Spark【RDD编程(二)RDD编程基础】
前言
接上午的那一篇,下午我们学习剩下的RDD编程,RDD操作中的剩下的转换操作和行动操作,最好把剩下的RDD编程都学完。
Spark【RDD编程(一)RDD编程基础】
RDD 转换操作
6、distinct
对 RDD 集合内部的元素进行去重,然后把去重后的其他元素放到一个新的 RDD 集合内。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object RDDTransForm {def main(args: Array[String]): Unit = {// 创建SparkContext对象val conf = new SparkConf()conf.setAppName("spark core rdd transform").setMaster("local")val sc = new SparkContext(conf)// 通过并行集合创建RDD对象val arr = Array("Spark","Flink","Spark","Storm")val rdd1: RDD[String] = sc.parallelize(arr)val rdd2: RDD[String] = rdd1.distinct()rdd2.foreach(println)//关闭SparkContextsc.stop()}
}
运行输出:
Flink
Spark
Storm可以看到,重复的元素"Spark"被去除掉。
7、union
// 通过并行集合创建RDD对象val arr1 = Array("Spark","Flink","Storm")val arr2 = Array("Spark","Flink","Hadoop")val rdd1: RDD[String] = sc.parallelize(arr1)val rdd2: RDD[String] = sc.parallelize(arr2)val rdd3: RDD[String] = rdd1.union(rdd2)rdd3.foreach(println)运行结果:
Spark
Flink
Storm
Spark
Flink
Hadoop8、intersection
对两个RDD 集合进行交集运算。
// 通过并行集合创建RDD对象val arr1 = Array("Spark","Flink","Storm")val arr2 = Array("Spark","Flink","Hadoop")val rdd1: RDD[String] = sc.parallelize(arr1)val rdd2: RDD[String] = sc.parallelize(arr2)val rdd3: RDD[String] = rdd1.intersection(rdd2)rdd3.foreach(println)运行结果:
Spark
Flink
"Spark"和"Flink"是两个RDD集合都有的。
9、subtract
对两个RDD 集合进行差集运算,并返回新的RDD 集合。
rdd1.substract(rdd2) 返回的是 rdd1有而rdd2中没有的元素,并不会把rdd2中有rdd1中没有的元素也包进来。
// 通过并行集合创建RDD对象val arr1 = Array("Spark","Flink","Storm")val arr2 = Array("Spark","Flink","Hadoop")val rdd1: RDD[String] = sc.parallelize(arr1)val rdd2: RDD[String] = sc.parallelize(arr2)val rdd3: RDD[String] = rdd1.subtract(rdd2)rdd3.foreach(println)运算结果:
Storm"Storm"是rdd1中有的二rdd2中没有的,并不会返回"Hadoop"。
10、zip
把两个 RDD 集合中的元素以键值对的形式进行合并,所以需要确保两个RDD 集合的元素个数必须是相同的。
// 通过并行集合创建RDD对象val arr1 = Array("Spark","Flink","Storm")val arr2 = Array(1,3,5)val rdd1: RDD[String] = sc.parallelize(arr1)val rdd2: RDD[Int] = sc.parallelize(arr2)val rdd3: RDD[(String,Int)] = rdd1.zip(rdd2)rdd3.foreach(println)运行结果:
(Spark,1)
(Flink,3)
(Storm,5)RDD 行动操作
RDD 的行动操作是真正触发计算的操作,计算过程十分简单。
1、count
返回 RDD 集合中的元素数量。
2、collect
以数组的形式返回 RDD 集合中所有元素。
3、first
返回 RDD 集合中的第一个元素。
4、take(n)
返回 RDD 集合中前n个元素。
5、reduce(func)
以规则函数func对RDD集合中的元素进行循环处理,比如将所有元素加到一起或乘起来。
6、foreach
