ELK日志收集系统(四十九)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
一、概述
二、组件
1. elasticsearch
2. logstash
2.1 工作过程
2.2 INPUT
2.3 FILETER
2.4 OUTPUTS
3. kibana
三、架构类型
3.1 ELK
3.2 ELKK
3.3 ELFK
3.5 EFK
四、案例
前言
ELK日志收集系统是一种常用的开源系统,由三个主要组件组成:Elasticsearch、Logstash和Kibana。
-
Elasticsearch是一个基于Lucene的分布式搜索和分析引擎,用于存储和索引大量数据。它能够快速地搜索和分析大规模的日志数据,并支持实时的数据查询和聚合分析。
-
Logstash是一个用于数据收集、处理和传输的工具。它能够从各种来源(如文件、数据库、消息队列等)收集日志数据,并对其进行过滤、转换和标准化处理,然后将数据发送给Elasticsearch进行存储和索引。
-
Kibana是一个用于数据可视化和分析的工具。它提供了用户友好的界面,可以通过图表、表格、仪表盘等方式展示和分析存储在Elasticsearch中的日志数据。用户可以使用Kibana进行数据查询、聚合、筛选和导出,并可以自定义仪表盘和报告。
ELK日志收集系统能够帮助企业集中收集、存储和分析各种类型的日志数据,提供实时的监控、诊断和故障排查能力,帮助提高系统的稳定性和性能。它还支持可扩展性和高可用性,并提供了丰富的插件和扩展机制,可以与其他工具和系统集成。
提示:以下是本篇文章正文内容,下面案例可供参考
一、概述
ELK由三个组件构成
作用
日志收集
日志分析
日志可视化
为什么使用?
日志对于分析系统、应用的状态十分重要,但一般日志的量会比较大,并且比较分散。
如果管理的服务器或者程序比较少的情况我们还可以逐一登录到各个服务器去查看、分析。但如果服务器或者程序的数量比较多了之后这种方法就显得力不从心。基于此,一些集中式的日志系统也就应用而生。目前比较有名成熟的有,Splunk(商业)、FaceBook 的Scribe、Apache的Chukwa Cloudera的Fluentd、还有ELK等等。
二、组件
1. elasticsearch
日志分析
开源的日志收集、分析、存储程序
特点
分布式
零配置
自动发现
索引自动分片
索引副本机制
Restful风格接口
多数据源
自动搜索负载
2. logstash
日志收集
搜集、分析、过滤日志的工具
2.1 工作过程
一般工作方式为c/s架构,Client端安装在需要收集日志的服务器上,Server端负责将收到的各节点日志进行过滤、修改等操作,再一并发往Elasticsearch上去
Inputs → Filters → Outputs
输入-->过滤-->输出
2.2 INPUT
File:从文件系统的文件中读取,类似于tail -f命令
Syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
(要使用 Logstash 从 Syslog 中读取数据,您可以按照以下步骤进行配置:
1. 创建 Logstash 配置文件:使用任意文本编辑器创建一个新的配置文件(例如 `syslog.conf`)。
2. 配置 Syslog 输入插件:在配置文件中添加以下内容,以配置 Logstash 从 Syslog 中读取数据:
```yaml
input {
syslog {
port => 514 # Syslog 默认的监听端口号为 514,请根据实际情况进行修改
type => "syslog"
}
}
```
这将配置 Logstash 使用 Syslog 输入插件监听默认的 Syslog 端口号(514),并使用 "syslog" 类型标记这些事件。
3. 可选的过滤器和输出配置:根据您的需求,您可以添加额外的过滤器或输出插件来处理从 Syslog 读取的数据。根据您的具体需求进行相应的配置。
4. 启动 Logstash:导航到 Logstash 的安装目录,并运行以下命令以启动 Logstash 并加载 Syslog 配置:
```bash
bin/logstash -f path/to/syslog.conf
```
请确保将 `path/to/syslog.conf` 替换为实际的配置文件路径。
启动 Logstash 后,它将监听来自 Syslog 的数据并进行处理。请确保 Logstash 能够接收 Syslog 数据,并且防火墙或网络配置允许 Logstash 与 Syslog 进行通信。如果您使用的是默认端口 514,请确保没有其他服务占用该端口。如有需要,可以修改 Logstash 配置文件中的端口设置来与 Syslog 配置一致。)
Redis:从redis service中读取(要使用Logstash从Redis中读取数据,您可以按照以下步骤设置Logstash配置:
1. 安装Logstash和Redis插件:首先,确保已在系统上安装了Logstash,并在Logstash的安装目录 下运行以下命令安装Redis插件:
```
bin/logstash-plugin install logstash-input-redis
```
2. 创建Logstash配置文件:创建一个新的配置文件(例如`redis.conf`),并使用任意文本编辑器打开。
3. 配置Redis输入插件:在配置文件中添加以下内容,以配置Logstash从Redis中读取数据:
```
input {
redis {
host => "localhost" # Redis主机地址,根据您的配置进行更改
port => 6379 # Redis端口,根据您的配置进行更改
data_type => "list" # Redis数据类型,例如list、channel、pattern等
key => "your_key" # Redis数据键名,根据您的配置进行更改
}
}
```
注意,这只是一个基本的配置示例,请根据您的Redis主机地址、端口、数据类型和键名进行相应的更改。
4. 配置Logstash输出:根据您的需求,您可以添加其他输出插件(如Elasticsearch、文件输出)
Beats:从filebeat中读取(要使 Logstash 从其他主机的 Filebeat 读取数据,您需要进行以下配置:
1. 在 Filebeat 上配置 Logstash 输出:编辑 Filebeat 的配置文件(通常是 `filebeat.yml`)并添加 Logstash 输出的配置。确保将 `output.logstash.hosts` 设置为 Logstash 主机的 IP 地址或主机名,如下所示:
```yaml
output.logstash:
hosts: ["logstash_host:5044"]
```
将 `logstash_host` 替换为实际的 Logstash 主机地址。确保配置中的端口号 `5044` 与 Logstash 监听的端口一致。
2. 在 Logstash 上配置 Filebeat 输入:创建一个新的 Logstash 配置文件(例如 `filebeat.conf`),并使用文本编辑器打开。在配置文件中添加以下内容:
```yaml
input {
beats {
port => 5044 # 设置 Logstash 监听的端口与 Filebeat 配置中一致
}
}
```
这将指示 Logstash 监听 Filebeat 发送的数据。
3. 可选的过滤器和输出配置:根据您的需求,您可以添加额外的过滤器或输出插件来处理从 Filebeat 读取的数据。根据您的具体需求进行相应的配置。
4. 启动 Logstash:导航到 Logstash 的安装目录并运行以下命令以启动 Logstash 并加载 Filebeat 配置:
```bash
bin/logstash -f path/to/filebeat.conf
```
请确保将 `path/to/filebeat.conf` 替换为实际的配置文件路径。
启动 Logstash 后,它将监听来自其他主机上 Filebeat 的数据,并根据配置进行处理。请确保 Logstash 能够访问其他主机上的 Filebeat,并且防火墙或网络配置允许 Logstash 与 Filebeat 进行通信)
2.3 FILETER
Grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
官方提供的grok表达式:logstash-patterns-core/patterns at main · logstash-plugins/logstash-patterns-core · GitHub
Grok在线调试:Grok Debugger
Mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
Drop:丢弃一部分Events不进行处理。
Clone:拷贝Event,这个过程中也可以添加或移除字段。
Geoip:添加地理信息(为前台kibana图形化展示使用)
2.4 OUTPUTS
Elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
File:将Event数据保存到文件中。
Graphite:将Event数据发送到图形化组件中,踏实一个当前较流行的开源存储图形化展示的组件。
3. kibana
日志可视化
Grafana
为Logstash和ElasticSearch在收集、存储的日志基础上进行分析时友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
三、架构类型
3.1 ELK
es
logstash
kibana
3.2 ELKK
es
logstash
kafka
kibana
3.3 ELFK
es
logstash 重量级
占用系统资源较多
filebeat 轻量级
占用系统资源较少
kibana
3.4 ELFKK
es
logstash
filebeat
kafka
kibana
3.5 EFK
es
logstash
fluentd
kafka
kibana
四、案例
ELK日志收集系统集群实验
1.实验拓扑

