书籍名字
for tag in soup.select("h3.name"):if "whole" in tag.attrs['class']:names.append(tag.text)else:chars = tag.select("span.char")chars = sorted(chars, key=lambda a: eval(a.attrs['style'][6:-3]))name = ""for char in chars:name += char.text.strip()names.append(name)- 作者可以直接p.class查询
# 获取作者名字
for tag in soup.select("p.authors"):authors.append(tag.text.strip().replace(" ", "").replace("\n", ""))2. 改进要求A
这里实现的是选项一:实现可以遍历网站的每一页来爬取书籍信息。从游览器url: https://antispider3.scrape.center/page/2 得之每页都是在后边加/page/页数,这不难实现,就是写个文本数字追加到url后即可;
url = "https://antispider3.scrape.center/page/"
page_start = int(input("请指定爬取起始页(包含该页):"))
page_end = int(input("请指定爬取结束页(不包含该页):"))
for i in range(page_start, page_end):names, pics, authors, links = get_cover(url + str(i))
指定爬取条目数量,当爬取总条目满足数量后停止爬取,这个就是在循环爬取写个计数器,爬取到指定数目,break即可,但只得注意的是:指定数量超过一页18条时,继续下一页爬取,也可以直接加在上述代码里,把结束页可以给的很大,用计数器break即可,不会造成伪死循环。
3. 改进要求B:
从上图页面分析得知:每本书得二级页面都是在https://antispider3.scrape.center后加/detail/数字,该部分网址在a标签得href属性里,由于页面里超链接很多,所以先find_all出div下的class=el-col el-col-24,这里用得class_是为了解决class是python中的关键字问题,爬取后与原始url拼接即可。
# 获取每本书对用url(二级页面)
tags = soup.find_all('div', class_='el-col el-col-24')
print(len(tags))
for tag in [tags[i] for i in range(len(tags)) if i % 2 == 0]:link = tag.find('a').get('href')links.append(url1 + link)
print(links)现在得到了每本书得二级页面得url,就可以分析二级页面页面结构,来爬取相应书籍信息,分析如下所示:
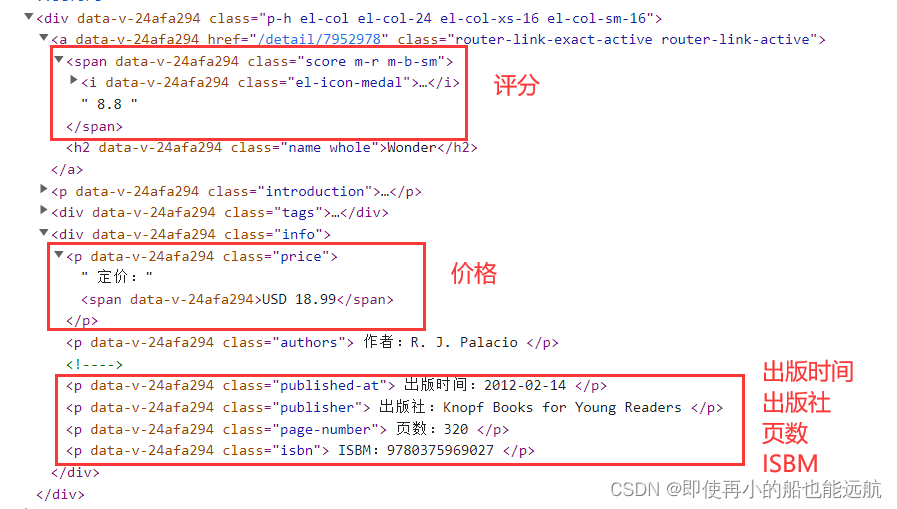
二级页面结构其实还是清新明了的,出了评分时span标签,再其他都是p标签,这里只爬取了上图标注的信息数据,再爬取其他的都是一样的,换汤不换药,其实就换个class就OK,这里不做过多介绍。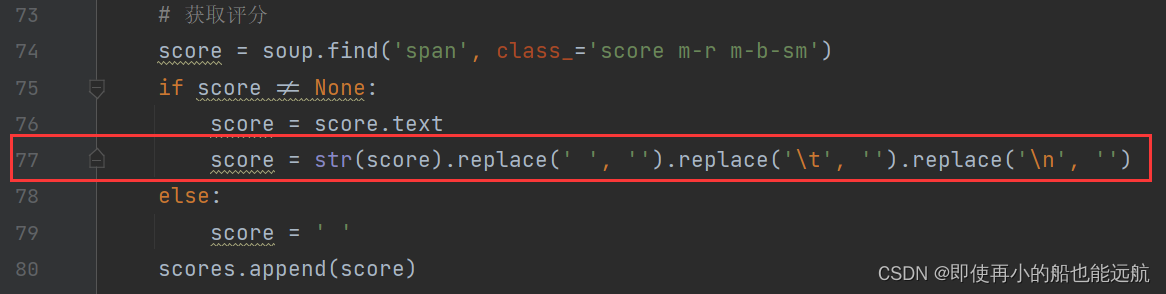
由于爬取页面过多,发现问题:有些书籍没有出版社,页数等,所以这里统一用None,没有的数据就用统一添加该字段去空即可,如做特殊处理,识别没有的信息,每个属性都要增加相同的代码,代码冗余度太高,学术水平限制,这里没想到其他好的方法,所以没有做特殊处理。爬取下来的数据由于中间有很多空格与\n,如下所示

这里就用到77行一系列的替换,使达到想要的格式,其他类似。
下面介绍主函数部分:
这里将每本书的二级页面的url赋给对应属性
for link in links:print(link)score, price, publishtime, publisher, page, isbm = get_details(link)这里遍历出每本书的信息保存在以书名为名称的json文件中。
for i in range(len(names)):book = {"title": names[i],"cover_url": pics[i],"authors": authors[i],"link": links[i],"score": scores[i],"price": prices[i],"publish_time": publishtimes[i],"publishers": publishers[i],"pages": pages[i],"ISBM": isbms[i]}data_path = f'{book["title"]}.json'json.dump(book, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)最后附上爬取结果:
本次实现总结:
计算机专业的课程只理论不实践那就例如纸上谈兵,本次实践说简单也不难,但有些点还是触及我的知识盲区了,例如span char的书名,实践是检验真理的唯一标准。爬虫技术有限,每次爬二级页面都要加载打开,很浪费时间的,后期学了更多的知识,再来解决此问题吧。
六、资料
1.实验框架代码:
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('https://antispider3.scrape.center/')
