【Spark】Pyspark RDD
- 1. RDD算子
- 1.1 文件 <=> rdd对象
- 1.2 map、foreach、mapPartitions、foreach Partitions
- 1.3 flatMap 先map再解除嵌套
- 1.4 reduceByKey、reduce、fold 分组聚合
- 1.5 mapValue 二元组value进行map操作
- 1.6 groupBy、groupByKey
- 1.7 filter、distinct 过滤筛选
- 1.8 union 合并
- 1.9 join、leftOuterJoin、rightOuterJoin 连接
- 1.10 intersection 交集
- 1.11 sortBy、sortByKey 排序
- 1.12 countByKey 统计key出现次数
- 1.13 first、take、top、count 取元素
- 1.14 takeOrdered 排序取前n个
- 1.15 takeSample 随机抽取
from pyspark import SparkConf, SparkContextconf = SparkConf().setAppName('test')\.setMaster('local[*]')
sc = SparkContext(conf=conf)
1. RDD算子
1.1 文件 <=> rdd对象
# 集合对象 -> rdd (集合对象,分区数默认cpu核数)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(rdd.glom().collect(), rdd.getNumPartitions())
# [[1, 2], [3, 4], [5, 6]] 3# 文件 -> rdd
rdd = sc.textFile("./data.csv")
print(rdd.collect())
# ['1, 2, 3, 4, 5, 6']# rdd -> 文件
rdd = sc.parallelize([1, 2, 3], 3)
rdd.saveAsTextFile('./output')
'''
生成output文件夹
里面有按分区存储的多个文件
'''
1.2 map、foreach、mapPartitions、foreach Partitions
# map函数
rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
rdd2 = rdd.map(lambda x: (x, 1))
print(rdd2.map(lambda x: x[0] + x[1]).collect())
# [2, 3, 4, 5, 6, 7]# foreach
# 同map,但无返回值,且不改变原元素
# 另有foreachPartitions
rdd = sc.parallelize([1, 2, 3])
rdd.foreach(lambda x: print(x))
# 1 3 2
rdd.foreach(lambda x: -x)
rdd.collect()
# [1, 2, 3]
# mapPartitions
'''
map 一次调出一个元素进行计算,io次数多
mapPartitions 一次将一个分区的所有元素调出计算s
'''
rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)def func(iter):# 相较于map时间复杂度没优化,空间复杂度优化res = list()for it in iter:res.append(it * 10)return resrdd.mapPartitions(func).collect()
# [10, 20, 30, 40, 50, 60]
1.3 flatMap 先map再解除嵌套
# flatMap 先执行map操作,再解除嵌套(降维 softmax前flatten)
rdd = sc.textFile("./data.csv")
print(rdd.collect())rdd.flatMap(lambda x: x.split(' ')).collect()
1.4 reduceByKey、reduce、fold 分组聚合
# reduceByKey 按照key分组,再对组内value完成聚合逻辑
# key-value型(二元元组)rdd
rdd = sc.parallelize([('a', 1), ('a', 2), ('b', 3)])
print(rdd.reduceByKey(lambda a, b: a + b).collect())
# [('b', 3), ('a', 3)]
# reduce 只聚合
# 不返回rdd
rdd = sc.parallelize(range(1, 3))
print(rdd.reduce(lambda a, b: a + b))
# 3
print(sc.parallelize([('a', 1), ('a', 1)]).reduce(lambda a, b: a + b))
# ('a', 1, 'a', 1)
# fold 带初值的reduce
rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(rdd.fold(10, lambda a, b: a + b))
'''
[[1, 2], [3, 4], [5, 6]]
10 + 1 + 2 = 13
10 + 3 + 4 = 17
10 + 5 + 6 = 21
10 + 13 + 17 + 21 = 61
> 61
'''
1.5 mapValue 二元组value进行map操作
# mapValues 对二元组内的value执行map操作, 没有分组操作
rdd = sc.parallelize([('a', 1), ('a', 2), ('b', 3)])
rdd.mapValues(lambda x: x * 10).collect()
1.6 groupBy、groupByKey
- groupBy、groupByKey、reduceByKey区别
# groupBy 多元组皆可进行分组,可选择按哪一个值分组
# reduceByKey 分组后(ByKey)对value进行聚合(reduce),二元组第一个值为key
rdd = sc.parallelize([('a', 1), ('a', 2), ('b', 3), ('b', 4)])# 分组 按第一个值
rdd2 = rdd.groupBy(lambda x: x[0])
print(rdd2.collect())
'''
返回的是迭代器,需进一步转换
[('a', <pyspark.resultiterable.ResultIterable object at 0x106178370>),
('b', <pyspark.resultiterable.ResultIterable object at 0x1060abe50>)]
'''