2. 环境配置
设置各个主机的IP地址为拓扑中的静态IP,在两个节点中修改主机名为node1和node2并设置hosts文件
node1:
hostnamectl set-hostname node1
vim /etc/hosts
192.168.156.11 node1
192.168.156.12 node2

node2:
hostnamectl set-hostname node2
vim /etc/hosts
192.168.156.11 node1
192.168.156.12 node2
3. 安装node1与node2节点的elasticsearch
安装
rpm -ivh elasticsearch-5.5.0.rpm

配置
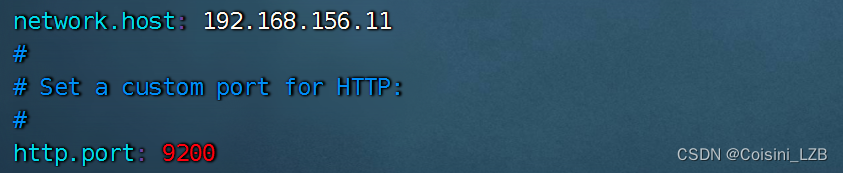
node1:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node1 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:192.168.56.11 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
![]()

![]()
![]()
![]()
node2:
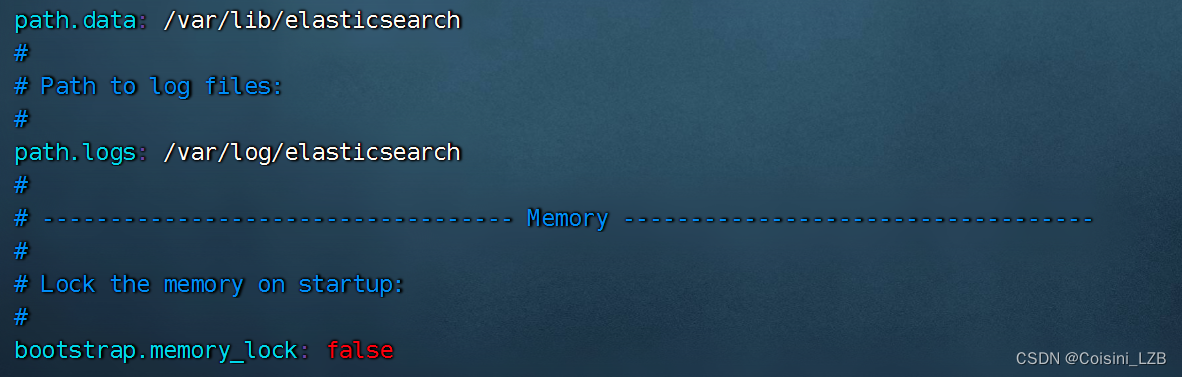
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node2 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:192.168.156.12 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
![]()
![]()
![]()

