Python数据分析的第三方库
ython作为一种简单易学、功能强大的编程语言,逐渐成为数据分析领域的首选工具。在Python数据分析中,有许多优秀的第三方库可以帮助我们进行数据处理、可视化和建模。
常用第三方库:
NumPy:提供了高性能的多维数组对象和用于数组操作的工具,是数据分析的基础库。
pandas:提供了用于数据处理和分析的数据结构和函数,可以处理结构化数据,如表格和时间序列数据。
Matplotlib:用于绘制各种类型的图表和可视化,包括线图、散点图、柱状图等。
Seaborn:基于 Matplotlib 的数据可视化库,提供了更高级的统计图表和绘图样式。
Scikit-learn:用于机器学习和数据挖掘的库,包括各种分类、回归、聚类和降维算法。
SciPy:用于科学计算的库,包括数值积分、优化、插值等功能。
Statsmodels:用于统计建模和计量经济学的库,提供了各种统计模型和方法。
NetworkX:用于复杂网络分析的库,支持图论算法和网络可视化。
BeautifulSoup:用于解析和提取网页数据的库,常用于网页爬虫和数据采集。
TensorFlow:用于机器学习和深度学习的库,支持构建和训练各种神经网络模型。
以上是一些常用的第三方库,用于Python数据分析的各个方面,可以根据具体需求选择合适的库进行使用。
这些常用的第三方库在Python数据分析中发挥了重要的作用。首先,NumPy是数据分析的基础库,提供了高性能的多维数组对象和丰富的数组操作工具,使得数据的处理更加高效和方便。pandas则是用于数据处理和分析的重要工具,它提供了强大的数据结构和函数,可以处理结构化数据,如表格和时间序列数据。通过pandas,可以进行数据清洗、数据聚合和数据转换等操作,为后续的分析提供了良好的基础。
在数据可视化方面,Matplotlib和Seaborn是常用的库。Matplotlib提供了丰富的绘图功能,可以绘制各种类型的图表,如线图、散点图、柱状图等,为数据的可视化提供了强大的支持。而Seaborn是基于Matplotlib的数据可视化库,提供了更高级的统计图表和绘图样式,可以使得数据的可视化更加美观和直观。
对于机器学习和数据挖掘任务,Scikit-learn是常用的库之一。它提供了各种分类、回归、聚类和降维算法,以及模型选择、特征提取和评估等功能,为机器学习任务提供了全面的支持。同时,Statsmodels也是一款重要的库,专注于统计建模和计量经济学,提供了各种统计模型和方法,可以进行统计分析和经济学研究。
此外,SciPy是一款用于科学计算的库,提供了数值积分、优化、插值等功能,为数据分析提供了更加丰富和广泛的科学计算工具。NetworkX是用于复杂网络分析的库,支持图论算法和网络可视化,可以用于研究和分析各种类型的网络结构。而BeautifulSoup则是用于解析和提取网页数据的库,常用于网页爬虫和数据采集。最后,TensorFlow是一款用于机器学习和深度学习的库,支持构建和训练各种神经网络模型,为深度学习任务提供了强大的支持。
综上所述,这些常用的第三方库提供了丰富的功能和工具,能够满足Python数据分析的各个方面的需求。通过合理选择和使用这些库,可以更加高效和便捷地进行数据分析工作。
以下是以上每个库的使用事例:
- NumPy:
import numpy as np# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])# 计算数组的平均值
mean = np.mean(arr)# 计算数组的标准差
std = np.std(arr)# 计算数组的累积和
cumsum = np.cumsum(arr)
- pandas:
import pandas as pd# 读取csv文件为DataFrame
df = pd.read_csv('data.csv')# 查看DataFrame的前几行
head = df.head()# 对DataFrame进行排序
df_sorted = df.sort_values(by='column_name')# 进行数据聚合
aggregated = df.groupby('column_name').sum()
- Matplotlib:
import matplotlib.pyplot as plt# 绘制折线图
x = [1, 2, 3, 4, 5]
y = [10, 20, 15, 25, 30]
plt.plot(x, y)# 绘制散点图
plt.scatter(x, y)# 绘制柱状图
plt.bar(x, y)# 添加标题和标签
plt.title('Title')
plt.xlabel('X Label')
plt.ylabel('Y Label')# 显示图表
plt.show()
- Seaborn:
import seaborn as sns
import matplotlib.pyplot as plt# 绘制带有趋势线的散点图
sns.regplot(x='x', y='y', data=df)# 绘制箱线图
sns.boxplot(x='group', y='value', data=df)# 绘制直方图和核密度估计
sns.distplot(df['column'], bins=10, kde=True)# 设置样式和调整图表布局
sns.set(style='darkgrid')
plt.tight_layout()# 显示图表
plt.show()
- Scikit-learn:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 创建线性回归模型
model = LinearRegression()# 在训练集上拟合模型
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
- SciPy:
from scipy.optimize import minimize
from scipy.interpolate import interp1d
from scipy.integrate import quad# 最小化函数
result = minimize(f, x0)# 插值函数
f_interp = interp1d(x, y, kind='linear')
y_interp = f_interp(x_new)# 数值积分
result, error = quad(f, a, b)
- Statsmodels:
import statsmodels.api as sm# 创建线性回归模型
model = sm.OLS(y, X)# 在训练集上拟合模型
results = model.fit()# 打印模型摘要
