【100天精通Python】Day53:Python 数据分析_NumPy数据操作和分析进阶
目录
1. 广播
2 文件输入和输出
3 随机数生成
4 线性代数操作
5 进阶操作
6 数据分析示例
1. 广播
广播是NumPy中的一种机制,用于在不同形状的数组之间执行元素级操作,使它们具有兼容的形状。广播允许你在不显式复制数据的情况下,对不同形状的数组进行运算。当你尝试对形状不同的数组进行操作时,NumPy会自动调整这些数组的形状,使它们具有兼容的形状,以便进行元素级运算。
广播规则和示例: 广播的规则如下:
- 如果两个数组的维度不同,将维度较小的数组的形状在其前面补1,直到两个数组的维度相同。
- 如果两个数组的形状在某个维度上不一致,但其中一个数组的维度大小为1,那么这个维度的大小将被扩展为与另一个数组相同。
- 如果两个数组在任何维度上的大小都不匹配且没有一个维度的大小为1,则广播操作将失败,引发异常。

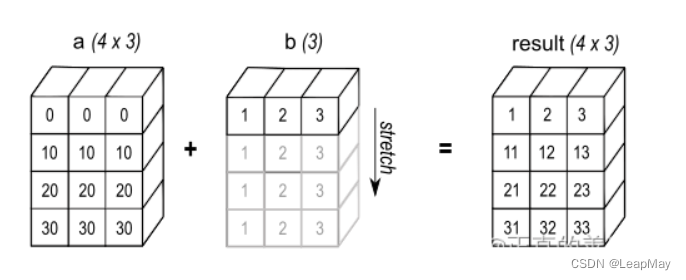
示例:
- 广播规则和示例
import numpy as np# 广播示例1:将标量与数组相乘
scalar = 2
array = np.array([1, 2, 3])
result = scalar * array
print("广播示例1结果:", result) # 输出:[2 4 6]# 广播示例2:将一维数组与二维数组相加
a = np.array([1, 2, 3])
b = np.array([[10, 20, 30], [40, 50, 60]])
result = a + b
print("广播示例2结果:\n", result)
# 输出:
# [[11 22 33]
# [41 52 63]]# 广播示例3:形状不兼容的情况
a = np.array([1, 2, 3])
b = np.array([10, 20])
try:result = a + b
except ValueError as e:print("广播示例3结果(异常):", e)
# 输出:广播示例3结果(异常):operands could not be broadcast together with shapes (3,) (2,)
2 文件输入和输出
读取文本文件:
np.loadtxt():用于从文本文件中读取数据并返回一个NumPy数组。np.genfromtxt():用于从文本文件中读取数据,并根据需要自动处理缺失值和数据类型。
写入文本文件:
np.savetxt():用于将NumPy数组写入文本文件。
读取和写入二进制文件:
np.save():将NumPy数组以二进制格式保存到磁盘文件中。np.load():从磁盘文件中加载保存的NumPy数组。
示例:
import numpy as np# 读取文本文件
data = np.loadtxt('data.txt') # 从文本文件中读取数据# 写入文本文件
np.savetxt('output.txt', data, delimiter=',') # 将数据写入文本文件,使用逗号作为分隔符# 读取和写入二进制文件
arr = np.array([1, 2, 3])
np.save('array_data.npy', arr) # 保存数组到二进制文件
loaded_arr = np.load('array_data.npy') # 从二进制文件中加载数组
3 随机数生成
生成随机数:
np.random.rand():生成均匀分布的随机数数组。np.random.randn():生成标准正态分布(平均值为0,标准差为1)的随机数数组。np.random.randint():生成指定范围内的随机整数。
随机种子:
np.random.seed():用于设置随机数生成器的种子,以确保生成的随机数可重复。
示例:
import numpy as np# 生成随机数
random_numbers = np.random.rand(3, 3) # 生成3x3的均匀分布的随机数数组
standard_normal = np.random.randn(2, 2) # 生成2x2的标准正态分布的随机数数组
random_integers = np.random.randint(1, 10, size=(2, 3)) # 生成2x3的随机整数数组,范围在1到10之间# 设置随机种子以可重复生成相同的随机数
np.random.seed(42)
random_a = np.random.rand(3)
np.random.seed(42) # 使用相同的种子