启动elasticsearch服务
node1和node2
systemctl start elasticsearch
![]()
![]()
查看节点信息
http://192.168.156.11:9200
http://192.168.156.12:9200


查看集群健康状态:
http://192.168.115.3:9200/_cluster/health
Green 健康 yellow 警告 red 集群不可用,严重错误

4. 在node1安装elasticsearch-head插件
tar xf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make && make install
![]()
![]()
![]()
等待安装完毕。
安装完毕后会生成命令:npm
拷贝命令
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin

![]()
![]()
![]()
安装elasticsearch-head
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head
npm install
![]()

修改elasticsearch配置文件
vim /etc/elasticsearch/elasticsearch.yml
添加 http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin: "*" //跨域访问允许的域名地址
![]()

启动elasticsearch-head
cd elasticsearch-head
npm run start &
![]()

查看监听: netstat -anput | grep :9100

访问:
http://192.168.156.11:9100
测试
在node1的终端中输入:
curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
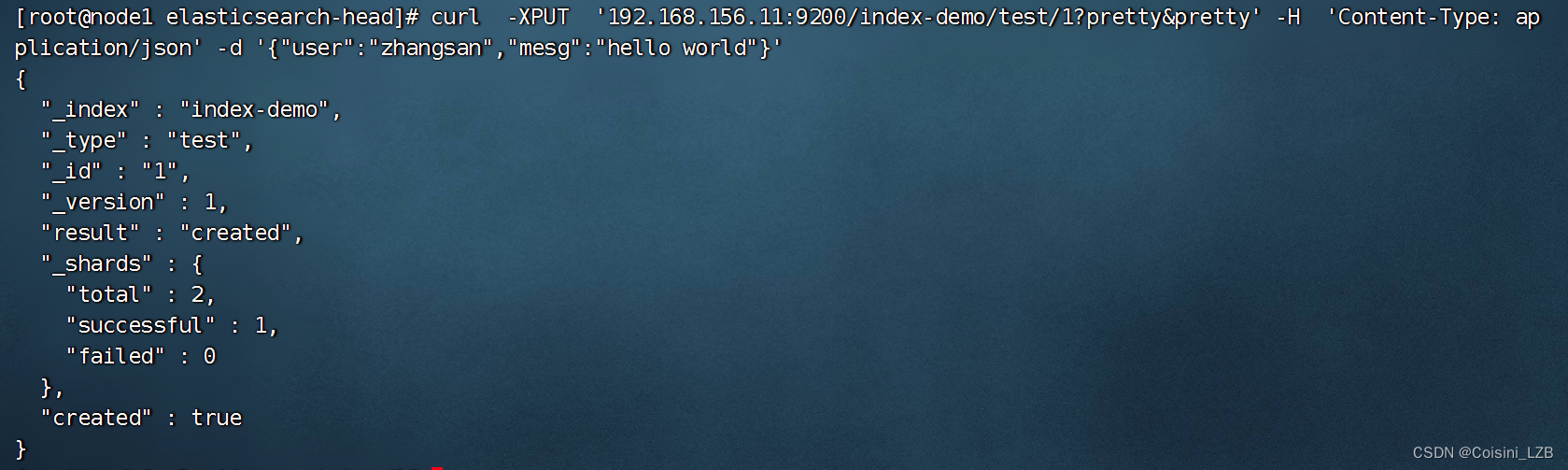
刷新浏览器可以看到对应信息即可


node1服务器安装logstash
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service

In -s /usr/share/logstash/bin/logstash /usr/local/bin/
![]()
测试1: 标准输入与输出
logstash -e 'input{ stdin{} }output { stdout{} }'

测试2: 使用rubydebug解码
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'

