九、idSpanMap使用基数树代替原本的unordered_map 十、使用基数树前后性能对比
九、idSpanMap使用基数树代替原本的unordered_map
我们原本的idSpanMap用的是STL容器中的unordered_map哈希桶,因为STL的容器本身是不保证线程安全的,所以我们在访问时需要加锁保证线程安全,这也就是我们写的内存池的性能的瓶颈点。因为我做的这个内存池的项目是参照谷歌的开源项目tc-malloc,然后自主实现的mini版本,我查看tc-malloc的源码的优化策略是利用一颗基数树来代替stl中的unordered_map的,因为我们的需求是要保存页号和Span的映射关系,Span是指针本质也是一个整数,也就是说我们要保存的是<int,int>的映射关系,而基数树正好可以满足我们的需求,所以基数树就成为了优化我们的内存池的不二人选,并且用这个基数树定义idSpanMap最大的好处是访问idSpanMap时不需要加锁也能保证线程安全的。那它是怎么做到的呢?接下来我们就来学习一下。
9.1 什么是基数树?
基数树说白了也是一种哈希结构,基数树分为一层基数树,两层基数树,三层基数树。
9.1.1 一层基数树
一层基数树采用的是直接映射的方法
32位机器下才可以用一层基数树,64位机器下不可以,因为2^62次方太大了,早已超出了我们机器的内存的大小了,所以64位机器要用两层基数树或者三层基数树。

9.1.2 两层基数树
两层基数树是把哈希映射的关系分成两层,第一层是利用低19位的高5位判断该id在第一层的哪一个位置,再按照低14位判断在第二层的哪个位置。
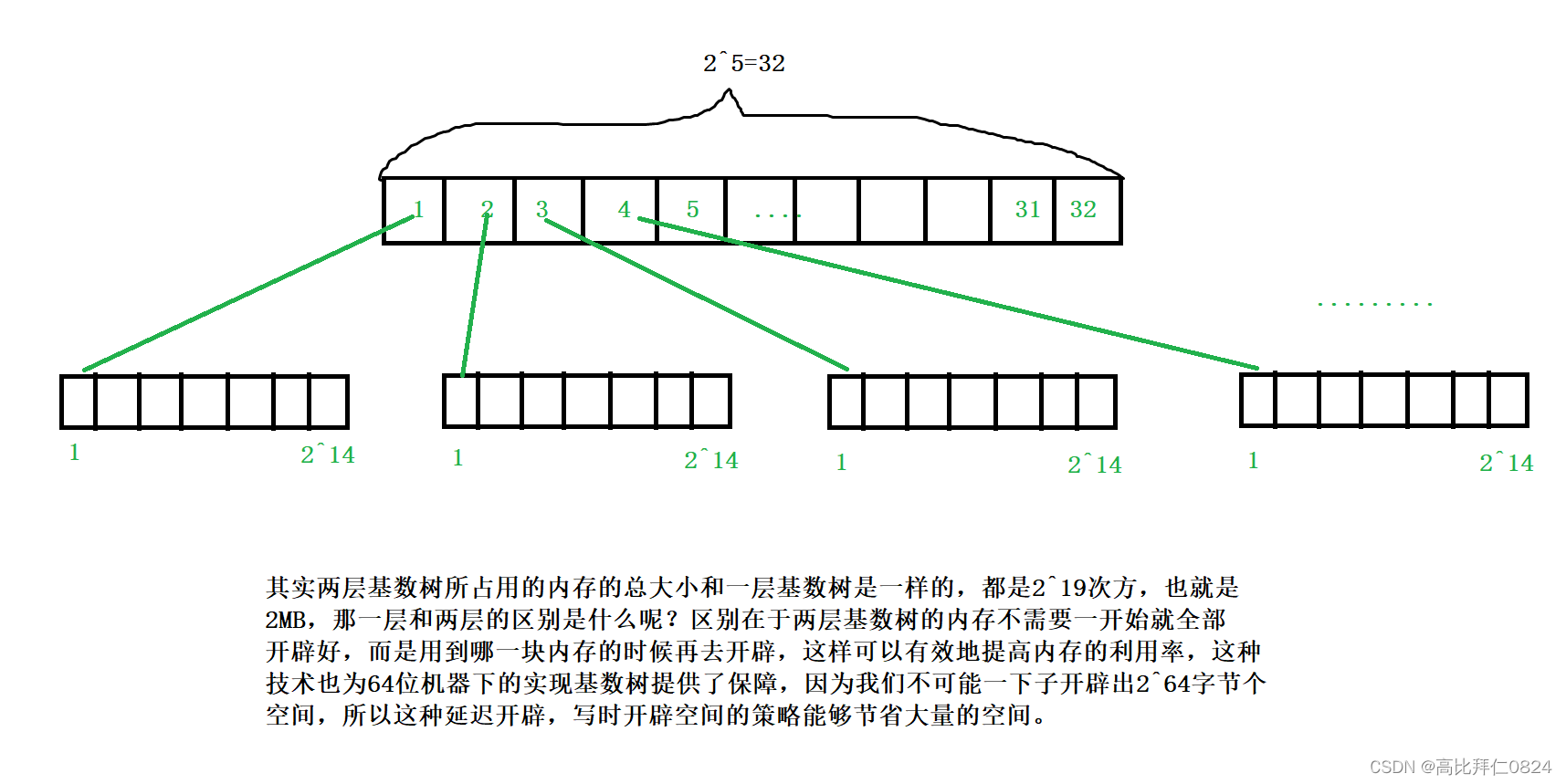
三层基数树也是按照两层基数树的模式继续延伸下去即可,在这也就不过多叙述了,详情可以看后面的代码实现。
9.2 tcmalloc中基数树的源码实现
//基数树,用来代替 idSpanMap,访问时可以不用加锁// Single-level array
template <size_t BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap1() {//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));size_t size = sizeof(void*) << BITS;size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodesvoid* (*allocator_)(size_t); // Memory allocatorpublic:typedef uintptr_t Number;//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap2() {//allocator_ = allocator;memset(root_, 0, sizeof(root_));PreallocateMoreMemory();}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);ASSERT(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;// Check for overflowif (i1 >= ROOT_LENGTH)return false;// Make 2nd level node if necessaryif (root_[i1] == NULL) {//Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));//if (leaf == NULL) return false;static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS);}
};// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:// How many bits should we consume at each interior levelstatic const int INTERIOR_BITS = (BITS + 2) / 3; // Round-upstatic const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;// How many bits should we consume at leaf levelstatic const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Interior nodestruct Node {Node* ptrs[INTERIOR_LENGTH];};// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Node* root_; // Root