print(results.summary())# 进行假设检验
hypothesis = 'x = 0'
t_test = results.t_test(hypothesis)# 进行预测
y_pred = results.predict(X_new)
- NetworkX:
import networkx as nx
import matplotlib.pyplot as plt# 创建图对象
G = nx.Graph()# 添加节点和边
G.add_nodes_from([1, 2, 3, 4])
G.add_edges_from([(1, 2), (2, 3), (3, 4), (4, 1)])# 绘制图形
nx.draw(G, with_labels=True)# 计算图的中心性指标
centrality = nx.betweenness_centrality(G)# 计算最短路径
shortest_path = nx.shortest_path(G, source=1, target=4)# 显示图形
plt.show()
- BeautifulSoup:
from bs4 import BeautifulSoup
import requests# 发送HTTP请求,获取网页内容
response = requests.get('https://www.example.com')# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.content, 'html.parser')# 提取网页中的文本内容
text = soup.get_text()# 提取指定标签的内容
links = soup.find_all('a')
for link in links:print(link.get('href'))
- TensorFlow:
import tensorflow as tf# 创建图和会话
graph = tf.Graph()
session = tf.Session(graph=graph)# 定义变量和操作
x = tf.constant(2)
y = tf.constant(3)
z = tf.add(x, y)# 运行操作
result = session.run(z)
print(result)# 定义神经网络模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(10, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_val, y_val))
这些使用事例展示了以上每个库的基本用法和功能,可以根据具体需求进行相应的调用和使用。
实际案例:
假设我们有一个电商网站的销售数据,想要对销售情况进行分析和预测。
首先,我们可以使用pandas读取销售数据的CSV文件为一个DataFrame,并进行数据清洗和整理,以便后续分析。
import pandas as pd# 读取销售数据
df = pd.read_csv('sales_data.csv')# 查看数据前几行
print(df.head())# 对数据进行清洗和整理
# ...
接下来,我们可以使用NumPy计算销售数据的一些统计指标,比如平均值、标准差等。
import numpy as np# 计算销售额的平均值和标准差
sales = df['sales'].values
mean_sales = np.mean(sales)
std_sales = np.std(sales)# 计算销售额的累积和
cumulative_sales = np.cumsum(sales)
然后,我们可以使用Matplotlib和Seaborn绘制销售数据的可视化图表,比如折线图、柱状图等。
import matplotlib.pyplot as plt
import seaborn as sns# 绘制销售额的折线图
dates = df['date'].values
plt.plot(dates, sales)
plt.xlabel('Date')
plt.ylabel('Sales')
plt.title('Sales Trend')
plt.show()# 绘制销售额的柱状图
categories = df['category'].values
sns.barplot(x=categories, y=sales)
plt.xlabel('Category')
plt.ylabel('Sales')
plt.title('Sales by Category')
plt.show()
接着,我们可以使用Scikit-learn进行销售数据的预测建模,比如线性回归模型。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 划分训练集和测试集
X = df[['feature1', 'feature2', 'feature3']].values
y = df['sales'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 创建线性回归模型
model = LinearRegression()# 在训练集上拟合模型
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
最后,我们可以使用Statsmodels进行销售数据的统计分析,比如回归分析和假设检验。
import statsmodels.api as sm# 创建线性回归模型
model = sm.OLS(y, X)# 在训练集上拟合模型
results = model.fit()# 打印模型摘要
print(results.summary())# 进行假设检验
hypothesis = 'feature1 = 0'
t_test = results.t_test(hypothesis)
这个实际案例结合了以上的库,展示了如何使用它们进行销售数据的分析和预测。通过对销售数据的统计分析和建模,我们可以获得对销售情况的洞察,并基于模型进行预测和决策。
综述:
Python数据分析的第三方库提供了丰富的功能和工具,可以方便地进行数据处理、可视化和建模。其中,Pandas提供了DataFrame数据结构,可以轻松进行数据清洗和整理;NumPy提供了高效的数组和矩阵操作,支持快速的数值计算;Matplotlib和Seaborn提供了强大的绘图功能,可以创建各种类型的图表;Scikit-learn是机器学习库,支持多种机器学习算法和工具;Statsmodels提供了统计建模和推断的功能。这些库的结合使用,可以帮助数据分析人员更快速、高效地完成数据分析任务,提供准确的分析结果和可视化展示。
相关文章:

Python数据分析的第三方库
ython作为一种简单易学、功能强大的编程语言,逐渐成为数据分析领域的首选工具。在Python数据分析中,有许多优秀的第三方库可以帮助我们进行数据处理、可视化和建模。 常用第三方库: NumPy:提供了高性能的多维数组对象和用于数组…...
,排除参数为空的条件)
EF列表分页查询(单表、多表),排除参数为空的条件
在日常使用EF框架查询数据库时,有时传入的参数为空,那么我们应该把该条件排除,不应列入组装的sql中,本篇文件以分页查询为例介绍EF框架的单表、多表的多条件查询,参数为空时排除条件。 首先我们要有派生自DBContext类的数据上下文…...

VisualStudio配置pybind11-Python调用C++方法
个人测试下来Debug生成的dll改pyd,py中import会报错gilstate->autoInterpreterState 如果遇到同样问题使用Release吧 目录 1.安装pybind11 1.pip: 2.github: 2.配置VS工程 2.在VC目录中的包含目录添加: 3.在VC目录中的库目录…...

ZZULIOJ 1164: 字符串加密,Java
ZZULIOJ 1164: 字符串加密,Java 题目描述 输入一串字符(长度不超过100)和一个正整数k,将其中的英文字母加密并输出加密后的字符串,非英文字母不变。加密思想:将每个字母c加一个序数k,即用它后…...