对RDD 集合进行遍历,输出RDD集合中所有元素。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object RDDAction {def main(args: Array[String]): Unit = {// 创建SparkContext对象val conf = new SparkConf()conf.setAppName("spark core rdd transform").setMaster("local")val sc = new SparkContext(conf)//通过并行集合创建 RDD 对象val arr: Array[Int] = Array(1,2,3,4,5)val rdd: RDD[Int] = sc.parallelize(arr)val size: Long = rdd.count()val nums: Array[Int] = rdd.collect()val value: Int = rdd.first()val res: Array[Int] = rdd.take(3)val sum: Int = rdd.reduce((v1, v2) => v1 + v2)println("size = " + size)println("The all elements are ")nums.foreach(println)println("The first element in rdd is " + value)println("The first three elements are ")res.foreach(println)println("sum is " + sum)rdd.foreach(print)//关闭SparkContextsc.stop()}}
运行结果:
size = 5
The all elements are
1
2
3
4
5
The first element in rdd is 1
The first three elements are
1
2
3
sum is 15
12345
Process finished with exit code 0文本长度计算案例
计算 data 目录下的文件字节数(文本总长度)。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object FileLength {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("spark core rdd transform").setMaster("local")val sc = new SparkContext(conf)val rdd1: RDD[String] = sc.textFile("data")val rdd2: RDD[Int] = rdd1.map(line => line.length)val fileLength: Int = rdd2.reduce((len1, len2) => len1 + len2)println("File length is " + fileLength)sc.stop()}
}持久化
在Spark 中,RDD采用惰性机制,每次遇到行动操作,就会从头到尾开始执行计算,这对于迭代计算代价是很大的,因为迭代计算经常需要多次重复使用相同的一组数据。
- 使用cache() 方法将需要持久化的RDD对象持久化进缓存中
- 使用unpersist() 方法将持久化rdd从缓存中释放出来
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object RDDCache {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("spark core rdd transform").setMaster("local")val sc = new SparkContext(conf)val list = List("Hadoop","Spark","Hive","Flink")val rdd: RDD[String] = sc.parallelize(list)rdd.cache()println(rdd.count()) //第一次行动操作println(rdd.collect.mkString(",")) //第二次行动操作rdd.unpersist() //把这个持久化的rdd从缓存中移除,释放内存空间sc.stop()}
}
分区
分区的作用
RDD 是弹性分布式数据集,通过 RDD 都很大,会被分成多个分区,分别保存在不同的节点上。进行分区的好处:
- 增加并行度。一个RDD不分区直接进行计算的话,不能充分利用分布式集群的计算优势;如果对RDD集合进行分区,由于一个文件保存在分布式系统中不同的机器节点上,可以就近利用本分区的机器进行计算,从而实现多个分区多节点同时计算,并行度更高。
- 减少通信开销。通过数据分区,对于一些特定的操作(如join、reduceByKey、groupByKey、leftOuterJoin等),可以大幅度降低网络传输。
分区的原则
使分区数量尽量等于集群中CPU核心数目。可以通过设置配置文件中的 spark.default.parallelism 这个参数的值,来配置默认的分区数目。
设置分区的个数
1、创建 RDD对象时指定分区的数量
1.1、通过本地文件系统或HDFS加载
sc.textFile(path,partitionNum)1.2、通过并行集合加载
对于通过并行集合来创建的RDD 对象,如果没有在参数中指定分区数量,默认分区数目为 min(defaultParallelism,2) ,其中defaultParallelism就是配置文件中的spark.default.parallelism。如果是从HDFS中读取文件,则分区数目为文件分片的数目。