WebDriverWait(browser, 10) \.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))
html = browser.page_source
doc = pq(html)
names = doc('.item .name')
for name in names.items():print(name.text())2.OpenSSL:Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions (slproweb.com)
3.Josn存储,先安装json包:
import jsonbook = {"title": "Wonder","cover_url":"https://img1.doubanio.com/view/subject/l/public/s27252687.jpg","authors":"R. J. Palacio"}data_path = f'{book["title"]}.json'
json.dump(book, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)4.实验小提示
可以根据HTML结构发现每个书籍信息都保存在。有的书名放在class="name whole"的H3元素,有书名由多个class="char"的SPAN元素组成。对于放在H3元素的书名,直接取出其元素内容即可,而对于放在多个SPAN元素中的书名,这里用到了文本反爬机制,利用CSS控制文本偏移来实现文本顺序改变。但不难发现其文本偏移由left属性决定原文正确顺序,因此需要按偏移left属性值大小升序排序获取正确的文本顺序。
七、源码
import json
import warnings
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from bs4 import BeautifulSoup# 定义容器用来存储书籍的信息
names = [] # 书籍名字
authors = [] # 书籍作者
pics = [] # 书籍封面图片
links = [] # 链接
scores = [] # 评分
prices = [] # 定价
publishtimes = [] # 出版时间
publishers = [] # 出版社
pages = [] # 页数
isbms = [] # ISBM# 获取书籍分面信息与对应书籍二级页面url
def get_cover(url):warnings.filterwarnings('ignore')browser = webdriver.Chrome()browser.get(url)WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))html = browser.page_sourcedoc = pq(html)# 使用BeautifulSoup进行解析网页soup = BeautifulSoup(doc.html(), "html.parser")browser.close()# 获取书籍名字for tag in soup.select("h3.name"):if "whole" in tag.attrs['class']:names.append(tag.text)else:chars = tag.select("span.char")chars = sorted(chars, key=lambda a: eval(a.attrs['style'][6:-3]))name = ""for char in chars:name += char.text.strip()names.append(name)# 获取作者名字for tag in soup.select("p.authors"):authors.append(tag.text.strip().replace(" ", "").replace("\n", ""))# 获取书籍封面图片urlfor tag in soup.select("img.cover"):pics.append(tag.attrs['src'])# 获取每本书对用url(二级页面)tags = soup.find_all('div', class_='el-col el-col-24')print(len(tags))for tag in [tags[i] for i in range(len(tags)) if i % 2 == 0]:link = tag.find('a').get('href')links.append(url1 + link)print(links)return names, pics, authors, links# 获取每本书的详细信息(二级页面信息)