测试3:输出到elasticsearch
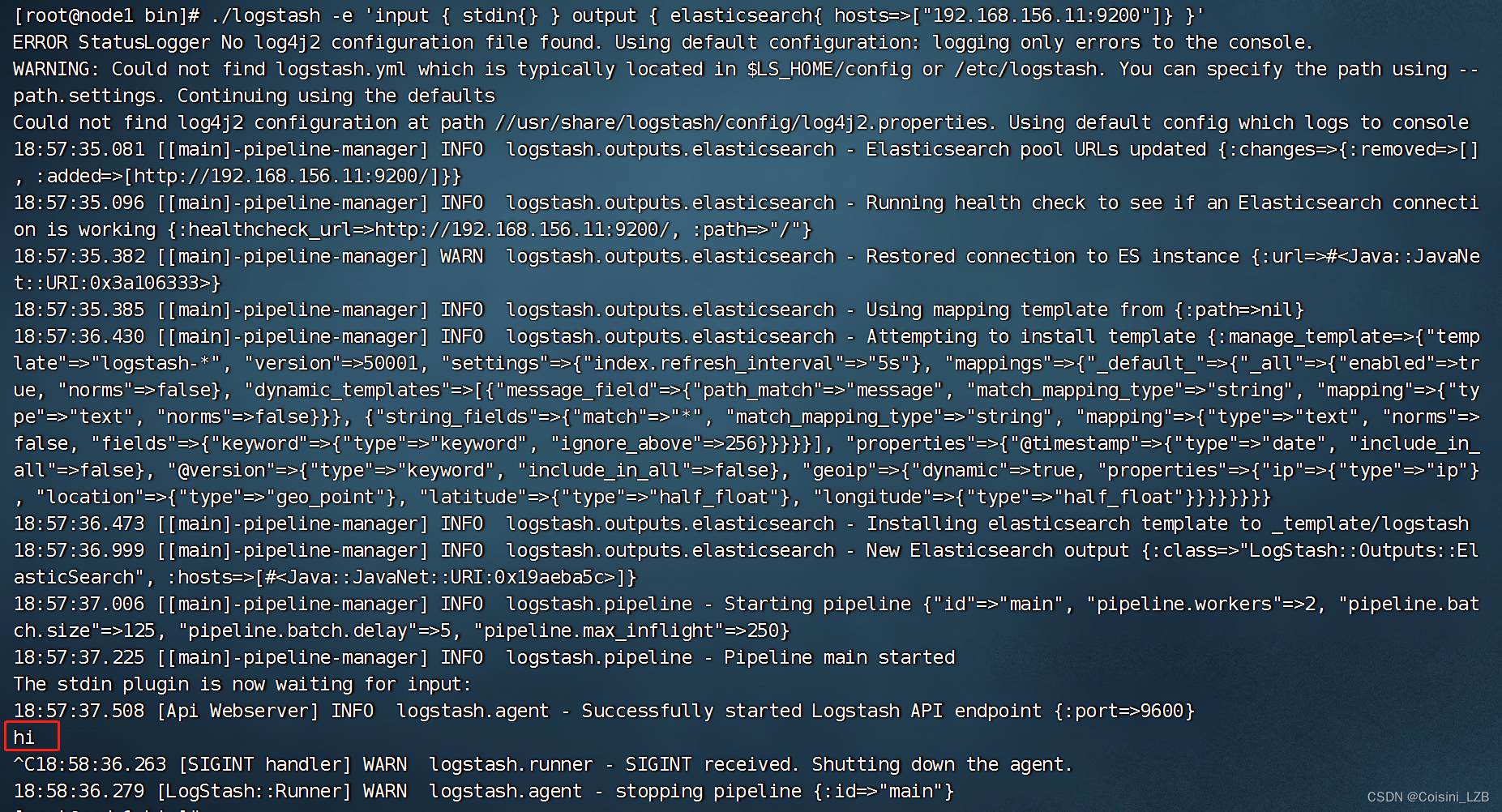
查看结果:
http://192.168.156.11:9100

logstash日志收集文件格式
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
案例:通过logstash收集系统信息日志
chmod o+r /var/log/messages
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.1.1:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}


重启日志服务: systemctl restart logstash
![]()
查看日志: http://192.168.156.11:9100

node1节点安装kibana
rpm -ivh kibana-5.5.1-x86_64.rpm

配置kibana
vim /etc/kibana/kibana.yml
server.port:5601 //Kibana打开的端口
server.host:"0.0.0.0" //Kibana侦听的地址
elasticsearch.url: "http://192.168.8.134:9200"
//和Elasticsearch 建立连接
kibana.index:".kibana" //在Elasticsearch中添加.kibana索引

![]()
启动kibana
systemctl start kibana
![]()

访问kibana :
http://192.168.156.11:5601

首次访问需要添加索引,我们添加前面已经添加过的索引:system-*

企业案例:
收集httpd访问日志信息
在httpd服务器上安装logstash,参数上述安装过程,可以不进行测试
logstash在httpd服务器上作为agent(代理),不需要启动

![]()

编写httpd日志收集配置文件
vim /etc/logstash/conf.d/httpd.conf
input {
file{
path=>"/var/log/httpd/access_log" //收集Apache访问日志
type => "access" //类型指定为 access
start_position => "beginning" //从开始处收集
}
output{
elasticsearch {
hosts =>["192.168.156.11:9200"] // elasticsearch 监听地址及端口
index =>"httpd_access-%{+YYYY.MM.dd}" //指定索引格式
}
}
![]()

使用logstash命令导入配置:
logstash -f /etc/logstash/conf.d/httpd.conf

使用kibana查看即可! http://192.168.156.11:5601 查看时在mangement选项卡创建索引httpd_access-* 即可!