联合体(共用体)的简单介绍
目录 概念: 联合的声明: 类比结构体: 联合体的大小: 联合的⼤⼩⾄少是最⼤成员的⼤⼩ 联合体的空间是共用的 联合体内部成员的赋值: 当最⼤成员⼤⼩不是最⼤对⻬数的整数倍的时候,就要对⻬到最⼤对⻬…...
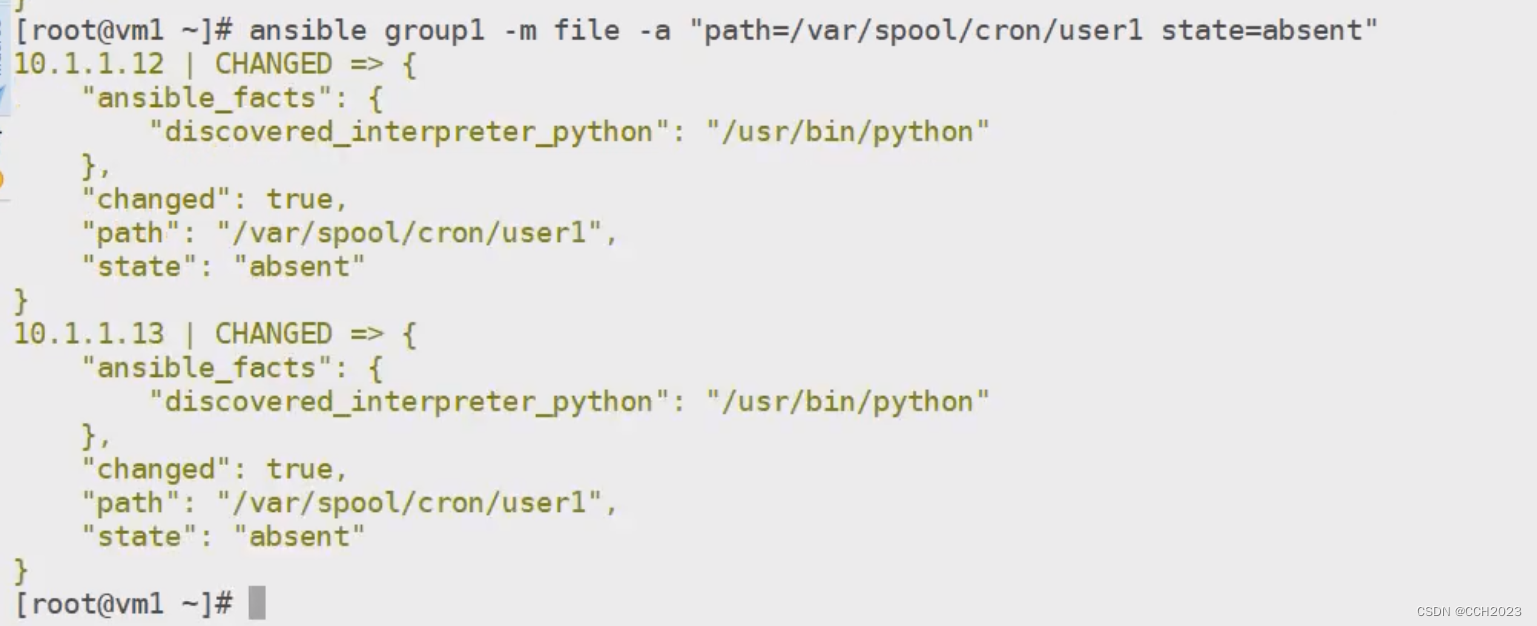
Ansible学习笔记8
group模块: 创建一个group组: [rootlocalhost ~]# ansible group1 -m group -a "nameaaa gid5000" 192.168.17.105 | CHANGED > {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python"}…...

五子棋游戏禁手算法的改进
五子棋游戏禁手算法的改进 五子棋最新的禁手规则: 1.黑棋禁手判负、白棋无禁手。黑棋禁手有“三三”(包括“四三三”)、“四四”(包括“四四三”)和“长连”。黑棋只能以“四三”取胜。 2.黑方…...
基于 Debian 12 的 Devuan GNU+Linux 5 为软件自由爱好者而生
导读Devuan 开发人员宣布发布 Devuan GNULinux 5.0 “代达罗斯 “发行版,它是 Debian GNU/Linux 操作系统的 100% 衍生版本,不包含 systemd 和相关组件。 Devuan GNULinux 5 基于最新的 Debian GNU/Linux 12 “书虫 “操作系统系列,采用长期支…...

算法系列-力扣234-回文链表判定
回文链表判定 给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。 方法一:栈反转对比法 解题思路:找到中间节点后用栈辅助反转对比 解题方法࿱…...