of radix treevoid* (*allocator_)(size_t); // Memory allocatorNode* NewNode() {Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));if (result != NULL) {memset(result, 0, sizeof(*result));}return result;}public:typedef uintptr_t Number;explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {allocator_ = allocator;root_ = NewNode();}void* get(Number k) const {const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 ||root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {return NULL;}return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3];}void set(Number k, void* v) {ASSERT(k >> BITS == 0);const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);// Check for overflowif (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)return false;// Make 2nd level node if necessaryif (root_->ptrs[i1] == NULL) {Node* n = NewNode();if (n == NULL) return false;root_->ptrs[i1] = n;}// Make leaf node if necessaryif (root_->ptrs[i1]->ptrs[i2] == NULL) {Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));if (leaf == NULL) return false;memset(leaf, 0, sizeof(*leaf));root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {}
};由于上面的基数树是更改idSpanMap的结构的,所以需要把idSpanMap的访问操作修改成对应的基数树的set和get
idSpanMap主要是在PageCache中使用,修改后如下:
PageCache PageCache::_sInst;//k代表的是这个span的大小k页
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);//如果申请的span的大小大于128页,则需要直接向堆申请if (k > NPAGES - 1){//向堆申请k页内存void* ptr = SystemAlloc(k);Span* kSpan = _spanPool.New();//地址转化成页号kSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;kSpan->_n = k;//把页号和Kspan的映射关系放进Map中//_idSpanMap[kSpan->_pageId] = kSpan;_idSpanMap.set(kSpan->_pageId, kSpan);return kSpan;}else{//如果PageCache第k个位置的哈希桶上有k页大小的span,则直接返回一个spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();//把kSpan的页号和对应的Span*的映射关系存放到哈希桶中去,方便//CentralCache回收小块内存时,查找对应的span//kSpan代表的是一个k页大小的Span的大块内存,kSpan->_pageId//代表这个大块内存的起始地址,有k页,所以这k页映射到的都是这个Spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){//_idSpanMap[kSpan->_pageId + i] = kSpan;_idSpanMap.set(kSpan->_pageId + i, kSpan);}return kSpan;}//走到这里说明PageCache第k个位置的哈希桶没有k页大小的span,则需要遍历//后面的大于k页的哈希桶,找到了一个n页大小的span就把这个span切分成一个// k页大小的span和一个n-k页大小的span,k页的返回,n-k页的挂到对应的哈希桶中//遍历后面的哈希桶for (size_t i = k + 1; i < NPAGES; i++){//找到了一个不为空的i页的哈希桶,就对它进行切分if (!