2、使用repartition()方法重新设置分区个数
val rdd2 = rdd1.repartition(1) //重新设置分区为1自定义分区函数
继承 org.apache.spark.Partitioner 这个类,并实现下面3个方法:
- numPartitions: Int ,用于返回创建出来的分区数。
- getPartition(key: Any),用于返回给定键的分区编号(0~paratitionNum-1)。
- equals(),Java中判断相等想的标准方法。
注意:Spark 的分区函数针对的是(key,value)类型的RDD,也就是说,RDD中的每个元素都是(key,value)类型的,然后函数根据 key 对RDD 元素进行分区。所以,当要对一些非(key,value)类型的 RDD 进行自定义分区时,需要首先把 RDD 元素转换为(key,value)类型,然后再使用分区函数。
案例
将奇数和偶数分开写到不同的文件中去。
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}class MyPartitioner(numParts: Int = 2) extends Partitioner{//覆盖默认的分区数目override def numPartitions: Int = numParts//覆盖默认的分区规则override def getPartition(key: Any): Int = {if (key.toString.toInt%2==0) 1 else 0}
}
object MyPartitioner{def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("partitioner").setMaster("local")val sc: SparkContext = new SparkContext(conf)val data: Array[Int] = (1 to 100).toArrayval rdd: RDD[Int] = sc.parallelize(data,5)val savePath:String = System.getProperty("user.dir")+"/data/rdd/out"rdd.map((_,1)).partitionBy(new MyPartitioner()).map(_._1).saveAsTextFile(savePath)sc.stop()}
}我们在代码中创建RDD 对象的时候,我们指定了分区默认的数量为 5,然后我们使用我们自定义的分区,观察会不会覆盖掉默认的分区数量:
运行结果:
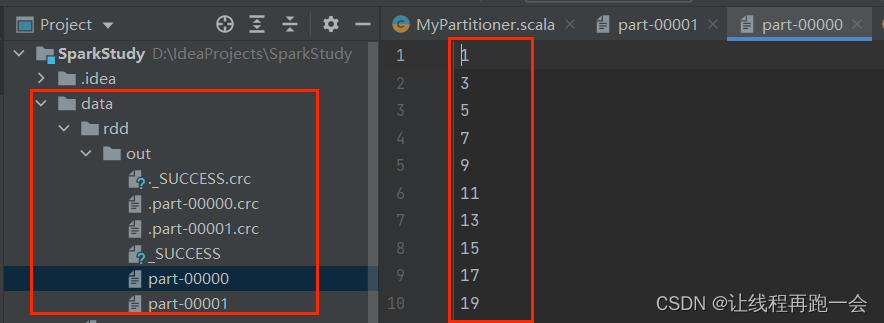
我们可以看到,除了校验文件,一共生成了两个文件,其中一个保存了1~100的所有奇数,一个保存了1~100的所有偶数;
综合案例
在上一篇博客中,我们已经做过WordCount了,但是明显篇幅比较长,这里我们简化后只需要两行代码:
//使用本地文件作为数据加载创建RDD 对象val rdd: RDD[String] = sc.textFile("data/word.txt")//RDD("Hadoop is good","Spark is better","Spark is fast")val res_rdd: RDD[(String,Int)] = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)//flatMap://RDD(Array("Hadoop is good"),Array("Spark is better"),Array("Spark is fast"))//RDD("Hadoop","is",good","Spark","is","better","Spark","is","fast"))运行结果:
(Spark,2)
(is,3)
(fast,1)
(good,1)
(better,1)
(Hadoop,1)总结
至此,我们RDD基础编程部分就结束了,但是RDD编程还没有结束,接下来我会继续学习键值对RDD、数据读写,最后总结性低做一个大的综合案例。
相关文章:
Spark【RDD编程(二)RDD编程基础】
前言 接上午的那一篇,下午我们学习剩下的RDD编程,RDD操作中的剩下的转换操作和行动操作,最好把剩下的RDD编程都学完。 Spark【RDD编程(一)RDD编程基础】 RDD 转换操作 6、distinct 对 RDD 集合内部的元素进行去重…...
【2023最新版】MySQL安装教程
目录 一、MySQL简介 二、MySQL安装 1. 官网 2. 下载 3. 安装 4. 配置环境变量 配置前 配置中 配置后 5. 验证 一、MySQL简介 MySQL是一种开源的关系型数据库管理系统(RDBMS),它被广泛用于存储和管理结构化数据。MySQL提供了强大的功…...

关于mysql数据文件损坏导致的mysql无法启动的问题
环境 rocky linux 9 (跟centos几乎一模一样) myqsl 8.0, 存储引擎使用innodb 问题描述 1. 服务器异常关机,重启启动后发现mysql无法连接,使用命令查看mysql状态: systemctl status mysqld 发现mysql服…...