def get_details(url):warnings.filterwarnings('ignore')browser = webdriver.Chrome()browser.get(url)WebDriverWait(browser, 300).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))html = browser.page_sourcedoc = pq(html)# 使用BeautifulSoup进行解析网页soup = BeautifulSoup(doc.html(), "html.parser")# 获取评分score = soup.find('span', class_='score m-r m-b-sm')if score != None:score = score.textscore = str(score).replace(' ', '').replace('\t', '').replace('\n', '')else:score = ' 'scores.append(score)# 获取定价price = soup.find('p', class_='price')if price != None:price = price.textprice = str(price).replace(' ', '').replace('\t', '').replace('\n', '').split(':')[1]else:price = ' 'prices.append(price)# 获取出版时间publishtime = soup.find('p', class_='published-at')if publishtime != None:publishtime = publishtime.textpublishtime = str(publishtime).replace(' ', '').replace('\t', '').replace('\n', '').split(':')[1]else:publishtime = ' 'publishtimes.append(publishtime)# 获取出版社publisher = soup.find('p', class_='publisher')if publisher != None:publisher = publisher.textpublisher = str(publisher).replace(' ', '').replace('\t', '').replace('\n', '').split(':')[1]else:publisher = ' 'publishers.append(publisher)# 获取页数page = soup.find('p', class_='page-number')if page != None:page = page.textpage = str(page).replace(' ', '').replace('\t', '').replace('\n', '').split(':')[1]else:page = ' 'pages.append(page)# 获取ISBMisbm = soup.find('p', class_='isbn')if isbm != None:isbm = isbm.textisbm = str(isbm).replace(' ', '').replace('\t', '').replace('\n', '').split(':')[1]else:isbm = ' 'isbms.append(isbm)browser.close()return score, price, publishtime, publisher, page, isbmif __name__ == '__main__':url1 = "https://antispider3.scrape.center"url = "https://antispider3.scrape.center/page/"page_start = int(input("请指定爬取起始页(包含该页):"))page_end = int(input("请指定爬取结束页(不包含该页):"))for i in range(page_start, page_end):names, pics, authors, links = get_cover(url + str(i))for link in links:print(link)score, price, publishtime, publisher, page, isbm = get_details(link)for i in range(len(names)):book = {"title": names[i],"cover_url": pics[i],"authors": authors[i],"link": links[i],"score": scores[i],"price": prices[i],"publish_time": publishtimes[i],"publishers": publishers[i],"pages": pages[i],"ISBM": isbms[i]}data_path = f'{book["title"]}.json'json.dump(book, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)
下一篇文章: 实验项目二:模拟登录和数据持久化
相关文章:
【爬虫】实验项目一:文本反爬网站的分析和爬取
目录 一、实验目的 二、实验预习提示 编辑 三、实验内容 四、实验要求 五、实验过程 1. 基本要求: 2. 改进要求A 3. 改进要求B: 六、资料 1.实验框架代码: 2.OpenSSL:Win32/Win64 OpenSSL Installer for Windows - Shining Light…...

DEAP库文档教程二-----创建类型
本节将展示如何通过creator创建类型以及如何使用toolbox进行初始化。 1、Fitness 已经提供的Fitness类是一个抽象类,它需要weight来使得它成为一个函数。一个最小化的适应度是通过负权重构建的,而一个最大化适应度则需要正权重。 creator.create(&quo…...