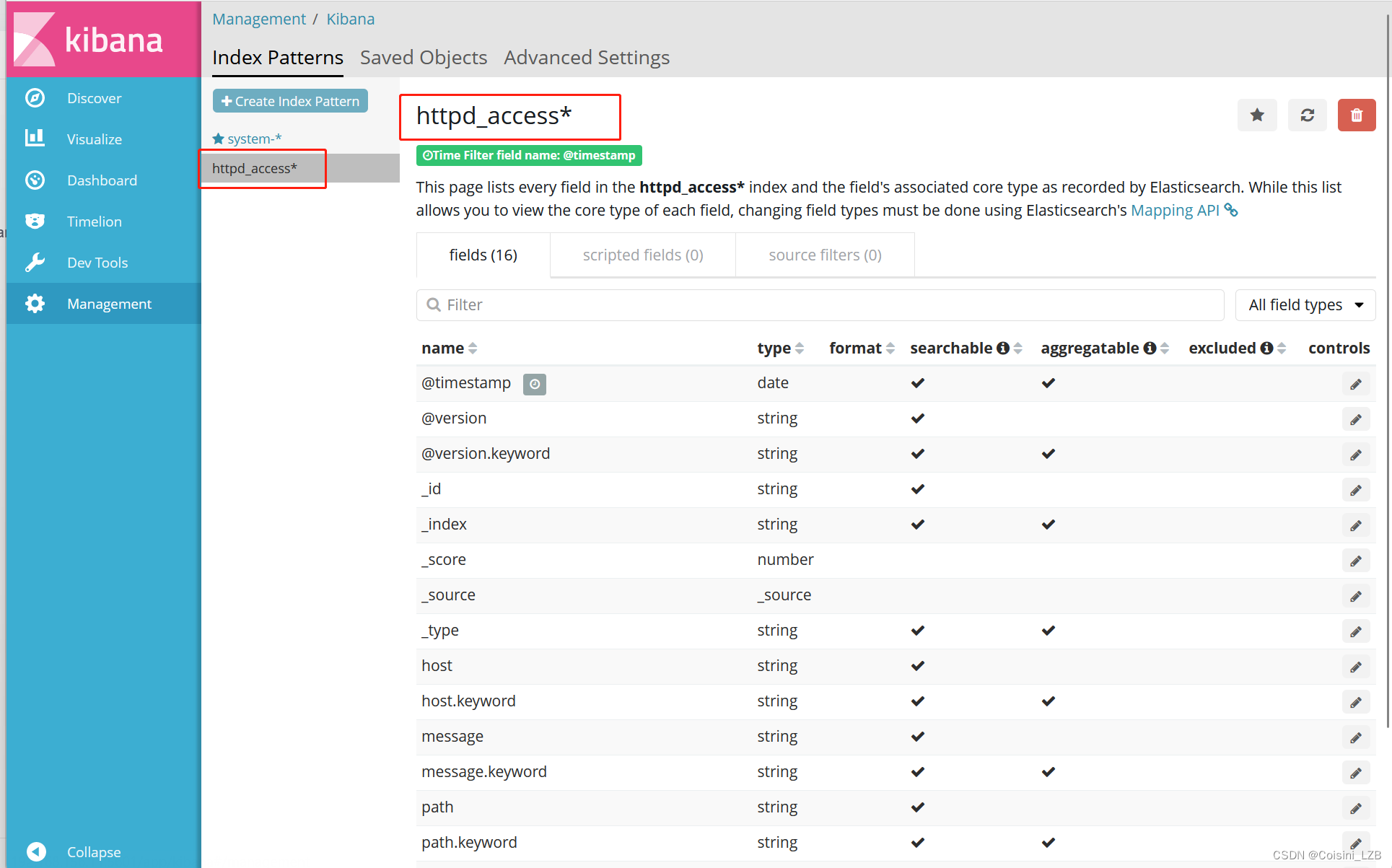
相关文章:
ELK日志收集系统(四十九)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 二、组件 1. elasticsearch 2. logstash 2.1 工作过程 2.2 INPUT 2.3 FILETER 2.4 OUTPUTS 3. kibana 三、架构类型 3.1 ELK 3.2 ELKK 3.3 ELFK 3.5 EF…...
Linux知识点 -- Linux多线程(四)
Linux知识点 – Linux多线程(四) 文章目录 Linux知识点 -- Linux多线程(四)一、线程池1.概念2.实现3.单例模式的线程池 二、STL、智能指针和线程安全1.STL的容器是否是线程安全的2.智能指针是否是线程安全的 三、其他常见的各种锁…...
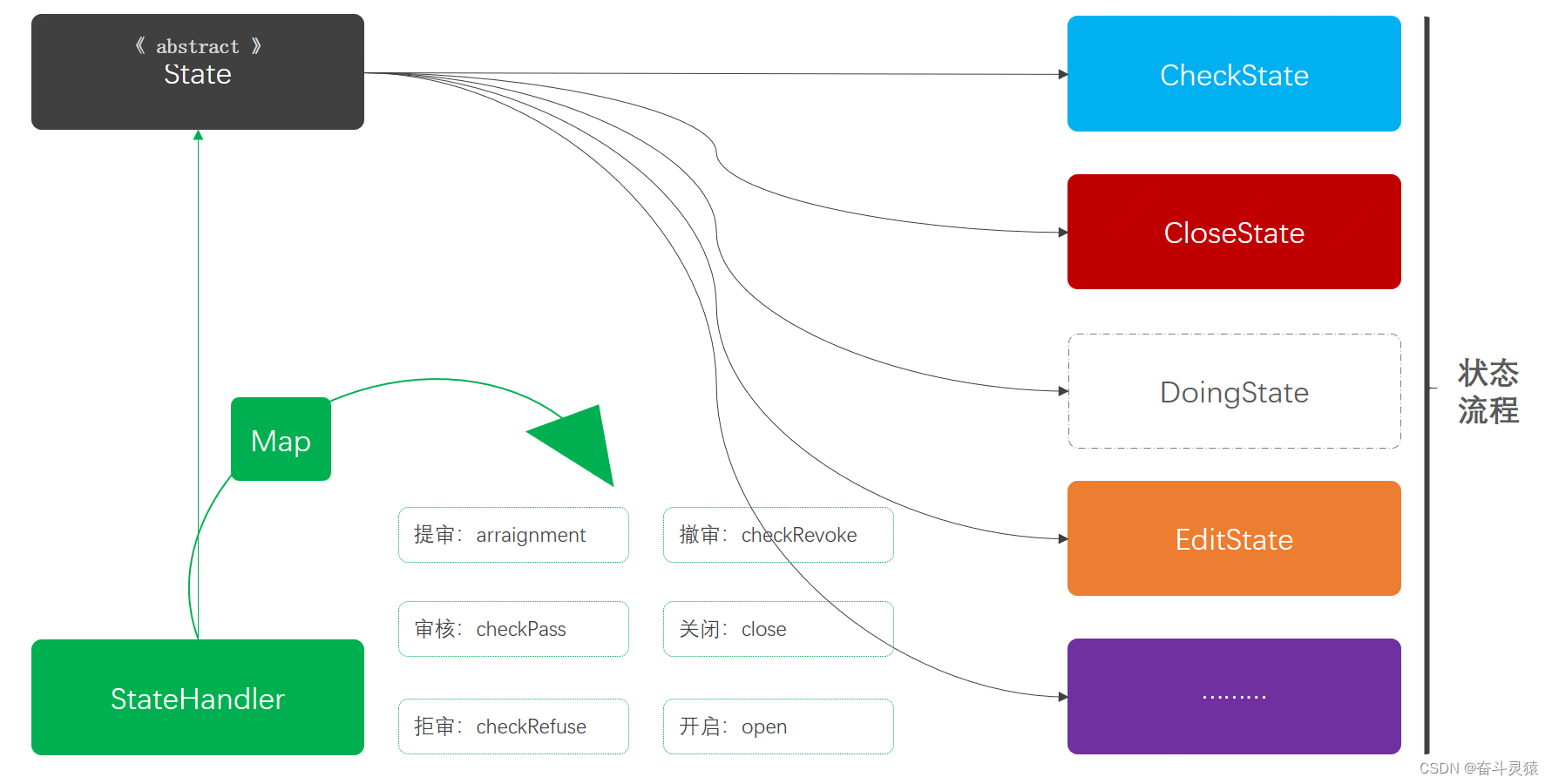
Java设计模式:四、行为型模式-07:状态模式
文章目录 一、定义:状态模式二、模拟场景:状态模式2.1 状态模式2.2 引入依赖2.3 工程结构2.4 模拟审核状态流转2.4.1 活动状态枚举2.4.2 活动信息类2.4.3 活动服务接口2.4.4 返回结果类 三、违背方案:状态模式3.0 引入依赖3.1 工程结构3.2 活…...