深度学习之视频分类项目小记
写在前面,最近一阵在做视频分类相关的工作,趁有时间来记录一下。本文更注重项目实战与落地,而非重点探讨多模/视频模型结构的魔改 零、背景 目标:通过多模态内容理解技术,构建视频层级分类体系原技术方案:…...
pandas(四十三)Pandas实现复杂Excel的转置合并
一、Pandas实现复杂Excel的转置合并 读取并筛选第一张表 df1 pd.read_excel("第一个表.xlsx") df1# 删除无用列 df1 df1[[股票代码, 高数, 实际2]].copy() df1df1.dtypes股票代码 int64 高数 float64 实际2 int64 dtype: object读取并处理第二张表…...
42、springboot 的 路径匹配 和 内容协商
springboot 的 路径匹配 和 内容协商 对于路径匹配,自己的总结就是: 以前路径匹配时默认不检查后缀,http://localhost:8080/aaa.json 可以直接访问到 RequstMapping(“/aaa”) 的方法。现在不行了。现在会检查后缀了。 内容协商的理解总结&…...

一文讲解Linux内核内存管理架构
内存管理子系统可能是linux内核中最为复杂的一个子系统,其支持的功能需求众多,如页面映射、页面分配、页面回收、页面交换、冷热页面、紧急页面、页面碎片管理、页面缓存、页面统计等,而且对性能也有很高的要求。本文从内存管理硬件架构、地址…...

教你如何使用API接口获取数据
随着互联网技术的发展和应用的普及,越来越多的系统和应用提供API接口供其他系统和应用进行数据交互。通过API接口,我们可以获取到各种各样的数据,例如天气预报、股票行情、新闻摘要等等。本文将介绍如何使用API接口获取数据,并附有…...
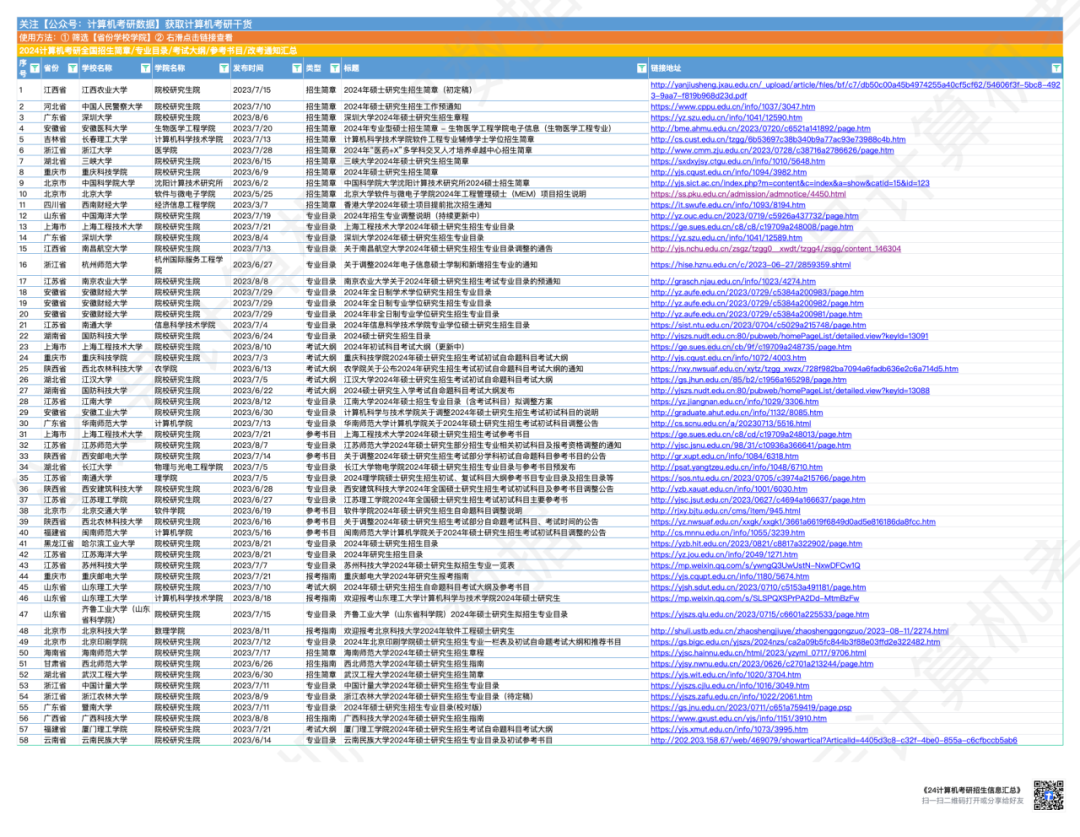
集美大学计算机改考408!福建省全面改考,仅剩一个自命题院校
9月5日,集美大学发布通知,0835软件工程、0854电子信息2024考试科目发生变更!由822数据结构调整为408计算机学科专业基础 https://zsb.jmu.edu.cn/info/1532/4701.htm 直接由一门改为考四门,难度升级不小。 目前福建省内计算机考…...