Axure RP美容美妆医美行业上门服务交互原型图模板源文件
Axure RP美容美妆医美行业上门服务交互原型图模板源文件,原型内容属于电商APP,区别于一般电商,它的内容是‘美容美发美妆等’上门服务等。大致流程是线上买单,线下实体店核销消费。 附上预览演示:axure9.com/mobile/73…...

【SpringBoot】用SpringBoot代码详细解释<List>的用法
在Spring Boot应用程序中,我们可以使用Java集合框架中的List接口来存储并操作一组数据。 List是Java集合框架中的一种数据结构,用于存储一组有序的元素。使用List可以方便地向其中添加、删除或者修改元素,也可以通过下标或者迭代器遍历其中的…...
HRS--人力资源系统(Springboot+vue)--打基础升级--(六)分页查询 + 重置按钮
一:先弄个简单的重置按钮 1.界面设计就放在搜索框同一列的位置 2. 在点击重置按钮时,清空搜索框内的内容,同时触发一次无条件查询(这个写法有bug,下面会有说明) 二:做分页 在MyBatis中,有多种方法可以实现分…...

JavaScript设计模式(二)——简单工厂模式、抽象工厂模式、建造者模式
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...
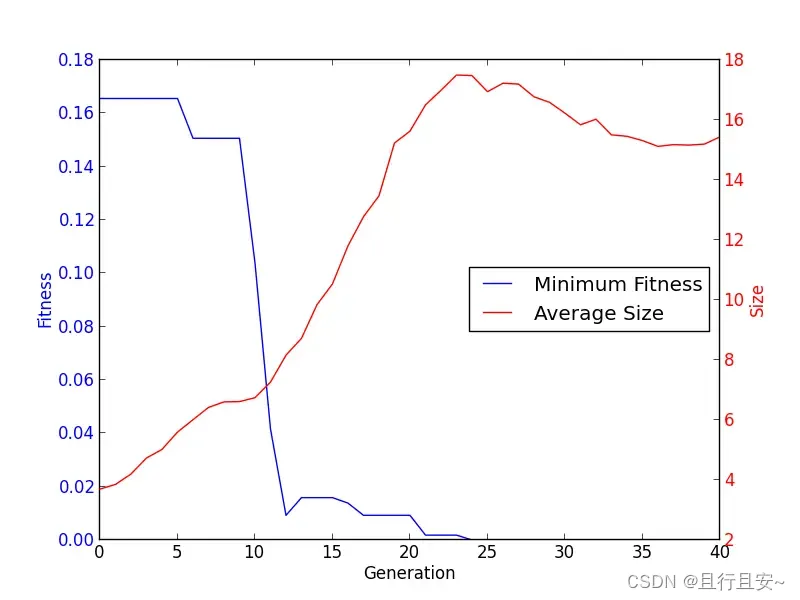
DEAP库文档教程五----计算统计
本小结将重点围绕模型在计算统计方面的问题,进行详细的论述 1、Computing Statistics 通常情况下,我们想要在优化过程中编辑数据。Statistic模块可以在任何设计好的目标上改变一些本不可改变的数据。为了达到这个目的,需要使用与工具箱中完…...

新型安卓恶意软件使用Protobuf协议窃取用户数据
近日有研究人员发现,MMRat新型安卓银行恶意软件利用protobuf 数据序列化这种罕见的通信方法入侵设备窃取数据。 趋势科技最早是在2023年6月底首次发现了MMRat,它主要针对东南亚用户,在VirusTotal等反病毒扫描服务中一直未被发现。 虽然研究…...

【AI数字人】如何基于DINet+Openface自训练AI数字人
文章目录 OpenFace环境配置提取特征特征处理DINet推理数据前处理训练frame training stageclip training stage参考DINet训练/推理过程中需要用到OPenFace的人脸数据,所以使用DINet训练定制数字人,需要配置OPenFace和DINet两个项目的环境。我是使用conda创建了一个dinet的虚拟…...
