Jmete+Grafana+Prometheus+Influxdb+Nginx+Docker架构搭建压测体系/监控体系/实时压测数据展示平台+遇到问题总结
背景
需要大批量压测时,单机发出的压力能力有限,需要多台jmeter来同时进行压测;发压机资源不够,被压测系统没到瓶颈之前,发压机难免先发生资源不足的情形;反复压测时候也需要在不同机器中启动压测脚本,更改脚本变动麻烦,收集压测数据难,启动和关闭压测进程难,分布式压测可以让压测时机的把控更准确,实现自由伸缩,一次配置,随处运行。
本文可实现从0到1搭建体系
可能面对的缺点:
1. 单台并发量不够,发压机资源不足
2. 手动方式在不同发压机上脚本更改麻烦
3. 测试结果难以整理
4. 扩增新节点发压时调试麻烦
5. 压测开始/结束时间点无法统一,手动操作有误差
6.长时间压测时,压测数据积压问题。超过1G的压测结果会出问题,严重影响磁盘IO(可更改采点时间间隔,但不是所有场景都适用如果想看到更细粒度数据就会很吃力)。
7. 压测数据保存。每次压测默认会覆盖上次的结果,虽然可以更改复写机制,但总会有超过阈值大小的时间,如果可能 保存到数据库更好。
8. 压测数据展示,不太美观。每次压测完需要根据jtl文件生成html报告
9. 发压机资源监控,无法知道发压机是否达到资源瓶颈,是否需要添加额外服务器,此举可有效节约服务器资源。
10. 每次执行都需要登录服务器进行操作,是否可集成到Jenkins中,每次运行直接在web端指定IP地址,进行压测?(需详细调研加以尝试)
一台Master,一台Slave,每次扩展只需要对Slave打一个镜像,拷贝几个相应虚拟机,压测时直接指定相应IP地址
搭建阶段
1.集群压测+数据入库
2.发压机指标监控
3.CI/CD集成Jenkins (待定)
Jmeter 分布式集群搭建
一. 分布式压测注意点
1、运行相同版本的JMeter(两台机器版本不一致,需要重新升级)
2、使用相同的java版本
3、都在一个网段
4、server.rmi.ssl.disable开关一致
5、关闭防火墙
6、使用的JMeter插件一致
7、如果压测的是java脚本,需要将java脚本和相关lib包都放在jmeter目录lib/ext下,在每一台机器上都得有脚本文件和依赖的jar包(如果是http脚本,在Master的机器上有脚本文件即可)
8、将jmeter的场景文件jmx上传到Master jmeter的任意位置,参数文件需要放到每一台压力机上(如果脚本中涉及从外部读取的csv文件,那该文件就需要上传到各个slaver施压机上) 9、关闭运行时千万不要通过control+c终止运行,需要再开一个窗口,在主jmeter的bin目录下"./shutdown.sh" 就会向从压力机发布指令,结束运行;
10、若是脚本中设置的并发线程数是100,采用3台slaver机器去施加压力,那么对于服务端来说,此时的并发线程数是300。
二. Jmeter分布式压测原理了解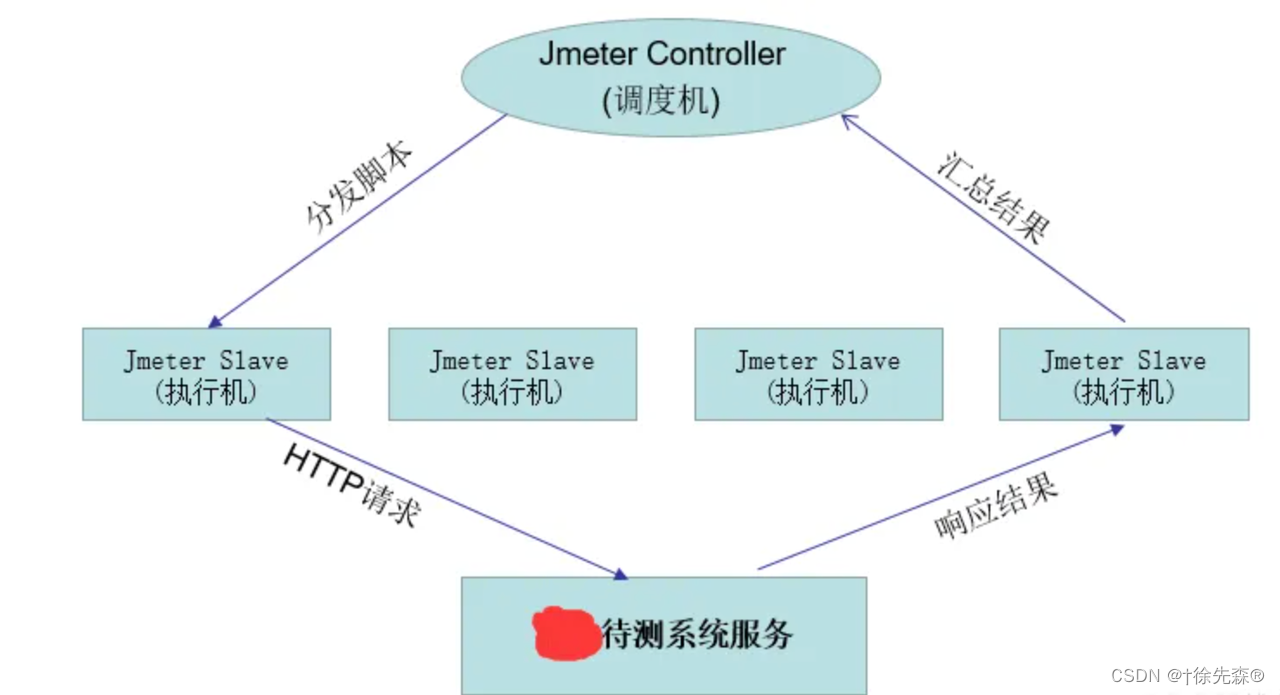
1、分为控制器(controller)和代理(agent),也有人叫master机和slave机(总控机器的节点master,其他产生压力的机器叫“肉鸡” server) 2、master会把压测脚本发送到 server上面
3、执行的时候,server上只需要把jmeter-server打开就可以了,不用启动jmeter 4、结束后,server会把压测数据回传给master,然后master汇总输出报告
controller 作为控制器不加入实际测试,只负责发送和收集 agent 信息。
三.参数优化
1. 控制台 取样 间隔的设置(linux中的日志输出时间间隔)
summariser.interval=10,默认时间为30秒,最低可修改为6秒 (在jmeter的bin目录下 jmeter.properties)2. JVM优化 (按照4c 8g配置)
因为整台服务器就是为性能测试使用,所以jvm堆栈可以调到最大比例,防止压测时发压机OOM异常。修改jmeter的bin目录下,vi jmeter,修改HEAP的size大小如下,也可以设置为6G,建议自测调整JVM大小
"${HEAP:="-Xms4g -Xmx4g -XX:MaxMetaspaceSize=512m"}"3. 修改默认编码
sampleresult.default.encoding=UTF-84. linux中没有实时输出日志
解决不输出实时日志:修改配置文件jmeter.properties中的配置项
找到 #summariser.ignore_transaction_controller_sample_result=true 改为 summariser.ignore_transaction_controller_sample_result=false5. 进入jmeter的bin目录下,修改reportgenerator.properties
修改 jmeter.reportgenerator.overall_granularity=1000 (报表中数据展示间隔1秒钟)6. 打开主从机器交互配置,修改jmeter.properties文件
将server.rmi.ssl.disable=true(去掉注释)【主从之间默认是https的,在局域网内部使用,没有必要使用https方式】7. 指定运行 slave节点,二选一配置
本机通过第二种方式
更改bin/jmeter-server,指定RMI_HOST_DEF=-Djava.rmi.server.hostname=本机内网ip,或者通过运行命令指定本机IP来启动nohup ./jmeter-server -Djava.rmi.server.hostname=192.168.0.107 &
否则会报错如下:
Server failed to start: java.rmi.RemoteException: Cannot start. localhost.localdomain is a loopback address. An error occurred: Cannot start. localhost.localdomain is a loopback address.8.压测执行 顺序
1. slave以server方式执行
执行命令如下(需要确认下新开的slave 是否会执行该命令 加载环境变量 将本机IP刷到Jmeter参数中)
该命令会将slave上的Jmeter以后台方式运行,并且将当前机器ip添加到jmeter-server配置中
localhostPrivateIp=$(/sbin/ifconfig -a eth0 |grep inet|grep -v 127.0.0.1|grep -v inet6 | awk '{print $2}' | tr -d "addr:") && nohup ./jmeter-server -Djava.rmi.server.hostname=$localhostPrivateIp &2.Master压测
运行时需要指定—R 127.0.0.1 128.0.0.1
jmeter -n -t getUserInfoById.jmx -l res.jtl -R 112.16.63.227(slave的内网ip地址英文逗号分隔)如果想要压测执行,请在Master节点中
进入jmeter/bin/目录下
运行 ./shundown.sh 实时数据展示平台搭建
使用Docker+Nginx+Prometheus+Grafana+Influxdb+Node-exporter方式
1.InfluxDb部署和配置
拉取镜像
docker pull influxdb:1.7.10启动容器
(后面的命令是为了让容器和宿主机的时间一致,避免因时间不一致导致的数据不显示问题)docker run -d --name=influxdb -p 8086:8086 -v ${PWD}:/var/lib/influxdb influxdb:1.7.10 /etc/localtime:/etc/localtime进入容器
docker exec -it influxdb bash 输入命令
influx进入influx内部
show databases;
查看influxdb现有数据库使用命令
create database jmeter;
创建名为jmeter的数据库use jmeter;
使用该数据库 show measurements;
查看下面具备哪些表select * from "表名字";
查看表中具有哪些数据
效果展示