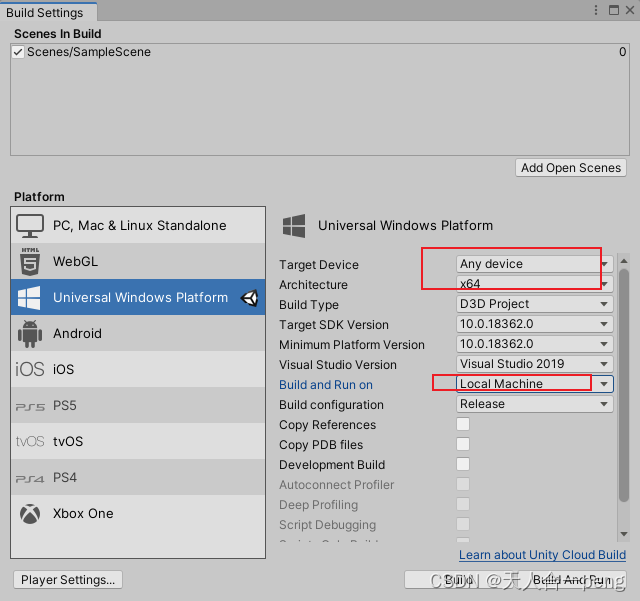
Hololens2部署很慢可能是unity工程选择不对
这样就很快,几分钟就完成了。(虽然又遇到新问题了) 第一次使用时如下,直接运行了一个多小时还没有完...

群论学习记录
群论学习记录 1. 2023.09.07 1. 2023.09.07 群论 (Group Theory) 终极速成 / 物理系零基础火箭级 notes https://zhuanlan.zhihu.com/p/378039151 https://zhuanlan.zhihu.com/p/164653537 群的定义重排定理子群陪集定理:由重排定理可推出1.4-(2&#x…...

Fiddler安装与使用教程(2) —— 软测大玩家
😏作者简介:博主是一位测试管理者,同时也是一名对外企业兼职讲师。 📡主页地址:【Austin_zhai】 🙆目的与景愿:旨在于能帮助更多的测试行业人员提升软硬技能,分享行业相关最新信息。…...

ChatGPT集锦
目录 1. 一条指令让ChatGPT变的更强大2. 对ChatGPT提问时,常见的10种错误描述3. Custom instructions如何设置1. 一条指令让ChatGPT变的更强大 在使用GPT的过程中,如何让AI更清晰地了解你的需求很重要?今天分享一个指令,可以让GPT成为你的好同事,与你一起分析和解决问题,…...
