【爬虫小知识】如何利用爬虫爬网页——python爬虫
前言
网络时代的到来,给我们提供了海量的信息资源,但是,想要获取这些信息,手动一个一个网页进行查找,无疑是一项繁琐且效率低下的工作。这时,爬虫技术的出现,为我们提供了一种高效的方式去获取网络上的信息。利用爬虫技术,我们可以自动化地爬取大量的数据,帮助我们快速地获取所需信息,并且在一定程度上提高了工作效率。

本文将介绍如何使用 Python 爬虫爬取网页,并使用代理 IP 来避免被封禁。我们会提供一些代码示例和实际应用场景的案例。
一、使用 Python 爬虫爬取网页
Python 有很多强大的网络爬虫库可供使用,比如 requests、Beautiful Soup 和 Scrapy 等。在这里我们以 requests 库为例来介绍如何使用 Python 爬虫爬取网页。
1. 安装 requests 库
在使用 requests 库之前,需要先安装它。可以通过 pip 来进行安装,命令如下:
pip install requests2. 发送 HTTP 请求
使用 requests 库发送 HTTP 请求非常简单,只需要调用 requests.get() 函数即可。以下是一个示例代码:
import requestsurl = 'https://www.example.com'
response = requests.get(url)
html = response.text
print(html)上述代码中,我们首先定义了要访问的网址 url,然后调用 requests.get() 函数来发送 HTTP GET 请求,并将返回的 HTML 内容保存在变量 html 中,最后用 print() 函数将其输出。
3. HTTP 请求的参数与响应
requests.get() 函数可以接收一些额外的参数来定制 HTTP 请求,如下:
import requestsurl = 'https://www.example.com'
params = {'param1': 'value1', 'param2': 'value2'}
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, params=params, headers=headers)
html = response.text
print(html)
这里我们定义了两个额外的参数:params 和 headers。params 表示要传递的参数,headers 表示请求头信息。使用 requests 库还可以获取 HTTP 响应的一些信息,如 HTTP 状态码、响应头和响应内容等,示例如下:
import requestsurl = 'https://www.example.com'
params = {'param1': 'value1', 'param2': 'value2'}
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, params=params, headers=headers)# 获取 HTTP 状态码
status_code = response.status_code# 获取响应头
headers = response.headers# 获取响应内容
html = response.text这里我们使用了 response 对象的三个方法:status_code、headers 和 text。status_code 方法返回 HTTP 状态码,headers 方法返回响应头信息,text 方法返回 HTML 内容。
二、使用代理 IP
有些网站会限制同一 IP 地址访问频率,甚至会封禁 IP 地址。因此,我们可以使用代理 IP 来避免被封禁。代理 IP 就是通过另外一个 IP 地址访问需要爬取的网站,从而达到隐藏真实 IP 地址的目的。
1. 代理 IP 的类型
常见的代理 IP 类型有两种:HTTP 代理和 SOCKS 代理。HTTP 代理在 HTTP 层面对数据进行转发,只能用于 HTTP 请求,而 SOCKS 代理则是在传输层面进行转发,支持 TCP 和 UDP 协议。
2. 使用代理 IP 进行爬虫
使用代理 IP 进行爬虫同样很简单,只需要在 requests.get() 函数中增加一个代理参数即可。示例如下:
import requestsurl = 'https://www.example.com'