rdd3 = rdd2.map(lambda x: (x[0], list(x[1])))
print(rdd3.collect())
'''
[('a', [('a', 1), ('a', 2)]),
('b', [('b', 3), ('b', 4)])]
'''
# groupByKey
# 自动按照key分组,分组后没有聚合操作,只允许二元组
rdd = sc.parallelize([('a', 1), ('a', 2), ('b', 3), ('b', 4)])rdd2 = rdd.groupByKey()
rdd2.map(lambda x: (x[0], list(x[1]))).collect()
# [('a', [1, 2]), ('b', [3, 4])]
1.7 filter、distinct 过滤筛选
# filter 过滤器
# 过滤条件True则保留
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.filter(lambda x: x > 3).collect()
# [4, 5]
# distinct 去重
rdd = sc.parallelize([1, 1, 1, 1, 2, 3, 'a', 'a'])
rdd.distinct().collect()
# [[1, 'a', 2, 3]
1.8 union 合并
# union 合并两个rdd
# 元素凑在一起,不考虑重复
rdd_a = sc.parallelize([1, 1, 2, 3])
rdd_b = sc.parallelize([2, 3, ('a', 1), ('b', 2)])rdd_a.union(rdd_b).collect()
# [1, 1, 2, 3, 2, 3, ('a', 1), ('b', 2)]
1.9 join、leftOuterJoin、rightOuterJoin 连接
# join JOIN操作
# 只用于二元组,相同key进行关联
rdd_a = sc.parallelize([('a', 1), ('a', 2), ('b', 3)])
rdd_b = sc.parallelize([('a', 1), ('b', 2), ('c', 3)])print(rdd_a.join(rdd_b).collect())
'''
内连接 取交集
[('b', (3, 2)),
('a', (1, 1)),
('a', (2, 1))]
'''
print(rdd_a.leftOuterJoin(rdd_b).collect())
'''
左连接 取交集和左边全部
[('b', (3, 2)),
('a', (1, 1)),
('a', (2, 1))]
'''
print(rdd_a.rightOuterJoin(rdd_b).collect())
'''
右连接 取交集和右边全部
[('b', (3, 2)),
('c', (None, 3)),
('a', (1, 1)),
('a', (2, 1))]
'''
1.10 intersection 交集
# intersection 取交集
# 区别于join,没有按key连接的操作
rdd_a = sc.parallelize([('a', 1), ('a', 2), ('b', 3)])
rdd_b = sc.parallelize([('a', 1), ('b', 2), ('c', 3)])rdd_a.intersection(rdd_b).collect()
# [('a', 1)]
1.11 sortBy、sortByKey 排序
# sortBy
# func 指定排序元素的方法
# ascending True生序,False降序
# numPartitions 用多少分区排序
rdd = sc.parallelize([[1, 2, 3], [7, 8, 9],[4, 5, 6]])
rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=3).collect()
'''
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
'''
# sortByKey 针对kv型rdd
'''
ascending True升序,False降序
numPartitions 全局有序要设为1,否则只能保证分区内有序
keyfunc 对key进行处理,再排序
'''
rdd = sc.parallelize([('a', 1), ('c', 2), ('B', 3)])
print(rdd.sortByKey(ascending=True, numPartitions=1).collect())
'''
[('B', 3), ('a', 1), ('c', 2)]
'''
print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda k: str(k).lower()).collect())
'''
[('a', 1), ('B', 3), ('c', 2)]
'''
1.12 countByKey 统计key出现次数
# countByKey 统计key出现次数,可多元元组
# 返回dict 不是rdd
rdd = sc.parallelize([('a', 1, 2), ('a'), ('b', 1)])
rdd.countByKey()
1.13 first、take、top、count 取元素
# first 取第一个元素
rdd = sc.parallelize([('a', 1, 2), ('a'), ('b', 1)])
print(rdd.first() )
# ('a', 1, 2)# take 取前n个元素
print(rdd.take(2))
# [('a', 1, 2), 'a']# count 返回元素个数
print(rdd.count())# top 降序排序取前n个
rdd = sc.parallelize([2, 4, 1, 6])
print(rdd.top(2))
# [6, 4]
1.14 takeOrdered 排序取前n个
# takeOrdered 排序取前n个
'''
param1: n
param2: func取数前更改元素,不更改元素本身,
不传func,默认升序(取前n最小值)
func = lambda x: -x 变为降序,取前n最大值,和top相同
'''
rdd = sc.parallelize([2, 4, 1, 6])
rdd.takeOrdered(2) # [1, 2]
rdd.takeOrdered(2, lambda x: -x) # [6, 4]
1.15 takeSample 随机抽取
# takeSample 随机抽取元素
'''
param1: True随机有放回抽样,Fasle不放回抽样
param2: 抽样个数
param3: 随机数种子
'''
rdd = sc.parallelize([1])
rdd.takeSample(True, 2)
相关文章:

【Spark】Pyspark RDD
1. RDD算子1.1 文件 <> rdd对象1.2 map、foreach、mapPartitions、foreach Partitions1.3 flatMap 先map再解除嵌套1.4 reduceByKey、reduce、fold 分组聚合1.5 mapValue 二元组value进行map操作1.6 groupBy、groupByKey1.7 filter、distinct 过滤筛选1.8 union 合并1.9 …...
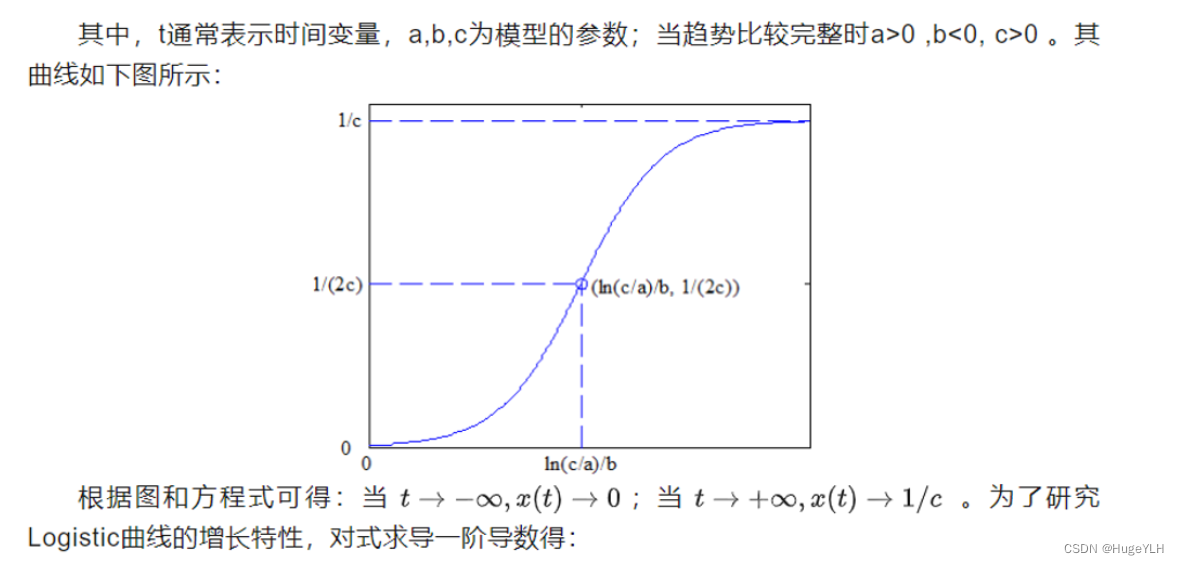
数学建模:Logistic回归预测
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:Logistic回归预测 Logistic回归预测 logistic方程的定义: x t 1 c a e b t x_{t}\frac{1}{cae^{bt}}\quad xtcaebt1 d x d t − a b e b t ( c a e b t ) 2 >…...