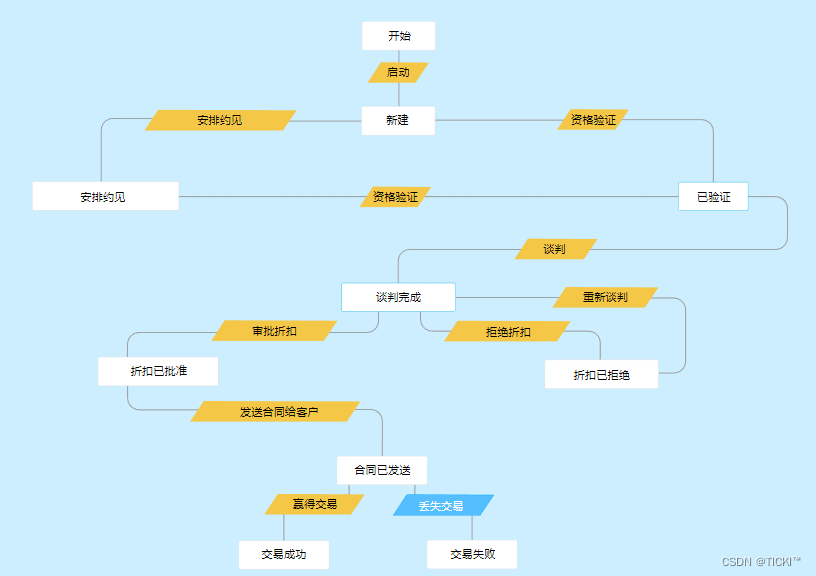
CRM系统中的工作流管理及其重要性
工作流是CRM系统中较为常见的功能,它可以有效减少重复工作、提高销售效率。如果您想深入了解,本文就来详细说说,CRM工作流是什么?工作流的作用? 什么是CRM工作流? CRM工作流是指在CRM系统中,根…...
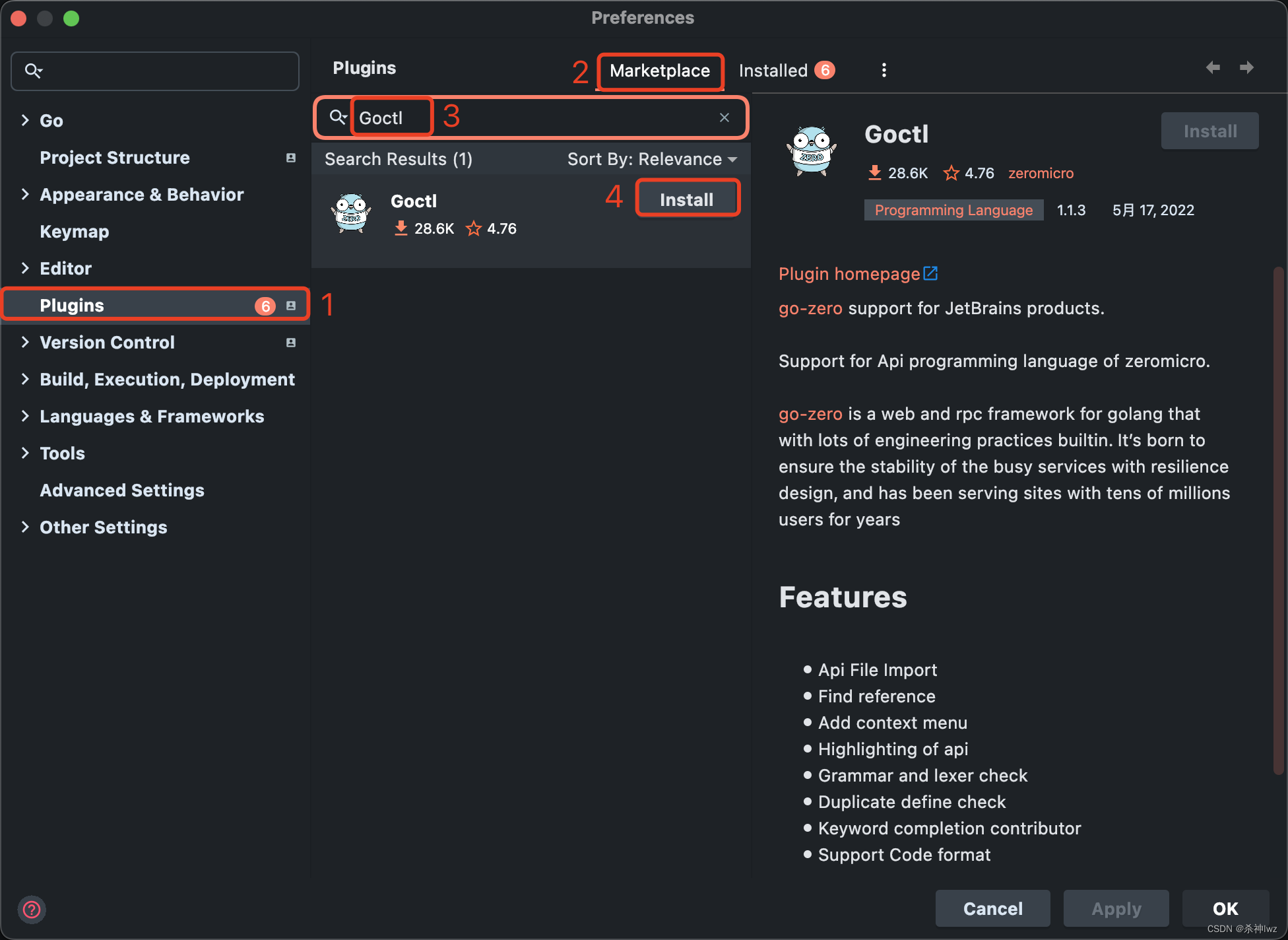
Go framework-go-zero
一、Go Go天然适配云原生,而云原生时代已经到来,各个应用组件基础设施等都应该积极的去拥抱云原生。 不要让框架束缚开发。 1、go-zero介绍 go-zero 是一个集成了各种工程实践的 web 和 rpc 框架。通过弹性设计保障了大并发服务端的稳定性,…...