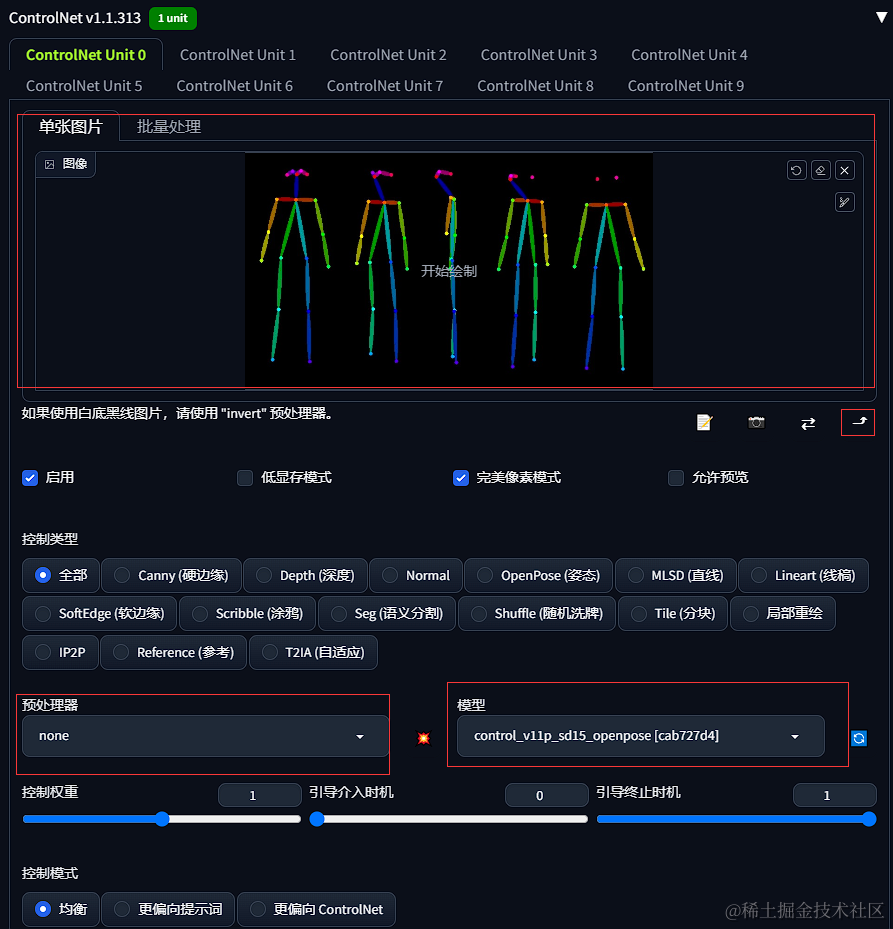
Stable Diffusion 多视图实践
此教程是基于秋叶的webui启动器 1.Stable Diffsuion 使用多视图需要准备一个多角度open pose 图 我给大家提供一个可使用的。 2.需要添加图片到到controlnet当中,不要选择预处理器,选择模型为openpose的模型,然后需要点选同步图片尺寸。 3.然后填写关键字可以参照一下这个…...
【实操干货】如何开始用Qt Widgets编程?(四)
Qt 是目前最先进、最完整的跨平台C开发工具。它不仅完全实现了一次编写,所有平台无差别运行,更提供了几乎所有开发过程中需要用到的工具。如今,Qt已被运用于超过70个行业、数千家企业,支持数百万设备及应用。 在本文中࿰…...

解决window安装docker报错问题
第一次打开Docker Desktop后提示错误 试了网上版本都没用,后面发现是电脑没有下载相关虚拟机: 先点击链接下载wsl2,下载后命令行执行:dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /…...

茄子科技面试题
1、RPC的重要组成有哪些? 客户端(Client):发起RPC请求的部分。客户端包含代表远程过程的存根(stub),它提供与本地过程相同的接口。 服务器(Server):接受RPC请…...