random_b = np.random.rand(3)
当你使用相同的随机种子值(在上述示例中是42)时,
np.random模块将生成相同的随机数序列。这对于研究、实验和调试非常有用,因为它确保了随机性的可复制性。例如:
import numpy as npnp.random.seed(42)
random_a = np.random.rand(3)# 使用相同的种子值生成相同的随机数序列
np.random.seed(42)
random_b = np.random.rand(3)# random_a 和 random_b 应该是相同的
print(random_a)
print(random_b)
这将产生相同的随机数序列,使得
random_a和random_b的值相等。请注意,如果你在不同地方使用相同的种子值,你将在这些地方生成相同的随机数序列。但是,如果你更改种子值,将生成不同的随机数序列。
随机数生成和随机种子在模拟、机器学习实验以及需要可重复性的应用中非常重要。使用随机种子可以确保你的实验结果是可复制的,而不受随机性的影响。
4 线性代数操作
线性代数在科学计算中起着关键作用,NumPy提供了许多用于处理矩阵和向量的线性代数操作。
- 矩阵乘法:
np.dot()、@运算符- 逆矩阵和伪逆矩阵:
np.linalg.inv()、np.linalg.pinv()- 特征值和特征向量:
np.linalg.eig()- 奇异值分解(SVD):
np.linalg.svd()
矩阵乘法:可以使用 np.dot() 函数或 @ 运算符进行矩阵乘法。
示例:
import numpy as npA = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])result = np.dot(A, B) # 或者使用 result = A @ B
逆矩阵和伪逆矩阵:可以使用 np.linalg.inv() 计算逆矩阵,以及 np.linalg.pinv() 计算伪逆矩阵(当矩阵不可逆时使用伪逆矩阵)。
示例:
import numpy as npA = np.array([[1, 2], [3, 4]])
inverse_A = np.linalg.inv(A)
pseudo_inverse_A = np.linalg.pinv(A)
特征值和特征向量:可以使用 np.linalg.eig() 计算矩阵的特征值和特征向量。
示例:
import numpy as npA = np.array([[1, 2], [2, 3]])
eigenvalues, eigenvectors = np.linalg.eig(A)
奇异值分解(SVD):可以使用 np.linalg.svd() 进行奇异值分解,将矩阵分解为三个矩阵的乘积。
示例:
import numpy as npA = np.array([[1, 2], [3, 4], [5, 6]])
U, S, VT = np.linalg.svd(A)
5 进阶操作
5.1 索引和切片技巧:
NumPy允许使用布尔掩码、整数数组索引等高级索引技巧来访问和修改数组的元素。
基本切片(Basic Slicing):
- 基本切片通过指定开始索引、结束索引和步长来提取数组的子数组。
- 示例:
arr[2:5]提取索引2到4的元素,arr[1:5:2]使用步长提取元素。布尔掩码(Boolean Masking):
- 布尔掩码允许你根据某些条件来选择数组中的元素,条件通常是布尔表达式。
- 示例:
arr[arr > 2]选择大于2的元素。整数数组索引(Integer Array Indexing):
- 使用整数数组作为索引,可以选择或重排数组中的元素。
- 示例:
arr[indices]使用整数数组indices选择指定索引的元素。多维数组切片:
- 对多维数组进行切片时,可以分别指定不同维度的切片条件。
- 示例:
arr2[1:3, 0:2]选择第2和第3行的前2列。
代码示例:
import numpy as np# 基本切片示例
arr = np.array([0, 1, 2, 3, 4, 5])
sub_array1 = arr[2:5] # 提取子数组,结果为 [2, 3, 4]
sub_array2 = arr[1:5:2] # 使用步长,结果为 [1, 3]# 布尔掩码示例
mask = arr > 2
result = arr[mask] # 选择大于2的元素,结果为 [3, 4, 5]# 整数数组索引示例
indices = np.array([0, 2, 4])