【Python】【Fintech】用Python和蒙特卡洛法预测投资组合未来收益
【背景】 想利用蒙特卡洛方法和yahoo,stooq等财经网站上的数据快速预测特定portfolio的收益。 【分析】 整个程序的功能包括 读取json中的portfolio组合创建蒙特卡洛模拟预测收益的算法创建从财经网站获得特定投资组合数据,并根据2的算法获得该Index或Portfolio收益预测结…...
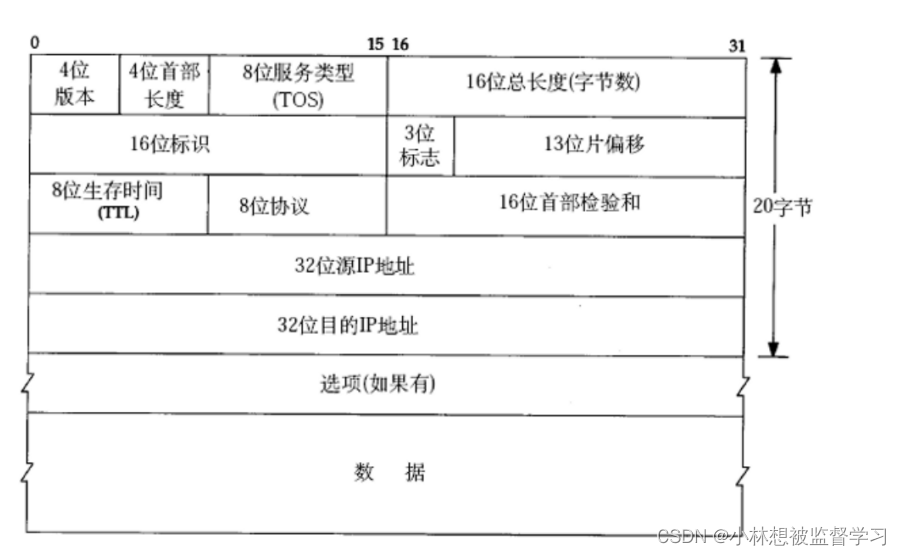
网络层重点协议-IP协议(结构分析)
IP协议数据报格式 一.4位版本号 用来表示IP协议的版本,现有的IP协议只有两个版本IPv4和IPv6 二.4位首部长度 IP协议数据报报头的长度 三.8位服务类型 3位优先权字段(已经弃用),4位TOS字段,和1位保留 字段(必…...

