x86 汇编手册快速入门
本文翻译自:Guide to x86 Assembly
在阅读 Linux 源码之前,我们需要有一些 x86 汇编知识。本指南描述了 32 位 x86 汇编语言编程的基础知识,包括寄存器结构,数据表示,基本的操作指令(包括数据传送指令、逻辑计算指令、算数运算指令),以及函数的调用规则。
一、寄存器(Registers)
如下图,现代 x86 处理器有 8 个 32-bit 的通用寄存器:

由于历史原因,EAX 寄存器过去被用于算术运算,ECX被用于保存循环索引。尽管现在大多数寄存器在现代指令集中已经失去了它们的特殊用途,但有两个寄存器一直保留用于特殊用途——堆栈指针(ESP,用于指示栈顶位置)和基址指针(EBP,用于指示子程序或函数调用的基址指针)。
对于 EAX、EBX、ECX、EDX 四个寄存器来说,其前两个高位字节和后两个低位字节可以独立使用,而后两个低位字节又分为高位(H)和低位(L)部分。这样做的原因主要是为了兼容 16 位程序。
二、内存和寻址模式(Memory and Addressing Modes)
2.1 声明静态数据区(Declaring Static Data Regions)
我们可以使用特殊的汇编指令 .DATA 在 x86 汇编中声明静态数据区域(类似于全局变量),在此指令之后,可以使用指令 DB、DW 和 DD分别声明一个、两个和四个字节的数据大小,声明的数据可以用标签(label)标记,以供以后引用。并且按顺序声明的数据将位于内存中相邻的位置。
下面是一个相关的例子:
.DATA
var DB 64 ; 声明一个字节, 里面的值为 64
var2 DB ? ; 声明一个未初始化的字节DB 10 ; 声明一个没有 label 的字节, 其值为 10
X DW ? ; 声明一个未初始化的双字节
Y DD 30000 ; 声明一个四字节,值为 30000x86 汇编语言中的数组只是在内存中连续放置的若干单元格,可以使用 DUP 指令来声明数据数组:
Z DD 1, 2, 3 ; 声明三个四字节的值, 分别初始化为 1, 2, 3; Z+8 位置存放的是 3
bytes DB 10 DUP(?) ; 声明 10 个未初始化的单字节数据
arr DD 100 DUP(0) ; 声明 100 个初始化为 0 的四字节数据
str DB 'hello',0 ; 声明 6 个单字节数据,前五个被初始化为 ASCII 字符, 最后一个初始化为 null(0) 字节2.2 内存寻址(Addressing Memory)
现代 x86 处理器最多能够寻址 字节大小的内存。在上面的例子中,我们使用标签表示内存区域,这些标签在实际汇编时,均被 32 位的实际地址代替。除了支持这种直接的内存区域描述,X86 还提供了一种灵活的内存寻址方式,即利用最多两个 32 位的寄存器和一个 32 位的有符号常数相加计算一个内存地址,其中一个寄存器可以乘 2, 4 或 8 以表述更大的空间。
下面是正确使用的例子:
mov eax, [ebx] ; 将 ebx 值指示的内存地址中的 4 个字节移动到 eax 中
mov [var], ebx ; 将 ebx 的内容移动到 var 标签所指示的内存地址中
mov eax, [esi-4] ; 将 esi-4 值指示的内存地址中的 4 个字节移动到 eax 中
mov [esi+eax], cl ; 将 cl 值的内容移动到 esi+eax 所指示的内存地址中
mov edx, [esi+4*ebx] ; 将 esi+4*ebx 所指示的内存地址中的 4 个字节移动到 edx 中下面是错误使用的例子:
mov eax, [ebx-ecx] ; 只能将寄存器的值相加,不能相减
mov [eax+esi+edi], ebx ; 最多只能有两个寄存器相加
通常,给定内存地址中数据项的预期大小可以从引用它的汇编代码指令推断出来。当我们加载一个 32 位寄存器时,汇编器可以推断我们引用的内存区域是 4 字节宽。当我们将一个字节寄存器的值存储到内存中时,汇编器可以推断出我们希望地址指向内存中的一个字节。
但对于 mov [ebx], 2 这条指令来说,汇编器无法判断应该将 2 值作为单个字节的数据还是多个字节的数据,这时就需要用到指令 BYTE PTR、WORD PTR 和 DWORD PTR,分别表示 1、2 和 4 字节的大小:
mov BYTE PTR [ebx], 2 ; 将一个字节表示的 2 移动到 ebx 所指向的内存地址处
mov WORD PTR [ebx], 2 ; 将两个字节表示的 2 移动到 ebx 所指向的内存地址处
mov DWORD PTR [ebx], 2 ; 将四个字节表示的 2 移动到 ebx 所指向的内存地址处
三、指令(Instructions)