一个面向MCU的小型前后台系统
JxOS简介 JxOS面向MCU的小型前后台系统,提供消息、事件等服务,以及软件定时器,低功耗管理,按键,led等常用功能模块。 gitee仓库地址为(复制到浏览器打开): https://gitee.com/jer…...
软件外包开发人员分类
在软件开发中,通常会分为前端开发和后端开发,下面和大家分享软件开发中的前端开发和后端开发分类和各自的职责,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 1. 前端开发&…...

HTML 元素被定义为块级元素或内联元素
大多数 HTML 元素被定义为块级元素或内联元素。 10. 块级元素 块级元素在浏览器显示时,通常会以新行来开始(和结束)。 我们已经学习过的块级元素有: <h1>, <p>, <ul>, <table> 等。 值得注意的是: <p> 标签…...

单调递增的数字【贪心算法】
单调递增的数字 当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。 给定一个整数 n ,返回 小于或等于 n 的最大数字,且数字呈 单调递增 。 public class Solution {public int monotoneIncreasingDigits…...
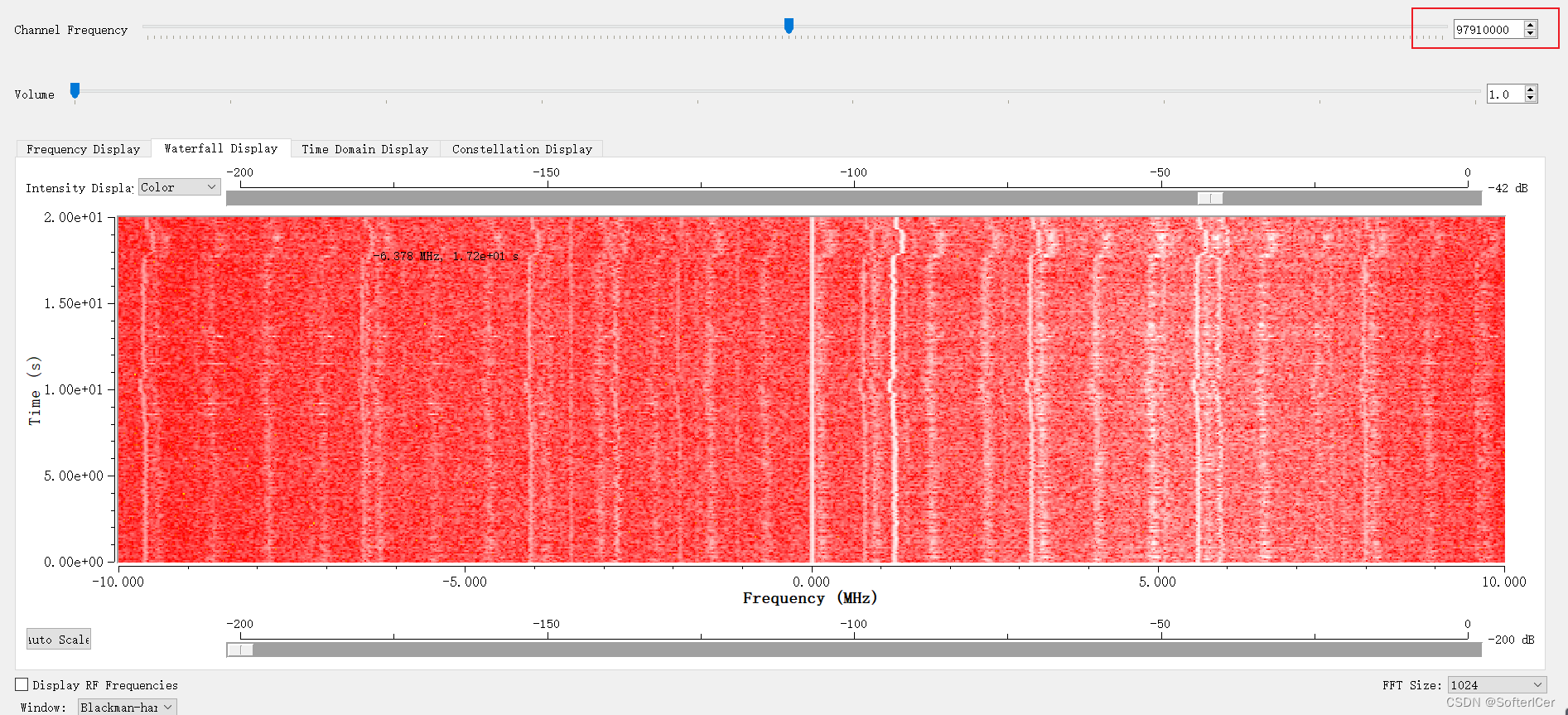
gnuradio-hackrf_info.exe -FM频率使用
97910000...
--生产环境的线程问题诊断)
JVM学习(三)--生产环境的线程问题诊断
1.如何定位哪个进程对cpu占用过高 使用top命令 2.如何定位到某个进程的具体某个线程 使用ps H -eo pid,tid,%cpu | grep 进程id (可以具体定位到某个进程的某个线程的cpu占用情况) 3.如何查看有问题线程的具体信息,定位到代码的行数 使用jstack 进程id 可以找…...