2.Grafana部署
Grafana就是一个报表展示平台,相比来说配置和安装更加容易,Grafana版本之间可能会有稍许差别,此处使用版本9.3.2;
拉取镜像
docker pull grafana/grafana:9.3.2运行镜像
(--link 是为了让grafana和influxd网络互通)
docker run -d --name=grafana --link=influxdb:influxdb -p 3000:3000 grafana/grafana:9.3.2效果截图

3.Prometheus部署和配置
注意
首先在tmp目录下新建prometheus和prometheus.yml文件
prometheus+docker方式部署+加载Nginx端口转发配置+允许热加载node-exporter+挂在配置文件到宿主机+prometheus允许后缀名方式访问(和Nignx配置对应)
拉取镜像
docker pull pro/prometheus 运行镜像
docker run -d -p 9090:9090 -v /tmp/prometheus:/etc/prometheus --name=prometheus prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.route-prefix=/ --web.external-url=/prometheus/ --web.enable-lifecycle 安装完prometheus并配置好Nginx和Node-exporter 后可访问IP/prometheus/ ,查看prometheus配置了几个node-exporter

4.Nginx 部署(Yum方式)
yum install -y nginx 安装完nginx , 修改配置文件,在/etc/nginx/nginx.conf
运维给我开通的是外网80端口,所以我就直接用80端口代理Grafana的web页面
完整http块内的配置如下(可能有的配置冗余,但也懒得去排查修改了)
http {log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';access_log /var/log/nginx/access.log main;sendfile on;tcp_nopush on;tcp_nodelay on;keepalive_timeout 65;types_hash_max_size 4096;include /etc/nginx/mime.types;default_type application/octet-stream;# Load modular configuration files from the /etc/nginx/conf.d directory.# See http://nginx.org/en/docs/ngx_core_module.html#include# for more information.include /etc/nginx/conf.d/*.conf;server {listen 80;listen [::]:80;server_name _;root /usr/share/nginx/html;location /prometheus/{proxy_pass http://127.0.0.1:9090/;proxy_set_header X-Real-IP $remote_addr;proxy_redirect default;proxy_http_version 1.1;proxy_set_header Upgrade $http_upgrade;proxy_set_header Connection "Upgrade";proxy_set_header Host $http_host;}location /influxdb/ {proxy_pass http://127.0.0.1:8086/;}location ^~ / {index index.html index.htm;proxy_pass http://127.0.0.1:3000/;proxy_set_header X-Real-IP $remote_addr;proxy_redirect default;proxy_http_version 1.1;proxy_set_header Upgrade $http_upgrade;proxy_set_header Connection "Upgrade";proxy_set_header Host $http_host;}# Load configuration files for the default server block.include /etc/nginx/default.d/*.conf;error_page 404 /404.html;location = /404.html {}error_page 500 502 503 504 /50x.html;location = /50x.html {}}5. Jmeter压测数据写入Influxdb
在相应Thread Group中添加Backend Listener,最好给不同的Backend Listener 起不同的名字,防止同时多脚本压测时出现数据写入混乱的问题;
-
1. 选择指定implementation
-
2.填写influxdb所在地址和端口,以及数据库名,如下截图(因为脚本要跑在Linux内网环境,所以 URL 我写的是内网IP)
-
3.measurement名字填写jmeter
-
4.application 可以填写指定名称(不同脚本)
-
5.填写的application名称会在Dashboard中的 application内显示,执行压测脚本时,会显示实时数据
-
6.Transaction 显示的是Samper名称
效果展示