_spanLists[i].Empty()){//k页的spanSpan* kSpan = _spanPool.New();//n页的spanSpan* nSpan = _spanLists[i].PopFront();//开始把一个n页的span切分成一个k页的span和一个n-k页的span// //从nSpan的头上切k页给kSpan,所以kSpan的页号就是nSpan的页号kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;//kSpan的页数是k//被切分以后nSpan的页号需要+=k页,因为头nSpan的头k页已经切分给了kSpannSpan->_pageId += k;nSpan->_n -= k;//nSpan的页数要-=k页,因为nSpan被切走了k页//把kSpan的页号和对应的Span*的映射关系存放到哈希桶中去,方便// CentralCache回收小块内存时,查找对应的span//kSpan代表的是一个k页大小的Span的大块内存,kSpan->_pageId//代表这个大块内存的起始地址,有k页,所以这k页映射到的都是这个Spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){//_idSpanMap[kSpan->_pageId + i] = kSpan;_idSpanMap.set(kSpan->_pageId + i, kSpan);}//nSpan被切分后的首页和尾页的页号和nspan的映射关系也需要保存起来//以便后续合并,因为合并的方式是前后页合并,往前找肯定找到的是一个span的//最后一页,往后找一定找的是一个span的第一页,所以挂在PageCache对应哈希桶//的span的第一页和最后一页与span的关系也需要保存起来// //_idSpanMap[nSpan->_pageId] = nSpan;//_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;_idSpanMap.set(nSpan->_pageId, nSpan);_idSpanMap.set(nSpan->_pageId + nSpan->_n - 1, nSpan);if (nSpan->_pageId == 0){int x = 0;}//把剩余的n-k页的span头插到对应下标的哈希桶中_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}//走到这里说明前面的NPAGES个哈希桶中都没有Span,(例如第一次申请内存时)//则需要向堆申请一个128页大小的span大块内存,挂到对应的哈希桶中void* ptr = SystemAlloc(NPAGES - 1);Span* bigSpan = _spanPool.New();bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;//内存的地址需要转换成页号映射到对应的哈希桶中bigSpan->_n = NPAGES - 1;//把NPAGES-1页大小的span头插到对应NPAGES-1号桶中去_spanLists[bigSpan->_n].PushFront(bigSpan);//本质是运用了复用的设计,避免代码中出现重复的逻辑return NewSpan(k);}}Span* PageCache::MapObjectToSpan(void* obj)
{//计算出obj对应的页号PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;访问_idSpanMap的时候需要加锁,避免线程安全的问题这里使用C++11的RAII锁,出了这个函数这把锁会自动解掉//std::unique_lock<std::mutex> lock(_pageMtx);通过页号查找该内存块对应的是哪一个span//auto ret = _idSpanMap.find(id);//if (ret != _idSpanMap.end())//{// return ret->second;//}//else//{// assert(false);// return nullptr;//}//换成了基数树作为map存放页号和Span*的映射关系之后,访问的时候是不需要再加锁的,原因有以下几点://1、只有在NewSpan函数和ReleaseSpanToPageCache函数会去写基数树。//2、基数树在写之前就会开好空间,写的过程中是不会影响到基数树的结构的,也就是说在两个线程在访问// 不同位置时互相是不会受到影响的。