因果推断(六)基于微软框架dowhy的因果推断
因果推断(六)基于微软框架dowhy的因果推断
DoWhy 基于因果推断的两大框架构建:「图模型」与「潜在结果模型」。具体来说,其使用基于图的准则与 do-积分来对假设进行建模并识别出非参数化的因果效应;而在估计阶段则主要基于潜在结果框架中的方法进行估计。DoWhy 的整个因果推断过程可以划分为四大步骤:
- 「建模」(model):利用假设(先验知识)对因果推断问题建模
- 「识别」(identify):在假设(模型)下识别因果效应的表达式(因果估计量)
- 「估计」(estimate):使用统计方法对表达式进行估计
- 「反驳」(refute):使用各种鲁棒性检查来验证估计的正确性
同样的,不过多涉及原理阐述,具体的可以参考因果推断框架 DoWhy 入门。
准备数据
# !pip install dowhy
import pandas as pd
from dowhy import CausalModel
from IPython.display import Image, display
import warnings
warnings.filterwarnings('ignore') # 设置warning禁止
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【因果推断06】自动获取~
raw_data = pd.read_csv('BankChurners.csv')
raw_data.head()

特征工程
# 计算高额信贷:信贷额度超过20000
raw_data['High_limit'] = raw_data['Credit_Limit'].apply(lambda x: True if x > 20000 else False)
# 定义流失用户
raw_data['Churn'] = raw_data['Attrition_Flag'].apply(lambda x: True if x == 'Attrited Customer' else False)
# 剔除
- 目标变量(Y):Churn
- 干预变量(V/treatment):High_limit
- 混淆变量(W):其他变量
这里通过随机试验进行简单的因果关系判断:
# 随机试验简单判断因果关系
def simple_cause(df, y, treatment, n_sample):counts_sum=0for i in range(1,10000):counts_i = 0rdf = df.sample(n_sample)counts_i = rdf[rdf[y] == rdf[treatment]].shape[0]counts_sum+= counts_ireturn counts_sum/10000simple_cause(raw_data, 'Churn', 'High_limit', 1000)
750.6551 \displaystyle 750.6551 750.6551
- 对X~Y进行随机试验,随机取1000个观测,统计y=treatment的次数,如果越接近于500,则越无法确定因果关系,越接近0/1则估计存在因果
- 对上述实验随机进行了10000次,得到y=treatment的次数均值为750。因此假设存在一定的因果关系
因果推断建模
定义问题
y = 'Churn'
treatment = 'High_limit'
W = raw_data.drop([y, treatment, 'Credit_Limit', 'Attrition_Flag'], axis=1).columns.to_list()
问题定义为:额度限制是影响客户流失的原因,因为低限制类别的人可能不那么忠诚于银行
因果图建模
# 定义训练集:y+treatment+W
train = raw_data[[y, treatment]+W].copy()
# 定义因果图的先验假设
causal_graph = """
digraph {
High_limit;
Churn;
Income_Category;
Education_Level;
U[label="Unobserved Confounders"];
Education_Level->High_limit; Income_Category->High_limit;
U->Churn;
High_limit->Churn; Income_Category -> Churn;
}
"""
# 因果图绘制
model= CausalModel(data = train,graph=causal_graph.replace("\n", " "),treatment=treatment,outcome=y)
model.view_model()
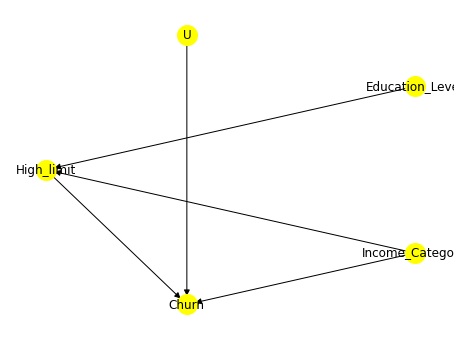
先验假设:额度高限制影响流失;收入类别影响额度限制从而影响流失;教育程度影响额度限制;其他混淆因素影响流失
识别
# 识别因果效应的估计量
ie = model.identify_effect()
print(ie)
Estimand type: nonparametric-ate### Estimand : 1
Estimand name: backdoor
Estimand expression:d
────────────(Expectation(Churn|Income_Category))
d[Highₗᵢₘᵢₜ]