机器指令通常分为三类:数据移动指令、算术/逻辑指令和控制流指令。在本节中,我们将分别介绍每种类型的重要 x86 指令示例。 这会使用到如下的几种符号表示:
| <reg32> | 任意 32 位寄存器 (EAX, EBX, ECX, EDX, ESI, EDI, ESP, or EBP) |
| <reg16> | 任意 16 位寄存器 (AX, BX, CX, or DX) |
| <reg8> | 任意 8 位寄存器 (AH, BH, CH, DH, AL, BL, CL, or DL) |
| <reg> | 任意寄存器 |
| <mem> | 内存地址 (e.g., [eax], [var + 4], or dword ptr [eax+ebx]) |
| <con32> | 任意 32 位常数 |
| <con16> | 任意 16 位常数 |
| <con8> | 任意 8 位常数 |
| <con> | 任意 32 位、16 位或 8 位常数 |
3.1 数据移动指令(Data Movement Instructions)
mov — Move (Opcodes: 88, 89, 8A, 8B, 8C, 8E, ...)
mov指令将其第二个操作数内容(可以是寄存器、内存或常量)复制到其第一个操作数(寄存器或内存)中。 不能直接用 mov 指令将内存中的值移动到另外一个内存地址。下面是 mov 指令的语法:
mov <reg>,<reg>
mov <reg>,<mem>
mov <mem>,<reg>
mov <reg>,<const>
mov <mem>,<const>例子:
mov eax, ebx ; 复制 ebx 中的内容到 eax
mov byte ptr [var], 5 ; 将单字节表示的 5 存入 var 所指示的内存单元push — Push stack (Opcodes: FF, 89, 8A, 8B, 8C, 8E, ...)
push 指令操作数压入内存的栈中。具体来说,push 指令首先将 ESP (栈指针) 减 4(因为 x86 栈向下增长),然后将其操作数放入地址为 [ESP] 位置的内存单元中。用法如下:
push <reg32>
push <mem>
push <con32>例子:
push eax — push eax on the stack
push [var] — push the 4 bytes at address var onto the stackpop — Pop stack
pop 指令从栈中取出一个数据放入指定寄存器或内存中。pop 指令首先移动地址为 [ESP] 位置的内存单元中的数据到指定寄存器或内存,然后再将 ESP 加 4。用法如下:
pop <reg32>
pop <mem>例子:
pop edi — pop the top element of the stack into EDI.
pop [ebx] — pop the top element of the stack into memory at the four bytes starting at location EBX.lea — Load effective address
lea 指令将第二个操作数指定的内存地址放置到第一个操作数指定的寄存器中。该指令不会加载该内存位置的内容,只计算有效地址并放入寄存器。用法如下:
lea <reg32>,<mem>例子:
lea edi, [ebx+4*esi] — the quantity EBX+4*ESI is placed in EDI.
lea eax, [var] — the value in var is placed in EAX.
lea eax, [val] — the value val is placed in EAX.3.2 算术/逻辑指令(Arithmetic and Logic Instructions)
add — Integer Addition
add 指令将两个操作数相加,结果存储到第一个操作数中。用法如下:
add <reg>,<reg>
add <reg>,<mem>
add <mem>,<reg>
add <reg>,<con>
add <mem>,<con>例子:
add eax, 10 — EAX ← EAX + 10
add BYTE PTR [var], 10 — add 10 to the single byte stored at memory address varsub — Integer Subtraction
sub 指令将两个操作数相减,结果存储到第一个操作数中。用法如下:
sub <reg>,<reg>
sub <reg>,<mem>
sub <mem>,<reg>
sub <reg>,<con>
sub <mem>,<con>例子:
sub al, ah — AL ← AL - AH