//3、基数树对同一个位置的读写是分离的,线程1对一个位置进行读写的时候,线程2不可能也在对同一个位置进行读写//写是在申请span和释放span的时候,是在没人用的时候做的;而读是在有人用这个span的时候做的,所以读写是分离的// 4、另一方面就是NewSpan函数和ReleaseSpanToPageCache函数在调用之前本身就已经加锁了,所以这里就不用加锁了//但是为什么用stl下的map要加锁呢?本质是红黑树在插入的时候会改变树的结构,一个线程在插入节点改变红黑树的结构,//一个线程在遍历就会有线程安全的问题,而基数树插入的时候不会影响结构,而且基数树读取的时候并不是遍历,而是直接通过下标//就访问到了对应的位置的//通过页号查找该内存块对应的是哪一个spanvoid* ret = _idSpanMap.get(id);if (ret != nullptr){return (Span*)ret;}else{assert(false);return nullptr;}
}//CentralCache把span还回来给PageCache
void PageCache::ReleaseSpanToPageCache(Span* span)
{//如果span的页数大于128页,则说明这个span是从堆上直接申请的,//直接释放给堆即可,不能挂到PageCache的哈希桶中,因为PageCache一个只有128个桶if (span->_n > NPAGES - 1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);_spanPool.Delete(span);return;}while (1){//找前一页的span,看是否能够和当前页合并,如果能,则循环向前合并,直到不能合并为止PAGE_ID prevId = span->_pageId - 1;void* ret = _idSpanMap.get(prevId);//_idSpanMap中没找到前一页和对应span,说明前一页的内存没有被申请,结束合并if (ret == nullptr){break;}Span* prevSpan = (Span*)ret;//如果前一页对应的span在CentralCache中正在被使用,结束合并if (prevSpan->_isUse == true){break;}//如果和前一页合并之后会超过哈希桶的最大的映射返回,结束合并if (prevSpan->_n + span->_n > NPAGES - 1){break;}//合并span和prevSpanspan->_pageId = prevSpan->_pageId;span->_n = prevSpan->_n + span->_n;//合并之后需要把prevSpan在对应的哈希桶中删除掉_spanLists[prevSpan->_n].Erase(prevSpan);//因为prevSpan已经被合并到了span中,所以prevSpan对应的内存可以delete掉了_spanPool.Delete(prevSpan);}while (1){//找span的下一个span的起始页号PAGE_ID nextId = span->_pageId + span->_n;void* ret = _idSpanMap.get(nextId);if (ret == nullptr){break;}Span* nextSpan = (Span*)ret;if (nextSpan->_isUse == true){break;}if (nextSpan->_n + span->_n > NPAGES - 1)//曾经写成NPAGES+1了{break;}//span的起始页号不变,页数相加span->_n = span->_n + nextSpan->_n;//合并之后需要把prevSpan在对应的哈希桶中删除掉_spanLists[nextSpan->_n].Erase(nextSpan);_spanPool.Delete(nextSpan);}//合并得到的新的span需要挂到对应页数的哈希桶中_spanLists[span->_n].PushFront(span);//在PageCache中的span要设置为false,好让后面相邻的span来合并span->_isUse = false;//为了方便后续的合并,需要把span的起始页号和尾页号和span建立映射关系//_idSpanMap[span->_pageId] = span;//_idSpanMap[span->_pageId + span->_n - 1] = span;_idSpanMap.set(span->_pageId, span);_idSpanMap.set(span->_pageId + span->_n - 1, span);}代码中用的是一层基数树:

9.3 为什么使用基数树在访问时不需要加锁?