result2 = arr[indices] # 使用整数数组索引,结果为 [0, 2, 4]# 多维数组切片示例
arr2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
sub_array3 = arr2[1:3, 0:2] # 选择第2和第3行的前2列
# 结果为
# [[4, 5],
# [7, 8]]# 输出结果
print("基本切片示例1:", sub_array1)
print("基本切片示例2:", sub_array2)
print("布尔掩码示例:", result)
print("整数数组索引示例:", result2)
print("多维数组切片示例:\n", sub_array3)
5.2 数组排序
NumPy提供了 np.sort() 和 np.argsort() 用于对数组进行排序和返回排序后的索引。
示例:
import numpy as nparr = np.array([3, 1, 2, 4, 5])
sorted_arr = np.sort(arr) # 对数组进行排序
sorted_indices = np.argsort(arr) # 返回排序后的索引
示例1:按值排序
import numpy as nparr = np.array([3, 1, 2, 4, 5])
sorted_arr = np.sort(arr) # 按值升序排序,结果为[1, 2, 3, 4, 5]
示例2:按索引排序
import numpy as nparr = np.array([3, 1, 2, 4, 5])
indices = np.argsort(arr) # 获取按值排序后的索引,结果为[1, 2, 0, 3, 4]
sorted_arr = arr[indices] # 按索引排序,结果为[1, 2, 3, 4, 5]
5.3 结构化数组:
结构化数组允许存储和操作不同数据类型的数据,类似于数据库的表格。
示例:
import numpy as npdata = np.array([(1, 'Alice', 25), (2, 'Bob', 30)],dtype=[('ID', 'i4'), ('Name', 'U10'), ('Age', 'i4')])# 访问结构化数组的元素
print(data['Name']) # 输出['Alice', 'Bob']
6 数据分析示例
我们将加载一个包含学生考试成绩的CSV文件,计算平均分、分数分布和绘制直方图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 加载CSV文件数据
data = pd.read_csv('student_scores.csv')# 提取分数列作为NumPy数组
scores = data['Score'].values# 计算统计信息
mean_score = np.mean(scores)
median_score = np.median(scores)
std_deviation = np.std(scores)# 绘制直方图
plt.hist(scores, bins=10, edgecolor='k', alpha=0.7)
plt.title('Score Distribution')
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.show()# 打印统计信息
print(f"Mean Score: {mean_score}")
print(f"Median Score: {median_score}")
print(f"Standard Deviation: {std_deviation}")
在这个示例中,我们首先使用Pandas库加载CSV文件,然后提取其中的分数列并将其转换为NumPy数组。接下来,我们使用NumPy计算平均分、中位数和标准差。最后,我们使用Matplotlib库绘制了分数的直方图。
这个示例展示了如何使用NumPy与其他库一起进行更复杂的数据分析任务,包括数据加载、计算统计信息和可视化数据。
相关文章:
【100天精通Python】Day53:Python 数据分析_NumPy数据操作和分析进阶
目录 1. 广播 2 文件输入和输出 3 随机数生成 4 线性代数操作 5 进阶操作 6 数据分析示例 1. 广播 广播是NumPy中的一种机制,用于在不同形状的数组之间执行元素级操作,使它们具有兼容的形状。广播允许你在不显式复制数据的情况下,对不同…...