sub eax, 216 — subtract 216 from the value stored in EAXinc, dec — Increment, Decrement
inc 指令将操作数的内容加一,而 dec 指令将操作数的内容减一。用法如下:
inc <reg>
inc <mem>
dec <reg>
dec <mem>例子:
dec eax — subtract one from the contents of EAX.
inc DWORD PTR [var] — add one to the 32-bit integer stored at location varimul — Integer Multiplication
imul 指令分为两个操作数和三个操作数两种类型,如果是两个操作数,则让两个操作数相乘,并将结果存入第一个操作数中;如果是三个操作数,则让第二个和第三个操作数相乘,结果存入第一个操作数中,且第三个操作数必须是常数。不管哪种类型,第一个操作数必须是寄存器。用法如下:
imul <reg32>,<reg32>
imul <reg32>,<mem>
imul <reg32>,<reg32>,<con>
imul <reg32>,<mem>,<con>例子:
imul eax, [var] — multiply the contents of EAX by the 32-bit contents of the memory location var. Store the result in EAX.
imul esi, edi, 25 — ESI → EDI * 25idiv — Integer Division
idiv 指令将 64 位整数 EDX:EAX (将 EDX 视为高 4 字节,将 EAX 视为低 4 字节) 的内容除以指定的操作数值。除法的商存储在 EAX 中,余数存储在 EDX 中。 用法如下:
idiv ebx — divide the contents of EDX:EAX by the contents of EBX. Place the quotient in EAX and the remainder in EDX.
idiv DWORD PTR [var] — divide the contents of EDX:EAX by the 32-bit value stored at memory location var. Place the quotient in EAX and the remainder in EDX.and, or, xor — Bitwise logical and, or and exclusive or
and,or,xor 指令分别对两个操作数作与、或、异或操作,结果存入第一个操作数中。用法如下:
and <reg>,<reg>
and <reg>,<mem>
and <mem>,<reg>
and <reg>,<con>
and <mem>,<con>or <reg>,<reg>
or <reg>,<mem>
or <mem>,<reg>
or <reg>,<con>
or <mem>,<con>xor <reg>,<reg>
xor <reg>,<mem>
xor <mem>,<reg>
xor <reg>,<con>
xor <mem>,<con>例子:
and eax, 0fH — clear all but the last 4 bits of EAX.
xor edx, edx — set the contents of EDX to zero.not — Bitwise Logical Not
not 指令逻辑上对操作数的内容求反 (即翻转操作数中的所有位)。用法如下:
not <reg>
not <mem>neg — Negate
neg 指令对操作数内容取负。用法如下:
neg <reg>
neg <mem>Example
neg eax — EAX → - EAXshl, shr — Shift Left, Shift Right
shl, shr 指令会左右移动第一个操作数的位,用0填充空的位。操作数最多可以被移动 31 位。移位的位数由第二个操作数指定,若操作数大于 32,则对其求模。 用法如下:
shl <reg>,<con8>
shl <mem>,<con8>
shl <reg>,<cl>
shl <mem>,<cl>shr <reg>,<con8>
shr <mem>,<con8>
shr <reg>,<cl>
shr <mem>,<cl>3.3 控制流指令(Control Flow Instructions)
x86 处理器维持着一个指示当前执行指令的指令指针(IP),当一条指令执行后,此指针自动指向下一条指令。IP 寄存器不能直接操作,但是可以用控制流指令更新(CS和IP寄存器的作用及执行分析_cs ip_猪哥-嵌入式的博客-CSDN博客)。