proxy = {'http': 'http://127.0.0.1:8080', 'https': 'https://127.0.0.1:8080'}
response = requests.get(url, proxies=proxy)
html = response.text
print(html)这里我们定义了一个代理字典 proxy,它包含两个键值对,表示使用 HTTP 和 HTTPS 协议分别使用不同的代理 IP。其中,http 表示 HTTP 协议使用的代理 IP,https 表示 HTTPS 协议使用的代理 IP。
以上是使用代理 IP 的基本方法,但是免费的代理 IP 质量很难保证,有可能会影响爬虫效率。因此,我们可以选择付费代理 IP,以确保代理 IP 的质量。下面将介绍一个常见的付费代理 IP 服务商。
3. 代理 IP 服务商
常见的代理 IP 服务商有很多,比如站大爷、蝶鸟ip、开心代理等。这里我们以站大爷为例来介绍如何使用其提供的代理 IP。
首先,需要到站大爷官网注册账号并购买代理 IP。购买后可以在站大爷官网的用户中心中获取账号和密码,并下载对应的代理 IP 工具包。
我们以 Python 为例来演示如何使用阿布云提供的代理 IP 进行爬虫。
import requests# 代理服务器 IP 和端口号
proxy_host = "123.25.14.114"
proxy_port = "9020"# 代理验证信息
proxy_username = "YOUR_USERNAME"
proxy_password = "YOUR_PASSWORD"proxy_meta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {"host": proxy_host,"port": proxy_port,"user": proxy_username,"pass": proxy_password,
}proxies = {"http": proxy_meta,"https": proxy_meta,
}# 设置请求头信息
headers = {'User-Agent': 'Mozilla/5.0','Accept-Language': 'en-US,en;q=0.5'
}url = 'https://www.example.com'response = requests.get(url, headers=headers, proxies=proxies)
html = response.text
print(html)在上述代码中,我们首先定义了站大爷提供的代理服务器 IP 和端口号,代理验证信息,然后拼接成了代理元组 proxy_meta。接着,我们定义了一个 proxies 字典,将代理元组作为值来定义。最后,我们设置了请求头信息,并使用 requests.get() 函数发送请求,从而获取网页 HTML 代码。
总结
使用 Python 爬虫爬取网页非常简单,只需要使用 requests 库来发送 HTTP 请求,然后使用 BeautifulSoup 库来解析 HTML 代码,从而提取出需要的信息。同时,使用代理 IP 可以避免被封禁,提高爬虫效率。在实际应用中,爬取网页可以帮助我们获取大量有用的数据,帮助研究市场变化、竞争对手等。
相关文章:
【爬虫小知识】如何利用爬虫爬网页——python爬虫
前言 网络时代的到来,给我们提供了海量的信息资源,但是,想要获取这些信息,手动一个一个网页进行查找,无疑是一项繁琐且效率低下的工作。这时,爬虫技术的出现,为我们提供了一种高效的方式去获取…...
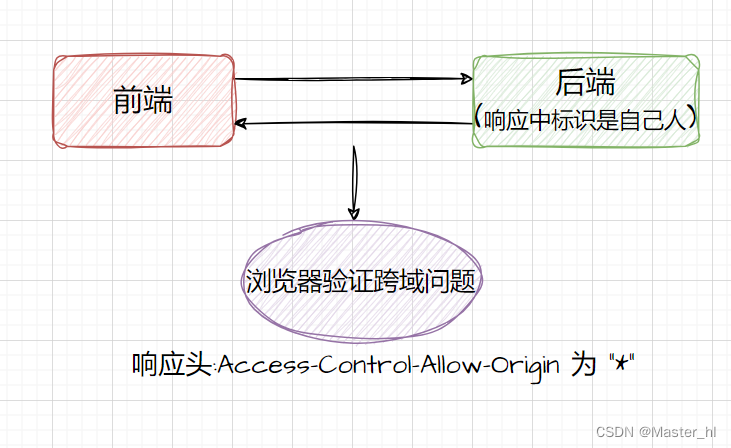
什么是跨域问题 ?Spring MVC 如何解决跨域问题 ?Spring Boot 如何解决跨域问题 ?
目录 1. 什么是跨域问题 ? 2. Spring MVC 如何解决跨域问题 ? 3. Spring Boot 如何解决跨域问题 ? 1. 什么是跨域问题 ? 跨域问题指的是不同站点之间,使用 ajax 无法相互调用的问题。 跨域问题的 3 种情况&#x…...

线性代数的学习和整理17:向量空间的基,自然基,基变换等(未完成)
目录 3 向量空间的基:矩阵的基础/轴 3.1 从颜色RGB说起 3.2 附属知识 3.3 什么样的向量可以做基? 3.4 基的分类 3.1.1 不同空间的基---向量组的数量可能不同 3.1.2 自然基 3.1.3 正交基 3.1.4 标准正交基 3.1.5 基和向量/矩阵 3.1.6 基变换 …...