十、使用基数树前后性能对比
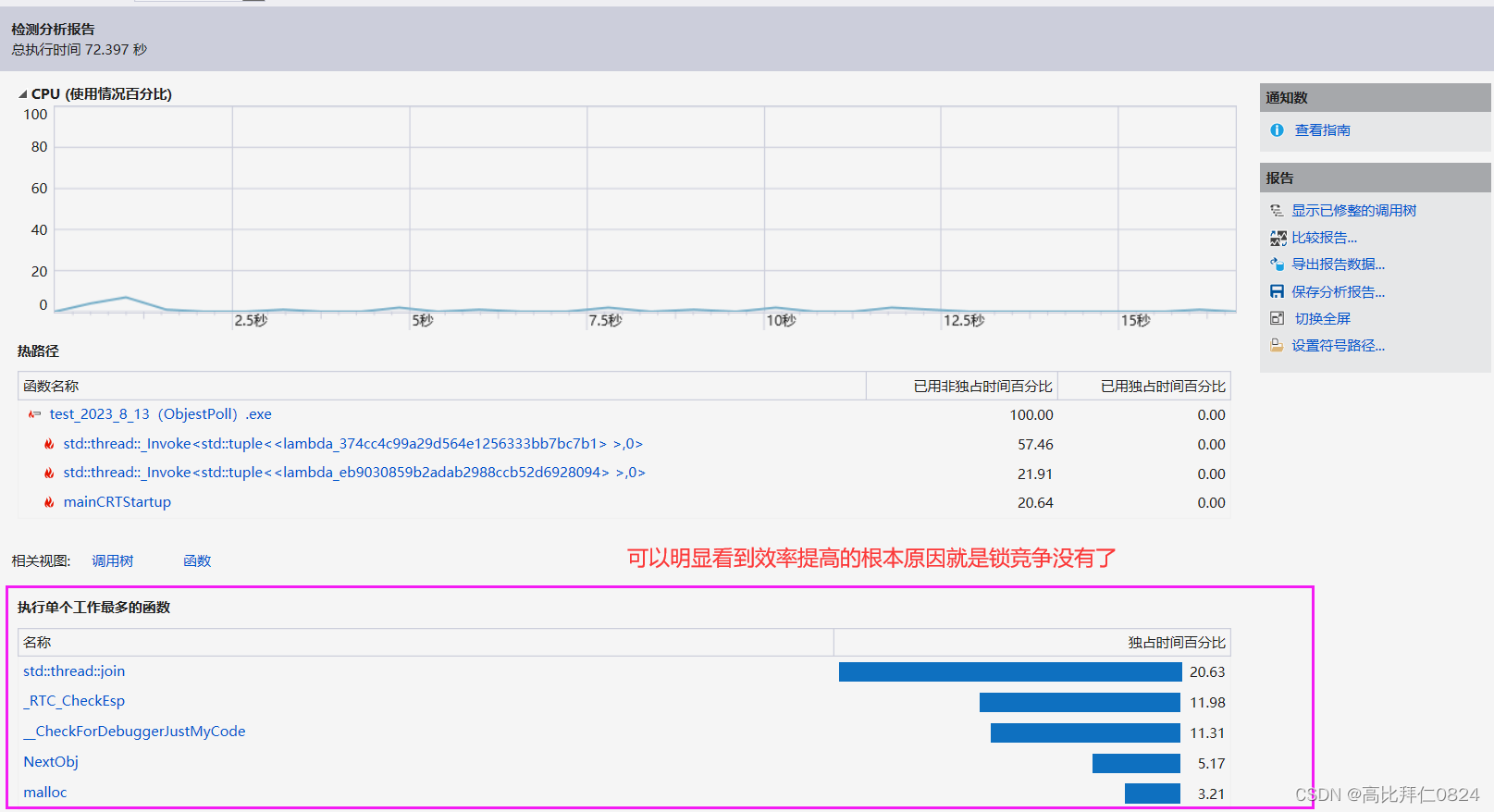
使用基数树优化前:我们的内存池比malloc还要稍微慢一些。

使用基数树优化后:我们的内存池的效率大概是malloc的10倍左右的样子,可见,基数树优化后的效率还是提高了不少的。

相关文章:
九、idSpanMap使用基数树代替原本的unordered_map 十、使用基数树前后性能对比
九、idSpanMap使用基数树代替原本的unordered_map 我们原本的idSpanMap用的是STL容器中的unordered_map哈希桶,因为STL的容器本身是不保证线程安全的,所以我们在访问时需要加锁保证线程安全,这也就是我们写的内存池的性能的瓶颈点。因为我做…...