6. Node-exporter部署,监控发压机
在需要监控的机器上,使用docker方式部署node-exporter
新服务器部署node-exporter 步骤
docker pull prom/node-exporterdocker run -d --net="host" --name node_exporter --restart=unless-stopped -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter然后在prometheus中配置该node-exporter所在地址和端口号 - job_name: 'Jmeter-slave-'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['IP:9100']加上新配置的node-exporter之后,使用命令在prometheus所在机器 进行 prometheus热加载更新,然后访问Prometheus web页面,确认该node-exporter是否添加到监控体系当中
curl -X POST http://ip:9090/-/reload7.Grafana展示Jmeter实时压测数据+展示Node-exporter数据
点击grafana的logo看到COMPLETE,add data source 新增数据源
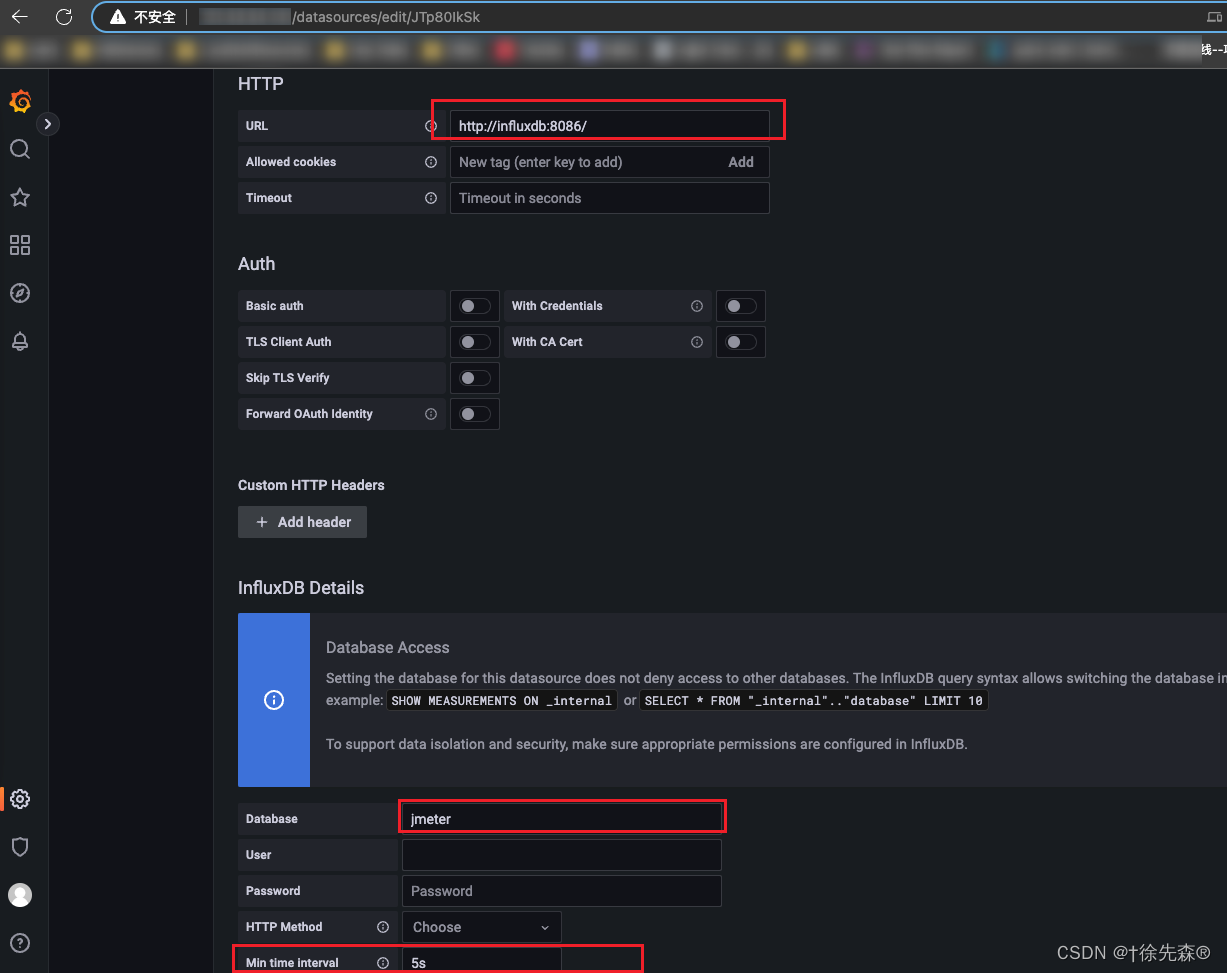
1.Grafana 配置 Jmeter压测数据源
指定docker中的influxdb:8086,并指定jmeter数据库,点击save and test 通过即成功;
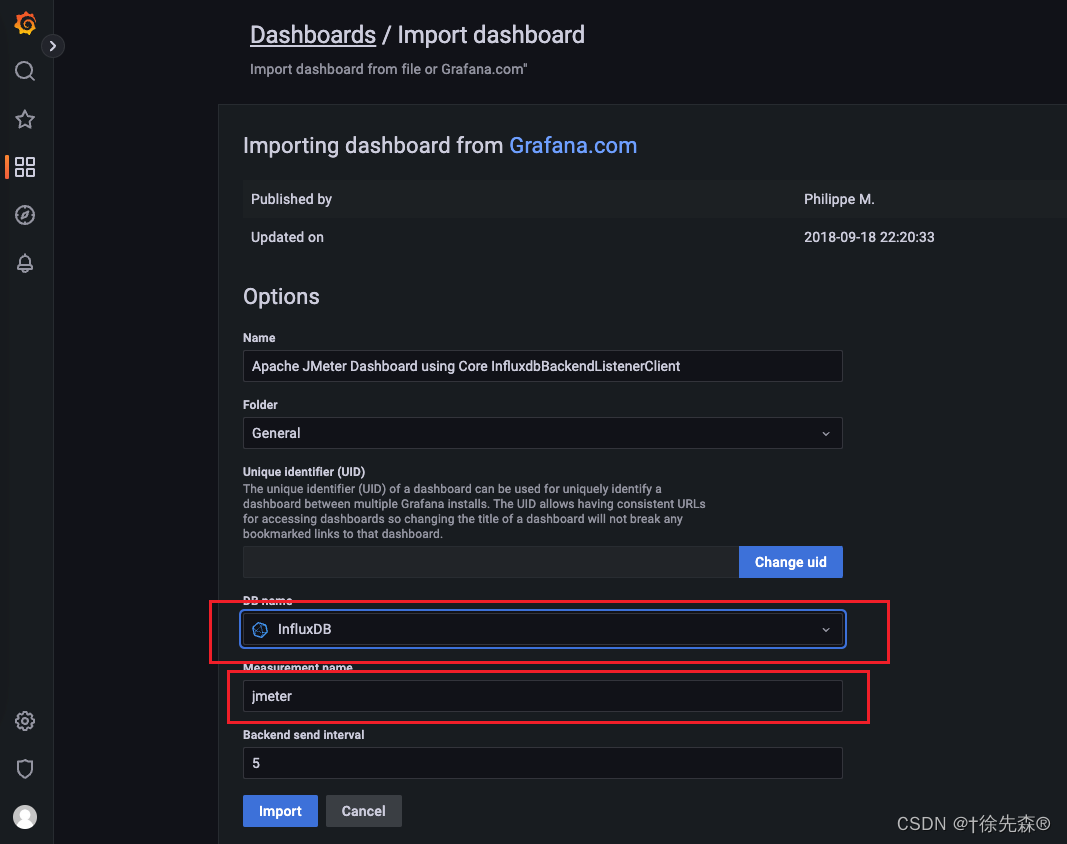
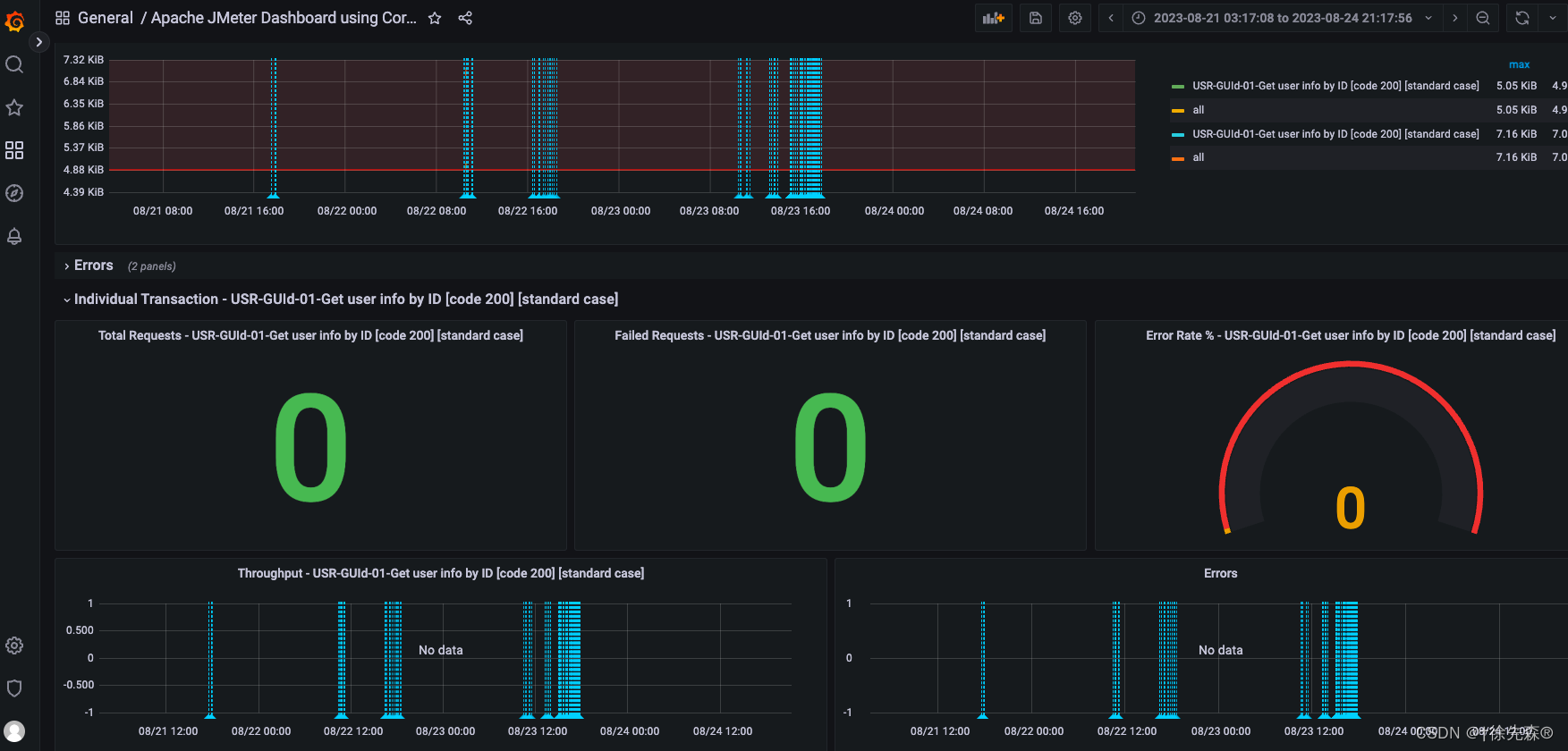
2. 展示Jmeter实时压测数据
Import 5496,点击load,加载出来后指定刚增加的data source Influxdb,指定表名字 jmeter,点击import ;