很多应用都是nginx+apache+tomcat
nginx 负责负载均衡,将大量的访问量平衡分配给多个服务器 apache 是用来处理静态html、图片等资源,在对HTML解析、响应等方面比tomcat效率更高。 tomcat 处理JSP等内容,进行后台业务操作。 upstream bbb.com.cn{ server 192.168.10.1:80 ;…...

原型模式:复制对象的技巧
欢迎来到设计模式系列的第六篇文章!在前面的几篇文章中,我们已经学习了一些常见的设计模式,今天我们将继续探讨另一个重要的设计模式——原型模式。 原型模式简介 原型模式是一种创建型设计模式,它主要用于复制对象。原型模式通…...
ClickHouse进阶(五):副本与分片-1-副本与分片
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…...

Android 华为手机荣耀8X调用系统裁剪工具不能裁剪方形图片,裁剪后程序就奔溃,裁剪后获取不到bitmap的问题
买了个华为荣耀8X,安装自己写的App后,调用系统裁剪工具发现裁剪是圆形的,解决办法: //专门针对华为手机解决华为手机裁剪图片是圆形图片的问题 if (Build.MANUFACTURER.equals("HUAWEI")) {intent.putExtra("aspectX", 9998);intent.putExtra("a…...
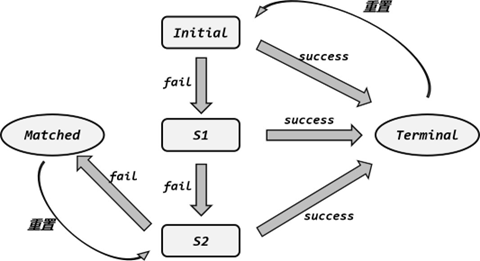
《Flink学习笔记》——第十二章 Flink CEP
12.1 基本概念 12.1.1 CEP是什么 1.什么是CEP? 答:所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(…...

谷歌IndexedDB客户端存储数据
IndexedDB 具有以下主要特点: 1.存储大量数据:IndexedDB 可以存储大量的数据,比如存储离线应用程序的本地缓存或存储在线应用程序的大量数据。 2.结构化数据:IndexedDB 使用对象存储空间(Object Stores)来…...