政府科技项目验收全流程分享
科技验收测试 (验收申请→主管部门初审→科技厅审核→组织验收→归档备案→信用管理): (一)验收申请 项目承担单位通过省科技业务管理系统提交验收申请。 按期完成的项目,项目承担单位应当在项目合同书…...
基于Matlab实现生活中的图像信号分类(附上源码+数据集)
在我们的日常生活中,我们经常会遇到各种各样的图像信号,例如照片、视频、图标等等。对这些图像信号进行分类和识别对于我们来说是非常有用的。在本文中,我将介绍如何使用Matlab来实现生活中的图像信号分类。 文章目录 介绍源码数据集下载 介…...

YOLOv5算法改进(12)— 替换主干网络之Swin Transformer
前言:Hello大家好,我是小哥谈。Swin Transformer是一种基于Transformer的深度学习模型,它在视觉任务中表现出色。与之前的Vision Transformer(ViT)不同,Swin Transformer具有高效和精确的特性,并…...

php 权限节点的位运算
一,概述 在 PHP 中,位运算可以用来进行权限节点的判断。通常,每个权限节点都会用一个不同的位表示(2的n次方,从0开始),可以将这些位组合成一个权限值。然后,可以使用位运算符来检查…...
ClickHouse进阶(六):副本与分片-2-Distributed引擎
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…...

Git和Github的基本用法
目录 背景 下载安装 安装 git for windows 安装 tortoise git 使用 Github 创建项目 注册账号 创建项目 下载项目到本地 Git 操作的三板斧 放入代码 三板斧第一招: git add 三板斧第二招: git commit 三板斧第三招: git push 小结 🎈个人主页…...

279. 完全平方数
279.完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 …...

一篇文章学会C#的正则表达式
https://blog.csdn.net/qq_38507850/article/details/79179128 正则表达式 一句话概括就是用来对字符串根据自己的规则进行匹配的,可以匹配(返回)出符合自己要求的匹配结果,有人说字符串类的函数也可以,确实是这样,但是字符串的函…...
智慧工地源码 智慧大屏、手机APP、SaaS模式
一、智慧工地可以通过安全八要素来提升安全保障,具体措施包括: 1.安全管理制度:建立科学完善的安全管理制度,包括安全标准规范、安全生产手册等,明确各项安全管理职责和要求。 2.安全培训教育:对工地人…...
C# WPF监听USB插入拨出
可以全部监听。好用 private void FormF100WriteCortexLicense_Load(object sender, EventArgs e){this.Text this.Text " " FT_Tools.Program.version;USB USBWatcher new USB();USBWatcher.AddUSBEventWatcher(USBEventHandler, USBEventHandler, new TimeSpa…...