压测时即可看到实时数据,展示效果如下
application名称是Backend listener中填写的application 名称
Transaction 显示的是Samper名称

3.添加Prometheus+node-exporter主机监控数据源
仿照上述新增数据源,内网ip/prometheus/,测试通过即可

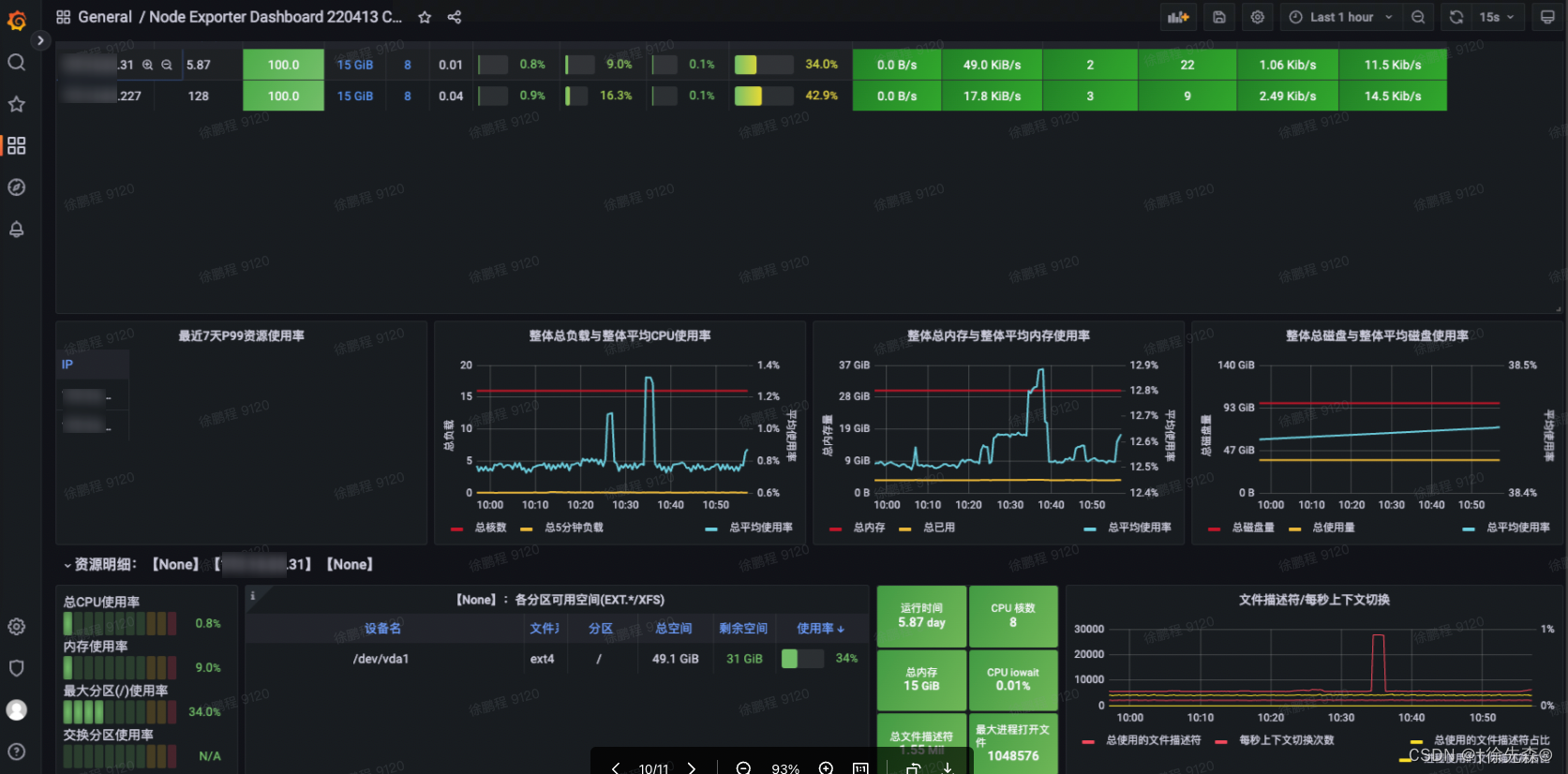
4. 展示主机监控数据,添加Dashboard
import dash board 8919,导入并保存即可
效果展示
问题总结
1. 为什么用Nginx?
因为运维只给开一个端口,但是还有那么多服务需要用,所以用作端口代理。
2. 为什么用Docker?
因为Docker部署更加方便。
3. Docker和Jmeter压测时时间不一致,无法写入数据(Grafana和Jmeter压测时间)
docker run -p 3306:3306 --name mysql -v /etc/localtime:/etc/localtime
根据需求更改启动容器时的参数,将宿主机的时间和docker时间一致(docker和宿主机在同一台机器)4. Jmeter数据无法写入Influxdb数据库,查询measurements为空
Jmeter:配置后端监听器(Backend Listener),使用Nginx作为端口转发,将Influxdb的服务映射到/influxdb路径
5.Jmeter入库后,Grafana配置数据源失败
在docker中运行时指定docker内influx的网络,配置时使用influxdb:8086
6.Grafana展示Jmeter中的数据为空
配置后端监听器measurement值为jmeter,否则读取不到数据
7.多个脚本同时执行添加了后端监听器,压测数据被写入到同一个Application库中
默认根据监听器名称进行判断监听器有没有执行,解决方案,不同后端监听器起不同的名称
8. Grafana 监控发压机 指标数据显示 no data
使用curl查看9100是否能取到node-exporter数据,如果可以取到 去prometheus web页面查看prometheus是否配置成功
相关文章:
Jmete+Grafana+Prometheus+Influxdb+Nginx+Docker架构搭建压测体系/监控体系/实时压测数据展示平台+遇到问题总结
背景 需要大批量压测时,单机发出的压力能力有限,需要多台jmeter来同时进行压测;发压机资源不够,被压测系统没到瓶颈之前,发压机难免先发生资源不足的情形;反复压测时候也需要在不同机器中启动压测脚本&…...