一般用标签(label)指示程序中的地址,在 x86 汇编代码中,可以在任何指令前加入标签。如:
mov esi, [ebp+8]
begin: xor ecx, ecxmov eax, [esi]这种标签只是用于取代 32 位地址值的一种便利的表示方式。这样在其他代码中就可以使用该标签,而不是使用其对应具体的 32 位地址。
jmp — Jump
jmp 指令用于跳转到指定的 label 位置处执行。用法如下:
jmp <label>Example
jmp begin — Jump to the instruction labeled begin.jcondition — Conditional Jump
jcondition 类的指令用于条件跳转(即满足条件才跳转)。这些条件存储在一个称为机器状态字 (machine status word) 的特殊寄存器中。一般会在执行下列指令之前先执行 cmp 指令对两个操作数进行比较。用法如下:
je <label> (jump when equal)
jne <label> (jump when not equal)
jz <label> (jump when last result was zero)
jg <label> (jump when greater than)
jge <label> (jump when greater than or equal to)
jl <label> (jump when less than)
jle <label> (jump when less than or equal to)Example
cmp eax, ebx
jle done; 如果 eax 小于 ebx 的内容,则跳转到标签 done 所指向的位置处指向,若大于则继续往下执行cmp — Compare
cmp 指令比较两个操作数指定的值,然后设置适当的机器状态字的状态码。这条指令等同于减法指令,但是会舍弃减法的结果。用法如下:
cmp <reg>,<reg>
cmp <reg>,<mem>
cmp <mem>,<reg>
cmp <reg>,<con>Example
cmp DWORD PTR [var], 10
jeq loopcall, ret — Subroutine call and return
call 和 ret 指令用于实现子程序的调用和返回。
call 指令首先将当前代码执行位置压入栈中,然后无条件跳转到 label 操作数指定的位置。与简单的跳转指令不同,该指令会保存当前代码执行位置,以便子程序执行完后返回。
ret 指令实现子程序的返回。该指令首先从栈弹出 call 指令保存的代码执行位置,然后无条件返回到该位置继续执行。
call <label>
ret四、调用约定(Calling Convention)
为了加强程序员之间的协作及简化程序开发进程,设定一个函数调用约定非常必要,函数调用约定规定了函数调用及返回的规则,只要遵照这种规则写的程序均可以正确执行,从而程序员不必关心诸如参数如何传递等问题;另一方面,在汇编语言中可以调用符合这种规则的高级语言所写的函数,从而将汇编语言程序与高级语言程序有机结合在一起。有了这个约定,我们就可以在汇编代码中调用 C 函数,或者在 C 代码中调用汇编实现的函数。
调用约定分为两个方面,及调用者约定和被调用者约定,如一个函数 A 调用一个函数 B,则 A 被称为调用者 (Caller),B 被称为被调用者 (Callee)。
下图显示一个调用过程中的内存中的栈布局:
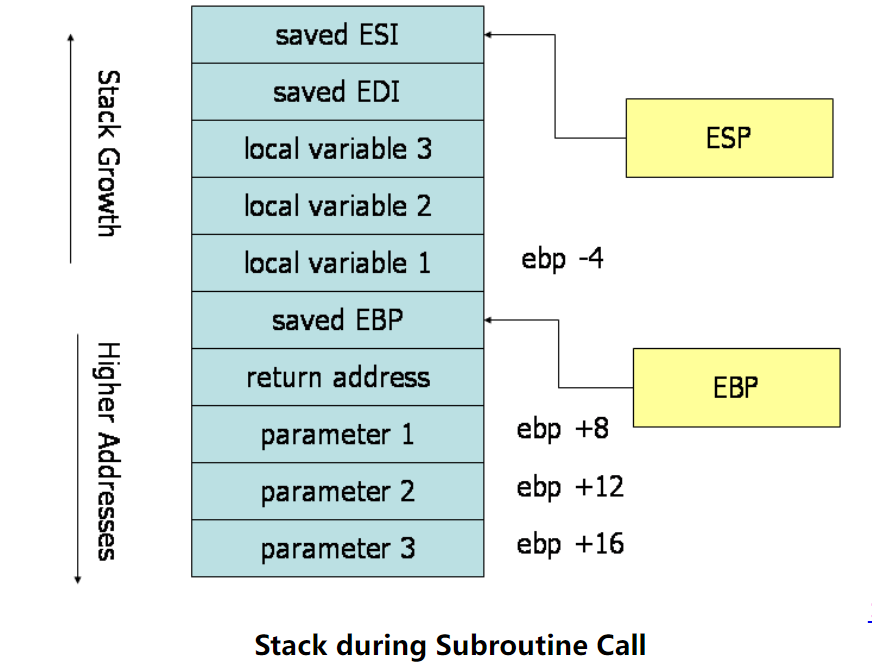
4.1 Caller Rules
调用者规则包括一系列约定:
- 在调用子程序之前,调用者应该保存一系列被设计为调用者应该保存的寄存器的值。调用者应该保存的寄存器有 EAX、ECX、EDX。由于被调用的子程序允许修改这些寄存器,如果调用者在子程序返回后还需要用到这些寄存器的值,则调用者必须将这些寄存器中的值压入堆栈(以便在子例程返回后可以恢复它们)。
- 要将参数传递给子例程,需要在调用之前将它们压入栈。参数应该按倒序推送 (即最后一个参数先 push),因为栈是向下增长的。
- 使用 call 指令调用子程序。该指令将返回地址放在栈的顶部,并转到子程序执行(子程序的执行将按照被调用者的规则执行)。
在子例程返回之后,调用者可以期望在寄存器 EAX 中找到子程序的返回值。为了恢复调用子程序执行之前的状态,调用者应该执行以下操作:
- 清除栈中的参数。
- 将栈中保存的 EAX 值、ECX 值以及 EDX 值出栈,恢复 EAX、ECX、EDX 的值(当然,如果其它寄存器在调用之前需要保存,也需要完成类似入栈和出栈操作)。
例子:
push [var] ; Push last parameter first