Estimand assumption 1, Unconfoundedness: If U→{High_limit} and U→Churn then P(Churn|High_limit,Income_Category,U) = P(Churn|High_limit,Income_Category)### Estimand : 2
Estimand name: iv
Estimand expression:
Expectation(Derivative(Churn, [Education_Level])*Derivative([High_limit], [Edu
cation_Level])**(-1))
Estimand assumption 1, As-if-random: If U→→Churn then ¬(U →→{Education_Level})
Estimand assumption 2, Exclusion: If we remove {Education_Level}→{High_limit}, then ¬({Education_Level}→Churn)### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
- 我们称干预Treatment导致了结果Outcome,当且仅当在其他所有状况不变的情况下,干预的改变引起了结果的改变
- 因果效应即干预发生一个单位的改变时,结果变化的程度。通过因果图的属性来识别因果效应的估计量
- 根据先验假设,模型支持backdoor、和iv准则下的两者因果关系。具体的因果表达式见打印结果
估计因果效应
# 根据倾向得分的逆概率加权估计
estimate = model.estimate_effect(ie,method_name="backdoor.propensity_score_weighting")
print(estimate)
propensity_score_weighting
*** Causal Estimate ***## Identified estimand
Estimand type: nonparametric-ate### Estimand : 1
Estimand name: backdoor
Estimand expression:d
────────────(Expectation(Churn|Income_Category))
d[Highₗᵢₘᵢₜ]
Estimand assumption 1, Unconfoundedness: If U→{High_limit} and U→Churn then P(Churn|High_limit,Income_Category,U) = P(Churn|High_limit,Income_Category)## Realized estimand
b: Churn~High_limit+Income_Category
Target units: ate## Estimate
Mean value: -0.028495525240213704
估计平均值为-0.03,表明具有高额度限制的客户流失率降低了3%
反驳结果
# 随机共同因子检验:用随机选择的子集替换给定的数据集,如果假设是正确的,则估计值不应有太大变化。
refutel = model.refute_estimate(ie, estimate, "random_common_cause")
print(refutel)
Refute: Add a random common cause
Estimated effect:-0.028495525240213704
New effect:-0.02852304490516341
p value:0.96
# 数据子集:用随机选择的子集替换给定的数据集,如果假设是正确的,则估计值不应有太大变化。
refutel = model.refute_estimate(ie, estimate, "data_subset_refuter")
print(refutel)
Refute: Use a subset of data
Estimated effect:-0.028495525240213704
New effect:-0.027690470580490477
p value:0.98
# 安慰剂:用独立的随机变量代替真实的干预变量,如果假设是正确的,则估计值应接近零
refutel = model.refute_estimate(ie, estimate, "placebo_treatment_refuter")
print(refutel)
Refute: Use a Placebo Treatment
Estimated effect:-0.028495525240213704
New effect:0.0006977458004958939
p value:0.98
基于上述的反驳,即稳健检验。表明High_limit与Churn具有因果关系
总结
和上期一样,这里的分享也权当一种冷门数据分析方法的科普,如果想深入了解的同学可自行查找资源进行充电。因果推断算的上一门高深的专业知识了,我本人也只是了解了些皮毛,如果在后续工作中有较深层次的理解后,再进行补充分享吧。也欢迎该领域的大佬慷慨分享~
共勉~
相关文章:
因果推断(六)基于微软框架dowhy的因果推断
因果推断(六)基于微软框架dowhy的因果推断 DoWhy 基于因果推断的两大框架构建:「图模型」与「潜在结果模型」。具体来说,其使用基于图的准则与 do-积分来对假设进行建模并识别出非参数化的因果效应;而在估计阶段则主要…...