php提交表单将html相互字符转化的封装函数
在 PHP 中,您可以使用 htmlspecialchars() 函数将 HTML 字符转换为文本。该函数将把 <、>、" 和 等特殊字符转换为对应的 HTML 实体,从而避免跨站点脚本(XSS)攻击。 例如,如果您有一个表单输入字段的值&a…...
7 Series FPGAs GTX/GTH Transceivers
目录 1. Overview2. Block Diagram3. Transmitter4. Receiver5. Physical Coding Sublayer(PCS)6. Physical Medium Attachment(PMA)本博客为Xilinx 7系列FPGA的千兆比特高速收发器(Gigabit Transceiver, GT)介绍 ug476 - 7 Series FPGAs GTX GTH TransceiversUser Guide…...

iOS系统下轻松构建自动化数据收集流程
在当今信息爆炸的时代,我们经常需要从各种渠道获取大量的数据。然而,手动收集这些数据不仅耗费时间和精力,还容易出错。幸运的是,在现代科技发展中有两个强大工具可以帮助我们解决这一问题——Python编程语言和iOS设备上预装的Sho…...

Android基础之Activity生命周期
Activity是Android四大组件之一、称为之首也恰如其分。 Activity直接翻译为中文叫活动。在Android系统中Activity就是我看到的一个完整的界面。 界面中看到的TextView(文字)、Button(按钮)、ImageView(图片)都是需要Activity来承载的。 总…...
:安装和使用方法)
Golang 程序漏洞检测利器 govulncheck(一):安装和使用方法
govulncheck 是什么? govulncheck 是一个命令行工具,可以帮助 Golang 开发者快速找到项目代码和依赖的模块中的安全漏洞。该工具可以分析源代码和二进制文件,识别代码中对这些漏洞的任何直接或间接调用。 默认情况下,govulnchec…...

强化学习算法总结 2
强化学习算法总结 2 4.动态规划 待解决问题分解成若干个子问题,先求解子问题,然后得到目标问题的解 需要知道整个状态转移函数和价值函数,状态空间离散且有限 策略迭代: 策略评估:贝尔曼期望方程来得到一个策略的 V ( s ) V(s…...