druid连接不上doris有哪些可能原因
如果你在使用Druid连接池连接Doris时遇到问题,无法连接上数据库,可能有以下几个原因和解决方案: 网络配置问题:确保你的应用程序能够与Doris数据库所在的服务器进行通信。检查防火墙设置、网络配置以及Doris数据库的监听端口是否…...

双边滤波 Bilateral Filtering
本文是对图像去噪领域经典的双边滤波法的一个简要介绍与总结,论文链接如下: https://users.soe.ucsc.edu/~manduchi/Papers/ICCV98.pdf 1.前言引入 对一副原始灰度图像,我们将它建模为一张二维矩阵u,每个元素称为一个像素pixel&am…...
PXE批量装机
目录 前言 一、交互式 (一)、搭建环境 (二)、配置dhcp服务 (三)、FTP服务 (四)、配置TFTP服务 (五)、准备pxelinx.0文件、引导文件、内核文件 &#…...
Linux--VMware的安装和Centos
一、VMware和Linux的关系 二、VMware的安装 VM_ware桌面虚拟机 最新中文版 软件下载 (weizhen66.cn) VMware-Workstation-Lite-16.2.2-19200509-精简安装注册版.7z - 蓝奏云 如果安装不成功,则设置BIOS 三、在VMware中加入Centos 下载地址: CentOS-…...
dji uav建图导航系列()ROS中创建dji_sdk节点包(一)项目结构
文章目录 1、整体项目结构1.1、 目录launch1.2、文件CMakeLists.txt1.3、文件package.xml1.4、目录include1.4、目录srv在ROS框架下创建一个无人机的节点dji_sdk,实现必需的订阅(控制指令)、发布(无人机里程计)、服务(无人机起飞降落、控制权得很)功能,就能实现一个类似…...
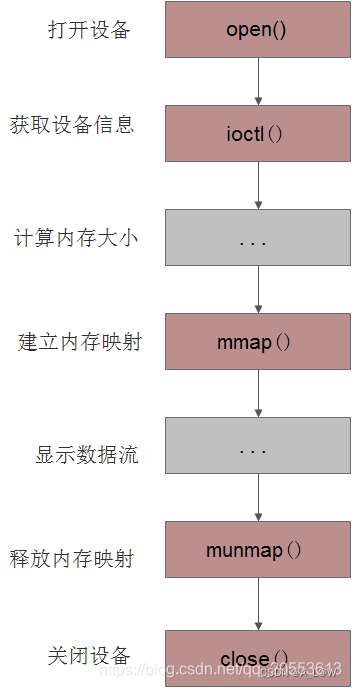
基于x86_64 ubuntu22.04的framebuffer编程
文章目录 前言一、framebuffer简介二、framebuffer接口1.framebuffer设备描述信息2.framebuffer访问接口3.查询/设置可更改信息 三、使用步骤 前言 前段时间由于笔记本没有保管好,LCD显示屏压碎了。于是,将笔记本电脑拆开查看LCD型号。在淘宝上下单买了…...

解密回文--栈
“ xyzyx ”是一个回文字符串,所谓回文字符 串就是指正读反读均相同的字符序列,如“席主席”、“记书记”、“ aha ”和“ ahaha ”均是回 文,但“ ahah ”不是回文。通过栈这个数据结构我们将很容易判断一个字符串是否为回文。 首先我们需…...

Mysql主从服务安装配置
1.下载地址 MySQL :: Download MySQL Community Server (Archived Versions)https://downloads.mysql.com/archives/community/ 2.安装配置 1.下载解压后,拷贝一份作为slave的安装目录 3.配置my.ini 由于下载mysql8版本,解压后,没有相关的my…...

双向BFS
1034 Number Game 分数 35 作者 陈越 单位 浙江大学 A number game is to start from a given number A, and to reach the destination number B by a sequence of operations. For the current number X, there are 3 types of operations: XX1 XX−1 XXN Your job is to f…...
数据艺术:精通数据可视化的关键步骤
数据可视化是将复杂数据转化为易于理解的图表和图形的过程,帮助我们发现趋势、关联和模式。同时数据可视化也是数字孪生的基础,本文小编带大家用最简单的话语为大家讲解怎么制作一个数据可视化大屏,接下来跟随小编的思路走起来~ 1.数据收集和…...

MySQL 是如何实现事务的四大特性的?
分析&回答 如果你不知道事务更不知道四大特性请先看看:说说什么是事务 原子性 语句要么都执行,要么都不执行,是事务最核心的特性,事务本身来说就是以原子性来定义的,实现主要是基于undo log undo logÿ…...
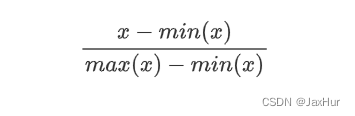
python实现zscore归一化和minmax标准化
zscore归一化: minmax from sklearn import preprocessing from sklearn.preprocessing import StandardScaler import numpy as np# 数据 x np.array([[1.,-1.,2.],[2.,0.,0.],[0.,1.,-1.]]) print(----------------minmaxscaler标准化-------------) # 调用minma…...