天气数据的宝库:解锁天气预报API的无限可能性
前言 天气预报一直是我们日常生活中的重要组成部分。我们依赖天气预报来决定穿什么衣服、何时出行、规划户外活动以及做出关于农业、交通和能源管理等方面的重要决策。然而,要提供准确的天气预报,需要庞大的数据集和复杂的计算模型。这就是天气预报API的…...
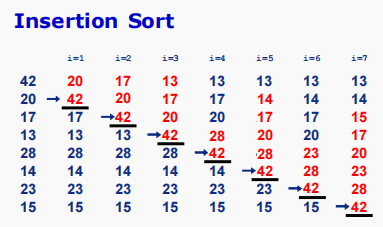
插入排序(Insertion Sort)
C自学精简教程 目录(必读) 插入排序 每次选择未排序子数组中的第一个元素,从后往前,插入放到已排序子数组中,保持子数组有序。 打扑克牌,起牌。 输入数据 42 20 17 13 28 14 23 15 执行过程 完整代码 #include <iostream…...
2023蓝帽杯初赛
最近打完蓝帽杯 现在进行复盘 re 签到题 直接查看源代码 输出的内容就是 变量s 变量 number 而这都是已经设定好了的 所以flag就出来了 WhatisYourStory34982733 取证 案件介绍 取证案情介绍: 2021年5月,公安机关侦破了一起投资理财诈骗类案件&a…...
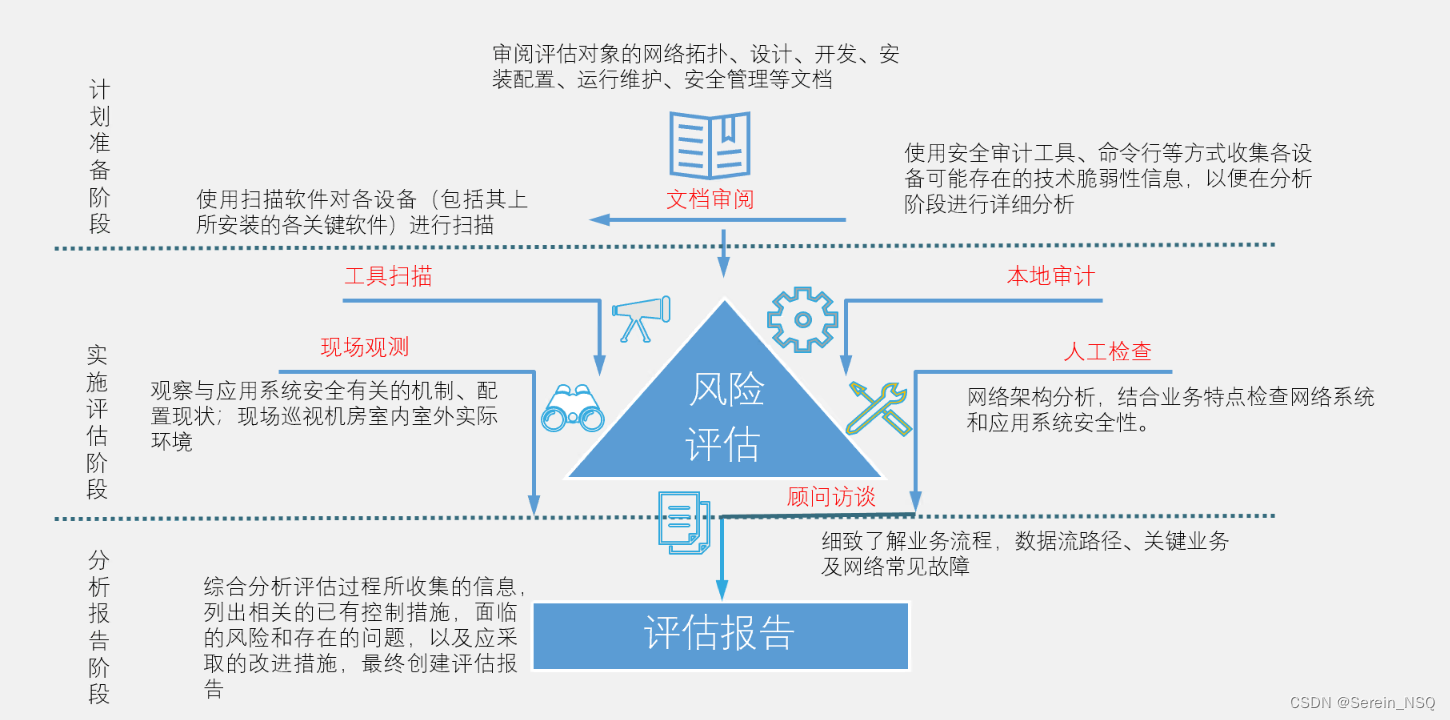
风险评估
风险评估概念 风险评估是一种系统性的方法,用于识别、评估和量化潜在的风险和威胁,以便组织或个人能够采取适当的措施来管理和减轻这些风险。 风险评估的目的 风险评估要素关系 技术评估和管理评估 风险评估分析原理 风险评估服务 风险评估实施流程...

直播软件app开发中的AI应用及前景展望
在当今数字化时代,直播市场蓬勃发展,而直播软件App成为人们获取实时信息和娱乐的重要渠道。随着人工智能(AI)技术的迅猛发展,直播软件App开发正逐渐融入AI的应用,为用户带来更智能、更个性化的直播体验。 …...