push 216 ; Push the second parameter
push eax ; Push first parameter lastcall _myFunc ; Call the function (assume C naming)add esp, 12上述例子展示了一个调用者执行的操作,在调用 _myFunc 函数之前,先保存函数的三个传入参数 eax、216 和 var,然后使用 call 指令调用函数,返回后再将 esp(栈指针)的值加 12(三个参数,每个四字节),加 12 的目的是为了清空栈中的三个参数。
_myFunc 的返回值保存在 eax 中。若该函数会改变 ecx 和 edx 中的值,调用者还必须在调用之前将其也保存在栈中,并在调用结束之后,出栈恢复ecx和edx的值。
4.2 Callee Rules
- 将 EBP(基址寄存器)入栈(push ebp),并将 ESP 中的值拷贝到 EBP 中(mov ebp esp),目的是保存调用子程序之前的基址指针,基址指针用于寻找栈上的参数和局部变量。当一个子程序开始执行时,基址指针保存栈指针指示子程序的执行。为了在子程序完成之后调用者能正确定位调用者的参数和局部变量,ebp的值需要返回。
- 在栈上为局部变量分配空间。
- 保存 callee-saved 寄存器的值,callee-saved 寄存器包括 ebx,edi 和 esi,将 ebx,edi 和 esi 压栈。
在上述三个步骤完成之后,子程序开始执行,当子程序返回时,必须完成如下工作:
- 将返回的执行结果保存在 eax 中
- 弹出栈中保存的 callee-saved 寄存器值,恢复 callee-saved 寄存器的值(ESI和EDI)
- 收回局部变量的内存空间。实际处理时,通过改变 EBP 的值即可:mov esp, ebp。
- 通过弹出栈中保存的 ebp 值恢复调用者的基址寄存器值。
- 执行 ret 指令返回到调用者程序。
例子:
.486
.MODEL FLAT
.CODE
PUBLIC _myFunc
_myFunc PROC; Subroutine Prologuepush ebp ; Save the old base pointer value.mov ebp, esp ; Set the new base pointer value.sub esp, 4 ; Make room for one 4-byte local variable.push edi ; Save the values of registers that the functionpush esi ; will modify. This function uses EDI and ESI.; (no need to save EBX, EBP, or ESP); Subroutine Bodymov eax, [ebp+8] ; Move value of parameter 1 into EAXmov esi, [ebp+12] ; Move value of parameter 2 into ESImov edi, [ebp+16] ; Move value of parameter 3 into EDImov [ebp-4], edi ; Move EDI into the local variableadd [ebp-4], esi ; Add ESI into the local variableadd eax, [ebp-4] ; Add the contents of the local variable; into EAX (final result); Subroutine Epilogue pop esi ; Recover register valuespop edimov esp, ebp ; Deallocate local variablespop ebp ; Restore the caller's base pointer valueret
_myFunc ENDP
END子程序首先通过入栈的手段保存 ebp,分配局部变量,保存寄存器的值。
在子程序体中,参数和局部变量均是通过 ebp 进行计算。由于参数传递在子程序被调用之前,所以参数总是在 ebp 指示的地址的下方(在栈中),因此,上例中的第一个参数的地址是 ebp+8,第二个参数的地址是 ebp+12,第三个参数的地址是 ebp+16;而局部变量在 ebp 指示的地址的上方,所有第一个局部变量的地址是 ebp-4,而第二个这是 ebp-8.
相关文章:
x86 汇编手册快速入门
本文翻译自:Guide to x86 Assembly 在阅读 Linux 源码之前,我们需要有一些 x86 汇编知识。本指南描述了 32 位 x86 汇编语言编程的基础知识,包括寄存器结构,数据表示,基本的操作指令(包括数据传送指令、逻…...