架构师成长之路Redis第三篇|Redis key过期清除策略
Eviction policies maxmemory 100mb 当我们设置的内存达到指定的内存量时,清除策略的配置方式决定了默认行为。Redis可以为可能导致使用更多内存的命令返回错误,也可以在每次添加新数据时清除一些旧数据以返回到指定的限制。 当达到最大内存限制时,Redis所遵循的确切行为是…...
C++智能指针之weak_ptr(保姆级教学)
目录 C智能指针之weak_ptr 概述 作用 本文涉及的所有程序 使用说明 weak_ptr的常规操作 lock(); use_count(); expired(); reset(); shared_ptr & weak_ptr 尺寸 智能指针结构框架 常见使用问题 shared_ptr多次引用同一数据,会导致两次释放同一内…...
ElementUI浅尝辄止18:Avatar 头像
用图标、图片或者字符的形式展示用户或事物信息。 常用于管理系统或web网站的用户头像,在用户账户模块更换头像操作也能看到关于Avatar组件的应用。 1.如何使用? 通过 shape 和 size 设置头像的形状和大小。 <template><el-row class"de…...
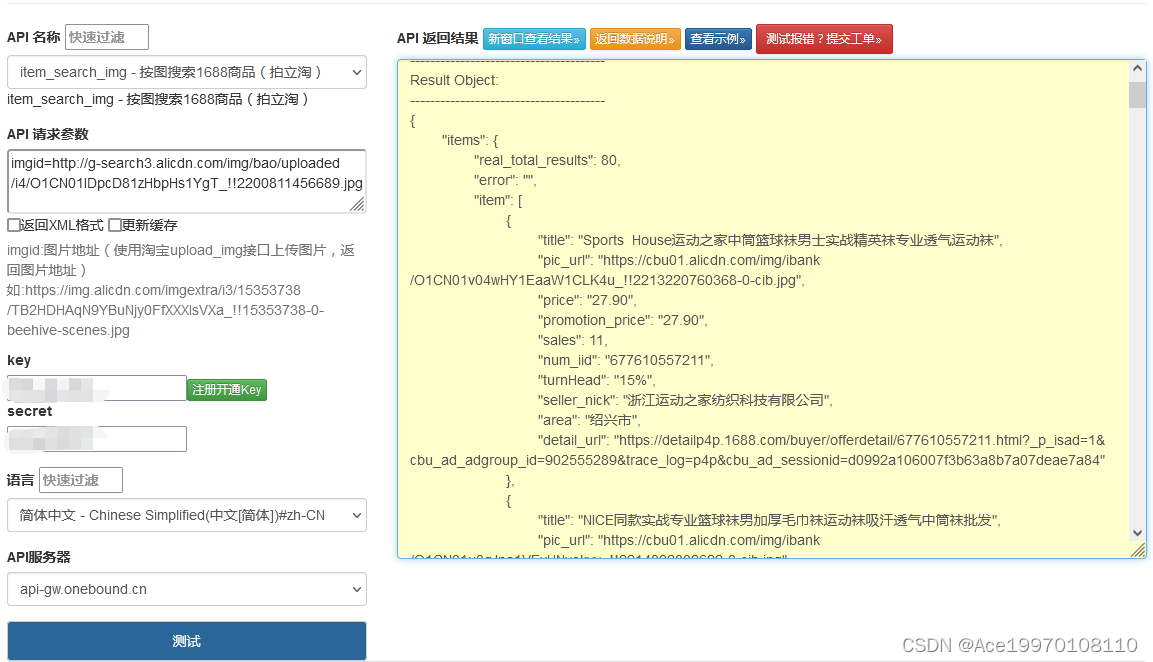
1688API技术解析,实现按图搜索1688商品(拍立淘)
一种可能的解决方案是使用图像识别和相似度匹配的算法。您可以通过将输入的图片与1688上的商品图片进行比对,找出最相似的商品。这涉及到图像特征提取、相似度计算以及数据库匹配等技术。您可以使用开源的图像处理库(如OpenCV)来进行图像处理…...

【面试经典150题】买卖股票的最佳时机
题目链接 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易中获取的…...
selenium可以编写自动化测试脚本吗?
Selenium可以用于编写自动化测试脚本,它提供了许多工具和API,可以与浏览器交互,模拟用户操作,检查网页的各个方面。下面是一些步骤,可以帮助你编写Selenium自动化测试脚本。 1、安装Selenium库和浏览器驱动程序 首先…...

CXL.mem M2S Message 释义
🔥点击查看精选 CXL 系列文章🔥 🔥点击进入【芯片设计验证】社区,查看更多精彩内容🔥 📢 声明: 🥭 作者主页:【MangoPapa的CSDN主页】。⚠️ 本文首发于CSDN,…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...

boost::filesystem::path文件路径使用详解和示例
boost::filesystem::path 是 Boost 库中用于跨平台操作文件路径的类,封装了路径的拼接、分割、提取、判断等常用功能。下面是对它的使用详解,包括常用接口与完整示例。 1. 引入头文件与命名空间 #include <boost/filesystem.hpp> namespace fs b…...