Java中支持分库分表的框架/组件/中间件简介
文章目录 1 sharding-jdbc2 TSharding3 Atlas4 Cobar5 MyCAT6 TDDL7 Vitess 列举一些比较常见的,简单介绍一下: sharding-jdbc(当当) TSharding(蘑菇街) Atlas(奇虎360) Cobar&#…...
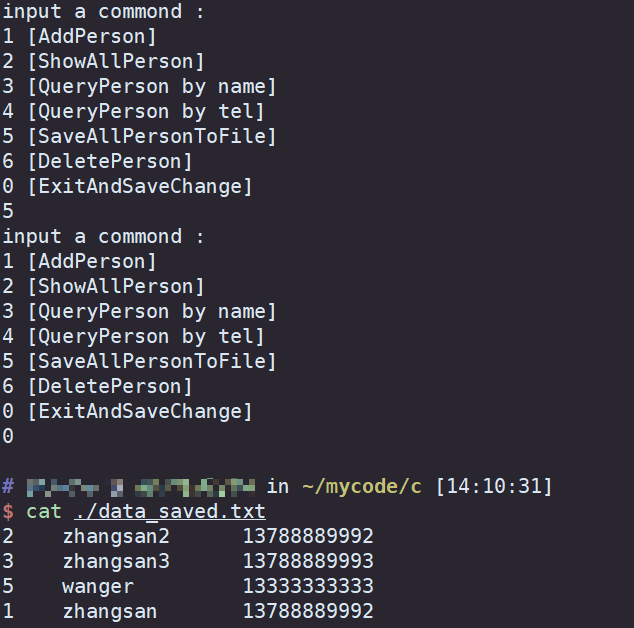
7.2 项目2 学生通讯录管理:文本文件增删改查(C 版本)(自顶向下设计+断点调试) (A)
C自学精简教程 目录(必读) 该作业是 作业 学生通讯录管理:文本文件增删改查(C版本) 的C 语言版本。 具体的作业题目描述,要求,可以参考 学生通讯录管理:文本文件增删改查(C版本)。…...
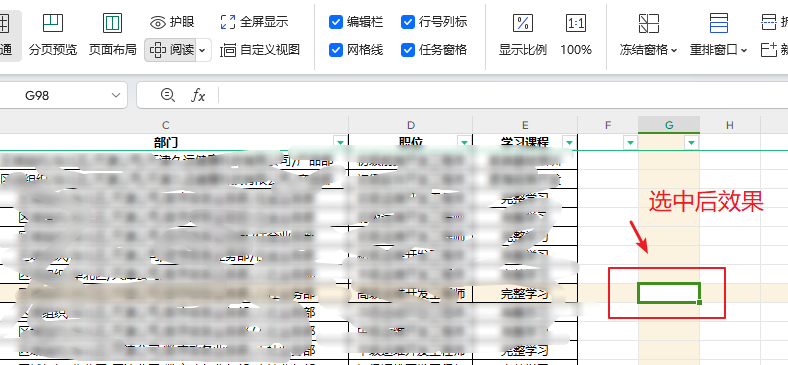
excel怎么设置任意选一个单元格纵横竖横都有颜色
有时excel表格内容过多的时候,我们通过excel设置任意选一个单元格纵横,竖横背景颜色,这样会更加具有辨识度。设置方式截图如下 设置成功后,预览的效果图...

期货-股票交易规则
交易时间 港股:9:00~9:20 集合竞价,9:3012:00,13:0016:00 持续交易,16:00~16:10 随机收市竞价沪股:9:00~9:25 集合竞价,9:3011:30,13:0015:00 持续交易,11:30~12:00 交易申报深股&a…...