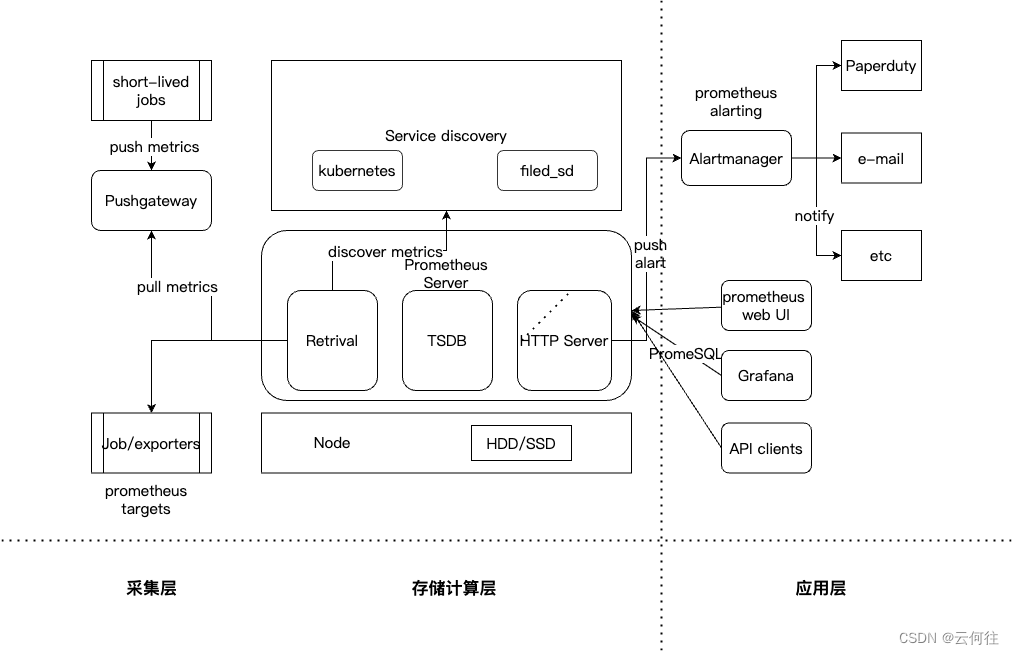
Prometheus监控(三)架构
文章目录 Prometheus架构图Prometheus生态圈组件Prometheus Serverclient librariesPushgatewayexporterAlartmanager Prometheus架构理解存储计算层采集层应用层 Prometheus架构图 Prometheus生态圈组件 Prometheus Server 主服务器,负责收集和存储时间序列数据 …...

linux kvm网桥br简单理解和持久化配置
linux网桥简单理解和持久化配置 文章目录 前言一、Linux 网桥是什么?二、网桥主要作用三、网桥配置命令及安装(CentOS系统) 1 网桥配置命令2.持久化网桥配置 前言 linux bridge是网络虚拟化中非常重要的一种设备,今天就来学习下linux bridge的相关知…...

【LeetCode-中等题】105. 从前序与中序遍历序列构造二叉树
文章目录 题目方法一:递归 题目 方法一:递归 preorder [3,9,20,15,7] inorder [9,3,15,20,7] 首先根据 preorder 找到根节点是 3然后根据根节点将 inorder 分成左子树和右子树 左子树 inorder [9]右子树 inorder [15,20,7]这时候3是根节点 3的左子树…...
uniapp 配置网络请求并使用请求轮播图
由于平台的限制,小程序项目中不支持 axios,而且原生的 wx.request() API 功能较为简单,不支持拦截器等全局定制的功能。因此,建议在 uni-app 项目中使用 escook/request-miniprogram 第三方包发起网络数据请求。 官方文档…...
c#在MVC Api(.net framework)当中使用Swagger,以及Demo下载
主要的步骤就是创建项目,通过nuget 添加Swashbuckle包,然后在SwaggerConfig当中进行相关的配置。 具体的步骤,可以参考下面的链接: https://www.cnblogs.com/94pm/p/8046580.htmlhttps://blog.csdn.net/xiaouncle/article/detail…...
Linux 常见命令操作
一、目录管理 1.1 列出目录 ls # ls 命令 # -a 参数,查看全部的文件,包括隐藏的文件 # -l 参数,列出所有的文件,包括文件的属性和权限,不显示隐藏文件 [rootlocalhost /]# ls bin boot dev etc home lib lib64…...