探索隧道ip如何助力爬虫应用
在数据驱动的世界中,网络爬虫已成为获取大量信息的重要工具。然而,爬虫在抓取数据时可能会遇到一些挑战,如IP封禁、访问限制等。隧道ip(TunnelingProxy)作为一种强大的解决方案,可以帮助爬虫应用更高效地获…...

题目:2629.复合函数
题目来源: leetcode题目,网址:2629. 复合函数 - 力扣(LeetCode) 解题思路: 倒序遍历计算。 解题代码: /*** param {Function[]} functions* return {Function}*/ var compose function(…...

【实训项目】精点考研
1.设计摘要 如果说高考是一次能够改变命运的考试,那么考研应该是另外一次。为什么那么多人都要考研呢?从中国教育在线官方公布是考研动机调查来看,大家扎堆考研的原因大概集中在这6个方面:本科就业压力大,提升竞争力、…...

软件测试Pytest实现接口自动化应该如何在用例执行后打印日志到日志目录生成日志文件?
Pytest可以使用内置的logging模块来实现接口自动化测试用例执行后打印日志到日志目录以生成日志文件。以下是实现步骤: 1、在pytest配置文件(conftest.py)中,定义一个日志输出路径,并设置logging模块。 import loggi…...

深入理解作用域、作用域链和闭包
🎬 岸边的风:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 📚 前言 📘 1. 词法作用域 📖 1.2 示例 📖 1.3 词法作用域的…...

7款适合3D建模和渲染的GPU推荐
选择一款完美的 GPU 并不是一件容易的事;您不仅必须确保有特定数量的线程和内核来处理图像,而且还应该有足够的 RAM。 这是因为 3D 渲染是一个活跃的工作过程,因为您必须坐在 PC 前并持续与软件交互。为了在 3D 场景中积极工作,您…...

边缘计算物联网网关在机械加工行业的应用及作用分享
随着工业4.0的推进,物联网技术正在逐渐渗透到各个行业领域。机械加工行业作为制造业的基础领域之一,其生产过程的自动化、智能化水平直接影响到产品质量和生产效率。边缘计算物联网网关作为物联网技术的重要组成部分,在机械加工行业中发挥着越…...
(笔记六)利用opencv进行图像滤波
(1)自定义卷积核图像滤波 import numpy as np import matplotlib.pyplot as plt import cv2 as cvimg_path r"D:\data\test6-6.png" img cv.imread(img_path)# 图像滤波 ker np.ones((6, 6), np.float32)/36 # 构建滤波器(卷积…...
WPF C# .NET7 基础学习
学习视频地址:https://www.bilibili.com/video/BV1hx4y1G7C6?p3&vd_source986db470823ebc16fe0b3d235addf050 开发工具:Visual Studio 2022 Community 基础框架:.Net 6.0 下载创建过程略 .Net和.Framework 区别是Net是依赖项ÿ…...

QT里使用sqlite的问题,好多坑
1. 我使用sqlite,开发机上好好的,测试机上却不行。后来发现是缺少驱动(Driver not loaded Driver not loaded),代码检查了又检查,发现应该是缺少dll文件(系统不提示,是自己使用 QMes…...

openGauss学习笔记-59 openGauss 数据库管理-相关概念介绍
文章目录 openGauss学习笔记-59 openGauss 数据库管理-相关概念介绍59.1 数据库59.2 表空间59.3 模式59.4 用户和角色59.5 事务管理 openGauss学习笔记-59 openGauss 数据库管理-相关概念介绍 59.1 数据库 数据库用于管理各类数据对象,与其他数据库隔离。创建数据…...

Nginx安装与部署
文章目录 一,说明二,下载三,Windows下安装1,安装2,启动3,验证 四,Linux下安装1,安装2,启动3,验证 五,Nginx配置 一,说明 Nginx是一款高性能Web和反向代理服务器,提供内存少,高并发,负载均衡和反向代理服务,支持windos和linux系统 二,下载 打开浏览器,输入地址: https://ngin…...
Linux中Tomcat发布war包后无法正常访问非静态资源
事故现象 在CentOS8中安装完WEB环境,首次部署WEB项目DEMO案例,发现可以静态的网页内容, 但是无法向后台发送异步请求,全部出现404问题,导致数据库数据无法渲染到界面上。 原因分析 CentOS请求中提示用来获取资源的连…...