WPF C# Binding绑定不上的解决情况
Binding绑定不上的一般解决情况: 1.添加上下文 DataContext d:DataContext"{d:DesignInstance Typelocal:CommSettingView}"2.添加相对位置 RelativeSource Command"{Binding SaveCommand, RelativeSource{RelativeSource AncestorTypeUserContr…...
【UE 材质】实现方形渐变、中心渐变材质
步骤 一、实现方形渐变 1. 新建一个材质,材质域选择“后期处理” 2. 通过“Mask”节点单独获取R、G通道,可以看到R通道是从左到右0~1之间的变化,对应U平铺 可以看到G通道是从上到下0~1之间的变化,对应V平铺 3. 完善如下节点 二、…...
PHP旅游管理系统Dreamweaver开发mysql数据库web结构php编程计算机网页
一、源码特点 PHP 旅游管理系统是一套完善的web设计系统,对理解php编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 PHP 旅游管理系统 源码下载地址: https://download.csdn.net/download/qq_41…...

java内存模型讨论及案例分析
常用内存选项 -Xmx: 最大堆大小 -Xms:最小堆大小 -Xss :线程堆栈大小,默认1M 生产环境最好保持 Xms Xmx java内存研究 内存布局 可见: 堆大小 新生代 老年代,新生代EFrom SurvivorTo Survivor。新…...