前端实习第七周周记
前言 第六周没写,是因为第六周的前两天在处理第五周的样本库部分。问题解决一个是嵌套问题(因为我用到了递归),还有一个问题在于本机没有问题,打包上线接口404。这个问题我会在这周的总结中说。 第六周第三天才谈好新…...
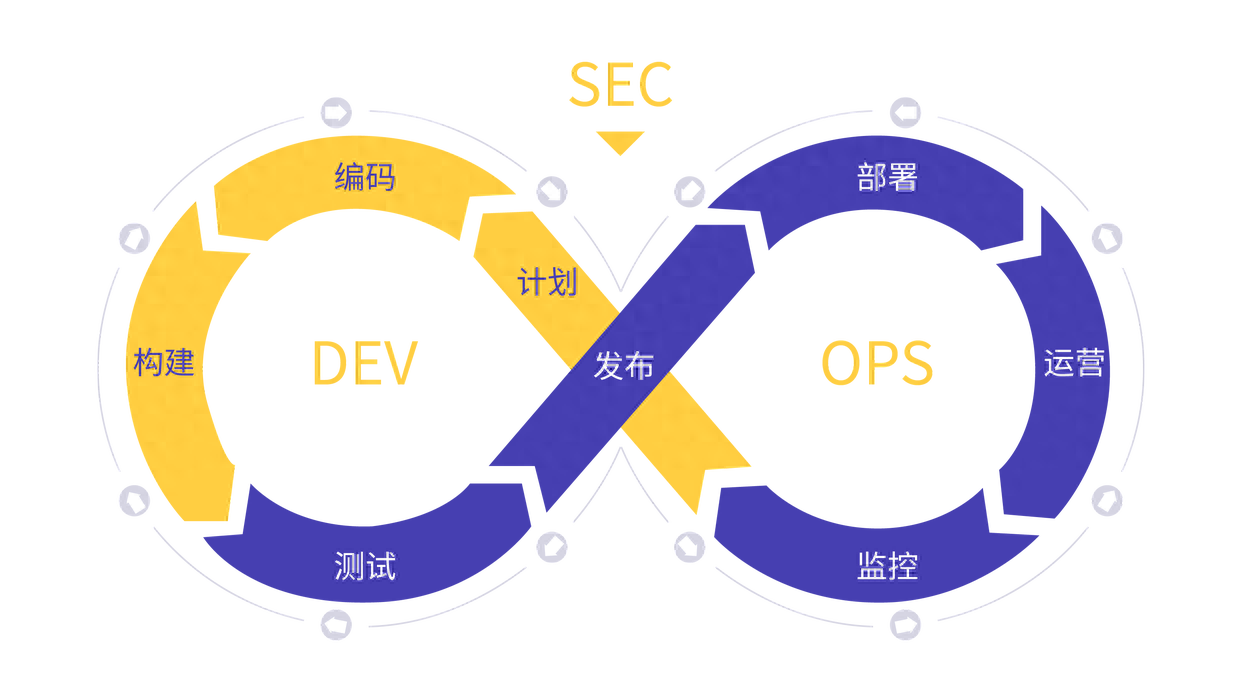
DevOps理念:开发与运维的融合
在现代软件开发领域,DevOps 不仅仅是一个流行的词汇,更是一种文化、一种哲学和一种方法论。DevOps 的核心理念是通过开发和运维之间的紧密合作,实现快速交付、高质量和持续创新。本文将深入探讨 DevOps 文化的重要性、原则以及如何在团队中实…...
windows下Mysql安装配置教程
Mysql下载 在官网下载mysql community Server https://dev.mysql.com/downloads/mysql/ 可以选择下载压缩包或者MSI安装程序 使用压缩包安装 MySQL 压缩包安装通常需要以下步骤: 1. 下载 MySQL 安装包 你可以从 MySQL 官网上下载适合你系统的 MySQL 安装包&am…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...