大数据、AI和云原生:引领未来软件开发的技术演进
文章目录 **1. 数据驱动的创新:****2. 智能化应用的兴起:****3. 云原生的敏捷和可扩展性:****4. 实时性和即时性:****5. 数据隐私和安全:****6. 跨平台和跨设备:****7. 自动化和智能编程:****8.…...
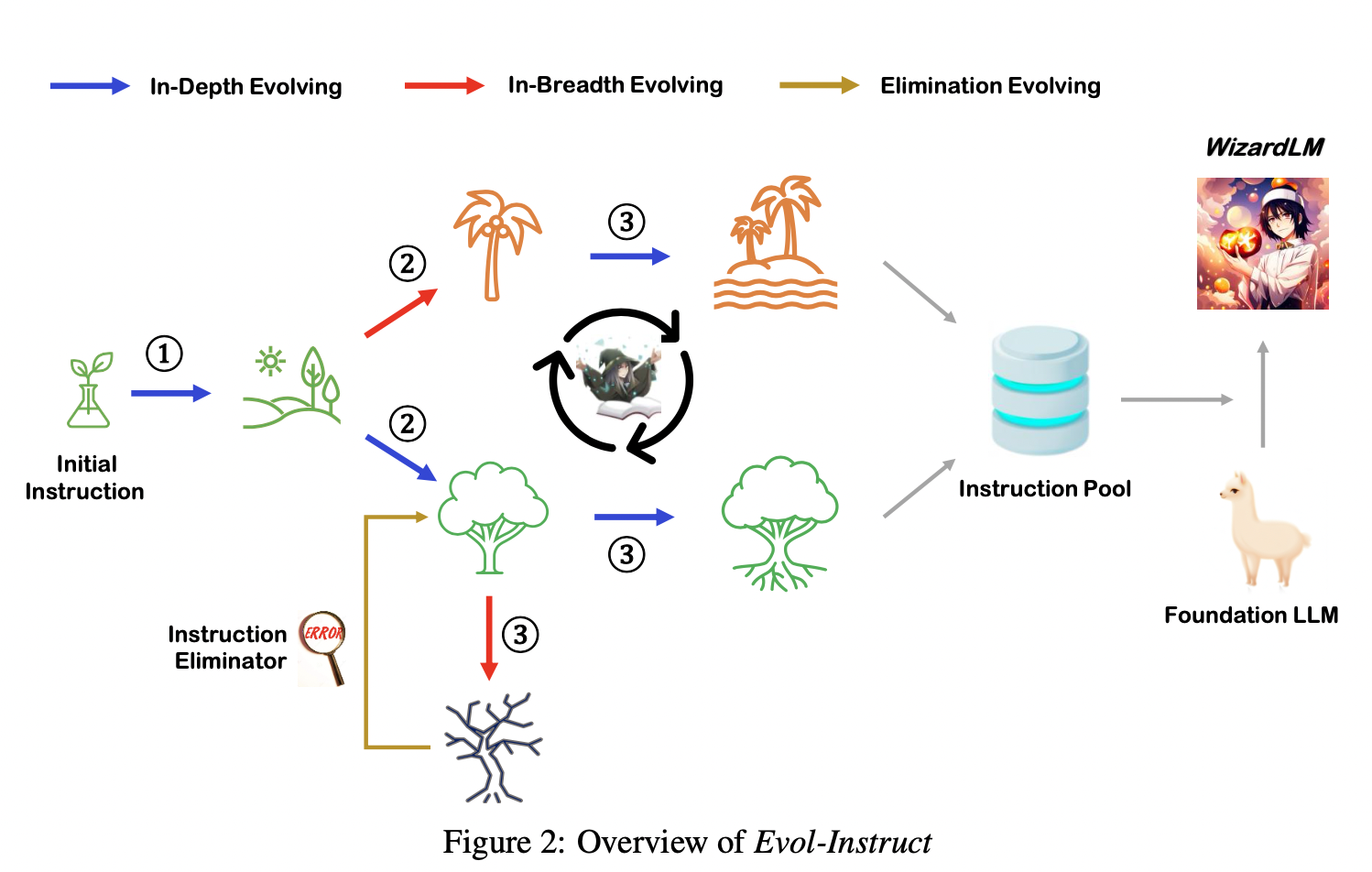
Text-to-SQL小白入门(四)指令进化大模型WizardLM
摘要 本文主要对大模型WizardLM的基本信息进行了简单介绍,展示了WizardLM取得的优秀性能,分析了论文的核心——指令进化方法。 论文概述 基本信息 英文标题:WizardLM: Empowering Large Language Models to Follow Complex Instructions中…...
浅谈红队资产信息收集经验
文章目录 子公司资产收集备案号|官网收集子域名|ip收集fofa灯塔ARLX情报社区 资产确认目录扫描Google Hacking绕过CDNnmap端口扫描参数技巧其他常用工具 子公司资产收集 红蓝对抗中往往只会给你目标企业的名称,以及对应的靶标系统地址,而很少有直接从靶标…...

list根据对象中某个字段属性去重Java流实现
list根据对象中某个字段属性去重Java流实现? 在Java的流(Stream)中,你可以使用distinct方法来实现根据对象中某个字段属性去重的功能。要实现这个功能,你需要重写对象的hashCode和equals方法,以确保相同字段属性的对象被认为是相…...

软件架构设计(三) B/S架构风格-层次架构(一)
层次架构风格从之前的两层C/S到三层C/S,然后演化为三层B/S架构,三层B/S架构之后仍然在往后面演化,我们来看一下层次架构演化过程中都有了哪些演化的架构风格呢? 而我们先简单了解一下之前的层次架构风格中分层的各个层次的作用。 表现层:由于用户进行交互,比如MVC,MVP,…...

大端字节和小端字节
介绍 大端字节序(Big-Endian)和小端字节序(Little-Endian)是在计算机系统中用来表示多字节数据类型(如整数、浮点数等)的存储方式。字节序指的是在内存中多字节数据的存放顺序,即哪个字节在前&…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...