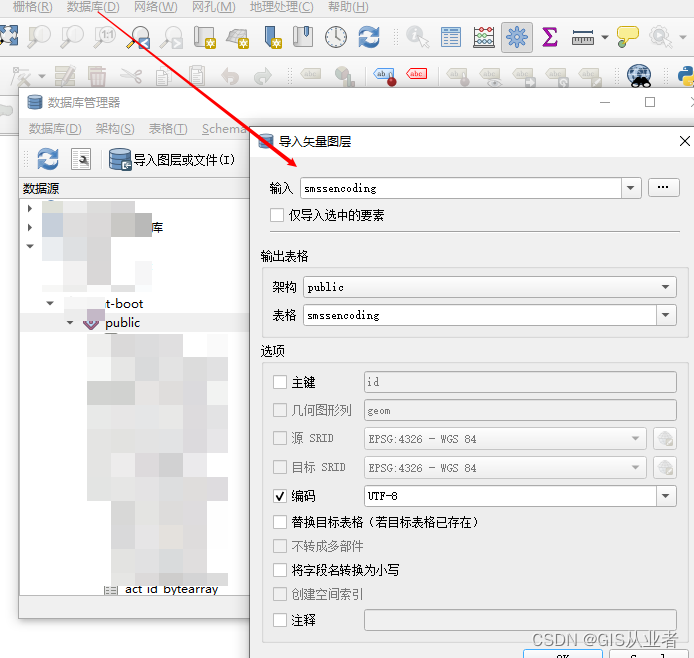
postgis数据库导出csv表再导入postgis
1、导出csv表 from settings_Address import * from sqlalchemy import create_engine, MetaData import pandas as pd def create_conn(Postgis_user,Postgis_password,Postgis_host,Postgis_port,dbname_PG):# return create_engine(PostgispyPostgis://{}:{}{}:{}/{}.forma…...

MySQL 特殊字符
文章目录 1.注释符2.字符串符3.反引号4.模式匹配通配符转义符 参考文献 1.注释符 SQL 注释是用来在 SQL 语句中添加对代码的解释说明。SQL 支持两种类型的注释符号。 单行注释:使用两个连续的减号(–)表示。减号后面的内容将被视为注释&…...
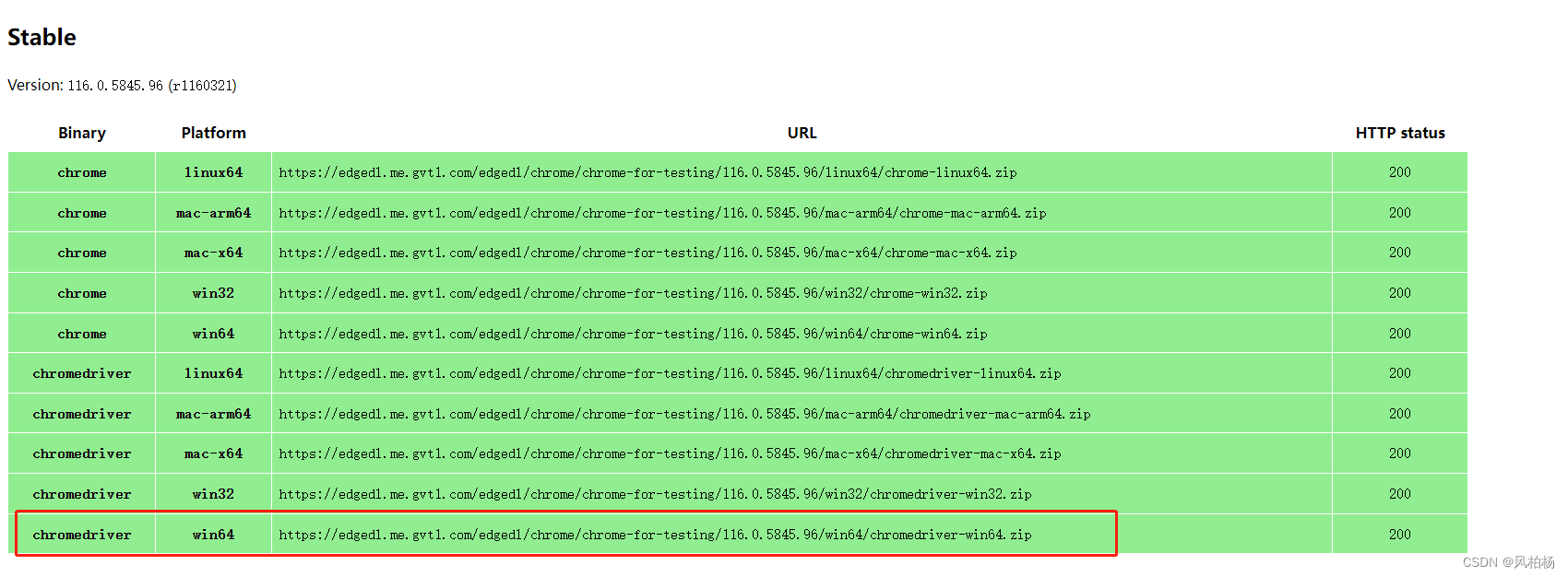
Chrome自动升级了,找不到最新版本的webdriver怎么办?