算法通关村——海量数据场景下的热门算法题的处理方法
1. 从40个亿中产生一个不存在的整数 题目要求:给定一个输入文件,包含40亿个非负整数,请设计一个算法,产生一个不存在该文件中的整数,假设你有1GB的内存来完成这项任务。 ● 进阶:如果只有10MB的内存可用&a…...
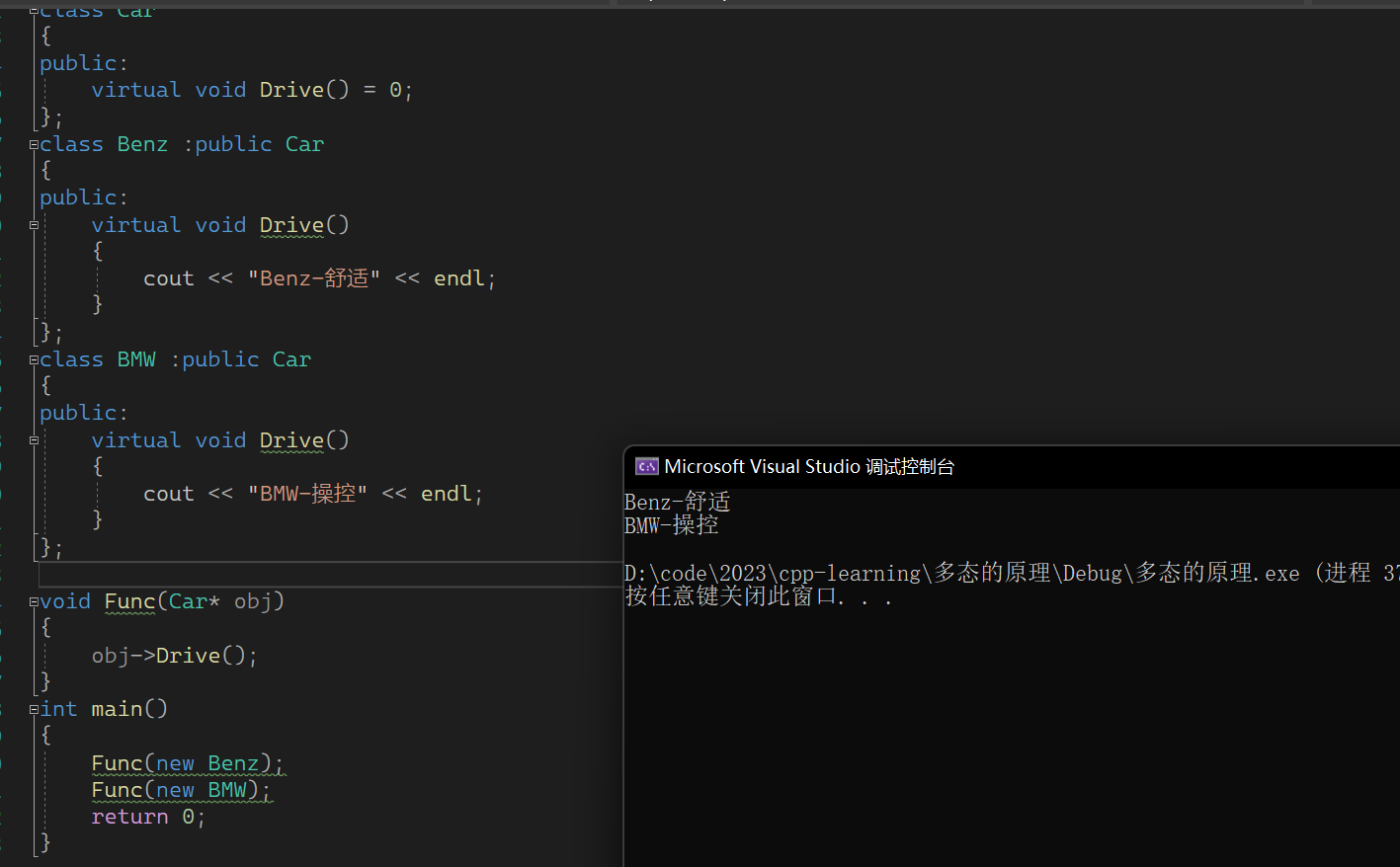
【C++从0到王者】第二十五站:多继承的虚表
文章目录 前言一、多继承的虚函数表二、菱形继承与菱形虚拟继承的虚函数表1.菱形继承2.菱形虚拟继承的虚函数表 三、抽象类1.抽象类的概念2.接口继承与实现继承 总结 前言 其实关于单继承的虚函数表我们在上一篇文章中已经说过了,就是派生类中的虚表相当于拷贝了一…...