PHP数组处理$arr1转换为$arr2
请编写一段程序将$arr1转换为$arr2 $arr1 array( 0>array (fid>1,tid>1,name>Name1), 1>array (fid>2,tid>2,name>Name2), 2>array (fid>3,tid>5,name>Name3), 3>array (fid>4,tid>7,name>Name4), 4>array (fid>5,tid…...
安全通告 TFV-10 (CVE-2022-47630))
ATF(TF-A)安全通告 TFV-10 (CVE-2022-47630)
安全之安全(security)博客目录导读 ATF(TF-A)安全通告汇总 目录 一、ATF(TF-A)安全通告 TFV-10 (CVE-2022-47630) 二、CVE-2022-47630 2.1 Bug 1:证书校验不足 2.2 Bug 2:auth_nvctr()中缺少边界检查...

详解 SpringMVC 中获取请求参数
文章目录 1、通过ServletAPI获取2、通过控制器方法的形参获取请求参数3、[RequestParam ](/RequestParam )4、[RequestHeader ](/RequestHeader )5、[CookieValue ](/CookieValue )6、通过POJO获取请求参数7、解决获取请求参数的乱码问题总结 在Spring MVC中,获取请…...

Message: ‘chromedriver‘ executable may have wrong permissions.
今天运行项目遇到如下代码 driverwebdriver.Chrome(chrome_driver, chrome_optionsoptions)上述代码运行报错如下: Message: chromedriver executable may have wrong permissions. Please see https://sites.google.com/a/chromium.org/chromedriver/home出错的原…...
每日一题 1372二叉树中的最长交错路径
题目 给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下: 选择二叉树中 任意 节点和一个方向(左或者右)。如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。改变前进方…...

【力扣每日一题】2023.9.2 最多可以摧毁的敌人城堡数量
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 这道题难在阅读理解,题目看得我匪夷所思,错了好多个测试用例才明白题目说的是什么。 我简单翻译一下就是寻找1和…...

kotlin实现java的单例模式
代码 package com.flannery.interviewdemo.singleinstance//https://blog.csdn.net/Jason_Lee155/article/details/128796742 Java实现 //public class SingletonDemo { // private static SingletonDemo instancenew SingletonDemo(); // private SingletonDemo() // …...

使用 KeyValueDiffers 检测Angular 对象的变化
使用 KeyValueDiffers 检测Angular 对象的变化 ngDoCheck钩子 ngDoCheck 是 Angular 生命周期钩子之一。它允许组件在 Angular 检测到变化时执行自定义的变化检测逻辑。 当任何组件或指令的输入属性发生变化、在组件内部发生了变更检测周期或者当主动触发变更检测策略&#…...

Macos 10.13.2安装eclipse
eclipse for php 安装2021-12最后版本4.22 2021-12 R | Eclipse Packages jdk17 x64 dmg安装包,要安装jdk这个才能运行 Java Downloads | Oracle...
Android逆向学习(一)vscode进行android逆向修改并重新打包
Android逆向学习(一)vscode进行android逆向修改并重新打包 写在前面 其实我不知道这个文章能不能写下去,其实我已经开了很多坑但是都没填上,现在专利也发出去了,就开始填坑了,本坑的主要内容是关于androi…...

【深入浅出设计模式--状态模式】
深入浅出设计模式--状态模式 一、背景二、问题三、解决方案四、 适用场景总结五、后记 一、背景 状态模式是一种行为设计模式,让你能在一个对象的内部状态变化时改变其行为,使其看上去就像改变了自身所属的类一样。其与有限状态机的概念紧密相关&#x…...

Debezium系列之:Debezium Server在生产环境大规模应用详细的技术方案
Debezium系列之:Debezium Server在生产环境大规模应用详细的技术方案 一、需求背景二、Debezium Server实现技术三、技术方案流程四、生成接入配置五、新增数据库接入和删除数据库接入效果六、监控zookeeper节点程序七、新增数据库接入部署debezium server程序八、删除数据库接…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤
从‘文件夹’到对象列表:手把手教你用MinIO Java Client实现灵活的文件查询与过滤在当今数据驱动的时代,对象存储已成为现代应用架构中不可或缺的一部分。MinIO作为高性能、兼容S3协议的开源对象存储解决方案,凭借其轻量级和易用性赢得了众多…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...