Chrome自动升级了,找不到最新版本的webdriver怎么办? 背景解决办法 背景 我用Selenium开发了Facebook和Linkedin爬虫,有些新需求要调一下,今天启动selenium时有报错,报错如下:selenium.common.exceptions.SessionNotCreatedExce…...
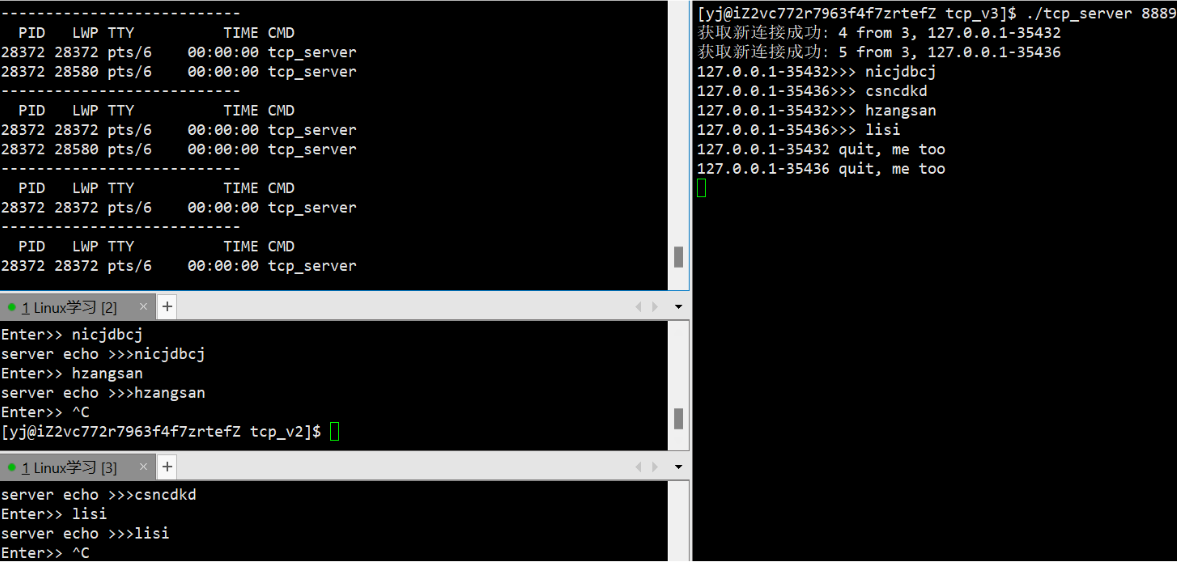
网络编程套接字(3): 简单的TCP网络程序
文章目录 网络编程套接字(3)4. 简单的TCP网络程序4.1 服务端创建(1) 创建套接字(2) 绑定端口(3) 监听(4) 获取新连接(5) 处理读取与写入 4.2 客户端创建(1)连接服务器 4.3 代码编写(1) v1__简单发送消息(2) v2_多进程版本(3) v3_多线程版本(4) v4_线程池版本 网络编程套接字(3)…...
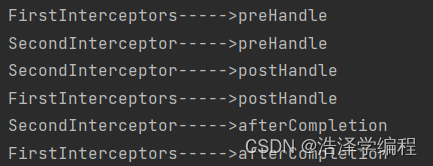
springMVC之拦截器
文章目录 前言一、拦截器的配置二、拦截器的三个抽象方法三、多个拦截器的执行顺序总结 前言 拦截器 一、拦截器的配置 SpringMVC中的拦截器用于拦截控制器方法的执行 SpringMVC中的拦截器需要实现HandlerInterceptor SpringMVC的拦截器必须在SpringMVC的配置文件中进行配置&…...