修改node_modules避免更新覆盖 patch-package
说明:直接修改第三方库的代码,会带来团队协作的问题,使用patch-package生成补丁包 什么是 patch-package? patch-package 是一个基于 Git 的工具,它可以帮助我们对依赖包进行修复补丁。通过创建一个与问题相关的补丁文…...
Elasticsearch安装,Springboot整合Elasticsearch详细教程
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够实现近乎实时的搜索。 Elasticsearch官网https://www.elastic.co/cn/ 这篇文章主要简单介绍一下Elasticsearch,Elasticsearch的java API博主也在学习中,文章会持续更新~ …...
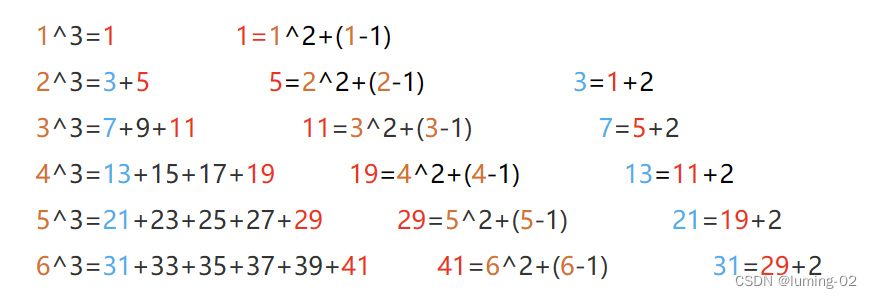
OJ题库:计算日期到天数转换、打印从1到最大的n位数 、尼科彻斯定理
前言:在部分大厂笔试时经常会使用OJ题目,这里对《华为机试》和《剑指offer》中的部分题目进行思路分析和讲解,希望对各位读者有所帮助。 题目来自牛客网,欢迎各位积极挑战: HJ73:计算日期到天数转换_牛客网 JZ17:打印…...
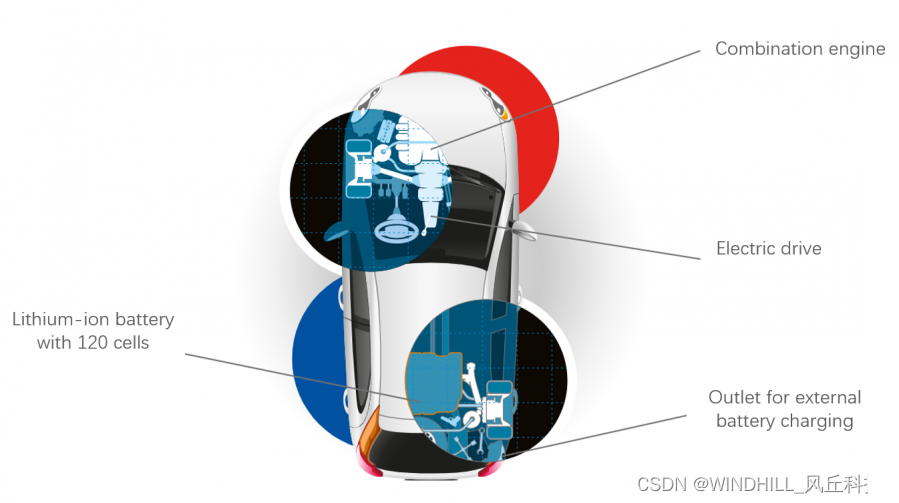
混合动力汽车耐久测试
一 背景 整车厂可通过发动机和电机驱动的结合为多款车型提供混合动力驱动技术。汽车集成电机驱动可大大减少二氧化碳的排放,不仅如此,全电动驱动或混合动力驱动的汽车还将使用户体验到更好的驾驶感受,且这种汽车可通过电动机来实现更快的加速…...
useRef 定义的 ref 在控制台可以打印但是页面不生效?
useRef 是一个 React Hook,它能让你引用一个不需要渲染的值。 点击计时器 点击按钮后在控制台可以打印但是页面不生效。 useRef 返回的值在函数组件中不会自动触发重新渲染,所以控制台可以显示变化而按钮上无法显示 ref.current的变化。 import { use…...
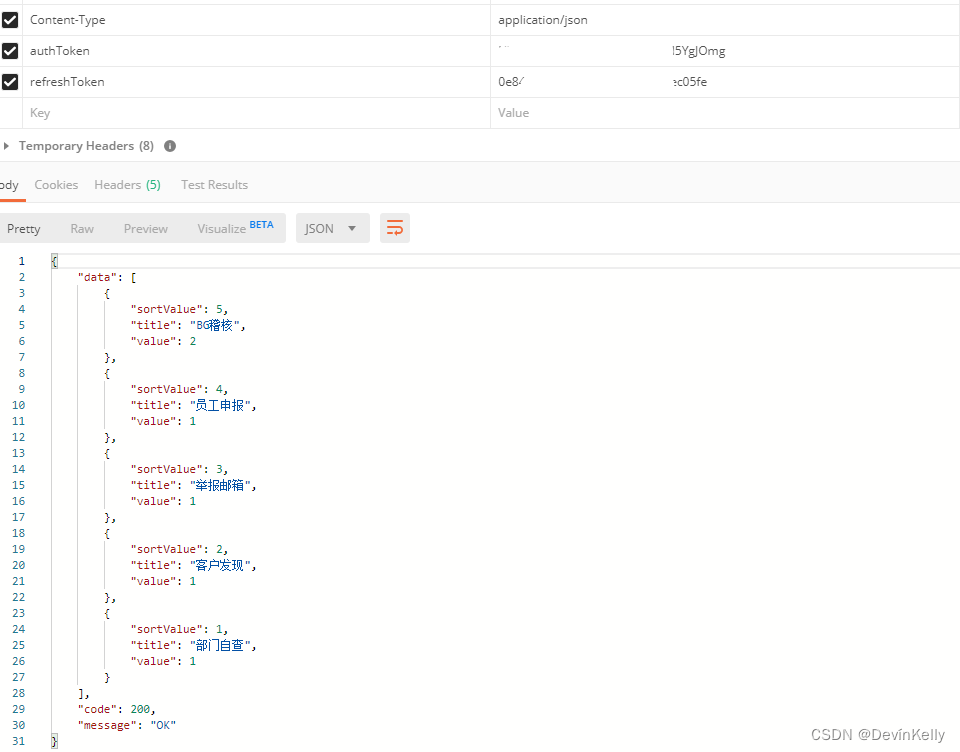
【Java 动态数据统计图】动态数据统计思路案例(动态,排序,动态数组(重点推荐))七(129)
需求:前端根据后端的返回数据:画统计图; 说明: 1.X轴为地域,Y轴为地域出现的次数; 2. 动态展示(有地域展示,没有不展示,且高低排序) Demo案例: …...

Cell Reports | 揭开METTL14在介导m6A修饰中的神秘面纱
m6A被认为是最丰富的mRNA修饰,广泛分布在大多数真核生物中,包括哺乳动物、植物、昆虫、酵母和某些病毒。m6A修饰的沉积和去除之间的动态平衡对于正常的生物过程和发育至关重要,如失调通常与癌症等疾病有关。m6A修饰由m6A甲基转移酶复合物&…...