Makefile一些语法
ifneq($(filter true,$(xxx)), )的含义 filter 是过滤的意思,它的原型是:$(filter PATTERN…,TEXT), 意义为:过滤掉字串“TEXT”中所有不符合模式“PATTERN”的单词,保留所有符合此模式的单词做返回值。 结合前面的if…...

0基础可以转行编程行业么
在2022年分行业门类分岗位就业人员年平均工资中,信息传输、软件和信息技术服务业的薪资遥遥领先其他行业,为全国平均薪资水平的 1.78 倍,远超第二名金融行业,其年增长率在9.4%,并成为年收入首个过20 万门槛的行业&…...

【spark】dataframe慎用limit
官方:limit通常和order by一起使用,保证结果是确定的 limit 会有两个步骤: LocalLimit ,发生在每个partitionGlobalLimit,发生shuffle,聚合到一个parttion 当提取的n大时,第二步是比较耗时的…...

基于OpenCV+LPR模型端对端智能车牌识别——深度学习和目标检测算法应用(含Python+Andriod全部工程源码)+CCPD数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境OpenCV环境Android环境1. 开发软件和开发包2. JDK设置3. NDK设置 模块实现1. 数据预处理2. 模型训练1)训练级联分类器2)训练无分割车牌字符识别模型 3. APP构建1)导入OpenCV库…...

C++学习6
C学习6 基础知识std::thread 实战boost domain socket server 基础知识 std::thread std::thread是C11标准库中的一个类,用于创建并发执行的线程。它的详细用法如下: 头文件 #include <thread>创建线程 std::thread t(func, args...);其中&am…...