vscode html使用less和快速获取标签less结构
扩展插件里面搜索 css tree 插件 下载 使用方法 选择你要生成的标签结构然后按CTRLshiftp 第一次需要在输入框输入 get 然后选择 Generate CSS tree less结构就出现在这个里面直接复制到自己的less文件里面就可以使用了 在html里面使用less 下载 Easy LESS 插件 自己创建…...
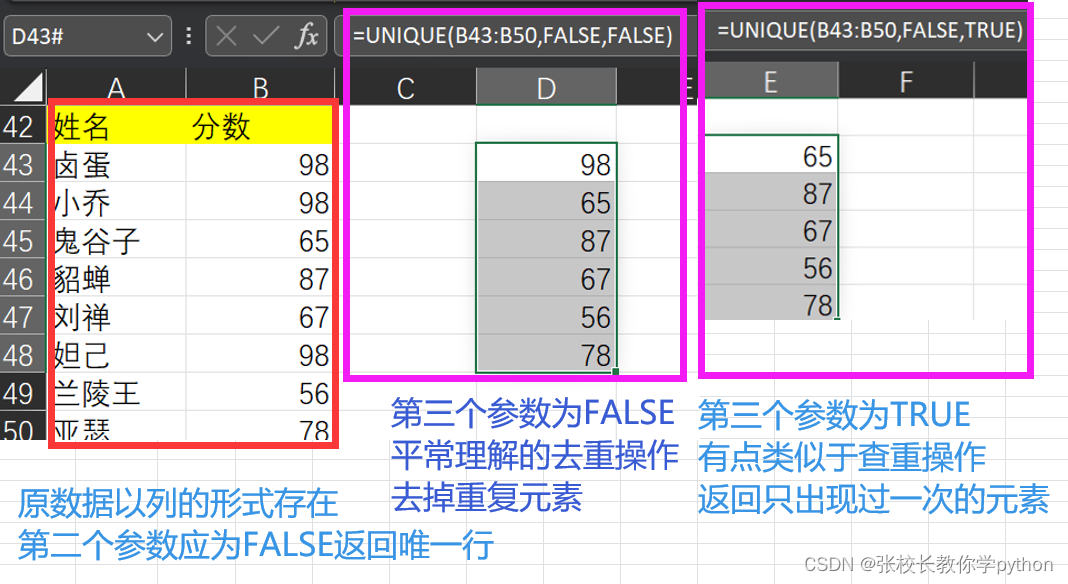
excel中的引用与查找函数篇1
1、COLUMN(reference):返回与列号对应的数字 2、ROW(reference):返回与行号对应的数字 参数reference表示引用/参考单元格,输入后引用单元格后colimn()和row()会返回这个单元格对应的列号和行号。若参数reference没有引用单元格,…...
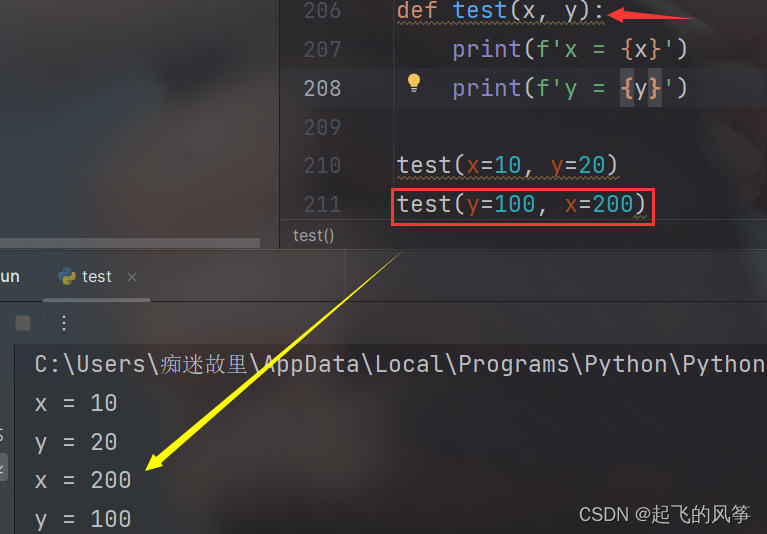
【python】—— 函数详解
前言: 本期,我们将要讲解的是有关python中函数的相关知识!!! 目录 (一)函数是什么 (二)语法格式 (三)函数参数 (四)函…...
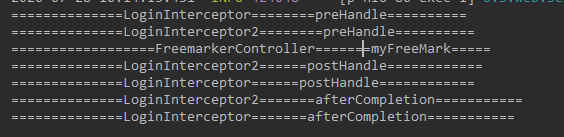
springboot web开发登录拦截器
在SpringBoot中我们可以使用HandlerInterceptorAdapter这个适配器来实现自己的拦截器。这样就可以拦截所有的请求并做相应的处理。 应用场景 日志记录,可以记录请求信息的日志,以便进行信息监控、信息统计等。权限检查:如登陆检测ÿ…...
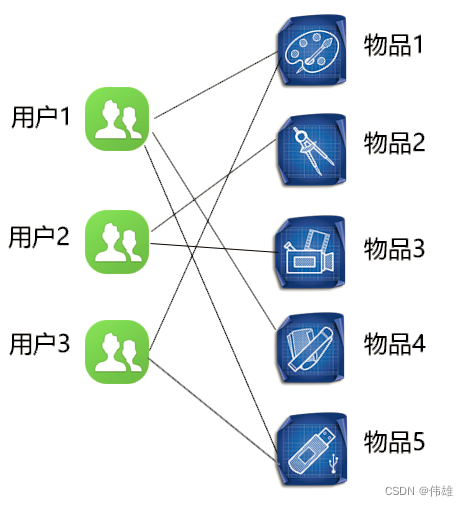
大数据课程K17——Spark的协同过滤法
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Spark的协同过滤概念; 一、协同过滤概念 1. 概念 协同过滤是一种借助众包智慧的途径。它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。其内在思想是相似度的定义…...

【力扣】1588. 所有奇数长度子数组的和 <前缀和>
【力扣】1588. 所有奇数长度子数组的和 给你一个正整数数组 arr ,请你计算所有可能的奇数长度子数组的和。子数组 定义为原数组中的一个连续子序列。请你返回 arr 中 所有奇数长度子数组的和 。 示例 1: 输入:arr [1,4,2,5,3] 输出&#x…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...