docker搭建个人网盘和私有仓库Harbor
目录 1、使用mysql:5.7和 owncloud 镜像,构建一个个人网盘 2、安装搭建私有仓库 Harbor 1、使用mysql:5.7和owncloud,构建一个个人网盘 1.拉取mysql:5.6镜像,并且运行mysql容器 [rootnode8 ~]# docker pull mysql:5.7 [rootnode8 ~]# doc…...
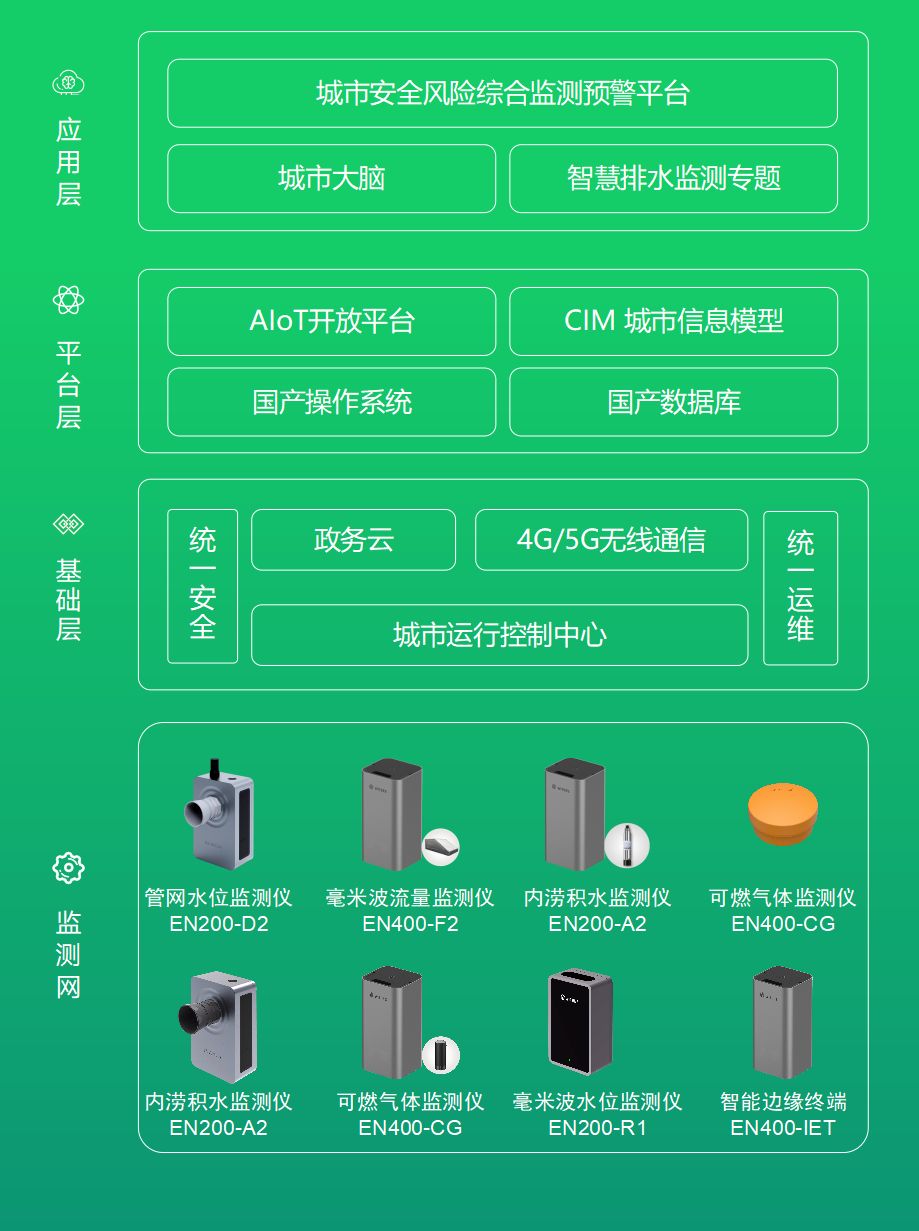
智慧排水监测系统,科技助力城市排水治理
城市里,人们每天通过道路通行,人多,路窄,都会拥堵。同样,下雨天,雨水通过雨篦汇集、管道输送,最终排出去,当雨水过大,或者管道过窄,或者管道不通畅࿰…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...