bazel使用中存在的问题
只开远端缓存时。kernel采用的bazel编译,遇到如下问题: 1、Action 详情二进制文件解析为文本文件时报错,无法进一步比较分析导致缓存不命中的原因。--- JDK版本的问题 2、远端缓存全部命中时间收益不明显 ---需分析是否为网络原因 3、$HOM…...
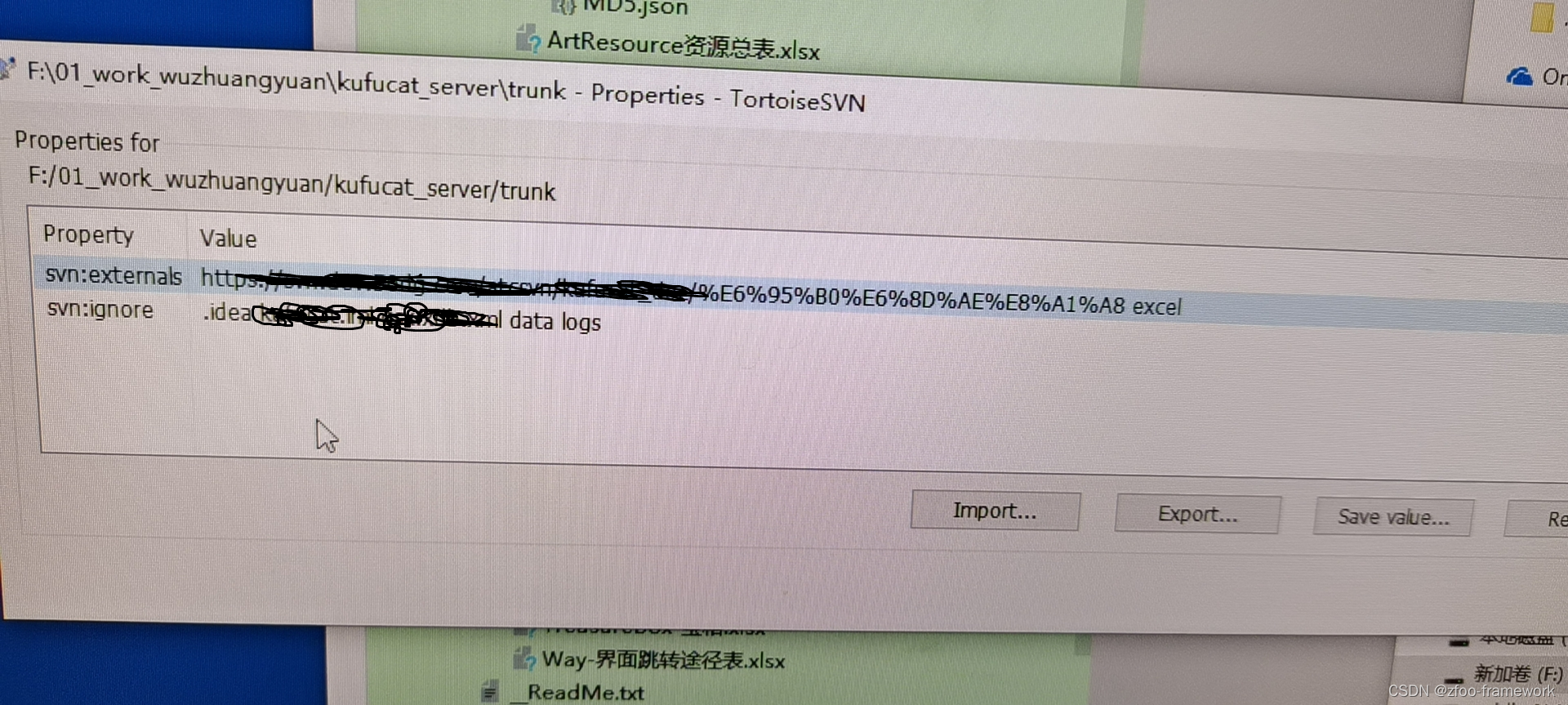
svn软连接和文件忽略
软连接 1)TortoiseSVN->Properties->New->Externals->New 2)填入软连接信息 Local path: 写下软连接后的文件夹的名字 URL: 想要软连接的牡蛎->TortoiseSVN->Repo-browser 复制下填入 文件忽略 以空格隔开就行...
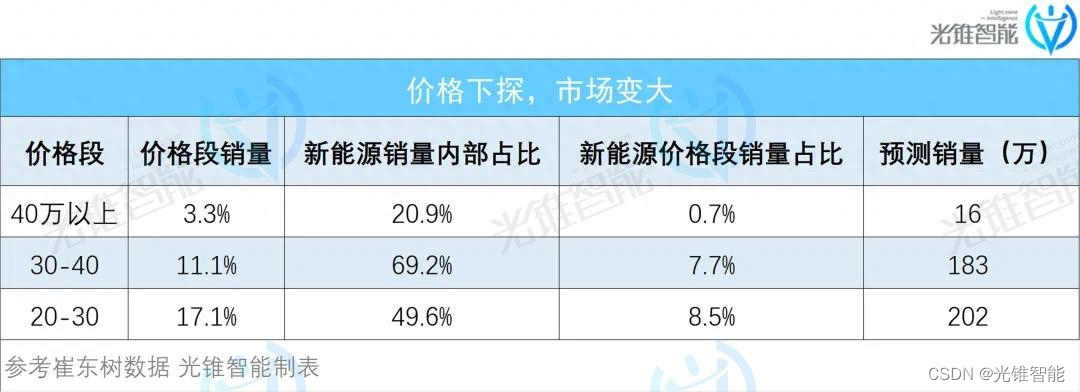
自动驾驶攻城战,华为小鹏先亮剑
点击关注 文|刘俊宏 编|苏扬、王一粟 本文为光锥智能x腾讯科技联合出品 2023年过半,城市NOA(城市领航辅助驾驶)的元年如预期中到来了吗? 8月25日,成都车展开幕,与4个月之前的上海…...
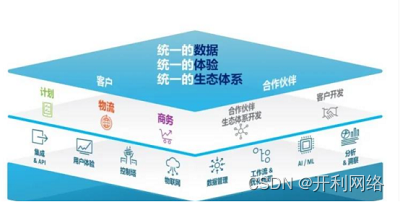
企业供应链数字化怎么做?企业数字化供应链流程落地方式
什么是供应链?简单来说,供应链是围绕客户需求,以提高产品流通各个环节的效率为目标,通过资源整合的方式来实现产品从设计、生产到销售、服务整个环节的组织形态。如同人工智能、区块链、5G等技术的发展带来的各种行业变化…...

java八股文面试[多线程]——synchronized 和lock的区别
其他差别: synchronized是隐式的加锁,lock是显式的加锁; synchronized底层采用的是objectMonitor,lock采用的AQS; synchronized在进行加锁解锁时,只有一个同步队列和一个等待队列, lock有一个同步队列,可以有多个等待队列; synchronized使用了object类的wait和noti…...