老程序员教你如何笑对问题,轻松培养逻辑思考和解决问题的能力
原文链接 老程序员教你如何笑对问题,轻松培养逻辑思考和解决问题的能力 故事发生在一个阳光明媚的午后,我们的主人公,老李,一位拥有十年工作经验的 Python 老程序员,正悠哉地在喝着咖啡。 这时&#x…...
Omni Recover for Mac(专业的iPhone数据恢复软件)
Omni Recover for Mac是一款专业的Mac数据恢复软件,能够帮助用户快速找回被误删除、格式化、病毒攻击等原因造成的文件和数据,包括图片、视频、音频、文档、邮件、应用程序等。同时,Omni Recover for Mac还具有数据备份和清理功能,…...
视频垂直镜像播放,为您的影片带来新鲜感
大家好!在制作视频时,我们常常希望能够给观众带来一些新鲜感和独特的视觉效果。而垂直镜像播放是一个能够让您的影片与众不同的技巧。然而,传统的视频剪辑软件往往无法直接实现视频的垂直镜像播放,给我们带来了一些困扰。现在&…...
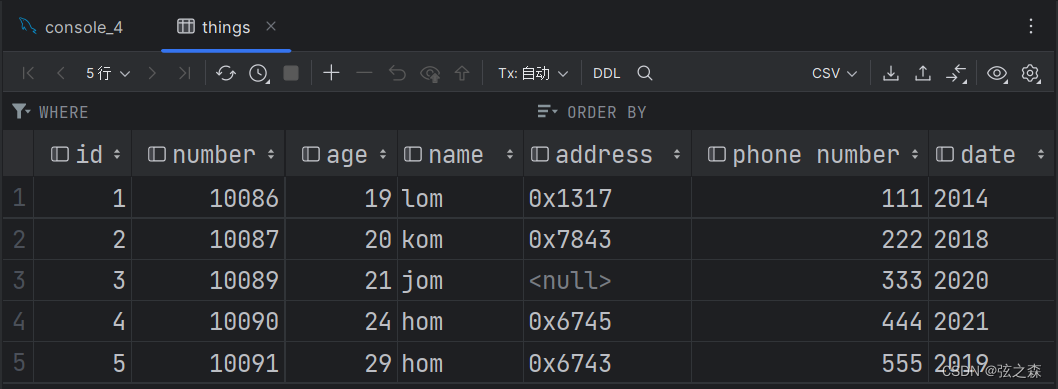
十一、MySQL(DQL)聚合函数
1、聚合函数 注意:在使用聚合函数时,所有的NULL是不参与运算的。 2、实际操作: (1)初始化表格 (2)统计该列数据的个数 基础语法: select count(字段名) from 表名; ;统…...
C语言:三子棋小游戏
简介: 目标很简单:实现一个 三子棋小游戏。三子棋大家都玩过,规则就不提及了。本博文中实现的三子棋在对局中,电脑落子是随机的,不具有智能性,玩家的落子位置使用键盘输入坐标。下面开始详细介绍如何实现一…...

JAVA - PO DTO 生成器
PO DTO 生成器 假设你是一个Java 高级程序员,我会提供一些信息,你需要帮我自动生成Java的PO、DTO 对象。 这些信息有着固定的形式,第一行是对象的类名,其后的每一行都是该对象的属性(简称“属性”)。 对于我属性,格式…...

tcpdump
TCPDump是一个用于抓取网络数据包的命令行工具。它可以帮助网络管理员和开发人员分析网络流量、故障排除以及安全问题。下面是一些TCPDump的详细用法: 基本用法: 监听指定网络接口:tcpdump -i eth0通过IP地址过滤:tcpdump host 19…...

数据通信——传输层TCP(可靠传输原理的ARQ)
引言 上一篇讲述了停止等待协议的工作流程,在最后提到了ARQ自动请求重传机制。接下来,我们就接着上一篇的篇幅,讲一下ARQ这个机制 还是这个图来镇楼 ARQ是什么? 发送端对出错的数据帧进行重传是自动进行的,因而这种…...

Compose - 交互组合项
按钮 Button OutLinedButton带外边框、TextButton只是文字、IconButton只是图标形状。 Button(onClick { }, //点击回调modifier Modifier,enabled true, //启用或禁用interactionSource MutableInteractionSource(),elevation ButtonDefaults.elevatedButtonElevation( /…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

C++使用 new 来创建动态数组
问题: 不能使用变量定义数组大小 原因: 这是因为数组在内存中是连续存储的,编译器需要在编译阶段就确定数组的大小,以便正确地分配内存空间。如果允许使用变量来定义数组的大小,那么编译器就无法在编译时确定数组的大…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...