windows使用vim编辑文本powershell
windows使用vim编辑文本 1、安装 chocolatey 包 以管理员身份打开 PowerShell 进行安装 Set-ExecutionPolicy Bypass -Scope Process -Force; iex ((New-Object System.Net.WebClient).DownloadString(https://chocolatey.org/install.ps1))2、管理员身份打开 PowerShell 并使…...

学单片机有前途吗?
学单片机有前途吗? 个人认为学习任何一门技术都比不学的强,针对学单片机有前途吗?那么比较对象当然就是在整个IT行业做对比。因此我们可以从职业前景、钱景、这几方面综合考量。 学单片机有前途吗?我觉得重要的一点就是是否适合职业生涯发展,总说程序…...
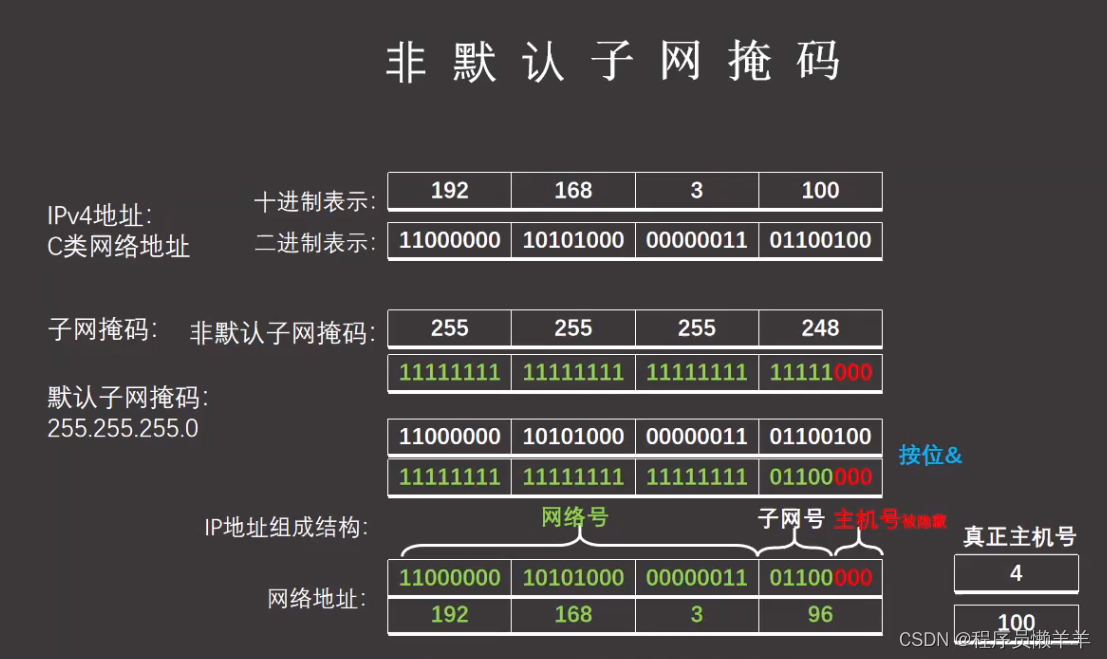
【计算机网络】 子网划分
文章目录 IP地址分类子网掩码网关广播地址非默认子网掩码子网划分常见问题 IP地址分类 学会十进制和二进制的相互转换可以很快速的有规律的记住 子网掩码 又叫网络掩码,地址掩码,子网络遮罩,就是说把子网络遮起来,不让外界窥探到…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...
之(六) ——通用对象池总结(核心))
怎么开发一个网络协议模块(C语言框架)之(六) ——通用对象池总结(核心)
+---------------------------+ | operEntryTbl[] | ← 操作对象池 (对象数组) +---------------------------+ | 0 | 1 | 2 | ... | N-1 | +---------------------------+↓ 初始化时全部加入 +------------------------+ +-------------------------+ | …...