297. 二叉树的序列化与反序列化
题目描述 序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。 请设计一个算法来实现二叉树的序列化与反序…...
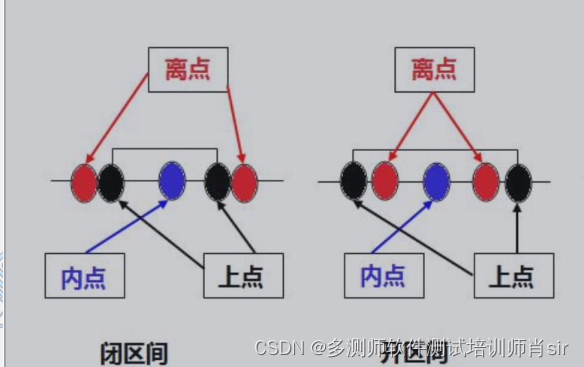
肖sir__设计测试用例方法之边界值03_(黑盒测试)
设计测试用例方法之边界值 边界点定义 上点:边界上的点 离点:离上点最近的点(即上点左右两边最邻近的点) 内点:在域范围内的点 案例:qq号:5-12位 闭区间: 离点:5 位 &…...

功能测试常用的测试用例大全
登录、添加、删除、查询模块是我们经常遇到的,这些模块的测试点该如何考虑 1)登录 ① 用户名和密码都符合要求(格式上的要求) ② 用户名和密码都不符合要求(格式上的要求) ③ 用户名符合要求,密码不符合要求(格式上的要求) ④ 密码符合要求,…...

css利用flex分配剩余高度出现子组件溢出问题
1.利用flex分配剩余高度/宽度 情景:父组件高度一定,子组件中,其他子组件高度固定,一个子组件高度不确定(页面滚动列表) .father{display: flex;flex-direction: column;.son1{height: 200px;}.son2{//或 …...
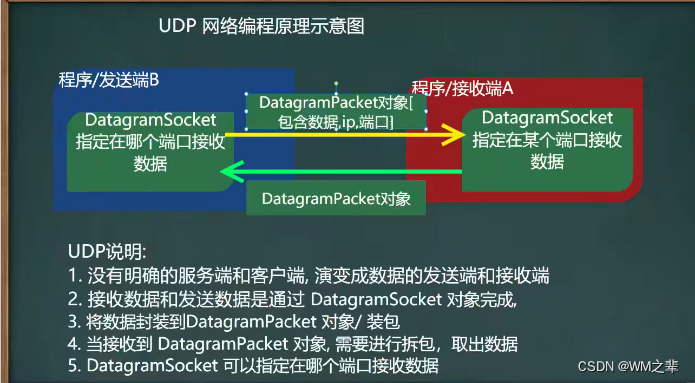
Java中的网络编程------基于Socket的TCP编程和基于UDP的网络编程,netstat指令
Socket 在Java中,Socket是一种用于网络通信的编程接口,它允许不同计算机之间的程序进行数据交换和通信。Socket使得网络应用程序能够通过TCP或UDP协议在不同主机之间建立连接、发送数据和接收数据。以下是Socket的基本介绍: Socket类型&…...

【【STM32-29正点原子版本串口发送传输实验】
STM32-29正点原子版本串口发送传输实验 通过串口接收或发送一个字符 例程目的 开发板上我们接入的是实现异步通信的UART接口 USB转串口原理图 我们一步步分析 PA9是串口1 的发送引脚 PA10是串口1 的接受引脚 。因为我们现在只是用到异步收发器功能,所以我们现…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...
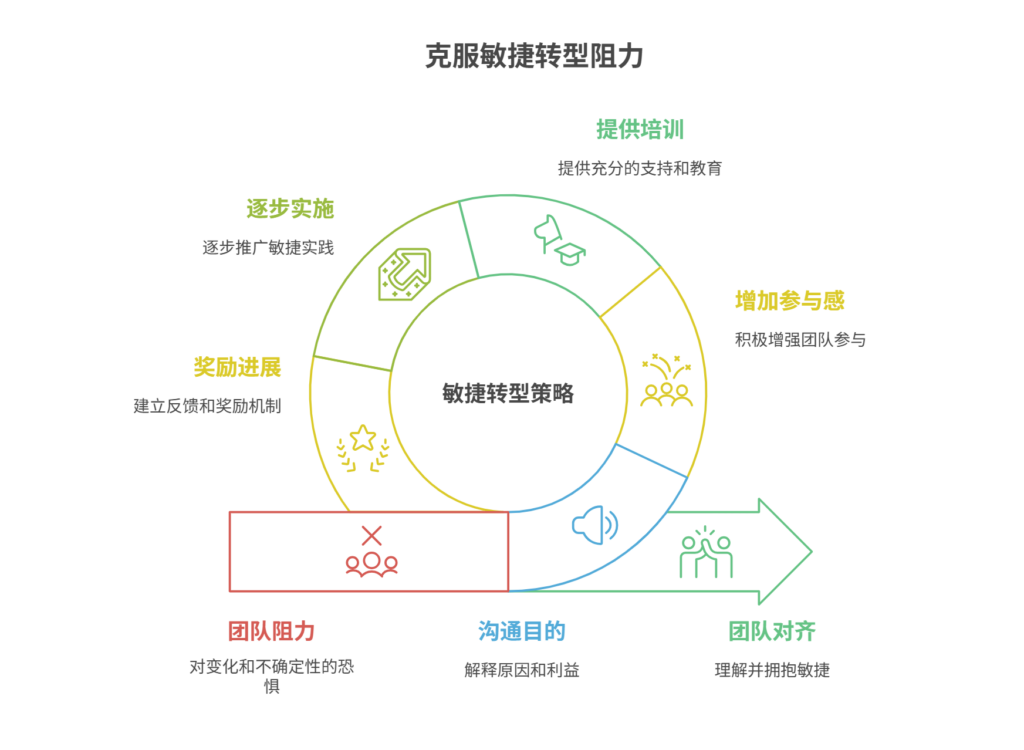
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...