对战ChatGPT,创邻科技的Graph+AI会更胜一筹吗?
大模型(大规模语言模型,即Large Language Model)的应用已经成为千行百业发展的必然。特定领域或行业中经过训练和优化的企业级垂直大模型则成为大模型走下神坛、真正深入场景的关键之路。 但是,企业级垂直大模型在正式落地应用前…...

9月2日,每日信息差
1、墨迹天气发布全球雷达融合降水服务产品。据介绍,该产品基于机器学习技术,对全球气象雷达观测图片进行智能识别去噪和外推,并融合全球气象模式、卫星等数据,提供全球范围公里级、分钟级降水预报,可围绕降水灾害的不同…...

uni-app之android项目云打包
1,项目根目录,找到mainfest.json,如果appid是空的,需要生成一个appid 2,点击重新获取appid,这个时候需要登录,那就输入账号密码登录下 3,登陆后可以看到获取appid成功 4,…...

C++的智能指针和可变参数模板详解
智能指针 1. 垃圾回收 垃圾回收机制已经大行其道,得到了诸多编程语言的支持,例如Java、Python、 C#、PHP等。而C虽然从来没有公开得支持过垃圾回收机制,但C98/03标准中,支持使用auto_ptr智能指针来实现堆内存的自动回收; C11新标…...

Docker及常用数据库安装
Docker安装常用数据库 1、Docker安装2、Mysql安装3、Redis安装4、DM安装5、Oracle安装1、Docker安装 1、确保 yum 包更新到最新yum update2、卸载旧版本(如果安装过旧版本的话)yum remove docker docker-common docker-selinux docker-engine3、安装需要的软件包, yum-util 提…...

前端使用 JavaScript 检测用户是否在线的6种方法
要检测用户是否在线,可以使用以下几种方法: 1. 使用navigator.onLine属性: navigator.onLine是一个布尔值,表示用户是否与互联网连接。当用户在线时,该属性的值为true,当用户离线时,该属性的值…...

Windows下Redis的安装
文章目录 一,Redis介绍二,Redis下载三,Redis安装-解压四,Redis配置五,Redis启动和关闭(通过terminal操作)六,Redis连接七,Redis使用 一,Redis介绍 远程字典服务,一个开源的,键值对形式的在线服务框架,值支持多数据结构,本文介绍windows下Redis的安装,配置相关,官网默认下载的是…...

SpringBoot第45讲:SpringBoot定时任务 - Timer实现方式
SpringBoot第45讲:SpringBoot定时任务 - Timer实现方式 定时任务在实际开发中有着广泛的用途,本文是SpringBoot第45讲,主要帮助你构建定时任务的知识体系,同时展示Timer 的schedule和scheduleAtFixedRate例子;后续的文章中我们将逐一介绍其它常见的定时任务,并与SpringBo…...
)
01背包(换汤不换药)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 有一个箱子容量为V(正整数,0 ≤ V ≤ 20000),同时有n个物品(0<n ≤ 30),每个物品有一个体积…...
c++ folly::baton
Baton folly::Baton 是 Facebook 开源的一个同步原语,它提供了一种简单而灵活的方式来进行线程间的同步。它属于 Folly 库,是 C 编程语言的一个组件。 Baton 通常用作线程间同步、等待、通知的标识符号,常用姿势是,一些线程调用…...

05.sqlite3学习——DML(数据管理:插入、更新、删除)
目录 DML(数据管理:插入、更新、删除) 插入 更新 删除整个表 语法 实例 DML(数据管理:插入、更新、删除) 数据操纵(DML):用于增、删、改数据 作用:负…...
Netty-ChannelPipeline
EventLoop可以说是 Netty 的调度中心,负责监听多种事件类型:I/O 事件、信号事件、定时事件等,然而实际的业务处理逻辑则是由 ChannelPipeline 中所定义的 ChannelHandler 完成的,ChannelPipeline 和 ChannelHandler应用开发的过程…...
从入门到精通,30天带你学会C++【第六天:与或非三兄弟和If判断语句(博主目前最长文章,2514字)】(学不会你找我)
目录 前言 计算机里的真和假 与或非三兄弟 编辑与运算(&&) 具体说明表格: 举个栗子1: 或运算(||) 具体说明表格: 举个栗子2: 非运算(!)…...

如何快速找出占用空间最大的文件?
分析&回答 使用 find 命令找到大于指定大小的文件: 当前目录大于500M文件 find ./ -size 500M用户目录大于500M文件 find ~ -type f -size 500M根目录大于500M文件 find / -type f -size 500M 复制代码 让文件按大小排序 du -h * | sort -n 喵呜面试助手&am…...

算法:分治思想处理归并递归问题
文章目录 算法原理实现思路典型例题排序数组数组中的逆序对计算右侧小于当前元素的个数 总结 算法原理 利用归并思想进行分治也是很重要的一种思路,在解决逆序对的问题上有很大的需求空间 于是首先归并排序是首先的,归并排序要能写出来: c…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...