实现一个简单的控制台版用户登陆程序, 程序启动提示用户输入用户名密码. 如果用户名密码出错, 使用自定义异常的方式来处理
//密码错误异常类 public class PasswordError extends Exception {public PasswordError(String message){super(message);} }//用户名错误异常类 public class UserError extends Exception{public UserError(String message){super(message);} }import java.util.Scanner;pu…...

Java 大厂八股文面试专题-设计模式 工厂方法模式、策略模式、责任链模式
面试专题-设计模式 前言 在平时的开发中,涉及到设计模式的有两块内容,第一个是我们平时使用的框架(比如spring、mybatis等),第二个是我们自己开发业务使用的设计模式。 面试官一般比较关心的是你在开发过程中ÿ…...
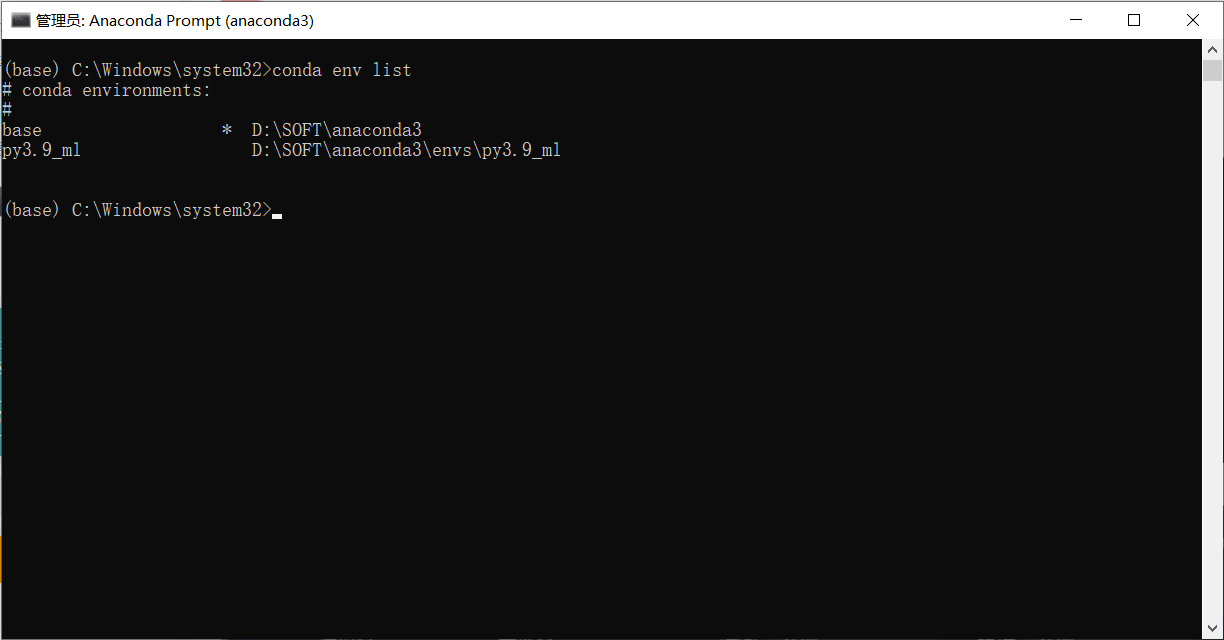
Anaconda Prompt输入jupyter lab无反应
问题:Anaconda Prompt界面输入指令无反应 原因:公司电脑勒索病毒防御工具阻止了进程 解决:找到黑名单恢复进程...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...